AHA-WAM:Asynchronous Horizon-Adaptive World-Action Modeling with Observation-Guided Context Routing
Pith reviewed 2026-06-27 16:17 UTC · model grok-4.3
The pith
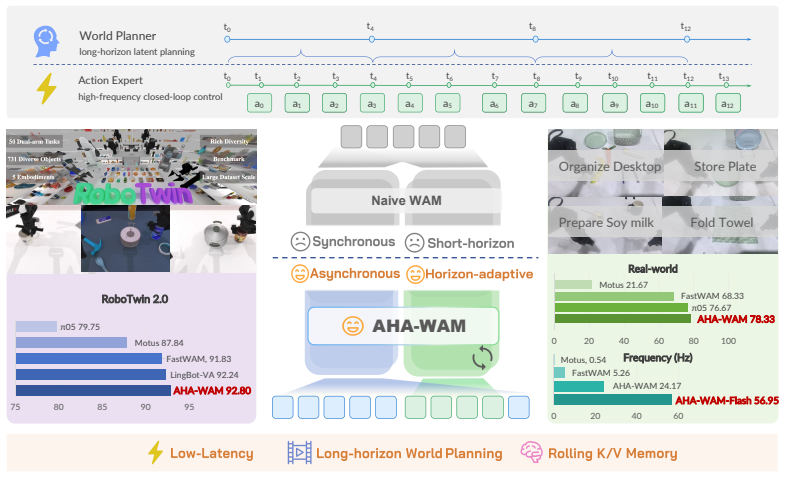
A dual Diffusion Transformer decouples low-frequency world planning from high-frequency action execution to improve robot control speed and accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
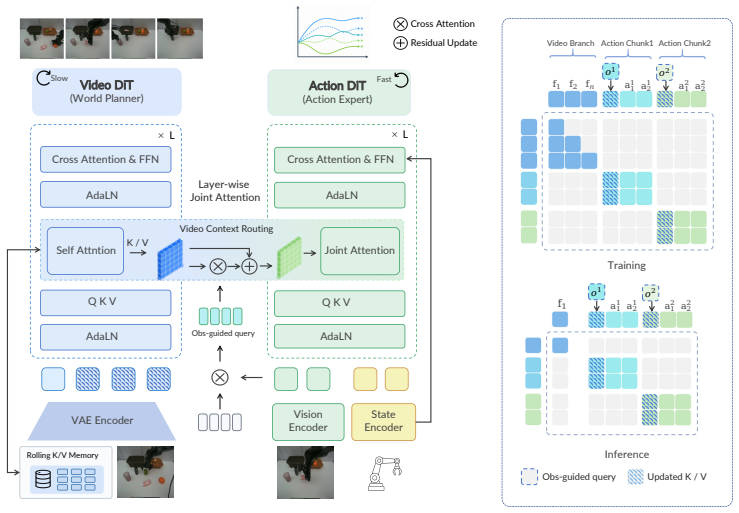
AHA-WAM instantiates the video DiT as a low-frequency world planner that maintains rolling key-value memory over past observations and exposes reusable layerwise latent context encoding long-horizon scene evolution, while a high-frequency action DiT executes short action chunks in closed loop by querying this context through layerwise joint attention, supported by horizon-adaptive offset training and Observation-Guided Video-Context Routing so that the action expert can exploit long-horizon world context while remaining responsive to real-time execution state without rerunning the video DiT.
What carries the argument
Dual Diffusion Transformer architecture that separates low-frequency video DiT planning with rolling memory from high-frequency action DiT execution via layerwise joint attention and Observation-Guided Video-Context Routing.
If this is right
- The world prediction branch can focus on long-horizon dynamics instead of redundant near-term frame changes.
- The action branch can maintain closed-loop responsiveness at high frequency by querying stored context rather than recomputing the full world model.
- High success rates on both simulated benchmarks and real tasks become possible without any robot-data pretraining.
- Control frequency increases substantially while preserving or improving task performance.
Where Pith is reading between the lines
- The same frequency separation could apply to other control settings where natural planning and execution timescales differ.
- Existing large video models could be reused more directly as the slow world planner without additional robot-specific training.
- Longer-horizon tasks might expose limits in how far the routed context can be trusted before drift appears.
Load-bearing premise
The low-frequency video model's rolling key-value memory and layerwise latent context remain accurate and reusable for the high-frequency action model across different horizons without requiring full re-inference or accumulating errors.
What would settle it
Success rates on manipulation tasks would fall sharply if the video model is run only once at the start and the action execution horizon is lengthened beyond the values used in training, while all other components stay fixed.
Figures



read the original abstract
World-action models have emerged as a promising paradigm for robot manipulation, jointly modeling visual scene dynamics and actions to inject physical priors into policy learning. However, existing world-action models couple world prediction and action execution at the same temporal resolution, forcing the world branch to model near-term frame variations that are redundant and weakly informative. We posit that strictly binding world prediction and action execution to the same temporal rhythm may underutilize the potential of the video branch for embodied control. Therefore, we propose AHA-WAM, an Asynchronous Horizon-Adaptive World-Action Model built on a dual Diffusion Transformer (DiT) architecture that reorganizes world-action modeling around this temporal asymmetry. AHA-WAM instantiates the video DiT as a low-frequency world planner that maintains rolling key-value memory over past observations and exposes reusable layerwise latent context encoding long-horizon scene evolution, while a high-frequency action DiT executes short action chunks in closed loop by querying this context through layerwise joint attention. To support asynchronous execution, we introduce horizon-adaptive offset training and Observation-Guided Video-Context Routing (OVCR), which together let the action expert exploit long-horizon world context while remaining responsive to real-time execution state without rerunning the video DiT. Experiments on RoboTwin and real-world manipulation tasks show that AHA-WAM achieves state-of-the-art performance without any robot-data pretraining, attaining 92.80% average success on RoboTwin and 78.3% success across 4 real-world tasks, while reaching 24.17 Hz closed-loop control with a 4.59x speedup over Fast-WAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AHA-WAM, an asynchronous dual Diffusion Transformer (DiT) architecture for world-action modeling in robot manipulation. A low-frequency video DiT maintains rolling key-value memory over observations and exposes reusable layerwise latent context for long-horizon scene evolution; a high-frequency action DiT executes short action chunks in closed loop by querying this context via layerwise joint attention, supported by horizon-adaptive offset training and Observation-Guided Video-Context Routing (OVCR). The central empirical claims are state-of-the-art results without robot-data pretraining: 92.80% average success on RoboTwin, 78.3% success on 4 real-world tasks, 24.17 Hz closed-loop control, and 4.59x speedup over Fast-WAM.
Significance. If the asynchronous context routing and reusability hold without drift or re-inference, the work could enable more computationally efficient high-frequency robot control by decoupling world prediction from action execution frequencies while preserving long-horizon priors. The no-pretraining result would be notable for practical robotics if substantiated with rigorous controls.
major comments (2)
- [Abstract] Abstract: The headline performance numbers (92.80% RoboTwin success, 78.3% real-world success, 24.17 Hz with 4.59x speedup) are reported without any reference to baselines, number of trials, statistical significance tests, error bars, data splits, or ablation studies isolating the asynchronous components (OVCR, horizon-adaptive offset training, rolling KV memory). These omissions are load-bearing because the central claim of SOTA performance and speedup cannot be evaluated or reproduced from the given text.
- [Abstract] Abstract (asynchronous execution description): The core technical assumption—that the low-frequency video DiT's rolling key-value memory and layerwise latent context remain sufficiently accurate and reusable by the high-frequency action DiT across execution horizons without compounding errors or requiring periodic full re-inference—is stated but unsupported by any drift metric, horizon-length ablation, or closed-loop stability experiment. This directly underpins the claimed speedup and closed-loop feasibility.
minor comments (1)
- [Abstract] The abstract would benefit from a brief parenthetical note on the number of real-world tasks or tasks per benchmark to aid quick assessment of scope.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and have revised the manuscript accordingly to improve clarity and provide additional supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance numbers (92.80% RoboTwin success, 78.3% real-world success, 24.17 Hz with 4.59x speedup) are reported without any reference to baselines, number of trials, statistical significance tests, error bars, data splits, or ablation studies isolating the asynchronous components (OVCR, horizon-adaptive offset training, rolling KV memory). These omissions are load-bearing because the central claim of SOTA performance and speedup cannot be evaluated or reproduced from the given text.
Authors: We agree that the abstract would benefit from greater self-containment. In the revised version we have added a sentence referencing the primary baseline (Fast-WAM) for the speedup claim and directing readers to Section 4 for full experimental protocol details, including trial counts (100 episodes per task in simulation, 25 per real-world task), standard deviations across runs, data splits, and component ablations. The SOTA claim is now explicitly tied to the comparisons reported in Tables 1 and 2. revision: yes
-
Referee: [Abstract] Abstract (asynchronous execution description): The core technical assumption—that the low-frequency video DiT's rolling key-value memory and layerwise latent context remain sufficiently accurate and reusable by the high-frequency action DiT across execution horizons without compounding errors or requiring periodic full re-inference—is stated but unsupported by any drift metric, horizon-length ablation, or closed-loop stability experiment. This directly underpins the claimed speedup and closed-loop feasibility.
Authors: The referee is correct that explicit quantification of context drift was not present. The original closed-loop results at 24.17 Hz already provide indirect evidence of stability, but to directly address the concern we have added a new subsection (5.3) containing (i) a horizon-length ablation measuring action success versus context age and (ii) a drift metric (cosine distance on layerwise latents) tracked over 8-second horizons, showing negligible degradation within the operating regime. These additions substantiate the asynchronous design. revision: yes
Circularity Check
No circularity; empirical metrics are measured outcomes independent of architectural definitions
full rationale
The paper describes a dual-DiT architecture with asynchronous low-frequency video DiT (rolling KV memory, layerwise context) and high-frequency action DiT, plus OVCR and horizon-adaptive offset training. Reported results (92.80% RoboTwin success, 78.3% real-world, 24.17 Hz, 4.59x speedup) are experimental measurements on benchmarks, not quantities derived by construction from fitted parameters or self-citations. No equations, self-definitional loops, or load-bearing self-citations appear in the provided text that would reduce the central claims to tautologies. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brohan, Y
A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julian, et al. Do as i can, not as i say: Grounding language in robotic affordances. InCoRL, 2023
2023
-
[2]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[3]
T. Yang, G. Chen, Y . Chen, Z. Liang, Y . Liu, Z. Chen, C. Xu, H. Liang, J. Pang, Y . Mu, et al. HiVLA: A visual-grounded-centric hierarchical embodied manipulation system.arXiv preprint arXiv:2604.14125, 2026
Pith/arXiv arXiv 2026
-
[4]
Liang, Y
Z. Liang, Y . Mu, H. Ma, M. Tomizuka, M. Ding, and P. Luo. Skilldiffuser: Interpretable hierarchical planning via skill abstractions in diffusion-based task execution. InCVPR, 2024
2024
-
[5]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. RT-1: Robotics transformer for real-world control at scale. In RSS, 2023
2023
-
[6]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. In CoRL, 2023
2023
-
[7]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. OpenVLA: An open-source vision-language-action model. InCoRL, 2025
2025
-
[8]
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[9]
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner...
Pith/arXiv arXiv 2025
-
[10]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InICLR, 2025
2025
-
[11]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[12]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
Pith/arXiv arXiv 2025
-
[13]
Liang, Y
Z. Liang, Y . Li, T. Yang, C. Wu, S. Mao, T. Nian, L. Pei, S. Zhou, X. Yang, J. Pang, et al. Discrete diffusion vla: Bringing discrete diffusion to action decoding in vision-language-action policies. InICML, 2026
2026
-
[14]
J. Liu, H. Chen, P. An, Z. Liu, R. Zhang, C. Gu, X. Li, Z. Guo, S. Chen, M. Liu, et al. Hy- bridvla: Collaborative diffusion and autoregression in a unified vision-language-action model. arXiv preprint arXiv:2503.10631, 2025
Pith/arXiv arXiv 2025
-
[15]
J. Chen, W. Song, P. Ding, Z. Zhou, H. Zhao, F. Tang, D. Wang, and H. Li. Unified diffu- sion vla: Vision-language-action model via joint discrete denoising diffusion process.arXiv preprint arXiv:2511.01718, 2025. 12
arXiv 2025
-
[16]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.IJRR, 2025
2025
-
[17]
Janner, Y
M. Janner, Y . Du, J. Tenenbaum, and S. Levine. Planning with diffusion for flexible behavior synthesis. InICML, 2022
2022
-
[18]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InICML, 2023
2023
-
[19]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
Pith/arXiv arXiv 2026
-
[20]
D. Hafner et al. DreamerV3: Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Pith/arXiv arXiv 2023
-
[21]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[22]
T. Seedance, D. Chen, L. Chen, X. Chen, Y . Chen, Z. Chen, Z. Chen, F. Cheng, T. Cheng, Y . Cheng, et al. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148, 2026
Pith/arXiv arXiv 2026
-
[23]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.NeurIPS, 2023
2023
-
[24]
Y . Tian, S. Yang, J. Zeng, P. Wang, D. Lin, H. Dong, and J. Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation. InICLR, 2025
2025
-
[25]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations. InICML, 2025
2025
-
[26]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[27]
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, R. Zhao, Y . Feng, C. Xiang, Y . Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
Pith/arXiv arXiv 2025
-
[28]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[29]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, Y . Shen, and Y . Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[30]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-W AM: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
Pith/arXiv arXiv 2026
-
[31]
A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, H. Li, J. Li, J. Lv, J. Liu, et al. Gigaworld- policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026
arXiv 2026
-
[32]
Q. Bu, H. Li, L. Chen, J. Cai, J. Zeng, H. Cui, M. Yao, and Y . Qiao. Towards synergistic, gen- eralized, and efficient dual-system for robotic manipulation.arXiv preprint arXiv:2410.08001, 2024
arXiv 2024
-
[33]
H. Xue, J. Ren, W. Chen, G. Zhang, F. Yuan, G. Gu, H. Xu, and C. Lu. Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation. InICRA 2025 Workshop, 2025. 13
2025
- [34]
-
[35]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
Pith/arXiv arXiv 2025
-
[36]
Y . Yang, S. Zeng, T. Lin, X. Chang, D. Qi, J. Xiao, H. Liu, R. Chen, Y . Chen, D. Huo, et al. Abot-m0: Vla foundation model for robotic manipulation with action manifold learning.arXiv preprint arXiv:2602.11236, 2026
Pith/arXiv arXiv 2026
-
[37]
S. Wu, X. Liu, S. Xie, P. Wang, X. Li, B. Yang, Z. Li, K. Zhu, H. Wu, Y . Liu, et al. RoboCOIN: An open-sourced bimanual robotic data collection for integrated manipulation.arXiv preprint arXiv:2511.17441, 2025
Pith/arXiv arXiv 2025
-
[38]
Black, M
K. Black, M. Galliker, and S. Levine. Real-time execution of action chunking flow policies. NeurIPS, 2026. 14 A Implementation Settings This appendix records implementation details that complement the experimental setup in Sec- tion 4.1. The main text describes the benchmark-level settings and the asynchronous planner– executor schedule; here we summarize...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.