KPGrasp: Scalable Keypoint Flow Matching for Dexterous Grasp Generation
Pith reviewed 2026-06-27 16:31 UTC · model grok-4.3
The pith
Keypoint flow matching with an all-Euclidean hand parameterization generates dexterous grasps at 76.3 percent success using only the standard loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
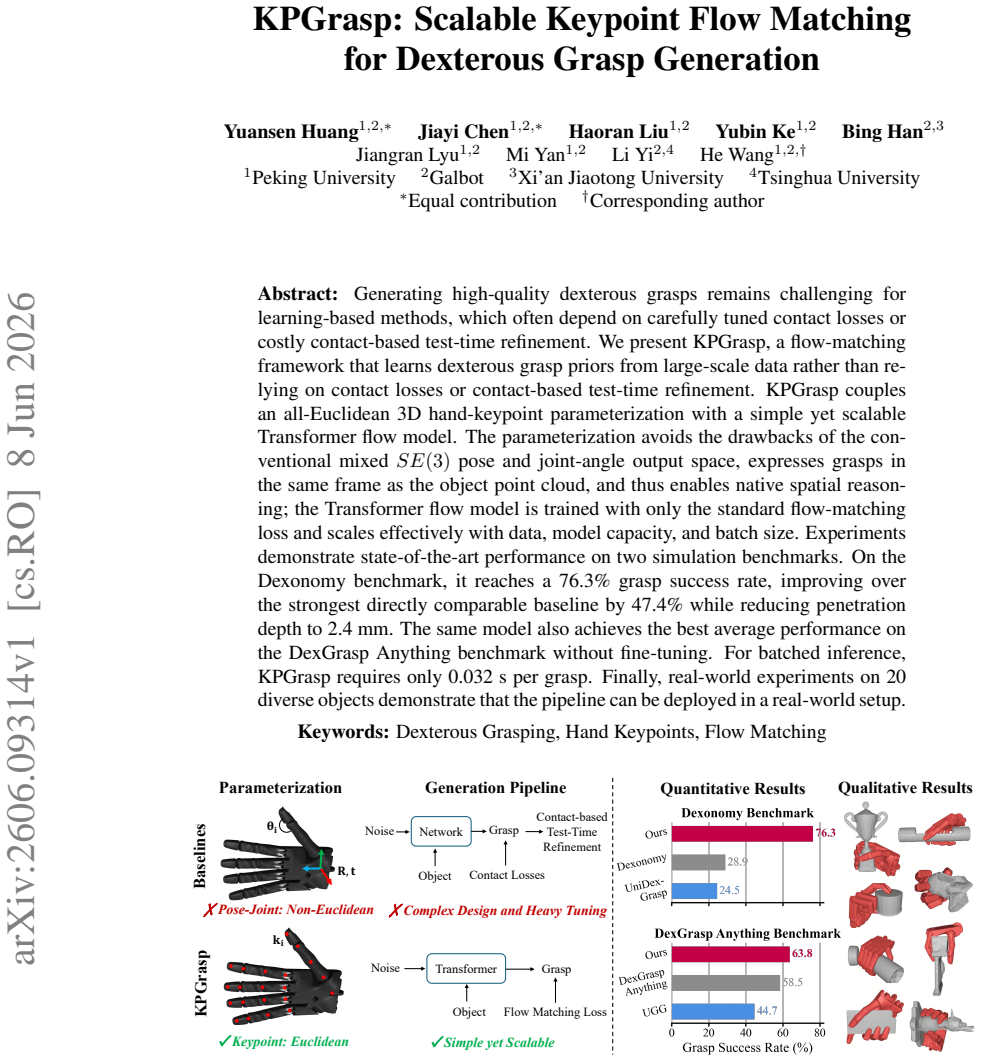
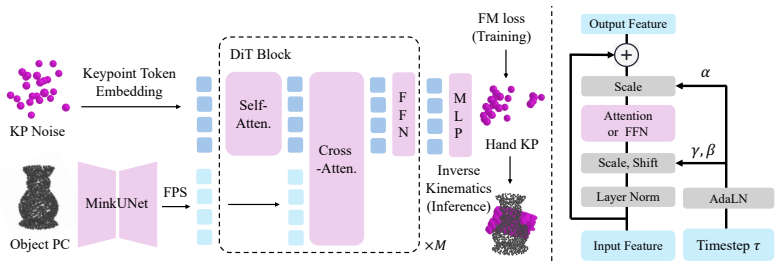
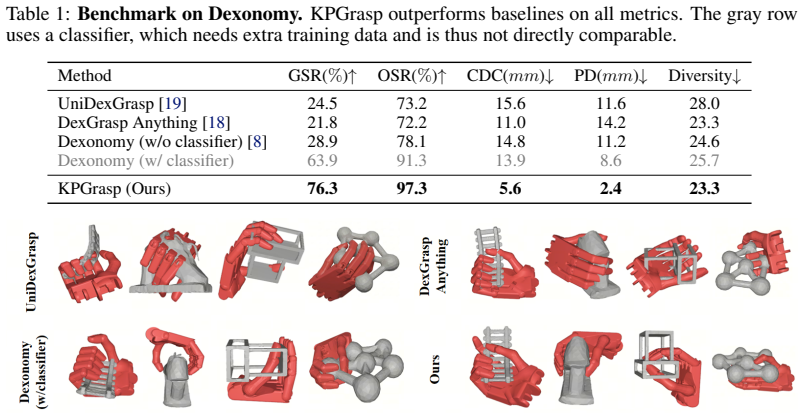
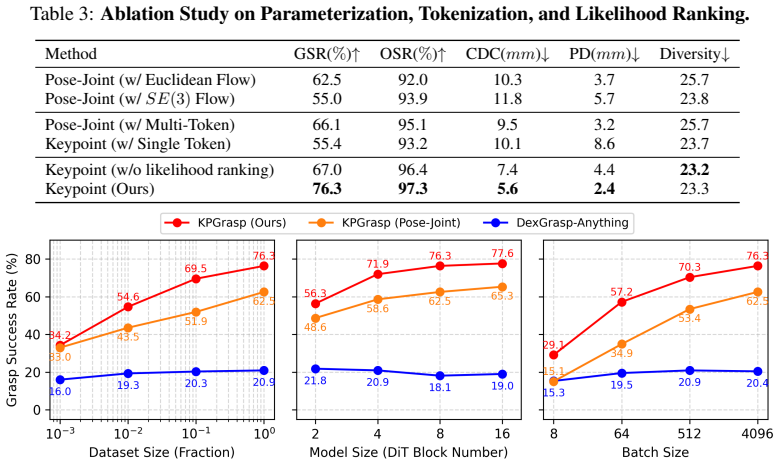
KPGrasp shows that dexterous grasp distributions can be modeled by transporting hand keypoints in Euclidean 3D space with a scalable Transformer flow model trained exclusively on the standard flow-matching loss; the resulting generator reaches 76.3 percent success on Dexonomy with 2.4 mm penetration, improves 47.4 percent over the best directly comparable baseline, leads the DexGrasp Anything benchmark without fine-tuning, and transfers to twenty real objects at 0.032 s per grasp.
What carries the argument
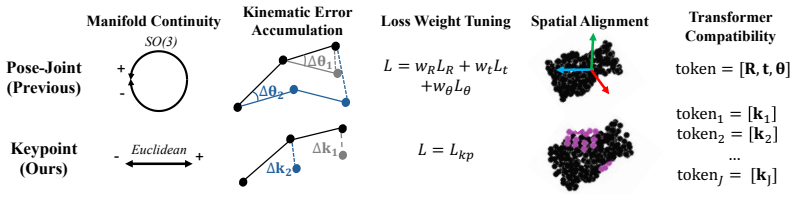
All-Euclidean 3D hand-keypoint parameterization that places grasp configurations in the same frame as the object point cloud, allowing a Transformer flow model to perform native spatial reasoning under the plain flow-matching objective.
If this is right
- Reaches 76.3 percent grasp success rate on the Dexonomy benchmark while cutting penetration depth to 2.4 mm.
- Improves 47.4 percent over the strongest directly comparable baseline that also avoids contact losses.
- Leads the DexGrasp Anything benchmark in average performance without any fine-tuning.
- Runs at 0.032 seconds per grasp under batched inference.
- Transfers directly to real-robot execution on twenty diverse objects.
Where Pith is reading between the lines
- Keypoint representations may reduce the need for hand-crafted contact terms across other contact-rich manipulation tasks.
- The observed scaling with data volume and model size suggests further gains are available from larger training corpora.
- Removing contact-loss engineering could shorten the iteration cycle when adapting the method to new robot hands.
- The same flow-matching pipeline might be tested on in-hand reorientation or tool-use sequences without redesigning the loss.
Load-bearing premise
The all-Euclidean 3D hand-keypoint parameterization is expressive enough to represent valid, collision-free dexterous grasps that generalize from large-scale training data to both simulation benchmarks and real-world objects.
What would settle it
A new test set of objects where the generated keypoint trajectories match the learned distribution yet produce frequent joint-limit violations or undetected collisions in full physics simulation would falsify the claim.
Figures

read the original abstract
Generating high-quality dexterous grasps remains challenging for learning-based methods, which often depend on carefully tuned contact losses or costly contact-based test-time refinement. We present KPGrasp, a flow-matching framework that learns dexterous grasp priors from large-scale data rather than relying on contact losses or contact-based test-time refinement. KPGrasp couples an all-Euclidean 3D hand-keypoint parameterization with a simple yet scalable Transformer flow model. The parameterization avoids the drawbacks of the conventional mixed SE(3) pose and joint-angle output space, expresses grasps in the same frame as the object point cloud, and thus enables native spatial reasoning; the Transformer flow model is trained with only the standard flow-matching loss and scales effectively with data, model capacity, and batch size. Experiments demonstrate state-of-the-art performance on two simulation benchmarks. On the Dexonomy benchmark, it reaches a 76.3% grasp success rate, improving over the strongest directly comparable baseline by 47.4% while reducing penetration depth to 2.4 mm. The same model also achieves the best average performance on the DexGrasp Anything benchmark without fine-tuning. For batched inference, KPGrasp requires only 0.032 s per grasp. Finally, real-world experiments on 20 diverse objects demonstrate that the pipeline can be deployed in a real-world setup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KPGrasp, a flow-matching framework for dexterous grasp generation that couples an all-Euclidean 3D hand-keypoint parameterization with a scalable Transformer model. The approach is trained using only the standard flow-matching loss on large-scale data, without contact losses or contact-based test-time refinement. It reports state-of-the-art results on the Dexonomy benchmark (76.3% grasp success rate, 47.4% improvement over the strongest comparable baseline, 2.4 mm penetration depth) and best average performance on the DexGrasp Anything benchmark without fine-tuning, along with 0.032 s per-grasp batched inference and successful real-world deployment on 20 diverse objects.
Significance. If the experimental claims hold under detailed scrutiny, the work shows that a simple, scalable data-driven flow model on a Euclidean keypoint representation can deliver strong dexterous grasping performance without specialized contact terms. This would be a meaningful simplification for the field and supports the value of scaling model capacity, batch size, and training data in grasp generation.
major comments (2)
- [§3] §3 (Method, keypoint parameterization subsection): The central claim that the standard flow-matching loss alone suffices for 76.3% success and 2.4 mm penetration rests on the all-Euclidean 3D keypoint parameterization being expressive enough to represent only valid, collision-free grasps. The text states that this parameterization 'avoids the drawbacks of the conventional mixed SE(3) pose and joint-angle output space' and 'enables native spatial reasoning,' but provides no explicit mechanism (fixed bone lengths, joint limits, or intra-hand collision avoidance) to keep generated keypoints on the reachable manifold. Without such constraints or a described decoding/projection step, it is unclear whether performance derives from the flow model or from training-data statistics; this must be clarified with concrete evidence from the model architecture or post-processing.
- [§5] §5 (Experiments, Dexonomy benchmark results): The reported 76.3% success rate and 47.4% relative improvement are load-bearing for the 'no contact losses or refinement' thesis. The abstract supplies no protocol details, baseline definitions, statistical significance, or ablation evidence; the full experimental section must include these (e.g., exact success metric definition, number of trials, variance across seeds, and direct comparison to the 'strongest directly comparable baseline') to substantiate that the gains are not artifacts of unstated post-processing.
minor comments (2)
- The abstract states 'the same model also achieves the best average performance on the DexGrasp Anything benchmark without fine-tuning' but does not define 'average performance' (success rate, penetration, or a composite metric). Clarify the metric and report per-object or per-category breakdowns for transparency.
- Real-world experiments are mentioned on 20 objects but lack quantitative metrics (success rate, penetration) or failure-mode analysis comparable to the simulation benchmarks. Adding these would strengthen the deployment claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity on the keypoint parameterization and to expand experimental protocol details.
read point-by-point responses
-
Referee: [§3] §3 (Method, keypoint parameterization subsection): The central claim that the standard flow-matching loss alone suffices for 76.3% success and 2.4 mm penetration rests on the all-Euclidean 3D keypoint parameterization being expressive enough to represent only valid, collision-free grasps. The text states that this parameterization 'avoids the drawbacks of the conventional mixed SE(3) pose and joint-angle output space' and 'enables native spatial reasoning,' but provides no explicit mechanism (fixed bone lengths, joint limits, or intra-hand collision avoidance) to keep generated keypoints on the reachable manifold. Without such constraints or a described decoding/projection step, it is unclear whether performance derives from the flow model or from training-data statistics; this must be clarified with concrete evidence from the model architecture or post-processing.
Authors: The all-Euclidean 3D keypoint parameterization contains no explicit mechanisms such as fixed bone lengths, joint limits, or intra-hand collision avoidance, either in the architecture or as post-processing. The model is trained solely with the standard flow-matching loss on large-scale valid grasp data; the Transformer learns the distribution of feasible keypoint configurations directly from that data, which empirically yields low penetration without contact terms. We will revise §3 to state this explicitly and add a short discussion of why hard constraints were omitted in favor of a purely data-driven approach. revision: yes
-
Referee: [§5] §5 (Experiments, Dexonomy benchmark results): The reported 76.3% success rate and 47.4% relative improvement are load-bearing for the 'no contact losses or refinement' thesis. The abstract supplies no protocol details, baseline definitions, statistical significance, or ablation evidence; the full experimental section must include these (e.g., exact success metric definition, number of trials, variance across seeds, and direct comparison to the 'strongest directly comparable baseline') to substantiate that the gains are not artifacts of unstated post-processing.
Authors: We agree that the experimental section requires additional protocol details to support the claims. In the revision we will specify the exact success metric (object lift without drop within a fixed time), the number of evaluation trials per object, reported variance across random seeds, and the precise definition of the strongest directly comparable baseline. No contact-based post-processing or refinement was applied at test time; the reported numbers reflect direct sampling from the flow model. We will also include the requested ablation evidence in §5. revision: yes
Circularity Check
No circularity: empirical results from standard flow-matching on external benchmarks
full rationale
The paper describes a data-driven Transformer flow model trained solely with the standard flow-matching loss on large-scale data, using an all-Euclidean keypoint parameterization. Reported metrics (76.3% success, 2.4 mm penetration) are measured on independent simulation benchmarks (Dexonomy, DexGrasp Anything) and real-world objects; they do not reduce to quantities defined inside the paper by construction, fitted parameters renamed as predictions, or self-citation chains. The method explicitly avoids contact losses and test-time refinement, making performance an external validation rather than a tautology. No load-bearing step matches any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
free parameters (1)
- Transformer capacity, batch size, and training data scale
axioms (1)
- domain assumption Large-scale grasp datasets contain representative examples of valid dexterous grasps that can be learned via flow matching without explicit contact modeling
Reference graph
Works this paper leans on
-
[1]
A. T. Miller and P. K. Allen. Graspit! a versatile simulator for robotic grasping.IEEE Robotics & Automation Magazine, 11(4):110–122, 2004
2004
-
[2]
Ciocarlie, C
M. Ciocarlie, C. Goldfeder, and P. Allen. Dexterous grasping via eigengrasps: A low- dimensional approach to a high-complexity problem. InRobotics: Science and systems ma- nipulation workshop-sensing and adapting to the real world, 2007
2007
-
[3]
T. Liu, Z. Liu, Z. Jiao, Y . Zhu, and S.-C. Zhu. Synthesizing diverse and physically stable grasps with arbitrary hand structures using differentiable force closure estimator.IEEE Robotics and Automation Letters, 7(1):470–477, 2021
2021
-
[4]
A. H. Li, P. Culbertson, J. W. Burdick, and A. D. Ames. Frogger: Fast robust grasp generation via the min-weight metric. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6809–6816. IEEE, 2023
2023
- [5]
-
[6]
J. Chen, Y . Chen, J. Zhang, and H. Wang. Task-oriented dexterous hand pose synthesis using differentiable grasp wrench boundary estimator. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5281–5288. IEEE, 2024
2024
-
[7]
J. Chen, Y . Ke, and H. Wang. Bodex: Scalable and efficient robotic dexterous grasp synthesis using bilevel optimization. In2025 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 01–08. IEEE, 2025
2025
- [8]
-
[9]
Ferrari, J
C. Ferrari, J. F. Canny, et al. Planning optimal grasps. InICRA, volume 3, page 6, 1992
1992
- [10]
-
[11]
Zhang, H
J. Zhang, H. Liu, D. Li, X. Yu, H. Geng, Y . Ding, J. Chen, and H. Wang. Dexgraspnet 2.0: Learning generative dexterous grasping in large-scale synthetic cluttered scenes. In8th Annual Conference on Robot Learning, 2024. 11
2024
- [12]
-
[13]
J. He, D. Li, X. Yu, Z. Qi, W. Zhang, J. Chen, Z. Zhang, Z. Zhang, L. Yi, and H. Wang. Dexvlg: Dexterous vision-language-grasp model at scale. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14248–14258, 2025
2025
-
[14]
T. Feix, J. Romero, H.-B. Schmiedmayer, A. M. Dollar, and D. Kragic. The grasp taxonomy of human grasp types.IEEE Transactions on human-machine systems, 46(1):66–77, 2015
2015
-
[15]
Jiang, S
H. Jiang, S. Liu, J. Wang, and X. Wang. Hand-object contact consistency reasoning for human grasps generation. InProceedings of the IEEE/CVF international conference on computer vision, pages 11107–11116, 2021
2021
-
[16]
T. Zhu, R. Wu, X. Lin, and Y . Sun. Toward human-like grasp: Dexterous grasping via semantic representation of object-hand. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15741–15751, 2021
2021
-
[17]
Xu, Y .-L
G.-H. Xu, Y .-L. Wei, D. Zheng, X.-M. Wu, and W.-S. Zheng. Dexterous grasp transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17933–17942, 2024
2024
-
[18]
Zhong, Q
Y . Zhong, Q. Jiang, J. Yu, and Y . Ma. Dexgrasp anything: Towards universal robotic dex- terous grasping with physics awareness. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22584–22594, 2025
2025
-
[19]
Y . Xu, W. Wan, J. Zhang, H. Liu, Z. Shan, H. Shen, R. Wang, H. Geng, Y . Weng, J. Chen, et al. Unidexgrasp: Universal robotic dexterous grasping via learning diverse proposal generation and goal-conditioned policy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4737–4746, 2023
2023
- [20]
-
[21]
J. Lu, H. Kang, H. Li, B. Liu, Y . Yang, Q. Huang, and G. Hua. Ugg: Unified generative grasping. InEuropean Conference on Computer Vision, pages 414–433. Springer, 2024
2024
-
[22]
Z. Weng, H. Lu, D. Kragic, and J. Lundell. Dexdiffuser: Generating dexterous grasps with diffusion models.IEEE Robotics and Automation Letters, 9(12):11834–11840, 2024
2024
-
[23]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5745–5753, 2019
2019
- [24]
- [25]
- [26]
- [27]
- [28]
-
[29]
B. Lim, J. Kim, J. Kim, Y . Lee, and F. C. Park. Equigraspflow: Se (3)-equivariant 6-dof grasp pose generative flows. In8th Annual Conference on Robot Learning, 2024
2024
- [30]
-
[31]
Cheng, J
W. Cheng, J. H. Park, and J. H. Ko. Handfoldingnet: A 3d hand pose estimation network using multiscale-feature guided folding of a 2d hand skeleton. InProceedings of the IEEE/CVF international conference on computer vision, pages 11260–11269, 2021
2021
-
[32]
J. Chen, M. Yan, J. Zhang, Y . Xu, X. Li, Y . Weng, L. Yi, S. Song, and H. Wang. Tracking and reconstructing hand object interactions from point cloud sequences in the wild. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 304–312, 2023
2023
-
[33]
Cheng, H
W. Cheng, H. Tang, L. Van Gool, and J. H. Ko. Handdiff: 3d hand pose estimation with diffusion on image-point cloud. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2274–2284, 2024
2024
-
[34]
S. Haldar and L. Pinto. Point policy: Unifying observations and actions with key points for robot manipulation.arXiv preprint arXiv:2502.20391, 2025
- [35]
- [36]
-
[37]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models
W. Grathwohl, R. T. Chen, J. Bettencourt, I. Sutskever, and D. Duvenaud. Ffjord: Free-form continuous dynamics for scalable reversible generative models.arXiv preprint arXiv:1810.01367, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based gen- erative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[40]
S. Umeyama. Least-squares estimation of transformation parameters between two point pat- terns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(4):376–380, 1991
1991
-
[41]
K. Zakka. Mink: Python inverse kinematics based on MuJoCo, Feb. 2026. URLhttps: //github.com/kevinzakka/mink
2026
-
[42]
C. Choy, J. Gwak, and S. Savarese. 4d spatio-temporal convnets: Minkowski convolutional neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3075–3084, 2019
2019
-
[43]
C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. InAdvances in neural information processing systems, volume 30, 2017
2017
-
[44]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023. 13
2023
-
[45]
J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y . Du, Y . Qin, W. Xu, E. Lu, J. Yan, Y . Chen, H. Zheng, Y . Liu, S. Liu, B. Yin, W. He, H. Zhu, Y . Wang, J. Wang, M. Dong, Z. Zhang, Y . Kang, H. Zhang, X. Xu, Y . Zhang, Y . Wu, X. Zhou, and Z. Yang. Muon is scalable for llm training. arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [46]
-
[47]
Huang, Z
S. Huang, Z. Wang, P. Li, B. Jia, T. Liu, Y . Zhu, W. Liang, and S.-C. Zhu. Diffusion-based gen- eration, optimization, and planning in 3d scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16750–16761, 2023
2023
-
[48]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[49]
Levinson, C
J. Levinson, C. Esteves, K. Chen, N. Snavely, A. Kanazawa, A. Rostamizadeh, and A. Maka- dia. An analysis of svd for deep rotation estimation.Advances in Neural Information Process- ing Systems, 33:22554–22565, 2020
2020
- [50]
-
[51]
C. Eugenio, H. Nick, A. Max, W. Tim, B. Thomas, and V . Abhinav. Learning robotic manipulation policies from point clouds with conditional flow matching.arXiv preprint arXiv:2409.07343, 2024
-
[52]
T. Ren, S. Liu, A. Zeng, J. Lin, K. Li, H. Cao, J. Chen, X. Huang, Y . Chen, F. Yan, Z. Zeng, H. Zhang, F. Li, J. Yang, H. Li, Q. Jiang, and L. Zhang. Grounded sam: Assembling open- world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [53]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.