Do Video Foundation Models Understand Intuitive Physics? A Layerwise Probing Analysis
Pith reviewed 2026-06-27 17:23 UTC · model grok-4.3
The pith
Pretrained video foundation models encode intuitive physics knowledge most accessibly in intermediate-to-late layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Intuitive-physics knowledge emerges reliably in pretrained video representations, but its accessibility depends strongly on pretraining paradigm, representational depth, and readout mechanism, with the clearest signals appearing at intermediate-to-late depth for models trained with predictive objectives.
What carries the argument
Layerwise frozen-feature probing on IntPhys2 and Minimal Video Pairs benchmarks, applied to V-JEPA, VideoMAE, and LTX-Video models.
If this is right
- Predictive joint-embedding pretraining produces stronger physics encoding than masked reconstruction or diffusion-based generation.
- Probes that explicitly model temporal dynamics recover more physics information than frame-independent readouts.
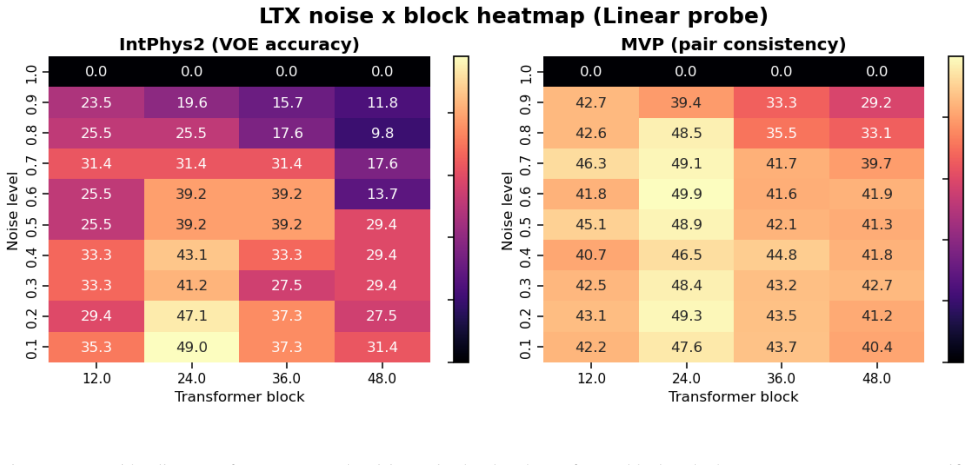
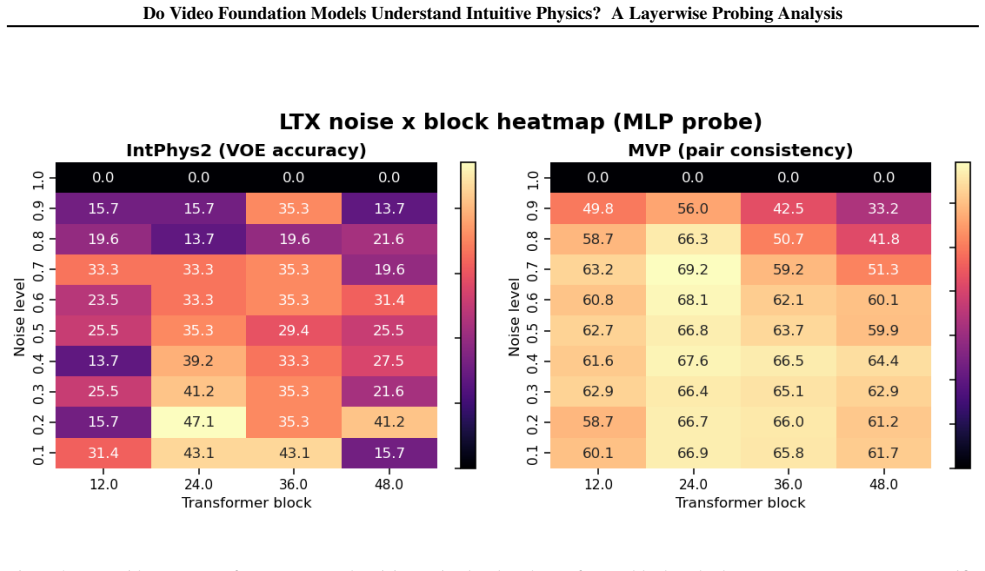
- Physics-relevant features are concentrated at intermediate-to-late depths rather than uniformly across the network.
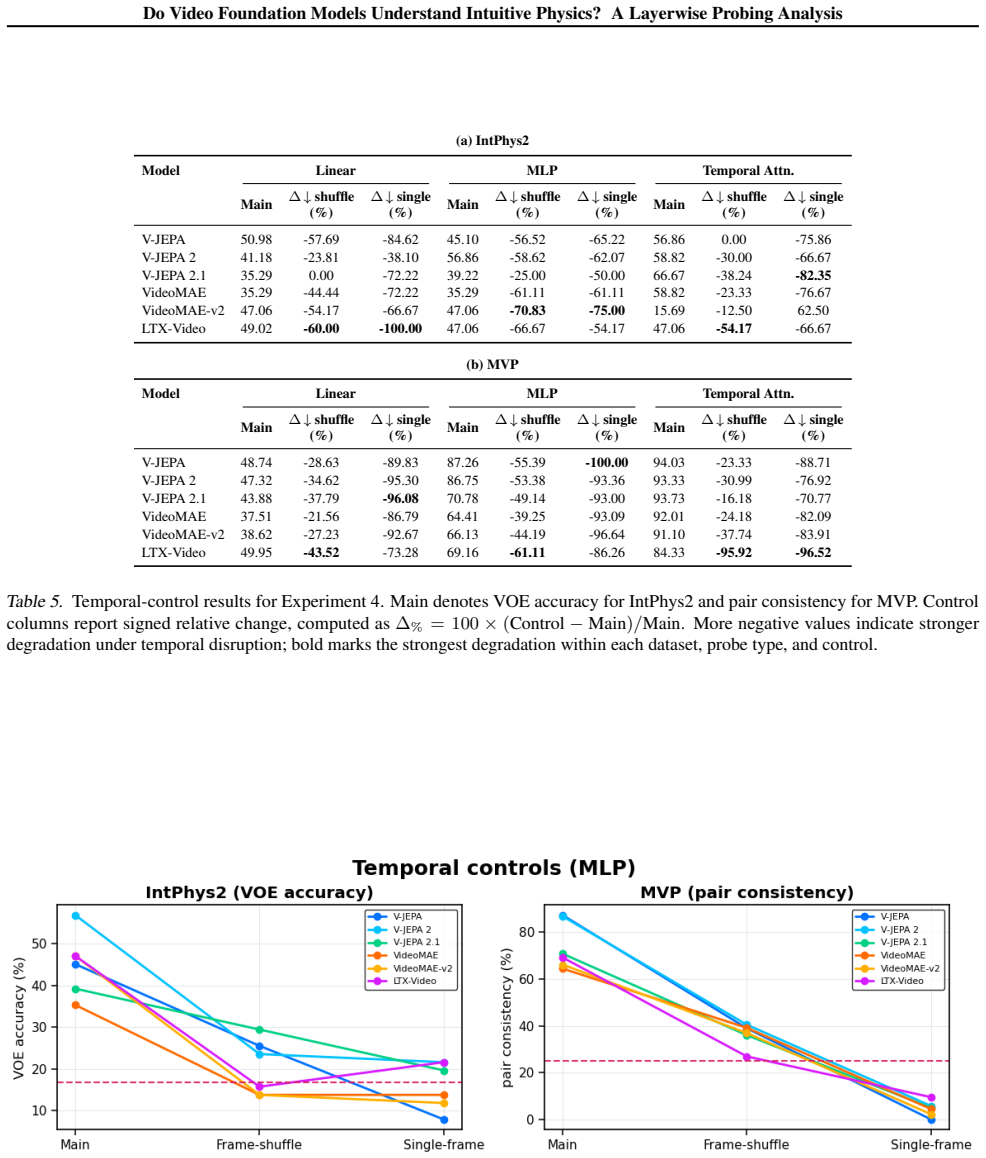
- Disrupting temporal order in the input substantially impairs access to the encoded physics knowledge.
Where Pith is reading between the lines
- Choosing readout layers from the middle-to-late range of predictive video models may improve results on downstream tasks that require physical reasoning.
- Comparing layer profiles across more model families could reveal whether certain architectural choices systematically improve physics capture.
- The same probing approach could be applied to test whether other abstract concepts such as causality or object permanence are also encoded during video pretraining.
Load-bearing premise
The probes and benchmarks isolate knowledge already present in the frozen features rather than allowing the probes to learn the tasks from the small amount of labeled data.
What would settle it
Performance on MVP remaining unchanged when input frames are presented in random order would show that the models are not using temporal physics structure.
Figures
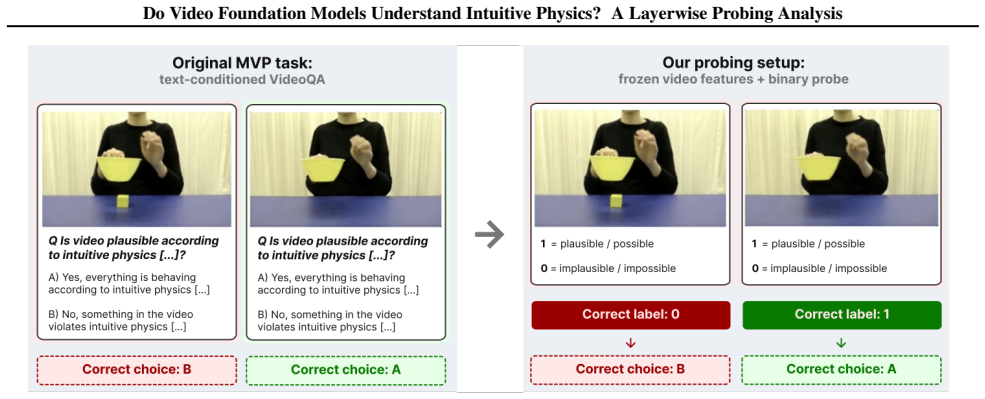


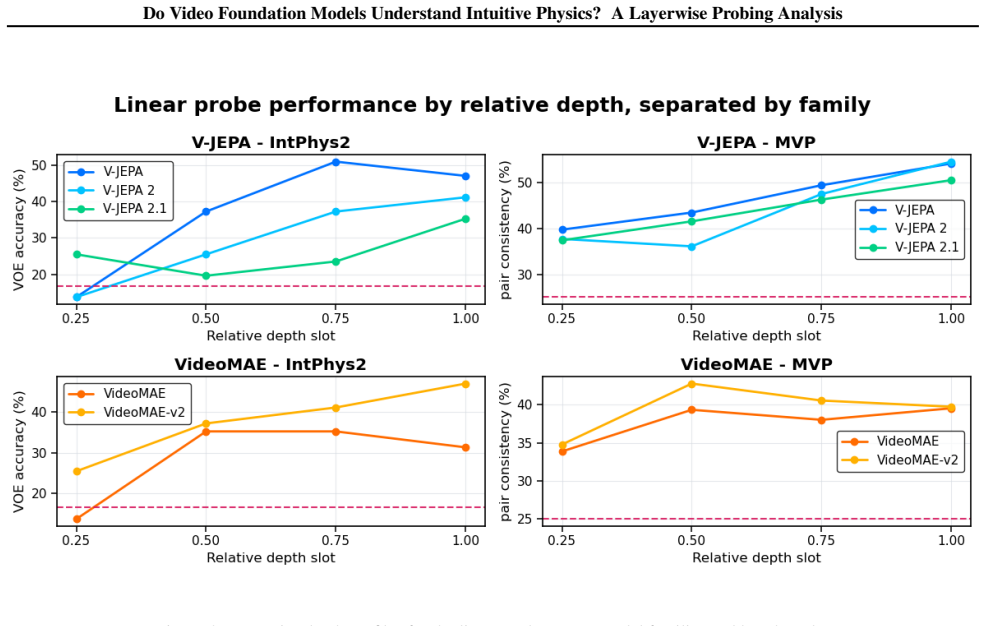
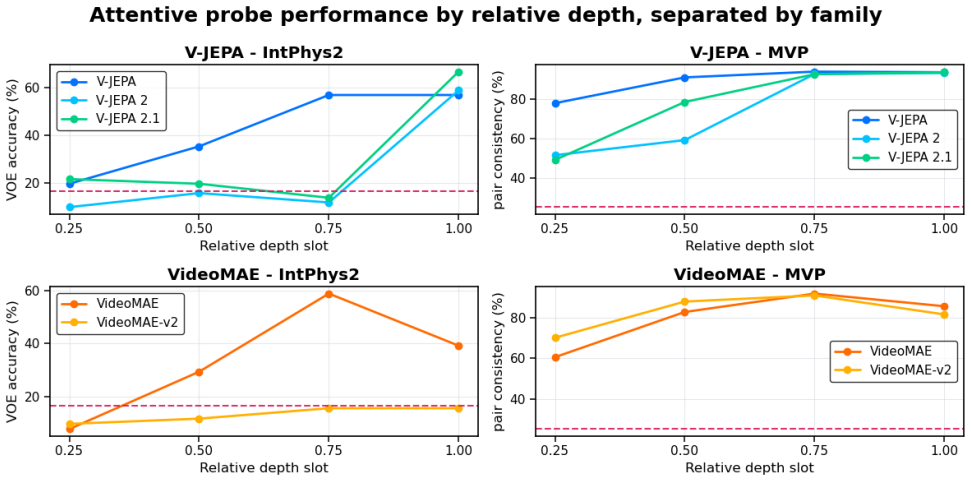
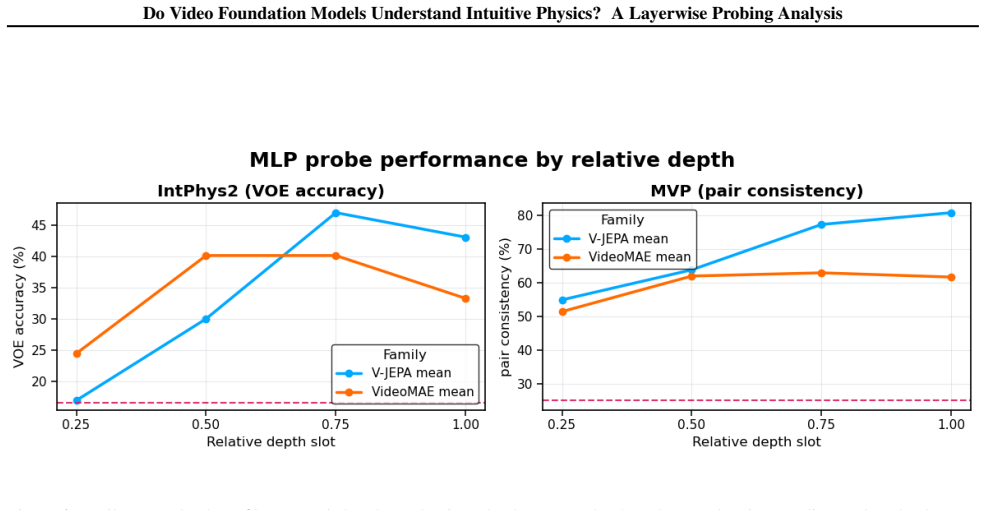
read the original abstract
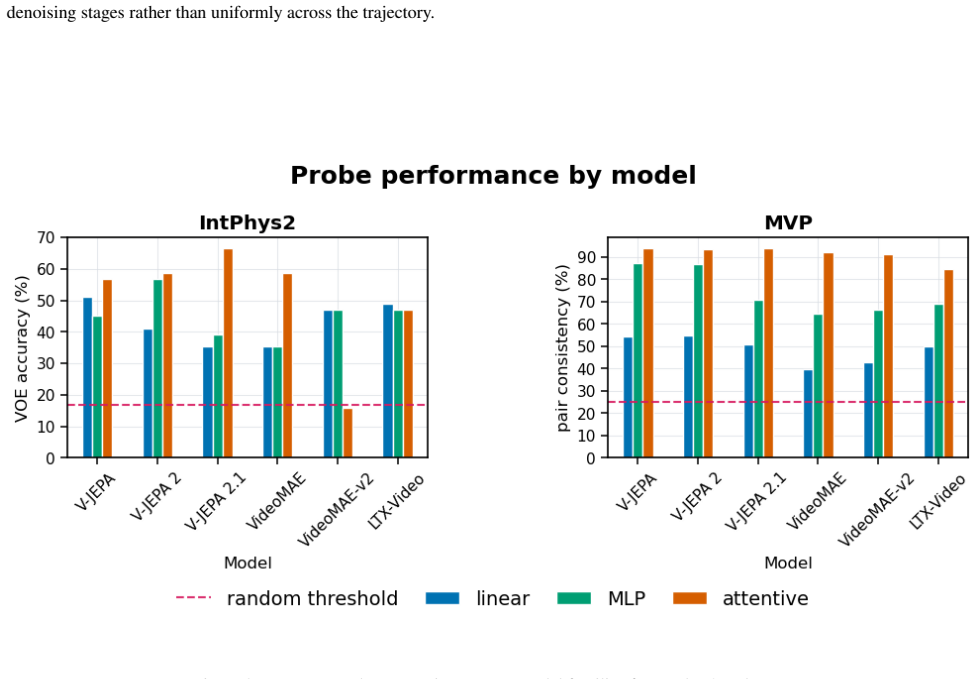
We study whether pretrained video foundation models encode intuitive-physics information in their frozen representations, and how this information varies across model families, layers, and probe types. Using frozen-feature probing on IntPhys2 and Minimal Video Pairs (MVP), we compare predictive joint-embedding models (V-JEPA), masked reconstruction models (VideoMAE), and a diffusion-based video generator (LTX-Video). V-JEPA achieves the strongest overall results across benchmarks, especially with probes that model temporal dynamics, while VideoMAE remains competitive and LTX-Video recovers weaker but non-trivial signal. Layerwise analyses show that physics-relevant information is weakest in early layers and becomes most accessible at intermediate-to-late depth, and temporal controls show that disrupting frame order substantially reduces performance, especially on MVP. Together, these results suggest that intuitive-physics knowledge emerges reliably in pretrained video representations, but its accessibility depends strongly on pretraining paradigm, representational depth, and readout mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a layerwise probing analysis of video foundation models (V-JEPA, VideoMAE, LTX-Video) on intuitive physics benchmarks IntPhys2 and MVP. It claims that intuitive-physics knowledge emerges in pretrained representations, with accessibility depending on pretraining paradigm, depth, and probe type, supported by stronger performance with temporal probes, layerwise patterns, and frame-order controls.
Significance. If the central claim is substantiated, the work contributes to understanding what video foundation models learn during pretraining by showing differential encoding of intuitive physics across architectures and layers. The comparisons between joint-embedding, masked reconstruction, and diffusion models, along with depth analyses, offer insights into representation learning that could inform future model development.
major comments (2)
- [Methods / Probing Setup] The central claim requires that above-chance performance reflects information already present in the frozen video representations rather than the probes acquiring the task during supervised probing. No results are reported for the same probe architectures trained on features from randomly initialized or untrained models of matching architecture (Methods section on probing setup and Experiments on IntPhys2/MVP).
- [Results / Temporal Controls] On MVP, frame-order disruption is shown to reduce performance, but without the random-feature baseline it remains possible that temporal-aware probes learn low-level motion cues from the limited labeled data rather than accessing pre-encoded knowledge (Results section on temporal controls).
minor comments (2)
- [Methods] Add details on probe architectures, data splits, number of trials, and statistical tests (including error bars) to the methods to support reproducibility and verification of the layerwise and cross-model comparisons.
- [Appendix / Probing Details] Clarify the exact readout mechanisms and any hyperparameter choices for the probes in the main text or appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments both highlight the value of a random-initialization baseline to isolate the contribution of pretraining; we address them below and commit to the necessary revisions.
read point-by-point responses
-
Referee: [Methods / Probing Setup] The central claim requires that above-chance performance reflects information already present in the frozen video representations rather than the probes acquiring the task during supervised probing. No results are reported for the same probe architectures trained on features from randomly initialized or untrained models of matching architecture (Methods section on probing setup and Experiments on IntPhys2/MVP).
Authors: We agree that a random-initialization control is required to substantiate that above-chance performance originates in the pretrained representations. In the revised manuscript we will extract features from randomly initialized versions of V-JEPA, VideoMAE, and LTX-Video (identical architectures and layer depths) and train the same probe families on these features for both IntPhys2 and MVP. These results will be reported in the Methods (probing setup) and Experiments sections alongside the pretrained results. revision: yes
-
Referee: [Results / Temporal Controls] On MVP, frame-order disruption is shown to reduce performance, but without the random-feature baseline it remains possible that temporal-aware probes learn low-level motion cues from the limited labeled data rather than accessing pre-encoded knowledge (Results section on temporal controls).
Authors: We acknowledge that the frame-order control alone does not fully rule out probe learning from limited labels. The random-initialization baseline described above will be applied to the temporal probes on MVP as well, directly addressing this concern. The existing frame-order results already show a substantial drop, consistent with reliance on temporal structure present in the pretrained features; the new baseline will provide the additional isolation requested. revision: yes
Circularity Check
No significant circularity; empirical probing study self-contained against external benchmarks
full rationale
The paper reports an empirical frozen-feature probing analysis comparing pretrained video models (V-JEPA, VideoMAE, LTX-Video) on IntPhys2 and MVP benchmarks, with layerwise results and temporal controls. No equations, derivations, or predictions are presented that reduce by construction to fitted inputs or self-citations. Claims rest on experimental outcomes from external benchmarks rather than definitional equivalences, renamed known results, or load-bearing self-citation chains. This is the standard case of a non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption IntPhys2 and Minimal Video Pairs benchmarks accurately isolate intuitive physics understanding independent of low-level visual cues.
Reference graph
Works this paper leans on
-
[1]
URL https://doi.org/ 10.1145/3292500.3330701
1145/3292500.3330701. URL https://doi.org/ 10.1145/3292500.3330701. Alain, G. and Bengio, Y . Understanding intermediate layers using linear classifier probes,
-
[2]
Assran, M., Duval, Q., Misra, I., Bojanowski, P., Vincent, P., Rabbat, M., LeCun, Y ., and Ballas, N
URL https:// arxiv.org/abs/1610.01644. Assran, M., Duval, Q., Misra, I., Bojanowski, P., Vincent, P., Rabbat, M., LeCun, Y ., and Ballas, N. Self-supervised learning from images with a joint-embedding predic- tive architecture,
-
[3]
URL https://arxiv.org/ abs/2301.08243. Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Mojtaba, Komeili, Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., Arnaud, S., Gejji, A., Martin, A., Hogan, F. R., Dugas, D., Bojanowski, P., Khalidov, V ., Labatut, P., Massa, F., Szafraniec, M., Krishnakumar, K., Li, Y ., Ma, X., Chandar, S., Meie...
-
[4]
Bardes, A., Garrido, Q., Ponce, J., Chen, X., Rabbat, M., LeCun, Y ., Assran, M., and Ballas, N
URLhttps://arxiv.org/abs/2506.09985. Bardes, A., Garrido, Q., Ponce, J., Chen, X., Rabbat, M., LeCun, Y ., Assran, M., and Ballas, N. Revisit- ing feature prediction for learning visual representations from video,
-
[5]
URL https://arxiv.org/abs/ 2404.08471. Belinkov, Y . Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 04
-
[6]
Chao and Derek Fai Wong , title =
doi: 10.1162/coli a 00422. Bergstra, J., Bardenet, R., Bengio, Y ., and K ´egl, B. Algorithms for hyper-parameter optimization. In Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., and Weinberger, K. (eds.),Advances in Neural Information Processing Systems, volume
-
[7]
cc/paper_files/paper/2011/file/ 86e8f7ab32cfd12577bc2619bc635690-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2011/file/ 86e8f7ab32cfd12577bc2619bc635690-Paper. pdf. Beyer, L., Zhai, X., and Kolesnikov, A. Better plain vit baselines for imagenet-1k,
2011
-
[8]
Bordes, F., Garrido, Q., Kao, J., Williams, A., Rabbat, M., and Dupoux, E
URL https: //arxiv.org/abs/2205.01580. Bordes, F., Garrido, Q., Kao, J., Williams, A., Rabbat, M., and Dupoux, E. Intphys 2: Benchmarking intu- itive physics understanding in complex synthetic envi- ronments, 06
-
[9]
Garrido, Q., Ballas, N., Assran, M., Bardes, A., Najman, L., Rabbat, M., Dupoux, E., and LeCun, Y
URL https://arxiv.org/abs/ 2505.14321. Garrido, Q., Ballas, N., Assran, M., Bardes, A., Najman, L., Rabbat, M., Dupoux, E., and LeCun, Y . Intuitive physics understanding emerges from self-supervised pretraining on natural videos,
-
[10]
URL https://arxiv.org/ abs/2502.11831. HaCohen, Y ., Chiprut, N., Brazowski, B., Shalem, D., Moshe, D., Richardson, E., Levin, E., Shiran, G., Zabari, N., Gordon, O., Panet, P., Weissbuch, S., Kulikov, V ., Bitterman, Y ., Melumian, Z., and Bibi, O. Ltx-video: Realtime video latent diffusion,
-
[11]
URL https: //arxiv.org/abs/2501.00103. Hewitt, J. and Liang, P. Designing and interpreting probes with control tasks,
-
[12]
URL https://arxiv. org/abs/1909.03368. Joseph, S., Garrido, Q., Balestriero, R., Kowal, M., Fel, T., Bakhtiari, S., Richards, B., and Rabbat, M. Interpreting physics in video world models,
arXiv 1909
-
[13]
Krojer, B., Komeili, M., Ross, C., Garrido, Q., Sinha, K., Ballas, N., and Assran, M
URL https: //arxiv.org/abs/2602.07050. Krojer, B., Komeili, M., Ross, C., Garrido, Q., Sinha, K., Ballas, N., and Assran, M. A shortcut-aware video-qa benchmark for physical understanding via minimal video pairs.arXiv,
-
[14]
URL https://arxiv. org/abs/2208.03550. Liu, N. F., Gardner, M., Belinkov, Y ., Peters, M. E., and Smith, N. A. Linguistic knowledge and transferability of contextual representations,
-
[15]
URL https:// arxiv.org/abs/1903.08855. 9 Do Video Foundation Models Understand Intuitive Physics? A Layerwise Probing Analysis Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization,
Pith/arXiv arXiv 1903
-
[16]
URL https://arxiv.org/abs/ 1711.05101. Mur-Labadia, L., Muckley, M., Bar, A., Assran, M., Sinha, K., Rabbat, M., LeCun, Y ., Ballas, N., and Bardes, A. V-jepa 2.1: Unlocking dense features in video self- supervised learning,
-
[17]
URL https://arxiv. org/abs/2603.14482. Ouyang, H., Wang, Q., Xiao, Y ., Bai, Q., Zhang, J., Zheng, K., Zhou, X., Chen, Q., and Shen, Y . Codef: Content de- formation fields for temporally consistent video process- ing,
-
[18]
Tong, Z., Song, Y ., Wang, J., and Wang, L
URL https://arxiv.org/abs/2506.10178. Tong, Z., Song, Y ., Wang, J., and Wang, L. Videomae: Masked autoencoders are data-efficient learners for self- supervised video pre-training,
-
[19]
Wang, L., Huang, B., Zhao, Z., Tong, Z., He, Y ., Wang, Y ., Wang, Y ., and Qiao, Y
URL https:// arxiv.org/abs/2203.12602. Wang, L., Huang, B., Zhao, Z., Tong, Z., He, Y ., Wang, Y ., Wang, Y ., and Qiao, Y . Videomae v2: Scaling video masked autoencoders with dual masking,
-
[20]
Xiao, Z., Zhou, Y ., Yang, S., and Pan, X
URL https://arxiv.org/abs/2303.16727. Xiao, Z., Zhou, Y ., Yang, S., and Pan, X. Video dif- fusion models are training-free motion interpreter and controller,
-
[21]
Zhu, Z., Feng, X., Chen, D., Yuan, J., Qiao, C., and Hua, G
URL https://arxiv.org/abs/ 2405.14864. Zhu, Z., Feng, X., Chen, D., Yuan, J., Qiao, C., and Hua, G. Exploring pre-trained text-to-video diffusion models for referring video object segmentation,
-
[22]
10 Do Video Foundation Models Understand Intuitive Physics? A Layerwise Probing Analysis A
URL https: //arxiv.org/abs/2403.12042. 10 Do Video Foundation Models Understand Intuitive Physics? A Layerwise Probing Analysis A. Appendix A.1. Code Availability All code necessary to reproduce the experiments is publicly available in the GitHub repository. A.2. Dataset Construction and Additional Benchmark Details IntPhys2We use the Main split of the da...
-
[23]
Each panel shows an illustrative fixed-camera frame sequence for one principle: permanence, immutability, spatio-temporal continuity, and solidity
IntPhys 2 physical conditions. Each panel shows an illustrative fixed-camera frame sequence for one principle: permanence, immutability, spatio-temporal continuity, and solidity. Frames are adapted from Fig. 6 of Bordes et al. (2025); figure layout and annotations are ours. A.3. Extended Model Descriptions V-JEPA FamilyThe V-JEPA (Video Joint-Embedding Pr...
2025
-
[24]
Unlike reconstruction-based approaches that operate on pixel-level data, the model learns to predict a target representation from context in a shared embedding space
models leverage the principle of latent space prediction. Unlike reconstruction-based approaches that operate on pixel-level data, the model learns to predict a target representation from context in a shared embedding space. This encourages abstract, semantically meaningful, and compact representations rather than appearance matching. Compared with the or...
2024
-
[25]
In this setting, the model learns to denoise a video sample over multiple steps, starting from a noisy latent and progressively refining it into a coherent video
LTX Video DiffuserLTX Video belongs to the diffusion-based video generation family (HaCohen et al., 2024). In this setting, the model learns to denoise a video sample over multiple steps, starting from a noisy latent and progressively refining it into a coherent video. The architecture is designed for generation rather than representation learning, but th...
2024
-
[26]
Patch size refers to spatial tokens; tubelet size is the temporal stride in frames
Detailed backbone configurations used in all experiments. Patch size refers to spatial tokens; tubelet size is the temporal stride in frames. 2https://huggingface.co/Lightricks/LTX-Video-0.9.8-13B-distilled 12 Do Video Foundation Models Understand Intuitive Physics? A Layerwise Probing Analysis A.4. Model and Probe Configuration Table 2 reports the model ...
2000
-
[27]
Each layer is assigned a 20-trial study with a TPE sampler (Bergstra et al.,
For the linear and MLP probes, we perform hyperparameter selection independently for each layer with Optuna (Akiba et al., 2019). Each layer is assigned a 20-trial study with a TPE sampler (Bergstra et al.,
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.