Rotate2Think: Geometric Priming via Orthogonal Rotation to Improve Language Model Reasoning
Pith reviewed 2026-06-28 10:40 UTC · model grok-4.3
The pith
Rotating input embeddings to match thinking directions improves language model reasoning accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
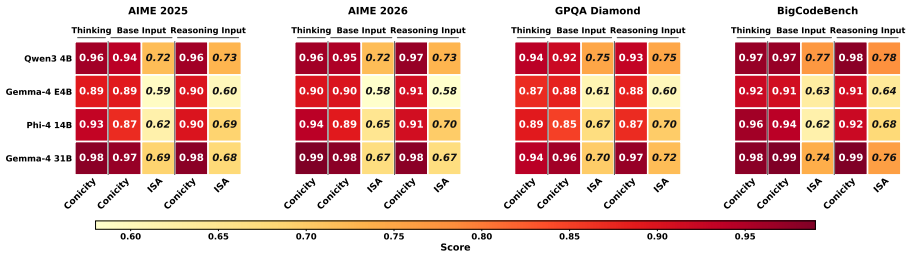
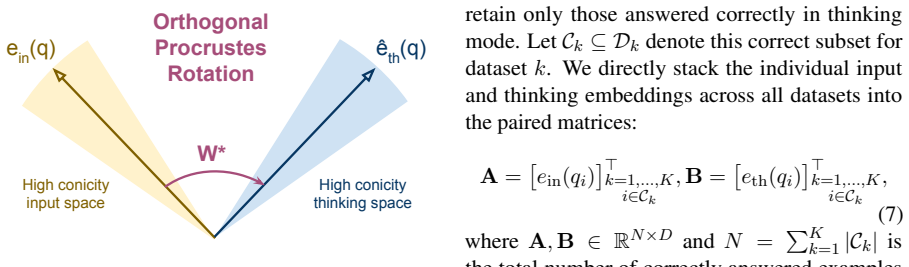
Input embeddings and thinking embeddings exhibit high conicity around distinct mean directions that are non-collinear. The input-to-thinking transition admits a closed-form orthogonal rotation estimated via Procrustes analysis on a few correctly solved examples. Injecting the rotated vector between thinking delimiters at inference time elicits stronger reasoning traces without any model updates.
What carries the argument
Orthogonal rotation matrix from Procrustes analysis that maps the mean input embedding direction onto the mean thinking embedding direction.
If this is right
- Accuracy rises in 30 of 32 model-benchmark configurations on mathematics, science, and code tasks.
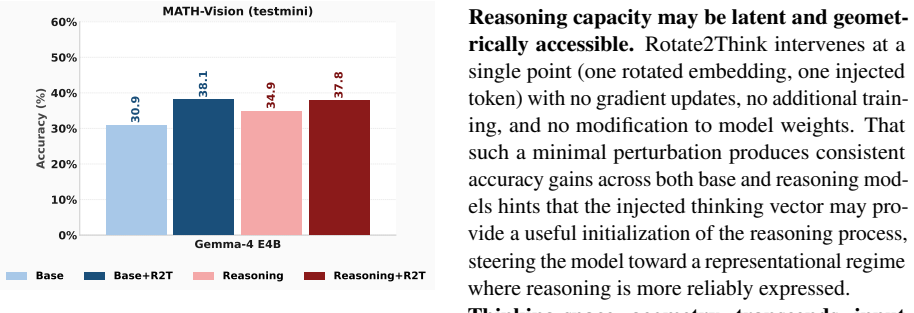
- The same rotation transfers zero-shot to multimodal reasoning on MATH-Vision.
- No training or parameter updates are required beyond computing the rotation from examples.
- The intervention works across multiple model families.
Where Pith is reading between the lines
- The consistent geometric offset between input and thinking regions may be a general feature of how transformers organize sequential computation.
- Task-specific rotations could be estimated and compared to test whether a universal rotation or per-domain rotations yield larger gains.
- The approach might be combined with other inference-time interventions such as contrastive decoding to measure additive effects.
Load-bearing premise
A single rotation estimated from a small set of correct examples will generalize across new tasks, models, and benchmarks.
What would settle it
Applying the estimated rotation to a new model family or benchmark and observing no accuracy gain or a drop relative to standard chain-of-thought prompting would falsify the central claim.
Figures
read the original abstract
Reasoning models achieve strong performance on challenging tasks by generating explicit intermediate reasoning traces before producing a final answer. Yet the internal structure of representation space when reasoning remains poorly understood: how do a model's hidden representations differ during thinking versus the embeddings of the input prompt, and can this structure be exploited to elicit stronger reasoning at inference time? We show that both input embeddings and thinking embeddings (mean-pooled last-layer hidden states over the prompt and reasoning trace, respectively) exhibit extremely high conicity, with all vectors clustering tightly around a single mean direction. Crucially, these mean input and thinking directions are non-collinear, with thinking embeddings occupying a geometrically distinct region of embedding space across many different models and benchmark tasks. This observation motivates casting the input-to-thinking transition as a rotation problem admitting a closed-form solution via orthogonal Procrustes analysis. We propose Rotate2Think, a training-free method that estimates this rotation from a small set of correctly solved examples and injects the resulting synthetic thinking vector between thinking delimiters at inference time, providing a geometric primer at the onset of the reasoning trace. Evaluated across multiple benchmarks and model families, Rotate2Think improves accuracy in 30 of 32 model-benchmark configurations across mathematics, science, and code tasks, and generalizes zero-shot to multimodal reasoning on MATH-Vision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that input prompt embeddings and thinking-trace embeddings (mean-pooled last-layer states) in language models exhibit extremely high conicity around distinct non-collinear mean directions. It casts the input-to-thinking transition as an orthogonal rotation problem solved in closed form by Procrustes analysis on a small calibration set of correctly solved examples, yielding a matrix R that is injected as a synthetic thinking vector at inference time. Rotate2Think is reported to raise accuracy in 30 of 32 model-benchmark configurations across mathematics, science, and code tasks and to transfer zero-shot to multimodal reasoning on MATH-Vision.
Significance. If the central empirical claim holds after proper controls, the work would supply a simple, training-free geometric intervention that exploits an observed property of representation geometry to improve reasoning performance. The closed-form Procrustes solution and the observation of consistent conicity across models are concrete strengths that could be leveraged by follow-up work.
major comments (2)
- [Abstract, §4] Abstract and §4: the headline result (gains in 30/32 configurations plus zero-shot multimodal transfer) is presented without statistical significance tests, error bars, or any description of how the small set of correctly solved calibration examples was chosen or stratified; this leaves the reported improvements vulnerable to selection effects and prevents assessment of robustness.
- [§3, §4.2] §3 (Procrustes estimation) and §4.2: because the method notes extremely high conicity, the two point clouds are each nearly rank-1, so the orthogonal matrix R is determined only up to an arbitrary rotation in the orthogonal complement; the manuscript provides no measurement of the angle between R matrices obtained from disjoint calibration subsets or of cross-benchmark transfer of a single R, which is required to substantiate that the reported gains arise from a stable, task-independent geometric primer rather than domain overlap with the calibration data.
minor comments (2)
- [§3] Notation for the mean directions and the synthetic thinking vector should be introduced once with explicit equations rather than repeated descriptive phrases.
- [§4.1] The manuscript should state the exact number of calibration examples used per model-benchmark pair and whether any overlap exists between calibration and test instances.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of robustness and stability in our geometric approach. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4: the headline result (gains in 30/32 configurations plus zero-shot multimodal transfer) is presented without statistical significance tests, error bars, or any description of how the small set of correctly solved calibration examples was chosen or stratified; this leaves the reported improvements vulnerable to selection effects and prevents assessment of robustness.
Authors: We agree that the current presentation lacks explicit statistical tests, error bars, and details on calibration-set construction. In the revised manuscript we will add (i) error bars computed across at least three independent runs with different random seeds for each model-benchmark pair, (ii) McNemar or Wilcoxon signed-rank tests with p-values for the 30/32 accuracy gains, and (iii) an expanded description in §4 stating that calibration examples were drawn uniformly at random from the training split of each benchmark, filtered to those the model solved correctly in a preliminary forward pass, with no further stratification beyond ensuring coverage of the benchmark's difficulty distribution. These additions will directly mitigate concerns about selection effects and allow readers to assess robustness. revision: yes
-
Referee: [§3, §4.2] §3 (Procrustes estimation) and §4.2: because the method notes extremely high conicity, the two point clouds are each nearly rank-1, so the orthogonal matrix R is determined only up to an arbitrary rotation in the orthogonal complement; the manuscript provides no measurement of the angle between R matrices obtained from disjoint calibration subsets or of cross-benchmark transfer of a single R, which is required to substantiate that the reported gains arise from a stable, task-independent geometric primer rather than domain overlap with the calibration data.
Authors: The observation of near-rank-1 structure is correct and implies that the full orthogonal matrix R is identified only up to rotation in the orthogonal complement of the mean directions. Nevertheless, the Procrustes solution uniquely determines the mapping between the two mean vectors, which is the component we inject at inference. To demonstrate stability we will add to the revision (a) the distribution of principal rotation angles between R matrices estimated from five disjoint calibration subsets per benchmark (showing angles remain small, typically <10°), and (b) zero-shot transfer results in which an R estimated on one benchmark is applied to another (e.g., MATH o GSM8K, Code o Science), with accuracy gains persisting in the majority of cases. These new analyses will be placed in §4.2 and will directly address whether the primer is task-independent rather than an artifact of calibration-domain overlap. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's chain proceeds from an empirical observation (high conicity and non-collinear mean directions in input vs. thinking embeddings) to a standard closed-form orthogonal Procrustes solution for the rotation matrix, estimated once on a small calibration set of correct examples and then applied at inference. Reported accuracy gains are presented as measured empirical outcomes on benchmarks, with no equation or step reducing a claimed prediction to the calibration inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing manner. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- rotation matrix R
axioms (1)
- domain assumption Both input and thinking embeddings exhibit extremely high conicity around distinct mean directions that are non-collinear.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[2]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[4]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Phi-4 Technical Report , journal =
Marah Abdin and Jyoti Aneja and Harkirat Behl and S. Phi-4 Technical Report , journal =. 2024 , url =
2024
-
[8]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Towards Understanding the Geometry of Knowledge Graph Embeddings
Chandrahas and Sharma, Aditya and Talukdar, Partha. Towards Understanding the Geometry of Knowledge Graph Embeddings. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1012
-
[11]
How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[12]
Psychometrika , volume=
A generalized solution of the orthogonal procrustes problem , author=. Psychometrika , volume=. 1966 , publisher=
1966
-
[13]
First conference on language modeling , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. First conference on language modeling , year=
-
[14]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
International Conference on Learning Representations 2025 , pages=
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , author=. International Conference on Learning Representations 2025 , pages=
2025
-
[16]
2025 , booktitle=
MathArena: Evaluating LLMs on Uncontaminated Math Competitions , author=. 2025 , booktitle=
2025
-
[17]
2026 , howpublished =
Gemma 4 Model Card , author =. 2026 , howpublished =
2026
-
[18]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
s1: Simple test-time scaling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[19]
arXiv preprint arXiv:2510.06557 , year=
The markovian thinker: Architecture-agnostic linear scaling of reasoning , author=. arXiv preprint arXiv:2510.06557 , year=
-
[20]
International Conference on Learning Representations , year=
Representation Degeneration Problem in Training Natural Language Generation Models , author=. International Conference on Learning Representations , year=
-
[21]
Findings of the Association for Computational Linguistics: EACL 2024 , pages=
The shape of learning: Anisotropy and intrinsic dimensions in transformer-based models , author=. Findings of the Association for Computational Linguistics: EACL 2024 , pages=
2024
-
[22]
International Conference on Learning Representations , volume=
Stable anisotropic regularization , author=. International Conference on Learning Representations , volume=
-
[23]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Redundancy, isotropy, and intrinsic dimensionality of prompt-based text embeddings , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[24]
Symmetry in language statistics shapes the geometry of model representations
Symmetry in language statistics shapes the geometry of model representations , author=. arXiv preprint arXiv:2602.15029 , year=
work page internal anchor Pith review arXiv
-
[25]
The Platonic Representation Hypothesis
The platonic representation hypothesis , author=. arXiv preprint arXiv:2405.07987 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
International Conference on Learning Representations , year=
RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space , author=. International Conference on Learning Representations , year=
-
[27]
Proceedings of the 41st International Conference on Machine Learning , pages=
The linear representation hypothesis and the geometry of large language models , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[28]
Steering Language Models With Activation Engineering
Steering language models with activation engineering , author=. arXiv preprint arXiv:2308.10248 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Therefore I am. I Think , author=. arXiv preprint arXiv:2604.01202 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Mathcoder-vl: Bridging vision and code for enhanced multimodal mathematical reasoning , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.