Baseline-Free Policy Optimization for Neural Combinatorial Optimization
Pith reviewed 2026-06-27 13:42 UTC · model grok-4.3
The pith
GRPO trains neural routing policies without a rollout baseline and avoids the collapse seen with REINFORCE on TSP-100.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
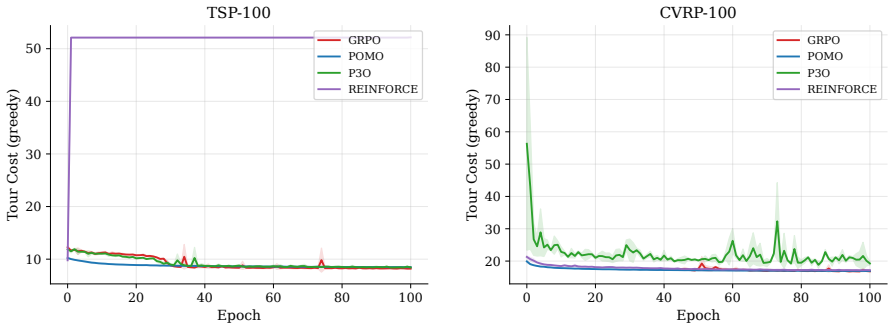
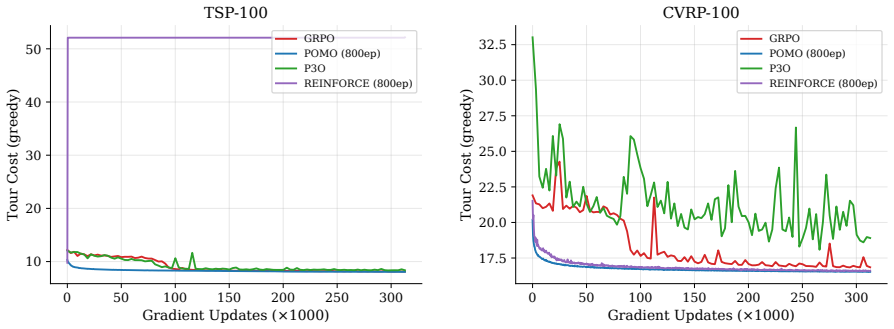
GRPO eliminates the structural vulnerability of rollout baselines by normalizing advantages within groups of trajectories sampled from the current policy, thereby achieving stable training on TSP and CVRP that reaches solution quality within 2 percent of POMO at matched updates without requiring any external baseline.
What carries the argument
Group Relative Policy Optimization (GRPO), which replaces the rollout baseline with within-group normalization of advantages across multiple trajectories drawn from the same policy.
If this is right
- GRPO avoids the immediate performance degradation from cost 9.8 to 52.1 after the warmup phase on TSP-100.
- At matched gradient updates GRPO reaches solution quality within 2 percent of POMO on both TSP and CVRP.
- P3O remains competitive on TSP but exhibits higher variability than GRPO on CVRP.
- Baseline-free normalization can replace rollout-dependent training in neural combinatorial optimization when baseline quality becomes unreliable.
Where Pith is reading between the lines
- Techniques developed for preference alignment in language models can transfer directly to policy optimization in combinatorial search.
- Group normalization may offer a general variance-reduction strategy for high-dimensional discrete action spaces beyond routing problems.
- Removing the requirement to store and periodically refresh a baseline copy simplifies distributed or memory-constrained training pipelines.
Load-bearing premise
Observed differences in stability and final performance are caused by the removal of the rollout baseline rather than by other uncontrolled differences in hyperparameters, instance generation, or implementation details.
What would settle it
GRPO exhibiting the same post-warmup collapse from cost 9.8 to 52.1 on TSP-100, or falling more than 2 percent behind POMO in solution quality, when run under identical conditions and matched gradient updates.
Figures
read the original abstract
Neural combinatorial optimization (NCO) trains autoregressive policies to solve routing problems. The standard training algorithm, REINFORCE with a rollout baseline, requires maintaining and periodically updating a frozen copy of the policy for variance reduction. This baseline introduces a structural vulnerability: on harder instances, a poor baseline produces noisy gradient estimates that can destabilize training. We evaluate Group Relative Policy Optimization (GRPO), an algorithm from large language model alignment that eliminates the baseline entirely by normalizing advantages within groups of sampled trajectories. In a controlled comparison of five RL algorithms on TSP and CVRP benchmarks within the RL4CO framework, we find that: (i) GRPO avoids the training collapse observed with REINFORCE on TSP-100, where performance degrades from cost 9.8 to 52.1 immediately after the warmup phase and does not recover under extended training; (ii) at matched gradient updates, GRPO achieves solution quality within 2% of POMO, a strong AM-based multi-start baseline, while requiring no external baseline; and (iii) P3O, a pairwise preference algorithm also from the alignment literature, is competitive on TSP but shows higher variability on CVRP. These results identify GRPO as a promising baseline-free alternative for NCO, particularly in settings where baseline-dependent training becomes fragile.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates Group Relative Policy Optimization (GRPO) as a baseline-free alternative to REINFORCE with rollout baseline for training autoregressive policies in neural combinatorial optimization on TSP and CVRP instances. It reports that GRPO avoids the post-warmup collapse seen with REINFORCE on TSP-100 (cost rising from 9.8 to 52.1), reaches solution quality within 2% of POMO at matched gradient updates, and that P3O is competitive on TSP but more variable on CVRP, all within a controlled comparison of five RL algorithms inside the RL4CO framework.
Significance. If the stability and performance claims hold under properly controlled conditions, the work supplies a concrete, baseline-free training option that could simplify NCO pipelines and reduce fragility on harder instances. The direct empirical head-to-head against REINFORCE, POMO, and P3O is a useful contribution; the absence of any invented parameters or circular derivations is also a strength.
major comments (2)
- [§4] §4 (Experiments) and the abstract: the claim of a 'controlled comparison' is load-bearing for the central attribution that GRPO's stability advantage stems from eliminating the rollout baseline. The text does not report whether REINFORCE was re-tuned to its own optimal hyperparameters, whether identical random seeds, batch sizes, gradient accumulation steps, and instance sampling procedures were used across all five algorithms, or whether the collapse is reproducible under alternative RL4CO configurations. Without these controls the causal link remains unverified.
- [Table 2, Figure 3] Table 2 and Figure 3 (TSP-100 results): the reported degradation from cost 9.8 to 52.1 for REINFORCE and the within-2% claim for GRPO versus POMO are presented without error bars, standard deviations across seeds, or statistical tests. This weakens the ability to assess whether the observed differences are reliable or could be explained by run-to-run variance.
minor comments (2)
- [§4] The experimental protocol paragraph in §4 should explicitly list the full hyperparameter grids searched for each algorithm and the final values used, to allow reproduction.
- [Figure 3] Figure captions and axis labels should state the exact number of gradient updates and the batch size used for the 'matched gradient updates' comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental controls and statistical reporting. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and the abstract: the claim of a 'controlled comparison' is load-bearing for the central attribution that GRPO's stability advantage stems from eliminating the rollout baseline. The text does not report whether REINFORCE was re-tuned to its own optimal hyperparameters, whether identical random seeds, batch sizes, gradient accumulation steps, and instance sampling procedures were used across all five algorithms, or whether the collapse is reproducible under alternative RL4CO configurations. Without these controls the causal link remains unverified.
Authors: All experiments were executed inside the RL4CO framework, which enforces identical random seeds, batch sizes, gradient accumulation steps, and instance sampling across the five algorithms via a shared training loop and data pipeline. Hyperparameters followed the original papers and RL4CO defaults to preserve a standardized comparison rather than per-algorithm tuning. We did not evaluate alternative RL4CO configurations. The revised §4 will explicitly document these controls and hyperparameter choices. revision: partial
-
Referee: [Table 2, Figure 3] Table 2 and Figure 3 (TSP-100 results): the reported degradation from cost 9.8 to 52.1 for REINFORCE and the within-2% claim for GRPO versus POMO are presented without error bars, standard deviations across seeds, or statistical tests. This weakens the ability to assess whether the observed differences are reliable or could be explained by run-to-run variance.
Authors: We agree that error bars, standard deviations across seeds, and statistical tests would strengthen reliability assessment. In revision we will rerun with multiple seeds and update Table 2 and Figure 3 to report means and standard deviations. revision: yes
Circularity Check
No circularity; purely empirical comparison
full rationale
The manuscript reports benchmark results from running five RL algorithms (including GRPO and REINFORCE) inside the RL4CO framework on TSP/CVRP instances. No equations, derivations, or first-principles predictions appear; performance claims rest on measured costs and stability observations that are externally falsifiable against the same public benchmarks. No self-citation chains, fitted parameters renamed as predictions, or ansatzes are invoked to support any result. This is the normal case of an empirical methods paper whose central claims do not reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The RL4CO framework supplies equivalent and unbiased implementations of the compared algorithms apart from the baseline mechanism.
Reference graph
Works this paper leans on
-
[1]
Attention, Learn to Solve Routing Problems!
W. Kool, H. V. Hoof, and M. Welling, “Attention, learn to solve routing problems!”arXiv preprint arXiv:1803.08475, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
RL4CO: an extensive reinforcement learning for combinatorial optimization benchmark,
F. Berto, C. Hua, J. Park, L. Luttmann, Y. Ma, F. Bu, J. Wang, H. Ye, M. Kim, S. Choiet al., “RL4CO: an extensive reinforcement learning for combinatorial optimization benchmark,” in Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2, 2025, pp. 5278–5289
2025
-
[3]
Simple statistical gradient-following algorithms for connectionist reinforce- ment learning,
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforce- ment learning,”Machine learning, vol. 8, no. 3, pp. 229–256, 1992
1992
-
[4]
POMO: Policy optimization with multiple optima for reinforcement learning,
Y.-D. Kwon, J. Choo, B. Kim, I. Yoon, Y. Gwon, and S. Min, “POMO: Policy optimization with multiple optima for reinforcement learning,”Advances in Neural Information Processing Systems, vol. 33, pp. 21 188–21 198, 2020
2020
-
[5]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Liet al., “Deepseek- Math: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
arXiv preprint arXiv:2310.00212 , year=
T. Wu, B. Zhu, R. Zhang, Z. Wen, K. Ramchandran, and J. Jiao, “Pairwise proximal policy op- timization: Harnessing relative feedback for llm alignment,”arXiv preprint arXiv:2310.00212, 9 2023
-
[7]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimiza- tion algorithms,”arXiv preprint arXiv:1707.06347, 7 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Graph reinforcement learning for combinatorial optimization: A survey and unifying perspective,
V.-A. Darvariu, S. Hailes, and M. Musolesi, “Graph reinforcement learning for combinatorial optimization: A survey and unifying perspective,”arXiv preprint arXiv:2404.06492, 2024
-
[9]
Pointer networks,
O. Vinyals, M. Fortunato, and N. Jaitly, “Pointer networks,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[10]
Neural combinatorial optimization with reinforcement learning,
I. Bello, H. Pham, Q. V. Le, M. Norouzi, and S. Bengio, “Neural combinatorial optimization with reinforcement learning,”5th International Conference on Learning Representations, ICLR 2017 - Workshop Track Proceedings, 11 2016
2017
-
[11]
Reinforcement learning for solving the vehicle routing problem,
M. Nazari, A. Oroojlooy, M. Tak´ aˇ c, and L. V. Snyder, “Reinforcement learning for solving the vehicle routing problem,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[12]
Reinforcement learning with combinato- rial actions: An application to vehicle routing,
A. Delarue, R. Anderson, and C. Tjandraatmadja, “Reinforcement learning with combinato- rial actions: An application to vehicle routing,”Advances in Neural Information Processing Systems, vol. 33, pp. 609–620, 2020. 9
2020
-
[13]
Deep reinforcement learning for solving the heterogeneous capacitated vehicle routing problem,
J. Li, Y. Ma, R. Gao, Z. Cao, A. Lim, W. Song, and J. Zhang, “Deep reinforcement learning for solving the heterogeneous capacitated vehicle routing problem,”IEEE Transactions on Cybernetics, vol. 54, pp. 13 572–13 585, 10 2021
2021
-
[14]
Multi-decoder attention model with embedding glimpse for solving vehicle routing problems,
L. Xin, W. Song, Z. Cao, and J. Zhang, “Multi-decoder attention model with embedding glimpse for solving vehicle routing problems,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 13, 2021, pp. 12 042–12 049
2021
-
[15]
A survey on coverage path planning for robotics,
E. Galceran and M. Carreras, “A survey on coverage path planning for robotics,”Robotics and Autonomous systems, vol. 61, pp. 1258–1276, 2013
2013
-
[16]
Surveillance planning with b´ ezier curves,
J. Faigl and P. Vana, “Surveillance planning with b´ ezier curves,”IEEE Robotics and Automa- tion Letters, vol. 3, pp. 750–757, 4 2018
2018
-
[17]
Riverine coverage with an autonomous surface vehicle over known environments,
N. Karapetyan, A. Braude, J. Moulton, J. A. Burstein, S. White, J. M. O’Kane, and I. Rek- leitis, “Riverine coverage with an autonomous surface vehicle over known environments,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 3098–3104
2019
-
[18]
Fields2cover: An open-source coverage path planning library for unmanned agricultural vehicles,
G. Mier, J. Valente, and S. D. Bruin, “Fields2cover: An open-source coverage path planning library for unmanned agricultural vehicles,”IEEE Robotics and Automation Letters, vol. 8, pp. 2166–2172, 2023
2023
-
[19]
Deep r-learning for continual area sweeping,
R. Shah, Y. Jiang, J. Hart, and P. Stone, “Deep r-learning for continual area sweeping,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 5 2020, pp. 5542–5547
2020
-
[20]
Learning coverage paths in unknown environments with deep reinforcement learning,
A. Jonnarth, J. Zhao, and M. Felsberg, “Learning coverage paths in unknown environments with deep reinforcement learning,” inInternational Conference on Machine Learning. PMLR, 2024, pp. 22 491–22 508
2024
-
[21]
Preference optimization for combinatorial optimization problems,
M. Pan, G. Lin, Y.-W. Luo, B. Zhu, Z. Dai, L. Sun, and C. Yuan, “Preference optimization for combinatorial optimization problems,”arXiv preprint arXiv:2505.08735, 2025
-
[22]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017. 10
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.