VAIC: Vision-Guided Humanoid Agile Object Interaction Control via Decoupled Commands
Pith reviewed 2026-06-27 16:36 UTC · model grok-4.3
The pith
VAIC distills a teacher policy into a single student policy that performs diverse agile object interactions on humanoids using only depth, proprioception, and decoupled commands.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
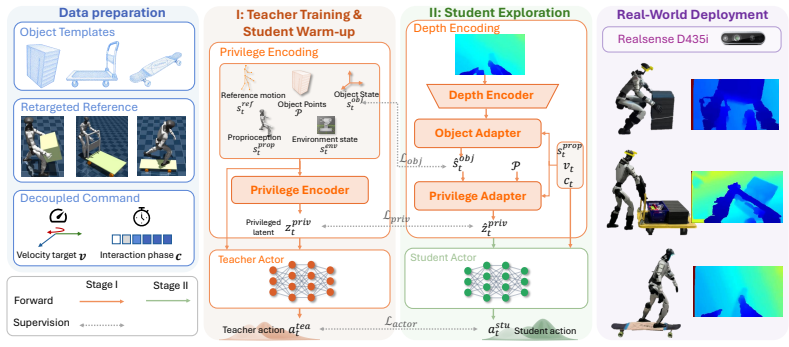
VAIC is a unified framework that bridges this gap by operating exclusively on onboard depth, historical proprioception, and a decoupled user command interface. It employs a two-stage distillation paradigm. First, a privileged teacher policy masters diverse interaction skills using precise object kinematics and exact environmental states. Second, a deployable student policy distills these capabilities by replacing full body tracking with velocity targets across multiple axes and an interaction indicator for each frame. The student utilizes a recurrent object adaptation module to implicitly infer unobservable object dynamics from raw depth streams and proprioception. Evaluations and real-world
What carries the argument
The recurrent object adaptation module, which replaces explicit state estimation by learning to recover hidden object dynamics directly from depth images and proprioceptive history inside the student policy.
If this is right
- A single policy can execute multiple dynamic tasks without per-task retraining or reference trajectories.
- Control remains functional when full environmental state is unavailable, relying instead on onboard depth and proprioception.
- Decoupled velocity commands plus an interaction flag suffice to coordinate whole-body motion for carrying, pushing, and balancing tasks.
- Real-world transfer succeeds on a physical humanoid without additional sensing hardware beyond depth and joint encoders.
Where Pith is reading between the lines
- The same distillation structure might allow reuse of the teacher across different robot morphologies if the student input interface stays fixed.
- Replacing explicit dynamics models with recurrent vision inference could reduce the engineering cost of adding new object classes.
- Extending the command interface to include higher-level goals such as target locations would test whether the current velocity-plus-indicator format remains sufficient.
Load-bearing premise
The recurrent object adaptation module can implicitly infer unobservable object dynamics from raw depth streams and proprioception.
What would settle it
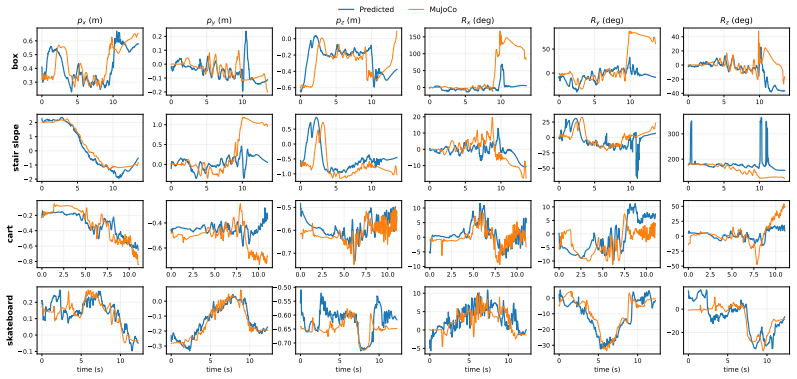
Deploy the student policy on objects whose mass or surface friction differs from training examples and measure whether interaction stability collapses when the module receives no explicit dynamics parameters.
Figures


read the original abstract
Humanoid robots hold immense potential for real-world assistance, yet agile interaction with objects in unstructured environments demands tightly coupled whole-body coordination. Despite recent advancements, current controllers face a critical deployment gap. They rely heavily on dense reference trajectories and perfect state observability, which inherently limits physical generalization. We present Vision Guided Agile Interaction Control (VAIC), a unified framework that bridges this gap by operating exclusively on onboard depth, historical proprioception, and a decoupled user command interface. VAIC employs a two-stage distillation paradigm. First, a privileged teacher policy masters diverse interaction skills using precise object kinematics and exact environmental states. Second, a deployable student policy distills these capabilities by replacing full body tracking with velocity targets across multiple axes and an interaction indicator for each frame. The student utilizes a recurrent object adaptation module to implicitly infer unobservable object dynamics from raw depth streams and proprioception. Evaluations and real-world deployments on the humanoid robot demonstrate that a single VAIC policy successfully executes highly diverse dynamic tasks. These tasks include box carrying, cart interaction, and skateboarding, consistently outperforming baselines and advancing autonomous humanoid deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VAIC, a two-stage distillation framework for humanoid agile object interaction. A privileged teacher policy learns diverse skills with full state access; the student policy operates on depth, proprioception history, and decoupled velocity targets plus an interaction indicator, using a recurrent object adaptation module to infer unobservable dynamics. The central claim is that a single student policy executes box carrying, cart interaction, and skateboarding on a real humanoid, consistently outperforming baselines.
Significance. If validated with quantitative evidence, the decoupled command interface and recurrent adaptation for implicit dynamics inference would represent a meaningful step toward generalizable humanoid controllers that reduce dependence on perfect observability and dense trajectories. The two-stage paradigm is a clear strength for sim-to-real transfer in multi-contact tasks.
major comments (2)
- [Abstract and Evaluations section] Abstract and Evaluations section: the claim that a single policy 'consistently outperforming baselines' on real-robot tasks is made without any reported metrics, baseline implementations, trial counts, success rates, or failure-mode analysis; this directly undermines assessment of the multi-task generalization result.
- [Student policy description] Student policy description (recurrent object adaptation module): no ablation studies, object-parameter variation sweeps, or quantitative tests are provided to support the claim that the RNN implicitly infers unobservable dynamics (mass distribution, friction, compliance) from depth and proprioception history across qualitatively different contact regimes; this is load-bearing for the headline claim.
minor comments (1)
- [Method] Notation for the decoupled velocity targets and interaction indicator could be made more explicit with an equation or diagram reference.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract and Evaluations section] Abstract and Evaluations section: the claim that a single policy 'consistently outperforming baselines' on real-robot tasks is made without any reported metrics, baseline implementations, trial counts, success rates, or failure-mode analysis; this directly undermines assessment of the multi-task generalization result.
Authors: We agree that the abstract's claim requires quantitative backing to be fully assessable. The current evaluations section focuses on qualitative real-robot demonstrations. We will revise to include a dedicated quantitative table reporting success rates, number of trials, baseline implementations, and failure-mode analysis for each task. revision: yes
-
Referee: [Student policy description] Student policy description (recurrent object adaptation module): no ablation studies, object-parameter variation sweeps, or quantitative tests are provided to support the claim that the RNN implicitly infers unobservable dynamics (mass distribution, friction, compliance) from depth and proprioception history across qualitatively different contact regimes; this is load-bearing for the headline claim.
Authors: The referee is correct that the submitted manuscript lacks ablations or parameter sweeps for the recurrent adaptation module. We will add new experiments, including ablations with and without the RNN, plus quantitative tests varying object mass, friction, and compliance across contact regimes, to directly support the inference claim. revision: yes
Circularity Check
No circularity: standard teacher-student distillation with no self-referential definitions or fitted predictions
full rationale
The paper describes a conventional two-stage RL distillation pipeline (privileged teacher mastering skills with full state, student trained on depth/proprioception plus velocity targets) without any equations, parameters, or uniqueness claims that reduce the reported outcome to its own inputs by construction. The recurrent adaptation module is presented as a trained component whose inference capability is an empirical training result rather than a definitional identity. No self-citations are invoked as load-bearing mathematical facts, and no fitted quantities are relabeled as independent predictions. The derivation chain is therefore self-contained against external RL benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. Wang, W. Zhang, R. Yu, T. Huang, J. Ren, F. Jia, Z. Wang, X. Niu, X. Chen, J. Chen, et al. Physhsi: Towards a real-world generalizable and natural humanoid-scene interaction system. arXiv preprint arXiv:2510.11072, 2025
arXiv 2025
-
[2]
H. Weng, Y . Li, N. Sobanbabu, Z. Wang, Z. Luo, T. He, D. Ramanan, and G. Shi. Hdmi: Learning interactive humanoid whole-body control from human videos.arXiv preprint arXiv:2509.16757, 2025
arXiv 2025
-
[3]
S. Zhao, Y . Ze, Y . Wang, C. K. Liu, P. Abbeel, G. Shi, and R. Duan. Resmimic: From gen- eral motion tracking to humanoid whole-body loco-manipulation via residual learning.arXiv preprint arXiv:2510.05070, 2025
arXiv 2025
-
[4]
S. Yin, Y . Ze, H.-X. Yu, C. K. Liu, and J. Wu. Visualmimic: Visual humanoid loco- manipulation via motion tracking and generation.arXiv preprint arXiv:2509.20322, 2025
arXiv 2025
-
[5]
D. Li, X. Chen, Q. Wu, B. Chen, S. Wu, H. Wu, G. Zhang, L. Li, M. Zhou, D. Xiang, J. Ma, Q. Zhang, and R. Xu. Haic: Humanoid agile object interaction control via dynamics-aware world model.arXiv preprint arXiv:2602.11758, 2026
Pith/arXiv arXiv 2026
-
[6]
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025
Pith/arXiv arXiv 2025
-
[7]
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Casta ˜neda, Z.-A. Cao, J. Li, D. Minor, Q. Ben, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025
Pith/arXiv arXiv 2025
-
[8]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4): 1–20, 2021
2021
-
[9]
Y . Lin, J. Shi, D. Wang, J. Kong, Y . Liu, C. Bai, and X. Li. Pro-hoi: Perceptive root-guided humanoid-object interaction.arXiv preprint arXiv:2603.01126, 2026
arXiv 2026
-
[10]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi. Omniretarget: Interaction-preserving data generation for humanoid whole-body loco- manipulation and scene interaction.arXiv preprint arXiv:2509.26633, 2025
Pith/arXiv arXiv 2025
-
[11]
Y . Wang, Q. Zhao, Y . F. Lau, R. Yu, H. W. Tsui, Q. Chen, J. Wang, J. Pang, and P. Tan. Humanx: Toward agile and generalizable humanoid interaction skills from human videos.arXiv preprint arXiv:2602.02473, 2026
arXiv 2026
-
[12]
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne. Deepmimic: Example-guided deep re- inforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
2018
-
[13]
Z. Chen, M. Ji, X. Cheng, X. Peng, X. B. Peng, and X. Wang. Gmt: General motion tracking for humanoid whole-body control.arXiv preprint arXiv:2506.14770, 2025
arXiv 2025
-
[14]
K. Yin, W. Zeng, K. Fan, M. Dai, Z. Wang, Q. Zhang, Z. Tian, J. Wang, J. Pang, and W. Zhang. Unitracker: Learning universal whole-body motion tracker for humanoid robots.arXiv preprint arXiv:2507.07356, 2025
arXiv 2025
-
[15]
J. P. Araujo, Y . Ze, P. Xu, J. Wu, and C. K. Liu. Retargeting matters: General motion retargeting for humanoid motion tracking.arXiv preprint arXiv:2510.02252, 2025. 9
arXiv 2025
-
[16]
T. He, W. Xiao, T. Lin, Z. Luo, Z. Xu, Z. Jiang, J. Kautz, C. Liu, G. Shi, X. Wang, et al. Hover: Versatile neural whole-body controller for humanoid robots. InInternational Conference on Robotics and Automation (ICRA), 2025
2025
-
[17]
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbabu, C. Pan, Z. Yi, G. Qu, K. Kitani, J. Hodgins, L. J. Fan, Y . Zhu, C. Liu, and G. Shi. Asap: Aligning sim- ulation and real-world physics for learning agile humanoid whole-body skills.arXiv preprint arXiv:2502.01143, 2025
arXiv 2025
- [18]
-
[19]
W. Zeng, S. Lu, K. Yin, X. Niu, M. Dai, J. Wang, and J. Pang. Behavior foundation model for humanoid robots.arXiv preprint arXiv:2509.13780, 2025
arXiv 2025
-
[20]
M. Yuan, T. Yu, W. Ge, X. Yao, D. Li, H. Wang, J. Chen, X. Jin, B. Li, H. Chen, et al. Behavior foundation model: Towards next-generation whole-body control system of humanoid robots. arXiv preprint arXiv:2506.20487, 2025
arXiv 2025
-
[21]
Y . Li, Z. Luo, T. Zhang, C. Dai, A. Kanervisto, A. Tirinzoni, H. Weng, K. Kitani, M. Guzek, A. Touati, et al. Bfm-zero: A promptable behavioral foundation model for humanoid control using unsupervised reinforcement learning.arXiv preprint arXiv:2511.04131, 2025
arXiv 2025
- [22]
-
[23]
Y . Shao, X. Huang, B. Zhang, Q. Liao, Y . Gao, Y . Chi, Z. Li, S. Shao, and K. Sreenath. Langwbc: Language-directed humanoid whole-body control via end-to-end learning.arXiv preprint arXiv:2504.21738, 2025
arXiv 2025
-
[24]
B. L. Bhatnagar, X. Xie, I. Petrov, C. Sminchisescu, C. Theobalt, and G. Pons-Moll. BEHA VE: Dataset and method for tracking human object interactions. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2022
2022
-
[25]
Zhang, H
J. Zhang, H. Luo, H. Yang, X. Xu, Q. Wu, Y . Shi, J. Yu, L. Xu, and J. Wang. Neuraldome: A neural modeling pipeline on multi-view human-object interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8834–8845, 2023
2023
-
[26]
Lu, C.-H
J. Lu, C.-H. P. Huang, U. Bhattacharya, Q. Huang, and Y . Zhou. Humoto: A 4d dataset of mocap human object interactions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10886–10897, 2025
2025
-
[27]
C. Zhao, J. Zhang, J. Du, Z. Shan, J. Wang, J. Yu, J. Wang, and L. Xu. I’m hoi: Inertia- aware monocular capture of 3d human-object interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 729–741, 2024
2024
-
[28]
S. Xu, D. Li, Y . Zhang, X. Xu, Q. Long, Z. Wang, Y . Lu, S. Dong, H. Jiang, A. Gupta, Y .-X. Wang, and L.-Y . Gui. Interact: Advancing large-scale versatile 3d human-object interac- tion generation. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025
2025
-
[29]
Y . Wang, J. Lin, A. Zeng, Z. Luo, J. Zhang, and L. Zhang. Physhoi: Physics-based imitation of dynamic human-object interaction.arXiv preprint arXiv:2312.04393, 2023
arXiv 2023
-
[30]
S. Xu, H. Y . Ling, Y .-X. Wang, and L. Gui. Intermimic: Towards universal whole-body con- trol for physics-based human-object interactions. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025. 10
2025
-
[31]
Y . Lin, Y . Xie, J. Xie, Y . Huang, R. Wang, J. Lv, Y . Ma, and X. Zuo. Simgenhoi: Physically realistic whole-body humanoid-object interaction via generative modeling and reinforcement learning.arXiv preprint arXiv:2508.14120, 2025
arXiv 2025
-
[32]
Q. Wu, Y . Shi, X. Huang, J. Yu, L. Xu, and J. Wang. Thor: Text to human-object interaction diffusion via relation intervention.arXiv preprint arXiv:2403.11208, 2024
arXiv 2024
-
[33]
L. Pan, Z. Yang, Z. Dou, W. Wang, B. Huang, B. Dai, T. Komura, and J. Wang. Tokenhsi: Uni- fied synthesis of physical human-scene interactions through task tokenization. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025
2025
-
[34]
J. Dao, H. Duan, and A. Fern. Sim-to-real learning for humanoid box loco-manipulation. In International Conference on Robotics and Automation (ICRA), 2024
2024
- [35]
-
[36]
W. Sun, L. Feng, B. Cao, Y . Liu, Y . Jin, and Z. Xie. Ulc: A unified and fine-grained controller for humanoid loco-manipulation.arXiv preprint arXiv:2507.06905, 2025
arXiv 2025
-
[37]
L. Wei, X. Peng, R.-Z. Qiu, T. Huang, X. Cheng, and X. Wang. Hmc: Learning heterogeneous meta-control for contact-rich loco-manipulation.arXiv preprint arXiv:2511.14756, 2025
arXiv 2025
- [38]
-
[39]
Y . Chen, S. Dong, X. Ji, J. Sun, Z. Luo, L. Zhao, J. Zhang, W. Li, J. Ma, B. Xu, et al. Learning human-like badminton skills for humanoid robots.arXiv preprint arXiv:2602.08370, 2026
arXiv 2026
-
[40]
J. Kong, X. Liu, Y . Lin, J. Han, S. Schwertfeger, C. Bai, and X. Li. Learning soccer skills for humanoid robots: A progressive perception-action framework.arXiv preprint arXiv:2602.05310, 2026
arXiv 2026
-
[41]
J. Ren, Y . Li, K. Zhang, P. Fu, H. Jiang, Y . Pan, G. Zeng, T. Huang, W. Guo, P. Lu, et al. Smash: Mastering scalable whole-body skills for humanoid ping-pong with egocentric vision. arXiv preprint arXiv:2604.01158, 2026
arXiv 2026
-
[42]
Allshire, H
A. Allshire, H. Choi, J. Zhang, D. McAllister, A. Zhang, C. M. Kim, T. Darrell, P. Abbeel, J. Malik, and A. Kanazawa. Visual imitation enables contextual humanoid control. InPro- ceedings of the Conference on Robot Learning (CoRL), 2025
2025
-
[43]
T. Wu, X. Kong, Y . Chen, Q. Yu, H. Ye, J. Li, Y . Wang, and H. Dong. Sugar: A scalable human- video-driven generalizable humanoid loco-manipulation learning framework.arXiv preprint arXiv:2605.20373, 2026
Pith/arXiv arXiv 2026
-
[44]
Agarwal, A
A. Agarwal, A. Kumar, J. Malik, and D. Pathak. Legged locomotion in challenging terrains using egocentric vision. InConference on Robot Learning (CoRL), 2022
2022
-
[45]
J. Long, J. Ren, M. Shi, Z. Wang, T. Huang, P. Luo, and J. Pang. Learning humanoid locomo- tion with perceptive internal model.arXiv preprint arXiv:2411.14386, 2024
arXiv 2024
-
[46]
J. Sun, G. Han, P. Sun, W. Zhao, J. Cao, J. Wang, Y . Guo, and Q. Zhang. Dpl: Depth- only perceptive humanoid locomotion via realistic depth synthesis and cross-attention terrain reconstruction.arXiv preprint arXiv:2510.07152, 2025
arXiv 2025
-
[47]
C. Han, S. He, Y . Cheng, L. Ye, and H. Liu. Prior: Perceptive learning for humanoid locomo- tion with reference gait priors.arXiv preprint arXiv:2603.18979, 2026. 11
arXiv 2026
- [48]
-
[49]
W. Sun, Y . Su, L. Huang, A. Zhang, D. Wei, M. San, D. Tian, E. Cao, B. Cao, Y . Liu, et al. Now you see that: Learning end-to-end humanoid locomotion from raw pixels.arXiv preprint arXiv:2602.06382, 2026
Pith/arXiv arXiv 2026
-
[50]
Zhuang, S
Z. Zhuang, S. Yao, and H. Zhao. Humanoid parkour learning. InConference on Robot Learn- ing (CoRL), 2024
2024
-
[51]
Z. Wu, X. Huang, L. Yang, Y . Zhang, K. Sreenath, X. Chen, P. Abbeel, R. Duan, A. Kanazawa, C. Sferrazza, et al. Perceptive humanoid parkour: Chaining dynamic human skills via motion matching.arXiv preprint arXiv:2602.15827, 2026
Pith/arXiv arXiv 2026
- [52]
-
[53]
S. Zhu, B. Ye, J. Wang, J. Chen, Z. Zhuang, L. Mou, R. Huang, and H. Zhao. Ttt-parkour: Rapid test-time training for perceptive robot parkour.arXiv preprint arXiv:2602.02331, 2026
arXiv 2026
-
[54]
H. Xue, X. Huang, D. Niu, Q. Liao, T. Kragerud, J. T. Gravdahl, X. B. Peng, G. Shi, T. Dar- rell, K. Sreenath, et al. Leverb: Humanoid whole-body control with latent vision-language instruction.arXiv preprint arXiv:2506.13751, 2025
arXiv 2025
-
[55]
T. He, Z. Wang, H. Xue, Q. Ben, Z. Luo, W. Xiao, Y . Yuan, X. Da, F. Casta ˜neda, S. Sas- try, et al. Viral: Visual sim-to-real at scale for humanoid loco-manipulation.arXiv preprint arXiv:2511.15200, 2025
arXiv 2025
- [56]
-
[57]
H. Liu, Y . Gao, S. Teng, Y . Chi, Y . S. Shao, Z. Li, M. Ghaffari, and K. Sreenath. Ego-vision world model for humanoid contact planning. InInternational Conference on Robotics and Automation (ICRA), 2026
2026
-
[58]
Y . Lin, J. Cui, Y . Li, B. Jia, Y . Zhu, and S. Huang. Lessmimic: Long-horizon humanoid interaction with unified distance field representations.arXiv preprint arXiv:2602.21723, 2026
arXiv 2026
-
[59]
X. He, S. Xu, X. Li, R. Dong, L. Bian, Y .-X. Wang, and L.-Y . Gui. Ultra: Unified mul- timodal control for autonomous humanoid whole-body loco-manipulation.arXiv preprint arXiv:2603.03279, 2026
arXiv 2026
-
[60]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 12 V AIC: Vision-Guided Humanoid Agile Object Interaction Control via Decoupled Commands Appendix In this appendix, we provide additional experimental setups and details: 1.Demo Video.A demonstration video includin...
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.