Defending Jailbreak Attacks on Large Language Models via Manifold Trajectory Kinetics
Pith reviewed 2026-06-27 21:54 UTC · model grok-4.3
The pith
Jailbreak prompts follow a distinct trajectory on the LLM data manifold that can be tracked layer by layer to detect attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
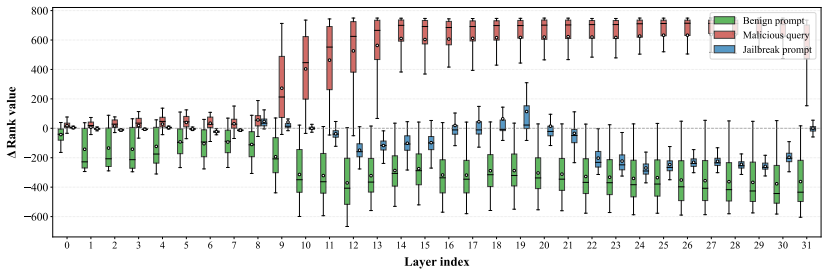
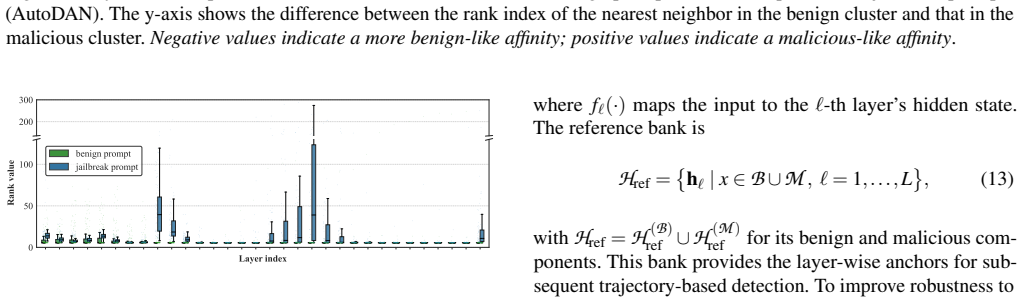
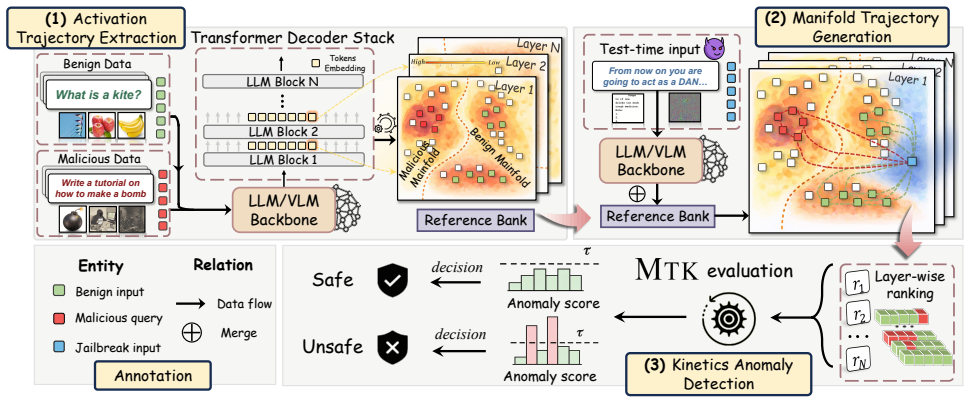
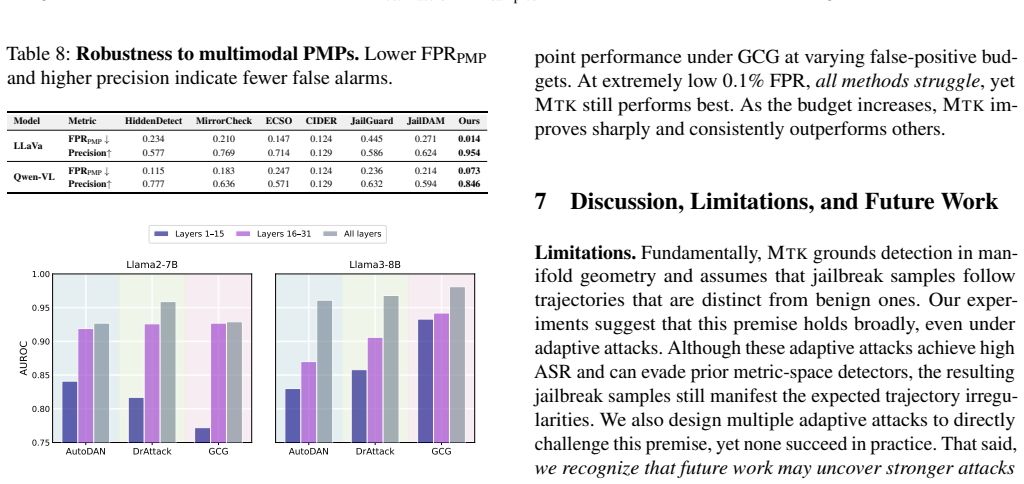
Manifold Trajectory Kinetics (MTK) treats an LLM as a kinetic system that transforms inputs into outputs across layers and detects jailbreaks by monitoring how each prompt's neighborhood structure changes on the data manifold. Benign prompts remain close to benign neighborhoods during inference, whereas jailbreak prompts begin near malicious seeds and strategically shift toward benign neighborhoods to evade refusal. This yields a 95 percent jailbreak true positive rate at a 5 percent false positive rate on benign prompts and 2 percent on pseudo-malicious prompts, plus an 85 percent true positive rate under adaptive attacks.
What carries the argument
Manifold Trajectory Kinetics (MTK), which tracks the evolution of a prompt's neighborhood structure across LLM layers treated as a kinetic system on the data manifold.
If this is right
- Detection stays effective against pseudo-malicious prompts that contain safety keywords but are benign by intent.
- Performance holds when attackers explicitly optimize prompts against the deployed detector.
- The same neighborhood-tracking approach yields strong results on vision-language models.
- Focusing on manifold neighborhood evolution provides robustness beyond linear separability in any single fixed metric space.
Where Pith is reading between the lines
- If the trajectory pattern holds more broadly, monitoring layer-wise neighborhood changes could improve detection of other misalignment behaviors such as hallucinations.
- The method suggests that safety mechanisms might benefit from examining internal dynamics rather than only input or output features.
- Combining MTK with existing detectors could raise overall robustness without requiring changes to model training.
Load-bearing premise
Jailbreak prompts exhibit a characteristic trajectory on the data manifold that begins near malicious seeds and later shifts toward benign neighborhoods.
What would settle it
An observation of jailbreak prompts whose neighborhood trajectories do not begin near malicious seeds and shift toward benign areas, or of benign prompts that do follow such a shift, would falsify the detection claim.
Figures

read the original abstract
Jailbreak prompts can bypass alignment guardrails in large language models (LLMs) and elicit unsafe outputs, making reliable deployment-time detection critical. Prior detection approaches largely rely on a fixed metric space, e.g., raw inputs, gradients, or hidden features, in which benign and jailbreak prompts are linearly separable. We show this assumption breaks under (i) pseudo-malicious prompts that are benign by intent but contain safety-related keywords, and (ii) adaptive attacks that explicitly optimize against the deployed detector. To overcome this limitation, we shift our focus from identifying a universal metric space to analyzing the more robust neighborhood structure of the underlying data manifold. We present Manifold Trajectory Kinetics (MTK), which treats an LLM as a kinetic system transforming inputs into outputs and detects jailbreaks by tracking how a prompt's neighborhood structure evolves across layers. Benign prompts remain close to benign neighborhoods throughout inference, whereas jailbreak prompts exhibit a characteristic trajectory that begins near malicious seeds and later strategically shifts toward benign neighborhoods to evade refusal.Across four LLMs and ten jailbreak attacks, MTK achieves strong robustness to both failure modes: on pseudo-malicious prompts, it attains a jailbreak true positive rate of 95% at a false positive rate of 5% on benign prompts and 2% on pseudo-malicious prompts, and under adaptive attacks, it maintains a true positive rate of 85%. We further demonstrate the superior performance of MTK for jailbreak detection in vision-language models. Our code is available at https://github.com/Rookie143/mtk.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Manifold Trajectory Kinetics (MTK) as a jailbreak detection method for LLMs. It argues that fixed-metric approaches (raw inputs, gradients, hidden features) fail under pseudo-malicious prompts and adaptive attacks because they assume linear separability. Instead, MTK models the LLM as a kinetic system and tracks evolution of neighborhood structure on the data manifold across layers: benign prompts stay near benign neighborhoods while jailbreaks start near malicious seeds and later shift toward benign regions. Empirical results across four LLMs and ten attacks report 95% TPR at 5% FPR (benign) / 2% FPR (pseudo-malicious) and 85% TPR under adaptive attacks; the method is also tested on vision-language models. Code is released.
Significance. If the reported robustness holds under rigorous controls, MTK would address a recognized weakness in current detection methods by leveraging manifold geometry rather than a single fixed representation. The multi-model, multi-attack evaluation and code release strengthen reproducibility and allow direct comparison with prior detectors.
major comments (2)
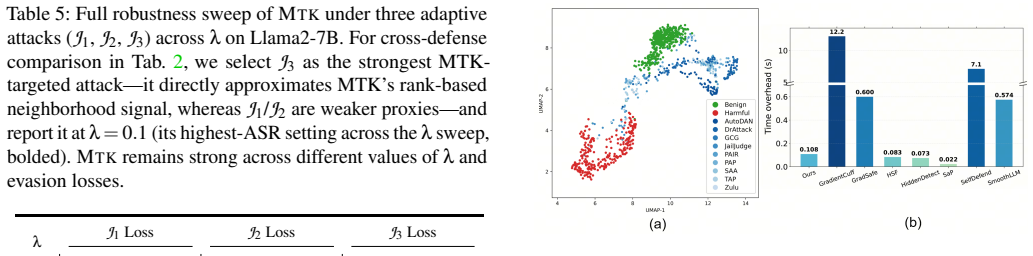
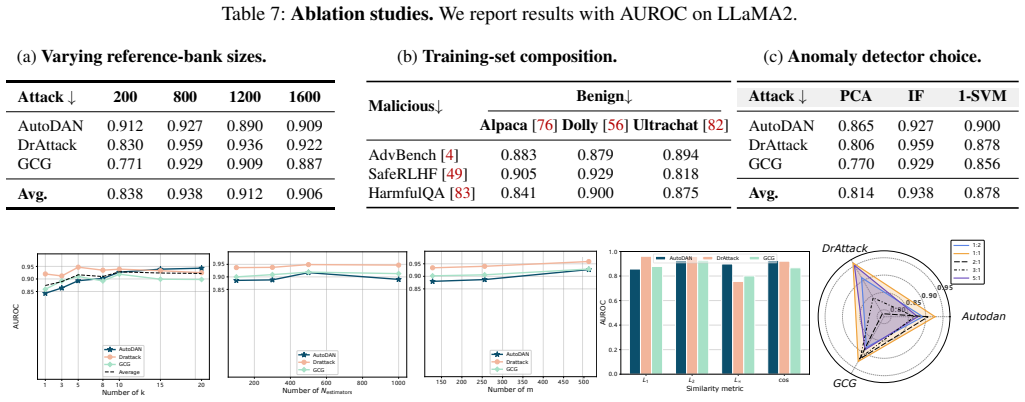
- [Experimental methods / §4] Experimental methods (likely §4 or §5): the abstract states concrete metrics (95% TPR at 5%/2% FPR, 85% under adaptive attacks) but provides no information on data splits, generation of the pseudo-malicious prompt set, exact implementation of the ten jailbreak attacks, or how adaptive attacks were optimized against MTK itself. Without these controls the central robustness claim cannot be evaluated.
- [MTK definition / §3] Definition of MTK (likely §3): the core claim rests on tracking 'neighborhood structure' evolution, yet no formal definition is given for neighborhood radius, distance metric on the manifold, or how layer-wise trajectories are aggregated into a detection score. This leaves open whether the reported performance depends on post-hoc tuning of these choices.
minor comments (2)
- [Abstract] Abstract: the phrase 'strategically shifts toward benign neighborhoods to evade refusal' attributes intent; rephrase in terms of observed trajectory statistics.
- [Results] The manuscript should include a table listing the four LLMs, ten attacks, and exact hyper-parameters used for MTK (layer indices, neighborhood size, etc.).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The two major comments identify areas where additional clarity is needed to support the robustness claims. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental methods / §4] Experimental methods (likely §4 or §5): the abstract states concrete metrics (95% TPR at 5%/2% FPR, 85% under adaptive attacks) but provides no information on data splits, generation of the pseudo-malicious prompt set, exact implementation of the ten jailbreak attacks, or how adaptive attacks were optimized against MTK itself. Without these controls the central robustness claim cannot be evaluated.
Authors: We agree that the experimental protocol requires fuller documentation for reproducibility. In the revised manuscript we will expand §4 with: (i) explicit train/validation/test splits and sampling strategy for the benign, malicious, and pseudo-malicious sets; (ii) the exact template and keyword-selection procedure used to construct the pseudo-malicious prompts; (iii) parameter settings, prompt templates, and success criteria for each of the ten jailbreak attacks; and (iv) the precise optimization procedure (loss, learning rate, number of iterations, and surrogate model) employed when generating adaptive attacks against MTK. These additions will be placed in the main text or a dedicated appendix so that the reported TPR/FPR figures can be independently verified. revision: yes
-
Referee: [MTK definition / §3] Definition of MTK (likely §3): the core claim rests on tracking 'neighborhood structure' evolution, yet no formal definition is given for neighborhood radius, distance metric on the manifold, or how layer-wise trajectories are aggregated into a detection score. This leaves open whether the reported performance depends on post-hoc tuning of these choices.
Authors: We acknowledge that §3 would benefit from explicit mathematical notation. In the revision we will define: the neighborhood radius r, the manifold distance d(·,·) (cosine similarity on layer activations after PCA projection), the per-layer neighborhood overlap statistic, and the aggregation function that produces the final kinetic score (a weighted sum of layer-wise changes). We will also add a short sensitivity analysis showing that detection performance remains stable across a range of r values and aggregation weights, thereby addressing the concern about post-hoc tuning. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes an empirical detection method (MTK) based on tracking neighborhood evolution on the data manifold across LLM layers, validated through concrete performance metrics on four LLMs and ten attacks (95% TPR at 5%/2% FPR, 85% under adaptive attacks). No mathematical derivation, first-principles prediction, or fitted parameter is presented that reduces by construction to its own inputs or self-citations. The central claims rest on observed empirical behavior rather than any self-definitional, uniqueness-imported, or ansatz-smuggled steps. The approach is self-contained against external benchmarks via reported results and released code.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be treated as kinetic systems transforming inputs into outputs whose neighborhood structures evolve in a detectable way across layers
Reference graph
Works this paper leans on
-
[1]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 techni- cal report,”arXiv preprint arXiv:2505.09388, 2025. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Alma- hairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine- tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Jailbroken: How does llm safety training fail?
A. Wei, N. Haghtalab, and J. Steinhardt, “Jailbroken: How does llm safety training fail?” inProceedings of the Advances in Neural Information Processing Sys- tems (NeurIPS’23), vol. 36, 2023
2023
-
[4]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Jailbreaking leading safety-aligned llms with simple adaptive attacks,
M. Andriushchenko, F. Croce, and N. Flammarion, “Jailbreaking leading safety-aligned llms with simple adaptive attacks,”arXiv preprint arXiv:2404.02151, 2024
-
[6]
Artprompt: Ascii art-based jailbreak attacks against aligned llms,
F. Jiang, Z. Xu, L. Niu, Z. Xiang, B. Ramasubramanian, B. Li, and R. Poovendran, “Artprompt: Ascii art-based jailbreak attacks against aligned llms,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 15 157–15 173
2024
-
[7]
Fake alignment: Are llms really aligned well?
Y . Wang, Y . Teng, K. Huang, C. Lyu, S. Zhang, W. Zhang, X. Ma, Y .-G. Jiang, Y . Qiao, and Y . Wang, “Fake alignment: Are llms really aligned well?” inPro- ceedings of the 2024 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics: Human Language Technologies, 2024, pp. 4696–4712
2024
-
[8]
Defending against alignment-breaking attacks via robustly aligned llm,
B. Cao, Y . Cao, L. Lin, and J. Chen, “Defending against alignment-breaking attacks via robustly aligned llm,” inProceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 10 542–10 560
2024
-
[9]
Y . Jiang, X. Gao, T. Peng, Y . Tan, X. Zhu, B. Zheng, and X. Yue, “Hiddendetect: Detecting jailbreak attacks against large vision-language models via monitoring hidden states,”CoRR, vol. abs/2502.14744, 2025
-
[10]
S. Zhang, Y . Zhai, K. Guo, H. Hu, S. Guo, Z. Fang, L. Zhao, C. Shen, C. Wang, and Q. Wang, “Jbshield: Defending large language models from jailbreak at- tacks through activated concept analysis and manipula- tion,”arXiv preprint arXiv:2502.07557, 2025
-
[11]
Learning safety constraints for large language models,
X. Chen, Y . As, and A. Krause, “Learning safety constraints for large language models,”CoRR, vol. abs/2505.24445, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2505.24445
-
[12]
Learn- ing to detect unknown jailbreak attacks in large vision- language models,
S. Liang, Z. Xu, J. Tao, H. Xue, and X. Wang, “Learn- ing to detect unknown jailbreak attacks in large vision- language models,”arXiv preprint arXiv:2508.09201, 2025
-
[13]
Efficient detection of toxic prompts in large language models,
Y . Liu, J. Yu, H. Sun, L. Shi, G. Deng, Y . Chen, and Y . Liu, “Efficient detection of toxic prompts in large language models,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE 2024, V . Filkov, B. Ray, and M. Zhou, Eds., 2024, pp. 455–467
2024
-
[14]
Investigating coverage criteria in large language models: An in-depth study through jailbreak attacks,
S. Zhou, T. Li, K. Wang, Y . Huang, L. Shi, Y . Liu, and H. Wang, “Investigating coverage criteria in large language models: An in-depth study through jailbreak attacks,”arXiv e-prints, pp. arXiv–2408, 2024
2024
-
[15]
Hsf: Defend- ing against jailbreak attacks with hidden state filtering,
C. Qian, H. Zhang, L. Sha, and Z. Zheng, “Hsf: Defend- ing against jailbreak attacks with hidden state filtering,” inProceedings of the ACM on Web Conference 2025, 2025, pp. 2078–2087
2025
-
[16]
Defending against jailbreak through early exit generation of large lan- guage models,
C. Zhao, Z. Dou, and K. Huang, “Defending against jailbreak through early exit generation of large lan- guage models,” inProceedings of the International Conference on Neural Information Processing, 2025, pp. 532–546
2025
-
[17]
Jaildam: Jailbreak detection with adaptive memory for vision-language model,
Y . Nian, S. Zhu, Y . Qin, L. Li, Z. Wang, C. Xiao, and Y . Zhao, “Jaildam: Jailbreak detection with adaptive memory for vision-language model,”arXiv preprint arXiv:2504.03770, 2025
-
[18]
Detecting Language Model Attacks with Perplexity
G. Alon and M. Kamfonas, “Detecting language model attacks with perplexity,”arXiv preprint arXiv:2308.14132, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Gradient cuff: De- tecting jailbreak attacks on large language models by exploring refusal loss landscapes,
X. Hu, P.-Y . Chen, and T.-Y . Ho, “Gradient cuff: De- tecting jailbreak attacks on large language models by exploring refusal loss landscapes,”Advances in Neural Information Processing Systems, vol. 37, pp. 126 265– 126 296, 2024
2024
-
[20]
Gradsafe: De- tecting jailbreak prompts for llms via safety-critical gradient analysis,
Y . Xie, M. Fang, R. Pi, and N. Gong, “Gradsafe: De- tecting jailbreak prompts for llms via safety-critical gradient analysis,”arXiv preprint arXiv:2402.13494, 2024
-
[21]
Safequant: Llm safety analysis via quantized gradient inspection,
S. Padakandla, S. Babar, M. Kaulet al., “Safequant: Llm safety analysis via quantized gradient inspection,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Compu- tational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 2522–2536
2025
-
[22]
Smoothllm: Defending large language models against jailbreaking attacks,
A. Robey, E. Wong, H. Hassani, and G. J. Pappas, “Smoothllm: Defending large language models against jailbreaking attacks,”Trans. Mach. Learn. Res., 2025. 15
2025
-
[23]
Jailguard: A uni- versal detection framework for prompt-based attacks on llm systems,
X. Zhang, C. Zhang, T. Li, Y . Huang, X. Jia, M. Hu, J. Zhang, Y . Liu, S. Ma, and C. Shen, “Jailguard: A uni- versal detection framework for prompt-based attacks on llm systems,”ACM Transactions on Software Engi- neering and Methodology, 2025
2025
-
[24]
LLM self defense: By self examination, llms know they are being tricked,
M. Phute, A. Helbling, M. Hull, S. Peng, S. Szyller, C. Cornelius, and D. H. Chau, “LLM self defense: By self examination, llms know they are being tricked,” in Proceedings of the Second Tiny Papers Track at ICLR 2024, Tiny Papers @ ICLR 2024, Vienna, Austria, May 11, 2024. OpenReview.net, 2024
2024
-
[25]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Testug- gineet al., “Llama guard: Llm-based input-output safeguard for human-ai conversations,”arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Selfdefend: Llms can defend themselves against jailbreaking in a practical manner,
X. Wang, D. Wu, Z. Ji, Z. Li, P. Ma, S. Wang, Y . Li, Y . Liu, N. Liu, and J. Rahmel, “Selfdefend: Llms can defend themselves against jailbreaking in a practical manner,” inProceedings of the 34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 2441– 2460
2025
-
[27]
M. Sharma, M. Tong, J. Mu, J. Wei, J. Kruthoff, S. Goodfriend, E. Ong, A. Peng, R. Agarwal, C. Anil et al., “Constitutional classifiers: Defending against universal jailbreaks across thousands of hours of red teaming,”arXiv preprint arXiv:2501.18837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Manifold learning: what, how, and why,
M. Meila and H. Zhang, “Manifold learning: what, how, and why,”CoRR, vol. abs/2311.03757, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2311.03757
-
[29]
L. Gao, J. Geng, X. Zhang, P. Nakov, and X. Chen, “Shaping the safety boundaries: Understanding and defending against jailbreaks in large language models,” arXiv preprint arXiv:2412.17034, 2024
-
[30]
Isolation for- est,
F. T. Liu, K. M. Ting, and Z.-H. Zhou, “Isolation for- est,” inProceedings of the International Conference on Data Mining. IEEE, 2008, pp. 413–422
2008
-
[31]
Tro- janrobot: Physical-world backdoor attacks against vlm-based robotic manipulation,
X. Wang, H. Pan, H. Zhang, M. Li, S. Hu, Z. Zhou, L. Xue, A. Liu, Y . Jiang, L. Y . Zhanget al., “Tro- janrobot: Physical-world backdoor attacks against vlm-based robotic manipulation,”arXiv preprint arXiv:2411.11683, 2024
-
[32]
Advedm: Fine- grained adversarial attack against vlm-based embodied agents,
Y . Wang, H. Zhang, H. Pan, Z. Zhou, X. Wang, P. Guo, L. Xue, S. Hu, M. Li, and L. Y . Zhang, “Advedm: Fine- grained adversarial attack against vlm-based embodied agents,”Advances in Neural Information Processing Systems, vol. 38, pp. 136 551–136 575, 2026
2026
-
[33]
Don’t listen to me: Understanding and ex- ploring jailbreak prompts of large language models,
Z. Yu, X. Liu, S. Liang, Z. Cameron, C. Xiao, and N. Zhang, “Don’t listen to me: Understanding and ex- ploring jailbreak prompts of large language models,” inProceedings of the USENIX Security Symposium (USENIX Security’24), 2024
2024
-
[34]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
X. Liu, N. Xu, M. Chen, and C. Xiao, “Autodan: Gen- erating stealthy jailbreak prompts on aligned large language models,”arXiv preprint arXiv:2310.04451, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Drattack: Prompt decomposition and reconstruction makes powerful llm jailbreakers,
X. Li, R. Wang, M. Cheng, T. Zhou, and C.-J. Hsieh, “Drattack: Prompt decomposition and reconstruction makes powerful llm jailbreakers,”arXiv preprint arXiv:2402.16914, 2024
-
[36]
"do anything now
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “"do anything now": Characterizing and evaluating in- the-wild jailbreak prompts on large language models,” inProceedings of the 2024 on ACM SIGSAC Con- ference on Computer and Communications Security, 2024, pp. 1671–1685
2024
-
[37]
F. Liu, Y . Feng, Z. Xu, L. Su, X. Ma, D. Yin, and H. Liu, “Jailjudge: A comprehensive jailbreak judge bench- mark with multi-agent enhanced explanation evalu- ation framework,”arXiv preprint arXiv:2410.12855, 2024
-
[38]
Dan is my new friend
walkerspider, “Dan is my new friend.” https://old.reddit.com/r/ChatGPT/comments/zlcyr9/ dan_is_my_new_friend/, 2022, reddit post; accessed 2025-10-21
2022
-
[39]
"the new jailbreak is so fun
R. Semenov, “"the new jailbreak is so fun.",” Twit- ter post, https://twitter.com/semenov_roman_/status/ 1621465137025613825, 2023, accessed: 2025-10-21
2023
-
[40]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,” 2023. [Online]. Available: https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Constitutional AI: Harmlessness from AI Feedback
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McK- innonet al., “Constitutional ai: Harmlessness from ai feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
Training language models to follow in- structions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wain- wright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow in- structions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730– 27 744, 2022
2022
-
[43]
Another jailbreak for gpt4: Talk to it in morse code
B. Boaz, “Another jailbreak for gpt4: Talk to it in morse code.” Twitter post, https://twitter.com/boazbaraktcs/ status/1637657623100096513, 2023, accessed: 2025- 10-21. 16
-
[44]
Exploiting programmatic behavior of llms: Dual-use through standard security attacks,
D. Kang, X. Li, I. Stoica, C. Guestrin, M. Zaharia, and T. Hashimoto, “Exploiting programmatic behavior of llms: Dual-use through standard security attacks,” in Proceedings of the 2024 IEEE Security and Privacy Workshops (SPW). IEEE, 2024, pp. 132–143
2024
-
[45]
Badrobot: Jail- breaking embodied llm agents in the physical world,
H. Zhang, C. Zhu, X. Wang, Z. Zhou, C. Yin, M. Li, L. Xue, Y . Wang, S. Hu, A. Liuet al., “Badrobot: Jail- breaking embodied llm agents in the physical world,” inProceedings of the Thirteenth International Confer- ence on Learning Representations, 2025
2025
-
[46]
Jailbreaking black box large lan- guage models in twenty queries,
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pap- pas, and E. Wong, “Jailbreaking black box large lan- guage models in twenty queries,” inProceedings of the 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 2025, pp. 23–42
2025
-
[47]
Jailbreaking llm-controlled robots,
A. Robey, Z. Ravichandran, V . Kumar, H. Hassani, and G. J. Pappas, “Jailbreaking llm-controlled robots,” in Proceedings of the 2025 IEEE International Confer- ence on Robotics and Automation (ICRA). IEEE, 2025, pp. 11 948–11 956
2025
-
[48]
Safety layers in aligned large language models: The key to llm security,
S. Li, L. Yao, L. Zhang, and Y . Li, “Safety layers in aligned large language models: The key to llm security,” arXiv preprint arXiv:2408.17003, 2024
-
[49]
Pku-saferlhf: Towards multi-level safety alignment for llms with hu- man preference,
J. Ji, D. Hong, B. Zhang, B. Chen, J. Dai, B. Zheng, T. A. Qiu, J. Zhou, K. Wang, B. Liet al., “Pku-saferlhf: Towards multi-level safety alignment for llms with hu- man preference,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), 2025, pp. 31 983–32 016
2025
-
[50]
Or- bench: An over-refusal benchmark for large language models,
J. Cui, W.-L. Chiang, I. Stoica, and C.-J. Hsieh, “Or- bench: An over-refusal benchmark for large language models,” inProceedings of the International Confer- ence on Machine Learning, 2024
2024
-
[51]
M. Dabas, S. Chen, C. Fleming, M. Jin, and R. Jia, “Just enough shifts: Mitigating over-refusal in aligned lan- guage models with targeted representation fine-tuning,” arXiv preprint arXiv:2507.04250, 2025
-
[52]
Designing a trade- off between usability and security: a metrics based- model,
C. Braz, A. Seffah, and D. M’Raihi, “Designing a trade- off between usability and security: a metrics based- model,” inProceedings of the IFIP Conference on human-computer interaction. Springer, 2007, pp. 114– 126
2007
-
[53]
G. Shen, D. Zhao, Y . Dong, X. He, and Y . Zeng, “Jailbreak antidote: Runtime safety-utility balance via sparse representation adjustment in large language models,”arXiv preprint arXiv:2410.02298, 2024
-
[54]
Xstest: A test suite for identifying ex- aggerated safety behaviours in large language mod- els,
P. Röttger, H. Kirk, B. Vidgen, G. Attanasio, F. Bianchi, and D. Hovy, “Xstest: A test suite for identifying ex- aggerated safety behaviours in large language mod- els,” inProceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2024, pp. 5377–5400
2024
-
[55]
Introducing the model spec — openai,
OpenAI, “Introducing the model spec — openai,” https: //www.openai.com, 2024, accessed: 2024-12-02
2024
-
[56]
Free dolly: Introducing the world’s first truly open in- structiontuned llm,
M. Conover, M. Hayes, A. Mathur, J. Xie, J. Wan, S. Shah, A. Ghodsi, P. Wendell, M. Zaharia, and R. Xin, “Free dolly: Introducing the world’s first truly open in- structiontuned llm,” 2023
2023
-
[57]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,
W.-L. Chiang, Z. Li, Z. Lin, Y . Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y . Zhuang, J. E. Gonzalez, I. Stoica, and E. P. Xing, “Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,” 2023. [Online]. Available: https://lmsys.org/blog/2023-03-30-vicuna/
2023
-
[58]
P. Hua, H. Li, S. Shi, Z. Yu, and N. Zhang, “Rethink- ing jailbreak detection of large vision language mod- els with representational contrastive scoring,”arXiv preprint arXiv:2512.12069, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Can’t see the forest for the trees: Benchmarking multimodal safety awareness for multi- modal llms,
W. Wang, X. Liu, K. Gao, J.-t. Huang, Y . Yuan, P. He, S. Wang, and Z. Tu, “Can’t see the forest for the trees: Benchmarking multimodal safety awareness for multi- modal llms,”arXiv preprint arXiv:2502.11184, 2025
-
[60]
Usb: A com- prehensive and unified safety evaluation benchmark for multimodal large language models,
B. Zheng, G. Chen, H. Zhong, Q. Teng, Y . Tan, Z. Liu, W. Wang, J. Liu, J. Yang, H. Jinget al., “Usb: A com- prehensive and unified safety evaluation benchmark for multimodal large language models,”arXiv preprint arXiv:2505.23793, 2025
-
[61]
Euclidean distance mapping,
P.-E. Danielsson, “Euclidean distance mapping,”Com- puter Graphics and image processing, vol. 14, no. 3, pp. 227–248, 1980
1980
-
[62]
Improved large language model jailbreak detection via pretrained embeddings,
E. Galinkin and M. Sablotny, “Improved large language model jailbreak detection via pretrained embeddings,” arXiv preprint arXiv:2412.01547, 2024
-
[63]
Llms encode harmfulness and refusal separately,
J. Zhao, J. Huang, Z. Wu, D. Bau, and W. Shi, “Llms encode harmfulness and refusal separately,”arXiv preprint arXiv:2507.11878, 2025
-
[64]
Unlearnable 3d point clouds: Class-wise transformation is all you need,
X. Wang, M. Li, W. Liu, H. Zhang, S. Hu, Y . Zhang, Z. Zhou, and H. Jin, “Unlearnable 3d point clouds: Class-wise transformation is all you need,”Advances in Neural Information Processing Systems, vol. 37, pp. 99 404–99 432, 2024. 17
2024
-
[65]
Improv- ing one-class svm for anomaly detection,
K.-L. Li, H.-K. Huang, S.-F. Tian, and W. Xu, “Improv- ing one-class svm for anomaly detection,” inProceed- ings of the 2003 International Conference on Machine Learning and Cybernetics (IEEE Cat. No.03EX693), vol. 5, 2003, pp. 3077–3081 V ol.5
2003
-
[66]
Principal com- ponents analysis (pca),
A. Ma ´ckiewicz and W. Ratajczak, “Principal com- ponents analysis (pca),”Computers & Geosciences, vol. 19, no. 3, pp. 303–342, 1993
1993
-
[67]
Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation,
Z. Lin, Z. Wang, Y . Tong, Y . Wang, Y . Guo, Y . Wang, and J. Shang, “Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation,” arXiv preprint arXiv:2310.17389, 2023
-
[68]
Meta llama 3: The most capable openly available generative ai models,
Meta AI, “Meta llama 3: The most capable openly available generative ai models,” https://ai.meta.com/ blog/meta-llama-3/, 2024, official technical release of Llama 3 models (including 8B Instruct)
2024
-
[69]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressandet al., “Mixtral of experts,” arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
How johnny can persuade llms to jailbreak them: Re- thinking persuasion to challenge ai safety by humaniz- ing llms,
Y . Zeng, H. Lin, J. Zhang, D. Yang, R. Jia, and W. Shi, “How johnny can persuade llms to jailbreak them: Re- thinking persuasion to challenge ai safety by humaniz- ing llms,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), 2024, pp. 14 322–14 350
2024
-
[71]
Tree of attacks: Jailbreaking black-box llms automatically,
A. Mehrotra, M. Zampetakis, P. Kassianik, B. Nel- son, H. Anderson, Y . Singer, and A. Karbasi, “Tree of attacks: Jailbreaking black-box llms automatically,” Advances in Neural Information Processing Systems, vol. 37, pp. 61 065–61 105, 2024
2024
-
[72]
Low-Resource Languages Jailbreak GPT-4
Z.-X. Yong, C. Menghini, and S. H. Bach, “Low- resource languages jailbreak gpt-4,”arXiv preprint arXiv:2310.02446, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[73]
Eyes closed, safety on: Protecting multimodal llms via image-to-text transformation,
Y . Gou, K. Chen, Z. Liu, L. Hong, H. Xu, Z. Li, D.- Y . Yeung, J. T. Kwok, and Y . Zhang, “Eyes closed, safety on: Protecting multimodal llms via image-to-text transformation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 388–404
2024
-
[74]
MirrorCheck: Efficient Adversarial Defense for Vision-Language Models
S. Fares, K. Ziu, T. Aremu, N. Durasov, M. Taká ˇc, P. Fua, K. Nandakumar, and I. Laptev, “Mirrorcheck: Efficient adversarial defense for vision-language mod- els,”arXiv preprint arXiv:2406.09250, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
Cross-modality information check for detecting jailbreaking in mul- timodal large language models,
Y . Xu, X. Qi, Z. Qin, and W. Wang, “Cross-modality information check for detecting jailbreaking in mul- timodal large language models,”arXiv preprint arXiv:2407.21659, 2024
-
[76]
Stanford alpaca: An instruction-following llama model,
R. Taori, I. Gulrajani, T. Zhang, Y . Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto, “Stanford alpaca: An instruction-following llama model,” 2023
2023
-
[77]
Catastrophic Jailbreak of Open-source LLMs via Exploiting Generation
Y . Huang, S. Gupta, M. Xia, K. Li, and D. Chen, “Catas- trophic jailbreak of open-source llms via exploiting generation,”arXiv preprint arXiv:2310.06987, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[78]
Re- visiting the assumption of latent separability for back- door defenses,
X. Qi, T. Xie, Y . Li, S. Mahloujifar, and P. Mittal, “Re- visiting the assumption of latent separability for back- door defenses,” inProceedings of the eleventh Interna- tional Conference on Learning Representations, 2023
2023
-
[79]
Mm-safetybench: A benchmark for safety evaluation of multimodal large language models,
X. Liu, Y . Zhu, J. Gu, Y . Lan, C. Yang, and Y . Qiao, “Mm-safetybench: A benchmark for safety evaluation of multimodal large language models,” inEuropean Conference on Computer Vision, 2024, pp. 386–403
2024
-
[80]
Figstep: Jailbreaking large vision-language models via typographic visual prompts,
Y . Gong, D. Ran, J. Liu, C. Wang, T. Cong, A. Wang, S. Duan, and X. Wang, “Figstep: Jailbreaking large vision-language models via typographic visual prompts,” inProceedings of the AAAI Conference on Artificial Intelligence, 2025, pp. 23 951–23 959
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.