Steganography Without Modification: Hidden Communication via LLM Seeds
Pith reviewed 2026-06-27 16:28 UTC · model grok-4.3
The pith
LLM inference stacks contain a steganographic channel that encodes 32 bits in the PRNG seed used for deterministic sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We demonstrate that widely deployed Large Language Model (LLM) inference stacks harbor a steganographic channel that requires no modification to model weights, sampling code, or output distributions. The channel exploits a structural property of deterministic decoding: pseudo-random number generators (PRNGs) used in inverse-transform sampling produce a seed-dependent sequence of token-level probability intervals that can be reconstructed from the generated text alone. A sender encodes a secret message in the PRNG seed before generation; a receiver reconstructs the intervals and recovers the seed, and thus the hidden payload, by exhaustive search over the seed space.
What carries the argument
The seed-dependent sequence of token-level probability intervals generated by PRNG-driven inverse-transform sampling, which a receiver reconstructs from observed tokens to enable exhaustive seed search.
If this is right
- 32 bits of data can be transmitted steganographically through any unmodified LLM inference stack that uses deterministic sampling.
- Ignorance of the prompt does not prevent reliable recovery when the output is sufficiently long.
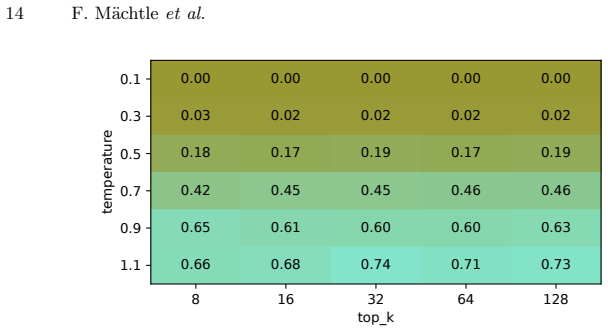
- Channel reliability varies with model family, text domain, prompting strategy, tokenization, and sampling hyperparameters.
- The same mechanism allows an observer to detect whether a given text was produced under a chosen seed.
Where Pith is reading between the lines
- Mitigations would require either non-deterministic sampling or explicit randomization of the PRNG state that cannot be recovered from the output.
- The channel could be repurposed as a passive watermark that survives post-generation editing if the intervals remain distinguishable.
- Similar seed-dependent interval leakage may exist in other sampling-based generative systems outside LLMs.
Load-bearing premise
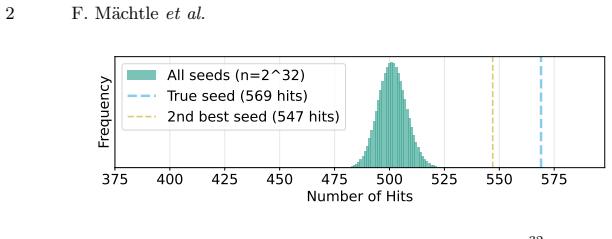
The sequence of probability intervals can be reconstructed from the generated text alone with enough fidelity to let exhaustive search over 2^32 seeds identify the correct one.
What would settle it
An experiment in which two different 32-bit seeds produce identical interval sequences for the same prompt and output text, or in which the search procedure fails to rank the true seed highest on outputs longer than 800 tokens.
Figures
read the original abstract
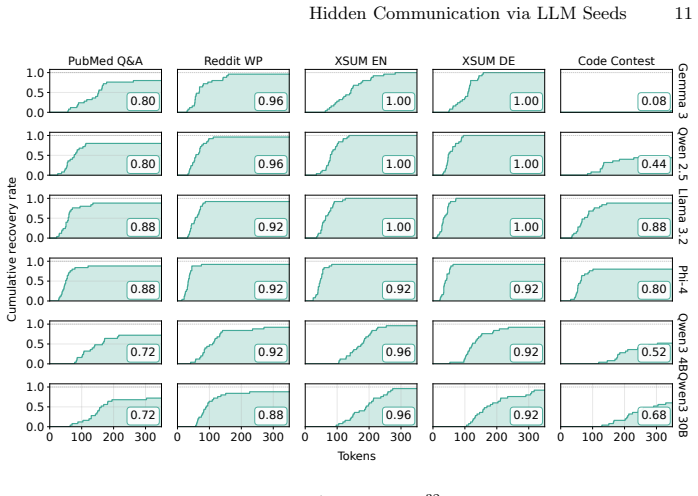
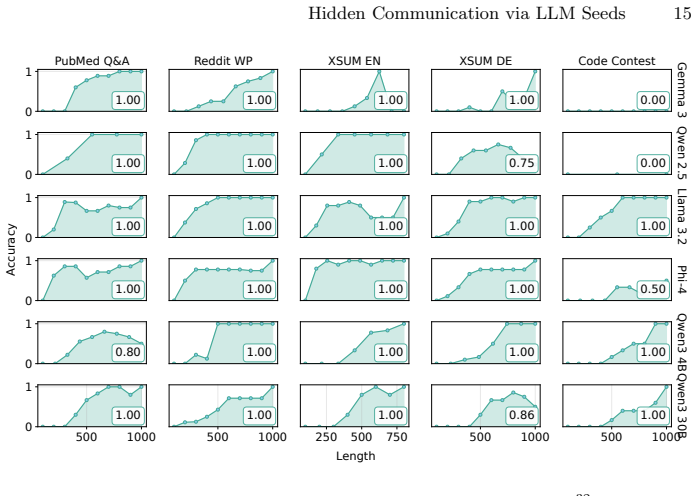
We demonstrate that widely deployed Large Language Model (LLM) inference stacks harbor a steganographic channel that requires no modification to model weights, sampling code, or output distributions. The channel exploits a structural property of deterministic decoding: pseudo-random number generators (PRNGs) used in inverse-transform sampling produce a seed-dependent sequence of token-level probability intervals that can be reconstructed from the generated text alone. A sender encodes a secret message in the PRNG seed before generation; a receiver reconstructs the intervals and recovers the seed, and thus the hidden payload, by exhaustive search over the seed space. We formalize two operational modes. In the known-prompt setting, sender and receiver share the prompt, enabling exact interval reconstruction and perfect seed recovery via forced alignment. In the unknown-prompt setting, only the generated text is available; approximate interval reconstruction combined with a maximum-hit-count scoring strategy still permits reliable recovery from sufficiently long outputs. Extensive experiments across six model families and five heterogeneous text domains show that, in the known-prompt setting, full 32-bit seed recovery from the complete 2^32 candidate space achieves up to 100% accuracy, depending on model and text domain, within 300 tokens and under 35 seconds on a single GPU. In the unknown-prompt setting, recovery reaches near-perfect accuracy at 600-800 tokens in about 12 seconds. We further analyze the influence of prompting strategies, tokenization ambiguities, and sampling hyperparameters on channel reliability. Moreover, we discuss several applications of our results: First, it allows for the steganographic transmission of 32 bits, but also shows that ignorance of the prompt is not a valid security assumption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that widely deployed LLM inference pipelines contain an unmodified steganographic channel: a sender encodes a 32-bit payload by choosing the PRNG seed for inverse-transform sampling; a receiver recovers the seed (hence the payload) by exhaustive search over the 2^32 space after reconstructing the sequence of token-level cumulative probability intervals from the generated text. Two modes are formalized—known-prompt (exact reconstruction via shared prompt, perfect recovery) and unknown-prompt (approximate reconstruction plus maximum-hit-count scoring, near-perfect recovery at 600–800 tokens)—and supported by experiments across six model families and five domains showing up to 100 % accuracy in the known-prompt case within 300 tokens.
Significance. If the central experimental claims hold, the result identifies a previously undocumented side-channel in production LLM stacks that requires no weight changes or output-distribution alterations, with direct implications for covert communication and output security assumptions. The breadth of the empirical evaluation (six model families, heterogeneous domains, timing measurements) is a positive feature; the absence of a parameter-free derivation or machine-checked argument means the contribution rests entirely on the reported experiments.
major comments (3)
- [unknown-prompt mode / methods] Unknown-prompt reconstruction procedure (described in the methods and unknown-prompt subsection): the manuscript states that approximate token-level probability intervals can be reconstructed from output text alone, yet provides no explicit algorithm, default-prompt strategy, or marginal-statistic fallback that would allow an independent reader to reproduce the interval sequence without the original conditioning context. Because the hit-count search relies on these intervals matching the sender’s intervals, this omission directly undermines verification of the near-perfect recovery reported at 600–800 tokens.
- [experiments / abstract] Experimental reporting (results section and abstract): accuracy figures are given as “up to 100 %” and “near-perfect” without per-model/per-domain tables, confidence intervals, or failure-case analysis. The central claim that the channel is reliable therefore rests on aggregate statements whose robustness cannot be assessed from the provided data.
- [analysis of prompting and hyperparameters] Tokenization and sampling-hyperparameter sensitivity (analysis subsection): the paper notes that tokenization ambiguities and sampling parameters affect reliability, but does not quantify how often these factors cause the true seed’s hit count to fall below the maximum, which is load-bearing for the claim that recovery remains reliable across “heterogeneous text domains.”
minor comments (2)
- [formalization] Notation for the interval reconstruction function is introduced without a compact mathematical definition or pseudocode, making the transition from exact (known-prompt) to approximate (unknown-prompt) reconstruction difficult to follow.
- [experiments] The timing measurements (under 35 s known-prompt, ~12 s unknown-prompt) are reported on a single GPU but without hardware specification or scaling behavior for larger seed spaces or longer sequences.
Simulated Author's Rebuttal
We thank the referee for the careful reading and specific suggestions for improving reproducibility and reporting. We address each major comment below and will make the indicated revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [unknown-prompt mode / methods] Unknown-prompt reconstruction procedure (described in the methods and unknown-prompt subsection): the manuscript states that approximate token-level probability intervals can be reconstructed from output text alone, yet provides no explicit algorithm, default-prompt strategy, or marginal-statistic fallback that would allow an independent reader to reproduce the interval sequence without the original conditioning context. Because the hit-count search relies on these intervals matching the sender’s intervals, this omission directly undermines verification of the near-perfect recovery reported at 600–800 tokens.
Authors: We agree that the current description is insufficient for independent reproduction. The revised manuscript will add an explicit algorithm (in pseudocode) for approximate interval reconstruction in the unknown-prompt setting, including the default-prompt strategy (neutral empty-string prompt) and the marginal-statistic fallback (model-family average token probabilities). This will directly support verification of the reported recovery performance. revision: yes
-
Referee: [experiments / abstract] Experimental reporting (results section and abstract): accuracy figures are given as “up to 100 %” and “near-perfect” without per-model/per-domain tables, confidence intervals, or failure-case analysis. The central claim that the channel is reliable therefore rests on aggregate statements whose robustness cannot be assessed from the provided data.
Authors: The manuscript already states that results vary by model and domain and reports the observed maxima. To improve transparency we will add per-model/per-domain accuracy tables, bootstrap confidence intervals on the key recovery rates, and a short failure-case analysis (primarily short outputs) in the results section. The abstract will be updated to reference these tables. revision: yes
-
Referee: [analysis of prompting and hyperparameters] Tokenization and sampling-hyperparameter sensitivity (analysis subsection): the paper notes that tokenization ambiguities and sampling parameters affect reliability, but does not quantify how often these factors cause the true seed’s hit count to fall below the maximum, which is load-bearing for the claim that recovery remains reliable across “heterogeneous text domains.”
Authors: We will extend the analysis subsection with quantitative results: the fraction of trials (per domain and model) in which the true seed’s hit count was not maximal, computed from the existing experimental data. This will provide the requested evidence on robustness across heterogeneous domains. revision: yes
Circularity Check
No significant circularity; claims rest on empirical demonstration
full rationale
The paper's central claims concern the existence of a steganographic channel via PRNG seed recovery from LLM output text, formalized into known-prompt and unknown-prompt modes. Recovery is asserted via exhaustive search over the 2^32 seed space, with performance quantified through experiments on six model families and five domains. No load-bearing mathematical derivation, equation, or parameter fit is presented that reduces the reported recovery rates to the inputs by construction. The unknown-prompt approximation is described as a practical strategy whose reliability is measured experimentally rather than derived from self-referential definitions or prior self-citations. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PRNGs used for inverse-transform sampling in LLM decoding are deterministic functions of the seed that produce reproducible sequences of probability intervals.
Reference graph
Works this paper leans on
-
[1]
AKeigo/Llama3.1 StoryGeneration: Post-training llama-3.1-8b for story generation only (hugging face model card).https://huggingface.co/AKeigo/ Llama3.1_StoryGeneration, August 2025
AKeigo. AKeigo/Llama3.1 StoryGeneration: Post-training llama-3.1-8b for story generation only (hugging face model card).https://huggingface.co/AKeigo/ Llama3.1_StoryGeneration, August 2025. Model card indicates story-generation finetune using SFT on writingprompts and RL on GRPO
2025
-
[2]
At- tacks and remedies for randomness in AI: cryptanalysis of PHILOX and THREE- FRY.IACR Cryptol
Jens Alich, Thomas Eisenbarth, Hossein Hadipour, Gregor Leander, Felix M¨ achtle, Yevhen Perehuda, Shahram Rasoolzadeh, Jonas Sander, and Cihangir Tezcan. At- tacks and remedies for randomness in AI: cryptanalysis of PHILOX and THREE- FRY.IACR Cryptol. ePrint Arch., 2025:2161, 2025
2025
-
[3]
Shim- mer: a provably secure steganography based on entropy collecting mechanism
Minhao Bai, Kaiyi Pang, Guorui Liao, Jinshuai Yang, and Yongfeng Huang. Shim- mer: a provably secure steganography based on entropy collecting mechanism. In 34th USENIX Security Symposium, USENIX Security 2025, Seattle, WA, USA, August 13-15, 2025, pages 5949–5965. USENIX Association, 2025
2025
-
[4]
Fast- detectgpt: Efficient zero-shot detection of machine-generated text via conditional probability curvature
Guangsheng Bao, Yanbin Zhao, Zhiyang Teng, Linyi Yang, and Yue Zhang. Fast- detectgpt: Efficient zero-shot detection of machine-generated text via conditional probability curvature. InThe Twelfth International Conference on Learning Repre- sentations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[5]
Paterson, and Phillip Rogaway
Mihir Bellare, Kenneth G. Paterson, and Phillip Rogaway. Security of symmetric encryption against mass surveillance. InAdvances in Cryptology - CRYPTO 2014 - 34th Annual Cryptology Conference, Santa Barbara, CA, USA, August 17-21, 2014, Proceedings, Part I, volume 8616 ofLecture Notes in Computer Science, pages 1–19. Springer, 2014
2014
-
[6]
Algorithm substitution attacks from a steganographic perspective
Sebastian Berndt and Maciej Liskiewicz. Algorithm substitution attacks from a steganographic perspective. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS 2017, Dallas, TX, USA, October 30 - November 03, 2017, pages 1649–1660. ACM, 2017
2017
-
[7]
On the universal steganography of opti- mal rate.Inf
Sebastian Berndt and Maciej Liskiewicz. On the universal steganography of opti- mal rate.Inf. Comput., 275:104632, 2020
2020
-
[8]
Dai and Zheng Cai
Falcon Z. Dai and Zheng Cai. Towards near-imperceptible steganographic text. In Proceedings of the 57th Conference of the Association for Computational Linguis- tics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 4303–4308. Association for Computational Linguistics, 2019
2019
-
[9]
Christian Schr¨ oder de Witt, Samuel Sokota, J. Zico Kolter, Jakob N. Foerster, and Martin Strohmeier. Perfectly secure steganography using minimum entropy coupling.CoRR, abs/2210.14889, 2022. 20 F. M¨ achtleet al
-
[10]
Discop: Provably secure steganography in practice based on ”distribution copies”
Jinyang Ding, Kejiang Chen, Yaofei Wang, Na Zhao, Weiming Zhang, and Neng- hai Yu. Discop: Provably secure steganography in practice based on ”distribution copies”. In44th IEEE Symposium on Security and Privacy, SP 2023, San Fran- cisco, CA, USA, May 21-25, 2023, pages 2238–2255. IEEE, 2023
2023
-
[11]
Angela Fan, Mike Lewis, and Yann N. Dauphin. Hierarchical neural story genera- tion. InProceedings of the 56th Annual Meeting of the Association for Computa- tional Linguistics, ACL 2018, Melbourne, Australia, July 15-20, 2018, Volume 1: Long Papers, pages 889–898. Association for Computational Linguistics, 2018
2018
-
[12]
Argyraki
Tina Fang, Martin Jaggi, and Katerina J. Argyraki. Generating steganographic text with lstms. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Student Research Workshop, pages 100–106. Association for Computational Lin- guistics, 2017
2017
-
[13]
llama.cpp: Inference of llama models in pure c/c++.https://github
ggml-org. llama.cpp: Inference of llama models in pure c/c++.https://github. com/ggml-org/llama.cpp, 2025. Accessed: 08/2025
2025
-
[14]
The curious case of neural text degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. In8th International Conference on Learning Represen- tations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020
2020
-
[15]
Transformers documentation.https://huggingface.co/docs/ transformers/en/index, 2025
Hugging Face. Transformers documentation.https://huggingface.co/docs/ transformers/en/index, 2025. Accessed: 08/2025
2025
-
[16]
Cohen, and Xinghua Lu
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W. Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP- IJCNLP 2019, Hong Kong, China, November 3-7, 20...
2019
-
[17]
Jois, Gabrielle Beck, and Gabriel Kaptchuk
Tushar M. Jois, Gabrielle Beck, and Gabriel Kaptchuk. Pulsar: Secure steganogra- phy for diffusion models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, CCS 2024, Salt Lake City, UT, USA, October 14-18, 2024, pages 4703–4717. ACM, 2024
2024
-
[18]
Jois, Matthew Green, and Aviel D
Gabriel Kaptchuk, Tushar M. Jois, Matthew Green, and Aviel D. Rubin. Meteor: Cryptographically secure steganography for realistic distributions. InCCS ’21: 2021 ACM SIGSAC Conference on Computer and Communications Security, Vir- tual Event, Republic of Korea, November 15 - 19, 2021, pages 1529–1548. ACM, 2021
2021
-
[19]
What percentage of new content is ai-generated?https://ahrefs
Ryan Law. What percentage of new content is ai-generated?https://ahrefs. com/blog/what-percentage-of-new-content-is-ai-generated/, May 2025. Ac- cessed: 03/2026
2025
-
[20]
Yujia Li, David H. Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, R´ emi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
A framework for designing provably secure steganography
Guorui Liao, Jinshuai Yang, Weizhi Shao, and Yongfeng Huang. A framework for designing provably secure steganography. In34th USENIX Security Symposium, USENIX Security 2025, Seattle, WA, USA, August 13-15, 2025, pages 6837–6856. USENIX Association, 2025. Hidden Communication via LLM Seeds 21
2025
-
[22]
Prompt pirates need a map: Stealing seeds helps stealing prompts
Felix M¨ achtle, Ashwath Shetty, Jonas Sander, Nils Loose, S¨ oren Pirk, and Thomas Eisenbarth. Prompt pirates need a map: Stealing seeds helps stealing prompts. CoRR, abs/2509.09488, 2025
-
[23]
Hidden in plain text: Emergence & mit- igation of steganographic collusion in llms
Yohan Mathew, Ollie Matthews, Robert McCarthy, Joan Velja, Christian Schr¨ oder de Witt, Dylan Cope, and Nandi Schoots. Hidden in plain text: Emergence & mit- igation of steganographic collusion in llms. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Associa...
2025
-
[24]
Tro- janstego: Your language model can secretly be A steganographic privacy leaking agent
Dominik Meier, Jan Philip Wahle, Paul R¨ ottger, Terry Ruas, and Bela Gipp. Tro- janstego: Your language model can secretly be A steganographic privacy leaking agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025, pages 27244–27261. Association for Computational Ling...
2025
-
[25]
Azure OpenAI in Microsoft Foundry Models – REST API Reference.https://learn.microsoft.com/en-us/azure/foundry/openai/ reference, 2026
Microsoft Corporation. Azure OpenAI in Microsoft Foundry Models – REST API Reference.https://learn.microsoft.com/en-us/azure/foundry/openai/ reference, 2026. Accessed: 03/2026
2026
-
[26]
Mistral API Reference – Chat Completion Endpoint.https://docs
Mistral AI. Mistral API Reference – Chat Completion Endpoint.https://docs. mistral.ai/api, 2026. Accessed: 03/2026
2026
-
[27]
Cohen, and Mirella Lapata
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summa- rization. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, pages 1797–1807. Association for Computational Lin...
2018
-
[28]
Fabien A. P. Petitcolas, Ross J. Anderson, and Markus G. Kuhn. Information hiding-a survey.Proc. IEEE, 87(7):1062–1078, 1999
1999
-
[29]
Tom´ as Pevn´ y and Andrew D. Ker. Steganographic key leakage through payload metadata. InIH&MMSec, pages 109–114. ACM, 2014
2014
-
[30]
Salmon, Mark A
John K. Salmon, Mark A. Moraes, Ron O. Dror, and David E. Shaw. Parallel random numbers: as easy as 1, 2, 3. InConference on High Performance Computing Networking, Storage and Analysis, SC 2011, Seattle, WA, USA, November 12-18, 2011, pages 16:1–16:12. ACM, 2011
2011
-
[31]
Near-imperceptible neural linguistic steganography via self-adjusting arithmetic coding
Jiaming Shen, Heng Ji, and Jiawei Han. Near-imperceptible neural linguistic steganography via self-adjusting arithmetic coding. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pages 303–313. Association for Computational Lin- guistics, 2020
2020
-
[32]
Gustavus J. Simmons. The subliminal channel and digital signature. InAdvances in Cryptology: Proceedings of EUROCRYPT 84, A Workshop on the Theory and Ap- plication of of Cryptographic Techniques, Paris, France, April 9-11, 1984, Proceed- ings, volume 209 ofLecture Notes in Computer Science, pages 364–378. Springer, 1984
1984
-
[33]
Gustavus J. Simmons. Subliminal communication is easy using the DSA. InAd- vances in Cryptology - EUROCRYPT ’93, Workshop on the Theory and Applica- tion of of Cryptographic Techniques, Lofthus, Norway, May 23-27, 1993, Proceed- ings, volume 765 ofLecture Notes in Computer Science, pages 218–232. Springer, 1993
1993
- [34]
-
[35]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 5998–6008, 2017
2017
-
[36]
vLLM: A high-throughput and memory-efficient inference and serv- ing engine for llms.https://github.com/vllm-project/vllm, 2025
vllm-project. vLLM: A high-throughput and memory-efficient inference and serv- ing engine for llms.https://github.com/vllm-project/vllm, 2025. Accessed: 08/2025
2025
-
[37]
Sparsamp: Efficient provably secure steganog- raphy based on sparse sampling
Yaofei Wang, Gang Pei, Kejiang Chen, Jinyang Ding, Chao Pan, Weilong Pang, Donghui Hu, and Weiming Zhang. Sparsamp: Efficient provably secure steganog- raphy based on sparse sampling. In34th USENIX Security Symposium, USENIX Security 2025, Seattle, WA, USA, August 13-15, 2025, pages 6817–6835. USENIX Association, 2025
2025
-
[38]
Synchronization of acoustic signals for steganographic transmission.Sensors, 21(10):3379, 2021
Jaroslaw Wojtun and Zbigniew Piotrowski. Synchronization of acoustic signals for steganographic transmission.Sensors, 21(10):3379, 2021
2021
-
[39]
Security-oriented steganographic payload allocation for multi-remote sensing images.Scientific Reports, 14(1):4826, February 2024
Tian Wu, Xuan Hu, and Chunnian Liu. Security-oriented steganographic payload allocation for multi-remote sensing images.Scientific Reports, 14(1):4826, February 2024
2024
-
[40]
xAI REST API – OpenAPI Specification.https://docs.x.ai/openapi
xAI. xAI REST API – OpenAPI Specification.https://docs.x.ai/openapi. json, 2026. Accessed: 03/2026
2026
-
[41]
Distinguishing llm-generated from human-written code by contrastive learning.ACM Trans
Xiaodan Xu, Chao Ni, Xinrong Guo, Shaoxuan Liu, Xiaoya Wang, Kui Liu, and Xi- aohu Yang. Distinguishing llm-generated from human-written code by contrastive learning.ACM Trans. Softw. Eng. Methodol., 34(4):91:1–91:31, 2025
2025
-
[42]
Rnn-stega: Linguistic steganography based on recurrent neural networks
Zhongliang Yang, Xiaoqing Guo, Zi-Ming Chen, Yongfeng Huang, and Yu-Jin Zhang. Rnn-stega: Linguistic steganography based on recurrent neural networks. IEEE Trans. Inf. Forensics Secur., 14(5):1280–1295, 2019
2019
-
[43]
Young and Moti Yung
Adam L. Young and Moti Yung. The dark side of ”black-box” cryptography, or: Should we trust capstone? InAdvances in Cryptology - CRYPTO ’96, 16th Annual International Cryptology Conference, Santa Barbara, California, USA, August 18- 22, 1996, Proceedings, volume 1109 ofLecture Notes in Computer Science, pages 89–103. Springer, 1996
1996
-
[44]
Young and Moti Yung
Adam L. Young and Moti Yung. Kleptography: Using cryptography against cryp- tography. InAdvances in Cryptology - EUROCRYPT ’97, International Conference on the Theory and Application of Cryptographic Techniques, Konstanz, Germany, May 11-15, 1997, Proceeding, volume 1233 ofLecture Notes in Computer Science, pages 62–74. Springer, 1997
1997
-
[45]
Provably secure generative linguistic steganography.CoRR, abs/2106.02011, 2021
Si-yu Zhang, Zhongliang Yang, Jinshuai Yang, and Yongfeng Huang. Provably secure generative linguistic steganography.CoRR, abs/2106.02011, 2021
-
[46]
Ziegler, Yuntian Deng, and Alexander M
Zachary M. Ziegler, Yuntian Deng, and Alexander M. Rush. Neural linguistic steganography. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Nat- ural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pages 1210–1215. Association for Computation...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.