Interpreting and Steering a Text-to-Speech Language Model with Sparse Autoencoders
Pith reviewed 2026-06-27 17:08 UTC · model grok-4.3
The pith
Sparse autoencoders on a TTS language model recover features that can be steered to control laughter, speaker gender, and speech rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
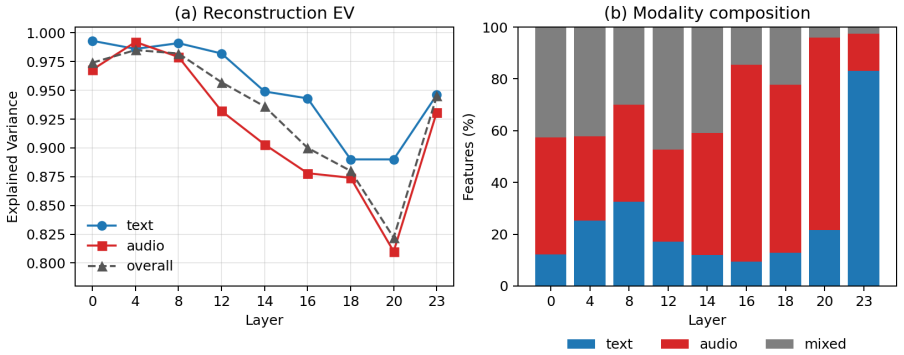
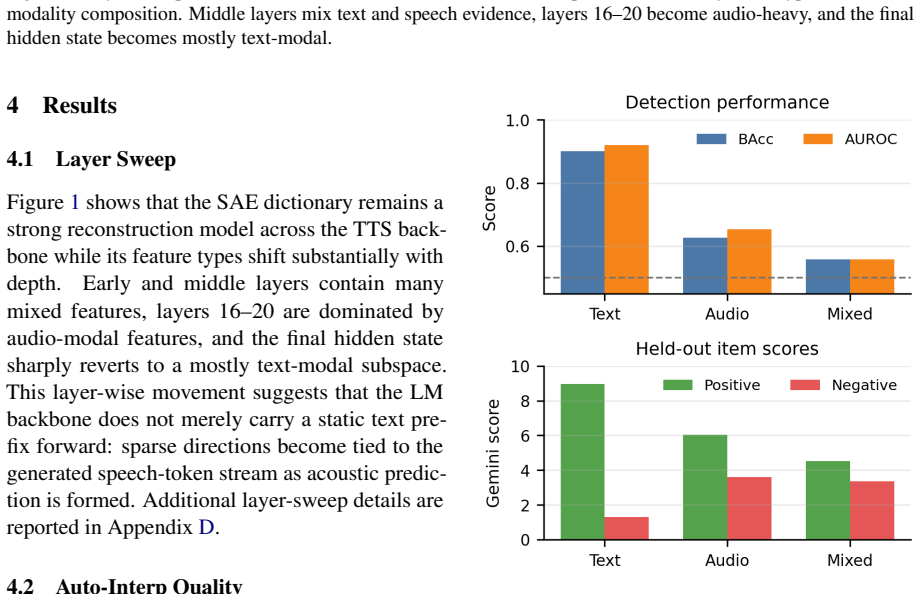
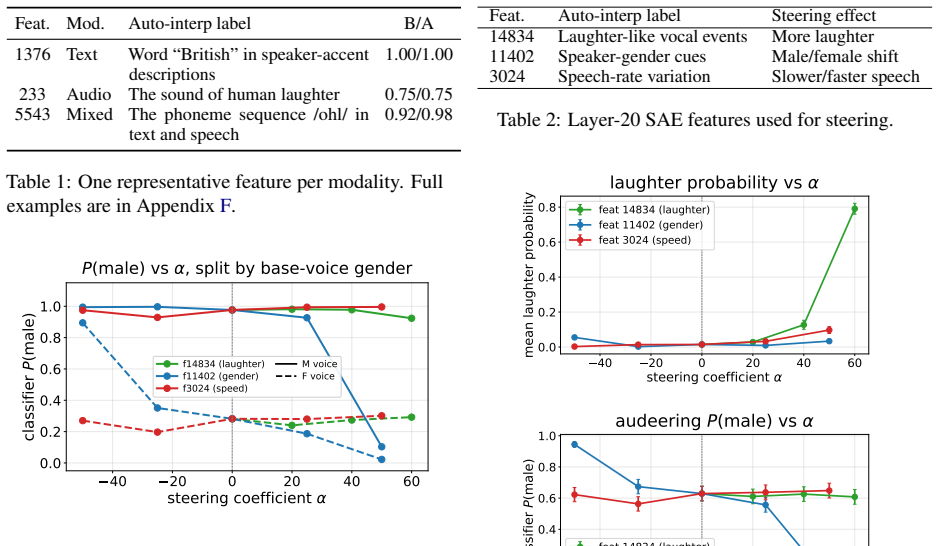
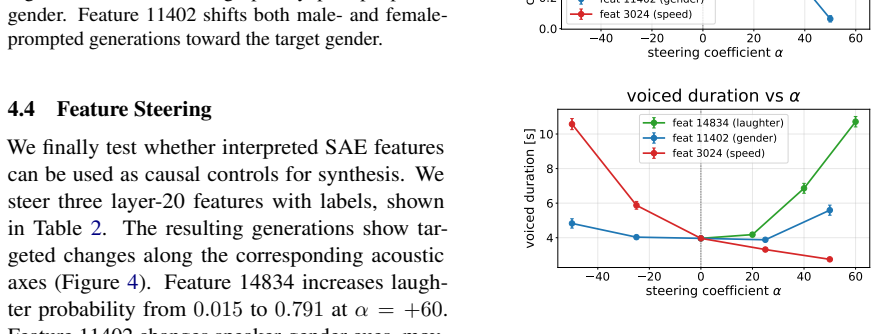
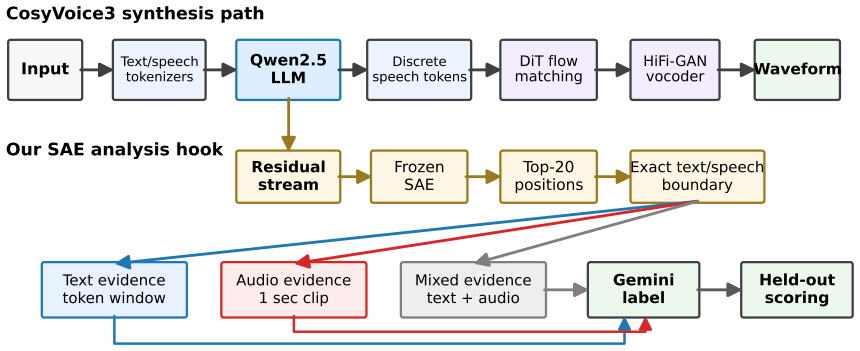
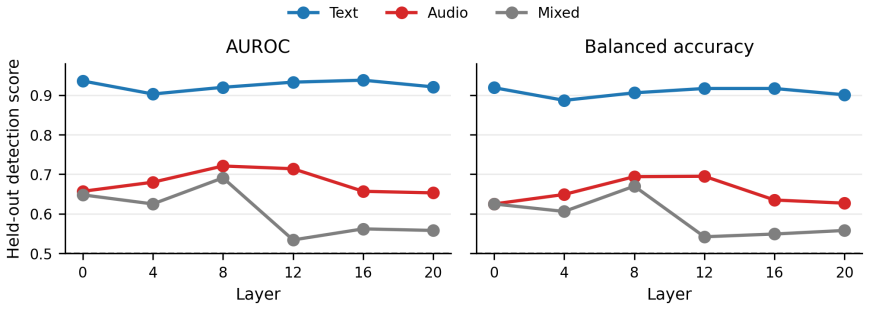
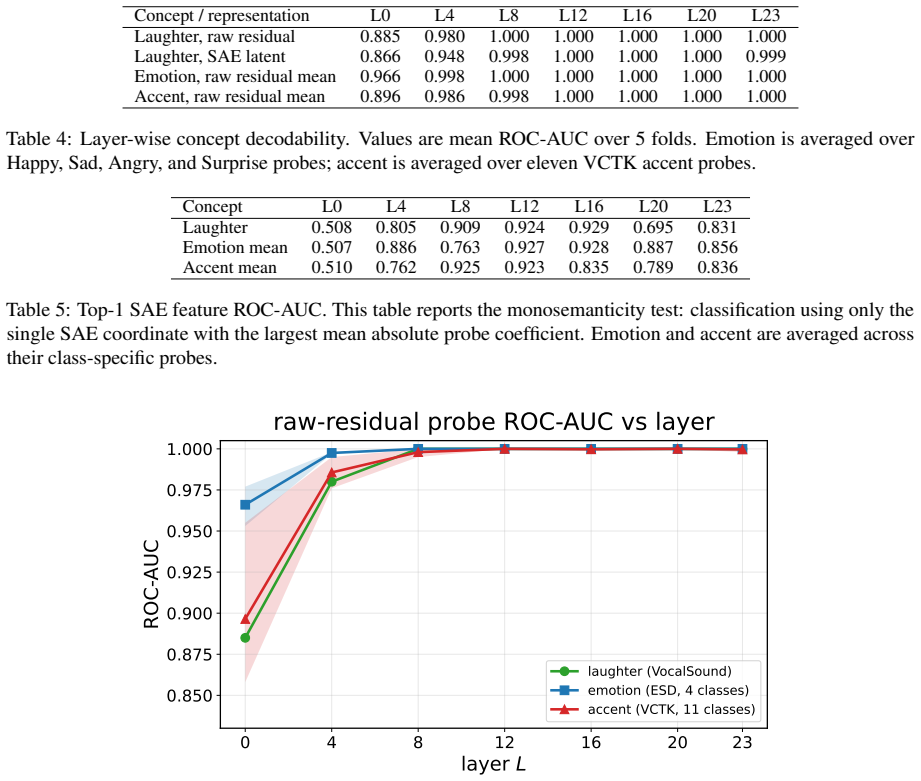
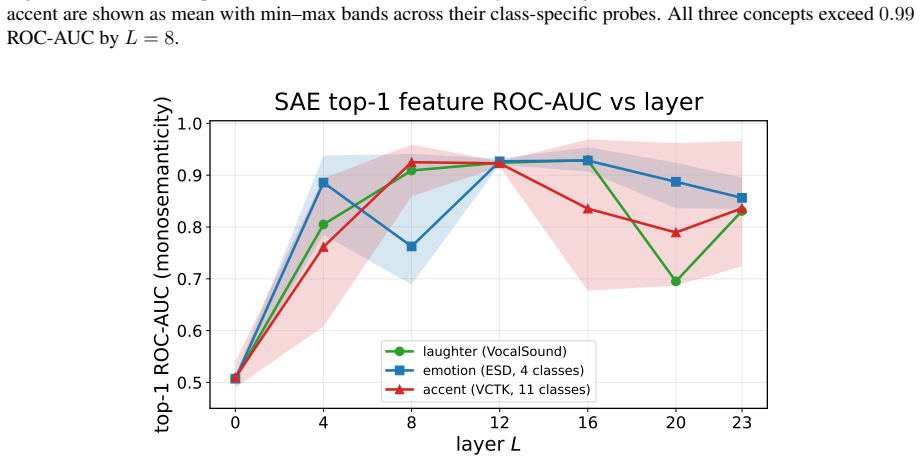
We train BatchTopK sparse autoencoders on the LM backbone of CosyVoice3 and introduce a modality-aware auto-interp pipeline that labels each feature from where it fires—text-prefix context, 1-second speech clips, or both. The recovered features are interpretable, spanning phonemes, laughter, accent prompts and speaker gender. Steering through the SAE latent space shows these features are causal rather than merely descriptive: targeted interventions raise laughter probability from 0.02 to 0.79, flip perceived speaker gender, and control speech rate while preserving spoken content. SAE features thus serve both as interpretability objects and as control directions for TTS synthesis.
What carries the argument
BatchTopK sparse autoencoders paired with a modality-aware auto-interpretation pipeline that tags each latent by its activation context in text or speech.
If this is right
- Targeted addition of an SAE feature can raise laughter probability from 0.02 to 0.79 while leaving spoken content unchanged.
- Subtraction or addition of gender-related features can flip perceived speaker gender in the output audio.
- Adjustment of rate-related features can alter speech speed without altering the words produced.
- The same latents function simultaneously as readable descriptions and as editable control vectors for synthesis.
Where Pith is reading between the lines
- The same pipeline could be applied to other TTS language models that interleave text and speech tokens to test whether comparable causal features emerge.
- Multiple SAE features might be combined in a single forward pass to achieve simultaneous control over several attributes such as emotion and accent.
- If the recovered features remain stable across different speakers and prompts, they could serve as a lightweight interface for editing generated speech after the initial decoding step.
Load-bearing premise
The assumption that the SAE features recovered by the modality-aware auto-interp pipeline are the correct level of abstraction and that the observed steering effects are not accompanied by unmeasured degradations in overall speech quality or coherence.
What would settle it
A controlled listening test in which laughter-directed interventions are applied yet the measured laughter probability remains near baseline or listener ratings of coherence drop measurably.
Figures
read the original abstract
Language models increasingly serve as the backbone of text-to-speech (TTS) systems, yet we understand little about the representations they build when text and generated speech tokens share a single residual stream. We train BatchTopK sparse autoencoders on the LM backbone of CosyVoice3 and introduce a modality-aware auto-interp pipeline that labels each feature from where it fires-text-prefix context, 1-second speech clips, or both. The recovered features are interpretable, spanning phonemes, laughter, accent prompts and speaker gender. Steering through the SAE latent space shows these features are causal rather than merely descriptive: targeted interventions raise laughter probability from 0.02 to 0.79, flip perceived speaker gender, and control speech rate while preserving spoken content. SAE features thus serve both as interpretability objects and as control directions for TTS synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript trains BatchTopK sparse autoencoders on the residual stream of the LM backbone in CosyVoice3. It introduces a modality-aware auto-interp pipeline that labels features according to activation context (text-prefix, 1-second speech clips, or both). The recovered features are interpretable, covering phonemes, laughter, accents, and speaker gender. Steering interventions in the SAE latent space are reported to demonstrate causality, raising laughter probability from 0.02 to 0.79, flipping perceived speaker gender, and controlling speech rate while preserving spoken content. The authors conclude that SAE features function as both interpretability objects and control directions for TTS synthesis.
Significance. If the steering results hold without unmeasured quality trade-offs, the work extends SAE-based interpretability to multimodal TTS LMs and supplies concrete quantitative intervention outcomes (laughter probability shift of 0.02 to 0.79) that could support more precise synthesis control. The modality-aware labeling approach is a methodological contribution for mixed-modality activations.
major comments (2)
- [Abstract] Abstract: The central claim that SAE steering demonstrates causality (rather than mere description) and 'preserves spoken content' is not accompanied by any quantitative post-steering metrics on naturalness, intelligibility, prosody consistency, or coherence (e.g., no MOS, WER, or artifact rates). This is load-bearing for the causality interpretation, because large attribute shifts could be side-effects of general disruption.
- [Results] Results (steering experiments): No baselines or statistical controls are described for the reported effect sizes relative to random latent interventions or non-SAE steering vectors. Without these, it is unclear whether the observed changes (laughter 0.02→0.79, gender flip, rate control) are specifically attributable to the recovered SAE features.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. The comments correctly identify gaps in the quantitative support for our steering claims. We address each point below and commit to revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that SAE steering demonstrates causality (rather than mere description) and 'preserves spoken content' is not accompanied by any quantitative post-steering metrics on naturalness, intelligibility, prosody consistency, or coherence (e.g., no MOS, WER, or artifact rates). This is load-bearing for the causality interpretation, because large attribute shifts could be side-effects of general disruption.
Authors: We agree that the absence of post-intervention metrics on naturalness and content preservation weakens the causality interpretation. In the revised manuscript we will add WER computed via an off-the-shelf ASR model on steered versus baseline utterances, together with human MOS ratings for naturalness and artifact presence. These numbers will be reported for all steering experiments. revision: yes
-
Referee: [Results] Results (steering experiments): No baselines or statistical controls are described for the reported effect sizes relative to random latent interventions or non-SAE steering vectors. Without these, it is unclear whether the observed changes (laughter 0.02→0.79, gender flip, rate control) are specifically attributable to the recovered SAE features.
Authors: The referee is correct that specificity to the learned SAE directions has not been demonstrated. We will add, in the revised results section, (i) steering with random vectors of matched norm, (ii) direct activation patching without the SAE, and (iii) bootstrap or permutation tests comparing the observed effect sizes against these controls. The new tables will quantify how much of the reported attribute change is attributable to the SAE features themselves. revision: yes
Circularity Check
No circularity: empirical intervention study with measured effects
full rationale
The paper trains BatchTopK SAEs on the CosyVoice3 LM backbone, applies a modality-aware auto-interp pipeline to label features, and then performs targeted steering interventions whose effects (laughter probability shift, gender flip, rate control) are directly measured on held-out outputs. No equations, predictions, or uniqueness claims reduce any reported quantity to the SAE training loss or fitted parameters by construction. The central causal claim rests on external empirical measurements rather than self-referential definitions or self-citation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Anthropic, accessed , year=
Scaling and evaluating sparse autoencoders , author=. Anthropic, accessed , year=
-
[3]
OpenAI blog , year=
Language models can explain neurons in language models , author=. OpenAI blog , year=
-
[4]
Automatically Interpreting Millions of Features in Large Language Models , author=. arXiv preprint arXiv:2410.13928 , year=
-
[5]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2 , author=. arXiv preprint arXiv:2408.05147 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Scaling and evaluating sparse autoencoders
Scaling and evaluating sparse autoencoders , author=. arXiv preprint arXiv:2406.04093 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2407.05361 , year=
Emilia: An Extensive, Multilingual, and Diverse Speech Dataset for Large-Scale Speech Generation , author=. arXiv preprint arXiv:2407.05361 , year=
-
[8]
Du, Zhihao and Chen, Qian and Zhang, Shiliang and Hu, Kai and Lu, Heng and Yang, Yexin and Hu, Hangrui and Zheng, Siqi and Gu, Yue and Ma, Ziyang and others , journal=
-
[9]
ASRU , year=
Layer-wise analysis of a self-supervised speech representation model , author=. ASRU , year=
-
[10]
AudioSAE: Towards Understanding of Audio-Processing Models with Sparse AutoEncoders , url=
Aparin, Georgii and Sadekova, Tasnima and Rukhovich, Alexey and Yermekova, Assel and Kushnareva, Laida and Popov, Vadim and Kuznetsov, Kristian and Piontkovskaya, Irina , year=. AudioSAE: Towards Understanding of Audio-Processing Models with Sparse AutoEncoders , url=. doi:10.18653/v1/2026.eacl-long.149 , booktitle=
-
[11]
2024 , institution=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2024 , institution=
2024
-
[12]
and Ellis, Daniel P
Gemmeke, Jort F. and Ellis, Daniel P. W. and Freedman, Dylan and Jansen, Aren and Lawrence, Wade and Moore, R. Channing and Plakal, Manoj and Ritter, Marvin , booktitle=
-
[13]
Gong, Yuan and Chung, Yu-An and Glass, James , booktitle=
-
[14]
ICML , year=
Robust speech recognition via large-scale weak supervision , author=. ICML , year=
-
[15]
Whisper Hallucination Detection and Mitigation via Hidden Representation Steering and Sparse AutoEncoders , author=. arXiv preprint arXiv:2606.07473 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Xie, Tianxin and Yang, Shan and Li, Chenxing and Yu, Dong and Liu, Li , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.