Titans-as-a-Layer: Test-Time Memory for Conversational Speech Emotion Recognition
Pith reviewed 2026-06-27 18:27 UTC · model grok-4.3
The pith
Test-time neural memory supplies per-dialogue context to audio LLMs for conversational speech emotion recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
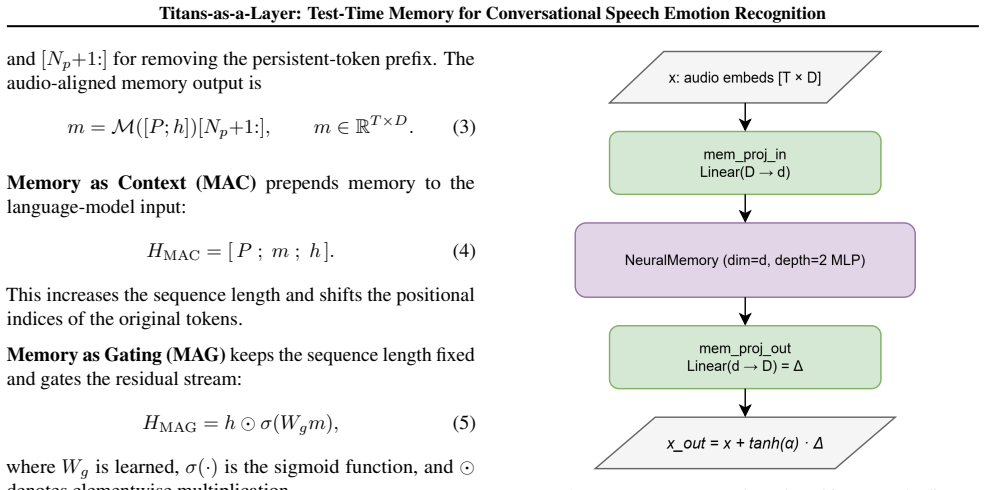
The central claim is that a Memory-as-a-Layer (MAL) adapter can be inserted into existing audio language models to improve conversational speech emotion recognition by storing dialogue history in a compact neural memory and retrieving it as a residual update aligned with the model's audio tokens, without any modification to the host model's parameters or token sequence.
What carries the argument
The Memory-as-a-Layer (MAL) adapter that writes dialogue history into neural memory and reads it as an audio-token-aligned residual update to the frozen audio LLM.
If this is right
- SER accuracy and related metrics improve on multiple datasets when the adapter is added.
- The gains hold across different pretrained audio LLMs without retraining their backbones.
- Test-time memory functions as a residual contextual mechanism for conversational emotion.
- The adapter requires no changes to the host model's token positions or architecture.
Where Pith is reading between the lines
- The same residual-memory pattern could be tested on other dialogue tasks such as turn-taking prediction or speaker diarization.
- It may reduce the need for full-model fine-tuning when new conversational context is required.
- Real-time deployment would require checking whether the memory read/write overhead stays low enough for live audio streams.
- Similar adapters might transfer to non-audio modalities that also suffer from missing dialogue state.
Load-bearing premise
A small neural memory written and read as an audio-token-aligned residual update can effectively supply the missing per-dialogue emotional context.
What would settle it
An experiment in which the MAL adapter produces no gain, or a loss, in SER accuracy or other metrics on conversational datasets relative to the unmodified audio LLM baseline.
Figures
read the original abstract
Speech emotion recognition (SER) is commonly formulated as utterance-level classification, although conversational emotion depends on a speaker's usual vocal range and the emotional context established by previous utterances. Speech-language models provide strong pretrained acoustic and semantic representations, and can adapts them to SER labels via finetune, but this mechanism still missing per-dialogue state. We study whether test-time neural memory can supply this missing context while leaving the large audio language models (LALMs) backbone intact. Building on Titans, we introduce a plug-and-play Memory-as-a-Layer (MAL) adapter that writes dialogue history into a small neural memory and reads it back as an audio-token-aligned residual update, avoiding changes to the host model's token positions. Across different audio LLMs and emotion recognition datasets evaluations, our design improves SER performs across different evaluation metrics, supporting test-time memory as a residual contextual mechanism for conversational SER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a plug-and-play Memory-as-a-Layer (MAL) adapter, built on the Titans architecture, that supplies test-time neural memory to large audio language models (LALMs) for conversational speech emotion recognition (SER). Dialogue history is written to a small neural memory and read back as an audio-token-aligned residual update; the LALM backbone and its token positions remain unchanged. The central claim is that this yields measurable SER gains across models and datasets, demonstrating test-time memory as an effective residual contextual mechanism.
Significance. If the empirical gains are substantiated with proper controls, the contribution would be meaningful for adapting frozen LALMs to dialogue-level tasks. The residual, token-aligned design offers a lightweight way to inject per-dialogue state without retraining or repositioning tokens, which aligns with practical constraints in large-model deployment. The approach could generalize beyond SER to other conversational audio tasks.
major comments (1)
- Abstract: The assertion that 'our design improves SER performs across different evaluation metrics' is presented without any quantitative results, baselines, datasets, error bars, or ablation studies. Because the central claim is purely empirical, the absence of this evidence in the manuscript prevents assessment of whether the claimed gains are real or statistically meaningful.
minor comments (4)
- Abstract, line 3: 'can adapts them' should be 'can adapt them'.
- Abstract, line 4: 'this mechanism still missing' should be 'this mechanism still misses'.
- Abstract, line 7: 'improves SER performs' should be 'improves SER performance'.
- Abstract, line 8: 'Across different audio LLMs and emotion recognition datasets evaluations' is grammatically awkward and should be rephrased for clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the recommendation for major revision. We address the single major comment below and will incorporate the suggested changes.
read point-by-point responses
-
Referee: Abstract: The assertion that 'our design improves SER performs across different evaluation metrics' is presented without any quantitative results, baselines, datasets, error bars, or ablation studies. Because the central claim is purely empirical, the absence of this evidence in the manuscript prevents assessment of whether the claimed gains are real or statistically meaningful.
Authors: We agree that the abstract as currently written does not include the quantitative evidence needed to substantiate the central empirical claim. The full manuscript reports results across multiple LALMs and SER datasets with baseline comparisons, but these details are absent from the abstract. We will revise the abstract to include specific quantitative improvements (e.g., absolute gains in accuracy or F1 on named datasets and models), along with references to the relevant experimental sections, tables, and figures. This revision will make the abstract self-contained for assessing the claimed gains. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an empirical adapter (MAL) built on prior Titans work and evaluates it via experiments on SER datasets and audio LLMs. No equations, parameter fits, derivations, or load-bearing self-citations appear in the abstract or described mechanism; the central claim is that the residual memory update yields measurable gains, presented as an outcome of the design rather than a quantity defined from or reduced to its own inputs. The approach is self-contained as an engineering modification whose validity rests on external benchmarks, not internal redefinition or fitted predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2512.02716 , year=
Menta: A Small Language Model for On-Device Mental Health Prediction , author=. arXiv preprint arXiv:2512.02716 , year=
-
[2]
arXiv preprint arXiv:2507.08031 , year=
Beyond scale: Small language models are comparable to gpt-4 in mental health understanding , author=. arXiv preprint arXiv:2507.08031 , year=
-
[3]
Titans: Learning to Memorize at Test Time
Titans: Learning to Memorize at Test Time , author =. arXiv preprint arXiv:2501.00663 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Proceedings of the 40th International Conference on Machine Learning , pages =
Robust Speech Recognition via Large-Scale Weak Supervision , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , organization =
2023
-
[5]
The Llama 3 Herd of Models , author =. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
-
[7]
Jamba: A Hybrid Transformer-Mamba Language Model
Jamba: A Hybrid Transformer-Mamba Language Model , author =. arXiv preprint arXiv:2403.19887 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models , author =. arXiv preprint arXiv:2402.19427 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
and Lee, Sungbok and Narayanan, Shrikanth S
Busso, Carlos and Bulut, Murtaza and Lee, Chi-Chun and Kazemzadeh, Abe and Mower, Emily and Kim, Samuel and Chang, Jeannette N. and Lee, Sungbok and Narayanan, Shrikanth S. , journal =. 2008 , publisher =
2008
-
[10]
International Conference on Learning Representations (ICLR) , year =
Towards a Unified View of Parameter-Efficient Transfer Learning , author =. International Conference on Learning Representations (ICLR) , year =
-
[11]
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , pages =
Pfeiffer, Jonas and Kamath, Aishwarya and R. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , pages =
-
[12]
2024 , howpublished =
Ultravox: An Open-Source Speech--Language Model , author =. 2024 , howpublished =
2024
-
[13]
Kong, Zhifeng and Goel, Arushi and Badlani, Rohan and Ping, Wei and Valle, Rafael and Catanzaro, Bryan , booktitle =. Audio
-
[14]
Kong, Zhifeng and Goel, Arushi and Ghosh, Sreyan and Majumder, Sonal and Badlani, Rohan and Ping, Wei and Valle, Rafael and Catanzaro, Bryan , journal =. Audio
-
[15]
Goel, Arushi and Ghosh, Sreyan and Kim, Jaehyeon and Kong, Zhifeng and Kumar, Sang-gil and Lee, Sang-gil and Valle, Rafael and Ping, Wei and Catanzaro, Bryan , journal =. Audio
-
[16]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio--Language Models , author =. arXiv preprint arXiv:2311.07919 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Qwen2-Audio Technical Report , author =. arXiv preprint arXiv:2407.10759 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Tang, Changli and Yu, Wenyi and Sun, Guangzhi and Chen, Xianzhao and Tan, Tian and Li, Wei and Lu, Lu and Ma, Zejun and Zhang, Chao , booktitle =
-
[19]
and Luo, Hongyin and Karlinsky, Leonid and Glass, James , booktitle =
Gong, Yuan and Liu, Alexander H. and Luo, Hongyin and Karlinsky, Leonid and Glass, James , booktitle =
-
[20]
and Salakhutdinov, Ruslan , booktitle =
Dai, Zihang and Yang, Zhilin and Yang, Yiming and Carbonell, Jaime and Le, Quoc V. and Salakhutdinov, Ruslan , booktitle =
-
[21]
International Conference on Learning Representations (ICLR) , year =
Compressive Transformers for Long-Range Sequence Modelling , author =. International Conference on Learning Representations (ICLR) , year =
-
[22]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Recurrent Memory Transformer , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[23]
International Conference on Learning Representations (ICLR) , year =
Memorizing Transformers , author =. International Conference on Learning Representations (ICLR) , year =
-
[24]
Leave No Context Behind: Efficient Infinite Context Transformers with
Munkhdalai, Tsendsuren and Faruqui, Manaal and Gopal, Siddharth , journal =. Leave No Context Behind: Efficient Infinite Context Transformers with
-
[25]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author =. arXiv preprint arXiv:2312.00752 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
Gated Linear Attention Transformers with Hardware-Efficient Training , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[27]
arXiv preprint arXiv:2510.09551 , year =
Titans Revisited: A Lightweight Reimplementation and Critical Analysis of a Test-Time Memory Model , author =. arXiv preprint arXiv:2510.09551 , year =
-
[28]
2025 , url =
Park, Young-Jae and Seo, Minseok and Jeon, Hae-Gon , booktitle =. 2025 , url =
2025
-
[29]
2025 , howpublished =
Audio. 2025 , howpublished =
2025
-
[30]
and Li, Haizhou , journal =
Chen, Yiming and Yue, Xianghu and Zhang, Chen and Gao, Xiaoxue and Tan, Robby T. and Li, Haizhou , journal =
-
[31]
Poria, Soujanya and Hazarika, Devamanyu and Majumder, Navonil and Naik, Gautam and Cambria, Erik and Mihalcea, Rada , booktitle =
-
[32]
Majumder, Navonil and Poria, Soujanya and Hazarika, Devamanyu and Mihalcea, Rada and Gelbukh, Alexander and Cambria, Erik , booktitle =
-
[33]
Ghosal, Deepanway and Majumder, Navonil and Poria, Soujanya and Chhaya, Niyati and Gelbukh, Alexander , booktitle =
-
[34]
and Scher, Sebastian and Weyn, Jonathan A
Rasp, Stephan and Dueben, Peter D. and Scher, Sebastian and Weyn, Jonathan A. and Mouatadid, Soukayna and Thuerey, Nils , journal =. 2020 , publisher =
2020
-
[35]
Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , publisher =. doi:10.18653/v1/2024.acl-long.860 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.