H2HMem: A Multimodal Memory Benchmark for Agents in Human-Human Interactions
Pith reviewed 2026-06-27 16:36 UTC · model grok-4.3
The pith
H2HMem benchmark shows current LLM agents have major gaps in building and using memory across multimodal multi-party conversations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
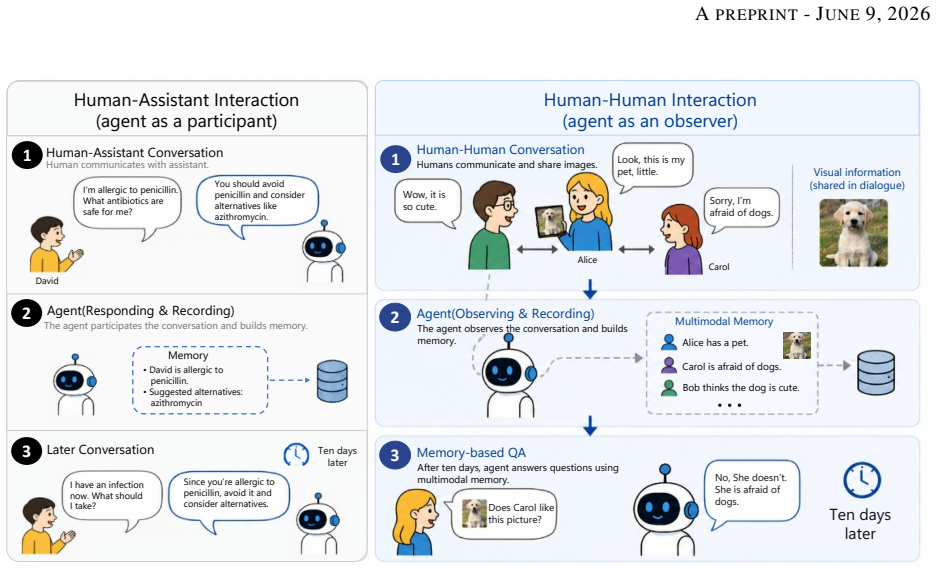
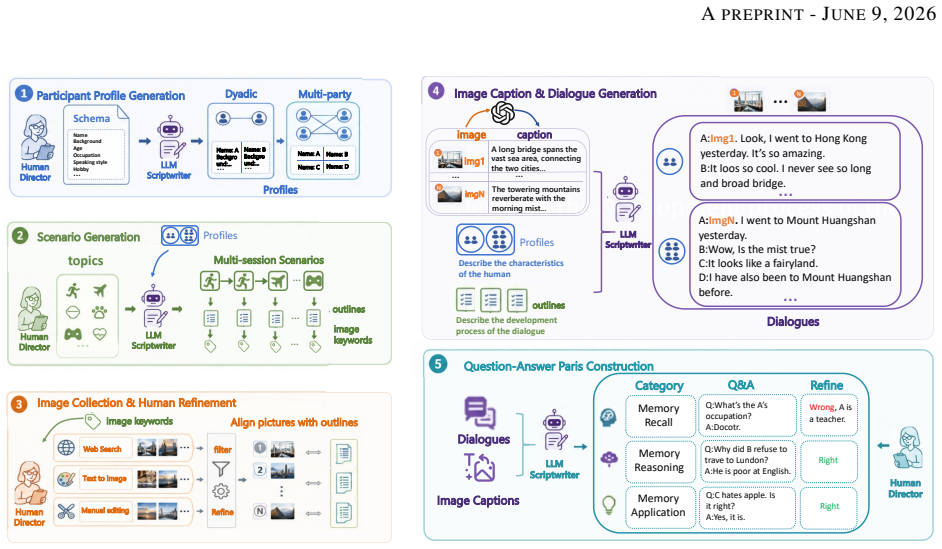
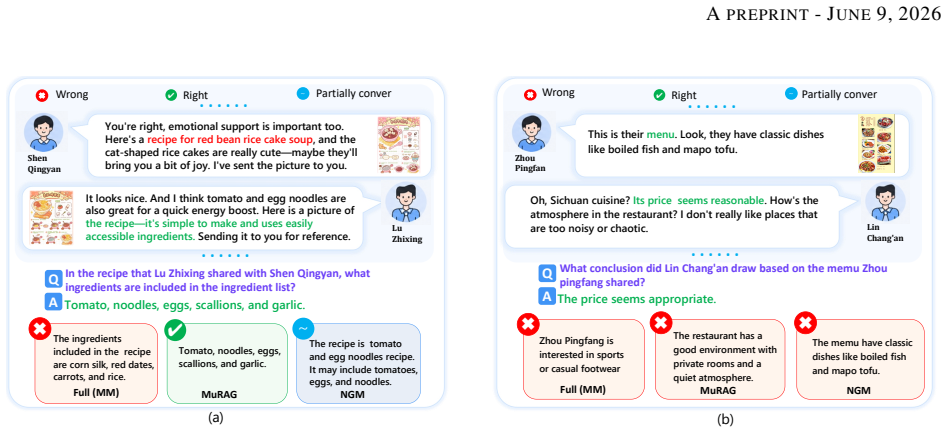
H2HMem consists of dyadic and multi-party conversations supplied with multimodal information streams and measures agents on three axes of memory recall, reasoning, and application; experiments with current agents demonstrate substantial limitations in constructing, retaining, and utilizing memories across modalities, participants, and sessions.
What carries the argument
H2HMem benchmark, which supplies dyadic and multi-party multimodal conversation streams and scores agents on memory recall, reasoning, and application.
If this is right
- Agents must develop improved mechanisms for tracking information across multiple speakers and time periods.
- Memory systems need to integrate and resolve multimodal inputs rather than treating each modality separately.
- Downstream uses such as meeting assistants require explicit handling of anaphora, deixis, and conflicting participant statements.
- Performance gaps persist even in advanced models, indicating that simple scaling will not close the identified shortfalls.
Where Pith is reading between the lines
- The benchmark could serve as a standard testbed for measuring progress when new memory architectures are proposed.
- Similar evaluation setups may be required for other multi-user domains such as collaborative writing or group decision tasks.
- The results imply that memory modules will need dedicated components for cross-participant and cross-session linking rather than relying on general context windows.
Load-bearing premise
The conversation scenarios, multimodal streams, and three evaluation dimensions chosen for the benchmark accurately reflect the main memory challenges present in real human-human interactions.
What would settle it
An agent architecture that achieves high scores on H2HMem recall, reasoning, and application tasks across the full set of dyadic and multi-party sessions would show the reported limitations do not hold.
Figures



read the original abstract
Large language model agents are increasingly deployed in human-human interaction settings, such as meeting assistants and clinical documentation systems, where they must observe conversations and retain information for downstream queries. Unlike traditional human-assistant settings, these environments are inherently multimodal, involve complex discourse phenomena such as anaphora and deixis, and contain asynchronous or conflicting information from multiple participants. However, existing memory benchmarks largely focus on single-user, text-only interactions, failing to capture these challenges. To address this gap, we introduce H2HMem, a Human-to-Human Multimodal Memory Benchmark for evaluating memory capabilities in complex human-human interactions. H2HMem includes both dyadic and multi-party conversations with multimodal information streams, and evaluates agents along three dimensions: memory recall, reasoning, and application. Experiments with advanced agents reveal substantial limitations in constructing, retaining, and utilizing memories across modalities, participants, and sessions, highlighting substantial room for improvement in next-generation LLM agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces H2HMem, a benchmark for LLM agents' memory capabilities in multimodal human-human interactions. It covers dyadic and multi-party conversations with multimodal streams, evaluating agents on three dimensions (memory recall, reasoning, and application). Experiments with advanced agents are reported to reveal substantial limitations in constructing, retaining, and utilizing memories across modalities, participants, and sessions.
Significance. If the benchmark design is shown to be representative, the work would usefully highlight gaps in current agents for real-world settings such as meeting assistants. The creation of a multimodal, multi-participant benchmark with explicit recall/reasoning/application dimensions is a constructive step beyond existing single-user text-only evaluations.
major comments (2)
- [Abstract] Abstract: the central claim that experiments demonstrate 'substantial limitations' is unsupported because the abstract (and by extension the reported evaluation) supplies no information on benchmark construction, dataset size, conversation sources, how multimodal streams are encoded, evaluation metrics, baselines, or statistical significance; without these elements the support for the claim cannot be verified.
- [§3 and §4] §3 (Benchmark Design) and §4 (Experiments): no explicit mapping, expert validation, or ablation is provided to show that the chosen dyadic/multi-party scenarios, specific multimodal phenomena (anaphora, deixis, conflicting information), and the three evaluation dimensions are the critical challenges that existing benchmarks miss; absent this justification, the reported limitations risk being benchmark artifacts rather than general properties of agents in human-human settings.
minor comments (1)
- Clarify the exact data sources and annotation process for the multimodal streams so that the benchmark can be reproduced or extended.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas for improved clarity in the abstract and stronger justification of benchmark design choices. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that experiments demonstrate 'substantial limitations' is unsupported because the abstract (and by extension the reported evaluation) supplies no information on benchmark construction, dataset size, conversation sources, how multimodal streams are encoded, evaluation metrics, baselines, or statistical significance; without these elements the support for the claim cannot be verified.
Authors: We agree the abstract is too condensed to convey these details. In the revised version we will expand it to briefly note dataset scale and sources, multimodal encoding approach, metrics, and reference to the statistical results and baselines reported in Sections 3–4, while remaining within length limits. revision: yes
-
Referee: [§3 and §4] §3 (Benchmark Design) and §4 (Experiments): no explicit mapping, expert validation, or ablation is provided to show that the chosen dyadic/multi-party scenarios, specific multimodal phenomena (anaphora, deixis, conflicting information), and the three evaluation dimensions are the critical challenges that existing benchmarks miss; absent this justification, the reported limitations risk being benchmark artifacts rather than general properties of agents in human-human settings.
Authors: We accept that an explicit mapping and validation section would strengthen the contribution. We will add a short subsection to §3 that (a) maps the selected phenomena and dimensions to documented gaps in prior single-user/text-only memory benchmarks with supporting citations, and (b) summarizes the design rationale and any expert review performed during construction. Space permitting, we will also include a brief ablation discussion or note it as future work. revision: yes
Circularity Check
No circularity: benchmark introduction and experimental reporting are self-contained
full rationale
The paper defines H2HMem explicitly as a new benchmark with dyadic/multi-party scenarios, multimodal streams, and three evaluation dimensions (recall/reasoning/application), then reports agent performance on it. No equations, fitted parameters, or predictions reduce to inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The central claim (agent limitations observed on H2HMem) follows directly from the experimental setup without self-referential reduction, making the derivation independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LlamaPIE: Proactive in-ear conversation assistants.arXiv preprint arXiv:2505.04066, 2025
Tuochao Chen, Nicholas Batchelder, Alisa Liu, Noah Smith, and Shyamnath Gollakota. LlamaPIE: Proactive in-ear conversation assistants.arXiv preprint arXiv:2505.04066, 2025
-
[2]
Farina, Isabel G
Mahshad Razaghi, Abdelrahman Hafez, Juan M. Farina, Isabel G. Scalia, Milagros Pereyra, Fatmaelzahraa E. Abdelfattah, Hesham Sheashaa, Kamal Awad, Steven J. Lester, Chadi Ayoub, and Reza Arsanjani. Transforming clinical documentation with ambient artificial intelligence (AI) scribes: a narrative review of technology, impact, and implementation.Cardiovascu...
2026
-
[3]
Overhearing LLM agents: A survey, taxonomy, and roadmap.arXiv preprint arXiv:2509.16325, 2025
Andrew Zhu and Chris Callison-Burch. Overhearing LLM agents: A survey, taxonomy, and roadmap.arXiv preprint arXiv:2509.16325, 2025
-
[4]
Clark and Edward F
Herbert H. Clark and Edward F. Schaefer. Contributing to discourse.Cognitive Science, 13(2):259–294, 1989
1989
-
[5]
ChatGPT: Optimizing language models for dialogue
OpenAI. ChatGPT: Optimizing language models for dialogue. Technical report, OpenAI, 2023
2023
-
[6]
DeepSeek-V3 technical report
DeepSeek-AI. DeepSeek-V3 technical report. Technical report, DeepSeek-AI, 2024
2024
-
[7]
Designing interfaces that support temporal work across meetings with generative AI
Rishi Vanukuru, Payod Panda, Xinyue Chen, Ava Elizabeth Scott, Lev Tankelevitch, and Sean Rintel. Designing interfaces that support temporal work across meetings with generative AI. InProceedings of the 2025 ACM Designing Interactive Systems Conference, pages 3600–3620, 2025
2025
-
[8]
Memoro: Using large language models to realize a concise interface for real-time memory augmentation
Wazeer Deen Zulfikar, Samantha Chan, and Pattie Maes. Memoro: Using large language models to realize a concise interface for real-time memory augmentation. InProceedings of the CHI Conference on Human Factors in Computing Systems, pages 1–18, 2024
2024
-
[9]
Pengfei Du. Memory for autonomous LLM agents: Mechanisms, evaluation, and emerging frontiers.arXiv preprint arXiv:2603.07670, 2026
-
[10]
Shengyue Guan, Jindong Wang, Jiang Bian, Bin Zhu, Jian-guang Lou, and Haoyi Xiong. Evaluating LLM-based agents for multi-turn conversations: A survey.arXiv preprint arXiv:2503.22458, 2026
-
[11]
Ye Shen, Dun Pei, Yiqiu Guo, Junying Wang, Yijin Guo, Zicheng Zhang, Qi Jia, Jun Zhou, and Guangtao Zhai. EvolMem: A cognitive-driven benchmark for multi-session dialogue memory.arXiv preprint arXiv:2601.03543, 2026
-
[12]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. LongMemEval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2025. 9 APREPRINT- JUNE9, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Fast multi-party open- ended conversation with a social robot.arXiv preprint arXiv:2503.15496, 2025
Giulio Antonio Abbo, Maria Jose Pinto-Bernal, Martijn Catrycke, and Tony Belpaeme. Fast multi-party open- ended conversation with a social robot.arXiv preprint arXiv:2503.15496, 2025
-
[14]
Zihan Liu, Parisa Rabbani, Veda Duddu, Kyle Fan, Madison Lee, and Yun Huang. The social gaze of LLMs: A literature review of multimodal approaches to human behavior understanding.arXiv preprint arXiv:2510.23947, 2025
-
[15]
Beyond turn-based interfaces: Synchronous LLMs as full-duplex dialogue agents
Bandhav Veluri, Benjamin N Peloquin, Bokai Yu, Hongyu Gong, and Shyamnath Gollakota. Beyond turn-based interfaces: Synchronous LLMs as full-duplex dialogue agents. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21390–21402, 2024
2024
-
[16]
Caixin Kang, Yifei Huang, Liangyang Ouyang, Mingfang Zhang, and Yoichi Sato. Can MLLMs read the room? A multimodal benchmark for verifying truthfulness in multi-party social interactions.CoRR, abs/2510.27195, 2025
-
[17]
SIV-Bench: A Video Benchmark for Social Interaction Understanding and Reasoning
Fanqi Kong, Weiqin Zu, Xinyu Chen, Yaodong Yang, Song-Chun Zhu, and Xue Feng. SIV-Bench: A video benchmark for social interaction understanding and reasoning.arXiv preprint arXiv:2506.05425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Smith, and Shyamnath Gollakota
Tuochao Chen, Nicholas Scott Batchelder, Alisa Liu, Noah A. Smith, and Shyamnath Gollakota. LlamaPIE: Proactive in-ear conversation assistants. InFindings of the Association for Computational Linguistics: ACL 2025, pages 13801–13824, 2025
2025
-
[19]
Memoro: Using large language models to realize a concise interface for real-time memory augmentation
Wazeer Deen Zulfikar, Samantha Chan, and Pattie Maes. Memoro: Using large language models to realize a concise interface for real-time memory augmentation. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, Article 450, pages 1–18, 2024
2024
-
[20]
Baumgart, Jake Hayward, and J Ross Mitchell
Samridhi Vaid, Mike Weldon, Jesse Dunn, Sacha Davis, Kevin Lonergan, Henry Li, Jeffrey Franc, Mohamed Abdalla, Daniel C. Baumgart, Jake Hayward, and J Ross Mitchell. Berta: an open-source, modular tool for AI-enabled clinical documentation.arXiv preprint arXiv:2603.23513, 2026
-
[21]
Anjanava Biswas and Wrick Talukdar. Intelligent clinical documentation: Harnessing generative AI for patient- centric clinical note generation.International Journal of Innovative Science and Research Technology (IJISRT), pages 994–1008, 2024
2024
-
[22]
Sumit Asthana, Sagi Hilleli, Pengcheng He, and Aaron Halfaker. Summaries, highlights, and action items: Design, implementation and evaluation of an LLM-powered meeting recap system.Proceedings of the ACM on Human-Computer Interaction, 9(2):1–29, 2025
2025
-
[23]
arXiv preprint arXiv:2504.14225 , year =
Bowen Jiang, Zhuoqun Hao, Young-Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle Ungar, Camillo J. Taylor, and Dan Roth. Know me, respond to me: Benchmarking LLMs for dynamic user profiling and personalized responses at scale.arXiv preprint arXiv:2504.14225, 2025
-
[24]
Evaluating memory in LLM agents via incremental multi-turn interactions
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in LLM agents via incremental multi-turn interactions. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[25]
Weizhi Zhang, Xiaokai Wei, Wei-Chieh Huang, Zheng Hui, Chen Wang, Michelle Gong, and Philip S. Yu. MemoryCD: Benchmarking long-context user memory of LLM agents for lifelong cross-domain personalization. InICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving, 2026
2026
-
[26]
Yuanchen Bei, Tianxin Wei, Xuying Ning, Yanjun Zhao, Zhining Liu, Xiao Lin, Yada Zhu, Hendrik Hamann, Jingrui He, and Hanghang Tong. Mem-Gallery: Benchmarking multimodal long-term conversational memory for MLLM agents.arXiv preprint arXiv:2601.03515, 2026
-
[27]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, S. Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents.arXiv preprint arXiv:2402.17753, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Chuanrui Hu, Tong Li, Xingze Gao, Hongda Chen, Yi Bai, Dannong Xu, Tianwei Lin, Xiaohong Li, Yunyun Han, Jian Pei, and Yafeng Deng. Evaluating long-horizon memory for multi-party collaborative dialogues.arXiv preprint arXiv:2602.01313, 2026
-
[29]
Beyond goldfish memory: Long-term open-domain conversation
Jing Xu, Arthur Szlam, and Jason Weston. Beyond goldfish memory: Long-term open-domain conversation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5180–5197, 2022
2022
-
[30]
Karthick, S.S
J. Karthick, S.S. Subithra, S. Suruthilaya, and A. Eswari. AI-powered multimodal assistant for medical board meetings. In2025 10th International Conference on Smart Structures and Systems (ICSSS), pages 1–6, 2025
2025
-
[31]
Zoom AI companion
Zoom Video Communications. Zoom AI companion. https://www.zoom.com/en/products/ ai-assistant/, 2026
2026
-
[32]
Lawrence Zitnick, and Devi Parikh
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015. 10 APREPRINT- JUNE9, 2026
2015
-
[33]
Rufai Yusuf Zakari, Jim Wilson Owusu, Hailin Wang, Ke Qin, Zaharaddeen Karami Lawal, and Yuezhou Dong. Vqa and visual reasoning: An overview of recent datasets, methods and challenges.arXiv preprint arXiv:2212.13296, 2022
-
[34]
The CANDOR corpus: Insights from a large multimodal dataset of naturalistic conversation.Science advances, 9(13):eadf3197, 2023
Andrew Reece, Gus Cooney, Peter Bull, Christine Chung, Bryn Dawson, Casey Fitzpatrick, Tamara Glazer, Dean Knox, Alex Liebscher, and Sebastian Marin. The CANDOR corpus: Insights from a large multimodal dataset of naturalistic conversation.Science advances, 9(13):eadf3197, 2023
2023
-
[35]
MMChat: Multi-modal chat dataset on social media
Yinhe Zheng, Guanyi Chen, Xin Liu, and Jian Sun. MMChat: Multi-modal chat dataset on social media. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 5778–5786, 2022
2022
-
[36]
Naturalconv: A chinese dialogue dataset towards multi-turn topic-driven conversation
Xiaoyang Wang, Chen Li, Jianqiao Zhao, and Dong Yu. Naturalconv: A chinese dialogue dataset towards multi-turn topic-driven conversation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 14006–14014, 2021
2021
-
[37]
Multi-TPC: A multimodal dataset for three-party conversations with speech, motion, and gaze.Scientific Data, 2026
Meng-Chen Lee and Zhigang Deng. Multi-TPC: A multimodal dataset for three-party conversations with speech, motion, and gaze.Scientific Data, 2026
2026
-
[38]
Towards scalable multi- domain conversational agents: The schema-guided dialogue dataset
Abhinav Rastogi, Xiaoxue Zang, Srinivas Sunkara, Raghav Gupta, and Pranav Khaitan. Towards scalable multi- domain conversational agents: The schema-guided dialogue dataset. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 8689–8696, 2020
2020
-
[39]
Personalized dialogue generation with diversified traits.arXiv preprint arXiv:1901.09672, 2019
Yinhe Zheng, Guanyi Chen, Minlie Huang, Song Liu, and Xuan Zhu. Personalized dialogue generation with diversified traits.arXiv preprint arXiv:1901.09672, 2019
-
[40]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with CLIP latents.arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. arXiv preprint arXiv:2205.11487, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
OpenAI, Aaron Hurst, et al. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
DialogCC: An automated pipeline for creating high-quality multi-modal dialogue dataset
Young-Jun Lee, Byungsoo Ko, Han-Gyu Kim, Jonghwan Hyeon, and Ho-Jin Choi. DialogCC: An automated pipeline for creating high-quality multi-modal dialogue dataset. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1938–1963, 2024
2024
-
[44]
An end-to-end model for photo-sharing multi-modal dialogue generation
Peiming Guo, Sinuo Liu, Yanzhao Zhang, Dingkun Long, Pengjun Xie, Meishan Zhang, and Min Zhang. An end-to-end model for photo-sharing multi-modal dialogue generation. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–7, 2024
2024
-
[45]
Pipeline coreference resolution model for anaphoric identity in dialogues
Damrin Kim, Seongsik Park, Mirae Han, and Harksoo Kim. Pipeline coreference resolution model for anaphoric identity in dialogues. InCODI, 2022
2022
-
[46]
Reformer: The efficient transformer
Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. InInternational Conference on Learning Representations, 2020
2020
-
[47]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[48]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InProceedings of the 36th International Conference on Neural Information Processing Systems, Article 1189, pages 1–16, 2022
2022
-
[49]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation.arXiv preprint arXiv:2306.15595, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[51]
Augmenting language models with long-term memory.Advances in Neural Information Processing Systems, 36:74530–74543, 2023
Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. Augmenting language models with long-term memory.Advances in Neural Information Processing Systems, 36:74530–74543, 2023
2023
-
[52]
Beyond fact retrieval: Episodic memory for rag with generative semantic workspaces
Shreyas Rajesh, Pavan Holur, Chenda Duan, David Chong, and Vwani Roychowdhury. Beyond fact retrieval: Episodic memory for rag with generative semantic workspaces. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32782–32790, 2026. 11 APREPRINT- JUNE9, 2026
2026
-
[53]
Replug: Retrieval-augmented black-box language models
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Richard James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. Replug: Retrieval-augmented black-box language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8371–8384, 2024
2024
-
[54]
A-Mem: Agentic memory for LLM agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-Mem: Agentic memory for LLM agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[55]
Memory OS of AI agent
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory OS of AI agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25961–25970, 2025
2025
-
[56]
MuRAG: Multimodal retrieval-augmented generator for open question answering over images and text
Wenhu Chen, Hexiang Hu, Xi Chen, Pat Verga, and William Cohen. MuRAG: Multimodal retrieval-augmented generator for open question answering over images and text. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5558–5570, 2022
2022
-
[57]
Neural graph memory: A structured approach to long-term memory in multimodal agents
Matthew Fisher. Neural graph memory: A structured approach to long-term memory in multimodal agents. 2025
2025
-
[58]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
OpenAI, Josh Achiam, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Tianyi Zhang and David Traum. Rethinking evaluation in retrieval-augmented personalized dialogue: A cognitive and linguistic perspective.arXiv preprint arXiv:2603.14217, 2026
work page internal anchor Pith review arXiv 2026
-
[61]
Evaluating RAG-based QA systems: A comparative analysis of LLM as a judge, traditional metrics, and human alignment
Renato Miyaji, Renato Moulin, Samuel Monção, and Leonardo Machado. Evaluating RAG-based QA systems: A comparative analysis of LLM as a judge, traditional metrics, and human alignment. InAnais do XVI Simpósio Brasileiro de Tecnologia da Informação e da Linguagem Humana, pages 247–258, 2025
2025
-
[62]
Evaluating large language models (LLMs): Comparison metrics and their impact on generated text quality.TPM: Testing, Psychometrics, Methodology in Applied Psychology, 32, 2025
Cerón-López Marco-Tulio, Peña-Aguilar Juanmanuel, Macías-Trejo Luis-Guadalupe, Pantojaamaro Luis- Fernando, and Bautista-Luis Laura. Evaluating large language models (LLMs): Comparison metrics and their impact on generated text quality.TPM: Testing, Psychometrics, Methodology in Applied Psychology, 32, 2025
2025
-
[63]
Aashiq Muhamed. CCRS: A zero-shot LLM-as-a-judge framework for comprehensive RAG evaluation.arXiv preprint arXiv:2506.20128, 2025
-
[64]
Development and evaluation of Dona, a privacy-preserving donation platform for messaging data from WhatsApp, Facebook, and Instagram.Behavior Research Methods, 57(3):94, 2025
Olya Hakobyan, Paul-Julius Hillmann, Florian Martin, Erwin Böttinger, and Hanna Drimalla. Development and evaluation of Dona, a privacy-preserving donation platform for messaging data from WhatsApp, Facebook, and Instagram.Behavior Research Methods, 57(3):94, 2025
2025
-
[65]
The vCon - conversation data container - overview
Thomas McCarthy-Howe. The vCon - conversation data container - overview. Internet-Draft draft-ietf-vcon- overview-01, Internet Engineering Task Force, 2026
2026
-
[66]
Multimodal co-learning: Challenges, applications with datasets, recent advances and future directions.Information Fusion, 81:203–239, 2022
Anil Rahate, Rahee Walambe, Sheela Ramanna, and Ketan Kotecha. Multimodal co-learning: Challenges, applications with datasets, recent advances and future directions.Information Fusion, 81:203–239, 2022
2022
-
[67]
BenchAgents: Automated benchmark creation with agent interaction
Natasha Butt, Varun Chandrasekaran, Neel Joshi, Besmira Nushi, and Vidhisha Balachandran. BenchAgents: Automated benchmark creation with agent interaction. InICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models, 2025
2025
-
[68]
Multimodal common ground annotation for partial information collaborative problem solving
Yifan Zhu, Changsoo Jung, Kenneth Lai, Videep Venkatesha, Mariah Bradford, Jack Fitzgerald, Huma Jamil, Carine Graff, Sai Kiran Ganesh Kumar, Bruce Draper, Nathaniel Blanchard, James Pustejovsky, and Nikhil Krishnaswamy. Multimodal common ground annotation for partial information collaborative problem solving. In Proceedings of the 21st Joint ACL - ISO Wo...
2025
-
[69]
MemBench: Towards more comprehensive evaluation on the memory of LLM-based agents
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong. MemBench: Towards more comprehensive evaluation on the memory of LLM-based agents. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19336–19352, 2025
2025
-
[70]
Lin Long, Yichen He, Wentao Ye, Yiyuan Pan, Yuan Lin, Hang Li, Junbo Zhao, and Wei Li. Seeing, listening, remembering, and reasoning: A multimodal agent with long-term memory.arXiv preprint arXiv:2508.09736, 2025
-
[71]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, 2019
2019
-
[72]
GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. GME: Improving universal multimodal retrieval by multimodal LLMs.arXiv preprint arXiv:2412.16855, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
J Richard Landis and Gary G Koch. The measurement of observer agreement for categorical data.Biometrics, pages 159–174, 1977. 12 APREPRINT- JUNE9, 2026 A Dataset Details We provide more detailed dialogue statistics and additional details on key components of our data construction pipeline that are not fully elaborated in the main paper. A.1 Conversation D...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.