AlloSpatial: Agentic Harness Framework for Spatial Reasoning in Foundation Models
Pith reviewed 2026-06-27 17:06 UTC · model grok-4.3
The pith
AlloSpatial converts egocentric observations into allocentric spatial trees and maps, lifting proprietary models 5-18% on spatial benchmarks without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
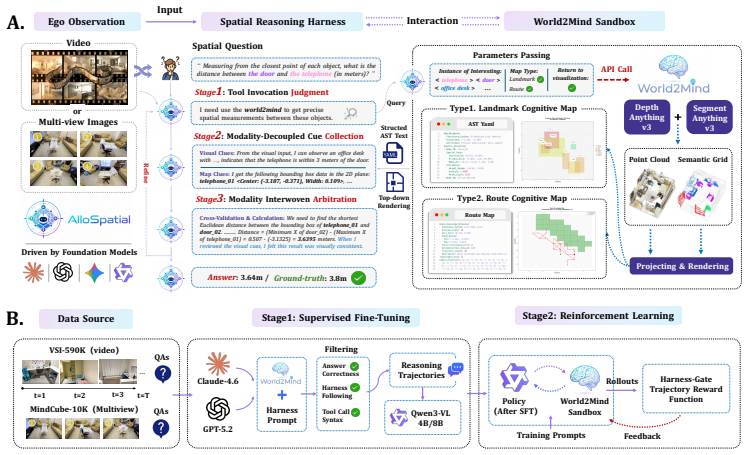
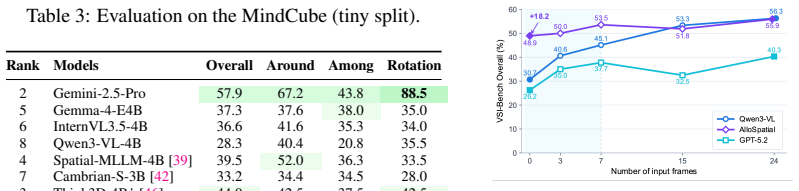
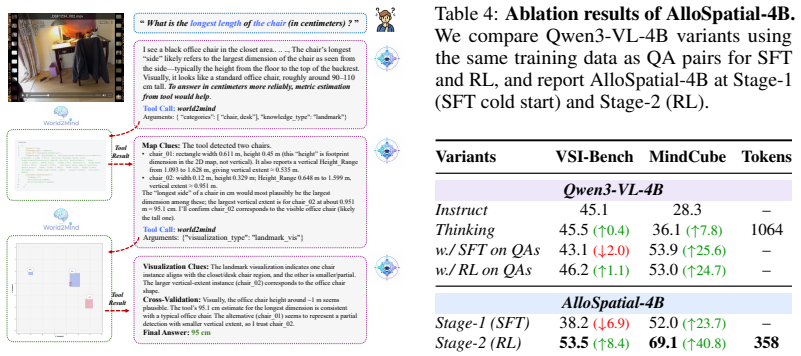
AlloSpatial introduces World2Mind to produce Allocentric-Spatial Trees and route maps from egocentric observations, together with a Spatial Reasoning Harness for tool-use judgment, modality-decoupled cue collection, and geometry-semantic arbitration; these components raise performance on VSI-Bench and MindCube by 5-18% for proprietary models in a training-free setting, allow strong reasoning without visual inputs, and let trained agents exceed larger general-purpose models.
What carries the argument
Allocentric-Spatial Trees (ASTs) that encode object topology, geometric relations, passability, and trajectories in a global frame, generated by the World2Mind sandbox and queried through the Spatial Reasoning Harness.
If this is right
- Proprietary models gain 5-18% on VSI-Bench and MindCube without any training.
- ASTs alone enable strong spatial reasoning when visual inputs are removed.
- Agents trained with harness-gated rewards outperform larger general-purpose models and spatial baselines.
- Structured allocentric representations plus active tool use provide a route to spatially capable foundation models.
Where Pith is reading between the lines
- The separation of mapping sandbox from reasoning harness suggests the same pattern could be tested on non-spatial tasks such as temporal planning or causal inference.
- If ASTs remain useful after visual removal, hybrid systems that maintain explicit spatial graphs may reduce reliance on raw pixel processing in deployed agents.
- The training-free gains imply that many existing models already contain latent spatial capacity that structured priors can unlock without parameter updates.
Load-bearing premise
The World2Mind sandbox reliably produces accurate Allocentric-Spatial Trees and route maps from noisy or ambiguous egocentric observations without introducing errors that the downstream harness cannot correct.
What would settle it
Run World2Mind on a set of egocentric sequences that produce demonstrably incorrect ASTs and route maps, then measure whether the harness still yields correct answers on VSI-Bench spatial queries or whether accuracy collapses when visual inputs are removed.
Figures

read the original abstract
Multimodal Foundation Models (MFMs) have made substantial progress, yet remain fragile in spatial reasoning over the physical world. A key bottleneck lies in their inability to transform local egocentric observations into a global allocentric spatial representation. To address this, we propose AlloSpatial, an agentic framework for allocentric spatial cognition in foundation models. AlloSpatial introduces World2Mind, a plug-and-play cognitive mapping sandbox that converts egocentric observations into structured allocentric priors, including Allocentric-Spatial Trees and route maps that support querying object topology, geometric relations, passability, and trajectories. To utilize these priors reliably under noisy reconstruction and ambiguous visual evidence, AlloSpatial introduces a Spatial Reasoning Harness for tool-use judgment, modality-decoupled cue collection, and geometry-semantic arbitration. We further internalize this process in Qwen3-VL through cold-start reinforcement learning with a harness-gated trajectory-level reward. Experiments on VSI-Bench and MindCube show that AlloSpatial improves proprietary models by 5%-18% in a training-free setting, while ASTs alone support strong spatial reasoning even when visual inputs are removed. The trained AlloSpatial agents further outperform larger general-purpose models and competitive spatial baselines, suggesting that structured allocentric representations, active tool use, and verifiable reasoning offer a promising route toward spatially capable foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AlloSpatial, an agentic framework for improving spatial reasoning in multimodal foundation models. It consists of World2Mind, a plug-and-play sandbox that transforms egocentric observations into allocentric priors such as Allocentric-Spatial Trees (ASTs) and route maps, and a Spatial Reasoning Harness that performs tool-use judgment, modality-decoupled cue collection, and geometry-semantic arbitration. The framework is further internalized via cold-start RL in Qwen3-VL using harness-gated rewards. Experiments claim 5-18% gains on VSI-Bench and MindCube for proprietary models in a training-free regime, that ASTs alone enable strong reasoning even with visual inputs removed, and that the trained agents outperform larger general-purpose models and spatial baselines.
Significance. If the empirical claims hold after verification, the work would provide evidence that structured allocentric representations combined with an arbitration harness can deliver training-free spatial gains and that internalizing the process via RL yields agents competitive with larger models. The emphasis on verifiable tool use and modality decoupling is a constructive direction. The manuscript does not report machine-checked proofs, fully reproducible code, or parameter-free derivations, so credit is limited to the conceptual framing of ASTs and the harness.
major comments (2)
- [Abstract] Abstract: The central claim that World2Mind produces sufficiently accurate ASTs and route maps from noisy egocentric inputs (so that the harness arbitrates rather than propagates errors) is load-bearing for the reported 5-18% gains and the 'ASTs alone support strong spatial reasoning' result, yet the manuscript supplies no quantitative reconstruction fidelity metrics, no ablation on observation noise levels, and no measurement of harness override frequency.
- [Abstract] Abstract: The headline improvements (5%-18% on VSI-Bench and MindCube) and the outperformance of trained agents over larger models are presented without any reported experimental controls, such as number of runs, variance or error bars, baseline definitions, or checks against post-hoc selection, rendering the magnitude and robustness of the gains unverifiable from the given text.
minor comments (1)
- [Abstract] Abstract: The phrase 'cold-start reinforcement learning with a harness-gated trajectory-level reward' is introduced without a brief definition of the reward components or the cold-start procedure, which would aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, indicating revisions where the manuscript will be updated to improve clarity and verifiability of the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that World2Mind produces sufficiently accurate ASTs and route maps from noisy egocentric inputs (so that the harness arbitrates rather than propagates errors) is load-bearing for the reported 5-18% gains and the 'ASTs alone support strong spatial reasoning' result, yet the manuscript supplies no quantitative reconstruction fidelity metrics, no ablation on observation noise levels, and no measurement of harness override frequency.
Authors: We agree that quantitative validation of World2Mind's reconstruction quality is important for substantiating the load-bearing claims. The current manuscript prioritizes end-to-end task performance and the downstream effects of the harness, but does not include explicit fidelity metrics or noise ablations. In the revised version we will add reconstruction accuracy metrics for ASTs and route maps (e.g., topology and geometry fidelity scores), an ablation on input noise levels, and statistics on harness override frequency to demonstrate that the harness primarily arbitrates rather than propagates errors. revision: yes
-
Referee: [Abstract] Abstract: The headline improvements (5%-18% on VSI-Bench and MindCube) and the outperformance of trained agents over larger models are presented without any reported experimental controls, such as number of runs, variance or error bars, baseline definitions, or checks against post-hoc selection, rendering the magnitude and robustness of the gains unverifiable from the given text.
Authors: The referee correctly notes the absence of reported run counts, variance, and error bars. While baseline definitions appear in the experimental setup section, we acknowledge that additional statistical controls would strengthen verifiability. We will revise the results section to report performance aggregated over multiple independent runs with standard deviations and will explicitly restate baseline selection criteria to address concerns about post-hoc selection. revision: yes
Circularity Check
No significant circularity; framework evaluated on external benchmarks
full rationale
The paper introduces AlloSpatial as an agentic framework with World2Mind (for egocentric-to-allocentric mapping via ASTs and route maps) and a Spatial Reasoning Harness (for tool-use and arbitration), then reports empirical gains on the external benchmarks VSI-Bench and MindCube. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the provided text that would reduce any claimed result to its own inputs by construction. The reported improvements (5-18% training-free, outperformance after RL) are presented as outcomes of the proposed components against independent test sets rather than tautological predictions or renamed fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Navigating cognition: Spatial codes for human thinking.Science, 362(6415):eaat6766, 2018
Jacob LS Bellmund, Peter Gärdenfors, Edvard I Moser, and Christian F Doeller. Navigating cognition: Spatial codes for human thinking.Science, 362(6415):eaat6766, 2018
2018
-
[3]
Spatial memory: how egocentric and allocentric combine.Trends in cognitive sciences, 10 (12):551–557, 2006
Neil Burgess. Spatial memory: how egocentric and allocentric combine.Trends in cognitive sciences, 10 (12):551–557, 2006
2006
-
[4]
Spatialbot: Precise spatial understanding with vision language models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9490–9498. IEEE, 2025
2025
-
[5]
Meng Cao, Xingyu Li, Xue Liu, Ian Reid, and Xiaodan Liang. Spatialdreamer: Incentivizing spatial reasoning via active mental imagery.arXiv preprint arXiv:2512.07733, 2025
-
[6]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
2024
-
[8]
Pingyi Chen, Yujing Lou, Shen Cao, Jinhui Guo, Lubin Fan, Yue Wu, Lin Yang, Lizhuang Ma, and Jieping Ye. Sd-vlm: Spatial measuring and understanding with depth-encoded vision-language models.arXiv preprint arXiv:2509.17664, 2025
-
[9]
SpaceTools: Tool-Augmented Spatial Reasoning via Double Interactive RL
Siyi Chen, Mikaela Angelina Uy, Chan Hee Song, Faisal Ladhak, Adithyavairavan Murali, Qing Qu, Stan Birchfield, Valts Blukis, and Jonathan Tremblay. Spacetools: Tool-augmented spatial reasoning via double interactive rl.arXiv preprint arXiv:2512.04069, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Spatialrgpt: Grounded spatial reasoning in vision-language models.Advances in Neural Information Processing Systems, 37:135062–135093, 2024
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models.Advances in Neural Information Processing Systems, 37:135062–135093, 2024
2024
-
[11]
Mm-spatial: Exploring 3d spatial understanding in multimodal llms
Erik Daxberger, Nina Wenzel, David Griffiths, Haiming Gang, Justin Lazarow, Gefen Kohavi, Kai Kang, Marcin Eichner, Yinfei Yang, Afshin Dehghan, et al. Mm-spatial: Exploring 3d spatial understanding in multimodal llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7395–7408, 2025
2025
-
[12]
Nianchen Deng, Lixin Gu, Shenglong Ye, Yinan He, Zhe Chen, Songze Li, Haomin Wang, Xingguang Wei, Tianshuo Yang, Min Dou, et al. Internspatial: A comprehensive dataset for spatial reasoning in vision-language models.arXiv preprint arXiv:2506.18385, 2025
-
[13]
Gemini 3.1 pro: Best for complex tasks and bringing creative concepts to life
Google. Gemini 3.1 pro: Best for complex tasks and bringing creative concepts to life. https:// deepmind.google/models/gemini/pro/, 2026
2026
-
[14]
Gemma 4, 2026
Google DeepMind. Gemma 4, 2026. URL https://deepmind.google/models/gemma/gemma-4/. Accessed: 2026-05-06
2026
-
[15]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning
Qiao Gu, Ali Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, et al. Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5021–5028. IEEE, 2024
2024
-
[16]
Jiaxin Huang, Ziwen Li, Hanlve Zhang, Runnan Chen, Xiao He, Yandong Guo, Wenping Wang, Tongliang Liu, and Mingming Gong. Surprise3d: A dataset for spatial understanding and reasoning in complex 3d scenes.arXiv preprint arXiv:2507.07781, 2025
-
[17]
Shuai Huang, Wenxuan Zhao, and Jun Gao. Si-bench: Benchmarking social intelligence of large language models in human-to-human conversations.arXiv preprint arXiv:2510.23182, 2025
-
[18]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Jingli Lin, Runsen Xu, Shaohao Zhu, Sihan Yang, Peizhou Cao, Yunlong Ran, Miao Hu, Chenming Zhu, Yiman Xie, Yilin Long, et al. Mmsi-video-bench: A holistic benchmark for video-based spatial intelligence. arXiv preprint arXiv:2512.10863, 2025
-
[20]
Zhanpeng Luo, Ce Zhang, Silong Yong, Cunxi Dai, Qianwei Wang, Haoxi Ran, Guanya Shi, Katia Sycara, and Yaqi Xie. pyspatial: Generating 3d visual programs for zero-shot spatial reasoning.arXiv preprint arXiv:2603.00905, 2026
-
[21]
Wufei Ma, Yu-Cheng Chou, Qihao Liu, Xingrui Wang, Celso de Melo, Jianwen Xie, and Alan Yuille. Spatialreasoner: Towards explicit and generalizable 3d spatial reasoning.arXiv preprint arXiv:2504.20024, 2025
-
[22]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. Advances in neural information processing systems, 36:46534–46594, 2023
2023
-
[23]
Enhancing spatial reasoning in multimodal large language models through reasoning-based segmentation
Zhenhua Ning, Zhuotao Tian, Shaoshuai Shi, Guangming Lu, Daojing He, Wenjie Pei, and Li Jiang. Enhancing spatial reasoning in multimodal large language models through reasoning-based segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7851–7860, 2025
2025
-
[24]
Oxford university press, 1978
John O’keefe and Lynn Nadel.The hippocampus as a cognitive map. Oxford university press, 1978
1978
-
[25]
Gpt -4v(ision) system card
OpenAI. Gpt -4v(ision) system card. https://cdn.openai.com/papers/GPTV_System_Card.pdf, 2023
2023
-
[26]
Spatial-r1: Enhancing mllms in video spatial reasoning.arXiv e-prints, pages arXiv–2504, 2025
Kun Ouyang. Spatial-r1: Enhancing mllms in video spatial reasoning.arXiv e-prints, pages arXiv–2504, 2025
2025
-
[27]
Jianing Qi, Jiawei Liu, Hao Tang, and Zhigang Zhu. Beyond semantics: Rediscovering spatial awareness in vision-language models.arXiv preprint arXiv:2503.17349, 2025
-
[28]
Does spatial cognition emerge in frontier models?arXiv preprint arXiv:2410.06468, 2024
Santhosh Kumar Ramakrishnan, Erik Wijmans, Philipp Kraehenbuehl, and Vladlen Koltun. Does spatial cognition emerge in frontier models?arXiv preprint arXiv:2410.06468, 2024
-
[29]
Krishan Rana, Jesse Haviland, Sourav Garg, Jad Abou-Chakra, Ian Reid, and Niko Suenderhauf. Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning.arXiv preprint arXiv:2307.06135, 2023
-
[30]
From reactive to cognitive: brain-inspired spatial intelligence for embodied agents.intelligence (AGI), 3(9):10, 2025
Shouwei Ruan, Liyuan Wang, Caixin Kang, Qihui Zhu, Songming Liu, Xingxing Wei, and Hang Su. From reactive to cognitive: brain-inspired spatial intelligence for embodied agents.intelligence (AGI), 3(9):10, 2025
2025
-
[31]
Memory and space: towards an understanding of the cognitive map.Journal of Neuroscience, 35(41):13904–13911, 2015
Daniela Schiller, Howard Eichenbaum, Elizabeth A Buffalo, Lila Davachi, David J Foster, Stefan Leutgeb, and Charan Ranganath. Memory and space: towards an understanding of the cognitive map.Journal of Neuroscience, 35(41):13904–13911, 2015
2015
-
[32]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[35]
Mindcube: Spatial mental modeling from limited views.arXiv e-prints, pages arXiv–2506, 2025
Qineng Wang, Baiqiao Yin, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, et al. Mindcube: Spatial mental modeling from limited views.arXiv e-prints, pages arXiv–2506, 2025
2025
-
[36]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023. 12
2023
-
[38]
N3d-vlm: Native 3d grounding enables accurate spatial reasoning in vision-language models
Yuxin Wang, Lei Ke, Boqiang Zhang, Tianyuan Qu, Hanxun Yu, Zhenpeng Huang, Meng Yu, Dan Xu, and Dong Yu. N3d-vlm: Native 3d grounding enables accurate spatial reasoning in vision-language models. arXiv preprint arXiv:2512.16561, 2025
-
[39]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Mingrui Wu, Zhaozhi Wang, Fangjinhua Wang, Jiaolong Yang, Marc Pollefeys, and Tong Zhang. From indoor to open world: Revealing the spatial reasoning gap in mllms.arXiv preprint arXiv:2512.19683, 2025
-
[41]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[42]
Cambrian-S: Towards Spatial Supersensing in Video
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis Brown, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et al. Cambrian-s: Towards spatial supersensing in video.arXiv preprint arXiv:2511.04670, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Re- act: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. Re- act: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[44]
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Lmms-eval: Reality check on the evaluation of large multimodal models, 2024. URLhttps://arxiv.org/abs/2407.12772
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Weichen Zhang, Ruiying Peng, Chen Gao, Jianjie Fang, Xin Zeng, Kaiyuan Li, Ziyou Wang, Jinqiang Cui, Xin Wang, Xinlei Chen, et al. The point, the vision and the text: Does point cloud boost spatial reasoning of large language models?arXiv preprint arXiv:2504.04540, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Think3d: Thinking with space for spatial reasoning.arXiv preprint arXiv:2601.13029, 2026
Zaibin Zhang, Yuhan Wu, Lianjie Jia, Yifan Wang, Zhongbo Zhang, Yijiang Li, Binghao Ran, Fuxi Zhang, Zhuohan Sun, Zhenfei Yin, et al. Think3d: Thinking with space for spatial reasoning.arXiv preprint arXiv:2601.13029, 2026
-
[47]
Swift:a scalable lightweight infrastructure for fine-tuning, 2024
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scalable lightweight infrastructure for fine-tuning, 2024. URLhttps://arxiv.org/abs/2408.05517
-
[48]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. A Training & Evaluation Configuration RL training configuration.AlloSpatial-4B and AlloSpatial-8B are initialized from their corre- sponding supervised cold-sta...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Therefore, IRB approval or equivalent review is not applicable
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.