SENTRY: Statistical Reliability Analysis of Vision Transformers Under Soft Errors
Pith reviewed 2026-06-28 18:48 UTC · model grok-4.3
The pith
Finite-population sampling bounds Vision Transformer soft-error failure rates within a 1% margin at 99% confidence using only a few thousand injections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
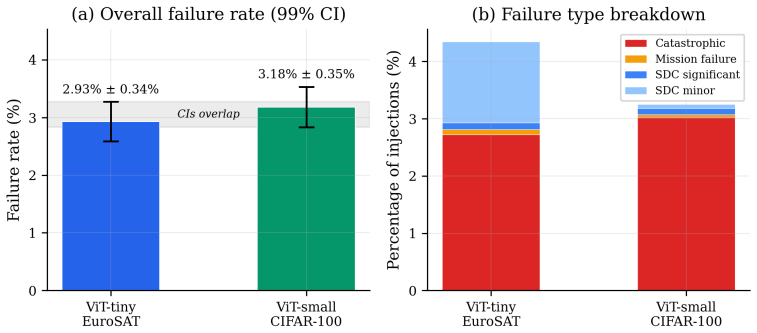
By modeling soft-error possibilities in ViT parameter storage as a finite population and drawing samples according to sampling theory, failure rates can be bounded within a 1% margin at 99% confidence with a few thousand injections; this holds across model scales and delivers up to a 10,700-fold reduction in experimental cost while still permitting localization of vulnerabilities to specific layers and bit positions.
What carries the argument
Finite-population sampling theory applied to fault-injection campaigns on ViT parameters stored in FP32 format.
If this is right
- Reliability statements remain valid when scaling from ViT-Tiny to ViT-Small and beyond.
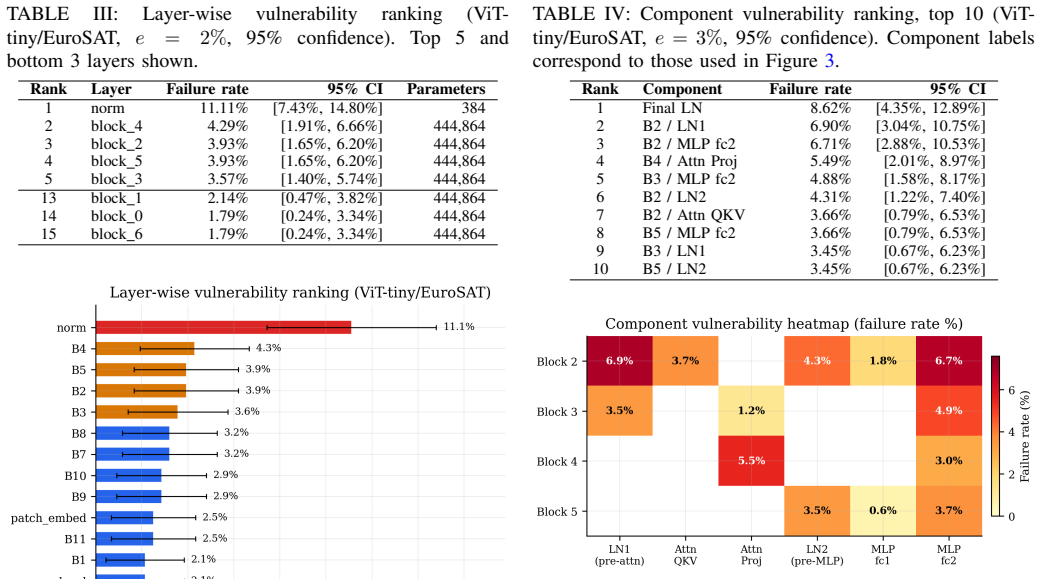
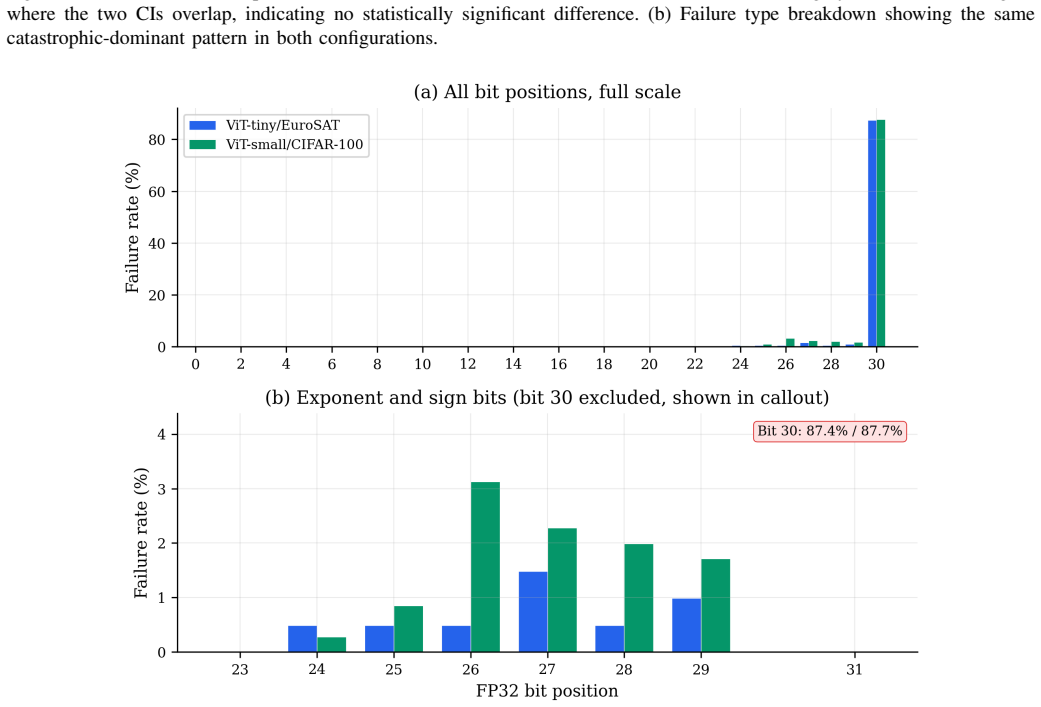
- Only about 3% of FP32 bit-flips produce any failure, yet the great majority of those produce catastrophic accuracy collapse.
- Vulnerabilities concentrate in normalization layers and the exponent bits of the IEEE-754 representation.
- Designers can target hardening effort at the identified layers and bits rather than the entire model.
- The same sampling budget suffices for any model size, removing the need to increase test effort with parameter count.
Where Pith is reading between the lines
- The sampling bounds could be recomputed on-the-fly during edge deployment to adapt to new input distributions.
- Error-correcting codes or selective bit protection could be applied only to the high-impact exponent positions identified by the method.
- The framework might extend to other floating-point formats or quantization schemes used in compressed ViTs.
Load-bearing premise
The space of all possible soft errors in the model parameters forms a finite population to which standard sampling formulas apply directly without systematic bias from architecture or input data.
What would settle it
Run an exhaustive fault-injection campaign on ViT-Tiny, compute the true failure rate, and check whether it lies inside the 1% interval predicted by the sampling procedure at 99% confidence.
Figures

read the original abstract
With the growth of Vision Transformers in safety-critical domains like autonomous systems and medical imaging, ensuring their reliability against soft errors is paramount. While ViTs offer state-of-the-art accuracy, their massive parameter counts render exhaustive fault injection campaigns infeasible. To bridge this gap, a statistical fault injection framework is presented, leveraging finite-population sampling theory to provide formal reliability guarantees. It is demonstrated that failure rates are bounded within a 1% margin at 99\% confidence using only a few thousand samples, regardless of model scale. This methodology achieves up to a 10,700 times reduction in experimental cost compared to exhaustive approaches, while preserving the ability to localize vulnerabilities across architectural components. Through extensive evaluation of different architectures like ViT-Tiny and ViT-Small, a highly non-uniform reliability landscape is uncovered. It is shown that while only 3% of FP32 bit-flips result in failure, the vast majority of these events lead to catastrophic accuracy collapse. Specific vulnerabilities are localized to normalization layers and critical exponent bits within the IEEE-754 format, providing a mathematical foundation and actionable insights for the design of hardened, edge-deployed ViT architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SENTRY, a statistical fault injection framework for Vision Transformers that applies finite-population sampling theory to bound soft-error failure rates within a 1% margin at 99% confidence using only a few thousand samples, independent of model scale. It claims up to 10,700x experimental cost reduction versus exhaustive injection while still localizing vulnerabilities, reports that only 3% of FP32 bit-flips cause failure (yet most of those are catastrophic), and identifies non-uniform sensitivities concentrated in normalization layers and exponent bits.
Significance. If the sampling bounds hold without data-distribution bias, the work would supply a scalable, formally grounded alternative to exhaustive campaigns for reliability assessment of large ViTs in safety-critical settings and would yield concrete architectural hardening targets.
major comments (2)
- [Abstract] Abstract: the claim that standard finite-population sampling delivers unbiased 1% margins at 99% confidence independent of model scale rests on the assumption that each bit-flip has a fixed, architecture- and data-independent failure label; yet failure is defined via accuracy drop on a fixed evaluation set, and the reported non-uniform sensitivities (normalization layers, exponent bits) imply that any shift in input distribution can move the proportion outside the stated bound.
- [Abstract] Abstract: no derivation of the finite-population correction, no validation against exhaustive baselines on even a small ViT, and no error-bar methodology are supplied, so the central 1% margin claim at a few thousand samples cannot be verified from the provided text.
minor comments (1)
- The abstract states results for ViT-Tiny and ViT-Small but does not reference the corresponding sections or tables that contain the per-component vulnerability statistics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our statistical fault injection framework. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that standard finite-population sampling delivers unbiased 1% margins at 99% confidence independent of model scale rests on the assumption that each bit-flip has a fixed, architecture- and data-independent failure label; yet failure is defined via accuracy drop on a fixed evaluation set, and the reported non-uniform sensitivities (normalization layers, exponent bits) imply that any shift in input distribution can move the proportion outside the stated bound.
Authors: The finite-population sampling bounds the failure proportion p for the specific labeling induced by the fixed evaluation set and model under test; this is the standard setup for fault-injection studies. The independence from model scale refers to the number of samples required to achieve the stated margin (via the finite-population correction), not to invariance of p itself. We acknowledge that a change in input distribution could alter p and will add an explicit limitations paragraph clarifying that the reported bounds apply to the evaluation distribution used in the experiments. revision: yes
-
Referee: [Abstract] Abstract: no derivation of the finite-population correction, no validation against exhaustive baselines on even a small ViT, and no error-bar methodology are supplied, so the central 1% margin claim at a few thousand samples cannot be verified from the provided text.
Authors: We agree that the main text should contain an explicit derivation of the finite-population correction, a validation experiment comparing sampling bounds against exhaustive injection on ViT-Tiny, and a description of the error-bar construction. These elements will be added to the revised manuscript (and the abstract updated to reference them). revision: yes
Circularity Check
No circularity; applies external finite-population sampling theory to fault population
full rationale
The derivation applies standard sampling theory (finite-population correction for proportion estimator and confidence bounds) to a defined population of bit-flips. Failure labels are obtained by direct injection and evaluation on a fixed dataset, but the reported bounds and cost-reduction factors are produced by the external statistical formulas rather than by any quantity fitted from the ViT outputs or by self-citation. No self-definitional, fitted-input-renamed-as-prediction, or load-bearing self-citation steps are present. The central claim therefore remains independent of the target ViT data.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Finite-population sampling theory supplies formal reliability bounds when applied to the complete set of possible soft errors in model parameters
Reference graph
Works this paper leans on
-
[1]
M. Taheri, “Phd thesis summary: Methods for reliability assessment and enhancement of deep neural network hardware accelerators,”arXiv preprint arXiv:2603.08724, 2026
-
[2]
Adap- tive fault resilience for early-exit dnns,
R. M. Kodamanchili, N. Cherezova, M. Taheri, and M. Jenihhin, “Adap- tive fault resilience for early-exit dnns,” in2025 IEEE International Test Conference in Asia (ITC-Asia). IEEE, 2025, pp. 108–113
2025
-
[3]
Mix-and-match pruning: Globally guided layer-wise sparsification of dnns,
D. Monachan, S. Nazari, M. Taheri, A. Azarpeyvand, M. Krstic, M. Huebner, and C. Herglotz, “Mix-and-match pruning: Globally guided layer-wise sparsification of dnns,”arXiv preprint arXiv:2603.20280, 2026
-
[4]
Resq: A unified frame- work for reliability-and security enhancement of quantized deep neural networks,
A. S. Mohammadi, S. Nazari, A. Azarpeyvand, M. Taheri, M. Krstic, M. H ¨ubner, C. Herglotz, and T. Ghasempouri, “Resq: A unified frame- work for reliability-and security enhancement of quantized deep neural networks,” in2026 IEEE 27th Latin American Test Symposium (LATS). IEEE, 2026, pp. 1–4
2026
-
[5]
An image is worth 16×16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16×16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[6]
Reliability-aware hyperparameter optimization for ann- to-snn conversion,
S. Sharifian, M. Taheri, V . Rashtchi, A. Azarpeyvand, C. Herglotz, and M. Jenihhin, “Reliability-aware hyperparameter optimization for ann- to-snn conversion,”WiPiEC Journal-Works in Progress in Embedded Computing Journal, vol. 11, no. 1, pp. 7–7, 2025
2025
-
[7]
Genie: Genetic algorithm-based reliability assessment methodology for deep neural networks,
S. Nazari, M. Taheri, A. Azarpeyvand, M. Afsharchi, C. Herglotz, and M. Jenihhin, “Genie: Genetic algorithm-based reliability assessment methodology for deep neural networks,” in2025 11th International Conference on Computing and Artificial Intelligence (ICCAI). IEEE, 2025, pp. 264–271
2025
-
[8]
Reliability-aware performance optimization of dnn hw acceler- ators through heterogeneous quantization,
——, “Reliability-aware performance optimization of dnn hw acceler- ators through heterogeneous quantization,” in2025 IEEE 26th Latin American Test Symposium (LATS). IEEE, 2025, pp. 1–6
2025
-
[9]
Fortune: A negative memory overhead hardware-agnostic fault tolerance technique in dnns,
S. Nazari, M. Taheri, A. Azarpeyvand, M. Afsharchi, T. Ghasempouri, C. Herglotz, M. Daneshtalab, and M. Jenihhin, “Fortune: A negative memory overhead hardware-agnostic fault tolerance technique in dnns,” Authorea Preprints, 2024
2024
-
[10]
Noise-tolerance gpu-based age estimation using resnet-50,
M. Taheri, M. Taheri, and A. Hadjahmadi, “Noise-tolerance gpu-based age estimation using resnet-50,”arXiv preprint arXiv:2305.00848, 2023
-
[11]
Ares: A framework for quantifying the resilience of deep neural networks,
B. Reagen, U. Gupta, L. Pentecost, P. Whatmough, S. K. Lee, N. Mulhol- land, D. Brooks, and G.-Y . Wei, “Ares: A framework for quantifying the resilience of deep neural networks,” inACM/IEEE Design Automation Conference (DAC), 2018, pp. 1–6
2018
-
[12]
Statistical fault injection: Quantified error and confidence,
R. Leveugle, A. Calvez, P. Maistri, and P. Vanhauwaert, “Statistical fault injection: Quantified error and confidence,” inDesign, Automation and Test in Europe Conference (DATE), 2009, pp. 502–506, tIMA Laboratory, Grenoble INP, UJF, CNRS
2009
-
[13]
An effective iterative statistical fault injection methodology for deep neural networks,
A. Ruospo, M. Sonza Reorda, R. Mariani, and E. Sanchez, “An effective iterative statistical fault injection methodology for deep neural networks,”IEEE Transactions on Computers, vol. 74, pp. 2431–2444, 2025
2025
-
[14]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (GELUs),” arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
Radiation-induced soft errors in advanced semiconductor technologies,
R. Baumann, “Radiation-induced soft errors in advanced semiconductor technologies,”IEEE Transactions on Device and Materials Reliability, vol. 5, no. 3, pp. 305–316, 2005
2005
-
[16]
Soft error reliability analysis of vision transformers,
X. Xue, C. Liu, Y . Wang, B. Yang, T. Luo, L. Zhang, H. Li, and X. Li, “Soft error reliability analysis of vision transformers,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 31, no. 12, pp. 2126–2136, 2023
2023
-
[17]
Fine-grained fault sensitivity analysis of vision transformers under soft errors,
J. He, Y . Liu, C. Xu, X. Liao, and Y . Yang, “Fine-grained fault sensitivity analysis of vision transformers under soft errors,”Electronics, vol. 14, p. 2418, 2025
2025
-
[18]
Analyzing and enhancing the reliability of vision transformer models against soft errors,
E.-Y . Liao and T.-C. Wang, “Analyzing and enhancing the reliability of vision transformer models against soft errors,” inIEEE International Symposium on Circuits and Systems (ISCAS), 2025, pp. 1–5
2025
-
[19]
EuroSAT: A novel dataset and deep learning benchmark for land use and land cover classi- fication,
P. Helber, B. Bischke, A. Dengel, and D. Borth, “EuroSAT: A novel dataset and deep learning benchmark for land use and land cover classi- fication,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 12, no. 7, pp. 2217–2226, 2019
2019
-
[20]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” University of Toronto, Tech. Rep., 2009. [Online]. Available: https://www.cs.toronto.edu/∼kriz/learning-features-2009-TR.pdf
2009
-
[21]
PyTorch Image Models,
R. Wightman, “PyTorch Image Models,” GitHub, 2019. [Online]. Available: https://github.com/huggingface/pytorch-image-models
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.