How Much Dense Attention is Necessary? Oracle-Guided Sparse Prefill for Full/GQA Layers in Hybrid Long-Context Models
Pith reviewed 2026-06-27 22:50 UTC · model grok-4.3
The pith
An attention-mass top-k oracle shows sparse prefill preserves Qwen performance within 1 point of dense on retrieval tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
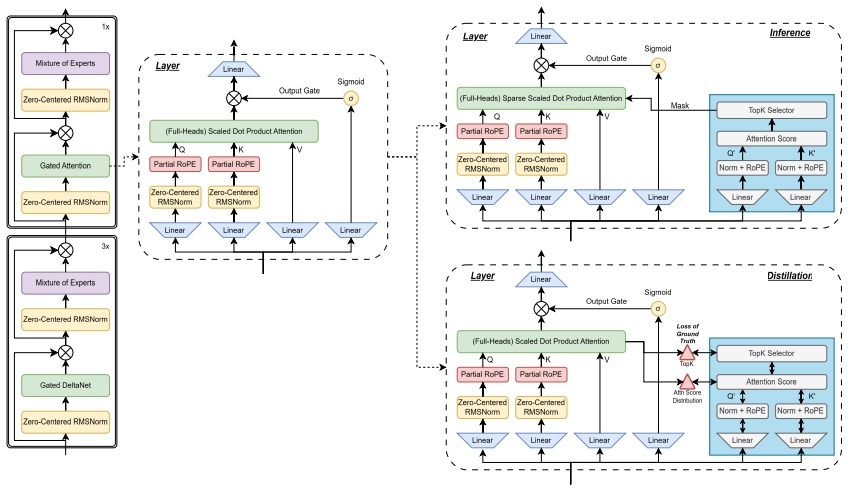
The central discovery is that an attention-mass top-k oracle, which computes dense attention, selects head-averaged token support, and recomputes only on that support, keeps task performance within 1 point of dense on Qwen-family retrieval-heavy evaluations and within 0.48 points on a 4K-to-100K RULER-style sweep for Qwen3.5-9B; a distilled head-collapsed indexer trained by KL from the dense attention-mass distributions then realizes most of that budget while the backbone stays frozen.
What carries the argument
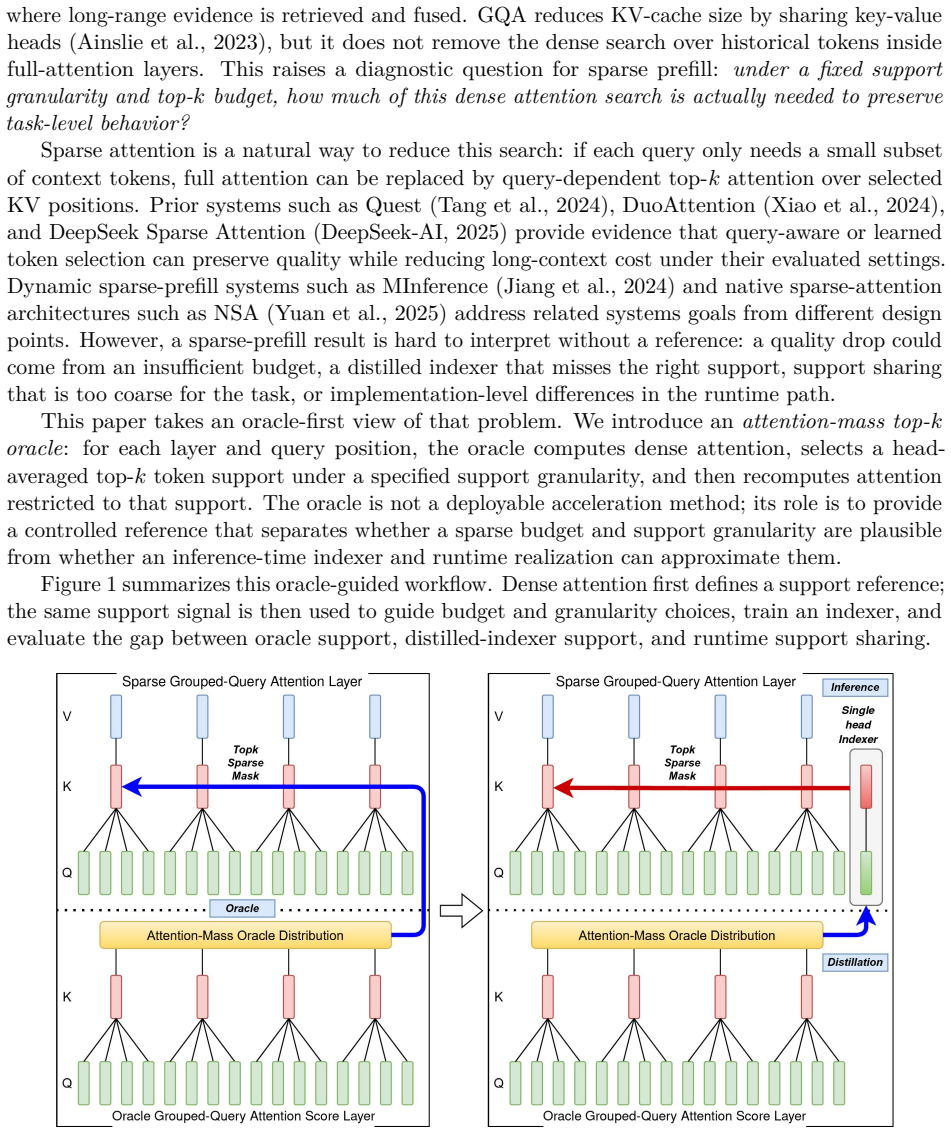
The attention-mass top-k oracle, which for each layer and query position computes dense attention, selects head-averaged token support, and recomputes attention only on that support.
If this is right
- Oracle-selected support is sufficient to keep performance within 1 point of dense on the tested retrieval tasks.
- KL-distilled head-collapsed indexers can approximate the oracle with macro gaps of +2.04 and +1.13 points on 16K/32K validation.
- Fused selection-block-shared support can widen the realization gap beyond the oracle gap.
- Distilled-indexer sparse serving yields 1.71x and 1.93x TTFT speedups on NPU and GPU against FlashAttention-2.
- Random-init indexers reach higher speedups up to 3.44x, though output quality is not validated.
Where Pith is reading between the lines
- The oracle could be used to audit other sparse or linear attention mechanisms on the same checkpoints.
- Separate indexers per model size suggest that distillation cost scales with backbone size but may still be cheaper than retraining.
- The separation of oracle feasibility from indexer quality and runtime realization leaves open whether a single end-to-end trained sparse layer can close the remaining gaps.
- If the oracle gap stays small across more tasks, hybrid models could systematically replace full attention layers with budgeted sparse ones.
Load-bearing premise
The assumption that the attention-mass top-k oracle accurately captures the token support needed to preserve task-level behavior, independent of indexer error or runtime effects.
What would settle it
A measured drop larger than 1 point on the Qwen retrieval-heavy evaluations when attention is restricted to the oracle-selected top-k support would falsify the claim that dense attention can be reduced to that level without harming task behavior.
Figures
read the original abstract
Long-context prefill remains expensive because full/GQA layers still score the historical sequence, even in hybrid models with local, sparse, linear, or recurrent components. We study how much dense attention is needed to preserve task-level behavior under explicit support granularity and top-k budgets. We introduce an attention-mass top-k oracle for existing GQA checkpoints: for each layer and query position, it computes dense attention, selects head-averaged token support, and recomputes attention only on that support. The oracle is a diagnostic reference, not a deployable accelerator, and separates sparse-budget feasibility from indexer error and runtime realization effects. On Qwen-family retrieval-heavy evaluations, the longest per-query oracle rows stay within 1 point of dense, and a Qwen3.5-9B RULER-style sweep from 4K to 100K stays within 0.48 points. Guided by the oracle, we derive a head-collapsed auxiliary indexer trained by KL distillation from dense attention-mass distributions while keeping the backbone frozen. With separately distilled Qwen3.5-0.8B and Qwen3.5-9B indexers, the reported 16K/32K validation macro gaps are +2.04 and +1.13 points, treated as quality preservation rather than improvement; fused selection-block-shared support can introduce a larger realization gap. Preliminary single-card TTFT measurements show distilled-indexer sparse serving speedups of 1.71x for Qwen3.5-0.8B on NPU and 1.93x for Qwen3.5-9B on GPU against its dense FlashAttention-2 baseline. Additional random-init stress rows reach 3.44x, indicating sparse-runtime headroom but not validated output quality. This first release separates oracle feasibility, distilled-indexer quality, and runtime headroom, leaving a fully matched quality-latency frontier to future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an attention-mass top-k oracle for GQA layers—computing dense attention, selecting head-averaged token support, and recomputing attention only on that support—preserves task-level behavior within 1 point of dense on Qwen-family retrieval tasks and within 0.48 points on a Qwen3.5-9B RULER sweep from 4K to 100K. Guided by this oracle, a head-collapsed auxiliary indexer is trained via KL distillation from dense attention-mass distributions (backbone frozen), yielding validation macro gaps of +2.04 and +1.13 points for 0.8B and 9B models; preliminary single-card TTFT speedups reach 1.71x (NPU) and 1.93x (GPU) versus FlashAttention-2, with random-init stress tests indicating up to 3.44x headroom.
Significance. If the oracle results hold, the work demonstrates that dense attention mass can be reduced to small explicit top-k supports while preserving downstream metrics in hybrid long-context models, cleanly separating budget feasibility from indexer error and runtime effects. The explicit diagnostic oracle, distillation-based indexer, and separation of concerns provide a useful framework for sparse prefill research; the reported speedups and RULER sweep add concrete empirical grounding.
major comments (4)
- [Oracle description] Oracle description (abstract): the manuscript states that the oracle 'recomputes attention only on that support' but provides no direct verification (e.g., KL divergence between original and oracle attention distributions, or logit-level differences) that renormalization over the selected keys preserves the original output distribution. This is load-bearing for the central claim that the oracle accurately measures necessary dense attention, as any systematic shift would undermine the feasibility conclusion even if task metrics remain close.
- [Experimental results] Experimental results (abstract): the reported gaps (within 1 point, 0.48 points on RULER, +2.04/+1.13 for indexers) are given without error bars, number of runs, or variance estimates. This prevents assessing whether the gaps are statistically reliable or influenced by post-hoc evaluation choices, directly affecting confidence in the 'quality preservation' interpretation.
- [Oracle definition] GQA handling (oracle definition): head-averaged token support is used for selection in GQA layers, yet no ablation compares this to per-head selection or quantifies how often head-specific critical tokens are discarded. This assumption is central to the claim that the oracle works for full/GQA layers.
- [Indexer training] Indexer results (abstract): the +2.04 and +1.13 point gaps are presented as 'quality preservation' after KL distillation, but the manuscript does not report the training dataset size, exact loss formulation, or comparison to a non-distilled baseline, making it difficult to isolate the contribution of the oracle-guided design.
minor comments (2)
- [Abstract] The abstract mentions that 'fused selection-block-shared support can introduce a larger realization gap' without quantifying the gap or referencing a table/figure.
- [Runtime measurements] TTFT measurements are described as 'preliminary' and 'single-card'; clarify whether they measure only prefill or the full generation pipeline, and whether KV cache effects are included.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will incorporate revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Oracle description] Oracle description (abstract): the manuscript states that the oracle 'recomputes attention only on that support' but provides no direct verification (e.g., KL divergence between original and oracle attention distributions, or logit-level differences) that renormalization over the selected keys preserves the original output distribution. This is load-bearing for the central claim that the oracle accurately measures necessary dense attention, as any systematic shift would undermine the feasibility conclusion even if task metrics remain close.
Authors: We agree that explicit verification of output distribution preservation (via KL divergence or logit differences) would provide stronger support for the oracle as a faithful diagnostic of necessary attention mass. While the current evidence centers on downstream task metrics, we will add these analyses comparing dense vs. oracle attention outputs in the revised manuscript. revision: yes
-
Referee: [Experimental results] Experimental results (abstract): the reported gaps (within 1 point, 0.48 points on RULER, +2.04/+1.13 for indexers) are given without error bars, number of runs, or variance estimates. This prevents assessing whether the gaps are statistically reliable or influenced by post-hoc evaluation choices, directly affecting confidence in the 'quality preservation' interpretation.
Authors: We acknowledge that the reported gaps lack error bars or variance estimates from multiple runs. These figures reflect single evaluations on the described tasks. In revision we will add repeated-run variance where computationally feasible or explicitly note the single-run nature to improve interpretability. revision: yes
-
Referee: [Oracle definition] GQA handling (oracle definition): head-averaged token support is used for selection in GQA layers, yet no ablation compares this to per-head selection or quantifies how often head-specific critical tokens are discarded. This assumption is central to the claim that the oracle works for full/GQA layers.
Authors: Head-averaged selection follows from the shared-key structure of GQA. We will add an ablation contrasting head-averaged vs. per-head selection and report the rate at which head-specific tokens are discarded by the averaging step. revision: yes
-
Referee: [Indexer training] Indexer results (abstract): the +2.04 and +1.13 point gaps are presented as 'quality preservation' after KL distillation, but the manuscript does not report the training dataset size, exact loss formulation, or comparison to a non-distilled baseline, making it difficult to isolate the contribution of the oracle-guided design.
Authors: We will expand the methods and experiments sections to report training dataset size, the precise KL loss formulation, and results from a non-distilled (e.g., random or supervised) baseline indexer to clarify the contribution of the oracle-guided distillation. revision: yes
Circularity Check
No significant circularity; claims rest on empirical measurements
full rationale
The paper defines an oracle that explicitly computes dense attention, selects head-averaged top-k support, and recomputes attention on that support as a diagnostic reference. Reported gaps (within 1 point on retrieval tasks, 0.48 on RULER sweep) are direct empirical comparisons between this oracle output and full dense attention, not quantities derived by construction from the paper's own equations. The indexer is trained via KL distillation from dense distributions and its gaps (+2.04/+1.13) are likewise measured against the same dense baseline. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises; the derivation chain consists of separate stages (oracle feasibility, distillation, runtime) whose outputs are externally validated by task metrics rather than reduced to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. GQA: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench v2: Towards deeper understanding and reasoning on realistic long-context multitasks.arXiv preprint arXiv:2412.15204,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[4]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Re. FlashAttention: Fast and memory-efficient exact attention with IO-awareness.arXiv preprint arXiv:2205.14135,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
DeepSeek-AI. DeepSeek-V3.2-Exp: Boosting long-context efficiency with DeepSeek sparse attention. Official repository and technical report, 2025.https://github.com/deepseek-ai/DeepSeek-V3. 2-Exp. Chaoyou Fu, Yuhan Dai, Yongdong Luo, et al. Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis.arXiv preprint arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Jamba: A Hybrid Transformer-Mamba Language Model
Opher Lieber et al. Jamba: A hybrid Transformer-Mamba language model.arXiv preprint arXiv:2403.19887,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu
26 Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, et al. MInference 1.0: Accelerating pre-filling for long-context LLMs via dynamic sparse attention.arXiv preprint arXiv:2407.02490,
-
[12]
Yubo Ma, Yuhang Zang, Liangyu Chen, et al. MMLongBench-Doc: Benchmarking long-context document understanding with visualizations.arXiv preprint arXiv:2407.01523,
-
[13]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lelio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothee Lacroix, and William El Sayed. Mistral 7B.arXiv preprint arXiv:23...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
https: //huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct. See also Qwen3 technical report, arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query-aware sparsity for efficient long-context LLM inference.arXiv preprint arXiv:2406.10774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
vLLM v0.18.0 attention backend docs; vLLM-Ascend v0.18.0 platform backend selection; vLLM-Ascend v0.18.0 attention backend; vLLM v0.20.0 attention backend docs. Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. DuoAttention: Efficient long-context LLM inference with retrieval and streaming heads.arXiv ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
Jingyang Yuan, Huazuo Gao, Damai Dai, et al. Native sparse attention: Hardware-aligned and natively trainable sparse attention.arXiv preprint arXiv:2502.11089,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Big Bird: Transformers for Longer Sequences
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big Bird: Transformers for longer sequences.arXiv preprint arXiv:2007.14062,
work page internal anchor Pith review Pith/arXiv arXiv 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.