Cross Paraphrastic Invariance Learning for Hallucination Detection
Pith reviewed 2026-06-27 19:57 UTC · model grok-4.3
The pith
A two-stage Siamese network learns paraphrase-invariant embeddings that detect hallucinations using roughly one percent of typical labeled data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
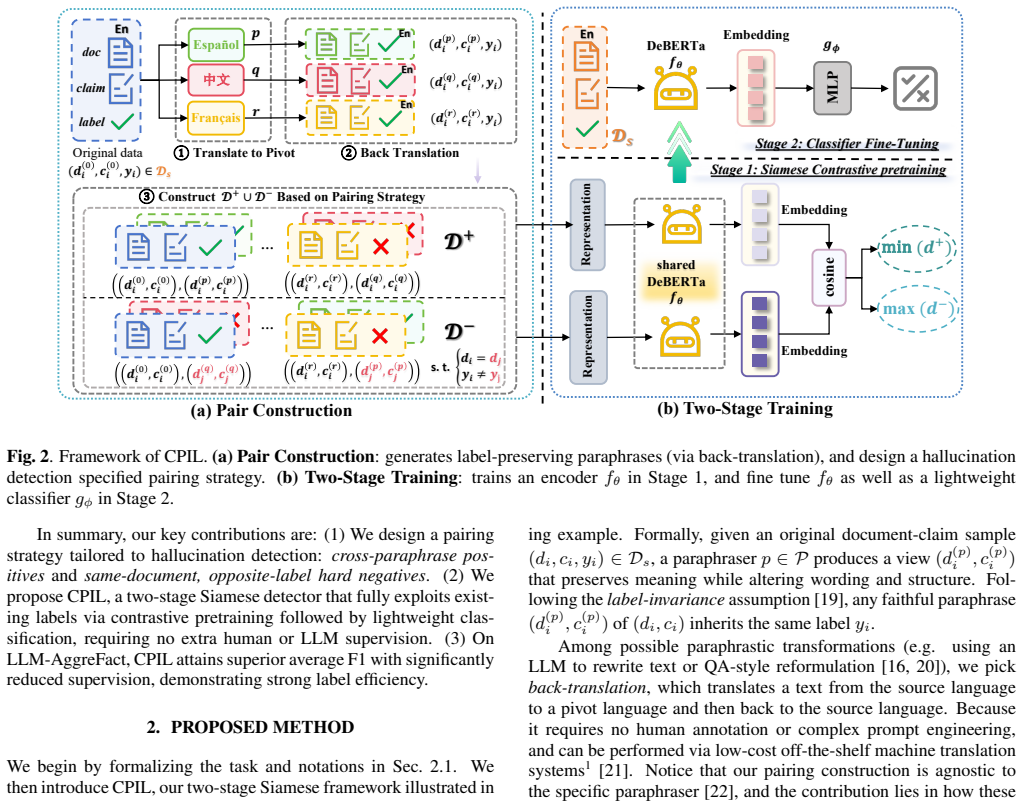
CPIL constructs positive pairs from automatically generated paraphrases of the same document-claim example and negative pairs from same-document instances that carry opposite groundedness labels; a first contrastive stage aligns the positives and repels the negatives to produce a paraphrase-invariant, grounding-aware embedding space, after which a second stage attaches a binary classifier that achieves higher F1 scores than strong baselines across eleven tasks while using only about one percent of the labeled data.
What carries the argument
Cross Paraphrastic Invariance Learning: a contrastive objective that aligns paraphrastic views of each example while separating same-document opposite-label pairs to enforce surface-form invariance and document-sensitive decision boundaries.
If this is right
- Existing labeled hallucination datasets can be reused far more efficiently than with standard supervised training.
- The two-stage process separates representation learning from classification, allowing the same embeddings to support multiple downstream checks.
- Performance gains hold across eleven distinct tasks without task-specific tuning beyond the shared contrastive stage.
- The framework reduces dependence on LLM-based evaluation pipelines for both training and inference.
Where Pith is reading between the lines
- The same construction of paraphrase positives and document-level hard negatives could be applied to related detection tasks such as factuality checking in summaries or dialogue.
- If the invariance property transfers across languages, the method might support low-resource hallucination detection without new labeled data in the target language.
- The approach suggests that surface-form invariance plus document context is a sufficient inductive bias for groundedness, which could be tested by ablating the hard-negative mining step.
Load-bearing premise
Automatically generated paraphrases preserve the original groundedness label and that same-document opposite-label pairs mined as hard negatives supply clean training signals without introducing artifacts or label noise.
What would settle it
Manually verify the groundedness label of a sample of the generated paraphrases, retrain the model on only the verified pairs, and check whether the reported F1 advantage over baselines disappears.
Figures
read the original abstract
Large language models (LLMs) frequently generate hallucinations, which are unsupported by a source document. To avoid costly LLM-as-evaluator pipelines and the heavy annotation demands of existing classifiers, we propose CPIL (Cross Paraphrastic Invariance Learning), a two-stage Siamese framework that maximizes the utility of existing labeled data. Concretely, CPIL constructs informative training pairs by: (i) generating paraphrastic views of each document-claim example as positives, and explicitly aligning their representations to enforce invariance to surface form; and (ii) mining same-document, opposite-label pairs as hard negatives to sharpen document-sensitive decision boundaries. Then CPIL conduct a two-stage model training: Stage 1 performs contrastive pretraining to learn a paraphrase-invariant, grounding-aware embedding space; and Stage 2 attaches a lightweight classifier for binary groundedness. On the LLM-AggreFact benchmark (11 tasks), CPIL surpasses strong baselines concerning F1 scores with only ~1% labeled data, showing its prediction superiority and label efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CPIL, a two-stage Siamese framework for hallucination detection in LLMs. Stage 1 performs contrastive pretraining by treating LLM-generated paraphrastic views of each document-claim pair as positives (to enforce invariance to surface form) and mining same-document opposite-label pairs as hard negatives (to sharpen document-sensitive boundaries), learning a paraphrase-invariant and grounding-aware embedding space. Stage 2 attaches a lightweight classifier for binary groundedness prediction. On the LLM-AggreFact benchmark (11 tasks), the method is claimed to surpass strong baselines in F1 score while using only ~1% labeled data.
Significance. If the result holds and the training-signal assumptions are validated, CPIL would demonstrate a practical route to label-efficient hallucination detection by repurposing limited existing annotations via contrastive invariance learning, reducing reliance on expensive LLM-as-evaluator pipelines.
major comments (1)
- [Abstract] Abstract and method description: the central training construction presupposes that LLM-generated paraphrases preserve the original binary groundedness label and that automatically mined same-document opposite-label pairs supply clean, document-sensitive hard negatives without label flips or generation artifacts. No post-generation label verification, human validation, or noise-robustness experiments are described; this assumption is load-bearing for the claimed F1 superiority and label efficiency because corrupted contrastive pairs would directly degrade the learned embedding space.
minor comments (1)
- [Abstract] The abstract supplies no experimental details on baseline implementations, statistical tests, ablation studies, or exact data splits, which hinders immediate assessment of the performance claims even if the full manuscript contains them.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the central training construction presupposes that LLM-generated paraphrases preserve the original binary groundedness label and that automatically mined same-document opposite-label pairs supply clean, document-sensitive hard negatives without label flips or generation artifacts. No post-generation label verification, human validation, or noise-robustness experiments are described; this assumption is load-bearing for the claimed F1 superiority and label efficiency because corrupted contrastive pairs would directly degrade the learned embedding space.
Authors: We acknowledge that the effectiveness of CPIL depends on the assumption that LLM-generated paraphrases largely preserve the original groundedness label and that same-document opposite-label pairs provide reliable hard negatives. This design choice follows from the semantic preservation property of paraphrasing and the use of existing dataset labels to create document-specific contrasts. The referee is correct that the initial submission does not include explicit post-generation verification, human validation, or dedicated noise-robustness experiments. We agree this is a substantive point that merits additional evidence. In the revision we will add a dedicated subsection reporting (i) label-consistency checks on a sampled subset of generated paraphrases via independent LLM evaluation and limited human annotation, and (ii) controlled noise-injection experiments that measure degradation under simulated label flips. These results will be used to quantify the sensitivity of the learned embedding space and to support the reported F1 gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents CPIL as a two-stage empirical method that constructs training pairs from existing labeled data (paraphrastic positives and same-document opposite-label negatives) and applies standard contrastive pretraining followed by classification. No equations, derivations, or self-citations appear that reduce the claimed F1 superiority or label efficiency to a fitted parameter, self-referential quantity, or definitional equivalence by construction. The central result is an empirical benchmark comparison that remains independent of any load-bearing self-citation or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cross Paraphrastic Invariance Learning for Hallucination Detection
INTRODUCTION Large language models (LLMs) show impressive fluency and coher- ence across a wide range of tasks. However, a persistent challenge ishallucinations, the generation of statements that are factually in- correct or unsupported by a given source document [1, 2]. Accu- rately detecting hallucination is essential for developing trustworthy, safety-...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
PROPOSED METHOD We begin by formalizing the task and notations in Sec. 2.1. We then introduce CPIL, our two-stage Siamese framework illustrated in Fig. 2. Sec. 2.2 describes how we obtain label-preserving paraphras- tic views and construct informative training pairs. Sec. 2.3 details contrastive pretraining and the classifier fine-tuning stages. 2.1. Prob...
-
[3]
Experiment Settings Evaluation & metrics.We evaluate onLLM-AggreFact, an aggre- gate benchmark comprising 11 factuality datasets [11]
EXPERIMENTS 3.1. Experiment Settings Evaluation & metrics.We evaluate onLLM-AggreFact, an aggre- gate benchmark comprising 11 factuality datasets [11]. We report per-task F1 (%) and the macro-averaged F1 (A VG) across all tasks. We follow the official splits and evaluation protocols. Baselines.CPIL is compared against four powerful non-LLM detectors:Summa...
-
[4]
CPIL con- verts individual labeled examples intopairsby considering cross- paraphrasepositivesand same-document, opposite-labelhard neg- atives
CONCLUSION We presented CPIL, a two-stage Siamese framework for hallucina- tion detection that maximizes the utility of existing labels. CPIL con- verts individual labeled examples intopairsby considering cross- paraphrasepositivesand same-document, opposite-labelhard neg- atives. A contrastive pretraining stage learns a paraphrase invari- ant representat...
-
[5]
Subhey Sadi Rahman, Md Adnanul Islam, Md Mahbub Alam, Musarrat Zeba, Md Abdur Rahman, Sadia Sultana Chowa, Mo- haimenul Azam Khan Raiaan, and Sami Azam, “Hallucination to truth: A review of fact-checking and factuality evaluation in large language models,”arXiv preprint arXiv:2508.03860, 2025
-
[6]
On faithfulness and factual- ity in abstractive summarization,
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan Mc- Donald, “On faithfulness and factuality in abstractive summa- rization,”arXiv preprint arXiv:2005.00661, 2020
-
[7]
Importing phantoms: Measuring llm package hal- lucination vulnerabilities,
Arjun Krishna, Erick Galinkin, Leon Derczynski, and Jeffrey Martin, “Importing phantoms: Measuring llm package hal- lucination vulnerabilities,”arXiv preprint arXiv:2501.19012, 2025
-
[8]
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
Potsawee Manakul, Adian Liusie, and Mark JF Gales, “Self- checkgpt: Zero-resource black-box hallucination detection for generative large language models,”arXiv preprint arXiv:2303.08896, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Selfcheckagent: Zero-resource hallucination detection in generative large language models,
Diyana Muhammed, Gollam Rabby, and S ¨oren Auer, “Self- checkagent: Zero-resource hallucination detection in genera- tive large language models,”arXiv preprint arXiv:2502.01812, 2025
-
[10]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu, “G-eval: Nlg evaluation us- ing gpt-4 with better human alignment,”arXiv preprint arXiv:2303.16634, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Chain-of- thought prompting elicits reasoning in large language models,
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al., “Chain-of- thought prompting elicits reasoning in large language models,” Advances in neural information processing systems, vol. 35, pp. 24824–24837, 2022
2022
-
[12]
Summac: Re-visiting nli-based models for inconsis- tency detection in summarization,
Philippe Laban, Tobias Schnabel, Paul N Bennett, and Marti A Hearst, “Summac: Re-visiting nli-based models for inconsis- tency detection in summarization,”Transactions of the Asso- ciation for Computational Linguistics, vol. 10, pp. 163–177, 2022
2022
-
[13]
Qafacteval: Improved qa-based factual consistency evaluation for summarization,
Alexander R Fabbri, Chien-Sheng Wu, Wenhao Liu, and Caiming Xiong, “Qafacteval: Improved qa-based factual consistency evaluation for summarization,”arXiv preprint arXiv:2112.08542, 2021
-
[14]
Alignscore: Evaluating factual consistency with a unified alignment function,
Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu, “Align- score: Evaluating factual consistency with a unified alignment function,”arXiv preprint arXiv:2305.16739, 2023
-
[15]
Minicheck: Efficient fact-checking of llms on ground- ing documents,
Liyan Tang, Philippe Laban, and Greg Durrett, “Minicheck: Efficient fact-checking of llms on grounding documents,” arXiv preprint arXiv:2404.10774, 2024
-
[16]
Factcg: Enhancing fact checkers with graph-based multi-hop data,
Deren Lei, Yaxi Li, Siyao Li, Mengya Hu, Rui Xu, Ken Archer, Mingyu Wang, Emily Ching, and Alex Deng, “Factcg: En- hancing fact checkers with graph-based multi-hop data,”arXiv preprint arXiv:2501.17144, 2025
-
[17]
Self-learn to ex- plain siamese networks robustly,
Chao Chen, Yifan Shen, Guixiang Ma, Xiangnan Kong, Srini- vas Rangarajan, Xi Zhang, and Sihong Xie, “Self-learn to ex- plain siamese networks robustly,” in2021 IEEE International Conference on Data Mining (ICDM). IEEE, 2021, pp. 1018– 1023
2021
-
[18]
A twofold siamese network for real-time object tracking,
Anfeng He, Chong Luo, Xinmei Tian, and Wenjun Zeng, “A twofold siamese network for real-time object tracking,” inPro- ceedings of the IEEE conference on computer vision and pat- tern recognition, 2018, pp. 4834–4843
2018
-
[19]
Understanding Back-Translation at Scale
Sergey Edunov, Myle Ott, Michael Auli, and David Grang- ier, “Understanding back-translation at scale,”arXiv preprint arXiv:1808.09381, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Evaluating the factual consis- tency of abstractive text summarization,
Wojciech Kry ´sci´nski, Bryan McCann, Caiming Xiong, and Richard Socher, “Evaluating the factual consistency of abstrac- tive text summarization,”arXiv preprint arXiv:1910.12840, 2019
-
[21]
A simple framework for contrastive learning of visual representations,
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton, “A simple framework for contrastive learning of visual representations,” inInternational conference on ma- chine learning. PmLR, 2020, pp. 1597–1607
2020
-
[22]
Grapheval: A knowledge- graph based llm hallucination evaluation framework,
Hannah Sansford, Nicholas Richardson, Hermina Petric Maretic, and Juba Nait Saada, “Grapheval: A knowledge- graph based llm hallucination evaluation framework,”arXiv preprint arXiv:2407.10793, 2024
-
[23]
Data aug- mentation in natural language processing: a novel text genera- tion approach for long and short text classifiers,
Markus Bayer, Marc-Andr ´e Kaufhold, Bj ¨orn Buchhold, Mar- cel Keller, J ¨org Dallmeyer, and Christian Reuter, “Data aug- mentation in natural language processing: a novel text genera- tion approach for long and short text classifiers,”International journal of machine learning and cybernetics, vol. 14, no. 1, pp. 135–150, 2023
2023
-
[24]
Hallucination detection in large language models with metamorphic relations,
Borui Yang, Md Afif Al Mamun, Jie M Zhang, and Gias Ud- din, “Hallucination detection in large language models with metamorphic relations,”Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 425–445, 2025
2025
-
[25]
Neural machine translation: A review,
Felix Stahlberg, “Neural machine translation: A review,”Jour- nal of Artificial Intelligence Research, vol. 69, pp. 343–418, 2020
2020
-
[26]
Eda: Easy data augmentation tech- niques for boosting performance on text classification tasks,
Jason Wei and Kai Zou, “Eda: Easy data augmentation tech- niques for boosting performance on text classification tasks,” arXiv preprint arXiv:1901.11196, 2019
-
[27]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen, “Deberta: Decoding-enhanced bert with disentangled attention,”arXiv preprint arXiv:2006.03654, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[28]
Supervised contrastive learning for pre-trained lan- guage model fine-tuning,
Beliz Gunel, Jingfei Du, Alexis Conneau, and Ves Stoy- anov, “Supervised contrastive learning for pre-trained lan- guage model fine-tuning,”arXiv preprint arXiv:2011.01403, 2020
-
[29]
Scaling Instruction-Finetuned Language Models
Hyung Won Chung, Le Hou, Shayne Longpre, et al., “Scaling instruction-finetuned language models,”arXiv:2210.11416, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Unified hallucination detection for multimodal large language models,
Xiang Chen, Chenxi Wang, Yida Xue, Ningyu Zhang, Xiaoyan Yang, Qiang Li, Yue Shen, Lei Liang, Jinjie Gu, and Huajun Chen, “Unified hallucination detection for multimodal large language models,”arXiv preprint arXiv:2402.03190, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.