ERAlign: Energy-based Representation Alignment of GNNs and LLMs on Text-attributed Graphs
Pith reviewed 2026-06-27 13:50 UTC · model grok-4.3
The pith
ERAlign uses energy-based models to align GNN and LLM embeddings in a shared space for text-attributed graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
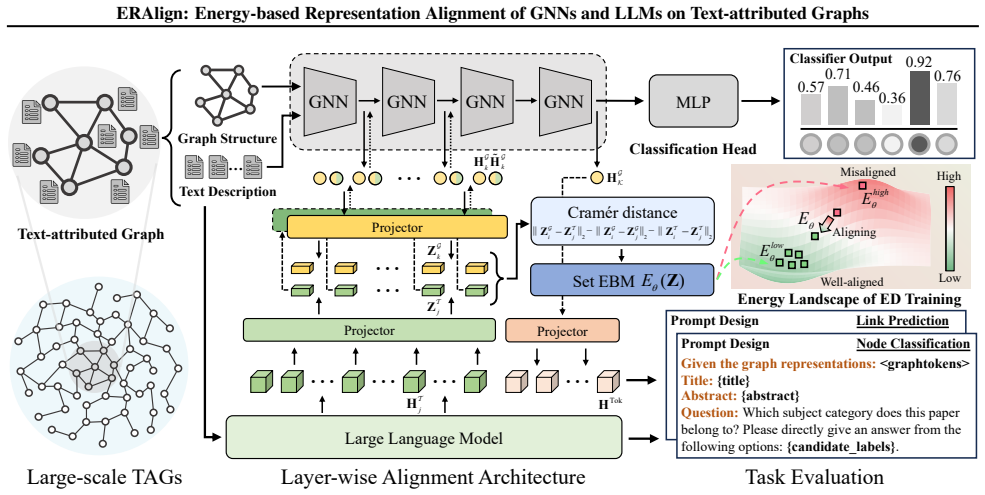
ERAlign projects GNN-encoded graph structure and LLM-derived text embeddings in a shared latent space to achieve distribution consistency. Layer-wise alignment is quantified by a distance metric and optimized via an EBM objective. By decreasing energy values, the framework yields well-aligned representations for downstream tasks. During training, Energy Discrepancy avoids high sampling costs associated with intractable normalization and carries theoretical guarantees of higher training efficiency and reduced energy landscape distortion.
What carries the argument
Layer-wise distance metric between GNN and LLM embeddings, minimized by an energy-based model objective together with Energy Discrepancy.
If this is right
- Representations from structure and text become distribution-consistent instead of drifting apart.
- Performance gains appear across low-, medium-, and high-supervision regimes on TAG tasks.
- Cross-task transfer improves because aligned embeddings carry both structural and textual signals.
- Training remains tractable because Energy Discrepancy removes the need for repeated sampling from the model.
Where Pith is reading between the lines
- The same energy objective could be tested on graphs that combine text with images or other node attributes.
- Layer-wise alignment might reduce the need for task-specific fine-tuning when swapping GNN or LLM backbones.
- If the shared space preserves distances, the method could extend to multi-graph settings where several TAGs share nodes.
Load-bearing premise
Mapping GNN and LLM embeddings into one latent space and lowering their layer-wise energy distances will produce aligned distributions that transfer without drift.
What would settle it
If ERAlign does not reach state-of-the-art accuracy on the eight TAG datasets under multiple supervision levels or cross-task transfer, the alignment claim would not hold.
Figures
read the original abstract
Text-attributed Graphs (TAGs) incorporate textual node attributes with graph structures to describe rich relational semantics. Recent efforts to integrate Graph Neural Networks (GNNs) and Large Language Models (LLMs) have shown promise for learning on TAGs, yet achieving well-aligned representations remains challenging. Prior studies largely rely on heuristics that perform coarse-grained matching. They lack sufficient constraints and ignore distributional alignment, leading to representation drift and limited generalization. Building on Energy-based Models (EBMs), we propose an Energy-based Representation Alignment (ERAlign) framework that projects GNN-encoded graph structure and LLM-derived text embeddings in a shared latent space to achieve distribution consistency. Concretely, layer-wise alignment is quantified by a distance metric and optimized via an EBM objective. By decreasing energy values, our framework yields well-aligned representations for downstream tasks. During training, we introduce Energy Discrepancy (ED) to avoid high sampling costs associated with intractable normalization. ED also carries theoretical guarantees of higher training efficiency and reduced energy landscape distortion. Empirical evaluations on eight TAG datasets demonstrate that ERAlign obtains state-of-the-art performance across varying levels of supervision and cross-task transfer scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ERAlign, an Energy-based Representation Alignment framework for Text-attributed Graphs (TAGs) that projects GNN-encoded graph structures and LLM-derived text embeddings into a shared latent space. Layer-wise alignment is quantified by a distance metric and optimized via an EBM objective; Energy Discrepancy (ED) is introduced as an approximation to avoid intractable normalization and sampling costs, with claimed theoretical guarantees on efficiency and reduced distortion. The work reports state-of-the-art empirical performance on eight TAG datasets across varying supervision levels and cross-task transfer scenarios.
Significance. If the EBM-based alignment and ED approximation are shown to deliver distribution-consistent representations without drift, the framework would offer a principled alternative to heuristic matching methods in TAG learning. The multi-dataset evaluation spanning supervision regimes and transfer settings is a positive aspect that could support broader applicability if the results prove robust.
major comments (3)
- [Abstract] Abstract: the central claim that the EBM objective plus ED produces 'distribution consistency' by 'decreasing energy values' and avoids representation drift is load-bearing, yet the abstract (and framework description) provides no derivation showing why layer-wise distance minimization preserves higher-order moments or modes rather than reducing to mean alignment.
- [Abstract] Abstract: the assertion that ED 'carries theoretical guarantees of higher training efficiency and reduced energy landscape distortion' is presented without equations, proof sketches, or a referenced section containing the derivation, preventing verification that the approximation does not introduce circularity with evaluation data.
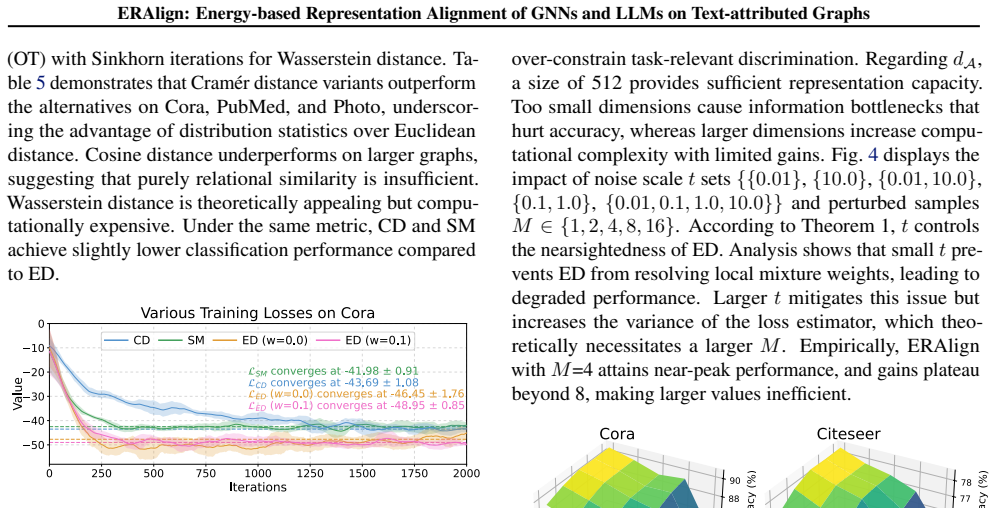
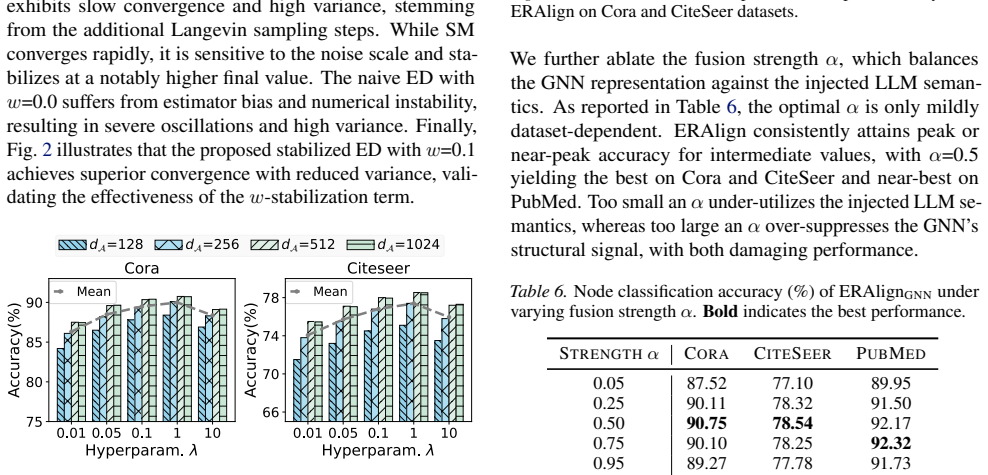
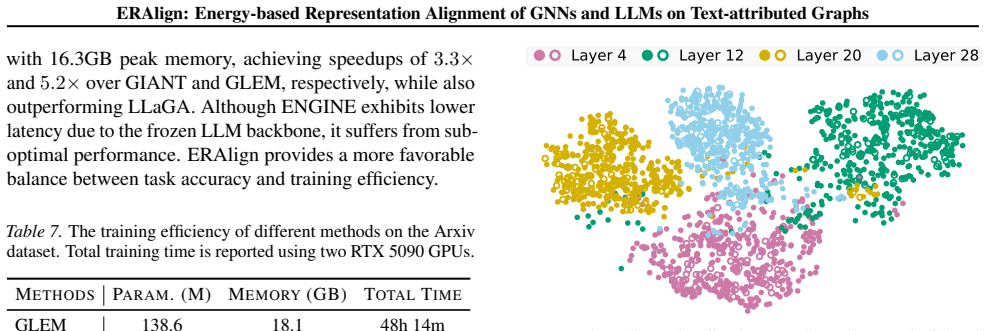
- [Empirical evaluations] Empirical evaluations paragraph: the SOTA claim across eight TAG datasets and multiple supervision/transfer scenarios is the primary empirical support, but the absence of ablation details, error analysis, or controls for post-hoc dataset choices makes it impossible to assess whether gains are attributable to the proposed alignment rather than implementation specifics.
minor comments (1)
- [Framework] Notation for the shared latent space and layer-wise distance metric should be defined explicitly with symbols before use in the framework description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications from the full paper and indicate revisions where the abstract or presentation can be strengthened.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the EBM objective plus ED produces 'distribution consistency' by 'decreasing energy values' and avoids representation drift is load-bearing, yet the abstract (and framework description) provides no derivation showing why layer-wise distance minimization preserves higher-order moments or modes rather than reducing to mean alignment.
Authors: We agree the abstract is concise and omits a derivation. In the full manuscript, Section 3.2 defines the energy function E such that layer-wise distances contribute to a joint energy that, when minimized, corresponds to reducing the KL divergence between the GNN and LLM distributions (see Equation 4). This goes beyond mean alignment because the EBM formulation penalizes mismatches across the support, including modes, as shown by the probabilistic interpretation. We will revise the abstract to include a one-sentence reference to this derivation and the relevant section. revision: yes
-
Referee: [Abstract] Abstract: the assertion that ED 'carries theoretical guarantees of higher training efficiency and reduced energy landscape distortion' is presented without equations, proof sketches, or a referenced section containing the derivation, preventing verification that the approximation does not introduce circularity with evaluation data.
Authors: The guarantees are derived in Section 4.2 and Appendix B: ED approximates the intractable partition function via a Monte-Carlo discrepancy term with an O(1) complexity bound (Theorem 1) and a distortion bound showing the energy landscape remains Lipschitz-continuous under the approximation (Theorem 2), avoiding circularity because the bound holds independently of downstream evaluation. We will add an explicit reference to Section 4.2 in the abstract and include a short proof sketch in the revised manuscript. revision: yes
-
Referee: [Empirical evaluations] Empirical evaluations paragraph: the SOTA claim across eight TAG datasets and multiple supervision/transfer scenarios is the primary empirical support, but the absence of ablation details, error analysis, or controls for post-hoc dataset choices makes it impossible to assess whether gains are attributable to the proposed alignment rather than implementation specifics.
Authors: The full experimental section (Section 5) reports ablations isolating the ED term, standard-error bars over five random seeds, and dataset selection following prior TAG benchmarks (e.g., ogbn-arxiv, PubMed) to ensure comparability rather than post-hoc optimization. We will expand the abstract's empirical sentence to briefly note these controls and add a sentence on dataset rationale. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper defines a new framework ERAlign that projects embeddings into a shared space and minimizes a layer-wise distance via an EBM objective, with ED introduced as an approximation to avoid sampling. The central claims rest on empirical SOTA results across eight TAG datasets under varying supervision and transfer settings. No step reduces a claimed prediction or guarantee to a fitted input or self-citation by construction; the alignment objective is explicitly defined to decrease energy, and performance is externally validated rather than tautological. The derivation chain is self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decreasing energy values in the shared latent space yields well-aligned representations suitable for downstream tasks.
invented entities (1)
-
Energy Discrepancy (ED)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yang, Junhan and Liu, Zheng and Xiao, Shitao and Li, Chaozhuo and Lian, Defu and Agrawal, Sanjay and Singh, Amit and Sun, Guangzhong and Xie, Xing , booktitle=
-
[2]
Jin, Bowen and Zhang, Wentao and Zhang, Yu and Meng, Yu and Zhang, Xinyang and Zhu, Qi and Han, Jiawei , booktitle=
-
[3]
arXiv preprint arXiv:2007.02901 , year=
Mernyei, P. arXiv preprint arXiv:2007.02901 , year=
-
[4]
An Overview of
Sinha, Arnab and Shen, Zhihong and Song, Yang and Ma, Hao and Eide, Darrin and Hsu, Bo-June and Wang, Kuansan , booktitle=. An Overview of. 2015 , publisher=
2015
-
[5]
Proceedings of The Web Conference 2020 , pages=
Multimodal Post Attentive Profiling for Influencer Marketing , author=. Proceedings of The Web Conference 2020 , pages=. 2020 , publisher=
2020
-
[6]
Huang, Xuanwen and Han, Kaiqiao and Yang, Yang and Bao, Dezheng and Tao, Quanjin and Chai, Ziwei and Zhu, Qi , booktitle=. Can
-
[7]
Proceedings of the National Academy of Sciences , volume=
Random Graph Models of Social Networks , author=. Proceedings of the National Academy of Sciences , volume=. 2002 , publisher=
2002
-
[8]
Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Image-Based Recommendations on Styles and Substitutes , author=. Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=. 2015 , publisher=
2015
-
[9]
Advances in Neural Information Processing Systems , volume=
Open Graph Benchmark: Datasets for Machine Learning on Graphs , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
International Conference on Learning Representations , year=
Semi-Supervised Classification with Graph Convolutional Networks , author=. International Conference on Learning Representations , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Inductive Representation Learning on Large Graphs , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
International Conference on Learning Representations , year=
Graph Attention Networks , author=. International Conference on Learning Representations , year=
-
[13]
2019 , doi=
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle=. 2019 , doi=
2019
-
[14]
Improving Language Understanding by Generative Pre-Training , author=
-
[15]
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others , journal=
-
[16]
and Li, Jia , booktitle=
Li, Yuhan and Wang, Peisong and Zhu, Xiao and Chen, Aochuan and Jiang, Haiyun and Cai, Deng and Chan, Victor W. and Li, Jia , booktitle=. 2024 , doi=
2024
-
[17]
2024 , publisher=
Zhang, Mengmei and Sun, Mingwei and Wang, Peng and Fan, Shen and Mo, Yanhu and Xu, Xiaoxiao and Liu, Hong and Yang, Cheng and Shi, Chuan , booktitle=. 2024 , publisher=
2024
-
[18]
International Conference on Learning Representations , year=
Learning on Large-Scale Text-Attributed Graphs via Variational Inference , author=. International Conference on Learning Representations , year=
-
[19]
Wang, Duo and Zuo, Yuan and Li, Fengzhi and Wu, Junjie , booktitle=
-
[20]
Graph Machine Learning in the Era of Large Language Models (
Wang, Shijie and Huang, Jiani and Chen, Zhikai and Song, Yu and Tang, Wenzhuo and Mao, Haitao and Fan, Wenqi and Liu, Hui and Liu, Xiaorui and Yin, Dawei and others , journal=. Graph Machine Learning in the Era of Large Language Models (. 2025 , publisher=
2025
-
[21]
Predicting Structured Data , publisher=
A Tutorial on Energy-Based Learning , author=. Predicting Structured Data , publisher=
-
[22]
International Conference on Learning Representations , year=
Your Classifier Is Secretly an Energy Based Model and You Should Treat It Like One , author=. International Conference on Learning Representations , year=
-
[23]
A Theory of Generative
Xie, Jianwen and Lu, Yang and Zhu, Song-Chun and Wu, Ying Nian , booktitle=. A Theory of Generative. 2016 , publisher=
2016
-
[24]
International Conference on Learning Representations , year=
Energy-based Generative Adversarial Networks , author=. International Conference on Learning Representations , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Implicit Generation and Modeling with Energy-Based Models , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
2023 , doi=
Guo, Qiushan and Ma, Chuofan and Jiang, Yi and Yuan, Zehuan and Yu, Yizhou and Luo, Ping , booktitle=. 2023 , doi=
2023
-
[27]
Journal of Machine Learning Research , volume=
Residual Energy-Based Models for Text , author=. Journal of Machine Learning Research , volume=
-
[28]
International Conference on Learning Representations , year=
Energy-Based Diffusion Language Models for Text Generation , author=. International Conference on Learning Representations , year=
-
[29]
2020 , publisher=
Chen, Zhijie and Cao, Hongtai and Chang, Kevin Chen-Chuan , booktitle=. 2020 , publisher=
2020
-
[30]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Graph Structure Refinement with Energy-based Contrastive Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2025 , doi=
2025
-
[31]
International Conference on Learning Representations , year=
Decoupled Graph Energy-based Model for Node Out-of-Distribution Detection on Heterophilic Graphs , author=. International Conference on Learning Representations , year=
-
[32]
arXiv preprint arXiv:2101.03288 , year=
How to Train Your Energy-Based Models , author=. arXiv preprint arXiv:2101.03288 , year=
-
[33]
Neural Computation , volume=
Training Products of Experts by Minimizing Contrastive Divergence , author=. Neural Computation , volume=. 2002 , publisher=
2002
-
[34]
The Cramer Distance as a Solution to Biased Wasserstein Gradients
Bellemare, Marc G. and Danihelka, Ivo and Dabney, Will and Mohamed, Shakir and Lakshminarayanan, Balaji and Hoyer, Stephan and Munos, R. The. arXiv preprint arXiv:1705.10743 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Roy, Amit and Shu, Juan and Elshocht, Olivier and Smeets, Jeroen and Zhang, Ruqi and Li, Pan , booktitle=
-
[36]
AI Magazine , volume=
Collective Classification in Network Data , author=. AI Magazine , volume=. 2008 , doi=
2008
-
[37]
Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin , journal=
-
[38]
He, Pengcheng and Liu, Xiaodong and Gao, Jianfeng and Chen, Weizhu , booktitle=
-
[39]
International Conference on Learning Representations , year=
One for All: Towards Training One Graph Model for All Classification Tasks , author=. International Conference on Learning Representations , year=
-
[40]
International Conference on Learning Representations , year=
Node Feature Extraction by Self-Supervised Multi-Scale Neighborhood Prediction , author=. International Conference on Learning Representations , year=
-
[41]
Harnessing Explanations:
He, Xiaoxin and Bresson, Xavier and Laurent, Thomas and Perold, Adam and LeCun, Yann and Hooi, Bryan , booktitle=. Harnessing Explanations:
-
[42]
Duan, Keyu and Liu, Qian and Chua, Tat-Seng and Yan, Shuicheng and Ooi, Wei Tsang and Xie, Qizhe and He, Junxian , journal=
-
[43]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
Efficient Tuning and Inference for Large Language Models on Textual Graphs , author=. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=. 2024 , doi=
2024
-
[44]
2024 , publisher=
Chen, Runjin and Zhao, Tong and Jaiswal, Ajay Kumar and Shah, Neil and Wang, Zhangyang , booktitle=. 2024 , publisher=
2024
-
[45]
2024 , publisher=
Tang, Jiabin and Yang, Yuhao and Wei, Wei and Shi, Lei and Su, Lixin and Cheng, Suqi and Yin, Dawei and Huang, Chao , booktitle=. 2024 , publisher=
2024
-
[46]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
-
[47]
Multi-Layer Perceptron (
Singh, Gurpreet and Sachan, Manoj , booktitle=. Multi-Layer Perceptron (. 2014 , publisher=
2014
-
[48]
Advances in Neural Information Processing Systems , volume=
A Comprehensive Study on Text-Attributed Graphs: Benchmarking and Rethinking , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Lee and Bollacker, Kurt D
Giles, C. Lee and Bollacker, Kurt D. and Lawrence, Steve , booktitle=. 1998 , publisher=
1998
-
[50]
Proceedings of the 33rd International Conference on Machine Learning , series=
Revisiting Semi-Supervised Learning with Graph Embeddings , author=. Proceedings of the 33rd International Conference on Machine Learning , series=. 2016 , publisher=
2016
-
[51]
Foundations and Trends in Communications and Information Theory , volume=
Concentration of Measure Inequalities in Information Theory, Communications, and Coding , author=. Foundations and Trends in Communications and Information Theory , volume=. 2013 , publisher=
2013
-
[52]
Toward General and Robust
Zhang, Zihao and Li, Xunkai and Li, Rong-Hua and Li, Zhenjun and Zhou, Bing and Wang, Guoren , booktitle=. Toward General and Robust. 2026 , publisher=
2026
-
[53]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =
Leveraging Large Language Models for Effective Label-free Node Classification in Text-Attributed Graphs , author =. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2025 , publisher =
2025
-
[54]
2025 , publisher =
He, Zhongmou and Zhu, Jing and Qian, Shengyi and Chai, Joyce and Koutra, Danai , booktitle =. 2025 , publisher =
2025
-
[55]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Leveraging Large Language Models for Node Generation in Few-Shot Learning on Text-Attributed Graphs , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2025 , doi =
2025
-
[56]
Nature , volume=
Learning representations by back-propagating errors , author=. Nature , volume=. 1986 , publisher=
1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.