PACT: Learning Diverse Diagnostic Strategies via Privileged Synthesis and Branch Consensus
Pith reviewed 2026-06-27 17:12 UTC · model grok-4.3
The pith
PACT trains LLMs on four separate diagnostic reasoning paradigms by synthesizing dialogues from full EMRs and aggregating LoRA branches via sign consensus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Coupling privileged multi-paradigm dialogue synthesis from complete EMRs with periodic anchor consensus training across paradigm-specific LoRA branches enables an LLM to master diverse diagnostic strategies and achieve state-of-the-art results on both diagnostic outcome accuracy and consultation process metrics in interactive Chinese medical diagnosis tasks.
What carries the argument
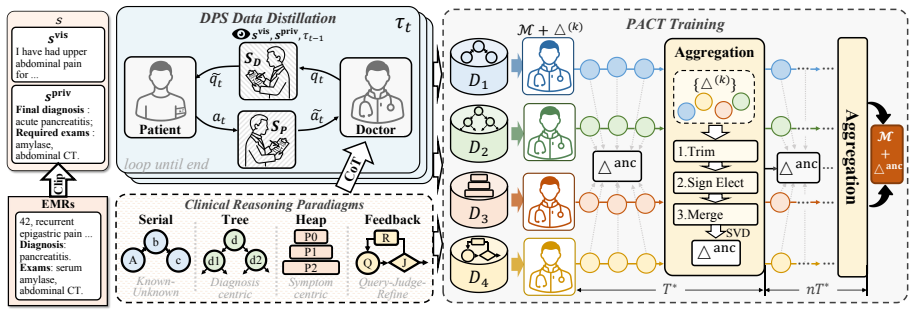
Doctor-Patient-Supervisor (DPS) synthesis that produces validated dialogues under four diagnostic paradigms while restricting the doctor agent to visible information, combined with Periodic Anchor Consensus Training (PACT) that maintains separate LoRA branches and aggregates them into a shared anchor through sign consensus.
If this is right
- Models can switch between reasoning paradigms during a single consultation without performance loss from interference.
- Training data for each paradigm remains isolated yet the final model benefits from all of them through periodic consensus.
- The same synthesis-plus-branch approach applies to any domain where multiple distinct strategies must be learned from privileged full-information sources.
- Consultation-process metrics improve alongside outcome metrics because each branch specializes in a different interaction style.
Where Pith is reading between the lines
- The consensus aggregation step may preserve knowledge across updates better than standard parameter averaging in continual learning settings.
- If the four paradigms prove insufficient for some cases, the branch structure allows adding new ones without retraining the entire model.
- The method's reliance on EMR-derived dialogues suggests a path for scaling to other languages or specialties by swapping the source records.
- Real-world deployment would still require separate validation that synthesized dialogues match the distribution of actual patient questions.
Load-bearing premise
The four diagnostic reasoning paradigms can be cleanly separated and synthesized from complete EMRs without the synthesis process introducing artifacts or correlations that would not exist in real patient interactions.
What would settle it
Run the trained PACT model on a held-out set of live doctor-patient conversations recorded without access to complete EMRs and measure whether its advantage over single-paradigm or naively mixed baselines disappears.
Figures
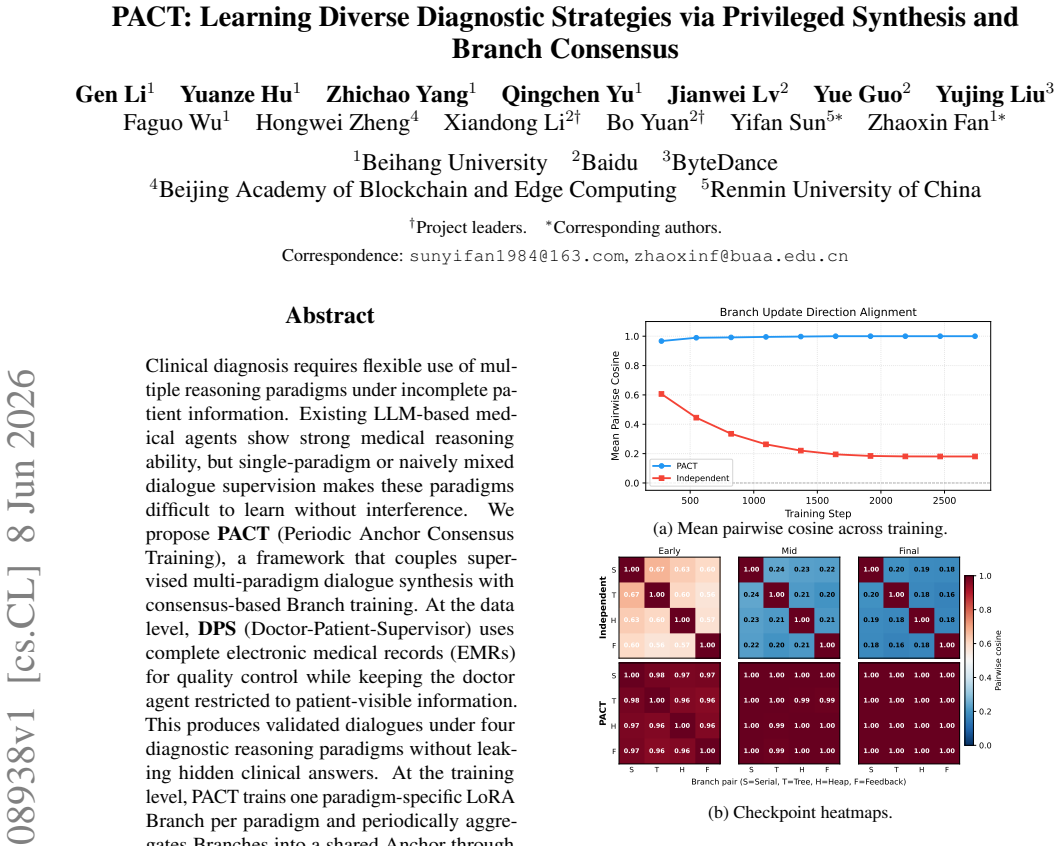

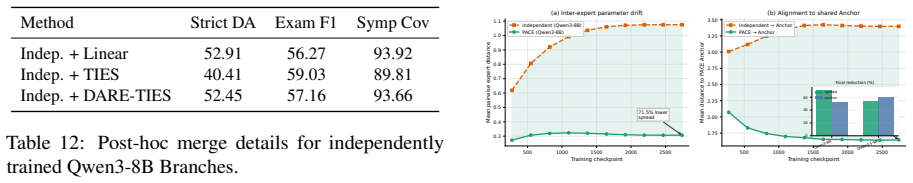
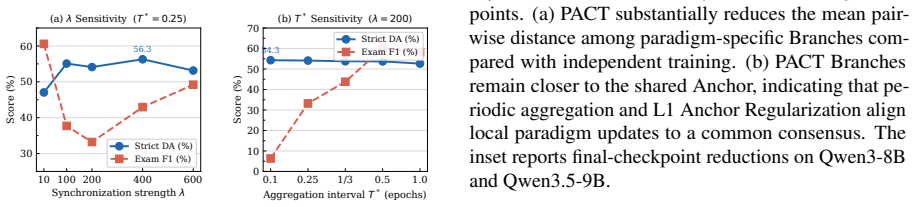
read the original abstract
Clinical diagnosis requires flexible use of multiple reasoning paradigms under incomplete patient information. Existing LLM-based medical agents show strong medical reasoning ability, but single-paradigm or naively mixed dialogue supervision makes these paradigms difficult to learn without interference. We propose \textbf{PACT} (Periodic Anchor Consensus Training), a framework that couples supervised multi-paradigm dialogue synthesis with consensus-based Branch training. At the data level, \textbf{DPS} (Doctor-Patient-Supervisor) uses complete electronic medical records (EMRs) for quality control while keeping the doctor agent restricted to patient-visible information. This produces validated dialogues under four diagnostic reasoning paradigms without leaking hidden clinical answers. At the training level, PACT trains one paradigm-specific LoRA Branch per paradigm and periodically aggregates Branches into a shared Anchor through sign consensus. We further construct a dynamic multi-turn Chinese medical diagnosis benchmark for interactive consultation. Experiments show that PACT achieves state-of-the-art performance among compared proprietary, medical-specialized, and task-adapted baselines on diagnostic outcome and consultation-process metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PACT (Periodic Anchor Consensus Training), a framework coupling DPS (Doctor-Patient-Supervisor) multi-paradigm dialogue synthesis from complete EMRs—with the doctor agent restricted to patient-visible information—with consensus-based training of paradigm-specific LoRA branches that are periodically aggregated into a shared Anchor via sign consensus. A new dynamic multi-turn Chinese medical diagnosis benchmark is constructed, and the paper claims SOTA results on diagnostic outcome and consultation-process metrics versus proprietary, medical-specialized, and task-adapted baselines.
Significance. If the central claims hold after addressing the data-generation concerns, the work would offer a concrete method for training medical LLMs to deploy multiple reasoning paradigms without mutual interference, supported by an explicit synthesis pipeline and a new interactive benchmark. The privileged-synthesis-plus-consensus design is a clear technical contribution; the benchmark itself is a reusable asset for the community.
major comments (2)
- [§3] §3 (DPS synthesis procedure): The claim that the four paradigms are cleanly separable and that generated dialogues contain only patient-visible information is load-bearing for the entire training pipeline and the interpretation of the SOTA results. No post-synthesis audit is reported that quantifies information leakage (e.g., via mutual information between generated turns and hidden EMR fields) or that statistically compares turn-level properties of synthesized versus real incomplete-information dialogues. Without such validation, it remains possible that the training signal contains artifacts unavailable in genuine consultations.
- [Experiments] Experiments section (SOTA tables): The assertion of state-of-the-art performance on both outcome and process metrics requires explicit support via error bars, number of evaluation runs, and statistical significance tests against each baseline class. The current presentation leaves open whether the reported gains are robust or could be explained by differences in prompting, decoding, or evaluation protocol.
minor comments (2)
- Notation for the four paradigms and the Branch/Anchor distinction should be introduced with a single consolidated table or diagram early in the paper to improve readability.
- The benchmark construction details (patient sampling, turn limits, success criteria) would benefit from an explicit pseudocode listing or additional appendix table.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the major comments point-by-point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (DPS synthesis procedure): The claim that the four paradigms are cleanly separable and that generated dialogues contain only patient-visible information is load-bearing for the entire training pipeline and the interpretation of the SOTA results. No post-synthesis audit is reported that quantifies information leakage (e.g., via mutual information between generated turns and hidden EMR fields) or that statistically compares turn-level properties of synthesized versus real incomplete-information dialogues. Without such validation, it remains possible that the training signal contains artifacts unavailable in genuine consultations.
Authors: We agree that an explicit post-synthesis audit would provide stronger evidence for the absence of information leakage. In the revised manuscript, we will add a new subsection in §3 reporting quantitative validation: (1) mutual information estimates between generated dialogue turns and hidden EMR fields, (2) statistical tests comparing turn-level properties (e.g., length, lexical diversity, medical entity density) of synthesized dialogues against a sample of real incomplete-information consultations. This will directly address the separability and no-leakage claims. revision: yes
-
Referee: [Experiments] Experiments section (SOTA tables): The assertion of state-of-the-art performance on both outcome and process metrics requires explicit support via error bars, number of evaluation runs, and statistical significance tests against each baseline class. The current presentation leaves open whether the reported gains are robust or could be explained by differences in prompting, decoding, or evaluation protocol.
Authors: We acknowledge the need for statistical rigor in reporting the SOTA results. In the revised version, we will expand the Experiments section to include: error bars (standard deviation across runs), the number of evaluation runs (we will use at least 5 independent runs with different random seeds), and statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values) comparing PACT against each baseline category. We will also clarify the evaluation protocol to ensure reproducibility. revision: yes
Circularity Check
No circularity detected; derivation is forward and self-contained
full rationale
The paper describes a forward training pipeline (DPS synthesis from EMRs followed by periodic anchor consensus on LoRA branches) whose claimed SOTA outcomes on diagnostic and process metrics are not reduced by any equation or definition to quantities fitted from those same metrics. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the abstract or described procedure; the synthesis and consensus steps remain independent of the final performance numbers they are evaluated against.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report
2023
-
[2]
Judith L Bowen. 2006. Educational strategies to promote clinical diagnostic reasoning. New England Journal of Medicine, 355(21):2217--2225
2006
-
[3]
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. 2024. Huatuogpt-o1, towards medical complex reasoning with llms
2024
- [4]
-
[5]
Pat Croskerry. 2009. A universal model of diagnostic reasoning. Academic medicine, 84(8):1022--1028
2009
-
[6]
Elstein, Lee S
Arthur S. Elstein, Lee S. Shulman, and Sarah A. Sprafka. Medical Problem Solving: An Analysis of Clinical Reasoning
-
[7]
Yichun Feng, Jiawei Wang, Lu Zhou, Zhen Lei, and Yixue Li. 2026. Doctoragent-rl: A multi-agent collaborative reinforcement learning system for multi-turn clinical dialogue. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 16952--16956. IEEE
2026
-
[8]
Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Meyers, Vladimir Karpukhin, Brian Benedict, Mark McQuade, and Jacob Solawetz. 2024. Arcee’s mergekit: A toolkit for merging large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 477--485
2024
-
[9]
Google DeepMind . 2026. Gemini 3.1 Pro model card. https://deepmind.google/models/model-cards/gemini-3-1-pro/. Google DeepMind, February 2026
2026
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Yue Guo, Fanfu Wang, Jianwei Lv, Xincheng Shi, Yuchen Li, Youya Wang, Yunsheng Zeng, Yujing Liu, Yunhao Qiao, Gen Li, and 1 others. 2026. Dr. assistant: Enhancing clinical diagnostic inquiry via structured diagnostic reasoning data and reinforcement learning. arXiv preprint arXiv:2601.13690
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv e-prints, pages arXiv--2106
2021
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. 2022. Editing models with task arithmetic. arXiv preprint arXiv:2212.04089
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Minbyul Jeong, Jiwoong Sohn, Mujeen Sung, and Jaewoo Kang. 2024. Improving medical reasoning through retrieval and self-reflection with retrieval-augmented large language models. Bioinformatics, 40(Supplement\_1):i119--i129
2024
-
[17]
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. 2020. Scaffold: Stochastic controlled averaging for federated learning. In International conference on machine learning, pages 5132--5143. PMLR
2020
- [18]
-
[19]
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. 2020. Federated optimization in heterogeneous networks. Proceedings of Machine learning and systems, 2:429--450
2020
-
[20]
Alexander H Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sad \'e , Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, and 1 others. 2026. Ministral 3. arXiv preprint arXiv:2601.08584
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. 2021. Conflict-averse gradient descent for multi-task learning. Advances in neural information processing systems, 34:18878--18890
2021
-
[22]
Wenge Liu, Jianheng Tang, Yi Cheng, Wenjie Li, Yefeng Zheng, and Xiaodan Liang. 2022. Meddg: an entity-centric medical consultation dataset for entity-aware medical dialogue generation. In CCF International Conference on Natural Language Processing and Chinese Computing, pages 447--459. Springer
2022
-
[23]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pages 1273--1282. Pmlr
2017
-
[24]
Geoffrey Norman. 2005. Research in clinical reasoning: past history and current trends. Medical education, 39(4):418--427
2005
-
[25]
OpenAI . 2025. Introducing GPT-4.1 in the API . https://openai.com/index/gpt-4-1/. OpenAI, April 2025
2025
-
[26]
Stephen G Pauker and Jerome P Kassirer. 1980. The threshold approach to clinical decision making. New England Journal of Medicine, 302(20):1109--1117
1980
-
[27]
Donald A Sch \"o n. 2017. The reflective practitioner: How professionals think in action. Routledge
2017
-
[28]
ByteDance Seed. 2025. Introduction to techniques used in seed1. 6. Online. Accessed, pages 12--21
2025
-
[29]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, and 1 others. 2025. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Mina Valizadeh and Natalie Parde. 2022. The ai doctor is in: A survey of task-oriented dialogue systems for healthcare applications. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6638--6660
2022
-
[31]
Vladimir Vapnik and Akshay Vashist. 2009. A new learning paradigm: Learning using privileged information. Neural networks, 22(5-6):544--557
2009
-
[32]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
2022
-
[33]
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and 1 others. 2022. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International conference on machine learning, pages ...
2022
-
[34]
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. 2023. Ties-merging: Resolving interference when merging models. Advances in neural information processing systems, 36:7093--7115
2023
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems, 36:11809--11822
2023
-
[37]
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. 2024. Language models are super mario: Absorbing abilities from homologous models as a free lunch. In Forty-first International Conference on Machine Learning
2024
-
[38]
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. 2020. Gradient surgery for multi-task learning. Advances in neural information processing systems, 33:5824--5836
2020
-
[39]
Guangtao Zeng, Wenmian Yang, Zeqian Ju, Yue Yang, Sicheng Wang, Ruisi Zhang, Meng Zhou, Jiaqi Zeng, Xiangyu Dong, Ruoyu Zhang, and 1 others. 2020. Meddialog: Large-scale medical dialogue datasets. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 9241--9250
2020
-
[40]
Hongbo Zhang, Junying Chen, Feng Jiang, Fei Yu, Zhihong Chen, Guiming Chen, Jianquan Li, Xiangbo Wu, Zhang Zhiyi, Qingying Xiao, and 1 others. 2023. Huatuogpt, towards taming language model to be a doctor. In Findings of the association for computational linguistics: EMNLP 2023, pages 10859--10885
2023
-
[41]
Kaiyan Zhang, Sihang Zeng, Ermo Hua, Ning Ding, Zhang-Ren Chen, Zhiyuan Ma, Haoxin Li, Ganqu Cui, Biqing Qi, Xuekai Zhu, and 1 others. 2024. Ultramedical: Building specialized generalists in biomedicine. Advances in Neural Information Processing Systems, 37:26045--26081
2024
-
[42]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, and 1 others. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595--46623
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.