Reachability and asymptotics of Gaussian Transformer dynamics
Pith reviewed 2026-06-28 23:31 UTC · model grok-4.3
The pith
Gaussian distributions remain exactly Gaussian under mean-field Transformer flows, reducing the dynamics to a finite-dimensional bilinear control system on mean and covariance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For the mean-field Transformer model with self-attention and affine feed-forward layers, Gaussian distributions remain exactly Gaussian along the induced flow. This invariance reduces the infinite-dimensional measure dynamics to a finite-dimensional bilinear control system governing the evolution of the mean and covariance, reformulates the expressive capacity of Transformers as a reachability problem for prescribed Gaussian moments, and reveals a novel connection with Riccati-type equations from classical filtering and control. For time-varying controls, any target Gaussian whose covariance has the same rank as the initial one is reachable in finite time; for constant parameters, explicit s
What carries the argument
The invariance of the Gaussian family under the mean-field Transformer flow, which closes the measure dynamics into a bilinear control system on the mean vector and covariance matrix.
If this is right
- Time-varying controls achieve exact finite-time reachability of any target Gaussian whose covariance matrix has the same rank as the initial one.
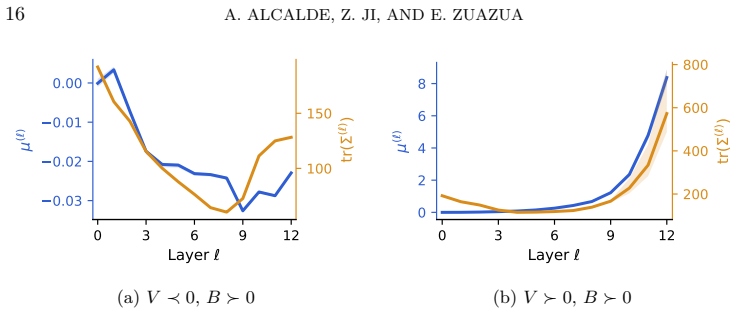
- Time-invariant parameters produce spectral conditions that decide between asymptotic stability to positive-definite equilibria and finite-time covariance blow-up.
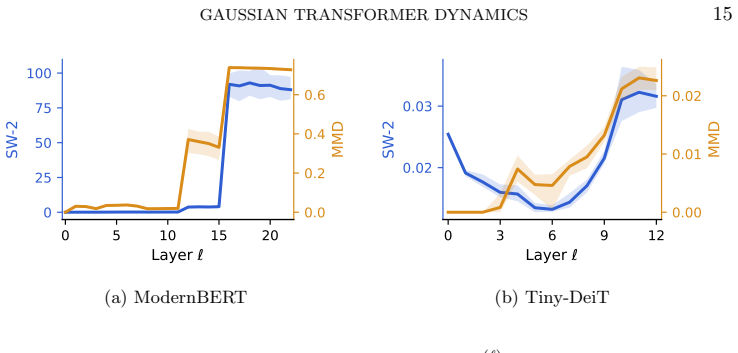
- Practical Transformers with Gaussian inputs remain close to the moment-matched Gaussian prediction through early and intermediate layers.
- Prescribed attention matrices reproduce the predicted regimes of bounded covariance evolution or blow-up.
Where Pith is reading between the lines
- The rank-invariance of the covariance suggests an intrinsic limitation on the linear dependence structure that such models can create or destroy.
- The exact reduction may serve as a tractable surrogate for analyzing training dynamics or generalization when width is large.
- Importing Riccati-based design techniques from control theory could yield new regularization or initialization schemes for attention layers.
Load-bearing premise
The mean-field limit together with quadratic self-attention and affine feed-forward layers preserves Gaussianity exactly.
What would settle it
A finite-width Transformer simulation in which the output distribution for Gaussian inputs deviates measurably from the Gaussian predicted by integrating the mean-covariance ODEs, beyond finite-sample error.
Figures


read the original abstract
We formulate data propagation through the Transformer, the machine learning architecture powering large language models, as a nonlinear control system on the space of probability measures. For the mean-field Transformer model with self-attention and affine feed-forward layers, we prove that Gaussian distributions remain exactly Gaussian along the induced flow. This invariance reduces the infinite-dimensional measure dynamics to a finite-dimensional bilinear control system governing the evolution of the mean and covariance, reformulates the expressive capacity of Transformers as a reachability problem for prescribed Gaussian moments, and reveals a novel connection with Riccati-type equations from classical filtering and control. For time-varying controls, we prove exact finite-time reachability of any target Gaussian distribution whose covariance matrix has the same rank as the initial one, this rank constraint being an intrinsic invariant of the dynamics. For time-invariant parameters, we derive explicit spectral conditions leading either to asymptotic stability toward positive-definite equilibria or to finite-time blow-up of the covariance. Numerical experiments complement the theory by showing that practical Transformers with Gaussian inputs remain close to moment-matched Gaussian distributions through early and intermediate layers, while Transformers with prescribed attention matrices reproduce the predicted covariance regimes: bounded evolution in stabilizing configurations and blow-up in destabilizing ones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates data propagation through Transformers as a nonlinear control system on probability measures. For the mean-field model with self-attention and affine feed-forward layers, it proves that Gaussian distributions remain invariant under the induced flow. This reduces the infinite-dimensional dynamics to a finite-dimensional bilinear control system on the mean and covariance. It establishes finite-time reachability of any target Gaussian whose covariance has the same rank as the initial one (an intrinsic invariant), and derives spectral conditions for asymptotic stability or finite-time blow-up under time-invariant parameters. Numerical experiments show that practical Transformers with Gaussian inputs stay close to moment-matched Gaussians in early layers and reproduce the predicted covariance regimes.
Significance. If the central invariance and reduction hold, the work establishes a rigorous link between Transformer dynamics and classical control/filtering theory (via Riccati structure), recasts expressive capacity as a reachability problem, and provides explicit stability criteria. The exact Gaussian invariance under the stated mean-field assumptions is a strong, parameter-free theoretical result that directly enables the finite-dimensional analysis and reachability theorem.
minor comments (3)
- [Introduction] The introduction would benefit from an explicit statement of the precise functional form of the self-attention map (quadratic in inputs) and the affine feed-forward layers before the invariance proof is invoked, to make the reduction to affine vector fields immediate for readers.
- [Numerical experiments] Figure captions for the numerical experiments should include the precise values of the attention matrices used in the stabilizing and destabilizing regimes, as well as the number of layers simulated, to allow direct reproduction of the bounded vs. blow-up behavior.
- [Reachability theorem] The statement of the rank-invariant in the reachability theorem should be cross-referenced to the explicit evolution equation for the covariance (likely in the section deriving the bilinear system) to clarify why rank is preserved.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation of minor revision. The provided summary accurately captures the core contributions regarding Gaussian invariance, the reduction to a bilinear control system on mean and covariance, reachability results, and stability analysis.
Circularity Check
No significant circularity; derivation is self-contained mathematical proof
full rationale
The paper derives Gaussian invariance under the mean-field Transformer flow directly from the quadratic form of self-attention (output equals mean of exponentially tilted measure) combined with affine feed-forward layers, which together map Gaussians to Gaussians and close the dynamics on mean/covariance. This is a standard invariance argument under the stated functional assumptions, with no fitted parameters renamed as predictions, no self-citation chains supporting the core claim, and no ansatz smuggled via prior work. The reachability and Riccati connections follow as consequences of the reduced bilinear system. The provided abstract and skeptic analysis confirm the result is independent of the target quantities and rests on explicit model assumptions rather than circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Transformer is exactly in the mean-field limit with self-attention quadratic in the inputs and feed-forward layers affine.
- standard math The space of probability measures carries a well-defined nonlinear control system induced by the layer operations.
Reference graph
Works this paper leans on
-
[1]
A Unified Perspective on the Dynamics of Deep Transformers
A Unified Perspective on the Dynamics of Deep Transformers , author=. arXiv preprint arXiv:2501.18322 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2411.04551 , year=
Measure-to-measure interpolation using Transformers , author=. arXiv preprint arXiv:2411.04551 , year=
-
[3]
SIAM Journal on Mathematics of Data Science , volume=
Clustering in pure-attention hardmax transformers and its role in sentiment analysis , author=. SIAM Journal on Mathematics of Data Science , volume=. 2025 , publisher=
2025
-
[4]
Burger, Martin and Kabri, Samira and Korolev, Yury and Roith, Tim and Weigand, Lukas , TITLE =. Philos. Trans. Roy. Soc. A , FJOURNAL =. 2025 , NUMBER =
2025
-
[5]
, TITLE =
Hotz, Anthony and Skelton, Robert E. , TITLE =. Internat. J. Control , FJOURNAL =. 1987 , NUMBER =
1987
-
[6]
Advances in Neural Information Processing Systems , volume=
The emergence of clusters in self-attention dynamics , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
arXiv preprint arXiv:2410.06833 , year=
Dynamic metastability in the self-attention model , author=. arXiv preprint arXiv:2410.06833 , year=
-
[8]
IEEE Trans
Tabuada, Paulo and Gharesifard, Bahman , TITLE =. IEEE Trans. Automat. Control , FJOURNAL =. 2023 , NUMBER =
2023
-
[9]
and Pavon, Michele , TITLE =
Chen, Yongxin and Georgiou, Tryphon T. and Pavon, Michele , TITLE =. IEEE Trans. Automat. Control , FJOURNAL =. 2016 , NUMBER =
2016
-
[10]
2003 , PAGES =
Abou-Kandil, Hisham and Freiling, Gerhard and Ionescu, Vlad and Jank, Gerhard , TITLE =. 2003 , PAGES =
2003
-
[11]
Ruymgaart, P. A. and Soong, T. T. , TITLE =. 1985 , PAGES =
1985
-
[12]
2012 , PAGES =
Teschl, Gerald , TITLE =. 2012 , PAGES =
2012
-
[13]
and Michel, Anthony N
Antsaklis, Panos J. and Michel, Anthony N. , TITLE =. 2006 , PAGES =
2006
-
[14]
2009 , isbn =
Elliott, David , title =. 2009 , isbn =
2009
-
[15]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
Optimal and Diffusion Transports in Machine Learning
Optimal and Diffusion Transports in Machine Learning , author=. arXiv preprint arXiv:2512.06797 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation by jointly learning to align and translate , author=. arXiv preprint arXiv:1409.0473 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[19]
The Thirteenth International Conference on Learning Representations , year=
Emergence of meta-stable clustering in mean-field transformer models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[20]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
A multiscale analysis of mean-field transformers in the moderate interaction regime , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[21]
SIAM Journal on Control and Optimization , volume =
Bianchini, Rosa-Maria and Kawski, Matthias , title =. SIAM Journal on Control and Optimization , volume =. 2003 , doi =
2003
-
[22]
Bulletin of the American Mathematical Society , volume=
A mathematical perspective on transformers , author=. Bulletin of the American Mathematical Society , volume=
-
[23]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics. 2019. doi:10.18653/v1/N19-1423
-
[24]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
nature , volume=
Highly accurate protein structure prediction with AlphaFold , author=. nature , volume=. 2021 , publisher=
2021
-
[26]
Nature , volume=
Accurate structure prediction of biomolecular interactions with AlphaFold 3 , author=. Nature , volume=. 2024 , publisher=
2024
-
[27]
1997 , publisher=
Topology from the differentiable viewpoint , author=. 1997 , publisher=
1997
-
[28]
and Johnson, Charles R
Horn, Roger A. and Johnson, Charles R. , year=. Matrix Analysis , publisher=
-
[29]
Nature , volume=
A foundation model for the Earth system , author=. Nature , volume=. 2025 , publisher=
2025
-
[30]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[31]
Nature , volume=
Probabilistic weather forecasting with machine learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[32]
International Conference on Artificial Intelligence and Statistics , pages=
Sinkformers: Transformers with doubly stochastic attention , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
2022
-
[33]
European conference on computer vision , pages=
End-to-end object detection with transformers , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[34]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Dynamical Properties of Tokens in Self-Attention and Effects of Positional Encoding , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[35]
The Fourteenth International Conference on Learning Representations , year=
Critical attention scaling in long-context transformers , author=. The Fourteenth International Conference on Learning Representations , year=
-
[36]
International Conference on Learning Representations , year=
Are Transformers universal approximators of sequence-to-sequence functions? , author=. International Conference on Learning Representations , year=
-
[37]
The Eleventh International Conference on Learning Representations , year=
Provable Memorization Capacity of Transformers , author=. The Eleventh International Conference on Learning Representations , year=
-
[38]
Mathematical Foundations of Machine Learning , year =
Alcalde, Albert and Fantuzzi, Giovanni and Zuazua, Enrique , title =. Mathematical Foundations of Machine Learning , year =
-
[39]
Advances in Neural Information Processing Systems , editor=
What Can Transformers Learn In-Context? A Case Study of Simple Function Classes , author=. Advances in Neural Information Processing Systems , editor=
-
[40]
Journal of Machine Learning Research , volume=
Trained transformers learn linear models in-context , author=. Journal of Machine Learning Research , volume=
-
[41]
International Conference on Machine Learning , pages=
Mimetic initialization of self-attention layers , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[42]
International Conference on Learning Representations , year=
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation , author=. International Conference on Learning Representations , year=
-
[43]
Proceedings of the 38th International Conference on Machine Learning , pages =
Training data-efficient image transformers & distillation through attention , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , volume =
2021
-
[44]
arXiv preprint arXiv:2603.01514 , year=
Training Dynamics of Softmax Self-Attention: Fast Global Convergence via Preconditioning , author=. arXiv preprint arXiv:2603.01514 , year=
-
[45]
International Conference on Machine Learning , pages=
Transformers learn in-context by gradient descent , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[46]
Multistability of Self-Attention Dynamics in Transformers , year=
Altafini, Claudio , journal=. Multistability of Self-Attention Dynamics in Transformers , year=
-
[47]
Quantifying Concentration Phenomena of Mean-Field Transformers in the Low-Temperature Regime
Quantifying Concentration Phenomena of Mean-Field Transformers in the Low-Temperature Regime , author=. arXiv preprint arXiv:2605.10931 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
arXiv preprint arXiv:2603.09571 , year=
An Optimal Control Approach To Transformer Training , author=. arXiv preprint arXiv:2603.09571 , year=
-
[49]
2009 , publisher=
Optimal transport: old and new , author=. 2009 , publisher=
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.