Achieving Cloud-Grade SLOs for Local Mixture-of-Experts Inference through CPU-GPU Hybrid Design
Pith reviewed 2026-06-27 12:05 UTC · model grok-4.3
The pith
A CPU-GPU hybrid system delivers cloud-grade SLOs for local full-precision MoE inference on consumer hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
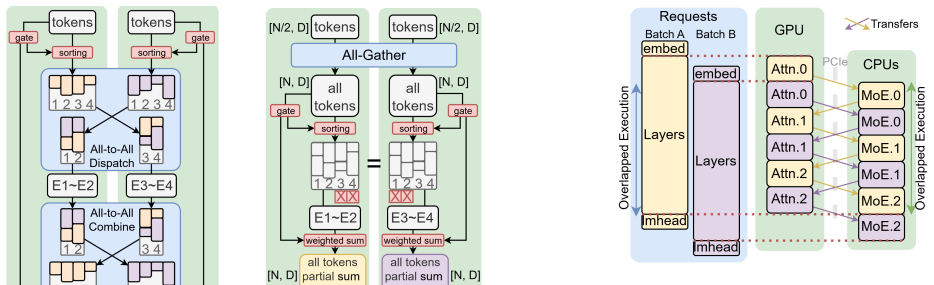
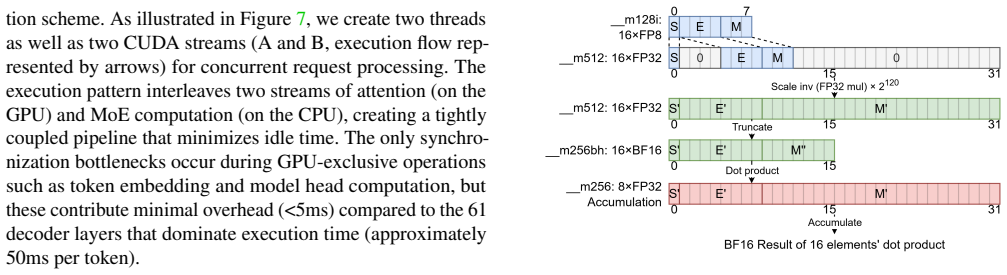
The authors establish that stream-loading prefill, distributed SLP with SmallEP parallelism, intra-node prefill-decode disaggregation using zero-copy shared weights and dual-batch overlap, an AVX-512 FP8 GEMV kernel, and fine-grained CPU parallelism together enable 30-second TTFT for prompts up to 45K tokens and decode rates of 21.5 tokens per second on intact FP8 DeepSeek-V3 using only dual-socket commodity CPUs and consumer GPUs.
What carries the argument
Intra-node prefill-decode disaggregation with zero-copy shared weights and stream-loading prefill, which separates the phases and overlaps attention-MoE computation to sustain concurrency without extra memory movement.
If this is right
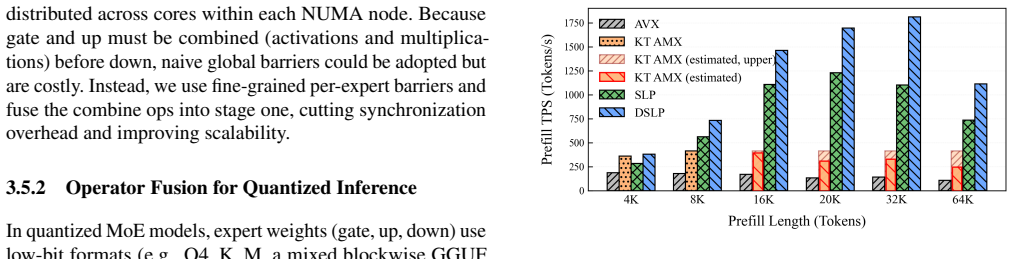
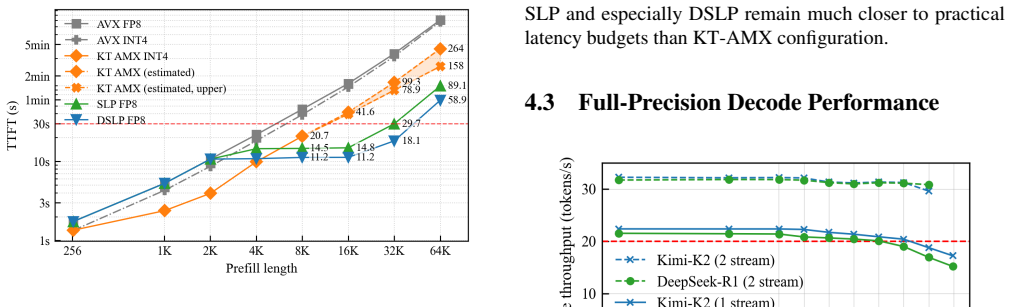
- Prefill reaches 1200 tokens per second on single-GPU setups and 1800 on two GPUs, supporting 32K-45K prompts inside the 30-second TTFT limit.
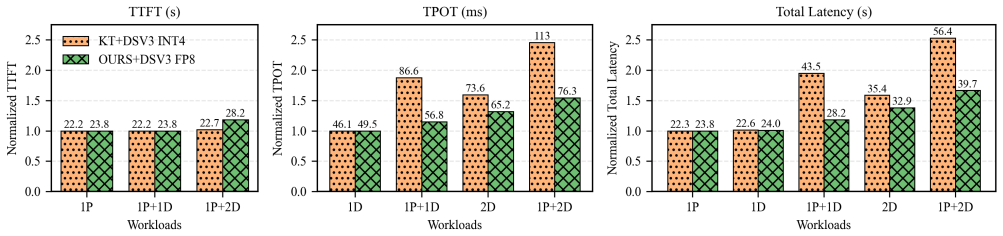
- Mixed prefill-decode and batched decode workloads sustain concurrency with under 15 percent latency increase and 50 percent throughput improvement.
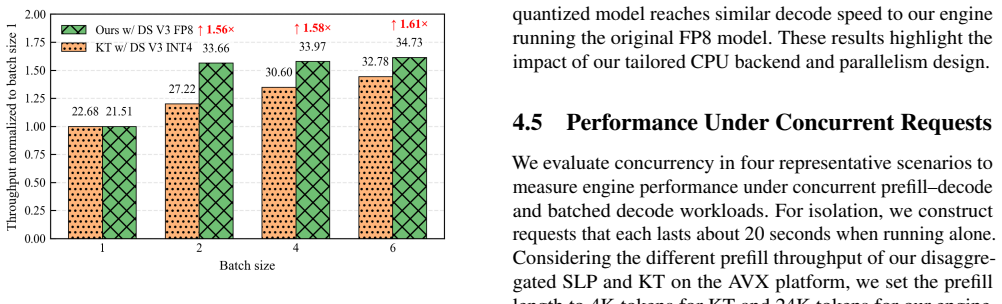
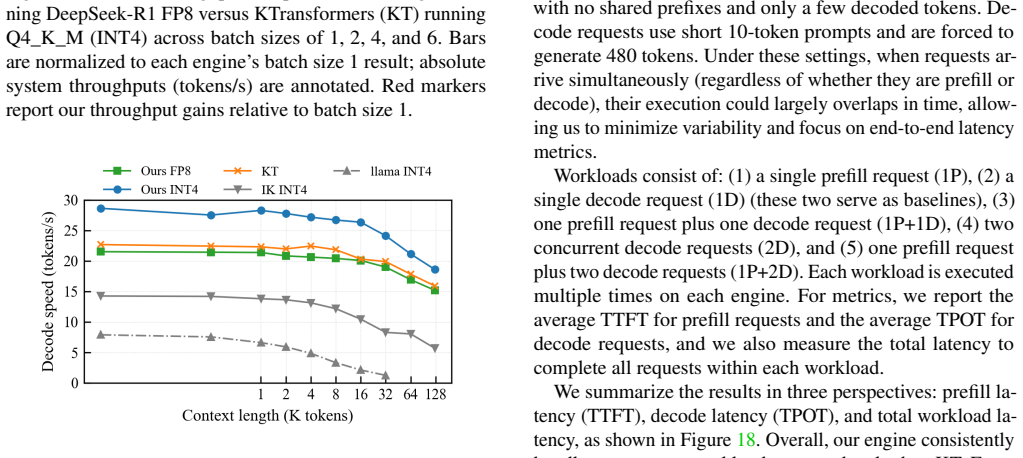
- Native CPU FP8 inference via the AVX-512 GEMV kernel cuts CPU latency by 4-5 times and reaches 28 tokens per second on INT4 DeepSeek-V3.
- Full original-precision inference becomes feasible on consumer platforms without datacenter infrastructure.
Where Pith is reading between the lines
- The same phase-separation and zero-copy sharing approach could be tested on non-MoE dense models to check whether the concurrency gains generalize.
- Consumer hardware vendors might prioritize better CPU-GPU memory sharing interfaces if the zero-copy benefit proves decisive.
- Applications that currently route to cloud endpoints for latency reasons could shift to local execution if the measured SLOs hold under real user traffic.
Load-bearing premise
The listed techniques can be implemented on dual-socket commodity CPUs and consumer GPUs without hidden overheads that would violate the stated SLOs.
What would settle it
A direct measurement on the target dual-socket CPU plus consumer GPU hardware showing that TTFT for a 12K-token prompt exceeds 30 seconds or decode throughput falls below 20 tokens per second under mixed prefill-decode workloads.
Figures
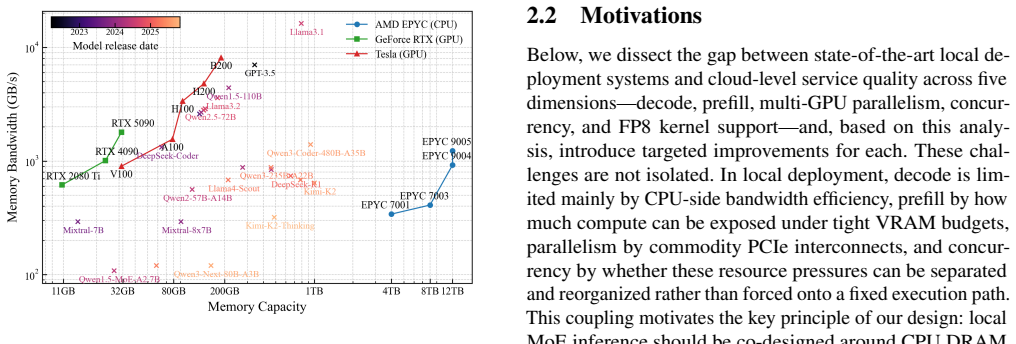
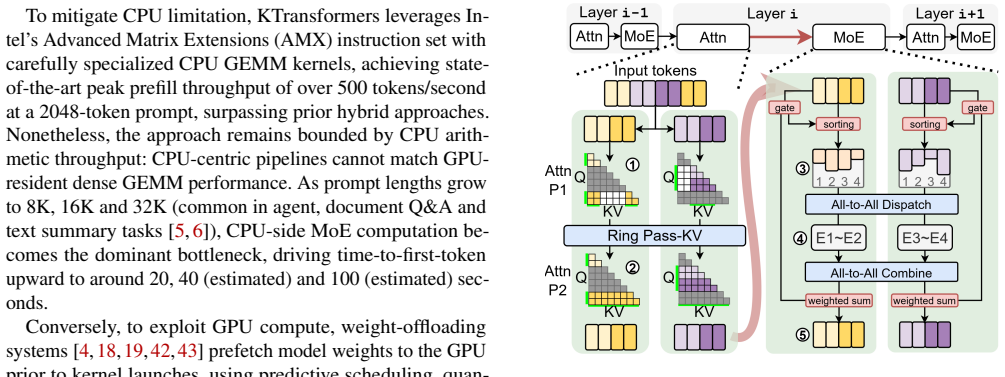
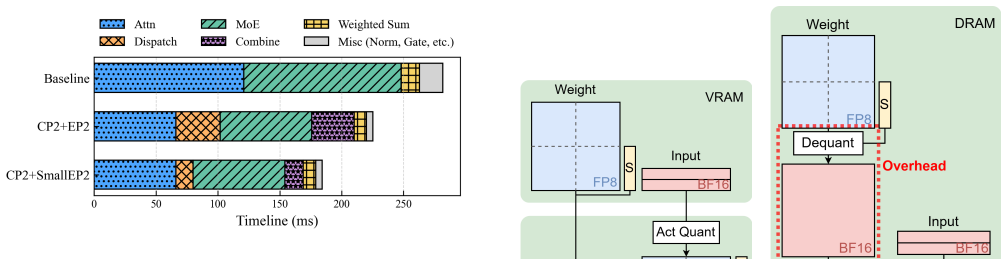
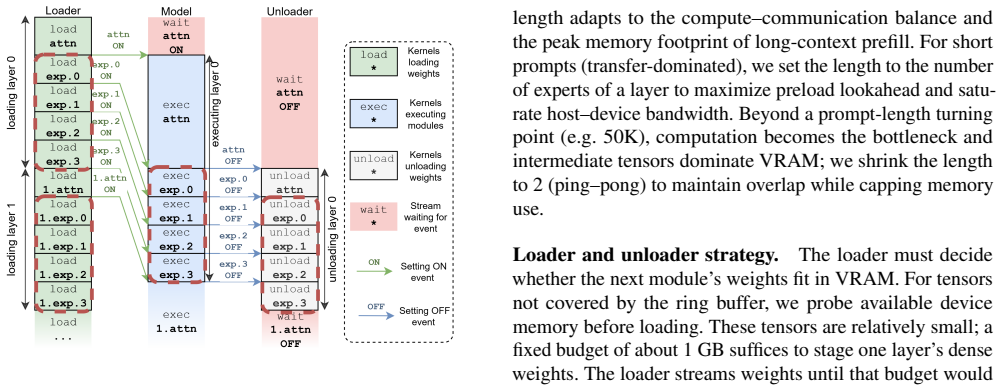


read the original abstract
Local deployment of large Mixture-of-Experts (MoE) models falls short of the service quality achieved in cloud-scale environments, even under low-concurrency workloads. We identify four key gaps in local MoE inference: reliance on capacity-reduced models (quantized, distilled, rerouted), inability to meet 30-second TTFT for long prefills (more than 12K), sub-baseline decode throughput (under 20 tokens/s), and poor concurrency under mixed prefill-decode and batched decode workloads. We present a CPU-GPU hybrid system that achieves cloud-level SLOs on dual-socket commodity CPUs and consumer GPUs by (1) stream-loading prefill (SLP), boosting prefill throughput to 1,200 tokens/s and enabling 32K prompts within 30 seconds; (2) distributed SLP (DSLP) with SmallEP expert parallelism, reaching 1,800 tokens/s and 45K prompts in 30 seconds on two RTX 5090s; (3) intra-node prefill-decode disaggregation with zero-copy shared weights and a dual-batch attention-MoE overlap scheme, sustaining concurrency with under 15 percent latency increase and 50 percent throughput gains; (4) an AVX-512-optimized FP8 GEMV kernel, enabling native CPU FP8 inference while delivering 4-5x lower CPU latency; and (5) fine-grained CPU parallelism that attains 28 tokens/s on INT4 DeepSeek-V3 and 21.5 tokens/s on intact FP8 V3. Evaluations show our system delivers cloud-level QoS for flagship MoE models on consumer CPU-GPU platforms, reshaping local deployment with intact, original-precision inference and enabling high-quality, cost-effective access without datacenter infrastructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a CPU-GPU hybrid system using stream-loading prefill (SLP), distributed SLP with SmallEP expert parallelism, intra-node prefill-decode disaggregation with zero-copy shared weights and dual-batch overlap, plus an AVX-512 FP8 GEMV kernel, can deliver cloud-grade SLOs (30 s TTFT for >12 K prompts, 28/21.5 tokens/s decode, <15 % latency increase under concurrency) for flagship MoE models on dual-socket commodity CPUs and consumer GPUs while preserving original precision.
Significance. If the claimed throughputs and latency bounds are reproducible, the work would enable high-quality local inference of large MoE models without quantization or distillation, lowering the barrier to consumer-grade deployment of models such as DeepSeek-V3. The concrete engineering techniques for hybrid scheduling and kernel optimization constitute a useful contribution to systems research on local inference.
major comments (3)
- [Abstract] Abstract: the central performance claims (1,200 tokens/s prefill, 1,800 tokens/s with DSLP, 28 tokens/s INT4 decode, 21.5 tokens/s FP8 decode, <15 % latency penalty) are presented without any description of measurement methodology, workload definitions, hardware configuration details, or error bars, rendering it impossible to verify that the listed techniques meet the stated SLOs.
- [Evaluation] Evaluation (presumed §5): the description of stream-loading prefill, zero-copy disaggregation, and dual-batch overlap supplies no bandwidth accounting or microbenchmark data for PCIe transfers, synchronization, or memory contention on the target dual-socket CPU + consumer GPU platform, leaving open the possibility that unmodeled data-movement costs violate the TTFT and decode latency targets.
- [Techniques] Techniques section (presumed §4): the claim that the AVX-512 FP8 GEMV kernel delivers 4-5× lower CPU latency while sustaining the reported decode throughputs on intact FP8 DeepSeek-V3 requires explicit microbenchmark results and comparison against baseline GEMV implementations to confirm the absence of hidden overheads.
minor comments (2)
- [Abstract] Define all acronyms (SLP, DSLP, SmallEP, TTFT) at first use and ensure consistent capitalization of model names (e.g., DeepSeek-V3).
- [Evaluation] Add a table or figure summarizing the exact hardware platform (CPU model, GPU model, interconnect) and the precise prompt lengths and batch sizes used for each reported number.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential significance of the CPU-GPU hybrid design for local MoE inference. We address each major comment below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (1,200 tokens/s prefill, 1,800 tokens/s with DSLP, 28 tokens/s INT4 decode, 21.5 tokens/s FP8 decode, <15 % latency penalty) are presented without any description of measurement methodology, workload definitions, hardware configuration details, or error bars, rendering it impossible to verify that the listed techniques meet the stated SLOs.
Authors: We agree that the abstract would benefit from a concise indication of the experimental context. In the revision we will append a brief clause noting that results were measured on dual-socket commodity CPUs with consumer GPUs (RTX 5090 class), using workloads of prompts longer than 12 K tokens, with throughput and latency figures averaged across repeated runs under the target SLOs. Full workload definitions, hardware specifications, and methodology remain in §5. revision: yes
-
Referee: [Evaluation] Evaluation (presumed §5): the description of stream-loading prefill, zero-copy disaggregation, and dual-batch overlap supplies no bandwidth accounting or microbenchmark data for PCIe transfers, synchronization, or memory contention on the target dual-socket CPU + consumer GPU platform, leaving open the possibility that unmodeled data-movement costs violate the TTFT and decode latency targets.
Authors: We concur that explicit microbenchmark data would strengthen the evaluation. The current text describes the mechanisms but omits dedicated bandwidth accounting. We will add a subsection to §5 that reports measured PCIe transfer rates, synchronization overheads, and memory-contention profiles on the dual-socket CPU + consumer GPU platform, confirming that data-movement costs remain within the SLO envelopes. revision: yes
-
Referee: [Techniques] Techniques section (presumed §4): the claim that the AVX-512 FP8 GEMV kernel delivers 4-5× lower CPU latency while sustaining the reported decode throughputs on intact FP8 DeepSeek-V3 requires explicit microbenchmark results and comparison against baseline GEMV implementations to confirm the absence of hidden overheads.
Authors: We accept that standalone microbenchmark evidence is needed. Although §4 presents the kernel and its end-to-end impact, we will insert direct comparisons against reference GEMV implementations (including standard BLAS baselines) on the target CPU, reporting per-operation latency reductions and verifying that no hidden overheads compromise the claimed decode throughputs. revision: yes
Circularity Check
No circularity: engineering systems paper with empirical claims only
full rationale
The paper presents a CPU-GPU hybrid inference system for MoE models, describing techniques such as stream-loading prefill, intra-node disaggregation, and optimized kernels, followed by evaluation results on throughput and latency. No mathematical derivations, equations, fitted parameters, or first-principles predictions appear in the provided text. Claims rest on empirical measurements rather than any chain that reduces by construction to inputs or self-citations. No load-bearing self-citation, ansatz smuggling, or renaming of known results is present. The derivation chain is self-contained as a description of implemented techniques and observed outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amd optimizing cpu libraries (aocl)
Advanced Micro Devices, Inc. Amd optimizing cpu libraries (aocl). https://www.amd.com/en/develop er/aocl.html, n.d. Accessed: 2025-08-29
2025
-
[2]
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, and Ramachan- dran Ramjee. Sarathi: Efficient llm inference by piggy- backing decodes with chunked prefills.arXiv preprint arXiv:2308.16369, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Kimi-k2-instruct (revision 2f7e011), 2025
Moonshot AI. Kimi-k2-instruct (revision 2f7e011), 2025
2025
-
[4]
Llm in a flash: Efficient large language model inference with lim- ited memory
Keivan Alizadeh, Seyed Iman Mirzadeh, Dmitry Be- lenko, S Khatamifard, Minsik Cho, Carlo C Del Mundo, Mohammad Rastegari, and Mehrdad Farajtabar. Llm in a flash: Efficient large language model inference with lim- ited memory. InProceedings of the 62nd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12562–12...
2024
-
[5]
LongBench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd An- nual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pa...
2024
-
[6]
LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xi- aozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Long- bench v2: Towards deeper understanding and reason- ing on realistic long-context multitasks.arXiv preprint arXiv:2412.15204, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
William Brandon, Aniruddha Nrusimha, Kevin Qian, Zachary Ankner, Tian Jin, Zhiye Song, and Jonathan Ragan-Kelley. Striped attention: Faster ring attention for causal transformers.arXiv preprint arXiv:2311.09431, 2023
-
[8]
Ktransformers: Unleash- ing the full potential of cpu/gpu hybrid inference for moe models
Hongtao Chen, Weiyu Xie, Boxin Zhang, Jingqi Tang, Ji- ahao Wang, Jianwei Dong, Shaoyuan Chen, Ziwei Yuan, Chen Lin, Chengyu Qiu, et al. Ktransformers: Unleash- ing the full potential of cpu/gpu hybrid inference for moe models. InProceedings of the ACM SIGOPS 31st Sym- posium on Operating Systems Principles, pages 1014– 1029, 2025
2025
-
[9]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with bet- ter parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Flashattention: Fast and memory- efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344– 16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344– 16359, 2022
2022
-
[11]
Deepgemm: Clean and efficient fp8 gemm kernels with fine-grained scaling
DeepSeek-AI. Deepgemm: Clean and efficient fp8 gemm kernels with fine-grained scaling. https://gi thub.com/deepseek-ai/DeepGEMM, 2025. Accessed: 2025-12-04
2025
-
[12]
One more thing, deepseek-v3/r1 infer- ence system overview
DeepSeek-AI. One more thing, deepseek-v3/r1 infer- ence system overview. https://github.com/dee pseek-ai/open-infra-index/blob/main/20250 2OpenSourceWeek/day_6_one_more_thing_deeps eekV3R1_inference_system_overview.md , 2025. Accessed: 2025-12-04
2025
-
[13]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI, Aixin Liu, Bei Feng, Bin Wang, Bingx- uan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Hao Yang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J. L. Cai, Jian...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Scaling fp8 training to trillion-token llms.arXiv preprint arXiv:2409.12517, 2024
Maxim Fishman, Brian Chmiel, Ron Banner, and Daniel Soudry. Scaling fp8 training to trillion-token llms.arXiv preprint arXiv:2409.12517, 2024
-
[15]
llama.cpp: Llm inference in c/c++
ggml-org. llama.cpp: Llm inference in c/c++. https:// github.com/ggml-org/llama.cpp, 2025. Accessed: 2025-12-04
2025
-
[16]
mmlu- redux (revision 53bc457), 2024
Edinburgh Dataset Analytics Working Group. mmlu- redux (revision 53bc457), 2024
2024
-
[17]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Xin He, Shunkang Zhang, Yuxin Wang, Haiyan Yin, Zihao Zeng, Shaohuai Shi, Zhenheng Tang, Xiaowen Chu, Ivor Tsang, and Ong Yew Soon. Expertflow: Op- timized expert activation and token allocation for ef- ficient mixture-of-experts inference.arXiv preprint arXiv:2410.17954, 2024
-
[19]
Pre- gated moe: An algorithm-system co-design for fast and scalable mixture-of-expert inference
Ranggi Hwang, Jianyu Wei, Shijie Cao, Changho Hwang, Xiaohu Tang, Ting Cao, and Mao Yang. Pre- gated moe: An algorithm-system co-design for fast and scalable mixture-of-expert inference. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 1018–1031. IEEE, 2024
2024
-
[20]
ik_llama.cpp: llama.cpp fork with addi- tional sota quants and improved performance
ikawrakow. ik_llama.cpp: llama.cpp fork with addi- tional sota quants and improved performance. https: //github.com/ikawrakow/ik_llama.cpp , 2025. Accessed: 2025-08-31
2025
-
[21]
Intel® 64 and ia-32 architectures software devel- oper manuals, 3/5/2025
Intel. Intel® 64 and ia-32 architectures software devel- oper manuals, 3/5/2025. Accessed: 2025
2025
-
[22]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajb- handari, and Yuxiong He. Deepspeed ulysses: Sys- tem optimizations for enabling training of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Keisuke Kamahori, Tian Tang, Yile Gu, Kan Zhu, and Baris Kasikci. Fiddler: Cpu-gpu orchestration for fast inference of mixture-of-experts models.arXiv preprint arXiv:2402.07033, 2024
-
[24]
Scal- ing beyond the gpu memory limit for large mixture- of-experts model training
Yechan Kim, Hwijoon Lim, and Dongsu Han. Scal- ing beyond the gpu memory limit for large mixture- of-experts model training. InForty-first International Conference on Machine Learning, 2024
2024
-
[25]
Efficient memory man- agement for large language model serving with page- dattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory man- agement for large language model serving with page- dattention. InProceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023
2023
-
[26]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, De- hao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling gi- ant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[27]
{AlpaServe}: Sta- tistical multiplexing with model parallelism for deep learning serving
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E Gonzalez, et al. {AlpaServe}: Sta- tistical multiplexing with model parallelism for deep learning serving. In17th USENIX Symposium on Oper- ating Systems Design and Implementation (OSDI 23), pages 663–679, 2023
2023
-
[28]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 techni- cal report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring at- tention with blockwise transformers for near-infinite context.arXiv preprint arXiv:2310.01889, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Ocp 8-bit floating point specification (ofp8).Open Compute Project, 2023
Paulius Micikevicius, Stuart Oberman, Pradeep Dubey, Marius Cornea, Andres Rodriguez, Ian Bratt, Richard Grisenthwaite, Norm Jouppi, Chiachen Chou, Amber Huffman, et al. Ocp 8-bit floating point specification (ofp8).Open Compute Project, 2023. 16
2023
-
[32]
Paulius Micikevicius, Dusan Stosic, Neil Burgess, Mar- ius Cornea, Pradeep Dubey, Richard Grisenthwaite, Sangwon Ha, Alexander Heinecke, Patrick Judd, John Kamalu, et al. Fp8 formats for deep learning.arXiv preprint arXiv:2209.05433, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Tensorrt-llm’s documentation
NVIDIA. Tensorrt-llm’s documentation. Accessed: 2025
2025
-
[34]
NVIDIA H100 Tensor Core GPU Architecture
NVIDIA Corporation. NVIDIA H100 Tensor Core GPU Architecture. White paper, NVIDIA, 2022. H100 Tensor Core GPU; describes the Hopper GPU architecture
2022
-
[35]
Openblas: An optimized blas and lapack library
OpenBLAS Project. Openblas: An optimized blas and lapack library. https://openblas.net, n.d. Accessed: 2025-08-29
2025
-
[36]
Fp8-lm: Training fp8 large language models.arXiv preprint arXiv:2310.18313, 2023
Houwen Peng, Kan Wu, Yixuan Wei, Guoshuai Zhao, Yuxiang Yang, Ze Liu, Yifan Xiong, Ziyue Yang, Bolin Ni, Jingcheng Hu, et al. Fp8-lm: Training fp8 large language models.arXiv preprint arXiv:2310.18313, 2023
-
[37]
Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot. In23rd USENIX Confer- ence on File and Storage Technologies (FAST 25), pages 155–170, 2025
2025
-
[38]
Qwen Team. Qwen3. https://qwenlm.github.io /blog/qwen3/, 2025. Accessed: 2025-12-04
2025
-
[39]
Flashattention- 3: Fast and accurate attention with asynchrony and low- precision.Advances in Neural Information Processing Systems, 37:68658–68685, 2024
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention- 3: Fast and accurate attention with asynchrony and low- precision.Advances in Neural Information Processing Systems, 37:68658–68685, 2024
2024
-
[40]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter lan- guage models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[42]
Promoe: Fast moe-based llm serving using proac- tive caching.arXiv preprint arXiv:2410.22134, 2024
Xiaoniu Song, Zihang Zhong, Rong Chen, and Haibo Chen. Promoe: Fast moe-based llm serving using proac- tive caching.arXiv preprint arXiv:2410.22134, 2024
-
[43]
Peng Tang, Jiacheng Liu, Xiaofeng Hou, Yifei Pu, Jing Wang, Pheng-Ann Heng, Chao Li, and Minyi Guo. Hob- bit: A mixed precision expert offloading system for fast moe inference.arXiv preprint arXiv:2411.01433, 2024
-
[44]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Ji- ahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Ke- lin Fu, Bofei Gao, Hongcheng Gao, Peizhong Gao, Tong Gao, Xinran Gu, Longyu Guan, Haiqing Guo, Jianhang Guo...
2025
-
[45]
Chitu: High-performance inference frame- work for large language models
thu-pacman. Chitu: High-performance inference frame- work for large language models. https://github.c om/thu-pacman/chitu, 2025. Accessed: 2025-12-04. 17
2025
-
[46]
Mmlu-pro (revision efb53c9), 2024
TIGER-Lab. Mmlu-pro (revision efb53c9), 2024
2024
-
[47]
unsloth/deepseek-r1-0528-bf16
unsloth. unsloth/deepseek-r1-0528-bf16. https://hu ggingface.co/unsloth/DeepSeek-R1-0528-BF16 ,
-
[49]
unsloth/deepseek-r1-gguf
unsloth. unsloth/deepseek-r1-gguf. https://hugg ingface.co/unsloth/DeepSeek-R1-GGUF , 2025. Accessed: 2025-12-04
2025
-
[50]
unsloth/deepseek-v3-0324-bf16
unsloth. unsloth/deepseek-v3-0324-bf16. https://hu ggingface.co/unsloth/DeepSeek-V3-0324-BF16 ,
-
[51]
Accessed: 2025-12-04
2025
-
[52]
unsloth/deepseek-v3-gguf
unsloth. unsloth/deepseek-v3-gguf. https://hugg ingface.co/unsloth/DeepSeek-V3-GGUF , 2025. Accessed: 2025-12-04
2025
-
[53]
Step-3 is large yet affordable: Model-system co-design for cost-effective decoding
Bin Wang, Bojun Wang, Changyi Wan, Guanzhe Huang, Hanpeng Hu, Haonan Jia, Hao Nie, Mingliang Li, Nuo Chen, Siyu Chen, et al. Step-3 is large yet affordable: Model-system co-design for cost-effective decoding. arXiv preprint arXiv:2507.19427, 2025
-
[54]
Optimizing Large Language Model Training Using FP4 Quantization
Ruizhe Wang, Yeyun Gong, Xiao Liu, Guoshuai Zhao, Ziyue Yang, Baining Guo, Zhengjun Zha, and Peng Cheng. Optimizing large language model training us- ing fp4 quantization.arXiv preprint arXiv:2501.17116, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Context parallelism for scalable million-token inference.arXiv preprint arXiv:2411.01783, 2024
Amy Yang, Jingyi Yang, Aya Ibrahim, Xinfeng Xie, Bangsheng Tang, Grigory Sizov, Jeremy Reizenstein, Jongsoo Park, and Jianyu Huang. Context parallelism for scalable million-token inference.arXiv preprint arXiv:2411.01783, 2024
-
[56]
Orca: A distributed serving system for {Transformer-Based} generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soo- jeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538, 2022
2022
-
[57]
Deepep: an efficient expert-parallel communication library
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. Deepep: an efficient expert-parallel communication library. https://github.com/deeps eek-ai/DeepEP, 2025
2025
-
[58]
Sglang: Efficient execution of structured language model programs.Advances in Neural Information Pro- cessing Systems, 37:62557–62583, 2024
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in Neural Information Pro- cessing Systems, 37:62557–62583, 2024
2024
-
[59]
Kan Zhu, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Yufei Gao, Qinyu Xu, Tian Tang, Zihao Ye, et al. Nanoflow: Towards optimal large language model serving throughput.arXiv preprint arXiv:2408.12757, 2024
-
[60]
ring-flash-attention
Zilin Zhu. ring-flash-attention. https://github.com /zhuzilin/ring-flash-attention , 2024. GitHub repository
2024
-
[61]
Serving large language models on huawei cloudmatrix384.arXiv preprint arXiv:2506.12708, 2025
Pengfei Zuo, Huimin Lin, Junbo Deng, Nan Zou, Xingkun Yang, Yingyu Diao, Weifeng Gao, Ke Xu, Zhangyu Chen, Shirui Lu, et al. Serving large language models on huawei cloudmatrix384.arXiv preprint arXiv:2506.12708, 2025. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.