Anything2Skill: Compiling External Knowledge into Reusable Skills for Agents
Pith reviewed 2026-06-27 16:49 UTC · model grok-4.3
The pith
Anything2Skill extracts reusable skills from arbitrary external records and installs them in agents so they can retrieve both facts and pre-compiled procedures at runtime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
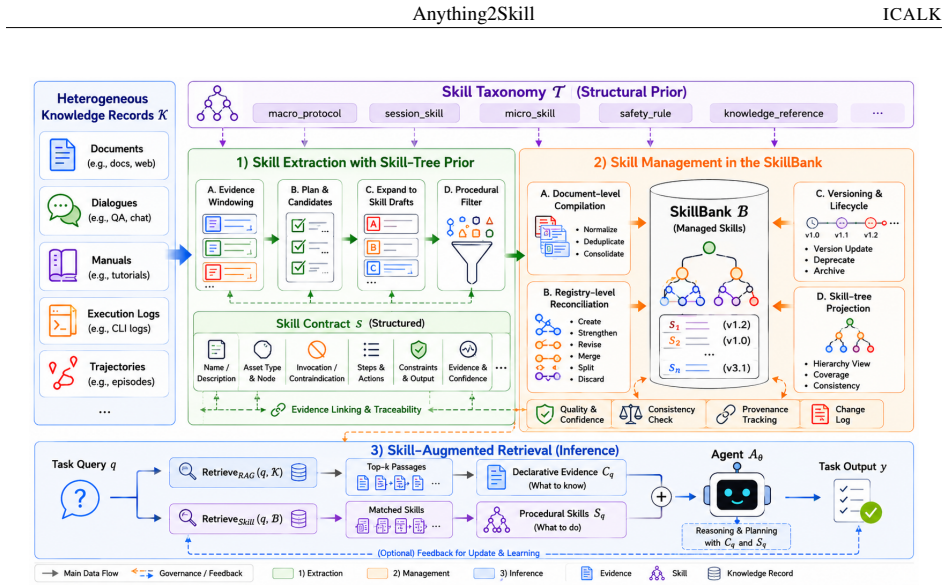
Anything2Skill is a taxonomy-guided pipeline that first decomposes external records into evidence windows, performs plan-and-expand skill extraction under a skill-tree prior, converts the results into structured skill contracts, and maintains them in a SkillBank through registry reconciliation, lifecycle tracking, and visible projections; at runtime agents retrieve both declarative passages and these procedural contracts, allowing RAG to supply evidence while the compiled skills supply executable guidance.
What carries the argument
The structured skill contract, which encodes invocation conditions, contraindications, action moves, workflow steps, constraints, output specifications, supporting evidence, and confidence scores for each extracted procedure.
If this is right
- Agents no longer re-infer the same workflow from raw passages on every similar task.
- SkillBank enables versioned updates and reconciliation so that new records can refine or replace earlier skills.
- Retrieval at inference time can jointly rank passages and skills, giving the agent both declarative and procedural context.
- The same pipeline applies to any corpus of manuals, logs, trajectories, or documentation without domain-specific retraining.
Where Pith is reading between the lines
- If the skill contracts prove reliable, future agents could treat the SkillBank as a form of long-term procedural memory that persists across sessions and users.
- The approach may reduce the need for few-shot prompting or fine-tuning by turning external knowledge directly into executable units.
- Taxonomy-aware compilation could be extended to automatically detect conflicting skills and surface them for human review.
Load-bearing premise
The plan-and-expand extraction step produces accurate, non-hallucinated, and reusable procedures from any external record without introducing systematic errors that would lower downstream agent performance.
What would settle it
An experiment that replaces the extracted skills with randomly generated or manually verified incorrect contracts and measures whether success rates on qsv and GitHub-CLI fall below the RAG-only baseline.
Figures
read the original abstract
Retrieval-augmented generation (RAG) enables agents to access external knowledge at inference time, but it primarily retrieves fragmented declarative evidence, leaving agents to repeatedly infer task procedures from passages, manuals, examples, logs, or trajectories. This raises a fundamental question: can skills extracted from external knowledge bases be installed into an agent, enabling it to rapidly approximate domain expertise? In this paper, we propose Anything2Skill, a taxonomy-guided framework that compiles heterogeneous external knowledge into reusable, retrievable, and executable skills for agents. Given a corpus of knowledge records, \textsc{Anything2Skill} first decomposes each record into evidence windows and performs plan-and-expand skill extraction under a skill-tree prior. The extracted candidates are then converted into structured skill contracts that specify invocation conditions, contraindications, action moves, workflow steps, constraints, output specifications, supporting evidence, and confidence scores. To construct a deployable procedural memory, Anything2Skill manages the extracted skills in a persistent SkillBank through taxonomy-aware compilation, registry-level reconciliation, lifecycle tracking, versioned updates, and visible skill-tree projection. At inference time, agents retrieve both task-specific passages from the original knowledge base and relevant procedural skills from the SkillBank, allowing RAG to provide declarative evidence while compiled skills provide reusable procedural guidance. Experiments on qsv and GitHub-CLI show that Anything2Skill combined with RAG achieves 98.85\% and 94.10\% success rates, respectively, substantially outperforming RAG-only agents. These results suggest that compiling latent procedural knowledge into explicit skills is an effective way to extend retrieval-augmented agents from knowledge access toward capability reuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Anything2Skill, a taxonomy-guided framework that compiles heterogeneous external knowledge into reusable skills for agents. It decomposes records into evidence windows, performs plan-and-expand extraction under a skill-tree prior, converts candidates to structured skill contracts (specifying conditions, steps, constraints, evidence, and confidence), manages them in a persistent SkillBank with taxonomy-aware compilation and lifecycle tracking, and at inference retrieves both RAG passages and skills from the SkillBank. Experiments on qsv and GitHub-CLI report 98.85% and 94.10% success rates for the combined system, substantially outperforming RAG-only agents, suggesting that explicit skill compilation extends RAG agents toward capability reuse.
Significance. If the extraction process reliably produces accurate, non-hallucinated procedures, the work would meaningfully advance retrieval-augmented agents by shifting from repeated inference over declarative fragments to reuse of compiled procedural memory. The SkillBank management and dual retrieval (declarative + procedural) address a recognized gap in current agent systems; the reported success rates, if substantiated with proper controls, would constitute a concrete demonstration of this extension.
major comments (3)
- [Abstract] Abstract: the reported success rates of 98.85% (qsv) and 94.10% (GitHub-CLI) are given only for the combined Anything2Skill+RAG system; no baseline comparisons, RAG-only numbers, ablations of the plan-and-expand extraction or contract conversion steps, error analysis, or failure-mode discussion are supplied, preventing attribution of gains to the skill compilation mechanism.
- [Method] Method (skill extraction and SkillBank): the central claim rests on the plan-and-expand extraction under skill-tree prior plus conversion to structured contracts producing accurate, reusable procedures; however, no quantitative evaluation of extraction fidelity, hallucination frequency, or agreement with source records is provided, leaving open the possibility that systematic mis-specification of workflows or constraints would inject errors into the SkillBank.
- [Experiments] Experiments: without ablations isolating SkillBank contribution, comparisons to alternative skill-acquisition methods, or cross-validation of extracted contracts against ground-truth procedures, the claim that the framework extends RAG agents via reusable skills remains under-supported by the presented evidence.
minor comments (2)
- [Abstract] The abstract introduces 'skill contract' and 'SkillBank' without a concise formal definition or illustrative example at first mention.
- [Method] Notation for confidence scores and taxonomy projection could be clarified with a small example table early in the methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional quantitative support and clearer presentation would strengthen attribution of the reported gains. We respond point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported success rates of 98.85% (qsv) and 94.10% (GitHub-CLI) are given only for the combined Anything2Skill+RAG system; no baseline comparisons, RAG-only numbers, ablations of the plan-and-expand extraction or contract conversion steps, error analysis, or failure-mode discussion are supplied, preventing attribution of gains to the skill compilation mechanism.
Authors: We agree that the abstract should enable immediate attribution. We will revise it to report the RAG-only baselines alongside the combined-system numbers and to reference the ablation studies and error analysis already present in the experiments section. This change will be made in the next version. revision: yes
-
Referee: [Method] Method (skill extraction and SkillBank): the central claim rests on the plan-and-expand extraction under skill-tree prior plus conversion to structured contracts producing accurate, reusable procedures; however, no quantitative evaluation of extraction fidelity, hallucination frequency, or agreement with source records is provided, leaving open the possibility that systematic mis-specification of workflows or constraints would inject errors into the SkillBank.
Authors: The concern is valid. The manuscript currently supports extraction quality through qualitative examples and end-task gains. In revision we will add a quantitative human-evaluation study on a sampled subset of extracted contracts, reporting agreement with source records and estimated hallucination rates. revision: yes
-
Referee: [Experiments] Experiments: without ablations isolating SkillBank contribution, comparisons to alternative skill-acquisition methods, or cross-validation of extracted contracts against ground-truth procedures, the claim that the framework extends RAG agents via reusable skills remains under-supported by the presented evidence.
Authors: We will expand the experiments section with ablations that isolate SkillBank retrieval (including comparisons against alternative skill-acquisition baselines) and will report cross-validation results on the subset of tasks for which ground-truth procedures exist. The revision will also explicitly discuss the scope of available ground truth. revision: partial
- Comprehensive cross-validation of all extracted contracts is constrained by the lack of ground-truth procedural annotations for the full heterogeneous corpus.
Circularity Check
No circularity: framework is procedural and benchmarked externally
full rationale
The paper describes a taxonomy-guided extraction pipeline (plan-and-expand under skill-tree prior, conversion to contracts, SkillBank management) followed by retrieval at inference time, with performance measured on external task benchmarks (qsv, GitHub-CLI). No equations, fitted parameters, self-citations as load-bearing premises, or renamings of known results appear in the provided text. The reported success rates are direct empirical outcomes of the combined system rather than quantities defined by the extraction process itself. This satisfies the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption External knowledge corpora contain extractable procedural skills that can be represented as structured contracts without loss of fidelity.
invented entities (2)
-
SkillBank
no independent evidence
-
skill contract
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas O˘guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,
2020
-
[2]
Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
2023
-
[3]
Omar Khattab, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, and Matei Zaharia. Demonstrate-search-predict: Composing retrieval and language models for knowledge-intensive NLP.arXiv preprint arXiv:2212.14024,
-
[4]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao
URL https://arxiv.org/abs/2603.01145. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InProceedings of the 11th International Conference on Learning Representations, 2023a. Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luk...
-
[5]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Code as Policies: Language Model Programs for Embodied Control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. InarXiv preprint arXiv:2209.07753,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. InarXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
REPLUG: Retrieval-augmented black-box language models
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. REPLUG: Retrieval-augmented black-box language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics,
2024
-
[9]
Kilt: a benchmark for knowledge intensive language tasks
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, et al. Kilt: a benchmark for knowledge intensive language tasks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tec...
2021
-
[10]
WebGPT: Browser-assisted question-answering with human feedback
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Precise zero-shot dense retrieval without relevance labels. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023a. Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Sau...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, Dor Muhlgay, Noam Rozen, Erez Schwartz, Gal Shachaf, Shai Shalev-Shwartz, Amnon Shashua, and Moshe Tenenholtz. MRKL systems: A modular, neuro-symbolic architecture that combines large language models, external knowledg...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Api-bank: A comprehensive benchmark for tool-augmented llms
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. Api-bank: A comprehensive benchmark for tool-augmented llms. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 3102–3116, 2023a. Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang,...
2023
-
[13]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36: 51991–52008, 2023b. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alex Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuh...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Accessed: 2026-06-08. GitHub. Github cli manual.https://cli.github.com/manual/,
2026
-
[16]
Accessed: 2026-06-08. 13
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.