PhysGraph: A Physics-aware 3D Scene Graph for Perception and Reasoning
Pith reviewed 2026-06-27 18:12 UTC · model grok-4.3
The pith
PhysGraph builds 3D scene graphs that include physical properties like mass and articulation from RGB-D observations in cluttered scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
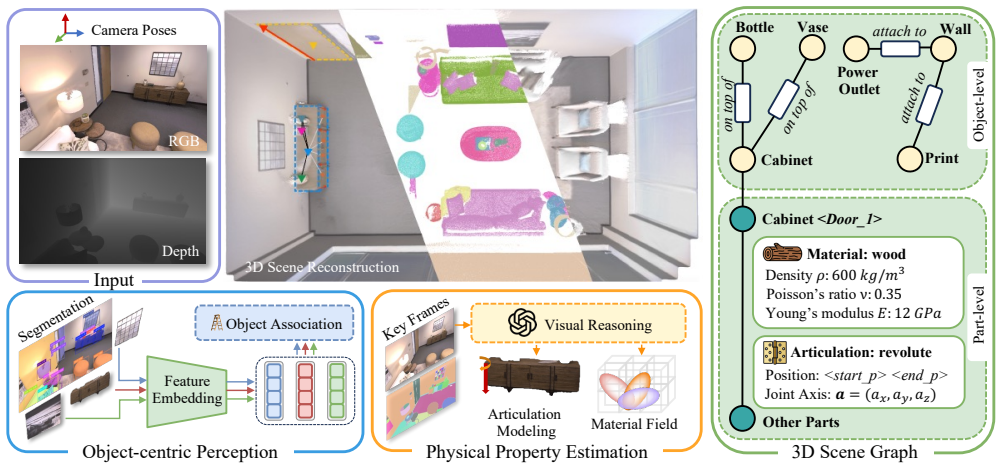
PhysGraph unifies symbolic reasoning with structured 3D geometry to model kinematic and physical properties in cluttered scenes. Given RGB-D observations, it reconstructs object-centric 3D geometry and associates object instances across views. It then decomposes objects into functional parts and infers materials and articulations through visual reasoning. Evaluated on both synthetic and real-world datasets, PhysGraph achieves state-of-the-art results in semantic segmentation, multi-object mass estimation, and articulation prediction, and supports downstream tasks such as constraint-aware 3D affordance prediction and real-to-sim transfer.
What carries the argument
The PhysGraph pipeline of object-centric 3D reconstruction from RGB-D, cross-view instance association, functional part decomposition, and visual inference of materials and articulations to form structured scene graphs.
If this is right
- The scene graphs support constraint-aware 3D affordance prediction for task planning.
- They enable real-to-sim transfer as demonstrated in the experiments.
- A single model handles semantic segmentation, multi-object mass estimation, and articulation prediction together.
- Object instances remain consistent across multiple views while physical properties are attached.
- The representation scales to cluttered scenes with varied object types.
Where Pith is reading between the lines
- The same structured output could initialize simulations with inferred physical parameters rather than manual setup.
- Downstream planners that use the graphs might avoid actions that violate inferred joint limits or material constraints.
- Extending the visual inference step to video input could capture time-varying articulations without additional sensors.
Load-bearing premise
Visual reasoning from RGB-D observations alone can accurately infer materials and articulations for diverse object types in cluttered scenes without narrow training sets or single-object modeling.
What would settle it
A test set of real cluttered scenes containing objects with matching appearances but different densities or joint types where the system's mass estimates or articulation predictions show large errors against ground-truth measurements.
Figures




read the original abstract
To perform a wide range of daily tasks, robots need to construct a 3D representation that is semantically rich, physically grounded, and structured enough to support task planning and affordance prediction. However, existing approaches primarily focus on semantic retrieval, often overlooking physical and kinematic factors. Methods that attempt to model physical properties typically rely on narrow training sets or single-object modeling, limiting scalability and generalization across diverse object types. To address these challenges, we present PhysGraph, a framework that unifies symbolic reasoning with structured 3D geometry to model kinematic and physical properties in cluttered scenes. Given RGB-D observations, PhysGraph reconstructs object-centric 3D geometry and associates object instances across views. It then decomposes objects into functional parts and infers materials and articulations through visual reasoning. Evaluated on both synthetic and real-world datasets, PhysGraph achieves state-of-the-art results in semantic segmentation, multi-object mass estimation, and articulation prediction. With its simple yet effective design, PhysGraph produces physically consistent and semantically structured scene graphs, serving as a structured 3D representation for downstream tasks such as constraint-aware 3D affordance prediction and real-to-sim transfer, both of which are demonstrated in our experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PhysGraph, a framework that builds a physics-aware 3D scene graph from RGB-D observations. It reconstructs object-centric geometry, associates instances across views, decomposes objects into functional parts, and uses visual reasoning to infer materials, articulations, and mass. The central claims are state-of-the-art performance in semantic segmentation, multi-object mass estimation, and articulation prediction on synthetic and real datasets, plus demonstrations of downstream uses in constraint-aware affordance prediction and real-to-sim transfer.
Significance. If the quantitative claims hold with proper baselines and error bars, the work would offer a scalable, object-centric representation that integrates semantic structure with physical properties, addressing limitations of narrow training sets or single-object models in robotics. The design choices (object-centric reconstruction plus part decomposition) align with standard practices, and the downstream applications are consistent with the representation. No machine-checked proofs or parameter-free derivations are present; the contribution is primarily empirical and engineering-oriented.
major comments (1)
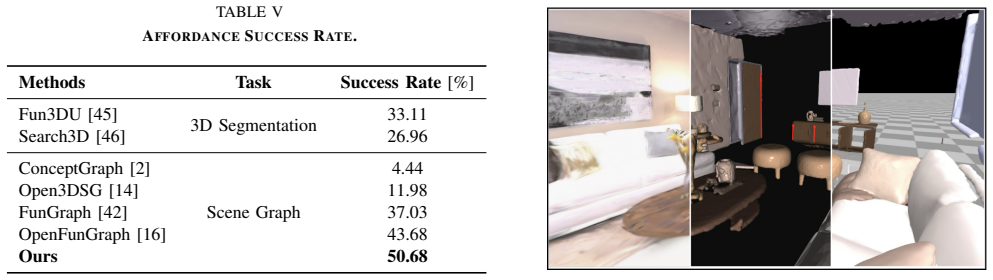
- [Abstract] Abstract: The claims of state-of-the-art results in semantic segmentation, multi-object mass estimation, and articulation prediction are presented without any description of methods, baselines, quantitative metrics, error bars, or dataset details. This absence makes the central empirical claims unverifiable from the provided text and is load-bearing for the paper's primary contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below regarding the abstract.
read point-by-point responses
-
Referee: The claims of state-of-the-art results in semantic segmentation, multi-object mass estimation, and articulation prediction are presented without any description of methods, baselines, quantitative metrics, error bars, or dataset details. This absence makes the central empirical claims unverifiable from the provided text and is load-bearing for the paper's primary contribution.
Authors: We acknowledge that the abstract is high-level and omits specific methodological details, baselines, metrics, error bars, and dataset information, as is conventional for abstracts due to strict length constraints. The full manuscript substantiates all claims with complete descriptions: methods in Section 3, baselines/quantitative metrics/error bars in Section 4 (including Tables 1-3 and Figures 4-6), and dataset details in Section 4.1. The claims are therefore verifiable from the manuscript body. We disagree that the abstract itself must contain these elements to support the contribution, but we can partially revise the abstract to include one additional sentence referencing key metrics (e.g., mIoU improvements) if the editor permits. revision: partial
Circularity Check
No significant circularity
full rationale
The provided abstract and high-level description contain no equations, derivations, fitted parameters, or predictions that could reduce to inputs by construction. The framework is described as a pipeline of reconstruction, part decomposition, and visual reasoning from RGB-D data, with SOTA claims resting on empirical evaluation rather than any self-referential mathematical step. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing way within the given text. The derivation chain is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural fields in robotics: A survey,
M. Z. Irshad, M. Comi, Y .-C. Lin, N. Heppert, A. Valada, R. Ambrus, Z. Kira, and J. Tremblay, “Neural fields in robotics: A survey,” arXiv:2410.20220, 2024
-
[2]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappaet al., “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,”ICRA, 2024
2024
-
[3]
Conceptfusion: Open-set multimodal 3d mapping,
K. M. Jatavallabhula, A. Kuwajerwala, Q. Gu, M. Omama, T. Chen, S. Li, G. Iyer, S. Saryazdi, N. Keetha, A. Tewari, J. B. Tenenbaum, C. M. de Melo, M. Krishna, L. Paull, F. Shkurti, and A. Torralba, “Conceptfusion: Open-set multimodal 3d mapping,”RSS, 2023
2023
-
[4]
Iaao: Interactive affordance learning for articulated objects in 3d environments,
C. Zhang and G. H. Lee, “Iaao: Interactive affordance learning for articulated objects in 3d environments,”CVPR, 2025
2025
-
[5]
Physical property understanding from language-embedded feature fields,
A. J. Zhai, Y . Shen, E. Y . Chen, G. X. Wang, X. Wang, S. Wang, K. Guan, and S. Wang, “Physical property understanding from language-embedded feature fields,”CVPR, 2024
2024
-
[6]
Pugs: Zero-shot physical understanding with gaussian splatting,
Y . Shuai, R. Yu, Y . Chen, Z. Jiang, X. Song, N. Wang, J. Zheng, J. Ma, M. Yang, Z. Wanget al., “Pugs: Zero-shot physical understanding with gaussian splatting,”arXiv:2502.12231, 2025
-
[7]
Mobilesamv2: Faster segment anything to everything,
C. Zhang, D. Han, S. Zhenget al., “Mobilesamv2: Faster segment anything to everything,”arXiv:2312.09579, 2023
-
[8]
O. Sim ´eoni, H. V . V o, M. Seitzer,et al., “DINOv3,”arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
(2025, aug) Gpt-5: System card
OpenAI. (2025, aug) Gpt-5: System card
2025
-
[10]
Lang3dsg: Language-based contrastive pre-training for 3d scene graph prediction,
S. Koch, P. Hermosilla, N. Vaskevicius, M. Colosi, and T. Ropinski, “Lang3dsg: Language-based contrastive pre-training for 3d scene graph prediction,”3DV, 2024
2024
-
[11]
3d scene graph: A structure for unified semantics, 3d space, and camera,
I. Armeni, Z.-Y . He, J. Gwak, A. R. Zamir, M. Fischer, J. Malik, and S. Savarese, “3d scene graph: A structure for unified semantics, 3d space, and camera,”ICCV, 2019
2019
-
[12]
arXiv preprint arXiv:2002.06289 (2020)
A. Rosinol, A. Gupta, M. Abate, J. Shi, and L. Carlone, “3d dynamic scene graphs: Actionable spatial perception with places, objects, and humans,”arXiv:2002.06289, 2020
-
[13]
Ifr-explore: Learning inter-object functional relationships in 3d indoor scenes,
Q. Li, K. Mo, Y . Yang, H. Zhao, and L. Guibas, “Ifr-explore: Learning inter-object functional relationships in 3d indoor scenes,” arXiv:2112.05298, 2021
-
[14]
Open3dsg: Open-vocabulary 3d scene graphs from point clouds with queryable objects and open-set relationships,
S. Koch, N. Vaskevicius, M. Colosi, P. Hermosilla, and T. Ropinski, “Open3dsg: Open-vocabulary 3d scene graphs from point clouds with queryable objects and open-set relationships,”CVPR, 2024
2024
-
[15]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,”ICML, 2021
2021
-
[16]
Open-vocabulary functional 3d scene graphs for real- world indoor spaces,
C. Zhang, A. Delitzas, F. Wang, R. Zhang, X. Ji, M. Pollefeys, and F. Engelmann, “Open-vocabulary functional 3d scene graphs for real- world indoor spaces,”CVPR, 2025
2025
-
[17]
Rgb-d local implicit function for depth completion of transparent objects,
L. Zhu, A. Mousavian, Y . Xiang, H. Mazhar, J. van Eenbergen, S. Debnath, and D. Fox, “Rgb-d local implicit function for depth completion of transparent objects,”CVPR, 2021
2021
-
[18]
Clip-fields: Weakly supervised semantic fields for robotic memory,
N. M. M. Shafiullah, C. Paxton, L. Pinto, S. Chintala, and A. Szlam, “Clip-fields: Weakly supervised semantic fields for robotic memory,” arXiv:2210.05663, 2022
-
[19]
Distilled feature fields enable few-shot language-guided manipula- tion,
W. Shen, G. Yang, A. Yu, J. Wong, L. P. Kaelbling, and P. Isola, “Distilled feature fields enable few-shot language-guided manipula- tion,”arXiv:2308.07931, 2023
-
[20]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,”ICCV, 2023
2023
-
[21]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoor- thi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, 2021
2021
-
[22]
Visual affordance and function understanding: A survey,
M. Hassanin, S. Khan, and M. Tahtali, “Visual affordance and function understanding: A survey,”ACM Computing Surveys, 2021
2021
-
[23]
Uad: Unsupervised affordance distillation for generaliza- tion in robotic manipulation,
Y . Tang, W. Huang, Y . Wang, C. Li, R. Yuan, R. Zhang, J. Wu, and L. Fei-Fei, “Uad: Unsupervised affordance distillation for generaliza- tion in robotic manipulation,”arXiv:2506.09284, 2025
-
[24]
ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
W. Huang, C. Wang, Y . Li, R. Zhang, and L. Fei-Fei, “Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation,”arXiv:2409.01652, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Learning dexterous grasping with object-centric visual affordances,
P. Mandikal and K. Grauman, “Learning dexterous grasping with object-centric visual affordances,”ICRA, 2021
2021
-
[26]
Q. Yu, X. Yuan, J. Chenet al., “Artgs: 3d gaussian splatting for interactive visual-physical modeling and manipulation of articulated objects,”arXiv:2507.02600, 2025
-
[27]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.”ACM Transactions on Graphics, 2023
2023
-
[28]
Yolo-world: Real-time open-vocabulary object detection,
T. Cheng, L. Song, Y . Ge, W. Liu, X. Wang, and Y . Shan, “Yolo-world: Real-time open-vocabulary object detection,”CVPR, 2024
2024
-
[29]
A survey on bounding volume hierarchies for ray tracing,
D. Meister, S. Ogaki, C. Benthin, M. J. Doyle, M. Guthe, and J. Bittner, “A survey on bounding volume hierarchies for ray tracing,”Computer Graphics F orum, 2021
2021
-
[30]
Understanding 3d object interaction from a single image,
S. Qian and D. F. Fouhey, “Understanding 3d object interaction from a single image,”ICCV, 2023
2023
-
[31]
The Replica Dataset: A Digital Replica of Indoor Spaces
J. Straub, T. Whelan, L. Maet al., “The replica dataset: A digital replica of indoor spaces,”arXiv:1906.05797, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[32]
Opengaussian: Towards point-level 3d gaussian-based open vocabulary understanding,
Y . Wu, J. Meng, H. Li, C. Wu, Y . Shi, X. Cheng, C. Zhao, H. Feng, E. Ding, J. Wang, and J. Zhang, “Opengaussian: Towards point-level 3d gaussian-based open vocabulary understanding,”NeurIPS, 2024
2024
-
[33]
Langsplat: 3d language gaussian splatting,
M. Qin, W. Li, J. Zhou, H. Wang, and H. Pfister, “Langsplat: 3d language gaussian splatting,”arXiv:2312.16084, 2023
-
[34]
Graspsplats: Efficient manipulation with 3d feature splatting,
M. Ji, R.-Z. Qiu, X. Zou, and X. Wang, “Graspsplats: Efficient manipulation with 3d feature splatting,”arXiv:2409.02084, 2024
-
[35]
Omnimap: A general mapping framework integrating optics, geometry, and semantics,
Y . Deng, Y . Yue, J. Dou, J. Zhao, J. Wang, Y . Tang, Y . Yang, and M. Fu, “Omnimap: A general mapping framework integrating optics, geometry, and semantics,”IEEE Transactions on Robotics, 2025
2025
-
[36]
Open-fusion: Real-time open-vocabulary 3d mapping and queryable scene representation,
K. Yamazaki, T. Hanyu, K. V o, T. Pham, M. Tran, G. Doretto, A. Nguyen, and N. Le, “Open-fusion: Real-time open-vocabulary 3d mapping and queryable scene representation,”ICRA, 2024
2024
-
[37]
Lian Fu, Ryoichi Ishikawa, Yoshihiro Sato, and Takeshi Oishi
Z. Chen, A. Walsman, M. Memmel, K. Mo, A. Fang, K. Vemuri, A. Wu, D. Fox, and A. Gupta, “Urdformer: A pipeline for con- structing articulated simulation environments from real-world images,” arXiv:2405.11656, 2024
-
[38]
Drawer: Digital reconstruction and articulation with environment realism,
H. Xia, E. Su, M. Memmelet al., “Drawer: Digital reconstruction and articulation with environment realism,”CVPR, 2025
2025
-
[39]
Openclip,
G. Ilharco, M. Wortsman, R. Wightman, C. Gordon, N. Carlini, R. Taori, A. Dave, V . Shankar, H. Namkoong, J. Miller, H. Hajishirzi, A. Farhadi, and L. Schmidt, “Openclip,”Zenodo, 2021
2021
-
[40]
C. Li, R. Zhang, J. Wonget al., “Behavior-1k: A human-centered, embodied ai benchmark with 1,000 everyday activities and realistic simulation,”arXiv:2403.09227, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
image2mass: Estimating the mass of an object from its image,
T. Standley, O. Sener, D. Chen, and S. Savarese, “image2mass: Estimating the mass of an object from its image,”CoRL, 2017
2017
-
[42]
Fungraph: Functionality aware 3d scene graphs for language-prompted scene interaction,
D. Rotondi, F. Scaparro, H. Blum, and K. O. Arras, “Fungraph: Functionality aware 3d scene graphs for language-prompted scene interaction,”IROS, 2025
2025
-
[43]
Scenefun3d: Fine-grained functionality and affordance understanding in 3d scenes,
A. Delitzas, A. Takmaz, F. Tombari, R. Sumner, M. Pollefeys, and F. Engelmann, “Scenefun3d: Fine-grained functionality and affordance understanding in 3d scenes,”CVPR, 2024
2024
-
[44]
Multiscan: Scalable rgbd scanning for 3d environments with articulated objects,
Y . Mao, Y . Zhang, H. Jiang, A. Chang, and M. Savva, “Multiscan: Scalable rgbd scanning for 3d environments with articulated objects,” NeurIPS, 2022
2022
-
[45]
Func- tionality understanding and segmentation in 3d scenes,
J. Corsetti, F. Giuliari, A. Fasoli, D. Boscaini, and F. Poiesi, “Func- tionality understanding and segmentation in 3d scenes,”CVPR, 2025
2025
-
[46]
Search3d: Hierarchical open-vocabulary 3d segmenta- tion,
A. Takmaz, A. Delitzas, R. W. Sumner, F. Engelmann, J. Wald, and F. Tombari, “Search3d: Hierarchical open-vocabulary 3d segmenta- tion,”RA-L, 2025
2025
-
[47]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model-based control,”IROS, 2012
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.