Blurry Window Attention
Pith reviewed 2026-06-28 17:41 UTC · model grok-4.3
The pith
Blurry Window Attention reconstructs KV history from a frequency window via Dirichlet kernel interpolation to reach linear complexity with high state efficiency on recall tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
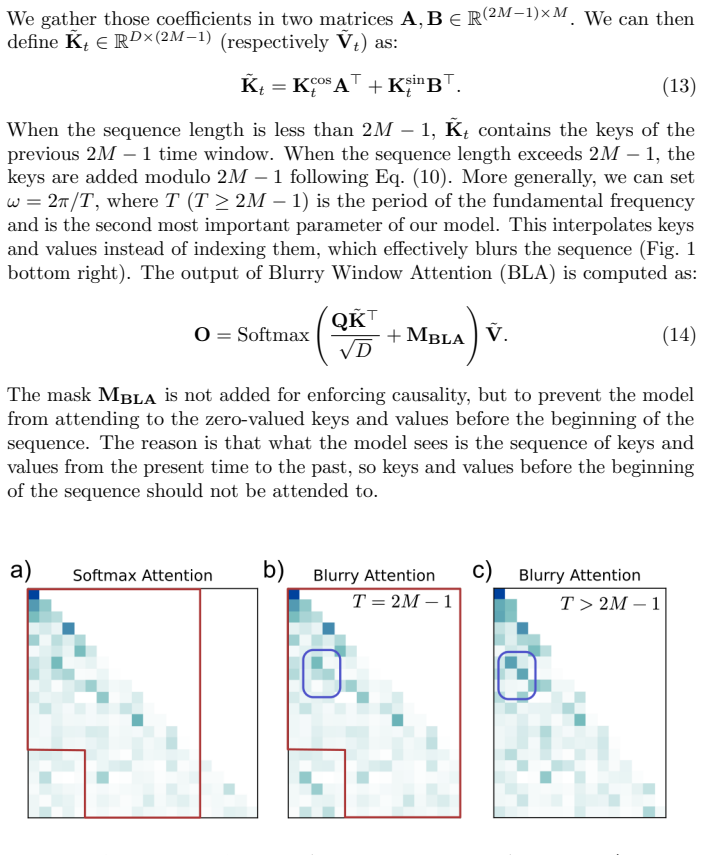
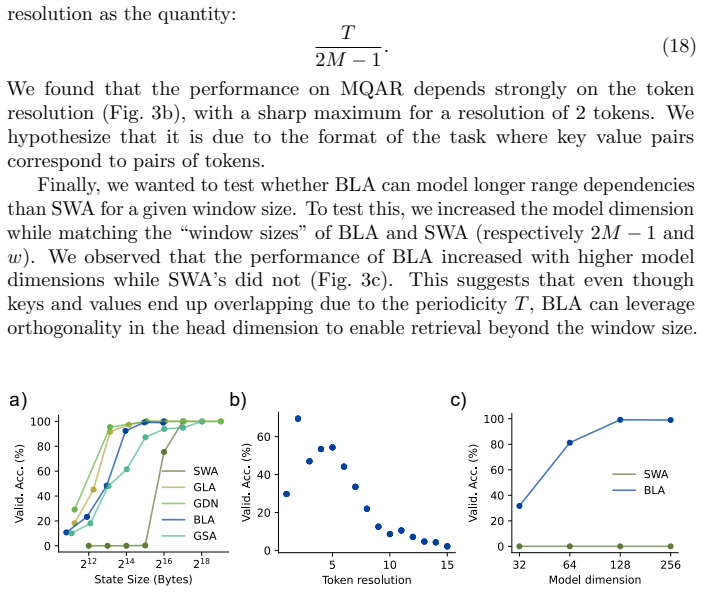
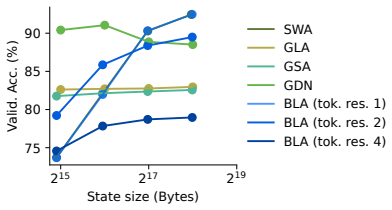
Blurry Window Attention stores a frequency window from which a blurry KV history is reconstructed via interpolation using Dirichlet kernels. BLA generalizes Sliding Window Attention depending on the Dirichlet kernels resolution and serves as a special case of Gated Slot Attention where the decay factor is implemented with Dirichlet kernels. On the Multi-Query Associate Recall task the state efficiency of BLA reaches 8 times that of Sliding Window Attention and matches popular linear attention models; on RegBench only BLA and Sliding Window Attention improve performance as state size grows among the linear models tested.
What carries the argument
Blurry Window Attention mechanism that stores a frequency window and reconstructs KV history through Dirichlet kernel interpolation.
If this is right
- BLA achieves comparable recall performance to Sliding Window Attention using one-eighth the state size on MQAR.
- BLA improves accuracy on RegBench when given larger state budgets, unlike most tested linear attention alternatives.
- BLA admits an efficient implementation that reduces to Sliding Window Attention at low kernel resolution.
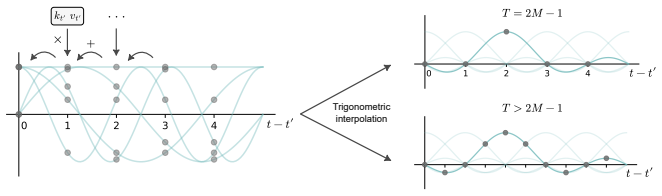
- BLA offers a concrete bounded-memory control method inside the ABC family that is directly inspired by state-space model ideas.
Where Pith is reading between the lines
- The frequency-window storage pattern may generalize to other sequence tasks that require selective recall without growing memory linearly with length.
- Treating the Dirichlet kernel as a tunable decay operator could allow direct comparisons between BLA and existing SSM decay schedules on the same benchmarks.
- If the interpolation step can be fused with existing linear attention code, BLA might serve as a drop-in upgrade for models already using bounded state.
Load-bearing premise
Dirichlet kernel interpolation from a frequency window preserves enough information for retrieval and recall tasks without task-specific tuning of kernel resolution or window parameters.
What would settle it
A run on the MQAR task in which BLA fails to reach 8 times the state efficiency of Sliding Window Attention, or a run on RegBench in which BLA performance does not improve as state size increases while other linear models remain flat.
Figures
read the original abstract
The Softmax Attention operation in Transformer language models has a quadratic complexity in the sequence length and a growing state size in the form of KV cache, which becomes a bottleneck in long context scenarios. To overcome this limitation, alternative architectures with linear complexity and finite state size have been introduced, such as State-Space Models (SSMs), Linear Attention (LA), and Attention with Bounded-memory Control (ABC). Though linear models achieve similar language perplexity as Transformers, they are still behind in tasks which require retrieval or recall of specific information. In this work, we introduce Blurry Window Attention (BLA) a novel ABC method inspired by SSMs. BLA stores a frequency window from which a blurry KV history is reconstructed via interpolation using Dirichlet kernels. BLA can be understood as a generalization of Sliding Window Attention (SWA) depending on the Dirichlet kernels resolution or as a special case of the Gated Slot Attention (GSA), where the decay factor is implemented with Dirichlet kernels. We describe in details the theory and efficient implementation of BLA. On the Multi-Query Associate Recall (MQAR) synthetic task, we show that the state efficiency of BLA is 8$\times$ better than SWA and is competitive with popular linear attention models, and in the RegBench synthetic task, only BLA and SWA improve their performance as the state size grows among the linear models we tested.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Blurry Window Attention (BLA), a bounded-memory attention method that stores a frequency window and reconstructs a blurry KV history via Dirichlet kernel interpolation. BLA is presented as a generalization of Sliding Window Attention (SWA) controlled by kernel resolution or as a special case of Gated Slot Attention (GSA). On the synthetic Multi-Query Associate Recall (MQAR) task, BLA achieves 8× better state efficiency than SWA while remaining competitive with linear attention models; on RegBench, only BLA and SWA improve performance as state size grows among the tested linear models.
Significance. If the synthetic-task advantages prove robust, BLA would supply a parameter-light interpolation mechanism that improves retrieval efficiency over pure sliding-window or linear attention baselines while retaining an SSM-inspired finite state. The explicit derivation of an efficient implementation and the positioning relative to SWA/GSA are constructive contributions that could be directly useful for follow-on work on bounded-memory attention.
major comments (3)
- [Abstract] Abstract: the 8× state-efficiency claim on MQAR and the statement that only BLA/SWA improve with state size on RegBench are reported without error bars, variance estimates, or ablation results on the two free parameters (Dirichlet kernel resolution and frequency window size). Because these parameters directly control the interpolation, the efficiency numbers cannot be assessed for robustness or sensitivity to the chosen values.
- [BLA construction] BLA construction (theory section): the claim that a single fixed frequency window and resolution suffices for associate-recall tasks without task-specific retuning is load-bearing for the generalization argument, yet no analysis is supplied showing that high-frequency content required for exact retrieval is preserved at the reported state sizes, nor is any cross-task transfer experiment presented.
- [Experiments] Experiments: baseline implementation details, hyper-parameter matching, and statistical significance for the MQAR and RegBench comparisons are not reported, making it impossible to verify that the observed efficiency gap is not an artifact of unequal tuning effort between BLA and the linear-attention or SSM baselines.
minor comments (1)
- [Theory] Notation for the Dirichlet kernel and the frequency-window indexing should be made fully explicit with an equation reference so that the interpolation step can be reproduced from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on robustness, theoretical analysis, and experimental details. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 8× state-efficiency claim on MQAR and the statement that only BLA/SWA improve with state size on RegBench are reported without error bars, variance estimates, or ablation results on the two free parameters (Dirichlet kernel resolution and frequency window size). Because these parameters directly control the interpolation, the efficiency numbers cannot be assessed for robustness or sensitivity to the chosen values.
Authors: We agree that error bars, variance estimates, and ablations on kernel resolution and frequency window size are needed to assess robustness. The revised manuscript will include these for MQAR and RegBench, along with sensitivity analysis across parameter ranges. The 8× claim will be qualified with the new statistics. revision: yes
-
Referee: [BLA construction] BLA construction (theory section): the claim that a single fixed frequency window and resolution suffices for associate-recall tasks without task-specific retuning is load-bearing for the generalization argument, yet no analysis is supplied showing that high-frequency content required for exact retrieval is preserved at the reported state sizes, nor is any cross-task transfer experiment presented.
Authors: The MQAR results demonstrate effective retrieval with fixed parameters, consistent with the Dirichlet kernel's approximation properties derived in the theory section. We acknowledge the absence of explicit high-frequency preservation analysis and cross-task transfer experiments. The revision will add a brief discussion of frequency content at the reported state sizes and note cross-task generalization as future work. revision: partial
-
Referee: [Experiments] Experiments: baseline implementation details, hyper-parameter matching, and statistical significance for the MQAR and RegBench comparisons are not reported, making it impossible to verify that the observed efficiency gap is not an artifact of unequal tuning effort between BLA and the linear-attention or SSM baselines.
Authors: We will expand the experiments section with full baseline implementation details, explicit hyperparameter matching procedures, and statistical significance metrics (e.g., standard deviations across seeds and significance tests). This will allow verification that the efficiency gap is not due to unequal tuning. revision: yes
Circularity Check
No significant circularity; construction is self-contained
full rationale
The paper presents BLA as an explicit new construction: a frequency window whose KV history is reconstructed via Dirichlet-kernel interpolation, explicitly positioned as a generalization of SWA (by kernel resolution) or special case of GSA (by implementing decay with kernels). No equation reduces the claimed state-efficiency gains on MQAR or the state-size scaling on RegBench to a fitted parameter or to a self-citation whose content is itself the target result. Performance numbers are reported as empirical outcomes of the construction on synthetic tasks, not as quantities forced by the definition of the method itself. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- Dirichlet kernel resolution
- frequency window size
axioms (2)
- domain assumption Dirichlet kernels can be used for accurate interpolation of frequency-domain data to reconstruct time-domain KV pairs
- standard math Standard properties of linear attention and bounded-memory control hold for the proposed variant
Reference graph
Works this paper leans on
-
[1]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[2]
Why stacking sliding windows can’t see very far
Guangxuan Xiao. Why stacking sliding windows can’t see very far. https: //guangxuanx.com/blog/stacking-swa.html, 2025
2025
-
[3]
Hippo: Recurrent memory with optimal polynomial projections.Advances in neural information processing systems, 33:1474–1487, 2020
Albert Gu, Tri Dao, Stefano Ermon, Atri Rudra, and Christopher R´ e. Hippo: Recurrent memory with optimal polynomial projections.Advances in neural information processing systems, 33:1474–1487, 2020
2020
-
[4]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher R´ e. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arxiv 2023.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Fran¸ cois Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational conference on machine learning, pages 5156–5165. PMLR, 2020. 13
2020
-
[7]
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training.arXiv preprint arXiv:2312.06635, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule.arXiv preprint arXiv:2412.06464, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Abc: Attention with bounded-memory control
Hao Peng, Jungo Kasai, Nikolaos Pappas, Dani Yogatama, Zhaofeng Wu, Lingpeng Kong, Roy Schwartz, and Noah A Smith. Abc: Attention with bounded-memory control. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7469–7483, 2022
2022
-
[10]
Gated slot attention for efficient linear-time sequence modeling.Advances in Neural Information Processing Systems, 37:116870–116898, 2024
Yu Zhang, Songlin Yang, Rui-Jie Zhu, Yue Zhang, Leyang Cui, Yiqiao Wang, Bolun Wang, Freda Shi, Bailin Wang, Wei Bi, et al. Gated slot attention for efficient linear-time sequence modeling.Advances in Neural Information Processing Systems, 37:116870–116898, 2024
2024
-
[11]
Aviv Bick, Eric Xing, and Albert Gu. Understanding the skill gap in recurrent language models: The role of the gather-and-aggregate mechanism. arXiv preprint arXiv:2504.18574, 2025
-
[12]
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
Johannes von Oswald, Nino Scherrer, Seijin Kobayashi, Luca Versari, Songlin Yang, Maximilian Schlegel, Kaitlin Maile, Yanick Schimpf, Oliver Sieberling, Alexander Meulemans, et al. Mesanet: Sequence modeling by locally optimal test-time training.arXiv preprint arXiv:2506.05233, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
On the param- eterization and initialization of diagonal state space models.Advances in Neural Information Processing Systems, 35:35971–35983, 2022
Albert Gu, Karan Goel, Ankit Gupta, and Christopher R´ e. On the param- eterization and initialization of diagonal state space models.Advances in Neural Information Processing Systems, 35:35971–35983, 2022
2022
-
[14]
Legendre memory units: Continuous-time representation in recurrent neural networks.Advances in neural information processing systems, 32, 2019
Aaron Voelker, Ivana Kaji´ c, and Chris Eliasmith. Legendre memory units: Continuous-time representation in recurrent neural networks.Advances in neural information processing systems, 32, 2019
2019
-
[15]
Resurrecting recurrent neural networks for long sequences
Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, and Soham De. Resurrecting recurrent neural networks for long sequences. InInternational Conference on Machine Learning, pages 26670–26698. PMLR, 2023
2023
-
[16]
arXiv preprint arXiv:2212.14052 , year=
Daniel Y Fu, Tri Dao, Khaled K Saab, Armin W Thomas, Atri Rudra, and Christopher R´ e. Hungry hungry hippos: Towards language modeling with state space models.arXiv preprint arXiv:2212.14052, 2022
-
[17]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Soham De, Samuel L Smith, Anushan Fernando, Aleksandar Botev, George Cristian-Muraru, Albert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, Srivatsan Srinivasan, et al. Griffin: Mixing gated linear recurrences with local attention for efficient language models.arXiv preprint arXiv:2402.19427, 2024. 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Mamba-3: Improved sequence modeling using state space principles
Aakash Lahoti, Kevin Li, Berlin Chen, Caitlin Wang, Aviv Bick, J Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved sequence modeling using state space principles. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=HwCvaJOiCj
2026
-
[19]
The dirichlet and fej´ er kernels
RE Edwards. The dirichlet and fej´ er kernels. ces` aro summability. InFourier Series: A Modern Introduction Volume 1, pages 78–86. Springer, 1979
1979
-
[20]
Michael Zhang, Kush Bhatia, Hermann Kumbong, and Christopher R´ e. The hedgehog & the porcupine: Expressive linear attentions with softmax mimicry.arXiv preprint arXiv:2402.04347, 2024
-
[21]
Fla: A triton-based library for hardware- efficient implementations of linear attention mechanism, January 2024
Songlin Yang and Yu Zhang. Fla: A triton-based library for hardware- efficient implementations of linear attention mechanism, January 2024. URL https://github.com/fla-org/flash-linear-attention
2024
-
[22]
Paral- lelizing linear transformers with the delta rule over sequence length.Advances in neural information processing systems, 37:115491–115522, 2024
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Paral- lelizing linear transformers with the delta rule over sequence length.Advances in neural information processing systems, 37:115491–115522, 2024
2024
-
[23]
arXiv preprint arXiv:2312.04927 , year=
Simran Arora, Sabri Eyuboglu, Aman Timalsina, Isys Johnson, Michael Poli, James Zou, Atri Rudra, and Christopher R´ e. Zoology: Measuring and im- proving recall in efficient language models.arXiv preprint arXiv:2312.04927, 2023
-
[24]
In-context lan- guage learning: Architectures and algorithms
Ekin Aky¨ urek, Bailin Wang, Yoon Kim, and Jacob Andreas. In-context lan- guage learning: Architectures and algorithms. InInternational Conference on Machine Learning, pages 787–812. PMLR, 2024
2024
-
[25]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Rethinking Attention with Performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers.arXiv preprint arXiv:2009.14794, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[27]
Random feature attention.arXiv preprint arXiv:2103.02143, 2021
Hao Peng, Nikolaos Pappas, Dani Yogatama, Roy Schwartz, Noah A Smith, and Lingpeng Kong. Random feature attention.arXiv preprint arXiv:2103.02143, 2021
-
[28]
Simple linear attention language models balance the recall-throughput tradeoff
Simran Arora, Sabri Eyuboglu, Michael Zhang, Aman Timalsina, Silas Alberti, Dylan Zinsley, James Zou, Atri Rudra, and Christopher R´ e. Simple linear attention language models balance the recall-throughput tradeoff. arXiv preprint arXiv:2402.18668, 2024. 15
-
[29]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Linear transform- ers are secretly fast weight programmers
Imanol Schlag, Kazuki Irie, and J¨ urgen Schmidhuber. Linear transform- ers are secretly fast weight programmers. InInternational conference on machine learning, pages 9355–9366. PMLR, 2021
2021
-
[31]
Kimi Linear: An Expressive, Efficient Attention Architecture
Kimi Team, Yu Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, et al. Kimi linear: An expressive, efficient attention architecture.arXiv preprint arXiv:2510.26692, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Transformers learn in-context by gradient descent
Johannes Von Oswald, Eyvind Niklasson, Ettore Randazzo, Jo˜ ao Sacra- mento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. InInternational Confer- ence on Machine Learning, pages 35151–35174. PMLR, 2023
2023
-
[33]
arXiv preprint arXiv:2309.05858 , year=
Johannes Von Oswald, Maximilian Schlegel, Alexander Meulemans, Seijin Kobayashi, Eyvind Niklasson, Nicolas Zucchet, Nino Scherrer, Nolan Miller, Mark Sandler, Max Vladymyrov, et al. Uncovering mesa-optimization algorithms in transformers.arXiv preprint arXiv:2309.05858, 2023
-
[34]
Learning long term dependencies via fourier recurrent units
Jiong Zhang, Yibo Lin, Zhao Song, and Inderjit Dhillon. Learning long term dependencies via fourier recurrent units. InInternational Conference on Machine Learning, pages 5815–5823. PMLR, 2018
2018
-
[35]
Rotational unit of memory: a novel representation unit for rnns with scalable applications.Transactions of the Association for Computational Linguistics, 7:121–138, 2019
Rumen Dangovski, Li Jing, Preslav Nakov, Mi´ co Tatalovi´ c, and Marin Soljaˇ ci´ c. Rotational unit of memory: a novel representation unit for rnns with scalable applications.Transactions of the Association for Computational Linguistics, 7:121–138, 2019
2019
-
[36]
FNet : M ixing T okens with F ourier T ransforms
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, and Santiago Ontanon. Fnet: Mixing tokens with fourier transforms. arxiv 2021.arXiv preprint arXiv:2105.03824, 2021
-
[37]
Megalodon: Efficient llm pretraining and inference with unlimited context length.Advances in Neural Information Processing Systems, 37:71831–71854, 2024
Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, and Chunting Zhou. Megalodon: Efficient llm pretraining and inference with unlimited context length.Advances in Neural Information Processing Systems, 37:71831–71854, 2024
2024
-
[38]
cosformer: Rethinking softmax in attention.arXiv preprint arXiv:2202.08791, 2022
Zhen Qin, Weixuan Sun, Hui Deng, Dongxu Li, Yunshen Wei, Baohong Lv, Junjie Yan, Lingpeng Kong, and Yiran Zhong. cosformer: Rethinking softmax in attention.arXiv preprint arXiv:2202.08791, 2022
-
[39]
Faedkv: Infinite-window fourier transform for unbiased kv cache compression
Runchao Li, Yao Fu, Mu Sheng, Xianxuan Long, Haotian Yu, and Pan Li. Faedkv: Infinite-window fourier transform for unbiased kv cache compression. arXiv preprint arXiv:2507.20030, 2025. 16
-
[40]
Dct-former: Efficient self-attention with discrete cosine transform.Journal of Scientific Computing, 94(3):67, 2023
Carmelo Scribano, Giorgia Franchini, Marco Prato, and Marko Bertogna. Dct-former: Efficient self-attention with discrete cosine transform.Journal of Scientific Computing, 94(3):67, 2023. 17 A Related Work A wide range of efficient attention models have emerged, each offering distinct strategies to scale linear architectures and compete with full attention...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.