One Lens, Many Worlds : A Capability-Typed Interface for World-Model Interpretability
Pith reviewed 2026-06-27 18:36 UTC · model grok-4.3
The pith
A capability-typed interface with four required methods lets the same interpretability code run on recurrent, token-based, and embedding world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
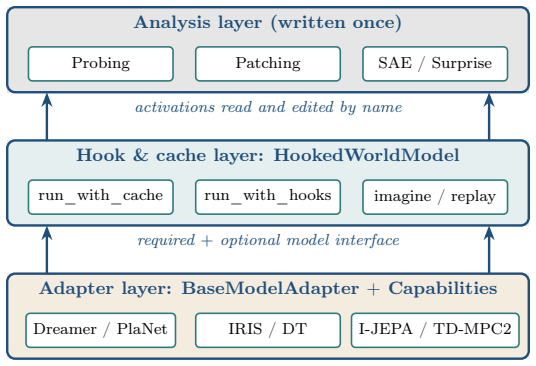
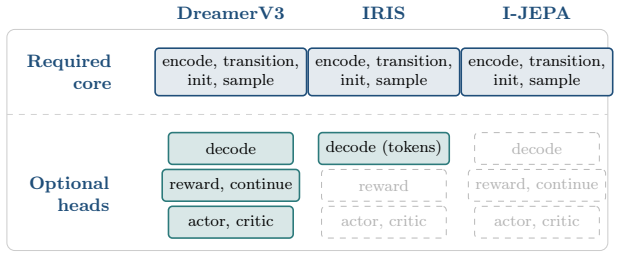
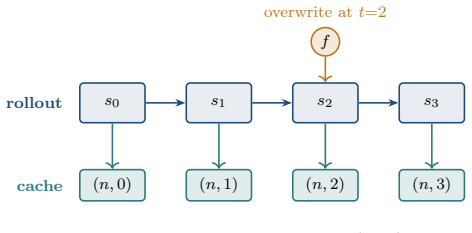
The shared structure of world models is captured by a small typed interface. Every model implements four required methods (encode, transition, initial state, sample) and declares a set of optional heads (decode, reward, continue, actor, critic) through an explicit capability descriptor. A single hook and cache layer exposes time-indexed activations, imagination rollouts, and intervention replay over this interface, allowing each analysis to be written once.
What carries the argument
The capability-typed adapter requiring every model to implement encode, transition, initial state, and sample while declaring optional heads via an explicit capability descriptor.
If this is right
- Probing, activation patching, sparse autoencoders, and surprise analysis each become architecture-independent once written against the interface.
- Reinforcement-learning world models with actor-critic heads and self-supervised models without actions are handled by the same code.
- A single hook-and-cache implementation supplies time-indexed activations and intervention replay for any compliant model.
- Imagination rollouts receive the same analysis primitives as real trajectories.
Where Pith is reading between the lines
- New world-model papers could be expected to ship the four methods and descriptor as a compatibility requirement.
- Direct numerical comparison of failure modes across recurrent, token, and embedding families becomes feasible once the tooling layer is shared.
- An automated checker could validate that a submitted model satisfies the interface before any interpretability experiment is attempted.
Load-bearing premise
The four required methods together with the capability descriptor are sufficient to support probing, activation patching, sparse autoencoders, and surprise analysis without any architecture-specific code.
What would settle it
A researcher ports a previously unsupported world-model architecture to the four methods and descriptor, then finds that sparse autoencoders or activation patching still require custom per-architecture logic to produce correct results.
Figures
read the original abstract
World models are now built on substantially different computational substrates. Latent recurrent state-space models such as PlaNet and the Dreamer family compress observations into recurrent states; token-based models such as IRIS quantize observations into a learned codebook and predict autoregressively with a transformer; and joint-embedding predictive architectures such as I-JEPA predict in a learned latent space with no pixel decoder. The interpretability methods applied to these models, including probing, activation patching, sparse autoencoders, and surprise analysis, share a common set of primitives, yet they are re-implemented from scratch for each architecture because existing hook-and-cache tooling assumes a transformer language model with no notion of actions, environment steps, or imagined rollouts. We argue that this fragmentation reflects the tooling rather than the models, and that the shared structure of world models is captured by a small typed interface. We present WorldModelLens, an open-source interpretability substrate organized around a capability-typed adapter: every model implements four required methods (encode, transition, initial state, sample) and declares a set of optional heads (decode, reward, continue, actor, critic) through an explicit capability descriptor, so that reinforcement-learning and self-supervised world models are first-class without either imitating the other. A single hook and cache layer exposes time-indexed activations, imagination rollouts, and intervention replay over this interface, allowing each analysis to be written once.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WorldModelLens, a capability-typed interface for world models across architectures (latent recurrent state-space models like PlaNet/Dreamer, token-based models like IRIS, and joint-embedding models like I-JEPA). It defines four required methods (encode, transition, initial_state, sample) plus an explicit capability descriptor for optional heads (decode, reward, continue, actor, critic). A unified hook-and-cache layer then supports time-indexed activations, imagination rollouts, and interventions, allowing interpretability methods (probing, activation patching, sparse autoencoders, surprise analysis) to be written once rather than reimplemented per architecture.
Significance. If the interface is shown to be sufficient, the work would reduce fragmentation in interpretability tooling for world models by providing a reusable substrate that treats RL and self-supervised models uniformly, enabling single implementations of analyses over diverse computational substrates without architecture-specific code paths.
major comments (1)
- [Abstract] Abstract: the central claim that the four required methods plus capability descriptor suffice to support the full set of listed interpretability methods (probing, activation patching, sparse autoencoders, surprise analysis) across the cited model families without architecture-specific code or loss of functionality is asserted but not accompanied by any coverage argument, implementation example, or test demonstrating that primitives such as full next-token distributions for surprise analysis or direct access to intermediate tensors for SAE training are exposed.
minor comments (2)
- The manuscript would benefit from explicit pseudocode or a small worked example showing how, e.g., activation patching is expressed using only the declared interface methods.
- Notation for the capability descriptor and how optional heads are declared should be formalized in a dedicated section or figure for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the clear identification of the gap in the abstract. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the four required methods plus capability descriptor suffice to support the full set of listed interpretability methods (probing, activation patching, sparse autoencoders, surprise analysis) across the cited model families without architecture-specific code or loss of functionality is asserted but not accompanied by any coverage argument, implementation example, or test demonstrating that primitives such as full next-token distributions for surprise analysis or direct access to intermediate tensors for SAE training are exposed.
Authors: We agree that the abstract, due to length constraints, asserts sufficiency without an explicit coverage argument or inline examples. The full manuscript (Sections 3–4) defines the hook-and-cache layer that registers and exposes time-indexed intermediate activations from any model implementing the four core methods, directly supporting SAE training and activation patching on latent states or token embeddings without per-architecture code. For surprise analysis, the sample method returns next-state predictions; token-based models (e.g., IRIS) can declare a capability head exposing logits or full distributions when needed, while the capability descriptor ensures only supported primitives are used. We will revise the abstract to add one sentence summarizing this coverage and referencing the relevant sections. No new empirical test is required for an interface proposal, but the revision will make the claim traceable from the abstract. revision: yes
Circularity Check
No circularity: design proposal for typed interface with no derivations or self-referential reductions
full rationale
The paper proposes a software abstraction (WorldModelLens) organized around four required methods and an explicit capability descriptor. No equations, fitted parameters, predictions, or self-citations appear in the provided text. The central claim is an engineering hypothesis about interface sufficiency for interpretability primitives across model families; this is not reduced to its inputs by construction, self-definition, or renaming. No load-bearing steps match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption World models share a common structure that can be captured by encode, transition, initial state, and sample methods plus optional heads.
invented entities (1)
-
capability-typed adapter
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ha and J
D. Ha and J. Schmidhuber. Recurrent World Models Facilitate Policy Evolution. InNeurIPS, 2018
2018
-
[2]
Hafner, T
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson. Learning Latent Dynamics for Planning from Pixels. InICML, 2019
2019
-
[3]
Hafner, T
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to Control: Learning Behaviors by Latent Imagination. InICLR, 2020
2020
-
[4]
Hafner, T
D. Hafner, T. Lillicrap, M. Norouzi, and J. Ba. Mastering Atari with Discrete World Models. InICLR, 2021
2021
-
[5]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering Diverse Domains through World Models. arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Micheli, E
V. Micheli, E. Alonso, and F. Fleuret. Transformers are Sample-Efficient World Models. InICLR, 2023
2023
-
[7]
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch. Decision Transformer: Reinforcement Learning via Sequence Modeling. InNeurIPS, 2021
2021
-
[8]
Assran, Q
M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y. LeCun, and N. Ballas. Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture. InCVPR, 2023
2023
-
[9]
Hansen, H
N. Hansen, H. Su, and X. Wang. TD-MPC2: Scalable, Robust World Models for Continuous Control. In ICLR, 2024
2024
-
[10]
Revisiting Feature Prediction for Learning Visual Representations from Video
A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y. LeCun, M. Assran, and N. Ballas. V-JEPA: Latent Video Prediction for Visual Representation Learning.arXiv:2404.08471, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA. Cosmos World Foundation Model Platform for Physical AI.arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Nanda and J
N. Nanda and J. Bloom. TransformerLens: A Library for Mechanistic Interpretability of Generative Language Models.https://github.com/TransformerLensOrg/TransformerLens, 2022
2022
-
[13]
Elhage, N
N. Elhage, N. Nanda, C. Olsson, T. Henighan, et al. A Mathematical Framework for Transformer Circuits.Transformer Circuits Thread, 2021
2021
-
[14]
K. Wang, A. Variengien, A. Conmy, B. Shlegeris, and J. Steinhardt. Interpretability in the Wild: A Circuit for Indirect Object Identification in GPT-2 Small. InICLR, 2023
2023
-
[15]
K. Meng, D. Bau, A. Andonian, and Y. Belinkov. Locating and Editing Factual Associations in GPT. In NeurIPS, 2022
2022
-
[16]
Localizing Model Behavior with Path Patching
N. Goldowsky-Dill, C. MacLeod, L. Sato, and A. Arora. Localizing Model Behavior with Path Patching. arXiv:2304.05969, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Cunningham, A
H. Cunningham, A. Ewart, L. Riggs, R. Huben, and L. Sharkey. Sparse Autoencoders Find Highly Interpretable Features in Language Models. InICLR, 2024
2024
-
[18]
Bricken, A
T. Bricken, A. Templeton, J. Batson, et al. Towards Monosemanticity: Decomposing Language Models with Dictionary Learning.Transformer Circuits Thread, 2023
2023
-
[19]
Understanding intermediate layers using linear classifier probes
G. Alain and Y. Bengio. Understanding Intermediate Layers Using Linear Classifier Probes. arXiv:1610.01644, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Belinkov
Y. Belinkov. Probing Classifiers: Promises, Shortcomings, and Advances.Computational Linguistics, 48(1), 2022
2022
-
[21]
N. Kokhlikyan, V. Miglani, M. Martin, et al. Captum: A Unified and Generic Model Interpretability Library for PyTorch.arXiv:2009.07896, 2020
-
[22]
J. Fiotto-Kaufman, A. R. Loftus, E. Todd, et al. NNsight and NDIF: Democratizing Access to Foundation Model Internals.arXiv:2407.14561, 2024. 11
-
[23]
D. D. Johnson. Penzai and Treescope: Tools for Visualizing and Manipulating Neural Networks. https://github.com/google-deepmind/penzai, 2024
2024
-
[24]
Sundararajan, A
M. Sundararajan, A. Taly, and Q. Yan. Axiomatic Attribution for Deep Networks. InICML, 2017
2017
-
[25]
Jain and B
S. Jain and B. C. Wallace. Attention is not Explanation. InNAACL, 2019
2019
-
[26]
Kornblith, M
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton. Similarity of Neural Network Representations Revisited. InICML, 2019
2019
-
[27]
R. T. Q. Chen, X. Li, R. Grosse, and D. Duvenaud. Isolating Sources of Disentanglement in Variational Autoencoders. InNeurIPS, 2018
2018
-
[28]
Eastwood and C
C. Eastwood and C. K. I. Williams. A Framework for the Quantitative Evaluation of Disentangled Representations. InICLR, 2018
2018
-
[29]
Kumar, P
A. Kumar, P. Sattigeri, and A. Balakrishnan. Variational Inference of Disentangled Latent Concepts from Unlabeled Observations. InICLR, 2018
2018
-
[30]
Higgins, L
I. Higgins, L. Matthey, A. Pal, et al. beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. InICLR, 2017
2017
-
[31]
E. Jang, S. Gu, and B. Poole. Categorical Reparameterization with Gumbel-Softmax. InICLR, 2017
2017
-
[32]
C. J. Maddison, A. Mnih, and Y. W. Teh. The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables. InICLR, 2017
2017
-
[33]
Schrittwieser, I
J. Schrittwieser, I. Antonoglou, T. Hubert, et al. Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model.Nature, 588, 2020
2020
-
[34]
Janner, Q
M. Janner, Q. Li, and S. Levine. Offline Reinforcement Learning as One Big Sequence Modeling Problem. InNeurIPS, 2021
2021
-
[35]
Bruce, M
J. Bruce, M. Dennis, A. Edwards, et al. Genie: Generative Interactive Environments. InICML, 2024
2024
-
[36]
Y. LeCun. A Path Towards Autonomous Machine Intelligence.OpenReview, 2022
2022
-
[37]
K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick. Masked Autoencoders Are Scalable Vision Learners. InCVPR, 2022
2022
-
[38]
Grill, F
J.-B. Grill, F. Strub, F. Altché, et al. Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning. InNeurIPS, 2020
2020
-
[39]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A Simple Framework for Contrastive Learning of Visual Representations. InICML, 2020
2020
-
[40]
Caron, H
M. Caron, H. Touvron, I. Misra, et al. Emerging Properties in Self-Supervised Vision Transformers. In ICCV, 2021
2021
-
[41]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, et al. Learning Transferable Visual Models from Natural Language Supervision. InICML, 2021
2021
-
[42]
B. A. Olshausen and D. J. Field. Emergence of Simple-Cell Receptive Field Properties by Learning a Sparse Code for Natural Images.Nature, 381, 1996
1996
-
[43]
L. Gao, T. Dupré la Tour, H. Tillman, et al. Scaling and Evaluating Sparse Autoencoders. arXiv:2406.04093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Improving Dictionary Learning with Gated Sparse Autoencoders
S. Rajamanoharan, A. Conmy, L. Smith, et al. Improving Dictionary Learning with Gated Sparse Autoencoders.arXiv:2404.16014, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Conmy, A
A. Conmy, A. Mavor-Parker, A. Lynch, S. Heimersheim, and A. Garriga-Alonso. Towards Automated Circuit Discovery for Mechanistic Interpretability. InNeurIPS, 2023
2023
-
[46]
N. Nanda. Attribution Patching: Activation Patching at Industrial Scale.https://neelnanda.io/ attribution-patching, 2023. 12
2023
-
[47]
L. Chan, A. Garriga-Alonso, N. Goldowsky-Dill, et al. Causal Scrubbing: A Method for Rigorously Testing Interpretability Hypotheses.Alignment Forum, 2022
2022
-
[48]
Interpreting GPT: The Logit Lens.LessWrong, 2020
nostalgebraist. Interpreting GPT: The Logit Lens.LessWrong, 2020
2020
-
[49]
SmoothGrad: removing noise by adding noise
D. Smilkov, N. Thorat, B. Kim, F. Viégas, and M. Wattenberg. SmoothGrad: Removing Noise by Adding Noise.arXiv:1706.03825, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. InICCV, 2017
2017
-
[51]
S. M. Lundberg and S.-I. Lee. A Unified Approach to Interpreting Model Predictions. InNeurIPS, 2017
2017
-
[52]
Samek, A
W. Samek, A. Binder, G. Montavon, S. Lapuschkin, and K.-R. Müller. Evaluating the Visualization of What a Deep Neural Network Has Learned.IEEE TNNLS, 28(11), 2017
2017
-
[53]
Raghu, J
M. Raghu, J. Gilmer, J. Yosinski, and J. Sohl-Dickstein. SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability. InNeurIPS, 2017
2017
-
[54]
Hewitt and P
J. Hewitt and P. Liang. Designing and Interpreting Probes with Control Tasks. InEMNLP, 2019
2019
-
[55]
K. Lee, K. Lee, H. Lee, and J. Shin. A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks. InNeurIPS, 2018
2018
-
[56]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, et al. Attention Is All You Need. InNeurIPS, 2017
2017
-
[57]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. InICLR, 2021
2021
-
[58]
D. P. Kingma and M. Welling. Auto-Encoding Variational Bayes. InICLR, 2014
2014
-
[59]
R. S. Sutton and A. G. Barto.Reinforcement Learning: An Introduction. MIT Press, 2nd edition, 2018
2018
-
[60]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, et al. DINOv2: Learning Robust Visual Features without Supervision.Transactions on Machine Learning Research, 2024
2024
-
[61]
Bengio, A
Y. Bengio, A. Courville, and P. Vincent. Representation Learning: A Review and New Perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8), 2013
2013
-
[62]
K. Li, A. K. Hopkins, D. Bau, F. Viégas, H. Pfister, and M. Wattenberg. Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task. InICLR, 2023
2023
-
[63]
B. Kim, M. Wattenberg, J. Gilmer, C. Cai, J. Wexler, F. Viégas, and R. Sayres. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). InICML, 2018
2018
-
[64]
Geiger, H
A. Geiger, H. Lu, T. Icard, and C. Potts. Causal Abstractions of Neural Networks. InNeurIPS, 2021
2021
-
[65]
Templeton, T
A. Templeton, T. Conerly, J. Marcus, et al. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet.Transformer Circuits Thread, 2024
2024
-
[66]
J. Vig, S. Gehrmann, Y. Belinkov, S. Qian, D. Nevo, Y. Singer, and S. Shieber. Investigating Gender Bias in Language Models Using Causal Mediation Analysis. InNeurIPS, 2020. 13
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.