The Lipreading Gap: Do VSR Models Perceive Visual Speech Like Human Lipreaders?
Pith reviewed 2026-06-27 21:56 UTC · model grok-4.3
The pith
VSR models surpass humans on lipreading benchmarks but rely on language cues from training data rather than visual perception.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
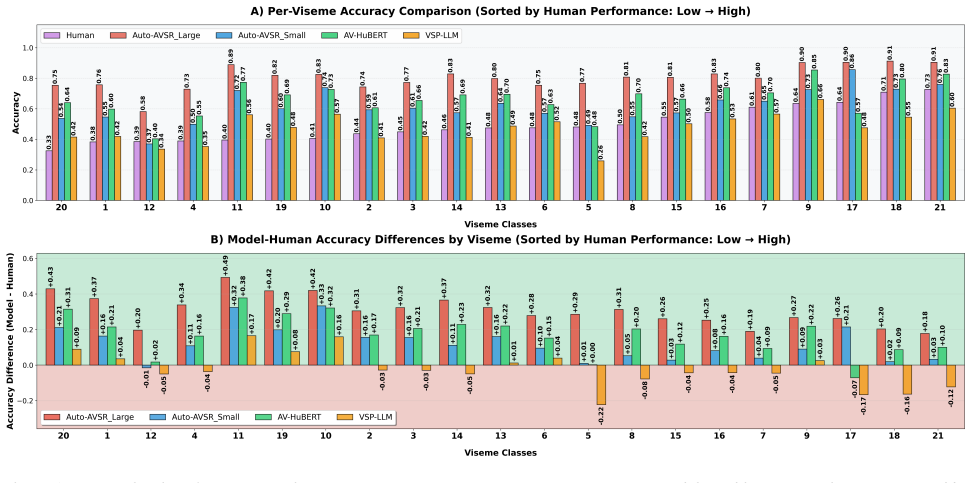
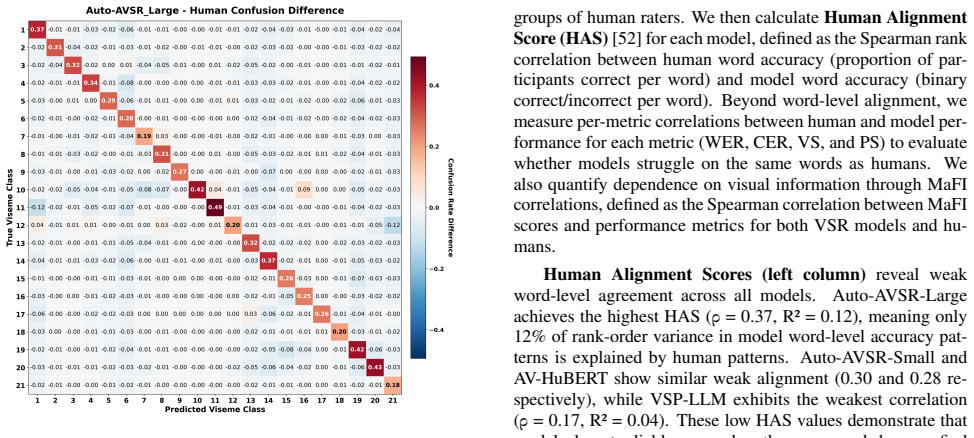
Although VSR models achieve higher overall accuracy than humans, they succeed and fail on different words than humans. A text-only n-gram baseline given only a few initial phonemes rivals human lipreading. VSR word-level errors are consistently better explained by training word frequency than by the visual informativeness of words. Viseme accuracies, confusion matrices and human-model correlations show that models gain most on visemes humans find hardest and show much weaker dependence on visual clarity. This demonstrates that VSR systems rely primarily on language cues from training data rather than visual perception, failing to bind visual features into meaningful words.
What carries the argument
Comparison of word, character, phoneme, and viseme-level metrics plus correlations of errors with training word frequency versus visual informativeness, between VSR models, humans, and a text-only n-gram baseline on the MaFI dataset.
Load-bearing premise
That differences in word-level success patterns, viseme accuracies, and correlations with word frequency versus visual informativeness demonstrate absence of visual perception rather than other factors such as model architecture or dataset biases.
What would settle it
A VSR model trained on data where word frequency is independent of visual informativeness would show errors tracking visual clarity instead of frequency if the claim is false.
Figures
read the original abstract
Visual speech recognition (VSR) models now surpass human lipreaders on benchmarks, but do such gains establish human-like visual speech perception? To explore this, we compare three VSR systems with human baselines on the MaFI word-level lipreading dataset using word, character, phoneme, and viseme-level metrics. Although models achieve higher overall accuracy, they succeed and fail on different words than humans. A text-only n-gram baseline given only a few initial phonemes rivals human lipreading. VSR word-level errors are consistently better explained by training word frequency than by the visual informativeness of words. Viseme accuracies, confusion matrices and human-model correlations further show that models gain most on visemes humans find hardest, and show much weaker dependence on visual clarity. Our work demonstrates that VSR systems rely primarily on language cues from training data rather than visual perception, failing to bind visual features into meaningful words.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares three VSR models against human lipreaders on the MaFI word-level dataset using word-, character-, phoneme-, and viseme-level metrics. It reports that models exceed human accuracy overall yet succeed and fail on different words; a text-only n-gram baseline using only initial phonemes matches human performance; model errors correlate more strongly with training-word frequency than with visual informativeness; and models outperform humans most on visemes humans find hardest. The central claim is that VSR systems rely primarily on language cues from training data rather than visual perception and therefore fail to bind visual features into meaningful words.
Significance. If the empirical patterns hold after appropriate controls, the work identifies a substantive mismatch between benchmark gains and human-like visual speech perception. This would imply that current VSR progress largely exploits linguistic priors rather than learning robust visual-to-word mappings, with direct consequences for generalization, robustness to domain shift, and the design of future architectures that must demonstrably use the visual stream.
major comments (3)
- [Abstract / Results] Abstract and Results: the inference that models 'rely primarily on language cues ... rather than visual perception' and 'fail to bind visual features' rests on correlations with word frequency and viseme difficulty, yet the manuscript provides no ablation or controlled experiment that isolates the contribution of the visual stream (e.g., visual-only vs. audio-visual training, feature occlusion, or gradient attribution). Without such evidence the observed patterns could equally arise from architecture, optimization, or dataset statistics that happen to align with frequency.
- [Abstract] Abstract: the n-gram baseline demonstrates that language modeling alone can rival human lipreading given partial phoneme input, but does not test whether the actual VSR models under-utilize the visual input they receive. A direct comparison (e.g., model performance with vs. without visual features masked) is required to support the claim that visual perception is absent.
- [Abstract] Abstract: the reported correlations between model errors and word frequency versus visual informativeness lack statistical tests, confidence intervals, or error bars. The soundness note indicates these details are missing; their absence prevents assessment of whether the frequency correlation is reliably stronger than the visual one and therefore load-bearing for the central claim.
minor comments (2)
- [Methods] The manuscript should specify the exact three VSR architectures, training corpora, and hyper-parameters used, as these details are necessary to interpret whether the observed patterns are architecture-specific.
- [Results] Clarify how 'visual informativeness' of words is quantified and how it is distinguished from frequency in the correlation analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the evidential basis for our central claim. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results: the inference that models 'rely primarily on language cues ... rather than visual perception' and 'fail to bind visual features' rests on correlations with word frequency and viseme difficulty, yet the manuscript provides no ablation or controlled experiment that isolates the contribution of the visual stream (e.g., visual-only vs. audio-visual training, feature occlusion, or gradient attribution). Without such evidence the observed patterns could equally arise from architecture, optimization, or dataset statistics that happen to align with frequency.
Authors: We agree that direct ablations (such as feature occlusion or gradient-based attribution) would provide stronger causal evidence isolating visual contributions from linguistic priors. The current manuscript relies on correlational patterns across multiple metrics and a language-only baseline. In revision we will add a controlled occlusion experiment on at least one VSR model and a limitations paragraph acknowledging that architecture or optimization effects cannot be fully ruled out without such controls. revision: yes
-
Referee: [Abstract] Abstract: the n-gram baseline demonstrates that language modeling alone can rival human lipreading given partial phoneme input, but does not test whether the actual VSR models under-utilize the visual input they receive. A direct comparison (e.g., model performance with vs. without visual features masked) is required to support the claim that visual perception is absent.
Authors: The n-gram baseline serves to show that linguistic information alone can approximate human performance levels, providing context for why model error patterns track frequency more closely than visual properties. We concur that a direct visual-masking comparison on the VSR models themselves would more conclusively demonstrate under-utilization of the visual stream. We will incorporate such a masking ablation in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the reported correlations between model errors and word frequency versus visual informativeness lack statistical tests, confidence intervals, or error bars. The soundness note indicates these details are missing; their absence prevents assessment of whether the frequency correlation is reliably stronger than the visual one and therefore load-bearing for the central claim.
Authors: We appreciate this observation. The original submission omitted formal statistical tests and uncertainty estimates for the correlations. In the revision we will compute and report Pearson/Spearman correlations with bootstrap confidence intervals and p-values comparing the strength of frequency versus visual-informativeness predictors. revision: yes
Circularity Check
No circularity: conclusions rest on independent empirical correlations
full rationale
The paper's central claim—that VSR models rely primarily on language cues rather than visual perception—is supported by direct comparisons of model vs. human performance on the MaFI dataset, including word-level error patterns, correlations of errors with training word frequency versus visual informativeness, viseme accuracies, and confusion matrices. These quantities are measured against external references (human baselines, dataset statistics, and visual clarity metrics) and do not reduce to any fitted parameter, self-definition, or self-citation chain. No equations or derivations are present that would create a self-referential loop; the analysis is observational and falsifiable by the reported metrics themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The MaFI word-level lipreading dataset and chosen metrics (word, character, phoneme, viseme) provide a valid basis for comparing model and human visual speech perception.
Reference graph
Works this paper leans on
-
[1]
Modern transformer-based models achieve word error rates (WER) below 17% on LRS3 [1, 2], representing a substantial improvement over earlier ap- proaches
Introduction Visual Speech Recognition (VSR) has achieved remarkable per- formance on standard benchmarks. Modern transformer-based models achieve word error rates (WER) below 17% on LRS3 [1, 2], representing a substantial improvement over earlier ap- proaches. These advances in architecture and self-supervised pretraining suggest that machines have maste...
-
[2]
in VSR. We compare three state-of-the-art models: Auto- A VSR [39] (supervised), A V-HuBERT [40] (self-supervised), and VSP-LLM [41] (LLM-based), against human baselines us- ing multi-level, multi-metric correlation analysis, viseme-level comparisons [27], and confusion pattern examination across vi- sual clarity levels. Our analysis reveals systematic di...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Materials and Methods 2.1. Dataset Description We conduct our analysis using the MaFI dataset [37], which provides Mouth and Facial Informativeness (MaFI) scores for 2,276 English words based on human lipreading experiments conducted with 410 participants (263 native British English speakers and 147 native North American English speakers). In these experi...
-
[4]
Detected face regions are cropped and resized to 96×96 pixels, at 25 FPS, which serves as the stan- dard input resolution for all VSR models
using RetinaFace [45]. Detected face regions are cropped and resized to 96×96 pixels, at 25 FPS, which serves as the stan- dard input resolution for all VSR models. All text sequences are normalized by removing punctuation, converting to lowercase, and standardizing whitespace. 2.4. Mapping the Mouth: Phonemes and Visemes To enable analysis at both the ph...
-
[5]
gondola,
Recognition Baselines: Humans vs Models We first establish baseline recognition performance across all VSR models on 2,189 words from the MaFI dataset [37]. While word-level accuracy provides an overall performance measure, it does not indicate whether models are truly using visual cues, as high accuracy could result from reliance on linguistic regu- lari...
-
[6]
VSR models are trained on large labeled corpora where they simultaneously learn visual- to-text mappings and language patterns
Isolating Language Patterns from Visual Understanding While VSR models outperform humans (as seen in Section 3), it remains unclear whether this stems from visual understand- ing or learned language patterns. VSR models are trained on large labeled corpora where they simultaneously learn visual- to-text mappings and language patterns. This raises two crit...
-
[7]
(11.1M tokens, 49,928 unique words) and trained 2-gram and 5-gram models using KenLM [50], to learn phoneme se- quence patterns from the training data, enabling word predic- tion from partial or complete phoneme sequences. For each test word, we extract the first K phonemes from the ground- truth word (e.g., K=3 from ”absolutely” gives ”æ b s”) and re- tr...
-
[8]
Successful lipreading therefore relies on recognizing groups of phonemes that share common visual characteristics
Reading the Lips: Viseme Ambiguity VSR is challenging because many phonemes appear visually similar or identical when spoken, a phenomenon known as viseme ambiguity [27]. Successful lipreading therefore relies on recognizing groups of phonemes that share common visual characteristics. To assess how VSR models handle this ambigu- ity compared to humans, we...
-
[9]
To further exam- ine this, we conducted correlation analyses [20] across multi- ple dimensions (Table 6) to assess VSR models’ alignment with human perceptual patterns
Human-Machine Alignment in Visual Speech Perception Despite their overall strong performance on viseme accuracy, it remains unclear whether VSR models succeed and fail on the same words that humans find easy or difficult. To further exam- ine this, we conducted correlation analyses [20] across multi- ple dimensions (Table 6) to assess VSR models’ alignmen...
-
[10]
We split the dataset into high- clarity (easy) words (M aF I >−1,N= 1056, visually clear) and low-clarity (hard) words (M aF I≤ −1,N= 1133, vi- sually ambiguous)
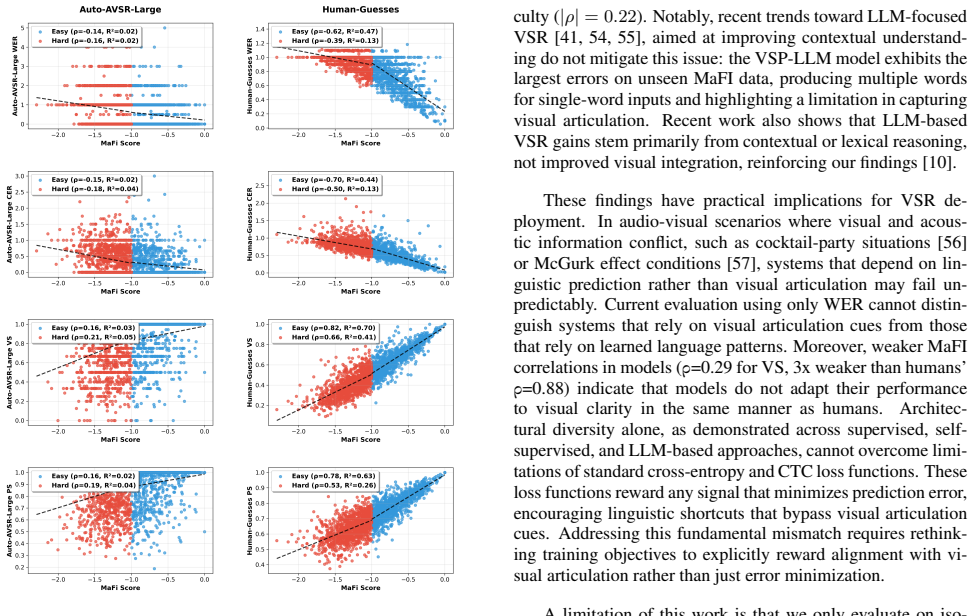
Performance by Visual Information Clarity To further assess how the visual saliency of words affects recog- nition performance, we group them according to their MaFI score, reflecting visual clarity. We split the dataset into high- clarity (easy) words (M aF I >−1,N= 1056, visually clear) and low-clarity (hard) words (M aF I≤ −1,N= 1133, vi- sually ambigu...
-
[11]
Our findings suggest this assumption is incom- plete
Discussion and Conclusion VSR research implicitly equates improvements in transcription accuracy (such as WER) with progress in visual speech un- derstanding. Our findings suggest this assumption is incom- plete. Given the first three phonemes as input, text-only n- grams achieve 76.7% accuracy on in-domain LRS3 vocabulary but only 41% on MaFI, revealing ...
-
[12]
Acknowledgments This publication emanates from research supported by Taighde ´Eireann – Research Ireland, Grant number 22/FFP-A/11059
-
[13]
Generative AI Use Disclosure During the preparation of this work, Claude (Anthropic) was used only for minor English grammar corrections and refining the clarity of written content
-
[14]
Synthvsr: Scaling up visual speech recognition with synthetic supervision,
X. Liu, E. Lakomkin, K. V ougioukas, P. Ma, H. Chen, R. Xie, M. Doulaty, N. Moritz, J. Kolar, S. Petridiset al., “Synthvsr: Scaling up visual speech recognition with synthetic supervision,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 18 806–18 815
2023
-
[15]
Lip reading sentences in the wild,
J. Son Chung, A. Senior, O. Vinyals, and A. Zisserman, “Lip reading sentences in the wild,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 6447–6456
2017
-
[16]
Speech Recogni- tion Models are Strong Lip-readers,
K. R. Prajwal, T. Afouras, and A. Zisserman, “Speech Recogni- tion Models are Strong Lip-readers,” inInterspeech 2024, 2024, pp. 2425–2429
2024
-
[17]
SyncVSR: Data-Efficient Visual Speech Recognition with End- to-End Crossmodal Audio Token Synchronization,
Y . J. Ahn, J. Park, S. Park, J. Choi, and K.-E. Kim, “SyncVSR: Data-Efficient Visual Speech Recognition with End- to-End Crossmodal Audio Token Synchronization,” inInter- speech 2024, 2024, pp. 867–871
2024
-
[18]
Beyond accuracy: quantifying trial-by-trial behaviour of cnns and humans by mea- suring error consistency,
R. Geirhos, K. Meding, and F. A. Wichmann, “Beyond accuracy: quantifying trial-by-trial behaviour of cnns and humans by mea- suring error consistency,”Advances in neural information pro- cessing systems (NeurIPS), vol. 33, pp. 13 890–13 902, 2020
2020
-
[19]
Uncovering the visual contribution in audio- visual speech recognition,
Z. Lin and N. Harte, “Uncovering the visual contribution in audio- visual speech recognition,” in2025 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[20]
Deep problems with neural network mod- els of human vision,
J. S. Bowers, G. Malhotra, M. Dujmovi ´c, M. L. Montero, C. Tsvetkov, V . Biscione, G. Puebla, F. Adolfi, J. E. Hummel, R. F. Heatonet al., “Deep problems with neural network mod- els of human vision,”Behavioral and Brain Sciences, vol. 46, p. e385, 2023
2023
-
[21]
LRS3-TED: a large-scale dataset for visual speech recognition
T. Afouras, J. S. Chung, and A. Zisserman, “Lrs3-ted: a large- scale dataset for visual speech recognition,” inarXiv preprint arXiv:1809.00496, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Do vsr models generalize beyond lrs3?
Y . A. D. Djilali, S. Narayan, E. LeBihan, H. Boussaid, E. Al- mazrouei, and M. Debbah, “Do vsr models generalize beyond lrs3?” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024, pp. 6635–6644
2024
-
[23]
From hype to insight: Rethinking large language model integration in visual speech recognition,
R. Jain and N. Harte, “From hype to insight: Rethinking large language model integration in visual speech recognition,” inPro- ceedings of 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026
2026
-
[24]
Lip-reading: Advances and unresolved questions in a key com- munication skill,
M. Battista, F. Collesei, E. Orzan, M. Fantoni, and D. Bottari, “Lip-reading: Advances and unresolved questions in a key com- munication skill,”Audiology Research, vol. 15, no. 4, p. 89, 2025
2025
-
[25]
Neural pathways for visual speech perception,
L. E. Bernstein and E. Liebenthal, “Neural pathways for visual speech perception,”Frontiers in neuroscience, vol. 8, p. 386, 2014
2014
-
[26]
Speech perception by humans and machines,
R. P. Lippmann, “Speech perception by humans and machines,” in Workshop on the Auditory Basis of Speech Perception, 1996, pp. 309–316
1996
-
[27]
Watch or listen: Robust audio-visual speech recognition with visual corruption modeling and reliability scoring,
J. Hong, M. Kim, J. Choi, and Y . M. Ro, “Watch or listen: Robust audio-visual speech recognition with visual corruption modeling and reliability scoring,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 18 783–18 794
2023
-
[28]
The visual speech head start improves perception and reduces superior temporal cortex re- sponses to auditory speech,
P. J. Karas, J. F. Magnotti, B. A. Metzger, L. L. Zhu, K. B. Smith, D. Yoshor, and M. S. Beauchamp, “The visual speech head start improves perception and reduces superior temporal cortex re- sponses to auditory speech,”elife, vol. 8, p. e48116, 2019
2019
-
[29]
Towards es- timating the upper bound of visual-speech recognition: The visual lip-reading feasibility database,
A. Fernandez-Lopez, O. Martinez, and F. M. Sukno, “Towards es- timating the upper bound of visual-speech recognition: The visual lip-reading feasibility database,” in2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017). IEEE Press, 2017, p. 208–215
2017
-
[30]
Comparison of human and machine-based lip-reading,
S. Hilder, R. Harvey, and B.-J. Theobald, “Comparison of human and machine-based lip-reading,” inProceedings of the Interna- tional Conference on Auditory-Visual Speech Processing (AVSP), 2009, pp. 86–89
2009
-
[31]
Large- vocabulary audio-visual speech recognition by machines and hu- mans
G. Potamianos, C. Neti, G. Iyengar, and E. Helmuth, “Large- vocabulary audio-visual speech recognition by machines and hu- mans.” inInterspeech 2001, 2001, pp. 1027–1030
2001
-
[32]
Which components of the face do humans and machines best speechread?
C. Benoit, T. Guiard-Marigny, B. Le Goff, and A. Adjoudani, “Which components of the face do humans and machines best speechread?” inSpeechreading by humans and machines: Mod- els, systems, and applications. Springer, 1996, pp. 315–328
1996
-
[33]
Evaluating auto- matic speech recognition systems in comparison with human per- ception results using distinctive feature measures,
X. Kong, J.-Y . Choi, and S. Shattuck-Hufnagel, “Evaluating auto- matic speech recognition systems in comparison with human per- ception results using distinctive feature measures,” in2017 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2017, pp. 5810–5814
2017
-
[34]
Insights into machine lip reading,
Y . Lan, R. Harvey, and B.-J. Theobald, “Insights into machine lip reading,” in2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2012, pp. 4825–4828
2012
-
[35]
Automatic lips reading for audio-visual speech processing and recognition,
J. Chaloupka, “Automatic lips reading for audio-visual speech processing and recognition,” inInterspeech 2004, 2004, pp. 2505– 2508
2004
-
[36]
Viseme- dependent weight optimization for CHMM-based audio-visual speech recognition,
A. Karpov, A. Ronzhin, K. Markov, and M. ˇZelezn´y, “Viseme- dependent weight optimization for CHMM-based audio-visual speech recognition,” inInterspeech 2010, 2010, pp. 2678–2681
2010
-
[37]
Lipreading approach for isolated digits recognition under whisper and neutral speech,
F. Tao and C. Busso, “Lipreading approach for isolated digits recognition under whisper and neutral speech,” inInterspeech 2014, 2014, pp. 1154–1158
2014
-
[38]
Lipreading using convolutional neural network,
K. Noda, Y . Yamaguchi, K. Nakadai, H. G. Okuno, and T. Ogata, “Lipreading using convolutional neural network,” inInterspeech 2014, 2014, pp. 1149–1153
2014
-
[39]
Decoding visemes: Improving ma- chine lip-reading,
H. L. Bear and R. Harvey, “Decoding visemes: Improving ma- chine lip-reading,” in2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 2009–2013
2016
-
[40]
Phoneme-to-viseme mappings: the good, the bad, and the ugly,
——, “Phoneme-to-viseme mappings: the good, the bad, and the ugly,”Speech Communication, vol. 95, pp. 40–67, 2017
2017
-
[41]
Hear- ing lips in noise: Universal viseme-phoneme mapping and trans- fer for robust audio-visual speech recognition,
Y . Hu, R. Li, C. Chen, C. Qin, Q.-S. Zhu, and E. S. Chng, “Hear- ing lips in noise: Universal viseme-phoneme mapping and trans- fer for robust audio-visual speech recognition,” inProceedings of the 61st Annual Meeting of the ACL, Toronto, Canada, Jul. 2023, pp. 15 213–15 232
2023
-
[42]
Improving the gap in visual speech recognition between normal and silent speech based on metric learning,
S. Kashiwagi, K. Tanaka, Q. Feng, and S. Morishima, “Improving the gap in visual speech recognition between normal and silent speech based on metric learning,” inInterspeech 2023, 2023, pp. 3397–3401
2023
-
[43]
Lip enhancement and multi-view sim- ulation for robust visual speech recognition in mavsr 2025,
F. Su, C. Li, and J. Liu, “Lip enhancement and multi-view sim- ulation for robust visual speech recognition in mavsr 2025,” in 2025 IEEE 19th International Conference on Automatic Face and Gesture Recognition (FG 2025), 2025, pp. 1–5
2025
-
[44]
Human alignment of neural network representa- tions,
L. Muttenthaler, J. Dippel, L. Linhardt, R. A. Vandermeulen, and S. Kornblith, “Human alignment of neural network representa- tions,” inProceedings of the International Conference on Learn- ing Representations (ICLR), 2023
2023
-
[45]
Visalign: Dataset for measuring the alignment between ai and humans in visual perception,
J. Lee, S. Kim, S. Won, J. Lee, M. Ghassemi, J. Thorne, J. Choi, O.-K. Kwon, and E. Choi, “Visalign: Dataset for measuring the alignment between ai and humans in visual perception,”Advances in Neural Information Processing Systems (NeurIPS), vol. 36, pp. 77 119–77 148, 2023
2023
-
[46]
Learning from human perception to improve automatic speaker verification in style-mismatched con- ditions,
A. Afshan and A. Alwan, “Learning from human perception to improve automatic speaker verification in style-mismatched con- ditions,” inInterspeech 2022, 2022, pp. 2338–2342
2022
-
[47]
Revisiting Parity of Human vs. Machine Conversational Speech Transcription,
C. Mansfield, S. Ng, G.-A. Levow, R. A. Wright, and M. Os- tendorf, “Revisiting Parity of Human vs. Machine Conversational Speech Transcription,” inInterspeech 2021, 2021, pp. 1997–2001
2021
-
[48]
Advocating char- acter error rate for multilingual ASR evaluation,
T. D. K, J. James, D. P. Gopinath, and M. A. K, “Advocating char- acter error rate for multilingual ASR evaluation,” inFindings of the ACL: NAACL 2025. Albuquerque, New Mexico: Associa- tion for Computational Linguistics, April 2025, pp. 4926–4935
2025
-
[49]
Av-superb: A multi-task evaluation benchmark for audio-visual representation models,
Y . Tsenget al., “Av-superb: A multi-task evaluation benchmark for audio-visual representation models,” in2024 IEEE interna- tional conference on acoustics, speech and signal processing (ICASSP), 2024, pp. 6890–6894
2024
-
[50]
Mouth and fa- cial informativeness norms for 2276 english words,
A. Krason, Y . Zhang, H. Man, and G. Vigliocco, “Mouth and fa- cial informativeness norms for 2276 english words,”Behavior Re- search Methods, vol. 56, no. 5, pp. 4786–4801, 2024
2024
-
[51]
Do self-supervised speech models de- velop human-like perception biases?
J. Millet and E. Dunbar, “Do self-supervised speech models de- velop human-like perception biases?” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 7591–7605
2022
-
[52]
Auto-avsr: Audio-visual speech recognition with automatic labels,
P. Ma, S. Petridis, and M. Pantic, “Auto-avsr: Audio-visual speech recognition with automatic labels,” in2023 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[53]
Learning audio-visual speech representation by masked multimodal cluster prediction,
B. Shi, W.-N. Hsu, K. Lakhotia, and A. Mohamed, “Learning audio-visual speech representation by masked multimodal cluster prediction,” inInternational Conference on Learning Representa- tions (ICLR), 2022
2022
-
[54]
Where visual speech meets language: VSP-LLM framework for efficient and context- aware visual speech processing,
J. H. Yeo, S. Han, M. Kim, and Y . M. Ro, “Where visual speech meets language: VSP-LLM framework for efficient and context- aware visual speech processing,” inFindings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 2024, pp. 11 391–11 406
2024
-
[55]
Binary codes capable of correcting deletions, insertions, and reversals,
V . I. Levenshtein, “Binary codes capable of correcting deletions, insertions, and reversals,”Soviet physics. Doklady, vol. 10, pp. 707–710, 1965
1965
-
[56]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvronet al., “Llama 2: Open foundation and fine-tuned chat models,” inin arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Lora: Low-rank adaptation of large language models
E. J. Huet al., “Lora: Low-rank adaptation of large language models.”Proceedings of the International Conference on Learn- ing Representations (ICLR), 2022
2022
-
[58]
Reti- naFace: Single-shot multi-level face localisation in the wild,
J. Deng, J. Guo, E. Ververas, I. Kotsia, and S. Zafeiriou, “Reti- naFace: Single-shot multi-level face localisation in the wild,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020, pp. 5202–5211
2020
-
[59]
Get facial position with viseme,
Microsoft, “Get facial position with viseme,” Mi- crosoft Learn, accessed: 30 October 2025. [Online]. Available: https://learn.microsoft.com/en-us/azure/ai-services/ speech-service/how-to-speech-synthesis-viseme
2025
-
[60]
Phonemizer: Text to phones transcrip- tion for multiple languages in python,
M. Bernard and H. Titeux, “Phonemizer: Text to phones transcrip- tion for multiple languages in python,”Journal of Open Source Software, vol. 6, no. 68, p. 3958, 2021
2021
-
[61]
Phoneme-to-viseme mapping for vi- sual speech recognition,
L. Cappelletta and N. Harte, “Phoneme-to-viseme mapping for vi- sual speech recognition,” inInternational Conference on Pattern Recognition Applications and Methods, vol. 2. SciTePress, 2012, pp. 322–329
2012
-
[62]
A normalized levenshtein distance metric,
L. Yujian and L. Bo, “A normalized levenshtein distance metric,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 29, no. 6, pp. 1091–1095, 2007
2007
-
[63]
Kenlm: Faster and smaller language model queries,
K. Heafield, “Kenlm: Faster and smaller language model queries,” inProceedings of the sixth workshop on statistical machine trans- lation, 2011, pp. 187–197
2011
-
[64]
The reliability of a two-item scale: Pearson, cronbach, or spearman-brown?
R. Eisingaet al., “The reliability of a two-item scale: Pearson, cronbach, or spearman-brown?”International journal of public health, vol. 58, no. 4, pp. 637–642, 2013
2013
-
[65]
Video-bench: Human-aligned video generation benchmark,
H. Hanet al., “Video-bench: Human-aligned video generation benchmark,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 18 858–18 868
2025
-
[66]
Prediction and constraint in au- diovisual speech perception,
J. E. Peelle and M. S. Sommers, “Prediction and constraint in au- diovisual speech perception,”Cortex, vol. 68, pp. 169–181, 2015
2015
-
[67]
Large language models are strong audio- visual speech recognition learners,
U. Cappellazzoet al., “Large language models are strong audio- visual speech recognition learners,” in2025 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[68]
Zero-avsr: Zero-shot audio-visual speech recognition with llms by learning language-agnostic speech representations,
J. H. Yeo, M. Kim, C. W. Kim, S. Petridis, and Y . M. Ro, “Zero-avsr: Zero-shot audio-visual speech recognition with llms by learning language-agnostic speech representations,” inPro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2025, pp. 6693–6703
2025
-
[69]
Cocktail-Party Audio-Visual Speech Recognition,
T.-B. Nguyen, N.-Q. Pham, and A. Waibel, “Cocktail-Party Audio-Visual Speech Recognition,” inInterspeech 2025, 2025, pp. 1828–1832
2025
-
[70]
Hearing lips and seeing voices,
H. McGurk and J. MacDonald, “Hearing lips and seeing voices,” Nature, vol. 264, no. 5588, pp. 746–748, 1976
1976
-
[71]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiyet al., “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Confer- ence on Learning Representations (ICLR), 2021
2021
-
[72]
Deep saliency models : The quest for the loss function,
A. Bruckert, H. R. Tavakoli, Z. Liu, M. Christie, and O. Le Meur, “Deep saliency models : The quest for the loss function,”Neuro- computing, vol. 453, pp. 693–704, 2021
2021
-
[73]
Predict-and-update network: Audio-visual speech recognition inspired by human speech per- ception,
J. Wang, X. Qian, and H. Li, “Predict-and-update network: Audio-visual speech recognition inspired by human speech per- ception,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, 2024
2024
-
[74]
Human- inspired computing for robust and efficient audio-visual speech recognition,
Q. Liu, J. Wang, Y . Wang, X. Yang, G. Pan, and H. Li, “Human- inspired computing for robust and efficient audio-visual speech recognition,”IEEE Transactions on Computers, 2025
2025
-
[75]
Can we read speech beyond the lips? rethinking roi selection for deep visual speech recognition,
Y . Zhang, S. Yang, J. Xiao, S. Shan, and X. Chen, “Can we read speech beyond the lips? rethinking roi selection for deep visual speech recognition,” in2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020). IEEE, 2020, pp. 356–363
2020
-
[76]
Vivit: A video vision transformer,
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lu ˇci´c, and C. Schmid, “Vivit: A video vision transformer,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 6836–6846
2021
-
[77]
Vallr: Visual asr language model for lip reading,
M. Thomas, E. Fish, and R. Bowden, “Vallr: Visual asr language model for lip reading,” inProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), October 2025
2025
-
[78]
Swinlip: An efficient vi- sual speech encoder for lip reading using swin transformer,
Y .-H. Park, R.-H. Park, and H.-M. Park, “Swinlip: An efficient vi- sual speech encoder for lip reading using swin transformer,”Neu- rocomputing, p. 130289, 2025
2025
-
[79]
Efficient train- ing for multilingual visual speech recognition: Pre-training with discretized visual speech representation,
M. Kim, J. Yeo, S. J. Park, H. Rha, and Y . M. Ro, “Efficient train- ing for multilingual visual speech recognition: Pre-training with discretized visual speech representation,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1311–1320
2024
-
[80]
Phoneme-level visual speech recognition via point-visual fusion and language model reconstruction,
M. Kit Khinn Teng, H. Zhang, and T. Saitoh, “Phoneme-level visual speech recognition via point-visual fusion and language model reconstruction,”arXiv e-prints, pp. arXiv–2507, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.