ResearchClawBench: A Benchmark for End-to-End Autonomous Scientific Research
Pith reviewed 2026-06-29 08:22 UTC · model grok-4.3
The pith
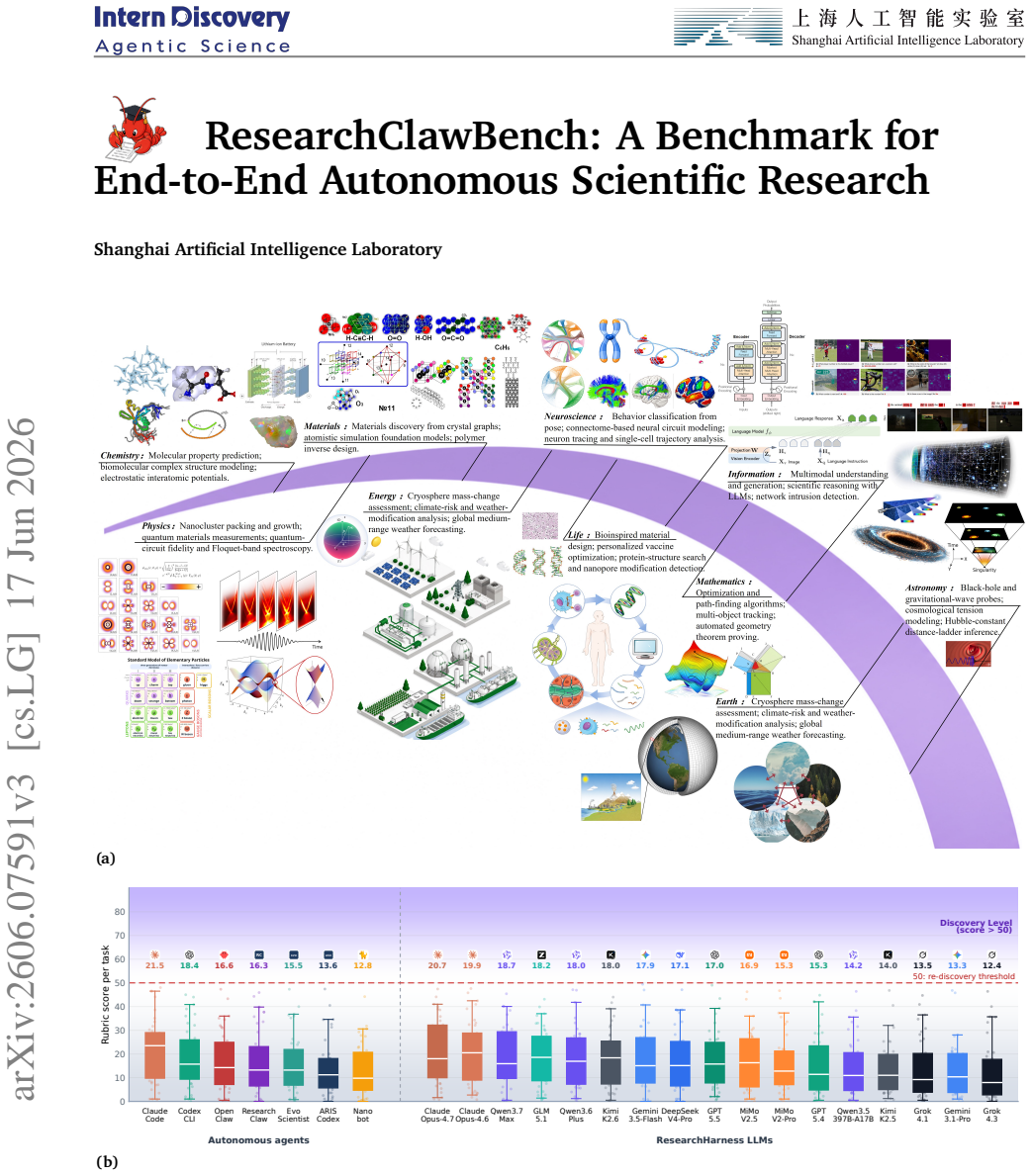
A benchmark shows top AI agents and LLMs average only 21-26 when tasked with re-discovering results from real published papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ResearchClawBench evaluates autonomous research agents on 40 tasks grounded in published papers across ten domains. The strongest autonomous agent, Claude Code, averages 21.5 while the strongest ResearchHarness LLM, Claude-Opus-4.7, averages 20.7, and the overall LLM frontier mean is 26.5. Failures concentrate in experimental protocol mismatch, evidence mismatch, and missing scientific core. The benchmark supplies expert-curated multimodal rubrics that allow scoring of target-paper-level re-discovery while still permitting new discovery.
What carries the argument
ResearchClawBench, a benchmark of 40 tasks each tied to a hidden published paper, equipped with expert-curated multimodal rubrics that decompose scientific artifacts into weighted scoring criteria.
If this is right
- Development of scientific AI agents can now be tracked against a fixed set of re-discovery tasks with public rubrics.
- Error patterns concentrated in protocol and evidence matching identify specific capabilities that must improve.
- The rubric design leaves explicit room for agents to produce discoveries beyond the original papers.
- A unified evaluation protocol enables direct comparison across different agent architectures and LLM backbones.
Where Pith is reading between the lines
- The benchmark could be expanded with tasks that require generating and testing new hypotheses rather than recovering existing ones.
- Persistent low scores point to a need for better long-horizon coordination between literature search, experiment design, and result interpretation.
- Adding simulation or robotic execution layers to the tasks would expose whether current failures are mainly reasoning or execution bottlenecks.
- Regular addition of newer papers would keep the benchmark from becoming a static target that agents overfit to.
Load-bearing premise
The expert-curated rubrics correctly identify the scientific core of each paper and fairly score agent outputs that may differ in form from the original publication.
What would settle it
An agent that scores above 70 on the majority of the 40 tasks under the same evaluation protocol would demonstrate reliable re-discovery of published scientific results.
Figures
read the original abstract
AI coding agents are increasingly used for scientific work, but their end-to-end autonomous research capability remains difficult to verify. We present ResearchClawBench, a benchmark for evaluating autonomous scientific research across 40 tasks from 10 scientific domains. Each task is grounded in a real published paper, provides related literature and raw data, and hides the target paper during evaluation. Expert-curated multimodal rubrics decompose the target scientific artifacts into weighted criteria, enabling evaluation of target-paper-level re-discovery while leaving room for new discovery. We evaluate seven autonomous research (auto-research) agents under a unified protocol and seventeen native LLMs through the lightweight ResearchHarness. Current systems remain far from reliable re-discovery: the strongest autonomous agent, Claude Code, averages 21.5, and the strongest ResearchHarness LLM, Claude-Opus-4.7, averages 20.7, with an LLM frontier mean of only 26.5. Error analysis shows that failures concentrate in experimental protocol mismatch, evidence mismatch, and missing scientific core. ResearchClawBench provides a reproducible evaluation frontier for measuring progress toward autonomous scientific research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ResearchClawBench, a benchmark with 40 tasks drawn from real published papers across 10 scientific domains. Each task supplies related literature and raw data while hiding the target paper; expert-curated multimodal rubrics decompose the target artifacts into weighted criteria for scoring autonomous re-discovery. Evaluations of seven auto-research agents and seventeen LLMs via ResearchHarness yield low averages (Claude Code at 21.5, Claude-Opus-4.7 at 20.7, frontier LLM mean 26.5), with errors concentrated in protocol mismatch, evidence mismatch, and missing scientific core. The work positions the benchmark as a reproducible frontier for measuring progress toward autonomous scientific research.
Significance. If the rubrics prove reliable, the benchmark supplies a concrete, reproducible yardstick that quantifies the distance between current AI systems and reliable end-to-end scientific re-discovery. The grounding in actual published papers, provision of raw data and literature, and explicit allowance for new discovery within the rubrics are constructive design choices that distinguish it from purely synthetic or narrow coding benchmarks.
major comments (3)
- [Abstract / Rubric Construction] Abstract and rubric description: The headline claim that systems remain 'far from reliable re-discovery' rests entirely on the reported scores (21.5–26.5). No details are supplied on how the expert-curated multimodal rubrics were constructed, what inter-rater agreement was achieved, or whether they were validated against human re-implementations that use different but scientifically equivalent protocols. Without this, it is impossible to determine whether the low scores reflect agent limitations or rubric choices that over-penalize format or protocol differences.
- [Error Analysis] Error analysis: The manuscript states that failures concentrate in 'experimental protocol mismatch' and 'evidence mismatch.' Because the rubrics are described only at a high level and no sensitivity analysis is reported, it remains unclear whether these categories would still dominate if the rubrics explicitly credited methodologically distinct but scientifically equivalent outputs, as the abstract claims they 'leave room for new discovery.'
- [Benchmark Construction] Task selection and generalizability: The 40 tasks are said to be 'grounded in a real published paper' across 10 domains, yet no explicit criteria for task selection, difficulty calibration, or domain representativeness are provided. This omission weakens the inference that the observed performance gap is representative of autonomous research capability in general rather than an artifact of the chosen papers.
minor comments (1)
- [Evaluation Protocol] The abstract refers to 'multimodal rubrics' but the manuscript should clarify whether scoring criteria include visual or data-visualization elements and how these are evaluated when agent outputs differ in presentation format.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that will strengthen the manuscript's transparency and rigor without altering its core claims or results.
read point-by-point responses
-
Referee: [Abstract / Rubric Construction] Abstract and rubric description: The headline claim that systems remain 'far from reliable re-discovery' rests entirely on the reported scores (21.5–26.5). No details are supplied on how the expert-curated multimodal rubrics were constructed, what inter-rater agreement was achieved, or whether they were validated against human re-implementations that use different but scientifically equivalent protocols. Without this, it is impossible to determine whether the low scores reflect agent limitations or rubric choices that over-penalize format or protocol differences.
Authors: We agree that the manuscript would benefit from greater transparency on rubric construction. In the revised version we will add a dedicated subsection describing the process: domain experts decomposed each target paper into weighted criteria based on scientific importance, with explicit allowance for equivalent protocols and new discoveries. We will report any inter-rater agreement metrics that were collected during rubric finalization. A formal validation study against independent human re-implementations was not conducted, as the benchmark's primary purpose is to measure AI performance relative to the published artifacts; however, we will clarify this scope limitation and discuss its implications for interpreting the low scores. revision: yes
-
Referee: [Error Analysis] Error analysis: The manuscript states that failures concentrate in 'experimental protocol mismatch' and 'evidence mismatch.' Because the rubrics are described only at a high level and no sensitivity analysis is reported, it remains unclear whether these categories would still dominate if the rubrics explicitly credited methodologically distinct but scientifically equivalent outputs, as the abstract claims they 'leave room for new discovery.'
Authors: The error categories were derived from qualitative review of agent outputs against the rubrics. To directly address the concern, the revision will include a sensitivity analysis on a representative subset of tasks: we will re-score outputs while explicitly crediting methodologically distinct but scientifically equivalent approaches and report the resulting changes in error distributions and aggregate scores. This will test whether the dominant failure modes persist under more flexible interpretations consistent with the benchmark's design intent. revision: yes
-
Referee: [Benchmark Construction] Task selection and generalizability: The 40 tasks are said to be 'grounded in a real published paper' across 10 domains, yet no explicit criteria for task selection, difficulty calibration, or domain representativeness are provided. This omission weakens the inference that the observed performance gap is representative of autonomous research capability in general rather than an artifact of the chosen papers.
Authors: We will expand the Benchmark Construction section to list the explicit selection criteria (availability of open raw data and code, presence of multimodal artifacts, coverage across 10 domains, and feasibility of expert rubric creation). Difficulty was calibrated via internal pilot runs with frontier models; we will report these steps and any observed variance. While the 40 tasks cannot claim exhaustive representativeness of all scientific research, the selection aimed for diversity; the revision will include a limitations paragraph on generalizability. revision: yes
Circularity Check
No significant circularity; benchmark uses external ground truth
full rationale
The paper defines ResearchClawBench using 40 tasks drawn from independently published external papers as ground truth, with expert-curated rubrics applied to score agent and LLM outputs. Reported averages (e.g., 21.5 for Claude Code) are computed directly from these fixed external references and rubrics under a unified protocol. No equations, fitted parameters, self-referential predictions, or derivations appear in the abstract or described structure; the central claim of low re-discovery performance rests on empirical evaluation against outside artifacts rather than reducing to quantities defined within the benchmark itself. This satisfies the condition of being self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 40 tasks drawn from published papers are representative of end-to-end scientific research across the 10 domains.
- domain assumption Expert-curated rubrics provide a valid decomposition of scientific artifacts into weighted, scorable criteria.
Forward citations
Cited by 2 Pith papers
-
Closed-loop Auto Research for Molecular Property Prediction: Discovering and Certifying Generalizable Improvements
Closed-loop LM-agent auto research finds some transferable gains on molecular property prediction benchmarks via external data but shows non-transfer for model and feature edits selected on validation.
-
EurekAgent: Agent Environment Engineering is All You Need For Autonomous Scientific Discovery
EurekAgent achieves new state-of-the-art results on mathematics, kernel engineering, and machine learning tasks by engineering agent environments for autonomous scientific discovery, including a 26-circle packing resu...
Reference graph
Works this paper leans on
-
[1]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Humanity's last exam , author=. arXiv preprint arXiv:2501.14249 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Advances in Neural Information Processing Systems , volume=
Scicode: A research coding benchmark curated by scientists , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
International Conference on Learning Representations , volume=
Scienceagentbench: Toward rigorous assessment of language agents for data-driven scientific discovery , author=. International Conference on Learning Representations , volume=
-
[5]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
The ai scientist: Towards fully automated open-ended scientific discovery , author=. arXiv preprint arXiv:2408.06292 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
PaperBench: Evaluating AI's Ability to Replicate AI Research
PaperBench: Evaluating AI's Ability to Replicate AI Research , author=. arXiv preprint arXiv:2504.01848 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Scienceworld: Is your agent smarter than a 5th grader? , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[8]
arXiv preprint arXiv:2502.14499 , year=
Mlgym: A new framework and benchmark for advancing ai research agents , author=. arXiv preprint arXiv:2502.14499 , year=
-
[9]
Proceedings of the 3rd Workshop on Noisy User-generated Text , pages=
Crowdsourcing multiple choice science questions , author=. Proceedings of the 3rd Workshop on Noisy User-generated Text , pages=
- [10]
-
[11]
International Conference on Learning Representations , volume=
Mle-bench: Evaluating machine learning agents on machine learning engineering , author=. International Conference on Learning Representations , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Discoveryworld: A virtual environment for developing and evaluating automated scientific discovery agents , author=. Advances in Neural Information Processing Systems , volume=
- [13]
-
[14]
Advances in Neural Information Processing Systems , volume=
Mlr-bench: Evaluating ai agents on open-ended machine learning research , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
AI & SOCIETY , volume=
Researchers’ perceptions of automating scientific research , author=. AI & SOCIETY , volume=. 2025 , publisher=
2025
-
[16]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
From generation to judgment: Opportunities and challenges of llm-as-a-judge , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[17]
EvoScientist: Towards multi-agent evolving AI scientists for end-to-end scientific discovery, 2026
Evoscientist: Towards multi-agent evolving ai scientists for end-to-end scientific discovery , author=. arXiv preprint arXiv:2603.08127 , year=
-
[18]
Journal of Systems and Software , volume=
Agent design pattern catalogue: A collection of architectural patterns for foundation model based agents , author=. Journal of Systems and Software , volume=. 2025 , publisher=
2025
-
[19]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents , author=. arXiv preprint arXiv:2307.13854 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Scibench: Evaluating college-level scientific problem-solving abilities of large language models , author=. arXiv preprint arXiv:2307.10635 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2506.12958 , year=
Domain specific benchmarks for evaluating multimodal large language models , author=. arXiv preprint arXiv:2506.12958 , year=
-
[23]
Bioinformatics , volume=
Chembench: a cheminformatics workbench , author=. Bioinformatics , volume=. 2010 , publisher=
2010
-
[24]
Advances in neural information processing systems , volume=
What can large language models do in chemistry? a comprehensive benchmark on eight tasks , author=. Advances in neural information processing systems , volume=
-
[25]
The Fourteenth International Conference on Learning Representations , year=
Earthse: A benchmark evaluating earth scientific exploration capability for large language models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[26]
MSEarth: A Multimodal Benchmark for Earth Science Phenomenon Discovery with MLLMs
MSEarth: A Multimodal Scientific Dataset and Benchmark for Phenomena Uncovering in Earth Science , author=. arXiv preprint arXiv:2505.20740 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Core-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark , author=. arXiv preprint arXiv:2409.11363 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
AutoReproduce: Automatic AI Experiment Reproduction with Paper Lineage
Autoreproduce: Automatic ai experiment reproduction with paper lineage , author=. arXiv preprint arXiv:2505.20662 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration , author=. arXiv preprint arXiv:2605.03042 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
arXiv preprint arXiv:2512.16969 , year=
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows , author=. arXiv preprint arXiv:2512.16969 , year=
-
[31]
arXiv preprint arXiv:2511.14366 , year=
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning , author=. arXiv preprint arXiv:2511.14366 , year=
-
[32]
Kimi K2.5: Visual Agentic Intelligence
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
arXiv preprint arXiv:2602.09132 , year=
SciDataCopilot: An Agentic Data Preparation Framework for AGI-driven Scientific Discovery , author=. arXiv preprint arXiv:2602.09132 , year=
-
[34]
MinerU: An Open-Source Solution for Precise Document Content Extraction
Mineru: An open-source solution for precise document content extraction , author=. arXiv preprint arXiv:2409.18839 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
2026 , howpublished =
Mingxin Yang , title =. 2026 , howpublished =
2026
-
[36]
Towards an AI co-scientist , author=. arXiv preprint arXiv:2502.18864 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
arXiv preprint arXiv:2505.18705 , year=
Ai-researcher: Autonomous scientific innovation , author=. arXiv preprint arXiv:2505.18705 , year=
-
[38]
2026 , eprint=
InternAgent-1.5: A Unified Agentic Framework for Long-Horizon Autonomous Scientific Discovery , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.