DuplexOmni: Real-Time Listening, Seeing, Thinking, and Speaking for Full-Duplex Interaction
Pith reviewed 2026-06-27 15:20 UTC · model grok-4.3
The pith
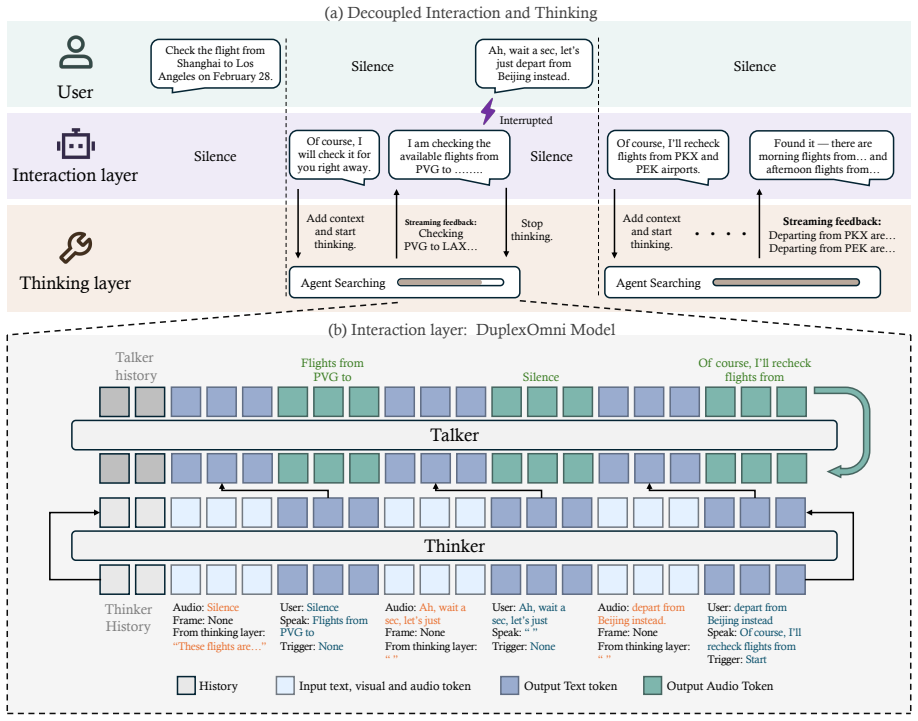
DuplexOmni splits an AI into an interaction layer and a thinking layer that run asynchronously in parallel to enable real-time full-duplex multimodal conversation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
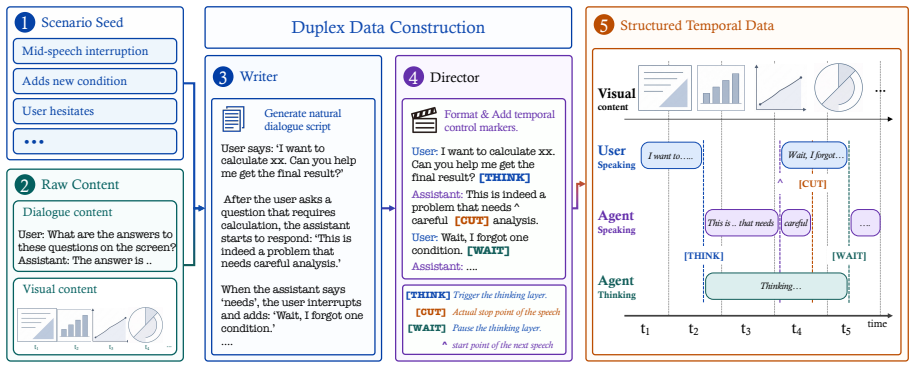
DuplexOmni separates model capability into an interaction layer and a thinking layer that collaborate asynchronously in parallel. The interaction layer is realized as an end-to-end DuplexOmni model that ingests streaming audio and video and emits text and speech responses in real time. The thinking layer acts as a detachable module supplying complex reasoning and tool-use functions. A Writer-Director pipeline supplies the continuous-interaction training data needed to learn stable full-duplex behavior.
What carries the argument
The interaction layer (DuplexOmni model) paired with a pluggable thinking layer that collaborate asynchronously in parallel.
If this is right
- Real-time speech and text generation can continue even while the thinking layer performs extended reasoning or calls external tools.
- The thinking layer can be swapped or upgraded independently without retraining the entire interaction system.
- Training data constructed via the Writer-Director pipeline enables the model to learn turn-taking and interruption handling directly from continuous streams.
- The same architecture supports simultaneous processing of audio and video inputs while maintaining low-latency output.
Where Pith is reading between the lines
- If the asynchronous split works reliably, similar layer separation could be applied to other multimodal systems that currently force all computation through a single forward pass.
- The approach suggests a route to add tool-use or long-horizon planning to voice assistants without forcing users to wait for each step.
- A natural next measurement would be how often users perceive the system as interrupting or drifting during extended reasoning episodes.
Load-bearing premise
The interaction and thinking layers can coordinate asynchronously without producing unacceptable latency, loss of coherence, or coordination failures, and the Writer-Director pipeline yields enough data to train stable full-duplex responses.
What would settle it
A live test in which the system must perform a multi-step reasoning task that requires several seconds while a user continues speaking and the model must respond without noticeable pauses, repetition, or context loss.
Figures

read the original abstract
Human interaction is continuous, multimodal, and full-duplex by nature. Although recent omni models have made substantial progress in unified speech, vision, and text modeling, combining seamless real-time interaction with complex reasoning and tool use remains challenging. We present DuplexOmni, a method for real-time multimodal full-duplex interaction. DuplexOmni separates model capability into an interaction layer and a thinking layer, which collaborate asynchronously in parallel. The interaction layer is implemented by the DuplexOmni model, an end-to-end system that processes streaming audio and video inputs while generating text and speech responses in real time. The thinking layer is a pluggable module that provides complex reasoning and tool-use capabilities. To support this method, we further develop a Writer-Director pipeline for constructing continuous-interaction training data. Experiments show that DuplexOmni achieves strong performance on multiple public benchmarks and exhibits natural full-duplex interaction ability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DuplexOmni, a method for real-time multimodal full-duplex interaction. It separates model capability into an interaction layer (implemented by the DuplexOmni end-to-end model that processes streaming audio/video inputs and generates text/speech responses) and a thinking layer (a pluggable module for complex reasoning and tool use). These layers collaborate asynchronously in parallel. A Writer-Director pipeline is introduced to construct continuous-interaction training data. The abstract states that experiments show strong performance on multiple public benchmarks and natural full-duplex interaction ability.
Significance. If the claims of effective asynchronous collaboration and benchmark performance hold with supporting evidence, the separation of interaction and thinking layers could enable more natural real-time multimodal AI systems that combine immediate responsiveness with deep reasoning. The Writer-Director data pipeline might address a key data scarcity issue for full-duplex training. However, the provided manuscript supplies no quantitative results, implementation details, or evaluations, so the significance cannot be assessed beyond the conceptual framing.
major comments (3)
- [Abstract] Abstract: The central claim that 'DuplexOmni achieves strong performance on multiple public benchmarks' is unsupported by any metrics, baselines, ablation studies, or experimental details. This directly undermines evaluation of the method's effectiveness for full-duplex interaction.
- [Abstract] Abstract: The assumption that the interaction layer and thinking layer 'collaborate asynchronously in parallel' without unacceptable latency, incoherence, or coordination failures is stated but receives no implementation description, latency measurements, or empirical test. This is load-bearing for the core architectural claim.
- [Abstract] Abstract: No details are provided on the DuplexOmni model architecture, training procedure, or how the Writer-Director pipeline generates data sufficient for stable full-duplex behavior, preventing assessment of whether the invented entities deliver the claimed capabilities.
minor comments (1)
- [Abstract] Abstract: The term 'DuplexOmni' is used both for the overall method and specifically for the interaction-layer model; clarifying this distinction in the title and text would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments correctly identify that the current manuscript version lacks the quantitative results, implementation specifics, and empirical measurements needed to fully support the abstract claims. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'DuplexOmni achieves strong performance on multiple public benchmarks' is unsupported by any metrics, baselines, ablation studies, or experimental details. This directly undermines evaluation of the method's effectiveness for full-duplex interaction.
Authors: We agree that the provided manuscript contains no metrics, baselines, ablation studies, or experimental details to support the performance claim. The revised version will add a full Experiments section reporting quantitative results on the referenced public benchmarks, including baselines and ablations. revision: yes
-
Referee: [Abstract] Abstract: The assumption that the interaction layer and thinking layer 'collaborate asynchronously in parallel' without unacceptable latency, incoherence, or coordination failures is stated but receives no implementation description, latency measurements, or empirical test. This is load-bearing for the core architectural claim.
Authors: This observation is accurate; the manuscript provides no implementation description, latency numbers, or tests for the asynchronous collaboration. In revision we will add a dedicated subsection describing the collaboration protocol together with latency measurements and empirical tests for coherence and coordination failures. revision: yes
-
Referee: [Abstract] Abstract: No details are provided on the DuplexOmni model architecture, training procedure, or how the Writer-Director pipeline generates data sufficient for stable full-duplex behavior, preventing assessment of whether the invented entities deliver the claimed capabilities.
Authors: We concur that the manuscript supplies no architecture diagrams, training procedure, or data-generation details for the Writer-Director pipeline. The revision will expand the Method section with these specifics, including how the pipeline produces training data that supports stable full-duplex behavior. revision: yes
Circularity Check
No significant circularity; derivation-free descriptive architecture
full rationale
The paper presents an architectural description of DuplexOmni (interaction layer + pluggable thinking layer + Writer-Director data pipeline) with no equations, no fitted parameters renamed as predictions, no self-citation chains, and no uniqueness theorems. The abstract and supplied text contain only high-level system claims and experimental statements; no derivation step reduces to its own inputs by construction. This is the expected outcome for a systems paper whose central contribution is an engineering decomposition rather than a mathematical derivation.
Axiom & Free-Parameter Ledger
invented entities (2)
-
DuplexOmni model
no independent evidence
-
Writer-Director pipeline
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Junjie Chen, Yao Hu, Junjie Li, Kangyue Li, Kun Liu, Wenpeng Li, Xu Li, Ziyuan Li, Feiyu Shen, Xu Tang, Manzhen Wei, Yichen Wu, Fenglong Xie, Kaituo Xu, and Kun Xie. 2025a. Fireredchat: A plug- gable, full-duplex voice interaction system with cas- caded and semi-cascaded implementations.CoRR, abs/2509.06502. Wenxi Chen, Ziyang Ma, Ruiqi Yan, Yuzhe Liang, ...
-
[2]
Qwen2-audio technical report.CoRR, abs/2407.10759. Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Moshi: a speech-text foundation model for real-time dialogue
Moshi: a speech- text foundation model for real-time dialogue.CoRR, abs/2410.00037. Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations
Enhancing chat language models by scaling high-quality instructional conver- sations.arXiv preprint arXiv:2305.14233. William Barr Held, Yanzhe Zhang, Weiyan Shi, Minzhi Li, Michael J. Ryan, and Diyi Yang
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Distill- ing an end-to-end voice assistant without instruction training data. InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 7876–7891. Association for Computational Linguistics. Baichuan Inc
2025
-
[6]
Yunjie Ji, Yan Gong, Yong Deng, Yiping Peng, Qiang Niu, Baochang Ma, and Xiangang Li
Baichuan-omni-1.5 technical re- port.CoRR, abs/2501.15368. Yunjie Ji, Yan Gong, Yong Deng, Yiping Peng, Qiang Niu, Baochang Ma, and Xiangang Li
-
[7]
Towards better instruction following language models for chi- nese: Investigating the impact of training data and evaluation.CoRR, abs/2304.07854. KimiTeam, Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, Zhengtao Wang, Chu Wei, Yifei Xin, Xinran Xu, Jianwei Yu, Yutao Zhang, Xinyu Zhou, Y . C...
-
[8]
Kimi- audio technical report.CoRR, abs/2504.18425. Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, Shahul ES, Sameer Suri, David Glushkov, Arnav Dantuluri, Andrew Maguire, Christoph Schuhmann, Huu Nguyen, and Alexander Mattick
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Openassistant conversations – democ- ratizing large language model alignment.Preprint, arXiv:2304.07327. Guan-Ting Lin, Jiachen Lian, Tingle Li, Qirui Wang, Gopala Anumanchipalli, Alexander H. Liu, and Hung-Yi Lee
-
[10]
InIEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2025, Honolulu, HI, USA, December 6-10, 2025, pages 1–8
Full-duplex-bench: A bench- mark to evaluate full-duplex spoken dialogue mod- els on turn-taking capabilities. InIEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2025, Honolulu, HI, USA, December 6-10, 2025, pages 1–8. IEEE. Yudong Lu, Yazhe Niu, Shuai Hu, and Haolin Wang
2025
-
[11]
Ziyang Ma, Yakun Song, Chenpeng Du, Jian Cong, Zhuo Chen, Yuping Wang, Yuxuan Wang, and Xie Chen
Cleans2s: Single-file framework for proactive speech-to-speech interaction.CoRR, abs/2506.01268. Ziyang Ma, Yakun Song, Chenpeng Du, Jian Cong, Zhuo Chen, Yuping Wang, Yuxuan Wang, and Xie Chen
-
[12]
Language model can listen while speak- ing. InThirty-Ninth AAAI Conference on Artificial Intelligence, Thirty-Seventh Conference on Innova- tive Applications of Artificial Intelligence, Fifteenth Symposium on Educational Advances in Artificial In- telligence, AAAI 2025, Philadelphia, PA, USA, Febru- ary 25 - March 4, 2025, pages 24831–24839. AAAI Press. T...
2025
- [13]
-
[14]
Gpt-4o system card.CoRR, abs/2410.21276. Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, South Brisbane, Queensland, Australia, April 19-24, 2015, pages 5206–5210
Librispeech: An ASR corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, South Brisbane, Queensland, Australia, April 19-24, 2015, pages 5206–5210. IEEE. 9 Nazneen Rajani, Lewis Tunstall, Edward Beeching, Nathan Lambert, Alexander M. Rush, and Thomas Wolf
2015
-
[16]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Un- locking multimodal understanding across millions of tokens of context.CoRR, abs/2403.05530. Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.arXiv preprint arXiv:2206.04615. Mirac Suzgun, Nathan Scales, Nathanael Schärli, Se- bastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, and Jason Wei
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261. Gemini Team
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: A family of highly capa- ble multimodal models.CoRR, abs/2312.11805. Qwen Team. 2025a. Qwen3-omni technical report. CoRR, abs/2509.17765. Qwen Team. 2025b. Qwen3 technical report.CoRR, abs/2505.09388. Qwen Team. 2026a. Qwen3-tts technical report.CoRR, abs/2601.15621. Qwen Team. 2026b. Qwen3.5-omni technical report. CoRR, abs/2604.15804. Tongyi Fun...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Peng Wang, Songshuo Lu, Yaohua Tang, Sijie Yan, Yuanjun Xiong, and Wei Xia
Fun-audio- chat technical report.CoRR, abs/2512.20156. Peng Wang, Songshuo Lu, Yaohua Tang, Sijie Yan, Yuanjun Xiong, and Wei Xia
-
[21]
A Full-Duplex Speech Dia- logue Scheme Based on Large Language Models,
A full-duplex speech dialogue scheme based on large language models.CoRR, abs/2405.19487. LLM-Core Xiaomi
-
[22]
Mimo-audio: Audio language models are few-shot learners.CoRR, abs/2512.23808. Zhifei Xie, Ziyang Ma, Zihang Liu, Kaiyu Pang, Hongyu Li, Jialin Zhang, Yue Liao, Deheng Ye, Chunyan Miao, and Shuicheng Yan
-
[23]
Mini- omni-reasoner: Token-level thinking-in-speaking in large speech models.CoRR, abs/2508.15827. Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin
-
[24]
Qwen2.5-omni technical report. CoRR, abs/2503.20215. Jianing Yang, Yusuke Fujita, and Yui Sudo
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Du- plexcascade: Full-duplex speech-to-speech dialogue with vad-free cascaded ASR-LLM-TTS pipeline and micro-turn optimization.CoRR, abs/2603.09180. Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, and 1 others
-
[26]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800. Wenyi Yu, Siyin Wang, Xiaoyu Yang, Xianzhao Chen, Xiaohai Tian, Jun Zhang, Guangzhi Sun, Lu Lu, Yux- uan Wang, and Chao Zhang
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu
Salmonn-omni: A standalone speech LLM without codec injection for full-duplex conversation.CoRR, abs/2505.17060. Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. 2023a. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. In Findings of the Association for Computational Lin- ...
-
[28]
Omniflatten: An end-to-end GPT model for seamless voice conversation. InProceedings of the 63rd An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vi- enna, Austria, July 27 - August 1, 2025, pages 14570– 14580. Association for Computational Linguistics. Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities,
Daily- omni: Towards audio-visual reasoning with temporal alignment across modalities.CoRR, abs/2505.17862. 10 A Full Control Token Set Table 4 lists the complete set of Director anno- tation tokens inserted during the Writer-Director pipeline. These tokens encode the temporal rela- tionship between user speech, assistant speech, and background thinking i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.