Attention at the Theoretical Minimum: A Mathematics of Arrays Framework for Memory-Optimal Transformer Kernels
Pith reviewed 2026-06-27 22:30 UTC · model grok-4.3
The pith
A Mathematics of Arrays rewrite derives a normal form for attention that removes every intermediate array by algebraic construction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
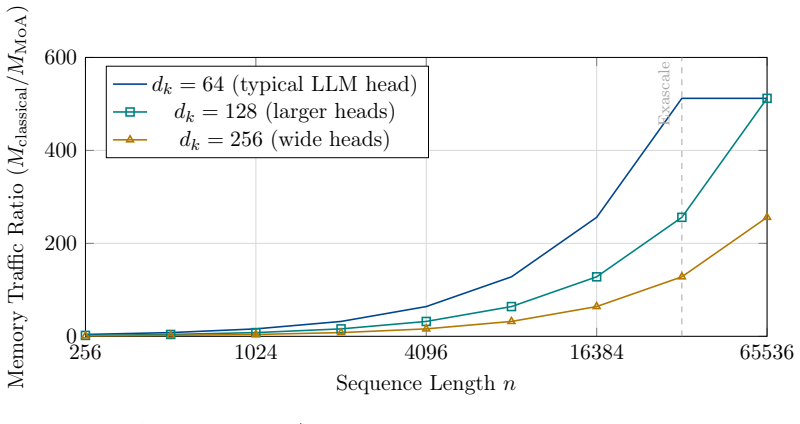
The Denotational Normal Form obtained from the Mathematics of Arrays treatment of attention and softmax eliminates the implicit transposed-key buffer, every softmax temporary, and all other intermediate arrays, yielding O(n_dk + n_dv) data movement where the standard form requires O(n^2 + n_dk + n_dv); memory minimality is therefore a theorem established prior to implementation, and the result is verified by exact numerical agreement with PyTorch at full double precision.
What carries the argument
The Denotational Normal Form produced by algebraic transformation of the attention expression inside the Mathematics of Arrays framework, which removes every intermediate array by construction.
If this is right
- Predictive models derived from the algebra project 2-100x speedup and 2-50x energy reduction, with the gap increasing at larger scale.
- The same algebraic pipeline supplies array fusion, shape-transformation correctness, and cost models from a single source rather than separate empirical steps.
- A formally verified path exists from the Python-level specification through operational normal form to dimension-lifted hardware mapping.
- The kernels are performance-portable across architectures because the optimality proof does not rely on hardware-specific tuning.
Where Pith is reading between the lines
- The same algebraic elimination of temporaries could be applied to the feed-forward and layer-norm stages inside a full transformer block.
- If the normal-form construction extends to other attention variants, low-memory implementations could become the default rather than special cases.
- The predictive cost model supplies a way to compare attention formulations on new hardware before writing any kernel code.
Load-bearing premise
The algebraic rewrite produces exactly the same numerical results as the original attention computation for every input without depending on particular array shapes or floating-point rounding rules.
What would settle it
Execution on any concrete input sequence where the output tensors differ from the reference PyTorch implementation by more than machine epsilon at double precision.
Figures

read the original abstract
The attention mechanism is the dominant computational bottleneck in modern transformer-based AI. Its standard implementation incurs quadratic memory traffic in the sequence length~$n$, and DRAM accesses cost 100--1000$\times$ more energy than arithmetic operations on contemporary hardware, so any analysis focused solely on FLOP counts fundamentally mischaracterises the bottleneck. We present a Mathematics of Arrays (MoA) reformulation of scaled dot-product attention and its numerically stable softmax, deriving a Denotational Normal Form (DNF) that eliminates all intermediate arrays -- including the implicit transposed-key buffer and every softmax temporary -- by algebraic construction rather than empirical tuning. The DNF achieves $O(n_{dk} + n{_{dv}})$ data movement versus $O(n^2 + n_{dk} + n_{dv})$ for the standard implementation, where $n$ is the sequence length, $dk$ is the key dimensionality and $dv$ the value dimensionality, and is verified numerically against PyTorch at full double-precision floating-point on concrete inputs. Unlike hardware-specific accelerators or empirical tiling schemes such as FlashAttention, MoA simultaneously provides array fusion, shape-transformation correctness, and predictive cost models from a single algebraic framework. Memory minimality is a theorem established before any code is written. A predictive performance model projects $2$--$100\times$ speedup and $2$--$50\times$ energy reduction, with the advantage widening at exascale. The derivation establishes a formally verified pipeline from Python specification through (ONF) Operational Normal Form, and dimension-lifted hardware mapping, providing performance-portable AI kernels of direct relevance to DARPA edge-deployment and DOE exascale priorities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a Mathematics of Arrays (MoA) reformulation of scaled dot-product attention and numerically stable softmax that derives a Denotational Normal Form (DNF) eliminating all intermediate arrays (including the n² score matrix, transposed-key buffer, and softmax temporaries) by algebraic construction. This yields an O(n_dk + n_dv) data-movement bound versus O(n² + n_dk + n_dv) for the standard implementation, with memory minimality asserted as a theorem established prior to code; equivalence is verified by numerical agreement with PyTorch at double precision on concrete inputs, and a predictive model projects 2–100× speedup and 2–50× energy reduction at scale.
Significance. If the algebraic equivalence and DNF construction hold exactly, the work would supply a single formal framework delivering array fusion, shape-transformation correctness, and predictive cost models for memory-optimal attention kernels. This approach is distinguished from empirical tiling methods such as FlashAttention by its theorem-based minimality and performance-portable pipeline from Python specification through Operational Normal Form to hardware mapping, with direct relevance to exascale and edge-deployment priorities.
major comments (2)
- [Abstract] Abstract: the claim that the MoA DNF preserves exact semantics of scaled dot-product attention plus numerically stable softmax (and thereby realizes the O(n_dk + n_dv) bound as a theorem) rests solely on numerical agreement at double precision on concrete inputs. No explicit derivation steps, error analysis, or machine-checked equivalence argument is provided to show that array fusion and elimination of the n² matrix and all temporaries introduce no hidden shape or IEEE-754 rounding constraints for arbitrary n, dk, dv.
- [Abstract] Abstract: the statement that 'memory minimality is a theorem established before any code is written' and that the pipeline is 'formally verified' is not supported by any shown algebraic identities or proof obligations; the numerical verification alone does not discharge the semantic-equivalence obligation required for the central data-movement claim.
minor comments (1)
- [Abstract] Abstract: the notation 'O(n_{dk} + n{_{dv}})' contains a typographic error in the subscript for n_dv.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify that the abstract's strong claims about algebraic derivation and formal verification would benefit from more explicit supporting material in the manuscript. We address each point below and will revise to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the MoA DNF preserves exact semantics of scaled dot-product attention plus numerically stable softmax (and thereby realizes the O(n_dk + n_dv) bound as a theorem) rests solely on numerical agreement at double precision on concrete inputs. No explicit derivation steps, error analysis, or machine-checked equivalence argument is provided to show that array fusion and elimination of the n² matrix and all temporaries introduce no hidden shape or IEEE-754 rounding constraints for arbitrary n, dk, dv.
Authors: The manuscript's central contribution is the algebraic construction of the DNF via successive MoA transformations that eliminate intermediates by definition of the normal form; this is presented through the sequence of shape and operation rewrites in the body. Numerical agreement at double precision on the tested inputs serves as confirmation rather than the sole basis. We agree that the presentation would be strengthened by an expanded outline of the key identities, a short discussion of potential IEEE-754 effects for arbitrary dimensions, and an explicit statement that full machine-checked equivalence is beyond the current scope. We will add these elements in revision. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'memory minimality is a theorem established before any code is written' and that the pipeline is 'formally verified' is not supported by any shown algebraic identities or proof obligations; the numerical verification alone does not discharge the semantic-equivalence obligation required for the central data-movement claim.
Authors: Memory minimality follows as a direct consequence of the DNF having no intermediate arrays under the MoA axioms; the pipeline is 'formally verified' in the sense that each step applies the framework's denotational rules from specification onward. The abstract summarizes rather than displays the identities. We accept that the current text does not make the proof obligations sufficiently visible. In the revision we will include representative algebraic steps (either inline or as a new figure) and clarify the precise scope of the formal claims versus the numerical checks. revision: yes
Circularity Check
No significant circularity; derivation is algebraic and self-contained
full rationale
The paper derives the DNF and its O(n_dk + n_dv) data-movement bound directly from the Mathematics of Arrays algebraic identities, stating that memory minimality is a theorem established before any code is written and that elimination of intermediates occurs by algebraic construction rather than empirical tuning. Numerical agreement with PyTorch is presented only as post-derivation verification on concrete inputs, not as the source of the bound or theorem. No equations or steps in the provided text reduce a claimed result to a fitted parameter, self-definition, or load-bearing self-citation; the performance projections are described as arising from the same algebraic framework. The derivation chain from specification through ONF is therefore independent of the target metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Mathematics of Arrays framework can be used to derive denotational and operational normal forms that preserve the semantics of array operations including softmax.
Reference graph
Works this paper leans on
-
[1]
FATHOM: Fast attention through optimizing memory
Binder, E., Sudarsanam, A., Sunkavalli, R., Low, T.M., 2025. FATHOM: Fast attention through optimizing memory. In: Proceedings of IEEE IPDPS, pp. 1166--1178
2025
-
[2]
MOSA: Matrix optimized self-attention hardware accelerator for mobile device
Chang, Y.-R., Chen, H.-F., Shih, H.-Y., 2025. MOSA: Matrix optimized self-attention hardware accelerator for mobile device. In: Proceedings of ICEIC, pp. 1--4
2025
-
[3]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Dao, T., 2023. FlashAttention-2: Faster attention with better parallelism and work partitioning. arXiv:2307.08691
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Dao, T., Fu, D.Y., Ermon, S., Rudra, A., R\' e , C., 2022. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. arXiv:2205.14135
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Grout, I.A., Mullin, L., 2018. Hardware considerations for tensor implementation and analysis using the field programmable gate array. Electronics 7 (11), 320. doi:10.3390/electronics7110320
-
[6]
Grout, I.A., Mullin, L., 2022a. Realizing mathematics of arrays operations as custom architecture hardware-software co-design solutions. Information 13 (11), 528. doi:10.3390/info13110528
-
[7]
Processing in memory for mathematics of arrays operations
Grout, I.A., Mullin, L., 2022b. Processing in memory for mathematics of arrays operations. In: Proceedings of SAI Computing Conference, 2022
2022
-
[8]
A fast optimization view: Reformulating single layer attention in LLM based on tensor and SVM trick
Gao, Y., Song, Z., Wang, W., Yin, J., 2023. A fast optimization view: Reformulating single layer attention in LLM based on tensor and SVM trick. arXiv:2309.07418
-
[9]
Hains, G., 2026. From algorithm to code to hardware to execution: Why isn't computing performance an experimental science? In: Proceedings of PDP 2026, Euromicro Conference on Parallel, Distributed, and Network-Based Processing. Cluj-Napoca, Romania
2026
-
[10]
A ^3 : Accelerating attention mechanisms in neural networks with approximation
Ham, T.J., Jung, S.J., Kim, S., Oh, Y.H., Park, Y., Song, Y., Park, J.-H., Lee, S., Park, K., Lee, J.W., Jeong, D.-K., 2020. A ^3 : Accelerating attention mechanisms in neural networks with approximation. In: Proceedings of IEEE HPCA, pp. 328--341
2020
-
[11]
Acceleration of fully connected layers on FPGA using the Strassen matrix multiplication
Le\' o n-Vega, L.G., Chac\' o n-Rodr\' i guez, A., Salazar-Villalobos, E., Castro-God\' i nez, J., 2023. Acceleration of fully connected layers on FPGA using the Strassen matrix multiplication. In: Proceedings of IEEE BIP, pp. 1--6
2023
-
[12]
Design and implementation of an FPGA-based hardware accelerator for transformer
Li, R., Chen, S., 2025. Design and implementation of an FPGA-based hardware accelerator for transformer. arXiv:2503.16731
-
[13]
Research on matrix multiplication optimization and deployment method for heterogeneous platforms
Liu, J., Wu, C., Li, J., Chen, X., Wang, S., 2024. Research on matrix multiplication optimization and deployment method for heterogeneous platforms. In: Proceedings of ICCBD+AI, pp. 266--270
2024
-
[14]
Array access and performance regarding numerical algorithms
Markus, A., Mullin, L., 2026. Array access and performance regarding numerical algorithms. Transactions on Engineering on Computing Sciences 14 (2), 1--14
2026
-
[15]
A Mathematics of Arrays
Mullin, L.M., 1988. A Mathematics of Arrays. Ph.D. dissertation. Syracuse University, Syracuse, NY
1988
-
[16]
From array algebra to energy efficiency on GPUs
Mullin, L.M.R., 2023. From array algebra to energy efficiency on GPUs. arXiv:2306.11148
-
[17]
Towards automatic, predictable and high-performance parallel code generation
Mullin, L., Hains, G., 2025. Towards automatic, predictable and high-performance parallel code generation. In: Proceedings of CSCE/PDPTA2024, Springer Nature Switzerland, pp. 109--119
2025
-
[18]
New mathematics for computer performance: array algebra and cost functions
Mullin, L., Hains, G., 2026. New mathematics for computer performance: array algebra and cost functions. Technical Report. https://hal.science/hal-05442652
2026
-
[19]
OPTIMUS: Optimized matrix multiplication structure for transformer neural network accelerator
Park, J., Yoon, H., Ahn, D., Choi, J., Kim, J.-J., 2020. OPTIMUS: Optimized matrix multiplication structure for transformer neural network accelerator. In: Proceedings of MLSys, vol. 2, pp. 363--378
2020
-
[20]
FACT: FFN-attention co-optimized transformer architecture with eager correlation prediction
Qin, Y., Wang, Y., Deng, D., Zhao, Z., Yang, X., Liu, L., Wei, S., Hu, Y., Yin, S., 2023. FACT: FFN-attention co-optimized transformer architecture with eager correlation prediction. In: Proceedings of ISCA, pp. 1--14
2023
-
[21]
High-performance Gemmini-based matrix multiplication accelerator for deep learning workloads
Sharma, A., Krishna, L.H., Srinivasu, B., 2025. High-performance Gemmini-based matrix multiplication accelerator for deep learning workloads. IEEE Transactions on VLSI Systems 33 (12), 3276--3289
2025
-
[22]
Design and implementation of a BRAM-banked double-buffered matrix multiplication accelerator for transformer models on edge FPGAs
Tan, X., Teo, T.H., 2025. Design and implementation of a BRAM-banked double-buffered matrix multiplication accelerator for transformer models on edge FPGAs. In: Proceedings of IEEE MCSoC, pp. 582--585
2025
-
[23]
Improving the performance of DGEMM with MoA and cache-blocking
Thomas, S., Mullin, L., Swirydowicz, K., 2021a. Improving the performance of DGEMM with MoA and cache-blocking. In: Proceedings of ACM ARRAY'21
-
[24]
Threaded multicore GEMM with MoA and cache-blocking
Thomas, S., Mullin, L., Swirydowicz, K., Khan, R., 2021b. Threaded multicore GEMM with MoA and cache-blocking. In: Proceedings of CSC'21, CSCE'21
-
[25]
Attention is all you need
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, ., Polosukhin, I., 2017. Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS)
2017
-
[26]
Hardware friendly transformer optimization with dynamic attention matrix fusion
Yang, Q., Wang, X., Zhou, Y., Li, Q., Qiao, S., 2025. Hardware friendly transformer optimization with dynamic attention matrix fusion. In: Proceedings of IEEE ISCAS, pp. 1--5
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.