Query Lens: Interpreting Sparse Key-Value Features with Indirect Effects
Pith reviewed 2026-06-28 19:04 UTC · model grok-4.3
The pith
Query Lens interprets sparse autoencoder features by jointly tracking key activations, value activations, and indirect module effects to produce coherent token signatures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
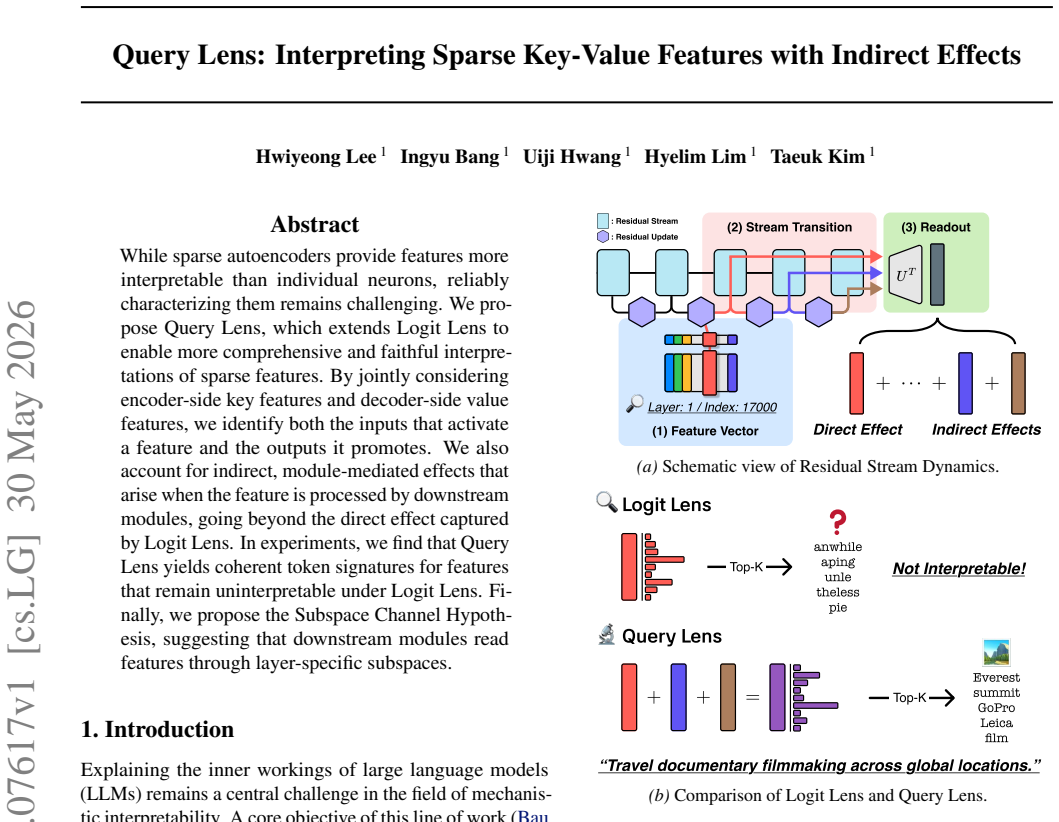
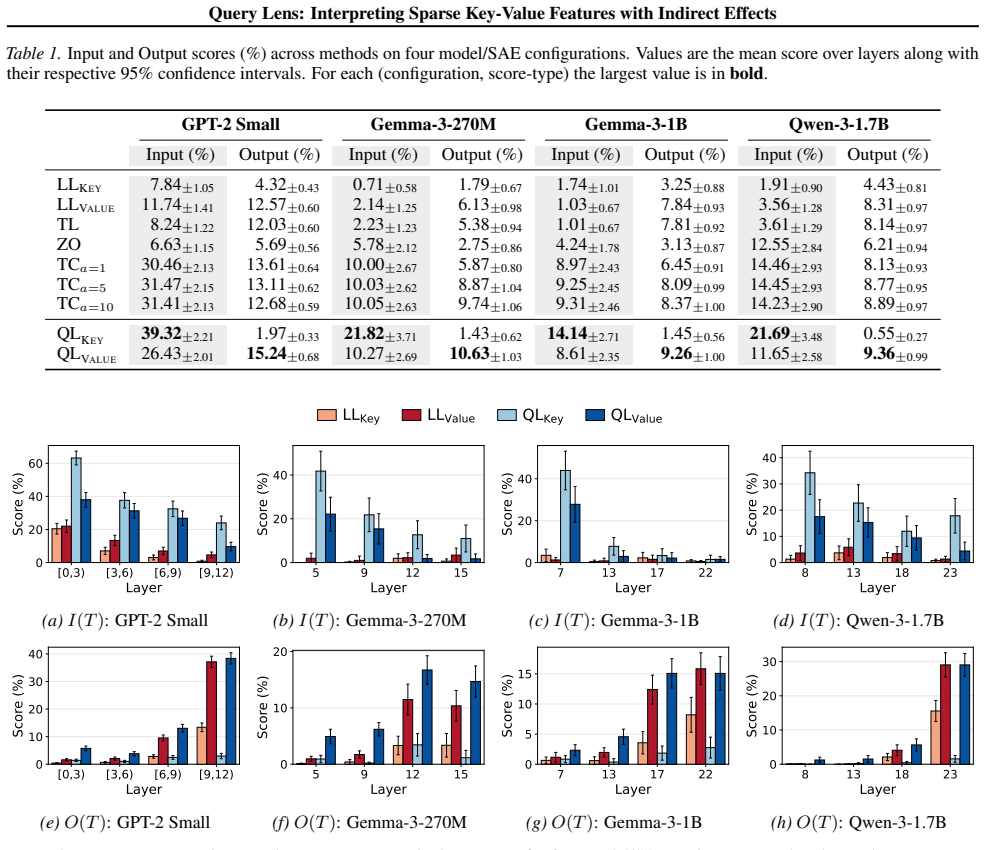
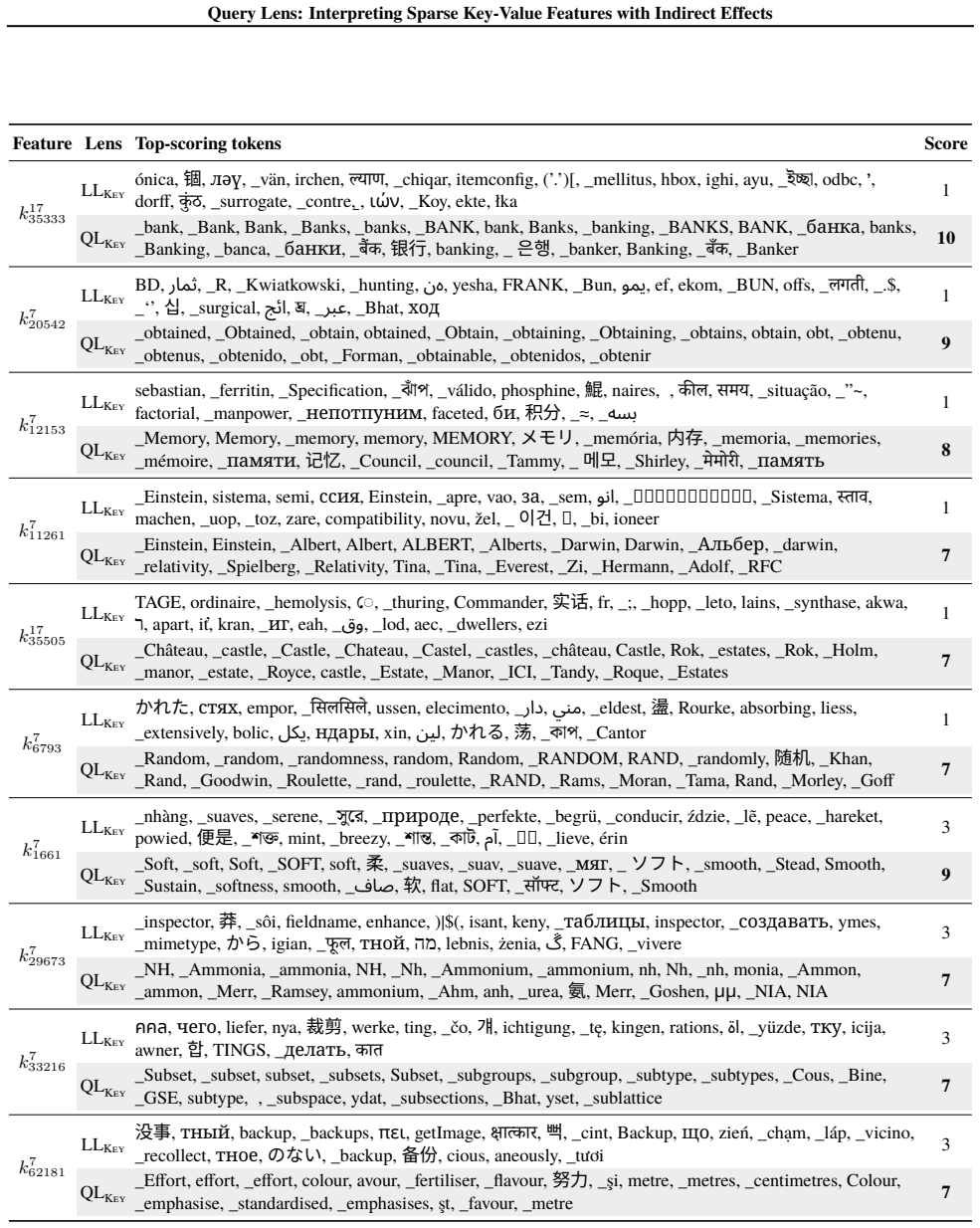
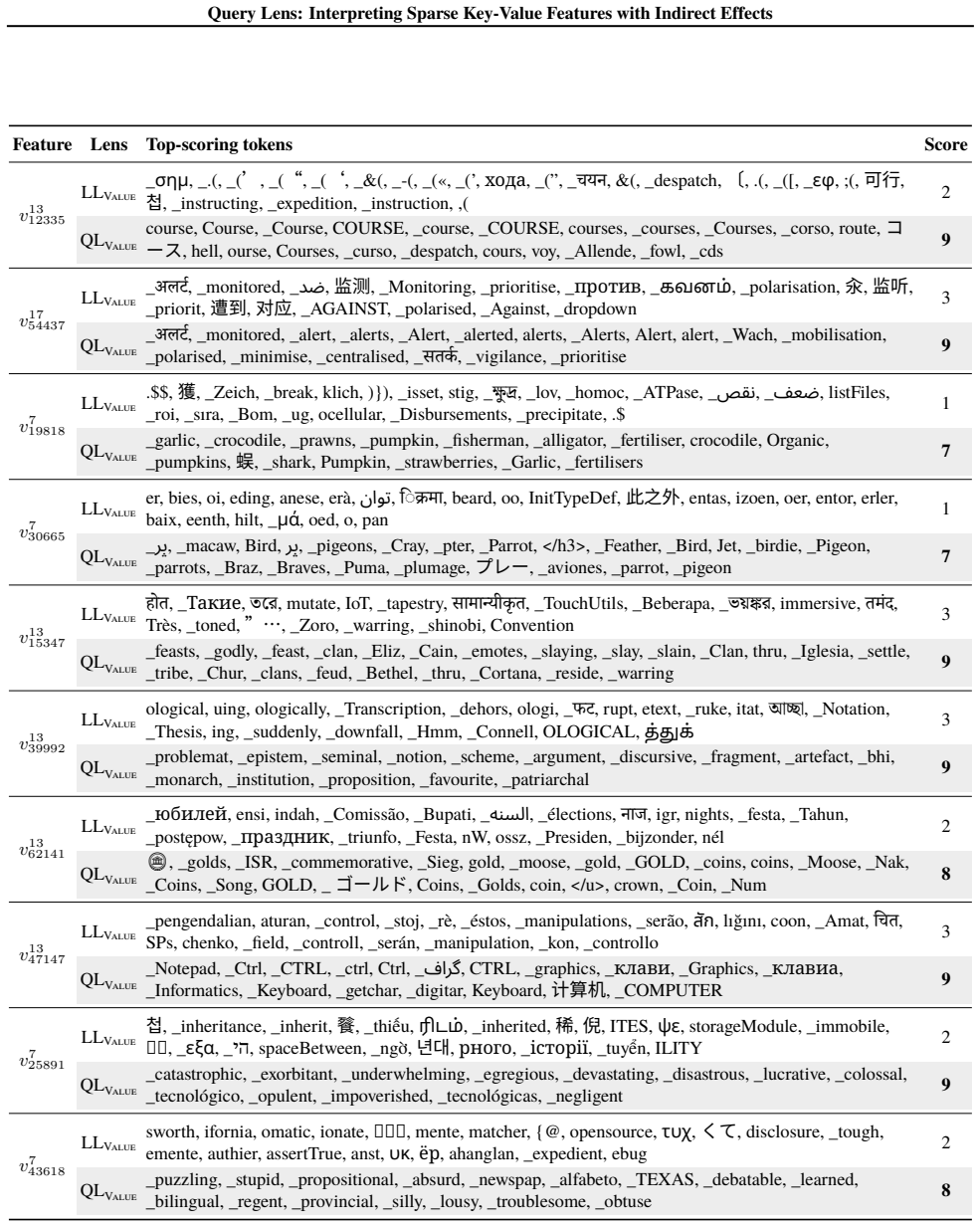
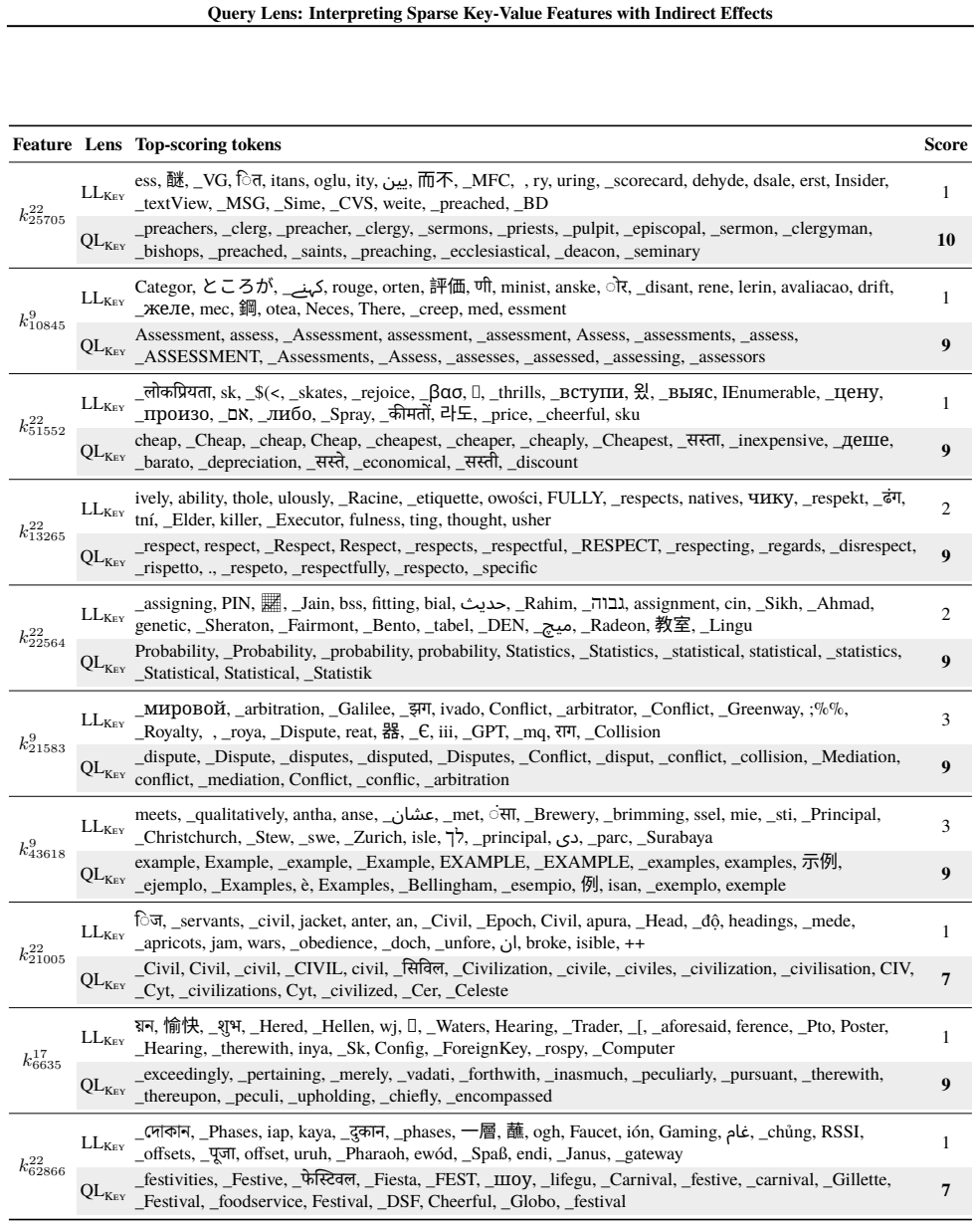
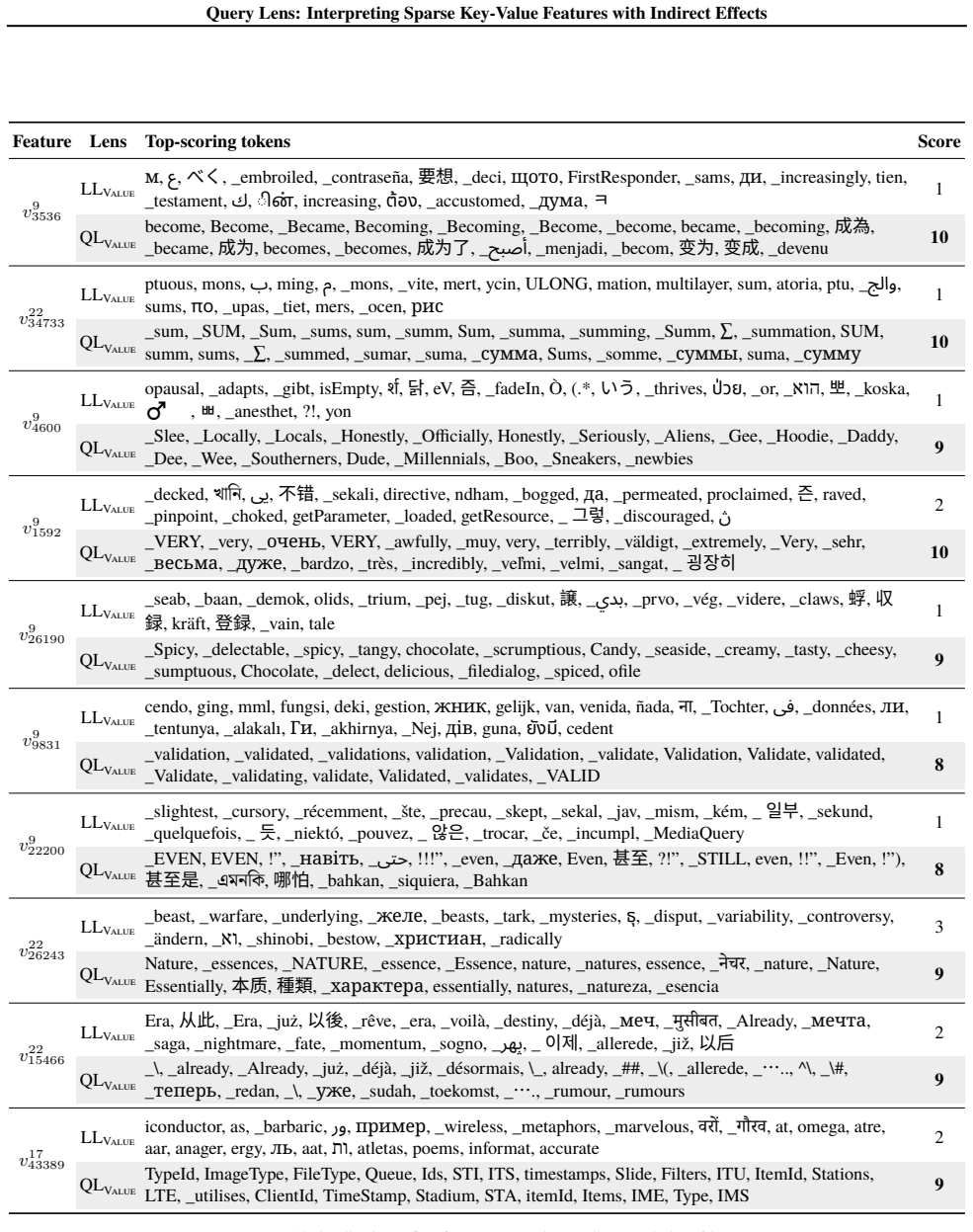
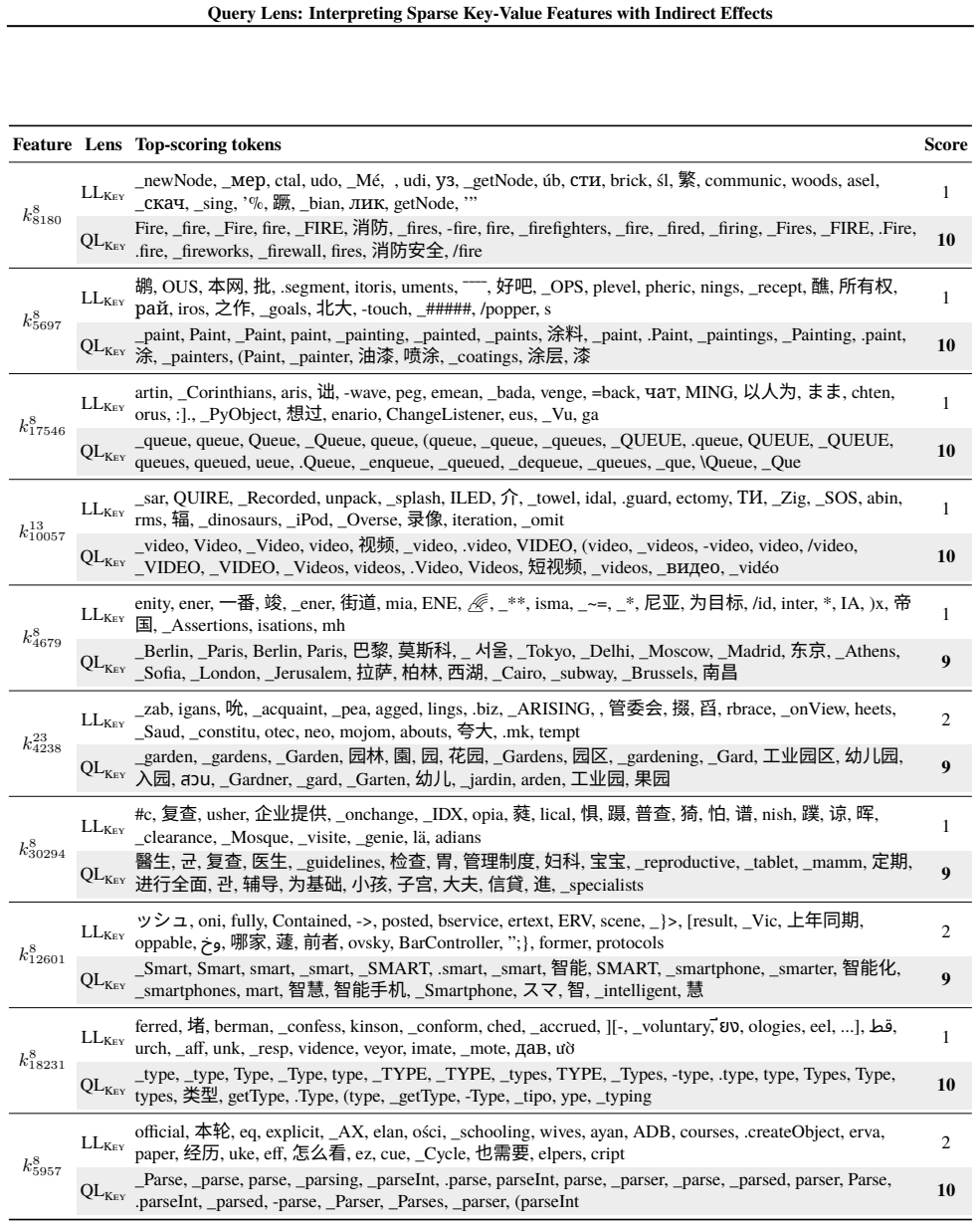
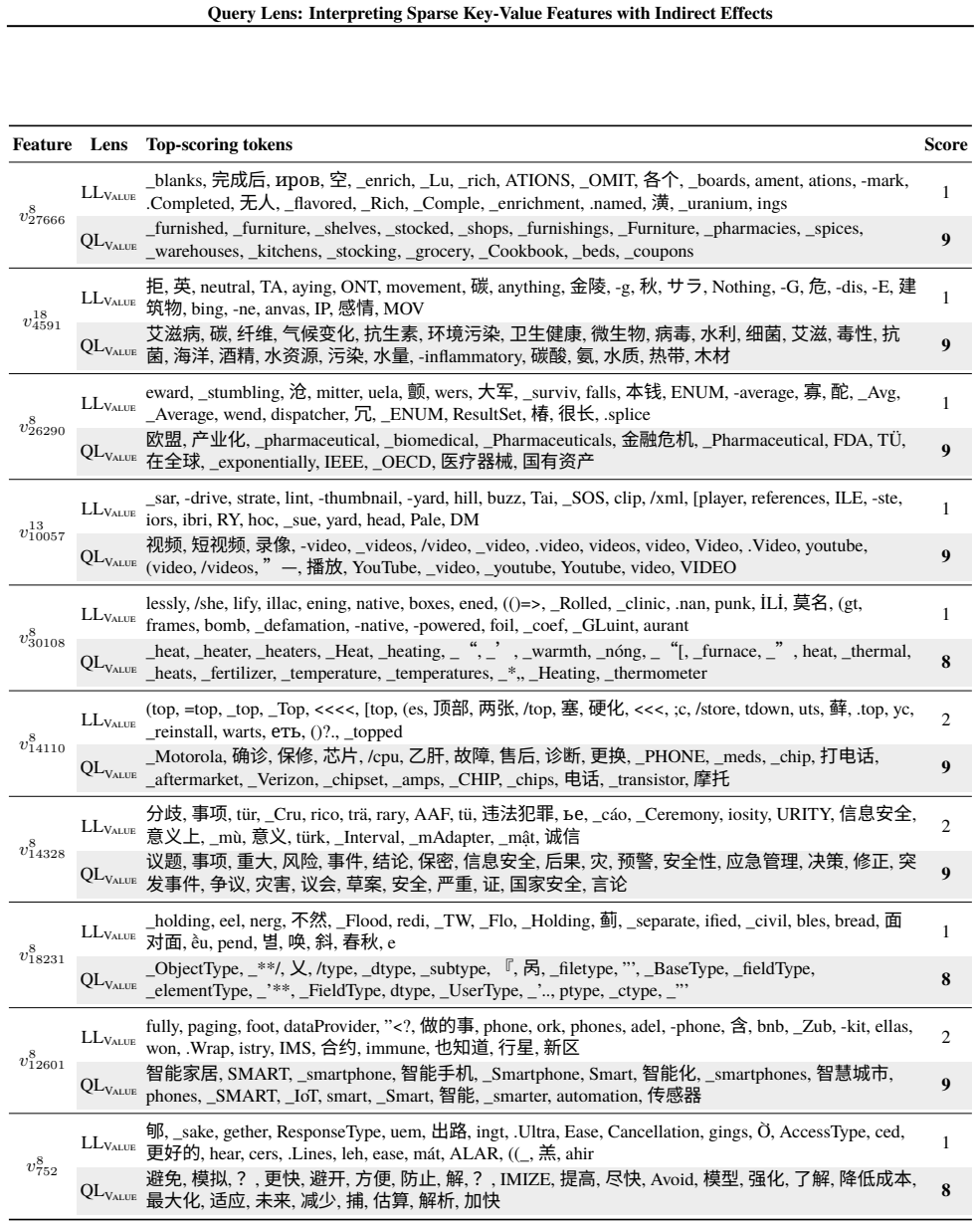
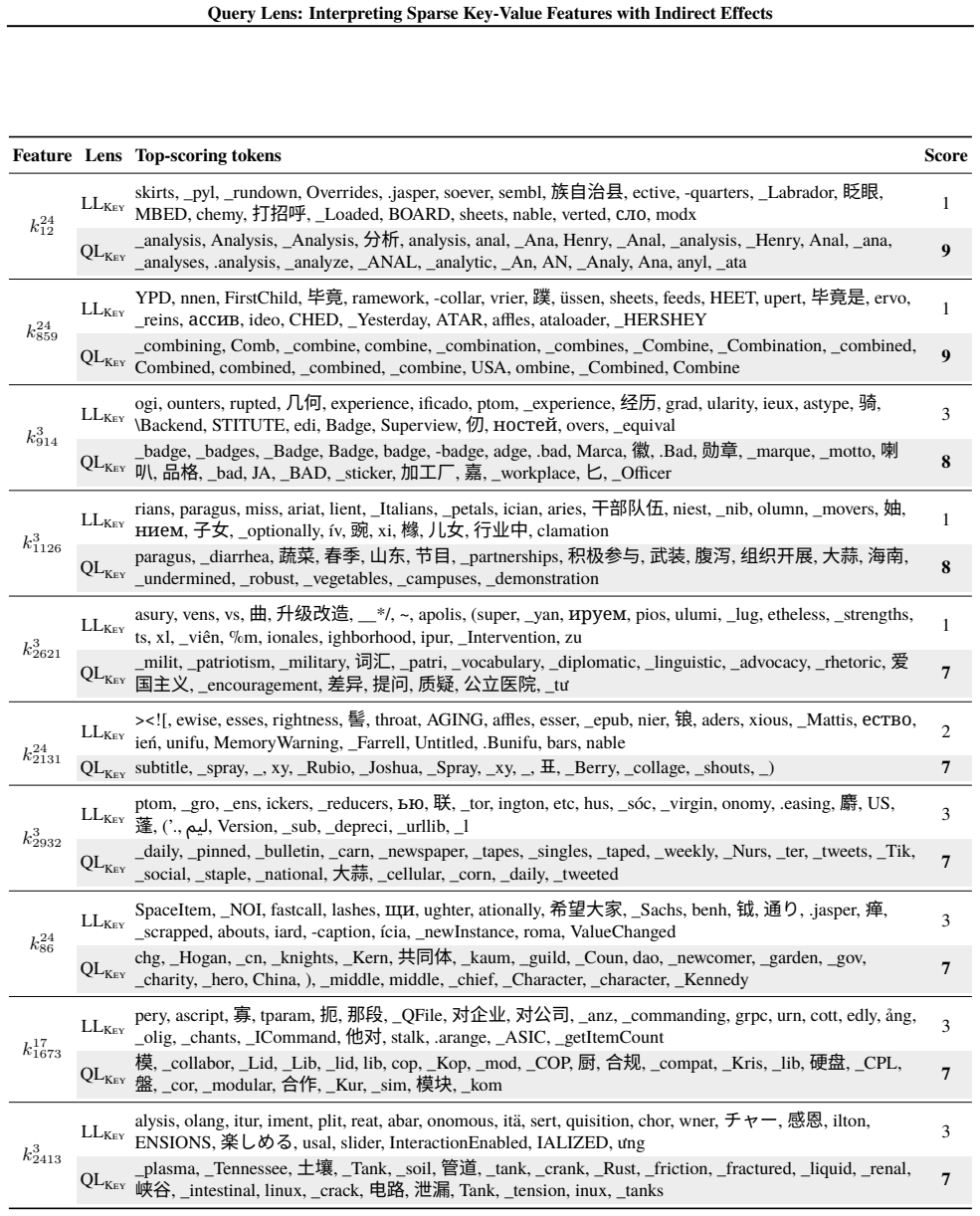
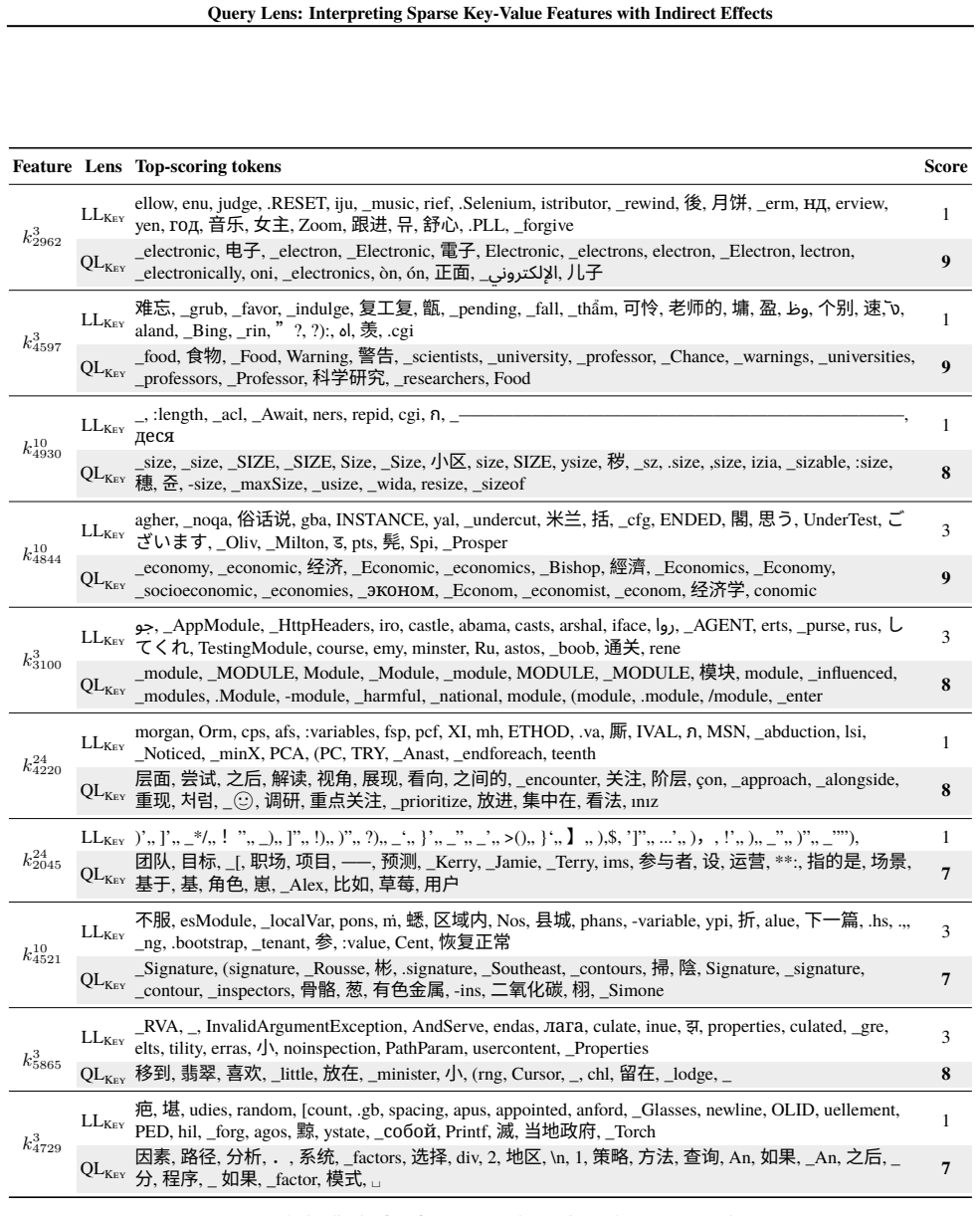
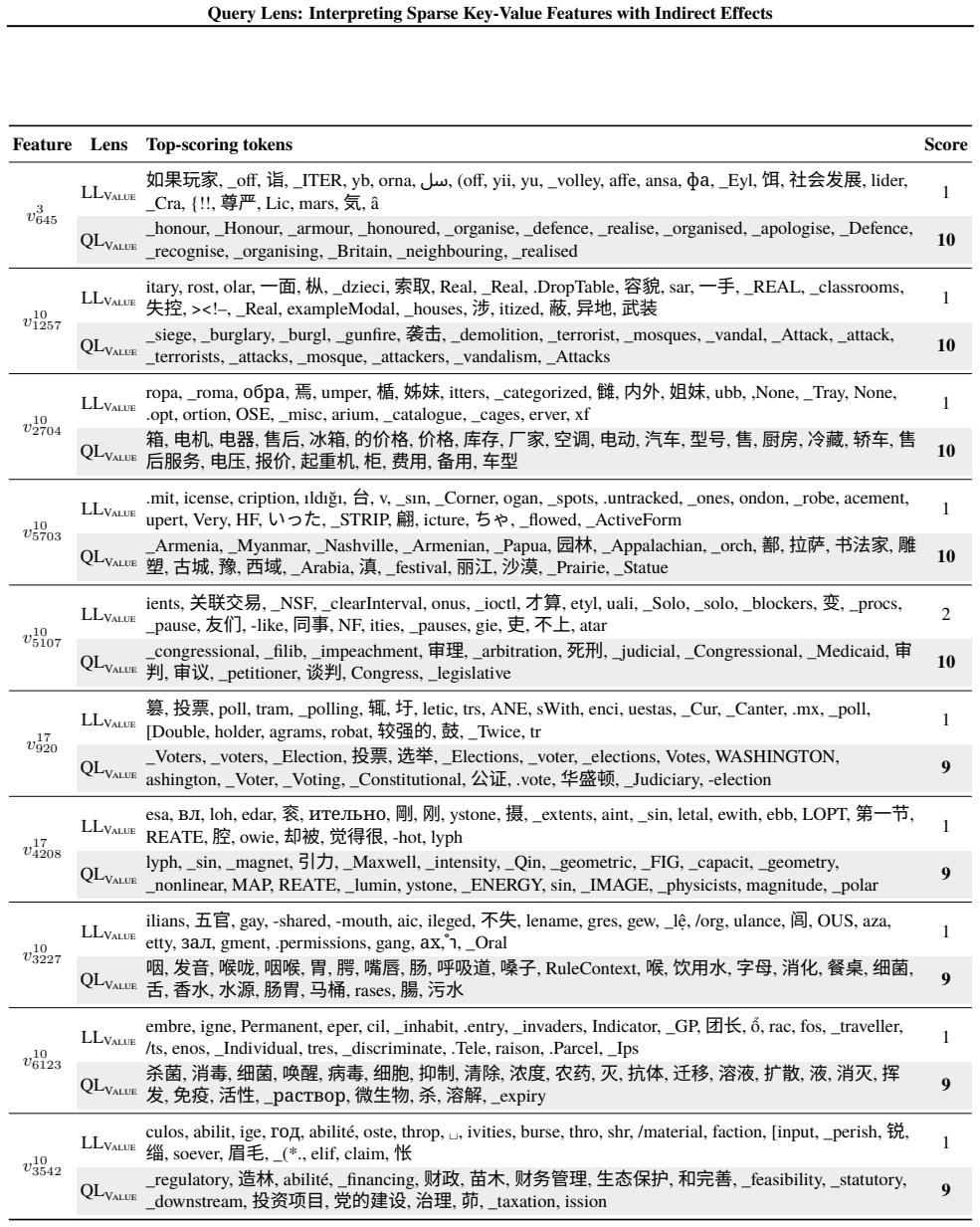
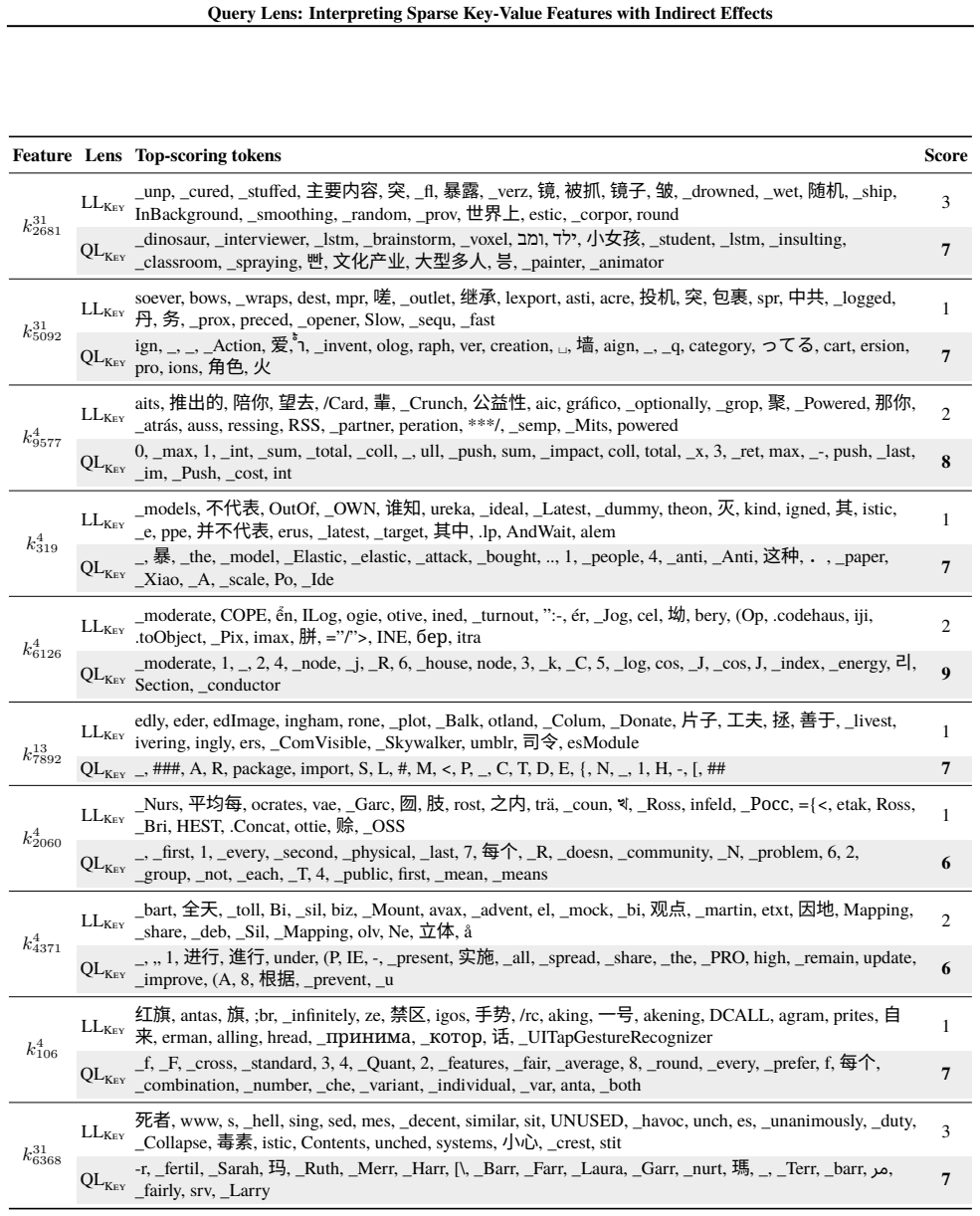
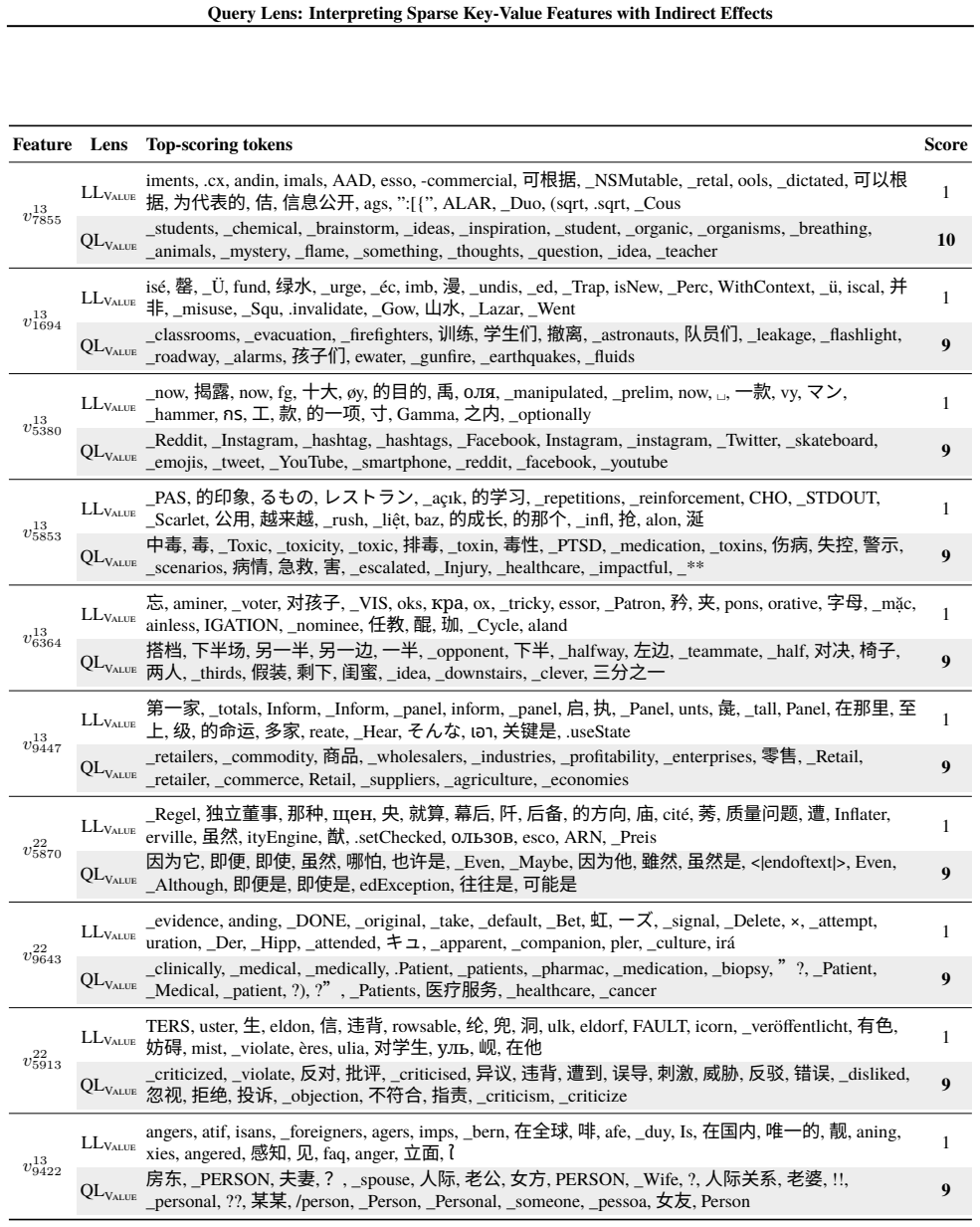
Query Lens extends Logit Lens by jointly considering encoder-side key features and decoder-side value features to identify both the inputs that activate a feature and the outputs it promotes, while also accounting for indirect, module-mediated effects that arise when the feature is processed by downstream modules, yielding coherent token signatures for features that remain uninterpretable under Logit Lens; the paper further proposes the Subspace Channel Hypothesis that downstream modules read features through layer-specific subspaces.
What carries the argument
Query Lens, the method that combines key-feature analysis on the encoder side, value-feature analysis on the decoder side, and indirect-effect tracing through downstream modules to interpret sparse autoencoder features.
If this is right
- Sparse features that previously lacked any readable meaning now acquire consistent input and output token signatures.
- Interpretations of features become more complete by including indirect effects routed through later modules rather than stopping at direct logit contributions.
- The Subspace Channel Hypothesis implies that each layer maintains distinct subspaces through which it reads and writes feature information.
- Downstream modules can be analyzed as selective readers that only respond to particular subspaces of upstream features.
Where Pith is reading between the lines
- The approach could be applied to other sparse decomposition methods beyond autoencoders to check whether the same key-value-plus-indirect pattern improves readability.
- If the Subspace Channel Hypothesis holds, interventions that target layer-specific subspaces might allow more precise editing of model behavior than whole-feature interventions.
- Future work could test whether the indirect effects captured by Query Lens correspond to measurable changes in attention patterns or MLP activations in the layers that follow the feature.
Load-bearing premise
That jointly considering encoder-side key features, decoder-side value features, and module-mediated indirect effects produces interpretations that are both more comprehensive and more faithful than direct-effect methods without the added components introducing their own systematic distortions.
What would settle it
Running Query Lens on the same set of sparse features that Logit Lens leaves uninterpretable and finding no coherent token signatures would falsify the central claim.
Figures

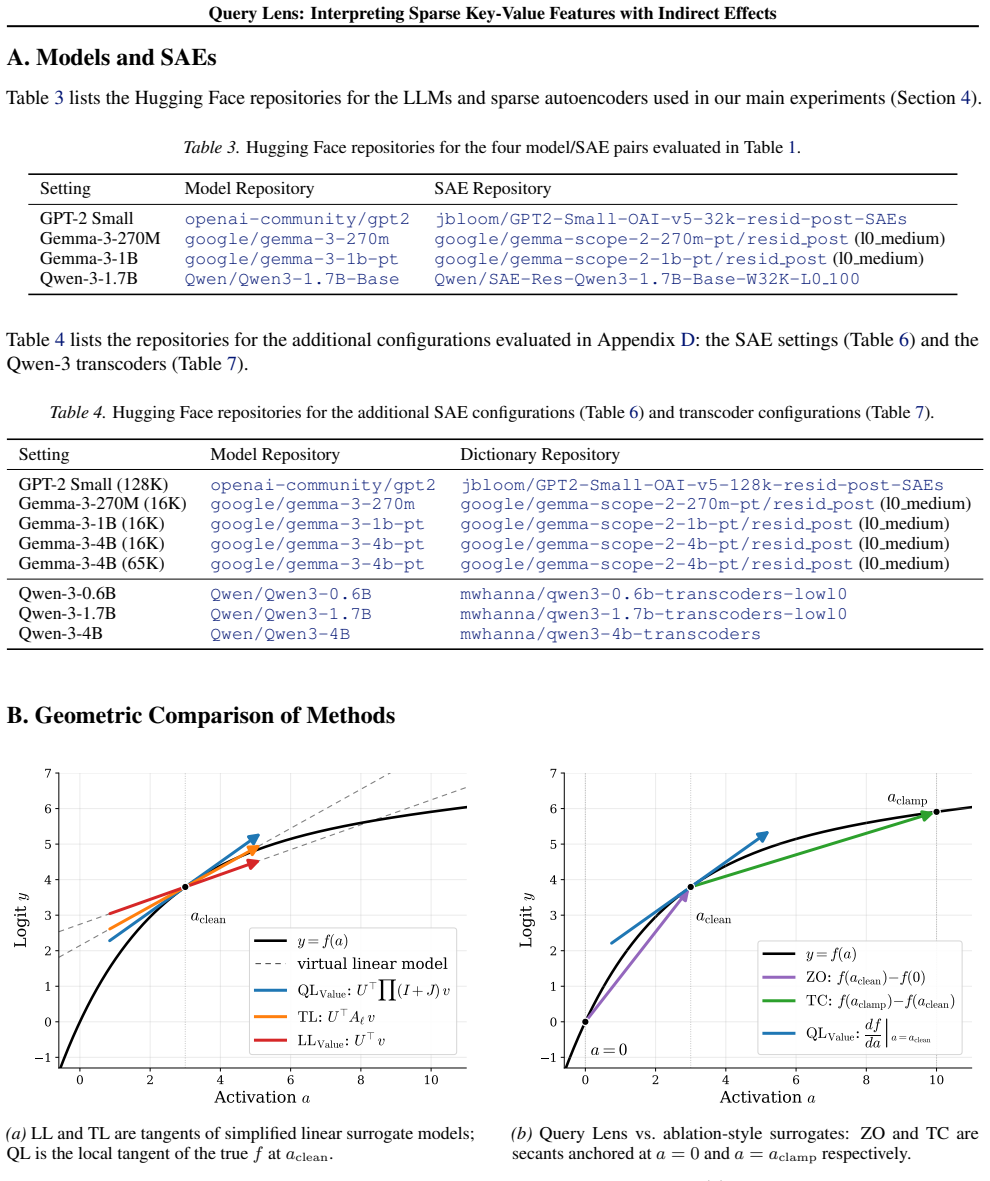
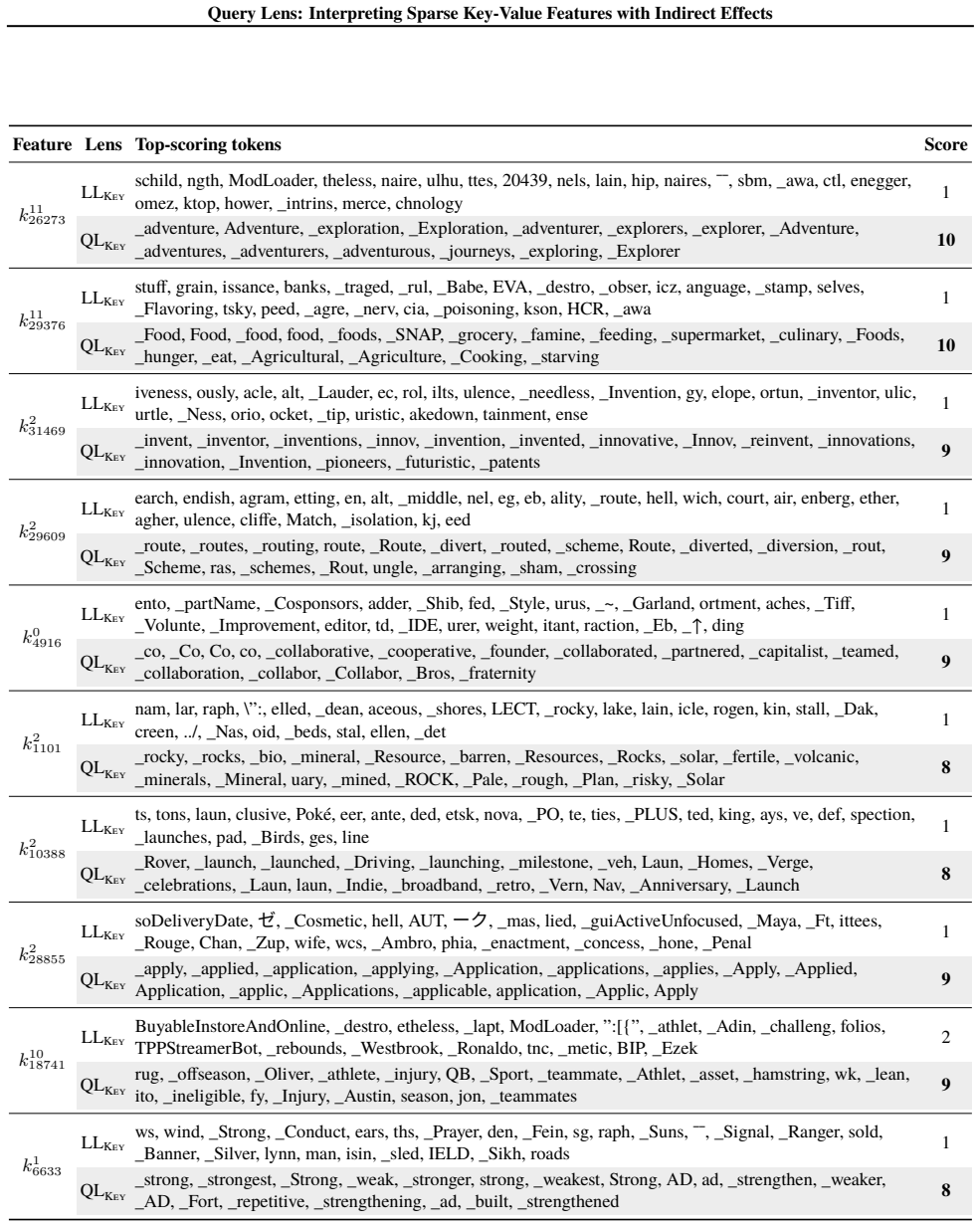

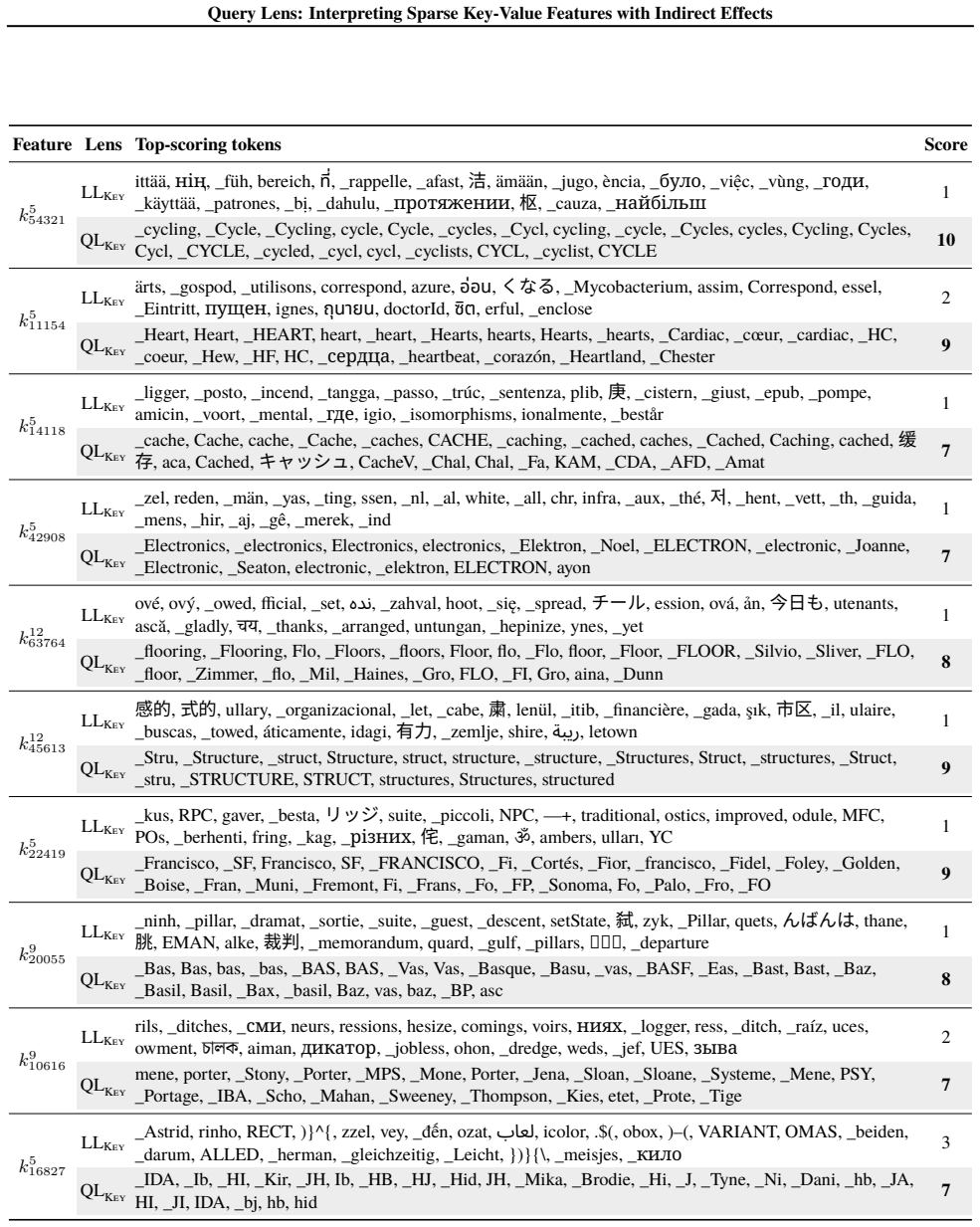
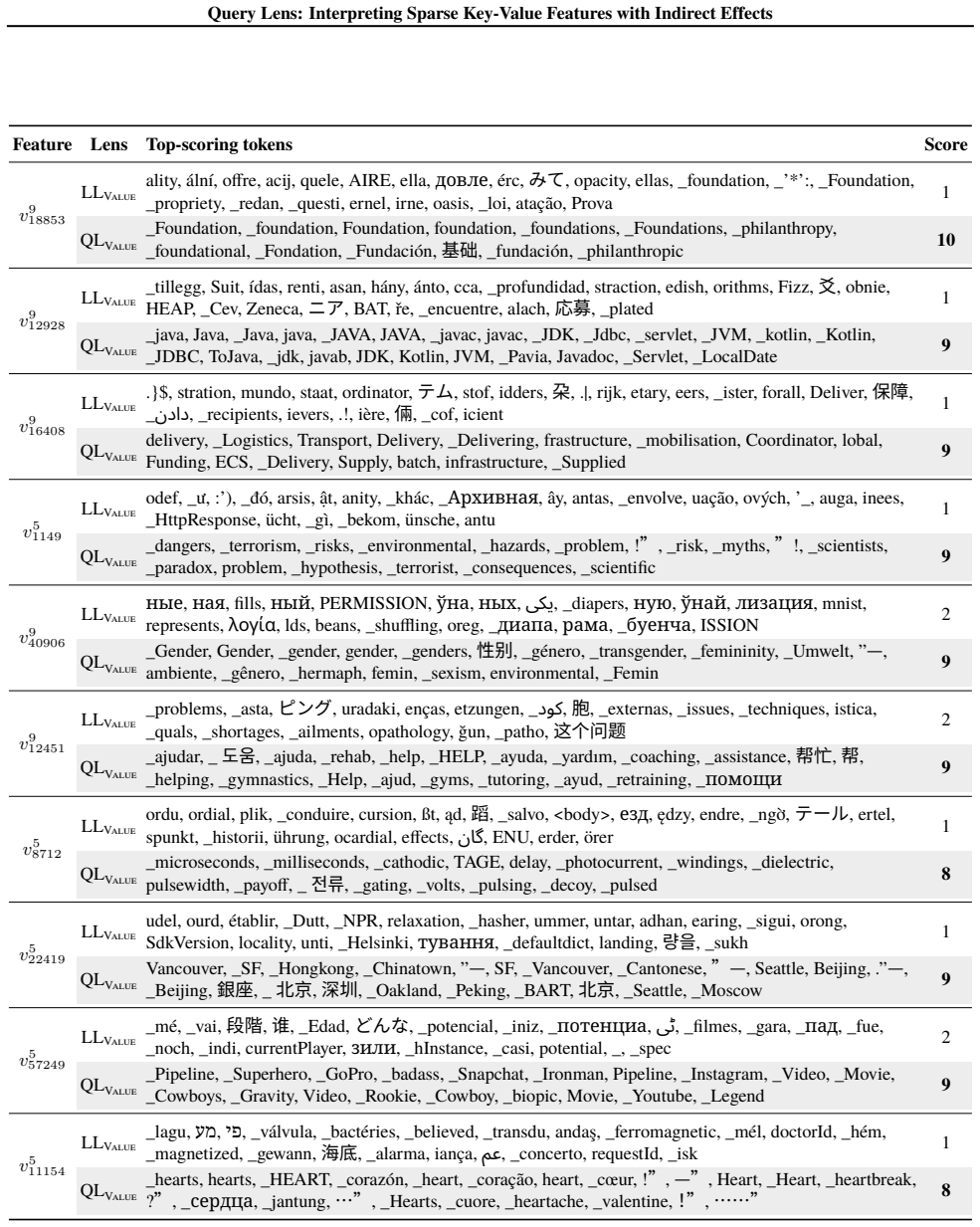

read the original abstract
While sparse autoencoders provide features more interpretable than individual neurons, reliably characterizing them remains challenging. We propose Query Lens, which extends Logit Lens to enable more comprehensive and faithful interpretations of sparse features. By jointly considering encoder-side key features and decoder-side value features, we identify both the inputs that activate a feature and the outputs it promotes. We also account for indirect, module-mediated effects that arise when the feature is processed by downstream modules, going beyond the direct effect captured by Logit Lens. In experiments, we find that Query Lens yields coherent token signatures for features that remain uninterpretable under Logit Lens. Finally, we propose the Subspace Channel Hypothesis, suggesting that downstream modules read features through layer-specific subspaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Query Lens, an extension of Logit Lens for interpreting sparse autoencoder features in transformers. It jointly models encoder-side key features, decoder-side value features, and indirect module-mediated effects to recover coherent token signatures for features uninterpretable under direct-effect methods. The paper reports experimental support for improved coherence and introduces the Subspace Channel Hypothesis, which suggests downstream modules read features via layer-specific subspaces.
Significance. If the experimental claims hold, Query Lens would advance mechanistic interpretability by addressing known limitations of Logit Lens through explicit modeling of indirect effects. The Subspace Channel Hypothesis provides a new conceptual framing that could inform future work on feature subspaces. The method is motivated directly from limitations of prior direct-effect approaches and includes a novel hypothesis as an additional contribution.
major comments (2)
- [Abstract] Abstract: the central claim that 'in experiments, we find that Query Lens yields coherent token signatures for features that remain uninterpretable under Logit Lens' is asserted without any quantitative metrics, ablation results, model/dataset details, or statistical comparisons. This absence is load-bearing because the superiority over Logit Lens cannot be evaluated from the provided evidence.
- [Abstract] Abstract: the Subspace Channel Hypothesis is stated without a formal definition, mathematical formulation, or description of how it would be tested or falsified. If §4 or later sections do not supply a precise statement or empirical protocol, the hypothesis remains too vague to serve as a substantive contribution.
minor comments (2)
- Clarify the precise definition of 'coherent token signatures' and the evaluation protocol used to compare Query Lens against Logit Lens (e.g., human ratings, automated metrics).
- Provide explicit pseudocode or equations for how key features, value features, and indirect effects are combined in the Query Lens computation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight opportunities to strengthen the abstract. We address each point below and will revise the manuscript to better support the central claims with quantitative context and to clarify the Subspace Channel Hypothesis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'in experiments, we find that Query Lens yields coherent token signatures for features that remain uninterpretable under Logit Lens' is asserted without any quantitative metrics, ablation results, model/dataset details, or statistical comparisons. This absence is load-bearing because the superiority over Logit Lens cannot be evaluated from the provided evidence.
Authors: We agree that the abstract, due to space constraints, does not preview the quantitative results. The full manuscript reports these details in Sections 3 and 4, including coherence metrics, direct comparisons and ablations against Logit Lens, model and dataset specifications, and statistical analysis. To address the concern, we will revise the abstract to include a brief summary of the key quantitative findings (e.g., coherence score improvements) while preserving brevity. revision: yes
-
Referee: [Abstract] Abstract: the Subspace Channel Hypothesis is stated without a formal definition, mathematical formulation, or description of how it would be tested or falsified. If §4 or later sections do not supply a precise statement or empirical protocol, the hypothesis remains too vague to serve as a substantive contribution.
Authors: Section 5 of the manuscript introduces the Subspace Channel Hypothesis with an informal definition, a description of the empirical protocol (layer-specific subspace alignment tests), and supporting experimental evidence. We acknowledge that the abstract version is too terse and will revise it to include a concise statement of the hypothesis along with a reference to its testability and empirical support in the main text. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes Query Lens as a methodological extension of Logit Lens that jointly incorporates encoder key features, decoder value features, and indirect module-mediated effects to interpret sparse autoencoder features. No equations, fitted parameters, or derivations appear in the provided abstract or description that reduce any claimed improvement or hypothesis to a self-referential definition, a renamed input, or a self-citation chain. The Subspace Channel Hypothesis is presented as a suggestion arising from experiments rather than an input assumption or uniqueness theorem imported from prior author work. The derivation chain is therefore self-contained and relies on external empirical support rather than internal reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse autoencoders provide features more interpretable than individual neurons
invented entities (1)
-
Subspace Channel Hypothesis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
Transformer Feed-Forward Layers Are Key-Value Memories
Geva, Mor and Schuster, Roei and Berant, Jonathan and Levy, Omer. Transformer Feed-Forward Layers Are Key-Value Memories. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.446
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[10]
Analyzing Transformers in Embedding Space
Dar, Guy and Geva, Mor and Gupta, Ankit and Berant, Jonathan. Analyzing Transformers in Embedding Space. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.893
-
[11]
The Thirteenth International Conference on Learning Representations , year=
Scaling and evaluating sparse autoencoders , author=. The Thirteenth International Conference on Learning Representations , year=
-
[12]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=. 2019 , url=
2019
-
[13]
2024 , eprint=
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders , author=. 2024 , eprint=
2024
-
[14]
Neuronpedia: Interactive Reference and Tooling for Analyzing Neural Networks , year =
-
[15]
2021 , journal=
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
2021
-
[16]
2020 , eprint=
The Pile: An 800GB Dataset of Diverse Text for Language Modeling , author=. 2020 , eprint=
2020
-
[17]
Enhancing Automated Interpretability with Output-Centric Feature Descriptions
Gur-Arieh, Yoav and Mayan, Roy and Agassy, Chen and Geiger, Atticus and Geva, Mor. Enhancing Automated Interpretability with Output-Centric Feature Descriptions. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.288
-
[18]
2024 , journal=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
2024
-
[19]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[20]
2023 , howpublished =
Language models can explain neurons in language models , author=. 2023 , howpublished =
2023
-
[21]
Forty-second International Conference on Machine Learning , year=
Automatically Interpreting Millions of Features in Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[22]
2024 , month =
Choi, Dami and Huang, Vincent and Meng, Kevin and Johnson, Daniel D and Steinhardt, Jacob and Schwettmann, Sarah , title =. 2024 , month =
2024
-
[23]
Deep Feature Interpolation for Image Content Changes , year=
Upchurch, Paul and Gardner, Jacob and Pleiss, Geoff and Pless, Robert and Snavely, Noah and Bala, Kavita and Weinberger, Kilian , booktitle=. Deep Feature Interpolation for Image Content Changes , year=
-
[24]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[25]
2022 , journal=
Toy Models of Superposition , author=. 2022 , journal=
2022
-
[26]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[27]
Bruno A. Olshausen and David J. Field , keywords =. Sparse coding with an overcomplete basis set: A strategy employed by V1? , journal =. 1997 , issn =. doi:https://doi.org/10.1016/S0042-6989(97)00169-7 , url =
-
[28]
Elad, Michael , title =. 2010 , publisher =. doi:10.1007/978-1-4419-7011-4 , url =
-
[29]
The Twelfth International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[30]
Transcoders find interpretable
Jacob Dunefsky and Philippe Chlenski and Neel Nanda , booktitle=. Transcoders find interpretable. 2024 , url=
2024
-
[31]
International Conference on Learning Representations , year=
Identifying and Controlling Important Neurons in Neural Machine Translation , author=. International Conference on Learning Representations , year=
-
[32]
2021 , eprint=
Compositional Explanations of Neurons , author=. 2021 , eprint=
2021
-
[33]
Knowledge Neurons in Pretrained Transformers
Dai, Damai and Dong, Li and Hao, Yaru and Sui, Zhifang and Chang, Baobao and Wei, Furu. Knowledge Neurons in Pretrained Transformers. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.581
-
[34]
The Thirteenth International Conference on Learning Representations , year=
The Geometry of Categorical and Hierarchical Concepts in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[35]
Proceedings of the eighth annual conference of the Cognitive Science Society , pages =
Learning distributed representations of concepts , author =. Proceedings of the eighth annual conference of the Cognitive Science Society , pages =. 1986 , organization =
1986
-
[36]
2025 , eprint=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. 2025 , eprint=
2025
-
[37]
interpreting
Nostalgebraist , year=. interpreting
-
[38]
openai.com/index/gpt-5-system-card , year=
GPT-5 System Card , author=. openai.com/index/gpt-5-system-card , year=
-
[39]
2024 , howpublished =
Understanding SAE Features with the Logit Lens , author =. 2024 , howpublished =
2024
-
[40]
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space
Geva, Mor and Caciularu, Avi and Wang, Kevin and Goldberg, Yoav. Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.3
-
[41]
Arad, Dana and Mueller, Aaron and Belinkov, Yonatan. SAE s Are Good for Steering -- If You Select the Right Features. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.519
-
[42]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[43]
2025 , howpublished=
Gemma Scope 2 , author=. 2025 , howpublished=
2025
-
[44]
Backward Lens: Projecting Language Model Gradients into the Vocabulary Space
Katz, Shahar and Belinkov, Yonatan and Geva, Mor and Wolf, Lior. Backward Lens: Projecting Language Model Gradients into the Vocabulary Space. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.142
-
[45]
The Twelfth International Conference on Learning Representations , year=
Linearity of Relation Decoding in Transformer Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[46]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex J Andonian and Yonatan Belinkov , booktitle=. Locating and Editing Factual Associations in. 2022 , url=
2022
-
[47]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[48]
2013 , eprint=
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation , author=. 2013 , eprint=
2013
-
[49]
International Conference on Learning Representations , year=
Categorical Reparameterization with Gumbel-Softmax , author=. International Conference on Learning Representations , year=
-
[50]
Qwen-Scope: Turning Sparse Features into Development Tools for Large Language Models
Boyi Deng and Xu Wang and Yaoning Wang and Yu Wan and Yubo Ma and Baosong Yang and Haoran Wei and Jialong Tang and Huan Lin and Ruize Gao and Tianhao Li and Qian Cao and Xuancheng Ren and Xiaodong Deng and An Yang and Fei Huang and Dayiheng Liu and Jingren Zhou , year=. 2605.11887 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Forty-first International Conference on Machine Learning , year=
Patchscopes: A Unifying Framework for Inspecting Hidden Representations of Language Models , author=. Forty-first International Conference on Machine Learning , year=
-
[52]
The Thirteenth International Conference on Learning Representations , year=
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[53]
Causal Representation Learning Workshop at NeurIPS 2023 , year=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. Causal Representation Learning Workshop at NeurIPS 2023 , year=
2023
-
[54]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Talking Heads: Understanding Inter-Layer Communication in Transformer Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[55]
Causal Learning and Reasoning (CLeaR) , year =
Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations , author =. Causal Learning and Reasoning (CLeaR) , year =
-
[56]
Advances in Neural Information Processing Systems , year =
Refusal in Language Models Is Mediated by a Single Direction , author =. Advances in Neural Information Processing Systems , year =
-
[57]
Future Lens: Anticipating Subsequent Tokens from a Single Hidden State
Pal, Koyena and Sun, Jiuding and Yuan, Andrew and Wallace, Byron and Bau, David. Future Lens: Anticipating Subsequent Tokens from a Single Hidden State. Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL). 2023. doi:10.18653/v1/2023.conll-1.37
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.