DiffoR: A Unified Continuous Generative Framework for Universal Ordinal Regression
Pith reviewed 2026-06-28 23:36 UTC · model grok-4.3
The pith
Ordinal regression improves when treated as continuous value recovery through diffusion model denoising rather than discrete categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
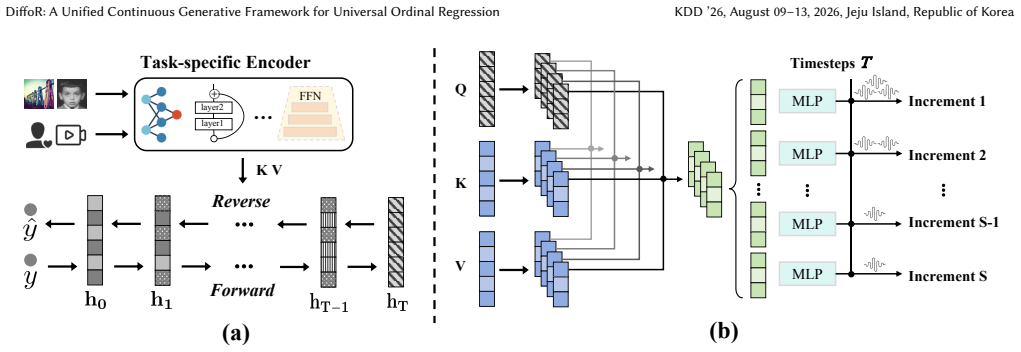
The paper states that ordinal regression can be cast as a Continuous Generative Ordinal Regression task in which diffusion models recover continuous ordinal values through iterative denoising, thereby learning soft semantic transitions, and that a Dual-Decoupling Strategy of Multi-scale Increment Aggregation and Dynamic Denoising Perception preserves ordinal topology, yielding improved representation capability and mechanistic interpretability.
What carries the argument
DiffOR, the diffusion-based framework that performs iterative denoising to recover continuous ordinal values while using Dual-Decoupling Strategy to maintain order topology.
If this is right
- Representation capability for ordinal data improves by modeling soft rather than hard transitions.
- Mechanistic interpretability of the regression process increases through the explicit denoising steps.
- Performance gains appear consistently across twelve benchmarks in four application domains.
- The framework offers a candidate general-purpose method for any ordered prediction problem.
Where Pith is reading between the lines
- The continuous formulation could be tested on ranking or preference-learning tasks where category boundaries are especially unclear.
- Uncertainty estimates might be derived directly from the diffusion trajectory for applications such as medical severity scoring.
- The multi-scale increment idea could be adapted to other ordered data types like time-series with natural progression.
Load-bearing premise
Diffusion models can capture non-stationary semantic transitions in ordinal data without rigid boundaries and the dual-decoupling strategy can preserve ordinal topology.
What would settle it
On the same 12 benchmarks, if DiffOR shows no consistent reduction in mean absolute error or increase in ordered accuracy relative to discretization-based or classification-based ordinal regression baselines.
Figures

read the original abstract
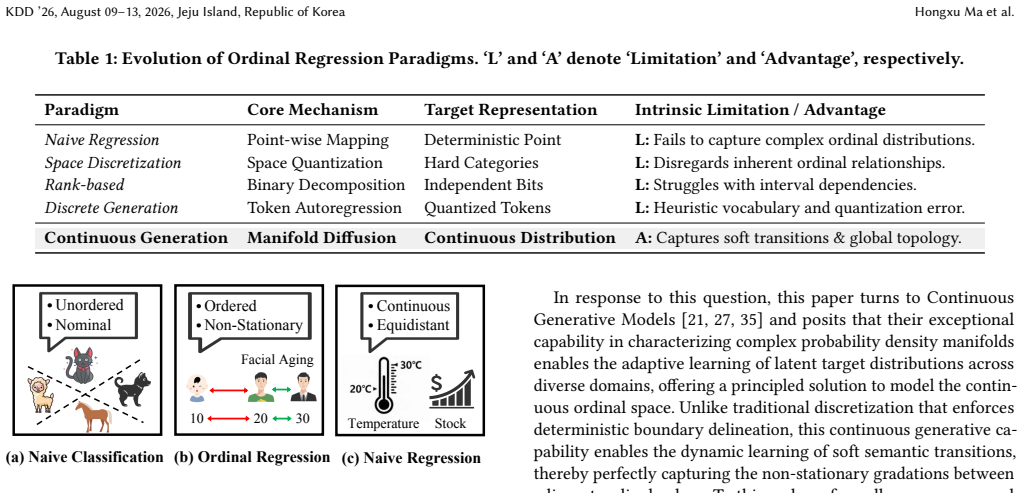
Ordinal Regression (OR) aims to predict target values with inherent order, underpinning critical applications across diverse domains, from recommender systems to computer vision. Though having evolved from naive regression to discretization-based classification and generation, existing paradigms remain fundamentally constrained by quantization artifacts and the lack of global ordinal topological perception. These methods typically enforce rigid boundary delineations, failing to capture the non-stationary semantic transitions inherent to ordinal data. In this paper, we propose a novel paradigm where OR is formulated as a Continuous Generative Ordinal Regression task. Under the novel paradigm, we introduce DiffOR, a unified framework that leverages diffusion models to recover continuous ordinal values via iterative denoising, thereby enabling the dynamic learning of soft semantic transitions. To explicitly preserve ordinal topology, we devise a Dual-Decoupling Strategy: Spatially, Multi-scale Increment Aggregation decomposes targets into hierarchical continuous increments; Temporally, Dynamic Denoising Perception synchronizes denoising steps with feature frequencies, ensuring robust coarse-to-fine refinement. Theoretically, we show that the proposed method can significantly enhance both representation capability and mechanistic interpretability. Extensive experiments on 12 benchmarks across four domains validate DiffOR's consistent superiority over state-of-the-art methods, establishing a new standard that demonstrates strong potential as a general-purpose solution for universal ordinal regression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes reformulating ordinal regression (OR) as a Continuous Generative Ordinal Regression task and introduces DiffOR, a unified diffusion-based framework that recovers continuous ordinal values via iterative denoising to enable dynamic learning of soft semantic transitions. It devises a Dual-Decoupling Strategy consisting of Multi-scale Increment Aggregation (spatial decomposition into hierarchical increments) and Dynamic Denoising Perception (temporal synchronization of denoising steps with feature frequencies). The authors claim theoretical improvements in representation capability and mechanistic interpretability, supported by experiments showing consistent superiority over SOTA methods on 12 benchmarks across four domains.
Significance. If the central claims hold, the work is significant in offering a generative paradigm that addresses quantization artifacts and rigid boundaries in prior OR approaches, potentially enabling better handling of non-stationary semantic transitions and serving as a general-purpose solution for universal ordinal regression.
minor comments (1)
- [Abstract] Abstract: the claim of 'theoretical' enhancements in representation and interpretability should be tied explicitly to a numbered section or equation in the full manuscript for verifiability.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the work's potential significance, and recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, derivations, or load-bearing steps that reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains. The central claim is a reformulation of ordinal regression as continuous generative modeling via diffusion, with a Dual-Decoupling Strategy presented as an architectural choice; these are presented as novel contributions without any quoted reduction to prior inputs or tautological definitions within the given text. No uniqueness theorems, ansatzes smuggled via citation, or renaming of known results are exhibited. The derivation chain is therefore self-contained against external benchmarks on the basis of the supplied material.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[2]
Bor-Chun Chen, Chu-Song Chen, and Winston H Hsu. 2014. Cross-age reference coding for age-invariant face recognition and retrieval. InComputer Vision–ECCV 2014
2014
- [3]
-
[4]
Shixing Chen, Caojin Zhang, Ming Dong, et al. 2017. Using ranking-CNN for age estimation. InProceedings of the IEEE conference on computer vision and pattern recognition
2017
-
[5]
Xiaokai Chen, Xiao Lin, Changcheng Li, and Peng Jiang. 2025. Personalized Tree-Based Progressive Regression Model for Watch-Time Prediction in Short Video Recommendation. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5609–5616
2025
-
[6]
Raul Diaz and Amit Marathe. 2019. Soft labels for ordinal regression. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4738–4747
2019
-
[7]
Raul Diaz and Amit Marathe. 2019. Soft labels for ordinal regression. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
2019
-
[8]
Anders Drachen, Mari Pastor, Aron Liu, Dylan Jack Fontaine, Yuan Chang, Julian Runge, Rafet Sifa, and Diego Klabjan. 2018. To be or not to be... social: Incorpo- rating simple social features in mobile game customer lifetime value predictions. InProceedings of the Australasian Computer Science Week Multiconference
2018
-
[9]
Yao Du, Qiang Zhai, Weihang Dai, and Xiaomeng Li. 2024. Teach clip to develop a number sense for ordinal regression. InEuropean Conference on Computer Vision. Springer, 1–17
2024
-
[10]
Yuming Fang, Hanwei Zhu, Yan Zeng, Kede Ma, and Zhou Wang. 2020. Perceptual quality assessment of smartphone photography. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
2020
-
[11]
Yue Feng, Jinwei Hu, Qijia Lu, Jiawei Niu, Li Tan, Shuo Yuan, Ziyi Yan, Yizhen Jia, Qingzhi He, Shiping Ge, et al . 2026. MUVR: A Multi-Modal Untrimmed Video Retrieval Benchmark with Multi-Level Visual Correspondence.Advances in Neural Information Processing Systems38 (2026)
2026
-
[12]
Bin-Bin Gao, Chao Xing, Chen-Wei Xie, Jianxin Wu, and Xin Geng. 2017. Deep label distribution learning with label ambiguity.IEEE Transactions on Image Processing(2017)
2017
-
[13]
Chongming Gao, Shijun Li, Wenqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, and Tat-Seng Chua. 2022. KuaiRec: A fully-observed KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Hongxu Ma et al. dataset and insights for evaluating recommender systems. InProceedings of the 31st ACM International Conference on Information & K...
2022
-
[14]
Chongming Gao, Shijun Li, Yuan Zhang, Jiawei Chen, Biao Li, Wenqiang Lei, Peng Jiang, and Xiangnan He. 2022. Kuairand: An unbiased sequential recom- mendation dataset with randomly exposed videos. InProceedings of the 31st ACM international conference on information & knowledge management. 3953–3957
2022
-
[15]
Fei Gao, Yuhao Lin, Jiaqi Shi, Maoying Qiao, and Nannan Wang. 2024. AesMamba: Universal Image Aesthetic Assessment with State Space Models. InProceedings of the 32nd ACM International Conference on Multimedia
2024
- [16]
-
[17]
Xizewen Han, Huangjie Zheng, and Mingyuan Zhou. 2022. Card: Classification and regression diffusion models.Advances in Neural Information Processing Systems35 (2022), 18100–18115
2022
-
[18]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition
2016
-
[19]
Shuai He, Anlong Ming, Yaqi Li, Jinyuan Sun, ShunTian Zheng, and Huadong Ma. 2023. Thinking image color aesthetics assessment: Models, datasets and benchmarks. InProceedings of the IEEE/CVF International Conference on Computer Vision
2023
-
[20]
Shuai He, Yongchang Zhang, Rui Xie, Dongxiang Jiang, and Anlong Ming. 2022. Rethinking Image Aesthetics Assessment: Models, Datasets and Benchmarks.. In IJCAI
2022
-
[21]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[22]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems(2020)
2020
-
[23]
Vlad Hosu, Bastian Goldlucke, and Dietmar Saupe. 2019. Effective aesthetics pre- diction with multi-level spatially pooled features. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
2019
-
[24]
Chenghou Jin, Yixin Ren, Hongxu Ma, Yewei Xia, Yi Guan, Hao Zhang, Jiandong Ding, Jihong Guan, and Shuigeng Zhou. 2026. Invariant Feature Learning for Counterfactual Watch-time Prediction in Video Recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 14964–14972
2026
-
[25]
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. 2021. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision
2021
-
[26]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
Shu Kong, Xiaohui Shen, Zhe Lin, Radomir Mech, and Charless Fowlkes. 2016. Photo aesthetics ranking network with attributes and content adaptation. In Computer Vision–ECCV 2016
2016
-
[29]
Lanitis, C.J
A. Lanitis, C.J. Taylor, and T.F. Cootes. 2002. Toward automatic simulation of aging effects on face images.IEEE Transactions on Pattern Analysis and Machine Intelligence(2002)
2002
-
[30]
Kunpeng Li, Guangcui Shao, Naijun Yang, Xiao Fang, and Yang Song. 2022. Billion-user customer lifetime value prediction: an industrial-scale solution from Kuaishou. InProceedings of the 31st ACM International Conference on Information & Knowledge Management
2022
-
[31]
Qiang Li, Jingjing Wang, Zhaoliang Yao, Yachun Li, Pengju Yang, Jingwei Yan, Chunmao Wang, and Shiliang Pu. 2022. Unimodal-concentrated loss: Fully adaptive label distribution learning for ordinal regression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2022
-
[32]
Wanhua Li, Xiaoke Huang, Jiwen Lu, Jianjiang Feng, and Jie Zhou. 2021. Learning probabilistic ordinal embeddings for uncertainty-aware regression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
2021
-
[33]
Wanhua Li, Xiaoke Huang, Zheng Zhu, Yansong Tang, Xiu Li, Jie Zhou, and Jiwen Lu. 2022. Ordinalclip: Learning rank prompts for language-guided ordinal regression.Advances in Neural Information Processing Systems35 (2022), 35313– 35325
2022
-
[34]
Xiao Lin, Xiaokai Chen, Linfeng Song, Jingwei Liu, Biao Li, and Peng Jiang
-
[35]
InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Tree based progressive regression model for watch-time prediction in short-video recommendation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4497–4506
-
[36]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
-
[37]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Wenshuang Liu, Guoqiang Xu, Bada Ye, Xinji Luo, Yancheng He, and Cunxiang Yin. 2024. MDAN: Multi-distribution Adaptive Networks for LTV Prediction. In Pacific-Asia Conference on Knowledge Discovery and Data Mining
2024
-
[39]
Xin Lu, Zhe Lin, Hailin Jin, et al. 2014. Rapid: Rating pictorial aesthetics using deep learning. InProceedings of the 22nd ACM international conference on Multimedia
2014
- [40]
-
[41]
Hongxu Ma, Guanshuo Wang, Fufu Yu, Qiong Jia, and Shouhong Ding. 2025. MS-DETR: Towards Effective Video Moment Retrieval and Highlight Detection by Joint Motion-Semantic Learning. InProceedings of the 33rd ACM International Conference on Multimedia. 4514–4523
2025
-
[42]
Hongxu Ma, Chenbo Zhang, Lu Zhang, Jiaogen Zhou, Jihong Guan, and Shuigeng Zhou. 2025. Fine-grained Zero-shot Object Detection. InProceedings of the 33rd ACM International Conference on Multimedia. 4504–4513
2025
-
[43]
Hongxu Ma, Han Zhou, Kai Tian, Xuefeng Zhang, Chunjie Chen, Han Li, Jihong Guan, and Shuigeng Zhou. 2026. GoR: A Unified and Extensible Generative Framework for Ordinal Regression. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=ys80cc2N5M
2026
-
[44]
Shuang Ma, Jing Liu, and Chang Wen Chen. 2017. A-lamp: Adaptive layout-aware multi-patch deep convolutional neural network for photo aesthetic assessment. InProceedings of the IEEE conference on computer vision and pattern recognition
2017
-
[45]
Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire space multi-task model: An effective approach for estimating post-click conversion rate. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval
2018
-
[46]
Naila Murray, Luca Marchesotti, and Florent Perronnin. 2012. AVA: A large-scale database for aesthetic visual analysis. In2012 IEEE conference on computer vision and pattern recognition
2012
-
[48]
Zhenxing Niu, Mo Zhou, Le Wang, Xinbo Gao, and Gang Hua. 2016. Ordinal regression with multiple output cnn for age estimation. InProceedings of the IEEE conference on computer vision and pattern recognition
2016
-
[49]
Hongyu Pan, Hu Han, Shiguang Shan, and Xilin Chen. 2018. Mean-variance loss for deep age estimation from a face. InProceedings of the IEEE conference on computer vision and pattern recognition
2018
-
[50]
Jakub Paplhám, Vojt Franc, et al. 2024. A call to reflect on evaluation practices for age estimation: comparative analysis of the state-of-the-art and a unified benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2024
-
[51]
Jian Ren, Xiaohui Shen, Zhe Lin, Radomir Mech, and David J Foran. 2017. Per- sonalized image aesthetics. InProceedings of the IEEE international conference on computer vision
2017
-
[52]
Karl Ricanek and Tamirat Tesafaye. 2006. Morph: A longitudinal image database of normal adult age-progression. In7th international conference on automatic face and gesture recognition (FGR06)
2006
-
[53]
Rasmus Rothe, Radu Timofte, and Luc Van Gool. 2015. Dex: Deep expectation of apparent age from a single image. InProceedings of the IEEE international conference on computer vision workshops. 10–15
2015
-
[54]
Dongyu She, Yu-Kun Lai, Gaoxiong Yi, and Kun Xu. 2021. Hierarchical layout- aware graph convolutional network for unified aesthetics assessment. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
2021
-
[55]
Kekai Sheng, Weiming Dong, Chongyang Ma, Xing Mei, Feiyue Huang, and Bao-Gang Hu. 2018. Attention-based multi-patch aggregation for image aes- thetic assessment. InProceedings of the 26th ACM international conference on Multimedia
2018
-
[56]
Nyeong-Ho Shin, Seon-Ho Lee, and Chang-Su Kim. 2022. Moving window regression: A novel approach to ordinal regression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
2022
-
[57]
Jie Sun, Zhaoying Ding, Xiaoshuang Chen, Qi Chen, Yincheng Wang, Kaiqiao Zhan, and Ben Wang. 2024. CREAD: A Classification-Restoration Framework with Error Adaptive Discretization for Watch Time Prediction in Video Recom- mender Systems. InProceedings of the AAAI Conference on Artificial Intelligence
2024
-
[58]
Hossein Talebi and Peyman Milanfar. 2018. NIMA: Neural image assessment. IEEE Transactions on Image Processing(2018)
2018
-
[59]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, and Yinxiao Li. 2022. Maxvit: Multi-axis vision transformer. InEuropean conference on computer vision
2022
- [61]
-
[62]
Jinhong Wang, Jintai Chen, Jian Liu, Dongqi Tang, Danny Z Chen, and Jian Wu
-
[63]
arXiv preprint arXiv:2503.00952(2025)
A Survey on Ordinal Regression: Applications, Advances and Prospects. arXiv preprint arXiv:2503.00952(2025)
-
[64]
Jinhong Wang, Yi Cheng, Jintai Chen, TingTing Chen, Danny Chen, and Jian Wu. 2023. Ord2Seq: regarding ordinal regression as label sequence prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision. DiffoR: A Unified Continuous Generative Framework for Universal Ordinal Regression KDD ’26, August 09–13, 2026, Jeju Island, Repub...
2023
-
[65]
Rui Wang, Peipei Li, Huaibo Huang, Chunshui Cao, Ran He, and Zhaofeng He
-
[66]
Learning-to-rank meets language: Boosting language-driven ordering alignment for ordinal classification.Advances in Neural Information Processing Systems36 (2023), 76908–76922
2023
- [67]
-
[68]
Zhe Wang, Yanxin Yin, Jianping Shi, Wei Fang, Hongsheng Li, and Xiaogang Wang. 2017. Zoom-in-net: Deep mining lesions for diabetic retinopathy detection. InInternational conference on medical image computing and computer-assisted intervention. Springer, 267–275
2017
-
[69]
Zi-Han Wang, Lam Nguyen, Zhengyang Zhao, Mengyue Yang, Chengwei Qin, Yujiu Yang, and Linyi Yang. 2026. CreativeBench: Benchmarking and Enhancing Machine Creativity via Self-Evolving Challenges.arXiv preprint arXiv:2603.11863 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [70]
-
[71]
Hongshen Xu, Zihan Wang, Zichen Zhu, Lei Pan, Xingyu Chen, Shuai Fan, Lu Chen, and Kai Yu. 2025. Alignment for Efficient Tool Calling of Large Language Models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 17776–17792. doi:10.18653/v1/2025.emnlp-main.898
-
[72]
Hongshen Xu, Zichen Zhu, Lei Pan, Zihan Wang, Su Zhu, Da Ma, Ruisheng Cao, Lu Chen, and Kai Yu. 2025. Reducing Tool Hallucination via Reliability Alignment. InForty-second International Conference on Machine Learning. https: //openreview.net/forum?id=WeOLZmDXyA
2025
-
[73]
Junwei Xu, Aisi Zheng, Ling Ding, Huangbin Zhang, Zhengwei Deng, Qun Yu, and Xiao-Ping Zhang. 2025. HiLTV: Hierarchical Multi-Distribution Modeling for Lifetime Value Prediction in Online Games. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval
2025
-
[74]
Shentao Yang, Haichuan Yang, Linna Du, Adithya Ganesh, and et al. 2024. SWaT: Statistical Modeling of Video Watch Time through User Behavior Analysis.arXiv preprint arXiv:2408.07759(2024). doi:10.48550/arXiv.2408.07759
-
[75]
Yijun Yang, Huazhu Fu, Angelica I Aviles-Rivero, Carola-Bibiane Schönlieb, and Lei Zhu. 2023. Diffmic: Dual-guidance diffusion network for medical image clas- sification. InInternational conference on medical image computing and computer- assisted intervention. Springer, 95–105
2023
-
[76]
Qinkai Yu, Jianyang Xie, Anh Nguyen, He Zhao, Jiong Zhang, Huazhu Fu, Yitian Zhao, Yalin Zheng, and Yanda Meng. 2024. CLIP-DR: Textual knowledge-guided diabetic retinopathy grading with ranking-aware prompting. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 667–677
2024
-
[77]
Hui Zeng, Zisheng Cao, Lei Zhang, and Alan C Bovik. 2019. A unified probabilistic formulation of image aesthetic assessment.IEEE Transactions on Image Processing (2019)
2019
-
[78]
Ruohan Zhan, Changhua Pei, Qiang Su, Jianfeng Wen, Xueliang Wang, Guanyu Mu, Dong Zheng, Peng Jiang, and Kun Gai. 2022. Deconfounding duration bias in watch-time prediction for video recommendation. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4472–4481
2022
-
[79]
Chenbo Zhang, Bing Huangfu, Hongxu Ma, Jihong Guan, and Shuigeng Zhou
-
[80]
InProceedings of the 33rd ACM International Conference on Multimedia
Multi-modal Prototype Guided Few-shot Object Detection. InProceedings of the 33rd ACM International Conference on Multimedia. 1852–1861
-
[81]
Zhifei Zhang, Yang Song, et al. 2017. Age progression/regression by conditional adversarial autoencoder. InProceedings of the IEEE conference on computer vision and pattern recognition
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.