Priors Persist Through Suppression: A Stroop Paradigm for Lexical Override
Pith reviewed 2026-06-29 22:13 UTC · model grok-4.3
The pith
Lexical priors from pretraining continue to shape model outputs even after explicit word redefinitions in the prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
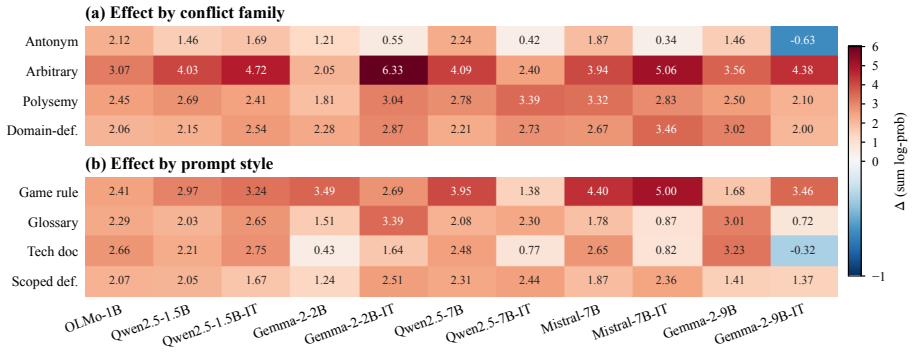
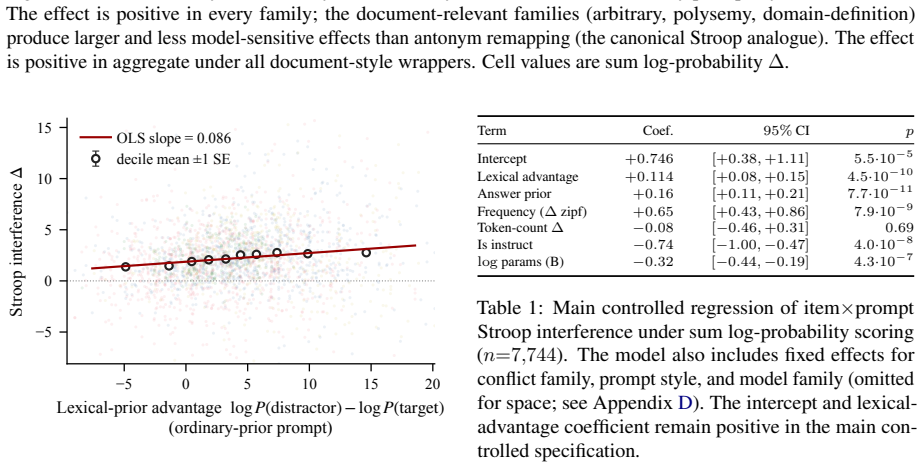
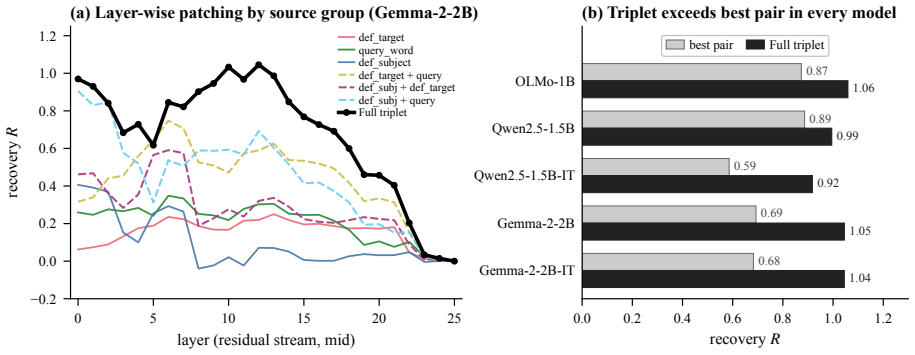
Across eleven open-weight models the strength of a word's lexical prior predicts the amount of interference it produces under an explicit remapping rule, even after item-level controls for answer prior, frequency, tokenization and prompt wording. Activation patching on five models locates the repair at three source positions—the definition subject, its new target, and the query word—whose restoration recovers the original interference magnitude (aggregate R between 0.92 and 1.06). The mechanism protects the contextual target rather than silencing the prior: perturbing those positions lowers the distractor probability but the target survives only when the redefinition remains intact.
What carries the argument
The Stroop-style paradigm that pits a remapping rule against a lexical-prior distractor, together with targeted activation patching at the three positions that carry the redefinition.
If this is right
- Override failure will be higher for words whose pretraining prior is stronger.
- The effect should appear across model families and sizes once prior strength is measured.
- Patching the three definition-carrying positions will largely restore the interference pattern.
- The distractor probability drops on perturbation while the target probability is preserved only when the redefinition stays intact.
Where Pith is reading between the lines
- Custom instructions may routinely fail to override high-prior associations without additional training.
- Measuring prior strength on new tasks could predict which prompt-based constraints will be brittle.
- The same three-position repair might generalize to other forms of contextual redefinition beyond single-word remappings.
Load-bearing premise
The paradigm and its item-level controls isolate the causal contribution of lexical-prior strength rather than other unmeasured differences in how models handle conflicting instructions.
What would settle it
After applying the listed controls, lexical-prior strength shows no reliable correlation with interference rates across the test items.
Figures



read the original abstract
Glossaries, technical specifications, and system prompts routinely ask language models to use familiar words in unfamiliar ways. When this works, the local rule does not overwrite the old meaning; the pretrained prior keeps operating underneath, and its strength still shows through. We test this with a Stroop-style paradigm: a remapping rule (doctor means forest) pitted against the query word's lexical-prior distractor (hospital), with matched neutral controls. Across 11 open-weight models spanning four families and 1B-9B parameters, lexical-prior strength predicts interference even after item-level controls for answer prior, frequency, tokenization, and prompt wording. Activation patching on five models then locates where the override is repaired internally. Restoring three source positions that carry the redefinition (the definition subject, its new target, and the query word) almost fully recovers the effect (aggregate $R \in [0.92, 1.06]$). The repair works by protecting the contextual target rather than by silencing the prior; the distractor's probability falls whenever these positions are perturbed, but the target survives only when the redefinition is restored intact. Behavior and mechanism converge on the same channel: the prior's strength both predicts which overrides fail and marks where the causal repair lands.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that lexical priors in language models persist even when suppressed by remapping rules in prompts (e.g., 'doctor means forest' vs. query 'hospital'). Using a Stroop-style paradigm with matched neutral controls, it reports that lexical-prior strength predicts interference across 11 open-weight models (four families, 1B-9B parameters) after item-level controls for answer prior, frequency, tokenization, and prompt wording. Activation patching on five models locates the repair at three redefinition positions (definition subject, new target, query word), with restoration recovering the effect (aggregate R in [0.92, 1.06]); the mechanism protects the contextual target rather than silencing the prior.
Significance. If the results hold, the work supplies convergent behavioral and mechanistic evidence on how pretrained lexical knowledge interacts with and resists contextual overrides in LMs. Strengths include the cross-family and cross-scale replication, the use of item-level regression controls, and the activation-patching results that identify specific positions and a protective (rather than suppressive) mechanism, providing falsifiable predictions about override failure.
major comments (2)
- [Methods] Methods/Experimental Design: The central claim that lexical-prior strength exerts a causal effect on override failure after controls requires that the item-level regression fully isolates this variable. No details are provided on whether interaction terms between prior strength and remapping-rule features (e.g., embedding of the constructed definition) were tested or included; if residual correlations remain, the predictive relationship could be partly spurious rather than evidence of prior persistence through suppression.
- [Results] Results (patching subsection): The aggregate R range [0.92, 1.06] is reported for recovery when restoring the three positions, but without per-model values, variance estimates, or a direct comparison to a null patching baseline, it is difficult to evaluate whether the recovery is uniformly strong or driven by a subset of the five models; this is load-bearing for the claim that behavior and mechanism converge on the same channel.
minor comments (3)
- [Abstract] Abstract: The range for R is given without specifying the correlation coefficient used or the number of items per condition; adding these would improve precision.
- The manuscript would benefit from an explicit statement of the total number of items, the exact regression specification (including any fixed effects), and whether post-hoc model or item exclusions were performed.
- Figure captions for the patching results should clarify the baseline (e.g., mean activation vs. zero) against which recovery is measured.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below and note planned revisions to address concerns about regression isolation and patching result transparency.
read point-by-point responses
-
Referee: [Methods] Methods/Experimental Design: The central claim that lexical-prior strength exerts a causal effect on override failure after controls requires that the item-level regression fully isolates this variable. No details are provided on whether interaction terms between prior strength and remapping-rule features (e.g., embedding of the constructed definition) were tested or included; if residual correlations remain, the predictive relationship could be partly spurious rather than evidence of prior persistence through suppression.
Authors: The reported regression used item-level controls for answer prior, frequency, tokenization, and prompt wording as covariates, with prior strength as the focal predictor. Interaction terms with remapping-rule features were not tested in the primary model to preserve degrees of freedom and limit multicollinearity. We agree this leaves a gap in ruling out residual correlations. The revised manuscript will add a supplementary analysis testing interactions between prior strength and definition-embedding features, reporting coefficients and confirming whether they alter the main effect. revision: yes
-
Referee: [Results] Results (patching subsection): The aggregate R range [0.92, 1.06] is reported for recovery when restoring the three positions, but without per-model values, variance estimates, or a direct comparison to a null patching baseline, it is difficult to evaluate whether the recovery is uniformly strong or driven by a subset of the five models; this is load-bearing for the claim that behavior and mechanism converge on the same channel.
Authors: The aggregate R was presented to summarize consistent recovery. To permit evaluation of uniformity across models, the revised version will report per-model R values with variance estimates and include a null baseline comparison (patching of unrelated positions) to show specificity of the recovery effect. revision: yes
Circularity Check
Empirical study with no self-referential derivations or load-bearing self-citations
full rationale
The paper is an empirical investigation relying on behavioral measurements across models, item-level regression controls, and activation patching interventions. No equations, mathematical derivations, or fitted parameters are presented that reduce any claimed result to its own inputs by construction. The central claim (lexical-prior strength predicting interference after controls) is tested via external data and interventions rather than self-definition or self-citation chains. The analysis is self-contained against external benchmarks with no patterns matching the enumerated circularity kinds.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained language models possess measurable lexical priors based on co-occurrence patterns in training data that produce measurable interference.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
Xu, Rongwu and Qi, Zehan and Guo, Zhijiang and Wang, Cunxiang and Wang, Hongru and Zhang, Yue and Xu, Wei , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
2024
-
[2]
Advances in Neural Information Processing Systems , volume =
Geiger, Atticus and Lu, Hanson and Icard, Thomas and Potts, Christopher , title =. Advances in Neural Information Processing Systems , volume =
-
[3]
and Potts, Christopher , title =
Geiger, Atticus and Wu, Zhengxuan and Lu, Hanson and Rozner, Josh and Kreiss, Elisa and Icard, Thomas and Goodman, Noah D. and Potts, Christopher , title =. Proceedings of the 39th International Conference on Machine Learning , year =
-
[4]
Ridley , title =
Stroop, J. Ridley , title =. Journal of Experimental Psychology , volume =. 1935 , doi =
1935
-
[5]
, title =
MacLeod, Colin M. , title =. Psychological Bulletin , volume =
-
[6]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention is all you need , journal =
-
[7]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda , title =. Advances in Neural Information Processing Systems , volume =
-
[8]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year =
Min, Sewon and Lyu, Xinxi and Holtzman, Ari and Artetxe, Mikel and Lewis, Mike and Hajishirzi, Hannaneh and Zettlemoyer, Luke , title =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year =
2022
-
[9]
Larger language models do in-context learning differently.arXiv preprint arXiv:2303.03846,
Wei, Jerry and Wei, Jason and Tay, Yi and Tran, Dustin and Webson, Albert and Lu, Yifeng and Chen, Xinyun and Liu, Hanxiao and Huang, Da and Zhou, Denny and Ma, Tengyu , title =. arXiv preprint arXiv:2303.03846 , year =
-
[10]
Findings of the Association for Computational Linguistics: ACL 2023 , year =
Pan, Jane and Gao, Tianyu and Chen, Howard and Chen, Danqi , title =. Findings of the Association for Computational Linguistics: ACL 2023 , year =
2023
-
[11]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , year =
Longpre, Shayne and Perisetla, Kartik and Chen, Anthony and Ramesh, Nikhil and DuBois, Chris and Singh, Sameer , title =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , year =
2021
-
[12]
The Twelfth International Conference on Learning Representations , year =
Xie, Jian and Zhang, Kai and Chen, Jiangjie and Lou, Renze and Su, Yu , title =. The Twelfth International Conference on Learning Representations , year =
-
[13]
Findings of the Association for Computational Linguistics: ACL 2024 , year =
Jin, Zhuoran and Cao, Pengfei and Yuan, Hongbang and Chen, Yubo and Xu, Jiexin and Li, Huaijun and Jiang, Xiaojian and Liu, Kang and Zhao, Jun , title =. Findings of the Association for Computational Linguistics: ACL 2024 , year =
2024
-
[14]
First Conference on Language Modeling (
Kortukov, Evgenii and Rubinstein, Alexander and Nguyen, Elisa and Oh, Seong Joon , title =. First Conference on Language Modeling (
-
[15]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics , year =
Webson, Albert and Pavlick, Ellie , title =. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics , year =
2022
-
[16]
Transformer Circuits Thread , year =
Elhage, Nelson and Nanda, Neel and Olsson, Catherine and Henighan, Tom and Joseph, Nicholas and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom , title =. Transformer Circuits Thread , year =
-
[17]
Advances in Neural Information Processing Systems , volume =
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Singer, Yaron and Shieber, Stuart , title =. Advances in Neural Information Processing Systems , volume =
-
[18]
Advances in Neural Information Processing Systems , volume =
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , title =. Advances in Neural Information Processing Systems , volume =
-
[19]
The Eleventh International Conference on Learning Representations , year =
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , title =. The Eleventh International Conference on Learning Representations , year =
-
[20]
Towards automated circuit discovery for mechanistic interpretability , booktitle =
Conmy, Arthur and Mavor-Parker, Augustine and Lynch, Aengus and Heimersheim, Stefan and Garriga-Alonso, Adri. Towards automated circuit discovery for mechanistic interpretability , booktitle =
-
[21]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , year =
Geva, Mor and Schuster, Roei and Berant, Jonathan and Levy, Omer , title =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , year =
2021
-
[22]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
Geva, Mor and Bastings, Jasmijn and Filippova, Katja and Globerson, Amir , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
2023
-
[23]
The Twelfth International Conference on Learning Representations , year =
Zhang, Fred and Nanda, Neel , title =. The Twelfth International Conference on Learning Representations , year =
-
[24]
2022 , howpublished =
Nanda, Neel and Bloom, Joseph , title =. 2022 , howpublished =
2022
-
[25]
Transformer Circuits Thread , year =
Olsson, Catherine and Elhage, Nelson and Nanda, Neel and Joseph, Nicholas and DasSarma, Nova and Henighan, Tom and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna , title =. Transformer Circuits Thread , year =
-
[26]
The Twelfth International Conference on Learning Representations , year =
Merullo, Jack and Eickhoff, Carsten and Pavlick, Ellie , title =. The Twelfth International Conference on Learning Representations , year =
-
[27]
Yang, An and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Li, Chengyuan and Liu, Dayiheng and Huang, Fei and Wei, Haoran , title =. arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Gemma 2: Improving open language models at a practical size , journal =
Rivi. Gemma 2: Improving open language models at a practical size , journal =
-
[29]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year =
Groeneveld, Dirk and Beltagy, Iz and Walsh, Evan and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year =
-
[30]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and Casas, Diego de las and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile , title =. arXiv preprint arXiv:2310.06825 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex , title =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex , title =. Advances in Neural Information Processing Systems , volume =
-
[32]
Language models as knowledge bases? , booktitle =
Petroni, Fabio and Rockt. Language models as knowledge bases? , booktitle =. 2019 , doi =
2019
-
[33]
Proceedings of the 40th International Conference on Machine Learning , year =
Kandpal, Nikhil and Deng, Haikang and Roberts, Adam and Wallace, Eric and Raffel, Colin , title =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[34]
Shi, Freda and Chen, Xinyun and Misra, Kanishka and Scales, Nathan and Dohan, David and Chi, Ed H. and Sch. Large language models can be easily distracted by irrelevant context , booktitle =
-
[35]
and Dasgupta, Ishita and Chan, Stephanie C
Lampinen, Andrew K. and Dasgupta, Ishita and Chan, Stephanie C. Y. and Mathewson, Kory W. and Tessler, Michael Henry and Creswell, Antonia and McClelland, James L. and Wang, Jane X. and Hill, Felix , title =. PNAS Nexus , year =
-
[36]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , year =
Misra, Kanishka and Rayz, Julia Taylor and Ettinger, Allyson , title =. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , year =
-
[37]
Transformer Circuits Thread , year =
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jermyn, Adam , title =. Transformer Circuits Thread , year =
-
[38]
Computational Linguistics , volume =
Mueller, Aaron and Brinkmann, Jannik and Li, Millicent and Marks, Samuel and Pal, Koyena and Prakash, Nikhil and Rager, Can and Sankaranarayanan, Aruna and Sharma, Arnab Sen and Sun, Jiuding and Todd, Eric and Bau, David and Belinkov, Yonatan , title =. Computational Linguistics , volume =. 2026 , doi =
2026
-
[39]
Negated and misprimed probes for pretrained language models: Birds can talk, but cannot fly , booktitle =
Kassner, Nora and Sch. Negated and misprimed probes for pretrained language models: Birds can talk, but cannot fly , booktitle =. 2020 , doi =
2020
-
[40]
Findings of the Association for Computational Linguistics: EMNLP 2020 , year =
Misra, Kanishka and Ettinger, Allyson and Rayz, Julia Taylor , title =. Findings of the Association for Computational Linguistics: EMNLP 2020 , year =
2020
-
[41]
Transactions of the Association for Computational Linguistics , volume =
Ettinger, Allyson , title =. Transactions of the Association for Computational Linguistics , volume =. 2020 , doi =
2020
-
[42]
Steering Language Models With Activation Engineering
Turner, Alexander Matt and Thiergart, Lisa and Leech, Gavin and Udell, David and Vazquez, Juan J. and Mini, Ulisse and MacDiarmid, Monte , title =. arXiv preprint arXiv:2308.10248 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
and Andreas, Jacob , title =
Hernandez, Evan and Li, Belinda Z. and Andreas, Jacob , title =. First Conference on Language Modeling (
-
[45]
The Twelfth International Conference on Learning Representations , year =
Feng, Jiahai and Steinhardt, Jacob , title =. The Twelfth International Conference on Learning Representations , year =
-
[46]
The Twelfth International Conference on Learning Representations , year =
Prakash, Nikhil and Shaham, Tamar Rott and Haklay, Tal and Belinkov, Yonatan and Bau, David , title =. The Twelfth International Conference on Learning Representations , year =
-
[47]
Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , year =
McDougall, Callum and Conmy, Arthur and Rushing, Cody and McGrath, Thomas and Nanda, Neel , title =. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , year =
-
[48]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
Yu, Qinan and Merullo, Jack and Pavlick, Ellie , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
2023
-
[49]
Competition of mechanisms: Tracing how language models handle facts and counterfactuals , booktitle =
Ortu, Francesco and Jin, Zhijing and Doimo, Diego and Sachan, Mrinmaya and Cazzaniga, Alberto and Sch. Competition of mechanisms: Tracing how language models handle facts and counterfactuals , booktitle =
-
[50]
Mixing Mechanisms: How Language Models Retrieve Bound Entities In-Context
Gur-Arieh, Yoav and Geva, Mor and Geiger, Atticus , title =. arXiv preprint arXiv:2510.06182 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
arXiv preprint arXiv:2602.17520 , year =
Thota, Yogeswar Reddy and Rafatirad, Setareh and Homayoun, Houman and Nikoubin, Tooraj , title =. arXiv preprint arXiv:2602.17520 , year =
-
[52]
arXiv preprint arXiv:2602.08221 , year =
Ma, Xuhua and Zhang, Richong and Nie, Zhijie , title =. arXiv preprint arXiv:2602.08221 , year =
-
[53]
, title =
Zhu, Jian-Qiao and Griffiths, Thomas L. , title =. Psychological Review , year =
-
[54]
International Conference on Learning Representations (ICLR) , year =
Xie, Sang Michael and Raghunathan, Aditi and Liang, Percy and Ma, Tengyu , title =. International Conference on Learning Representations (ICLR) , year =
-
[55]
Formal Representation of Human Judgment , editor =
Edwards, Ward , title =. Formal Representation of Human Judgment , editor =
-
[56]
, title =
Grether, David M. , title =. Journal of Economic Behavior & Organization , volume =. 1992 , doi =
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.