CheXanatomy: Anatomy-Aware Vision-Language Modeling for Chest Radiographs
Pith reviewed 2026-06-27 18:59 UTC · model grok-4.3
The pith
Training vision-language models to autoregressively output anatomical segmentation masks from chest X-rays produces representations competitive with dedicated convolutional networks and more robust to real-world data shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
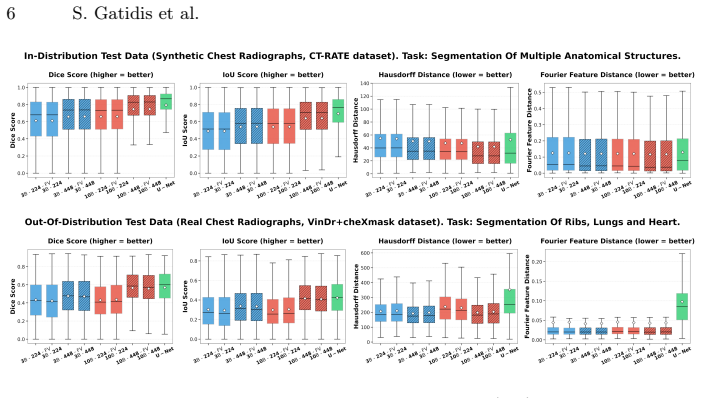
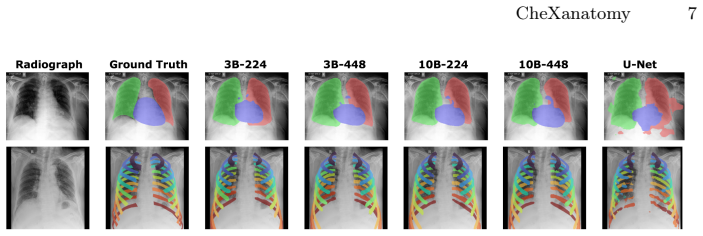
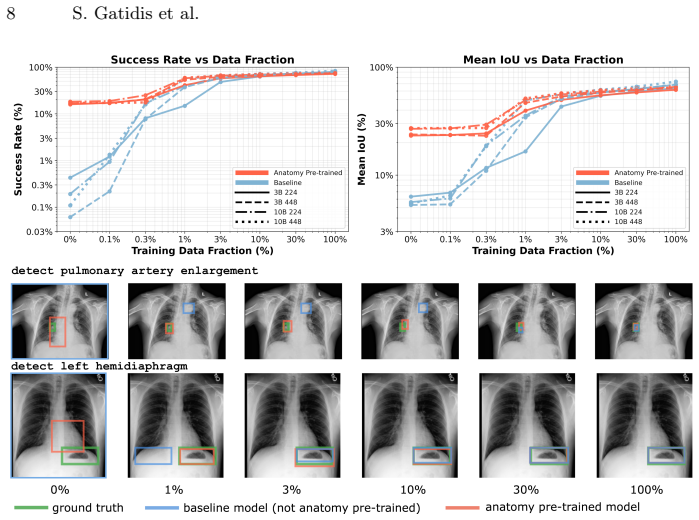
By training a pretrained vision-language model to generate anatomical segmentation masks via next-token prediction on synthetic chest radiographs derived from CT, the approach embeds explicit anatomical knowledge directly into the generative objective, achieving performance comparable to specialized convolutional models in-distribution while demonstrating improved geometric robustness under domain shift to real CXR data and better sample efficiency for novel tasks.
What carries the argument
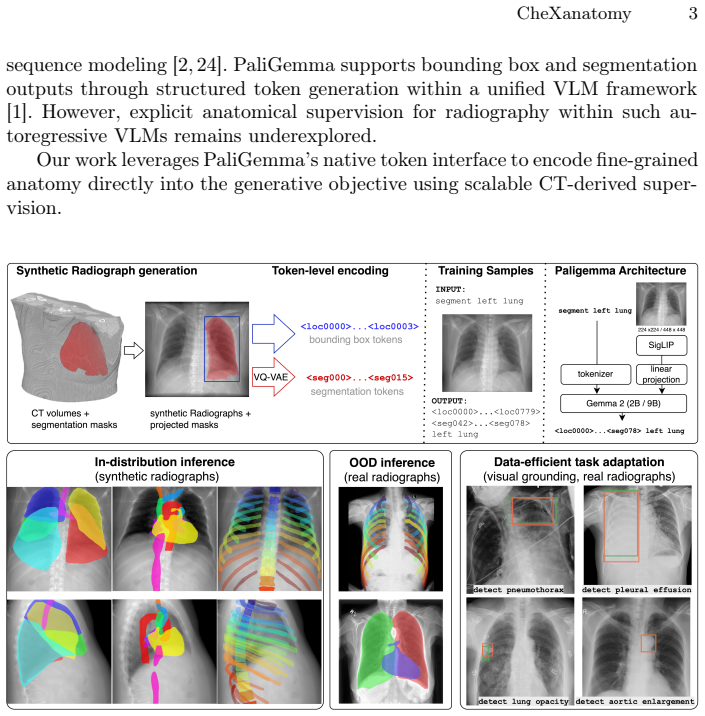
autoregressive token-space supervision, where the model generates anatomical segmentation masks through next-token prediction instead of using task-specific decoder heads
Load-bearing premise
Forward-projected CT segmentation labels create supervision signals that are anatomically accurate and close enough in distribution to real chest radiographs for the representations to transfer effectively.
What would settle it
A direct comparison showing that a model trained only on the synthetic data underperforms a standard U-Net by a large margin on segmentation of real chest radiographs would falsify the transfer claim.
Figures
read the original abstract
Vision-language models (VLMs) pretrained on large-scale image-text pairs demonstrate strong image-level understanding, but are primarily optimized for global alignment and do not explicitly encode fine-grained anatomical structure, limiting their suitability for spatially precise tasks such as segmentation. We introduce CheXanatomy, a framework that integrates explicit anatomical knowledge into a pretrained VLM through autoregressive token-space supervision. Instead of adding task-specific decoder heads, the model is trained to generate anatomical segmentation masks via next-token prediction. To enable scalable supervision, we synthesize realistic chest radiographs from CT volumes and forward-project CT segmentation labels to obtain anatomically consistent 2D masks. We evaluate the approach on synthetic and real chest radiographs against a U-Net baseline, including ablations on model scale, input resolution, and vision encoder fine-tuning. Autoregressive anatomical supervision achieves performance comparable to specialized convolutional models in-distribution and demonstrates improved geometric robustness under domain shift to real CXR data. In addition, anatomy-pretrained models exhibit improved sample efficiency when adapting to novel localization tasks under limited supervision. Larger models and higher input image resolution improve performance, while vision encoder fine-tuning has limited effect. These results show that embedding anatomical structure directly into the generative objective promotes spatially grounded representations and supports anatomy-aware medical vision-language modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CheXanatomy, a framework that integrates explicit anatomical knowledge into pretrained vision-language models for chest radiographs via autoregressive next-token prediction of segmentation masks. Supervision is obtained by synthesizing radiographs from CT volumes and forward-projecting CT segmentation labels into 2D masks. The model is evaluated against a U-Net baseline on both synthetic and real CXR data, with ablations on model scale, input resolution, and vision-encoder fine-tuning. The central claims are that autoregressive anatomical supervision yields performance comparable to specialized convolutional models in-distribution, improved geometric robustness under domain shift to real CXR, and better sample efficiency when adapting to novel localization tasks under limited supervision.
Significance. If the empirical claims hold after verification of the synthetic-to-real transfer, the work would advance anatomy-aware medical VLMs by demonstrating that generative supervision on projected anatomical labels can produce spatially grounded representations without task-specific decoder heads. This could improve robustness and few-shot efficiency for localization tasks in medical imaging while leveraging scalable synthetic supervision.
major comments (2)
- [Abstract and data-synthesis description] Abstract and data-synthesis description: the central claims of comparable in-distribution performance and improved geometric robustness under domain shift rest on the unverified assumption that forward-projected CT segmentation labels produce supervision signals that are both anatomically accurate and distributionally close to real chest radiographs. No quantitative measures of domain gap (e.g., intensity histogram divergence, projection artifact analysis) or failure-mode examination are reported, which directly undermines the transfer and robustness assertions.
- [Evaluation section] Evaluation section: the abstract asserts 'performance comparable to specialized convolutional models' and 'improved geometric robustness' yet supplies no quantitative metrics, error bars, Dice/IoU scores, or ablation tables, leaving the strength of the central empirical claims impossible to assess from the provided description.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., Dice score or robustness delta) to support the performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of the synthetic data pipeline and clearer presentation of quantitative results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and data-synthesis description] Abstract and data-synthesis description: the central claims of comparable in-distribution performance and improved geometric robustness under domain shift rest on the unverified assumption that forward-projected CT segmentation labels produce supervision signals that are both anatomically accurate and distributionally close to real chest radiographs. No quantitative measures of domain gap (e.g., intensity histogram divergence, projection artifact analysis) or failure-mode examination are reported, which directly undermines the transfer and robustness assertions.
Authors: We agree that explicit quantitative characterization of the synthetic-to-real domain gap would strengthen the manuscript. The current version relies on downstream performance on real CXR data as evidence of successful transfer and robustness, but does not report intensity histogram divergence, projection artifact statistics, or a dedicated failure-mode analysis of the forward-projection process. In revision we will add these analyses, including side-by-side intensity distribution comparisons and qualitative examples of projection artifacts. revision: yes
-
Referee: [Evaluation section] Evaluation section: the abstract asserts 'performance comparable to specialized convolutional models' and 'improved geometric robustness' yet supplies no quantitative metrics, error bars, Dice/IoU scores, or ablation tables, leaving the strength of the central empirical claims impossible to assess from the provided description.
Authors: The full manuscript contains the requested quantitative results: Dice and IoU scores with standard-error bars across multiple runs, direct comparisons against the U-Net baseline on both synthetic and real data, and ablation tables for model scale, input resolution, and vision-encoder fine-tuning. These appear in the Evaluation section with accompanying figures and tables. The abstract follows the conventional practice of summarizing findings at a high level without numerical values. We can expand the abstract to include key metrics if the editor prefers. revision: partial
Circularity Check
No circularity; external CT supervision and standard eval keep claims independent
full rationale
The paper trains a VLM on forward-projected CT segmentations to generate 2D masks autoregressively, then evaluates transfer to real CXR and few-shot tasks. No equations, fitted parameters, or self-citations reduce the reported performance, robustness, or sample-efficiency gains to quantities defined inside the paper. Supervision originates from independent CT volumes; evaluation uses held-out synthetic and real data. This matches the default non-circular case.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Forward projection of CT segmentation labels yields 2D masks that are anatomically consistent and sufficiently representative of real chest radiograph anatomy for model training and transfer.
Reference graph
Works this paper leans on
-
[1]
PaliGemma: A versatile 3B VLM for transfer
Beyer, L., Steiner, A., Susano Pinto, A., Kolesnikov, A., Wang, X., Salz, D., Neu- mann, M., Alabdulmohsin, I., Tschannen, M., Bugliarello, E., Unterthiner, T., Keysers, D., Koppula, S., Liu, F., Grycner, A., Gritsenko, A., Houlsby, N., Kumar, M., Rong, K., Eisenschlos, J., Kabra, R., Bauer, M., Bošnjak, M., Chen, X., Min- derer, M., Voigtlaender, P., Bic...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [2]
-
[3]
Deperrois, N., Matsuo, H., Ruipérez-Campillo, S., Vandenhirtz, M., Laguna, S., Ryser, A., Fujimoto, K., Nishio, M., Sutter, T., Vogt, J.E., Kluckert, J., Frauen- felder, T., Blüthgen, C., Nooralahzadeh, F., Krauthammer, M.: RadVLM: A mul- titask conversational vision-language model for chest x-ray interpretation (2025), https://arxiv.org/abs/2502.03333
-
[4]
Dong, Z., Wu, W., Hao, J., Chen, T., Weng, Z., Zhou, B.: AnyCXR: Human anatomy segmentation of chest x-ray at any acquisition position using multi-stage domain randomized synthetic data with imperfect annotations and conditional joint annotation regularization learning (2025), https://arxiv.org/abs/2512.17263
-
[5]
Scientific Data11(1), 511 (2024)
Gaggion, N., Mosquera, C., Mansilla, L., Saidman, J.M., Aineseder, M., Milone, D.H., Ferrante, E.: CheXmask: a large-scale dataset of anatomical segmentation masks for multi-center chest x-ray images. Scientific Data11(1), 511 (2024). https://doi.org/10.1038/s41597-024-03358-1
-
[6]
Medical Image Analysis10(1), 19–40 (2006)
van Ginneken, B., Stegmann, M.B., Loog, M.: Segmentation of anatomi- cal structures in chest radiographs using supervised methods: A comparative study on a public database. Medical Image Analysis10(1), 19–40 (2006). https://doi.org/10.1016/j.media.2005.02.002
-
[7]
Gopalakrishnan, V., Golland, P.: Fast auto-differentiable digitally reconstructed radiographs for solving inverse problems in intraoperative imaging. In: Clinical Image-Based Procedures: 11th Workshop, CLIP 2022, Held in Conjunction with MICCAI 2022, Singapore, September 18, 2022, Proceedings. pp. 1–11. Springer- Verlag, Berlin, Heidelberg (2022). https:/...
-
[8]
Hamamci, I.E., Er, S., Almas, F., Simsek, A.G., Esirgun, S.N., Dogan, I., Das- delen, M.F., Durugol, O.F., Wittmann, B., Amiranashvili, T., Simsar, E., Sim- sar, M., Erdemir, E.B., Alanbay, A., Sekuboyina, A., Lafci, B., Bluethgen, C., Ozdemir, M.K., Menze, B.: Generalist foundation models from a multimodal dataset for 3D computed tomography. Nature Biome...
-
[9]
arXiv preprint arXiv:2406.03688 (2024)
Hou, B., Zhu, Q., Mathai, T.S., Jin, Q., Lu, Z., Summers, R.M.: Shadow and light: Digitally reconstructed radiographs for disease classification. arXiv preprint arXiv:2406.03688 (2024)
-
[10]
In: International Conference on Learning Representations (2022), https://openreview.net/forum?id=nZeVKeeFYf9
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language mod- els. In: International Conference on Learning Representations (2022), https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[11]
Isensee, F., Jaeger, P.F., Kohl, S.A.A., Petersen, J., Maier-Hein, K.H.: nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature Methods (2021). https://doi.org/10.1038/s41592-020-01008-z
-
[12]
Kirillov, A., et al.: Segment anything (2023), https://arxiv.org/abs/2304.02643 CheXanatomy 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [13]
-
[14]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023)
Liu, J., Zhang, Y., Chen, J.N., Xiao, J., Lu, Y., Landman, B.A., Yuan, Y., Yuille, A., Tang, Y., Zhou, Z.: CLIP-driven universal model for organ segmentation and tumor detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023)
2023
- [15]
-
[16]
arXiv preprint (2021), https://arxiv.org/abs/2107.01327, arXiv:2107.01327
Nguyen, H.C., Le, T.T., Pham, H.H., Nguyen, H.Q.: VinDr-RibCXR: A benchmark dataset for automatic segmentation and labeling of individual ribs on chest x-rays. arXiv preprint (2021), https://arxiv.org/abs/2107.01327, arXiv:2107.01327
-
[17]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021), https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Riviere, M., Pathak, S., Sessa, P.G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ramé, A., Ferret, J., Liu, P., Tafti, P., Friesen, A., Casbon, M., Ramos, S., Kumar, R., Le Lan, C., Jerome, S., Tsitsulin, A., Vieillard, N., Stanczyk, P., Girgin, S., Momchev, N., Hoffman, M., Thakoor, S., et al.: Gemma 2: Improving open language...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional networks for biomed- ical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. Springer (2015), https://arxiv.org/abs/1505.04597
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [20]
-
[21]
In: British Machine Vi- sion Conference (BMVC) (2022), https://bmvc2022.mpi-inf.mpg.de/0058.pdf
Seibold, C.M., Reiß, S., Sarfraz, M.S., Fink, M.A., Mayer, V., Sellner, J., Kim, M.S., Maier-Hein, K.H., Kleesiek, J., Stiefelhagen, R.: Detailed annotations of chest x-rays via ct projection for report understanding. In: British Machine Vi- sion Conference (BMVC) (2022), https://bmvc2022.mpi-inf.mpg.de/0058.pdf
2022
-
[22]
PaliGemma 2: A Family of Versatile VLMs for Transfer
Steiner, A., Susano Pinto, A., Tschannen, M., Keysers, D., Wang, X., Bitton, Y., Gritsenko,A.,Minderer,M.,Sherbondy,A.,Long,S.,Qin,S.,Ingle,R.,Bugliarello, E., Kazemzadeh, S., Mesnard, T., Alabdulmohsin, I., Beyer, L., et al.: PaliGemma 2: A family of versatile vision–language models for transfer. arXiv preprint (2024), https://arxiv.org/abs/2412.03555, a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Nature Biomedical Engineering6, 1399–1406 (2022)
Tiu, E., Talius, E., Patel, P., Langlotz, C.P., Ng, A.Y., Rajpurkar, P.: Expert-level detection of pathologies from unannotated chest x-ray images via self-supervised learning. Nature Biomedical Engineering6, 1399–1406 (2022). https://doi.org/10.1038/s41551-022-00936-9
- [24]
-
[25]
Radiology: Artificial Intelligence (Jul 2023), https://pubs.rsna.org/doi/10.1148/ryai.230024
Wasserthal, J., Meyer, M., Hanneman, K., et al.: TotalSegmentator: ro- bust segmentation of 104 anatomical structures in ct images. Radiology: Ar- tificial Intelligence5(5), e230024 (2023). https://doi.org/10.1148/ryai.230024, https://arxiv.org/abs/2208.05868
-
[26]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 11975–11986 (October 2023) 12 S. Gatidis et al
2023
- [27]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.