Reasoning Arena: Trace Tournaments When Verifiable Rewards Fall Short
Pith reviewed 2026-06-27 17:16 UTC · model grok-4.3
The pith
Reasoning Arena converts groups of identical-reward reasoning traces into relative training signals via anchor-based trace tournaments and Bradley-Terry ranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
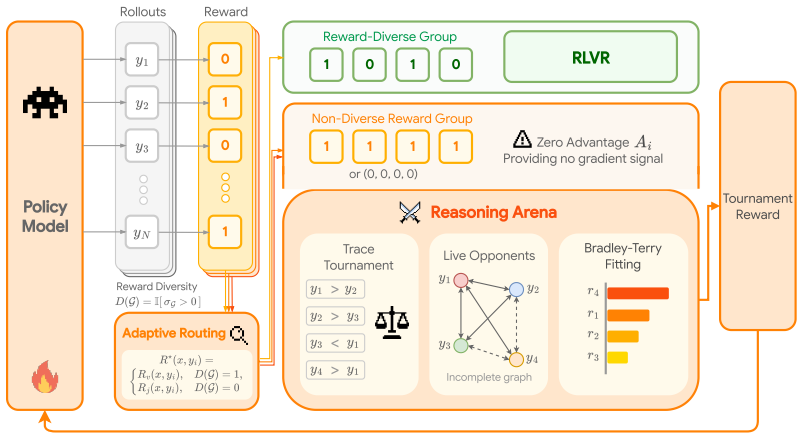
When all traces for a prompt share the same verifiable reward, Reasoning Arena builds an adaptive tournament by pitting each new trace against a dynamically maintained anchor pool, records the head-to-head outcomes, fits a Bradley-Terry model on the resulting sparse graph, and supplies the derived relative rewards to the RL objective, thereby recovering gradient signal from otherwise uninformative groups.
What carries the argument
Trace tournaments that evaluate new reasoning traces against a small dynamic anchor pool, then fit a Bradley-Terry model on the incomplete comparison graph to produce relative reward signals.
If this is right
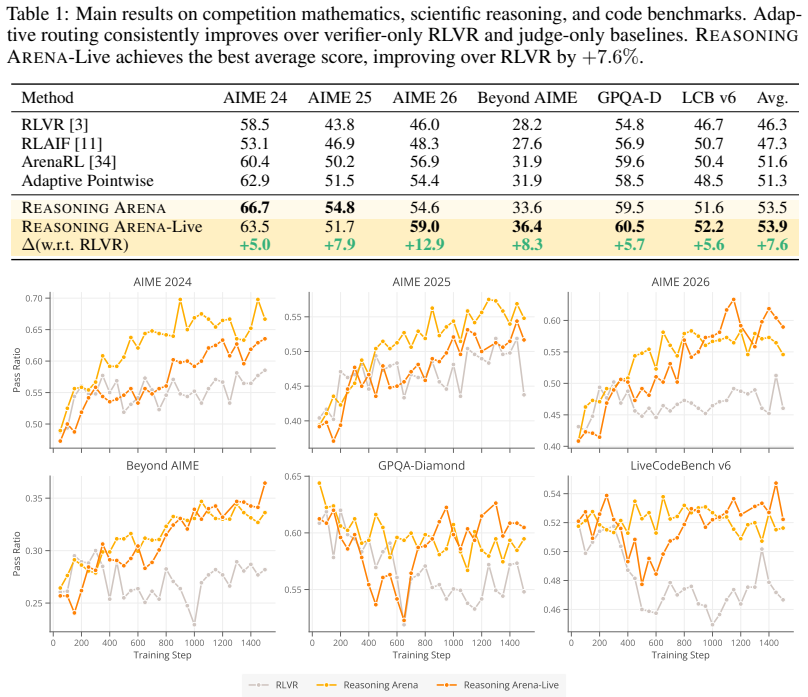
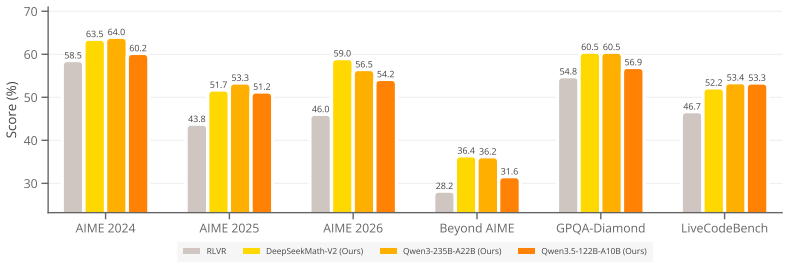
- The method outperforms the standard RLVR baseline by 7.6 percent on average across competition mathematics and coding benchmarks.
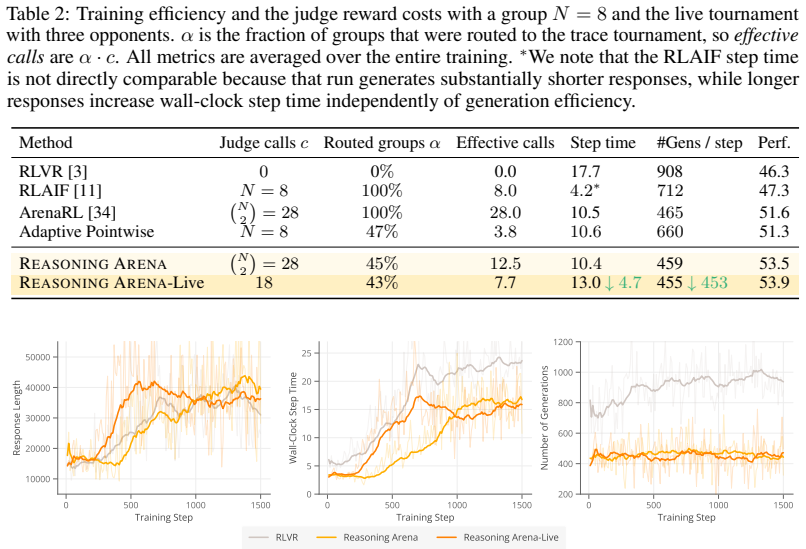
- Training converges 27 to 41 percent faster by turning zero-advantage samples into useful updates.
- Generation compute is reduced by nearly 50 percent because fewer samples are discarded.
- Overall reasoning performance improves because finer-grained preference signals are available throughout training.
Where Pith is reading between the lines
- The same anchor-tournament structure could be applied in any RL setting where outcome signals are coarse but process quality varies across trajectories.
- If judge reliability scales with model size, the approach points toward hybrid supervision that mixes verifiable outcomes with process comparisons without requiring full pairwise evaluation.
- The efficiency gain from incomplete graphs suggests that similar sparse comparison designs could reduce cost in other preference-learning pipelines that currently rely on exhaustive ranking.
Load-bearing premise
Head-to-head comparisons performed by the judge system accurately reflect genuine differences in reasoning quality that are invisible to final-answer verification.
What would settle it
An experiment showing that the relative rewards produced by the Bradley-Terry fit on judge comparisons yield no improvement over the RLVR baseline on held-out math and coding tasks, or that those rewards show no correlation with independent human rankings of trace quality.
Figures
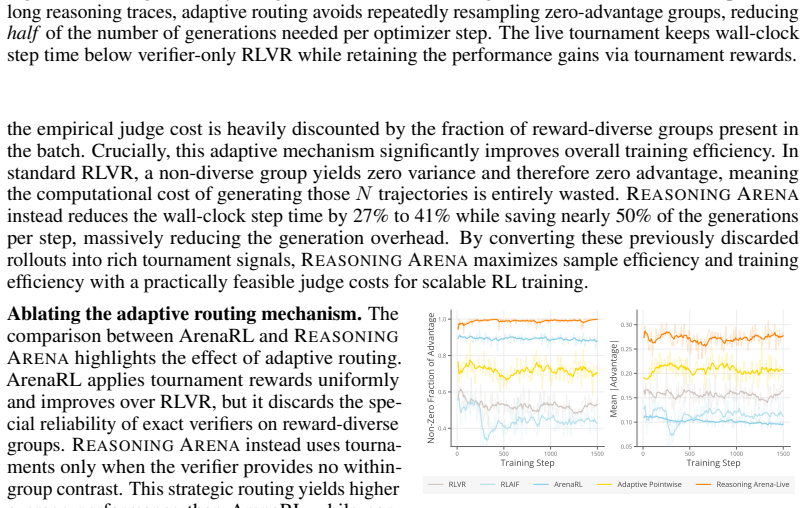
read the original abstract
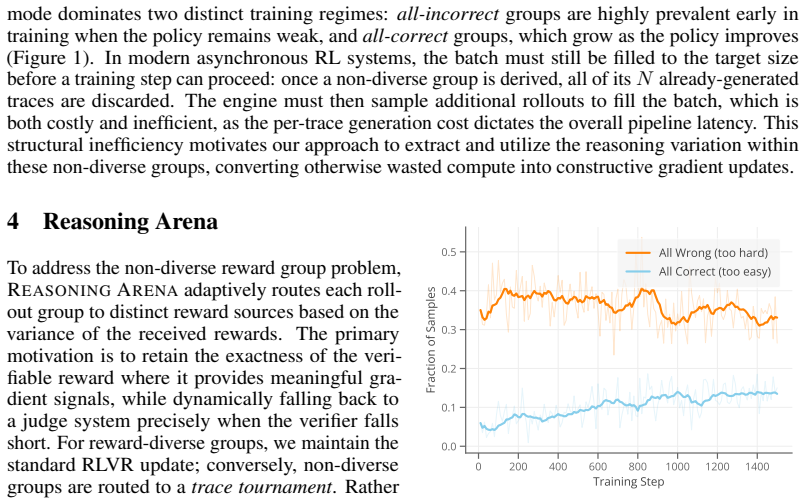
Reinforcement learning with verifiable rewards (RLVR) has become a leading paradigm for improving the reasoning ability of large language models through outcome-based supervision. However, verifiable rewards frequently become uninformative at the group level: when all sampled traces of a given prompt receive identical rewards, group-relative advantage estimation provides no gradient signal, even though the traces may differ substantially in reasoning quality. We propose Reasoning Arena, an adaptive training framework that routes such non-diverse reward groups to a judge system instead of discarding them. Beyond examining the final answer, Reasoning Arena constructs trace tournaments, where reasoning traces are compared head-to-head to expose finer-grained preferences within the group, converting reasoning quality into rich relative reward signals. To make reward estimation efficient, rather than exhaustively comparing every pair, each new trace is evaluated against a small, dynamically updated pool of previously generated traces as anchors to efficiently establish a relative ranking. We then fit a Bradley-Terry model on the incomplete comparison graph, enabling scalable RL integration without quadratic pairwise comparisons. Empirical results demonstrate that Reasoning Arena consistently outperforms the RLVR baseline by 7.6% on average in competition mathematics and coding benchmarks. By converting otherwise wasted zero-advantage samples into useful gradient updates, our method accelerates training by 27% to 41%, saving nearly 50% of generation compute, and substantially improves overall reasoning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Reasoning Arena, an adaptive training framework extending RL with verifiable rewards (RLVR). When all sampled reasoning traces for a prompt receive identical final-answer rewards (yielding zero group-relative advantage), the method routes the group to an LLM judge that conducts head-to-head trace comparisons against a dynamically updated anchor pool, constructs an incomplete comparison graph, and fits a Bradley-Terry model to produce relative reward signals for gradient updates. The paper claims this converts otherwise wasted samples into useful signal, yielding a 7.6% average performance improvement over RLVR baselines on competition mathematics and coding benchmarks, 27-41% faster training, and nearly 50% savings in generation compute.
Significance. If the judge-derived rankings reliably encode reasoning quality differences beyond verifiable outcomes, the framework addresses a practical bottleneck in RLVR by salvaging zero-advantage groups and improves sample efficiency. The anchor-pool approach for scalable BT fitting on incomplete graphs is a pragmatic engineering contribution that avoids full pairwise costs. Credit is due for the explicit focus on converting non-informative samples into gradient updates, which directly targets a known limitation in outcome-supervised reasoning training.
major comments (3)
- [§3] §3 (anchor pool update rule and BT fitting on incomplete graph): The central performance and compute-saving claims rest on the assumption that head-to-head LLM judge preferences embedded in the Bradley-Terry model over the sparse, dynamically updated anchor graph produce relative advantages that are both more informative than zero-advantage signals and free of systematic bias or inconsistency; however, the manuscript provides no validation (e.g., inter-annotator agreement, correlation with human judgments, or stability under anchor-pool size variation) that the induced ordering reflects genuine reasoning quality rather than judge noise or position bias.
- [§4] §4 (empirical results): The headline claims of 7.6% average outperformance, 27-41% training acceleration, and ~50% generation compute savings are presented without reported details on the exact benchmarks used, number of independent runs, statistical significance tests, error bars, or ablation on judge model choice and anchor-pool hyperparameters, which are required to assess whether the gains are robust or could be artifacts of the specific judge implementation.
- [§3] The method description does not include any check for transitivity violations or ranking inconsistency in the incomplete comparison graph; if such inconsistencies are common, the fitted BT advantages become correlated noise, directly undermining both the reported performance delta and the claim that the approach accelerates training by converting wasted samples.
minor comments (2)
- [§3] Notation for the Bradley-Terry parameters and the anchor-pool update rule could be clarified with an explicit equation or pseudocode block to make the incomplete-graph construction reproducible.
- [Abstract, §4] The abstract and results section would benefit from a brief statement of the judge model (e.g., specific LLM and prompting strategy) and any safeguards against position bias in pairwise comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, providing clarifications and committing to revisions where the manuscript can be strengthened without misrepresenting our contributions.
read point-by-point responses
-
Referee: [§3] §3 (anchor pool update rule and BT fitting on incomplete graph): The central performance and compute-saving claims rest on the assumption that head-to-head LLM judge preferences embedded in the Bradley-Terry model over the sparse, dynamically updated anchor graph produce relative advantages that are both more informative than zero-advantage signals and free of systematic bias or inconsistency; however, the manuscript provides no validation (e.g., inter-annotator agreement, correlation with human judgments, or stability under anchor-pool size variation) that the induced ordering reflects genuine reasoning quality rather than judge noise or position bias.
Authors: We agree this is a fair critique and that direct validation would strengthen the paper. In the revision we will add (i) stability experiments varying anchor-pool size (5/10/20) and reporting ranking correlation across runs, and (ii) inter-judge agreement when multiple LLM judges are available. A small-scale qualitative comparison against human preferences on 50 examples will also be included in the appendix. Full-scale human correlation studies remain outside the current scope due to cost, but we will explicitly discuss this limitation and its implications for the claims. revision: partial
-
Referee: [§4] §4 (empirical results): The headline claims of 7.6% average outperformance, 27-41% training acceleration, and ~50% generation compute savings are presented without reported details on the exact benchmarks used, number of independent runs, statistical significance tests, error bars, or ablation on judge model choice and anchor-pool hyperparameters, which are required to assess whether the gains are robust or could be artifacts of the specific judge implementation.
Authors: We acknowledge the omission. The revised manuscript will specify all benchmarks (MATH, GSM8K, AIME, Codeforces, LiveCodeBench), report results over 5 independent random seeds with mean ± std, include paired t-test p-values against the RLVR baseline, and add ablations on judge model (GPT-4o, Claude-3.5, Llama-3-70B) and anchor-pool sizes. These additions will allow readers to evaluate robustness directly. revision: yes
-
Referee: [§3] The method description does not include any check for transitivity violations or ranking inconsistency in the incomplete comparison graph; if such inconsistencies are common, the fitted BT advantages become correlated noise, directly undermining both the reported performance delta and the claim that the approach accelerates training by converting wasted samples.
Authors: We will add a quantitative consistency analysis in §3 and the appendix. For each tournament we will report the fraction of cyclic triads and the Kendall tau distance between the BT ranking and a transitive closure; empirical results on our training runs show inconsistency rates below 8 %. If higher rates appear under certain hyperparameters we will discuss mitigation via additional anchor comparisons. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical intervention that routes zero-advantage groups to a judge-based trace tournament and fits a Bradley-Terry model on an incomplete anchor graph; the reported gains (7.6 % average improvement, 27–41 % faster training) are measured on external competition-math and coding benchmarks rather than derived from any equation or first-principles result that reduces to the method’s own fitted parameters or self-citations by construction. No load-bearing step equates a claimed prediction to its input, and the central claims remain externally falsifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bradley, R. A. and Terry, M. E. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[2]
Beyondaime: Advancing math reasoning evaluation beyond high school olympiads.Hugging Face repository, 2025
ByteDance-Seed. Beyondaime: Advancing math reasoning evaluation beyond high school olympiads.Hugging Face repository, 2025
2025
-
[3]
Chen, A., Li, A., Gong, B., Jiang, B., Fei, B., Yang, B., Shan, B., Yu, C., Wang, C., Zhu, C., et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025
Pith/arXiv arXiv 2025
-
[4]
Tourno: Tournament optimization for reinforcement learning in non-verifiable domains, 2026
Feng, D., Kumar, B., and Tang, L. Tourno: Tournament optimization for reinforcement learning in non-verifiable domains, 2026. URLhttps://www.haizelabs.com/blog/tourno
2026
-
[5]
Gunjal, A., Wang, A., Lau, E., Nath, V ., He, Y ., Liu, B., and Hendryx, S. M. Rubrics as rewards: Reinforcement learning beyond verifiable domains. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=c1bTcrDmt4
2026
-
[6]
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[7]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Jain, N., Han, K., Gu, A., Li, W.-D., Yan, F., Zhang, T., Wang, S., Solar-Lezama, A., Sen, K., and Stoica, I. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations,
-
[8]
URLhttps://openreview.net/forum?id=chfJJYC3iL
-
[9]
Jia, R., Yang, Y ., Wu, Y ., Gai, Y ., Tao, S., Zhou, M., Lin, J., Jiang, X., and Jiang, G. Open rubric system: Scaling reinforcement learning with pairwise adaptive rubric.arXiv preprint arXiv:2602.14069, 2026
arXiv 2026
-
[10]
S., Reid, M., Matsuo, Y ., and Iwasawa, Y
Kojima, T., Gu, S. S., Reid, M., Matsuo, Y ., and Iwasawa, Y . Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
2022
-
[11]
V ., Jeon, M., Vu, K., Lai, V
Le, T.-L. V ., Jeon, M., Vu, K., Lai, V . D., and Yang, E. No prompt left behind: Exploiting zero-variance prompts in LLM reinforcement learning via entropy-guided advantage shaping. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps: //openreview.net/forum?id=kiXFIESZKv
2026
-
[12]
RLAIF vs
Lee, H., Phatale, S., Mansoor, H., Mesnard, T., Ferret, J., Lu, K., Bishop, C., Hall, E., Carbune, V ., Rastogi, A., and Prakash, S. RLAIF vs. RLHF: scaling reinforcement learning from human feedback with AI feedback. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, pp. 26874–26901, 2024. URL https:...
2024
-
[13]
Large language models are miscal- ibrated in-context learners
Li, C., Zhou, H., Glavaš, G., Korhonen, A., and Vuli´c, I. Large language models are miscal- ibrated in-context learners. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Findings of the Association for Computational Linguistics: ACL 2025, pp. 11575–11596, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-8-8...
-
[14]
Liu, A. H., Khandelwal, K., Subramanian, S., Jouault, V ., Rastogi, A., Sadé, A., Jeffares, A., Jiang, A., Cahill, A., Gavaudan, A., et al. Ministral 3.arXiv preprint arXiv:2601.08584, 2026
Pith/arXiv arXiv 2026
-
[15]
Liu, D. C. and Nocedal, J. On the limited memory bfgs method for large scale optimization. Mathematical Programming, 45(1):503–528, 1989. doi: 10.1007/BF01589116. URL https: //doi.org/10.1007/BF01589116
-
[16]
Aligning with human judgement: The role of pairwise preference in large language model evaluators
Liu, Y ., Zhou, H., Guo, Z., Shareghi, E., Vuli´c, I., Korhonen, A., and Collier, N. Aligning with human judgement: The role of pairwise preference in large language model evaluators. InFirst Conference on Language Modeling, 2024. URL https://openreview.net/forum? id=9gdZI7c6yr
2024
-
[17]
Liu, Y ., Yu, Y ., Su, D., Wang, S., Wang, X., Jiang, S., Liu, B., Cohan, A., Tian, Y ., and Chen, Z. Examining reasoning llms-as-judges in non-verifiable llm post-training.arXiv preprint arXiv:2603.12246, 2026
arXiv 2026
-
[18]
X., Wan, X., Nakhost, H., Lee, C.-Y ., Pfister, T., and Arık, S
Long, D. X., Wan, X., Nakhost, H., Lee, C.-Y ., Pfister, T., and Arık, S. Ö. Vista: A test-time self-improving video generation agent.arXiv preprint arXiv:2510.15831, 2025
arXiv 2025
-
[19]
Training language models to follow instructions with human feedback
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[20]
D., Ermon, S., and Finn, C
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[21]
L., Stickland, A
Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y ., Dirani, J., Michael, J., and Bowman, S. R. GPQA: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024. URLhttps://openreview.net/forum?id=Ti67584b98
2024
-
[22]
Rezaei, M., Vacareanu, R., Wang, Z., Wang, C., Liu, B., He, Y ., and Akyürek, A. F. Online rubrics elicitation from pairwise comparisons.arXiv preprint arXiv:2510.07284, 2025
arXiv 2025
-
[23]
Z., Ivison, H., Kishore, V ., Zhuo, J., Zhao, X., Park, M., Finlayson, S
Shao, R., Asai, A., Shen, S. Z., Ivison, H., Kishore, V ., Zhuo, J., Zhao, X., Park, M., Finlayson, S. G., Sontag, D., et al. Dr tulu: Reinforcement learning with evolving rubrics for deep research. arXiv preprint arXiv:2511.19399, 2025
Pith/arXiv arXiv 2025
-
[24]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[25]
Shao, Z., Luo, Y ., Lu, C., Ren, Z., Hu, J., Ye, T., Gou, Z., Ma, S., and Zhang, X. Deepseekmath- v2: Towards self-verifiable mathematical reasoning.arXiv preprint arXiv:2511.22570, 2025
arXiv 2025
-
[26]
X., Wen, Z., Zhang, Z., and Zhou, J
Tang, X., Zhang, Z., Liu, Y ., Zhao, W. X., Wen, Z., Zhang, Z., and Zhou, J. Towards high data efficiency in reinforcement learning with verifiable reward.arXiv preprint arXiv:2509.01321, 2025
arXiv 2025
-
[27]
Checklists are better than reward models for aligning language models
Viswanathan, V ., Sun, Y ., Kong, X., Cao, M., Neubig, G., and Wu, T. Checklists are better than reward models for aligning language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id= RPRqKhjrr6
2026
-
[28]
Wan, X., Zhou, H., Sun, R., Nakhost, H., Jiang, K., Sinha, R., and Arık, S. Ö. Maestro: Self- improving text-to-image generation via agent orchestration.arXiv preprint arXiv:2509.10704, 2025
arXiv 2025
-
[29]
Large language models are not fair evaluators
Wang, P., Li, L., Chen, L., Cai, Z., Zhu, D., Lin, B., Cao, Y ., Kong, L., Liu, Q., Liu, T., and Sui, Z. Large language models are not fair evaluators. In Ku, L.-W., Martins, A., and Srikumar, V . (eds.),Proceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pp. 9440–9450, Bangkok, Thailand, August
-
[30]
Large Language Models are not Fair Evaluators
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.511. URL https://aclanthology.org/2024.acl-long.511/. 11
-
[31]
Wang, Y ., Li, Z., Zang, Y ., Zhou, Y ., Bu, J., Wang, C., Lu, Q., Jin, C., and Wang, J. Pref-grpo: Pairwise preference reward-based grpo for stable text-to-image reinforcement learning.arXiv preprint arXiv:2508.20751, 2025
Pith/arXiv arXiv 2025
-
[32]
Useless, or untapped? unlocking the full value of zero-advantage samples for better policy optimization, 2025
Wu, G., Liao, W., JIANG, C., Lu, X., Ma, L., and Wei, Y . Useless, or untapped? unlocking the full value of zero-advantage samples for better policy optimization, 2025. URL https: //openreview.net/forum?id=FPVB4qSXCZ
2025
-
[33]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[34]
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
Pith/arXiv arXiv 2025
-
[35]
Rlpr: Extrapolating rlvr to general domains without verifiers.arXiv preprint arXiv:2506.18254, 2025
Yu, T., Ji, B., Wang, S., Yao, S., Wang, Z., Cui, G., Yuan, L., Ding, N., Yao, Y ., Liu, Z., et al. Rlpr: Extrapolating rlvr to general domains without verifiers.arXiv preprint arXiv:2506.18254, 2025
arXiv 2025
-
[36]
Arenarl: Scaling rl for open-ended agents via tournament-based relative ranking
Zhang, Q., Chen, B., Zhang, F., Ding, R., Wang, S., Wang, Q., Huang, Y ., Zhang, H., Zhu, R., Wang, P., et al. Arenarl: Scaling rl for open-ended agents via tournament-based relative ranking. arXiv preprint arXiv:2601.06487, 2026
arXiv 2026
-
[37]
Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y ., Men, R., Yang, A., et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
Pith/arXiv arXiv 2025
-
[38]
R., Kailkhura, B., Lai, F., Zhao, J., and Chen, B
Zheng, H., Zhou, Y ., Bartoldson, B. R., Kailkhura, B., Lai, F., Zhao, J., and Chen, B. Act only when it pays: Efficient reinforcement learning for LLM reasoning via selective rollouts. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=x5lITYXmW2
2026
-
[39]
Fairer preferences elicit improved human-aligned large language model judgments
Zhou, H., Wan, X., Liu, Y ., Collier, N., Vuli ´c, I., and Korhonen, A. Fairer preferences elicit improved human-aligned large language model judgments. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 1241–1252, Miami, Florida, USA, November 2024. Associati...
-
[40]
A., and Roy, S
Zhou, H., Wan, X., Proleev, L., Mincu, D., Chen, J., Heller, K. A., and Roy, S. Batch calibration: Rethinking calibration for in-context learning and prompt engineering. In The Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=L3FHMoKZcS. 12 A Limitations and Future Work REASONINGARENAis an adaptive r...
2024
-
[41]
Include the first element of the pair
-
[42]
Include the second element of the pair
-
[43]
Here is my evaluation of the response:
Include both el em en ts of the pair . Since we must include 0 and at least one element from each pair , the total number of f u n c t i o n s is the product of the number of choices for each pair : 3 x 3 = 9 Therefore , the number of f u n c t i o n s that satisfy the given c o n d i t i o n is \ boxed {9}. Judge’s verdict: 14 Both r e s p o n s e s c o ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.