SV-Detect: AI-generated Text Detection with Steering Vectors
Pith reviewed 2026-06-27 22:14 UTC · model grok-4.3
The pith
Steering vectors extracted layer by layer from a frozen language model separate human-written from machine-generated text and support accurate detection even after domain changes, model switches, or editing attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
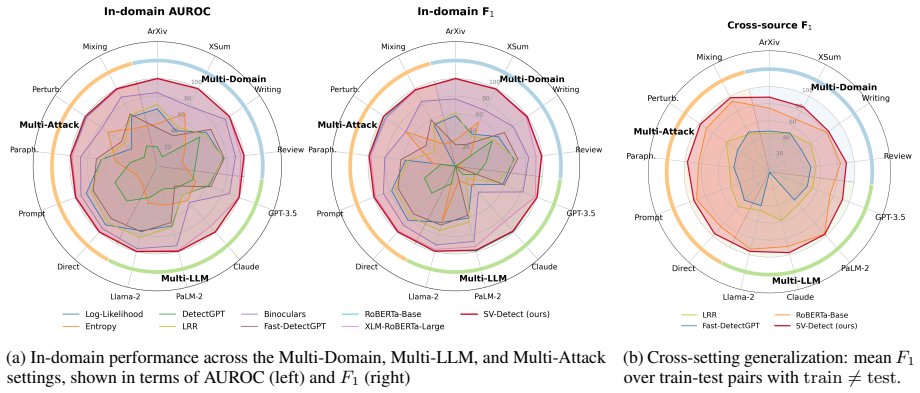
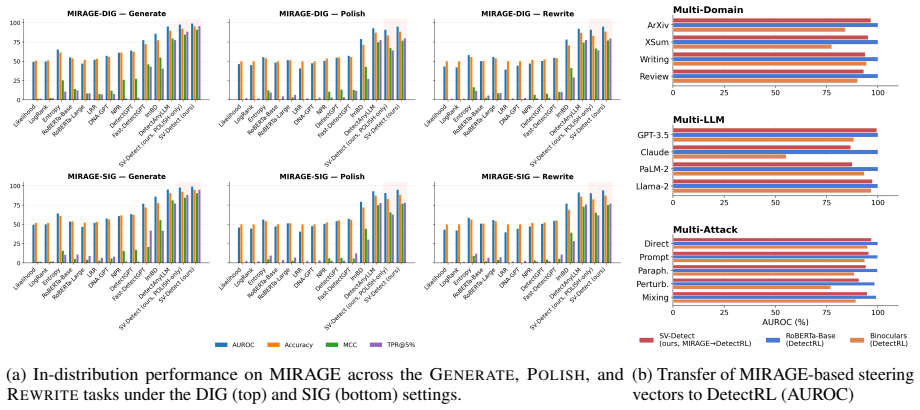
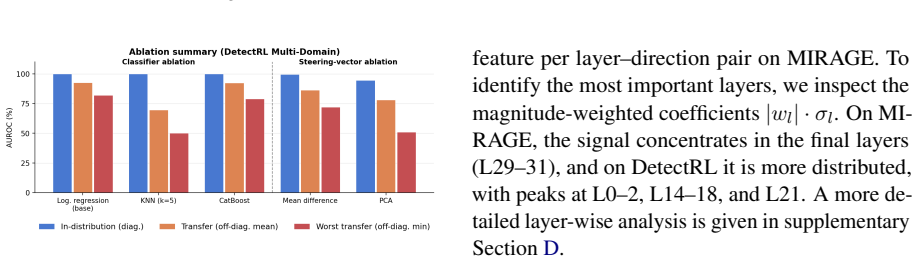
A detector is built by computing, at every layer of a frozen language model, the direction that best separates hidden representations of human-written text from machine-generated text; each new input is represented by its projection onto these layer-wise directions, and a lightweight classifier trained on the resulting feature vectors yields the final detection score. This construction achieves strong accuracy both in-distribution and under distribution shift across domains, source models, and machine-editing operations such as polishing and rewriting.
What carries the argument
Steering vectors: the set of layer-specific directions in hidden representation space that separate human from machine text, used as projection features for classification.
If this is right
- The same layer-wise directions remain informative when the source model or domain changes.
- Performance holds after polishing or rewriting edits performed by another model.
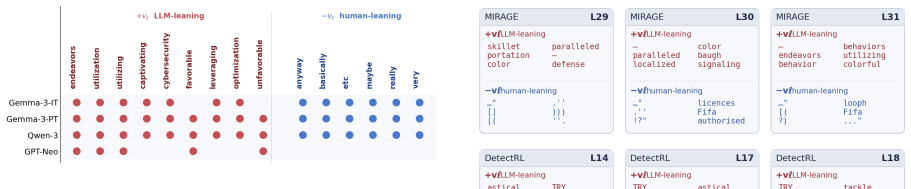
- The directions capture stylistic cues plus signal beyond surface-level features.
- Fake-text detection reduces to finding and using these representation-space directions.
Where Pith is reading between the lines
- If the directions are stable across many shifts, they may also help detect text generated by entirely unseen future models.
- The method could be tested on distinguishing text from two different machine sources rather than human versus machine.
- Layer-wise projections might serve as a lightweight probe for other generation-related properties such as factual consistency.
Load-bearing premise
Stable separating directions exist in the hidden space of the frozen model and remain useful across the distribution shifts tested.
What would settle it
A new test collection that applies a strong editing transformation or domain shift where the layer-wise projection features yield near-random classification accuracy would falsify the claim.
Figures




read the original abstract
Detecting machine-generated text is especially difficult under distribution shift, such as transfer across domains, source models, and editing attacks. We propose a fake-text detector based on steering vectors extracted from the hidden representations of a frozen language model. At each layer, we construct a direction that separates human-written from machine-generated text, and represent each input by its layer-wise alignment with these directions. A lightweight classifier trained on these projection features yields the final detection score. Our method achieves strong performance both in-distribution and under distribution shift, including across domains, source models, and machine-editing transformations such as polishing and rewriting. Interpretation analyses show that the learned directions align with recognizable stylistic cues while capturing substantial additional signal beyond surface features. These results position fake-text detection as a representation-space probing problem and show that steering vectors provide a simple and effective solution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SV-Detect, a detector for AI-generated text that extracts steering vectors from the hidden representations of a frozen language model. At each layer a separating direction between human and machine text is constructed; each input is represented by its layer-wise alignment with these directions; and a lightweight classifier is trained on the resulting projection features to yield the detection score. The central claim is that this yields strong performance both in-distribution and under distribution shift (domains, source models, polishing/rewriting edits), while the learned directions align with stylistic cues yet capture additional signal.
Significance. If the results and the existence of consistent cross-shift separating directions are substantiated, the work would be significant: it reframes fake-text detection as a representation-probing task and supplies a simple, potentially generalizable alternative to standard supervised classifiers that often fail under shift. The interpretability analysis is a secondary strength if it is shown to go beyond surface features.
major comments (1)
- [Abstract] Abstract: the claim of 'strong performance both in-distribution and under distribution shift' is stated without any metrics, baselines, datasets, error bars, or experimental protocol, rendering the central claim unevaluable from the supplied text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the positive assessment of the work's potential significance. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'strong performance both in-distribution and under distribution shift' is stated without any metrics, baselines, datasets, error bars, or experimental protocol, rendering the central claim unevaluable from the supplied text.
Authors: We agree that the abstract would be strengthened by including concrete quantitative details to support the performance claims. In the revised manuscript we will update the abstract to report key metrics (e.g., accuracy or AUC on in-distribution and out-of-distribution settings), name the primary datasets and source models, reference the main baselines, and briefly note the experimental protocol and error-bar reporting. This change will make the central claim directly evaluable while preserving the abstract's length and readability. revision: yes
Circularity Check
No significant circularity
full rationale
The described approach extracts separating directions from hidden representations of a frozen LM (standard mean-difference or similar construction on labeled data), projects inputs onto those directions, and trains a lightweight classifier on the resulting features. This is a conventional supervised pipeline on derived representations with no equations or steps that reduce the final detection score to the inputs by definition, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems invoked. The central performance claims under distribution shift are empirically testable against external benchmarks and do not collapse into self-referential constructions.
Axiom & Free-Parameter Ledger
free parameters (1)
- lightweight classifier parameters
axioms (1)
- domain assumption Existence of layer-wise directions separating human and machine text
Reference graph
Works this paper leans on
-
[1]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou and Long Phan and Sarah Li Chen and James Campbell and Phillip Guo and Richard Ren and Alexander Pan and Xuwang Yin and Mantas Mazeika and Ann. Representation Engineering:. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.01405 , eprinttype =. 2310.01405 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01405 2023
-
[2]
Tanzila Kehkashan and Raja Adil Riaz and Ahmad Sami Al. AI-generated text detection:. Comput. Sci. Rev. , volume =. 2025 , url =. doi:10.1016/J.COSREV.2025.100793 , timestamp =
-
[3]
Wong and Shu Yang and Xinyi Yang and Yulin Yuan and Lidia S
Junchao Wu and Runzhe Zhan and Derek F. Wong and Shu Yang and Xinyi Yang and Yulin Yuan and Lidia S. Chao , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.23746 , eprinttype =. 2410.23746 , timestamp =
-
[4]
Jiachen Fu and Chun. DetectAnyLLM: Towards Generalizable and Robust Detection of Machine-Generated Text Across Domains and Models , journal =. 2025 , url =. doi:10.48550/ARXIV.2509.14268 , eprinttype =. 2509.14268 , timestamp =
-
[5]
Yuxia Wang and Artem Shelmanov and Jonibek Mansurov and Akim Tsvigun and Vladislav Mikhailov and Rui Xing and Zhuohan Xie and Jiahui Geng and Giovanni Puccetti and Ekaterina Artemova and Jinyan Su and Minh Ngoc Ta and Mervat Abassy and Kareem Ashraf Elozeiri and Saad El Dine Ahmed El Etter and Maiya Goloburda and Tarek Mahmoud and Raj Vardhan Tomar and Nu...
-
[6]
Jiaqi Chen and Xiaoye Zhu and Tianyang Liu and Ying Chen and Xinhui Chen and Yiwen Yuan and Chak Tou Leong and Zuchao Li and Tang Long and Lei Zhang and Chenyu Yan and Guanghao Mei and Jie Zhang and Lefei Zhang , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.10432 , eprinttype =. 2412.10432 , timestamp =
-
[7]
Guangsheng Bao and Yanbin Zhao and Zhiyang Teng and Linyi Yang and Yue Zhang , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.05130 , eprinttype =. 2310.05130 , timestamp =
-
[8]
Eric Mitchell and Yoonho Lee and Alexander Khazatsky and Christopher D. Manning and Chelsea Finn , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2301.11305 , eprinttype =. 2301.11305 , timestamp =
-
[9]
Abhimanyu Hans and Avi Schwarzschild and Valeriia Cherepanova and Hamid Kazemi and Aniruddha Saha and Micah Goldblum and Jonas Geiping and Tom Goldstein , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2401.12070 , eprinttype =. 2401.12070 , timestamp =
-
[10]
Petzold and William Yang Wang and Haifeng Chen , title =
Xianjun Yang and Wei Cheng and Linda R. Petzold and William Yang Wang and Haifeng Chen , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2305.17359 , eprinttype =. 2305.17359 , timestamp =
-
[11]
Jinyan Su and Terry Yue Zhuo and Di Wang and Preslav Nakov , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2306.05540 , eprinttype =. 2306.05540 , timestamp =
-
[12]
Laida Kushnareva and Daniil Cherniavskii and Vladislav Mikhailov and Ekaterina Artemova and Serguei Barannikov and Alexander Bernstein and Irina Piontkovskaya and Dmitri Piontkovski and Evgeny Burnaev , title =. CoRR , volume =. 2021 , url =. 2109.04825 , timestamp =
arXiv 2021
-
[13]
Nikolenko and Irina Piontkovskaya , title =
Kristian Kuznetsov and Eduard Tulchinskii and Laida Kushnareva and German Magai and Serguei Barannikov and Sergey I. Nikolenko and Irina Piontkovskaya , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.08113 , eprinttype =. 2410.08113 , timestamp =
-
[14]
Junchao Wu and Shu Yang and Runzhe Zhan and Yulin Yuan and Lidia S. Chao and Derek Fai Wong , title =. Comput. Linguistics , volume =. 2025 , url =. doi:10.1162/COLI\_A\_00549 , timestamp =
-
[15]
Testing of Detection Tools for AI-Generated Text , journal =
Debora Weber. Testing of Detection Tools for AI-Generated Text , journal =. 2023 , url =. doi:10.48550/ARXIV.2306.15666 , eprinttype =. 2306.15666 , timestamp =
-
[16]
Automatic Detection of Machine Generated Text:
Ganesh Jawahar and Muhammad Abdul. Automatic Detection of Machine Generated Text:. Proceedings of the 28th International Conference on Computational Linguistics,. 2020 , url =. doi:10.18653/V1/2020.COLING-MAIN.208 , timestamp =
-
[17]
Yafu Li and Qintong Li and Leyang Cui and Wei Bi and Zhilin Wang and Longyue Wang and Linyi Yang and Shuming Shi and Yue Zhang , editor =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.3 , timestamp =
-
[18]
A Practical Examination of AI-Generated Text Detectors for Large Language Models , booktitle =
Brian Tufts and Xuandong Zhao and Lei Li , editor =. A Practical Examination of AI-Generated Text Detectors for Large Language Models , booktitle =. 2025 , url =. doi:10.18653/V1/2025.FINDINGS-NAACL.271 , timestamp =
-
[19]
2024 , eprint=
AI-generated text boundary detection with RoFT , author=. 2024 , eprint=
2024
-
[20]
Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics,
Yuxia Wang and Jonibek Mansurov and Petar Ivanov and Jinyan Su and Artem Shelmanov and Akim Tsvigun and Chenxi Whitehouse and Osama Mohammed Afzal and Tarek Mahmoud and Toru Sasaki and Thomas Arnold and Alham Fikri Aji and Nizar Habash and Iryna Gurevych and Preslav Nakov , editor =. Proceedings of the 18th Conference of the European Chapter of the Associ...
2024
-
[21]
2020 , month = aug, howpublished =
nostalgebraist , title =. 2020 , month = aug, howpublished =
2020
-
[22]
G en AI Content Detection Task 1: E nglish and Multilingual Machine-Generated Text Detection: AI vs
Wang, Yuxia and Shelmanov, Artem and Mansurov, Jonibek and Tsvigun, Akim and Mikhailov, Vladislav and Xing, Rui and Xie, Zhuohan and Geng, Jiahui and Puccetti, Giovanni and Artemova, Ekaterina and Su, Jinyan and Ta, Minh Ngoc and Abassy, Mervat and Elozeiri, Kareem Ashraf and El Etter, Saad El Dine Ahmed and Goloburda, Maiya and Mahmoud, Tarek and Tomar, ...
2025
-
[23]
Release Strategies and the Social Impacts of Language Models , journal =
Irene Solaiman and Miles Brundage and Jack Clark and Amanda Askell and Ariel Herbert. Release Strategies and the Social Impacts of Language Models , journal =. 2019 , url =. 1908.09203 , timestamp =
Pith/arXiv arXiv 2019
-
[24]
Detecting Fake Content with Relative Entropy Scoring , booktitle =
Thomas Lavergne and Tanguy Urvoy and Fran. Detecting Fake Content with Relative Entropy Scoring , booktitle =. 2008 , url =
2008
-
[25]
Sebastian Gehrmann and Hendrik Strobelt and Alexander M. Rush , title =. CoRR , volume =. 2019 , url =. 1906.04043 , timestamp =
Pith/arXiv arXiv 2019
-
[26]
Biru Zhu and Lifan Yuan and Ganqu Cui and Yangyi Chen and Chong Fu and Bingxiang He and Yangdong Deng and Zhiyuan Liu and Maosong Sun and Ming Gu , editor =. Beat LLMs at Their Own Game: Zero-Shot LLM-Generated Text Detection via Querying ChatGPT , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.463 , timestamp =
-
[27]
Sungjoon Park and Jihyung Moon and Sungdong Kim and Won. CoRR , volume =. 2021 , url =. 2105.09680 , timestamp =
arXiv 2021
-
[28]
Unsupervised Cross-lingual Representation Learning at Scale , journal =
Alexis Conneau and Kartikay Khandelwal and Naman Goyal and Vishrav Chaudhary and Guillaume Wenzek and Francisco Guzm. Unsupervised Cross-lingual Representation Learning at Scale , journal =. 2019 , url =. 1911.02116 , timestamp =
Pith/arXiv arXiv 2019
-
[29]
Automatic Detection of Generated Text is Easiest when Humans are Fooled , booktitle =
Daphne Ippolito and Daniel Duckworth and Chris Callison. Automatic Detection of Generated Text is Easiest when Humans are Fooled , booktitle =. 2020 , url =. doi:10.18653/V1/2020.ACL-MAIN.164 , timestamp =
-
[30]
Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov , title =. CoRR , volume =. 2019 , url =. 1907.11692 , timestamp =
Pith/arXiv arXiv 2019
-
[31]
2021 , howpublished=
GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow , author=. 2021 , howpublished=
2021
-
[32]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[33]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.