Non-linear mechanical field reconstruction coupling recurrent neural networks with physics-informed graph neural networks
Pith reviewed 2026-06-27 11:18 UTC · model grok-4.3
The pith
A coupled LSTM-GNN reconstructs local stress fields under nonlinear history-dependent loading three orders of magnitude faster than finite elements while generalizing to longer sequences and different meshes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
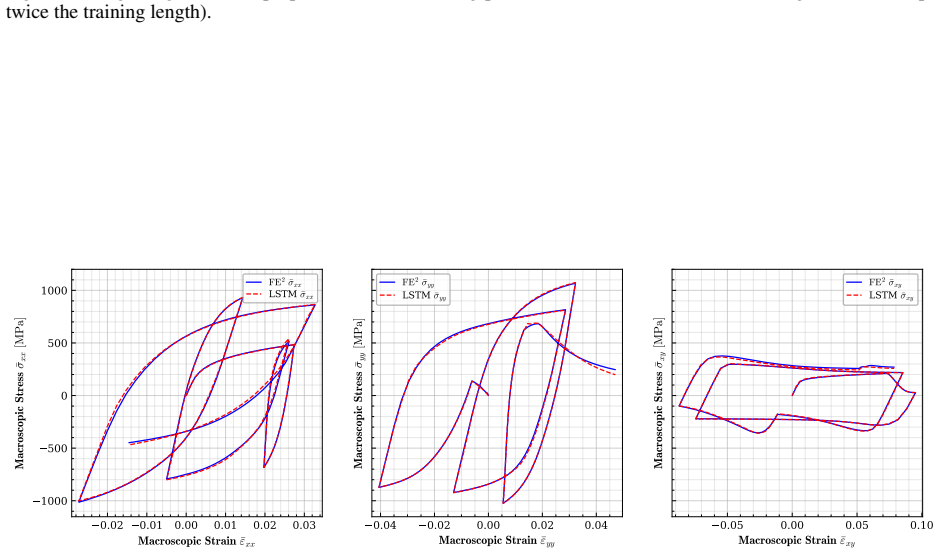
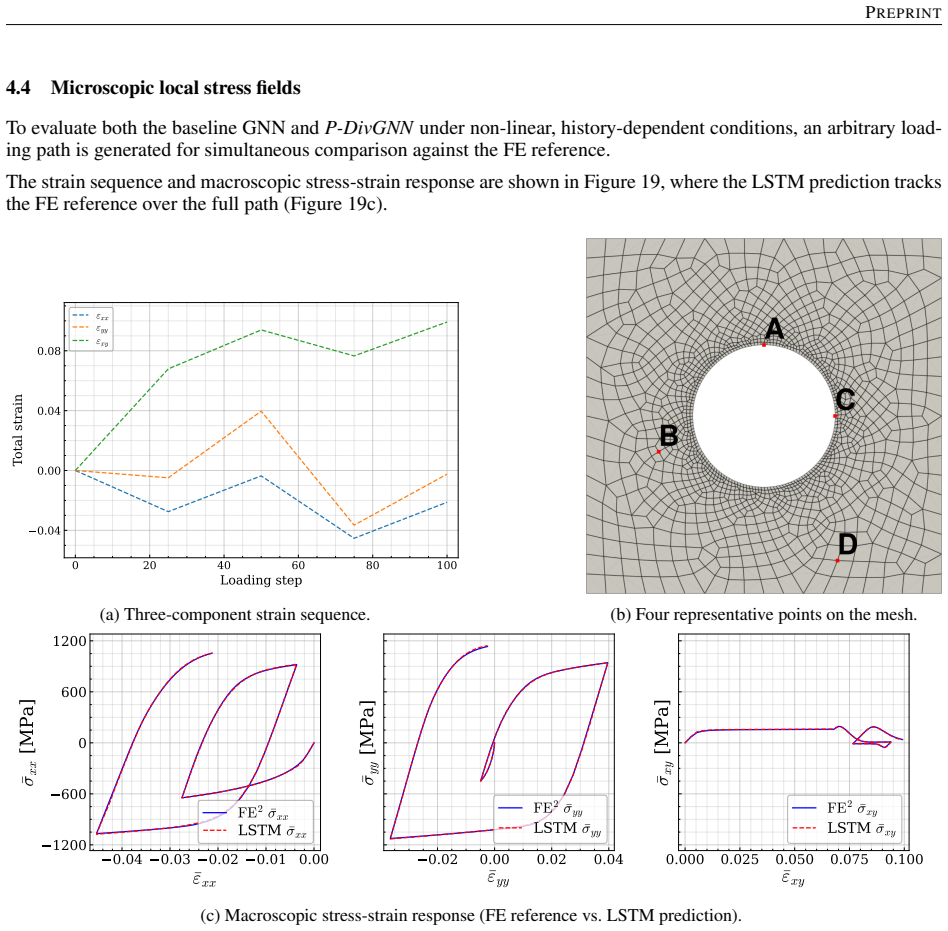
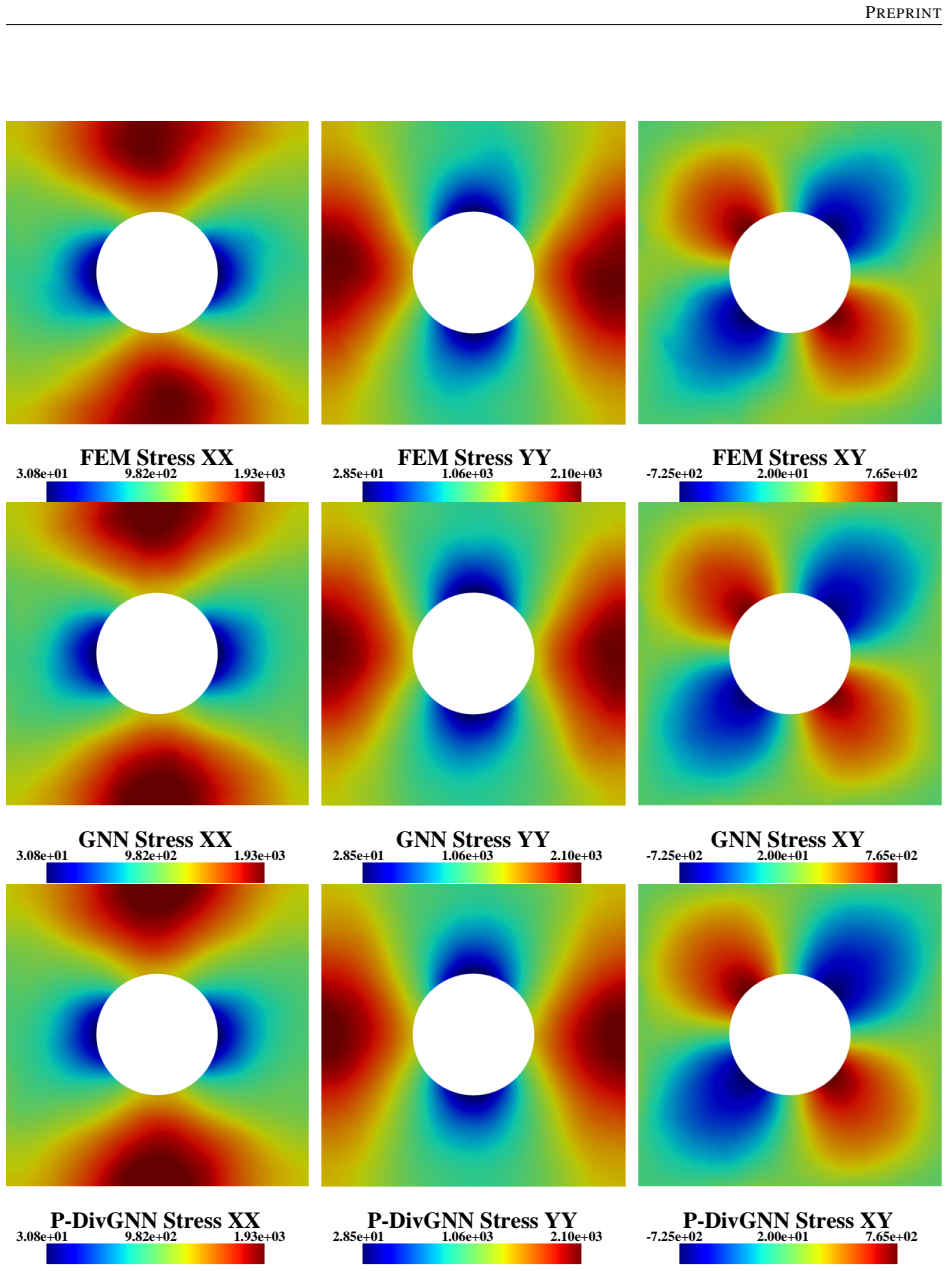
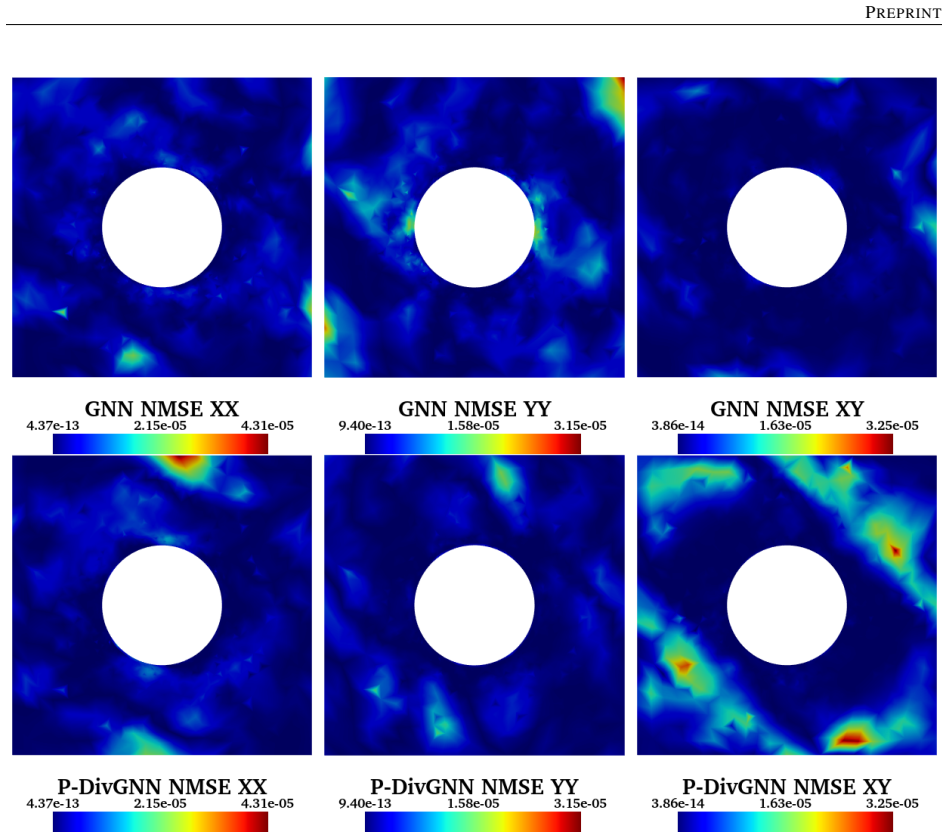
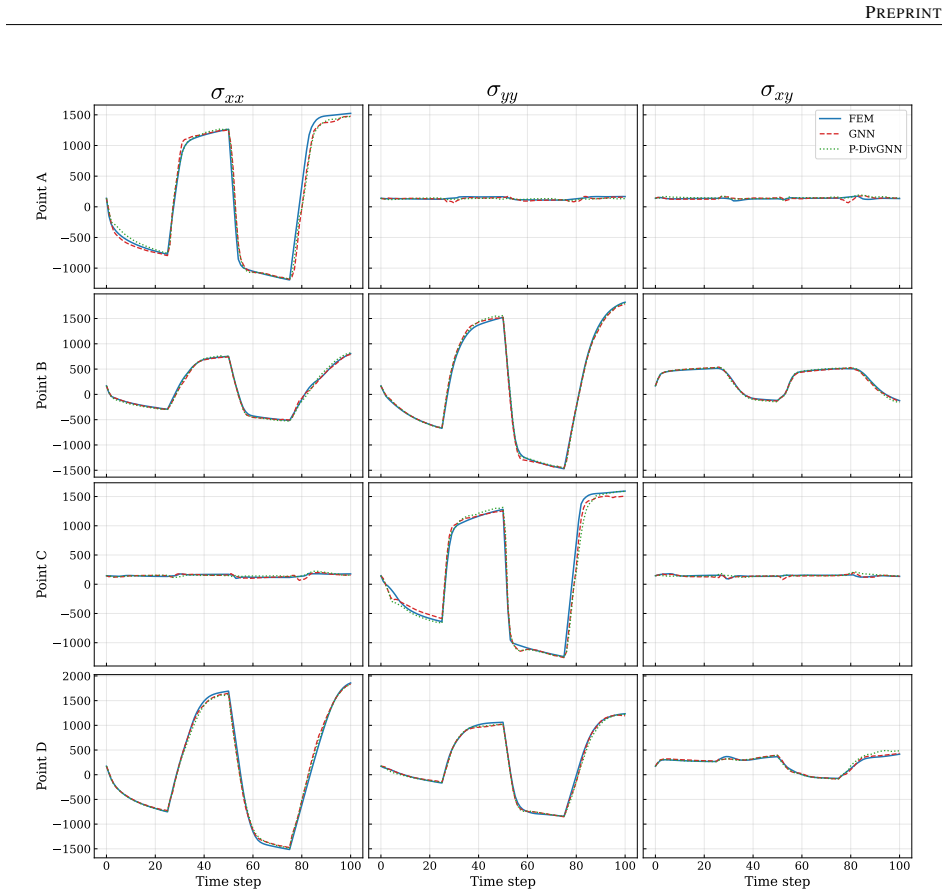
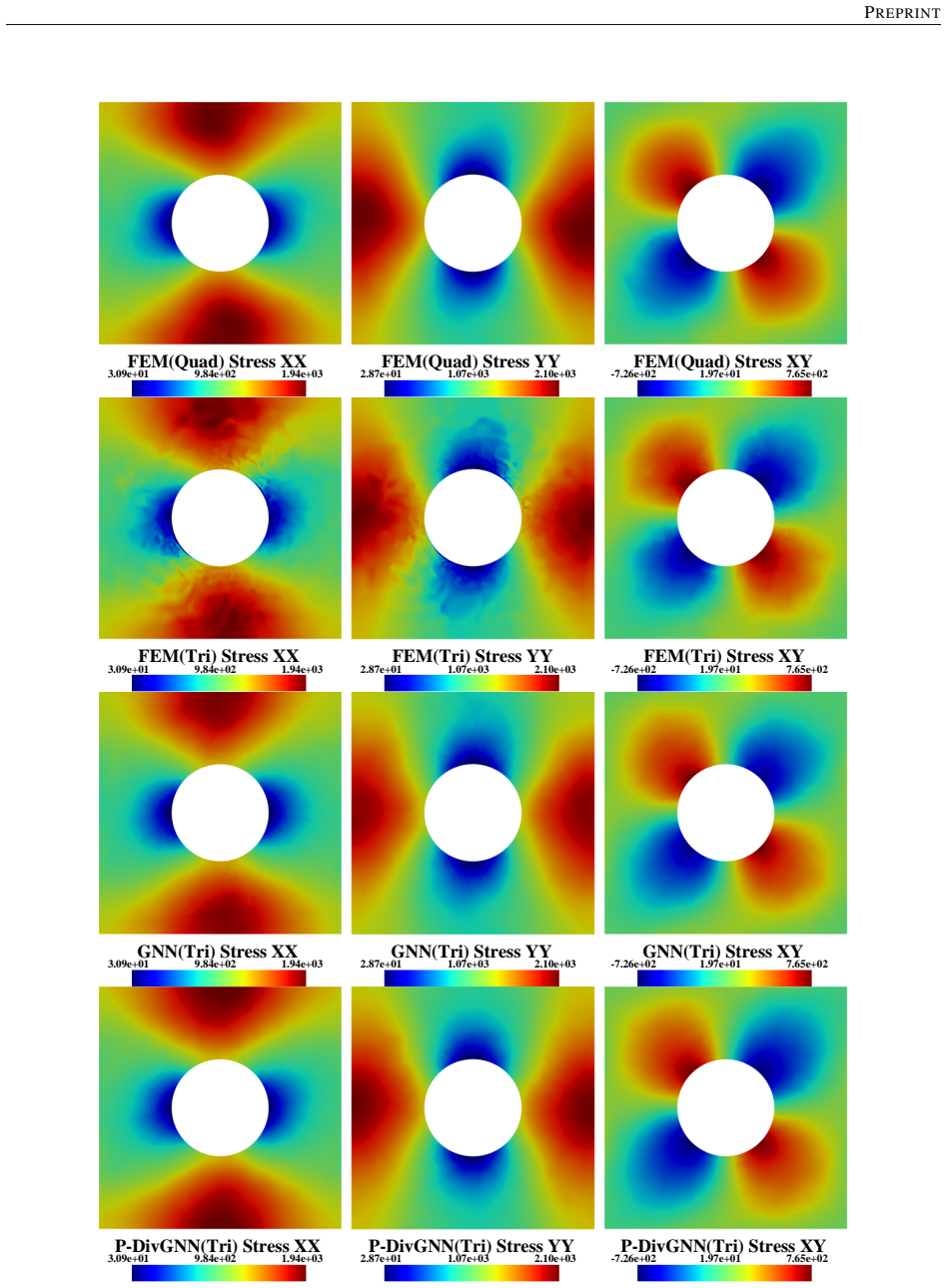
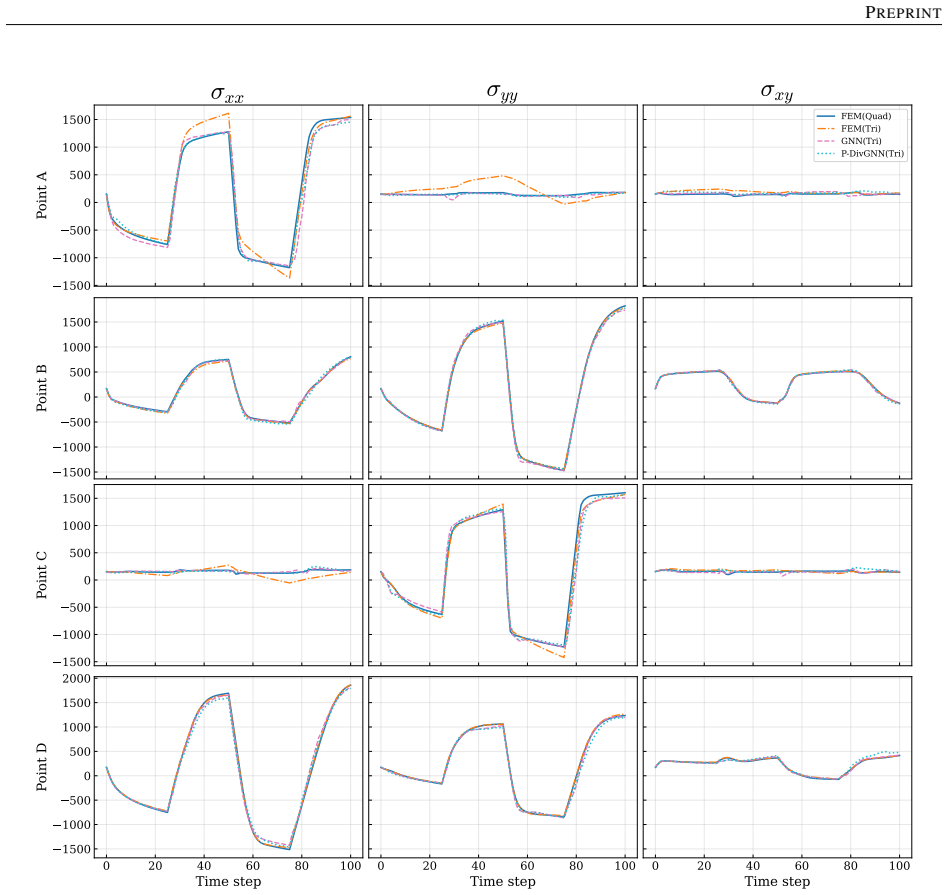
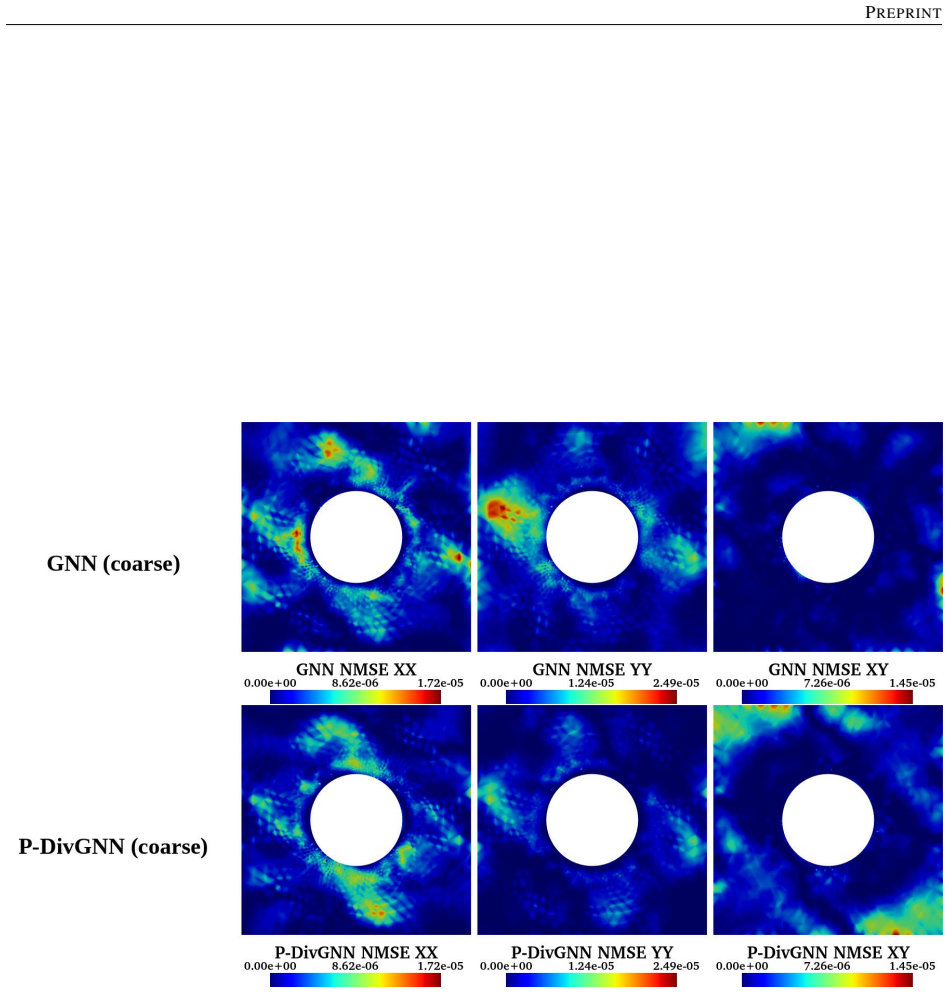
The central claim is that an LSTM hidden state encoding the macroscopic loading path, passed at each time step to a MeshGraphNet-style GNN whose message-passing layers are regularized by a divergence-based equilibrium penalty, yields a surrogate that matches finite-element stress fields to high accuracy, runs three orders of magnitude faster, generalizes to loading sequences twice the training length with 1.9 percent cumulative error, and transfers directly to meshes of different element type and resolution because the architecture depends only on nodal connectivity rather than element shape functions.
What carries the argument
The coupled LSTM-GNN with relative weighting and linear warm-up of the discrete divergence-based equilibrium penalty.
If this is right
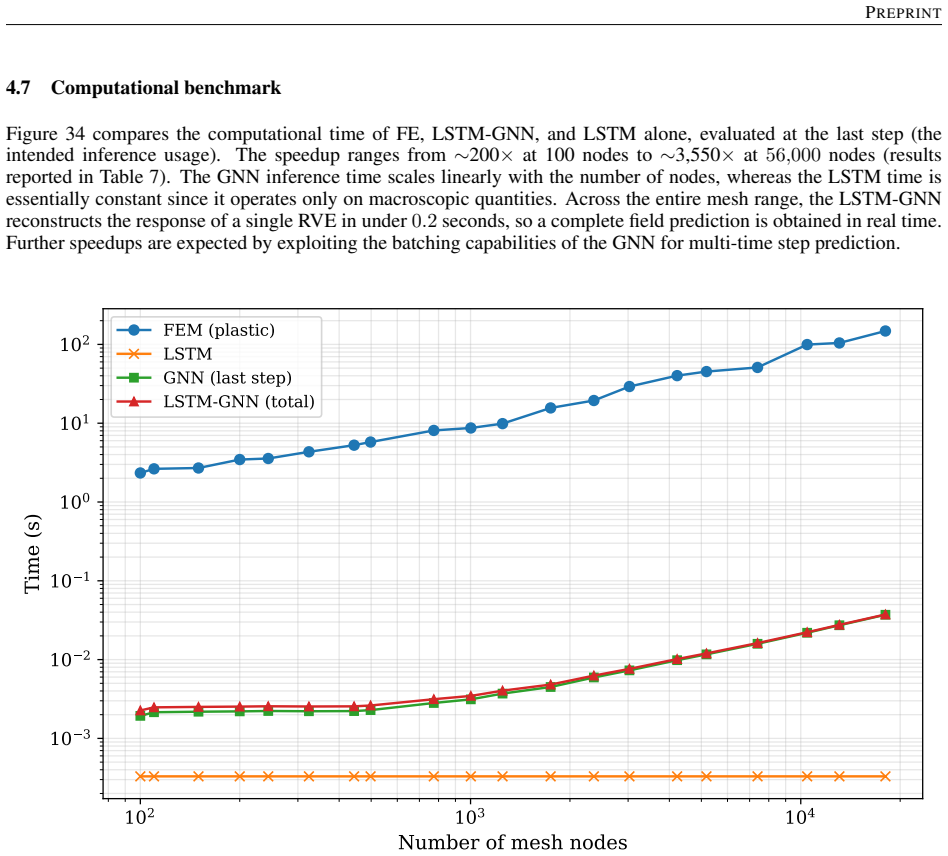
- The surrogate delivers three orders of magnitude speedup over finite-element simulation for the same microstructure and constitutive model.
- Loading sequences up to twice the training length are reproduced with 1.9 percent cumulative error.
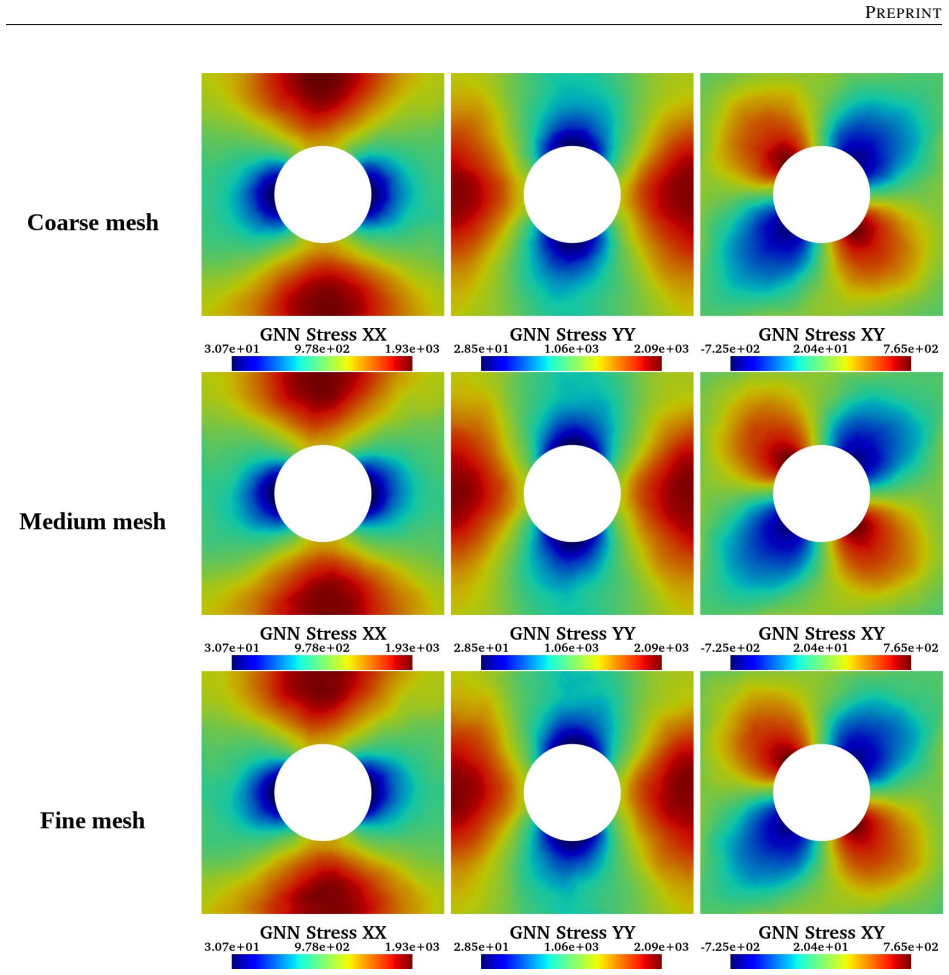
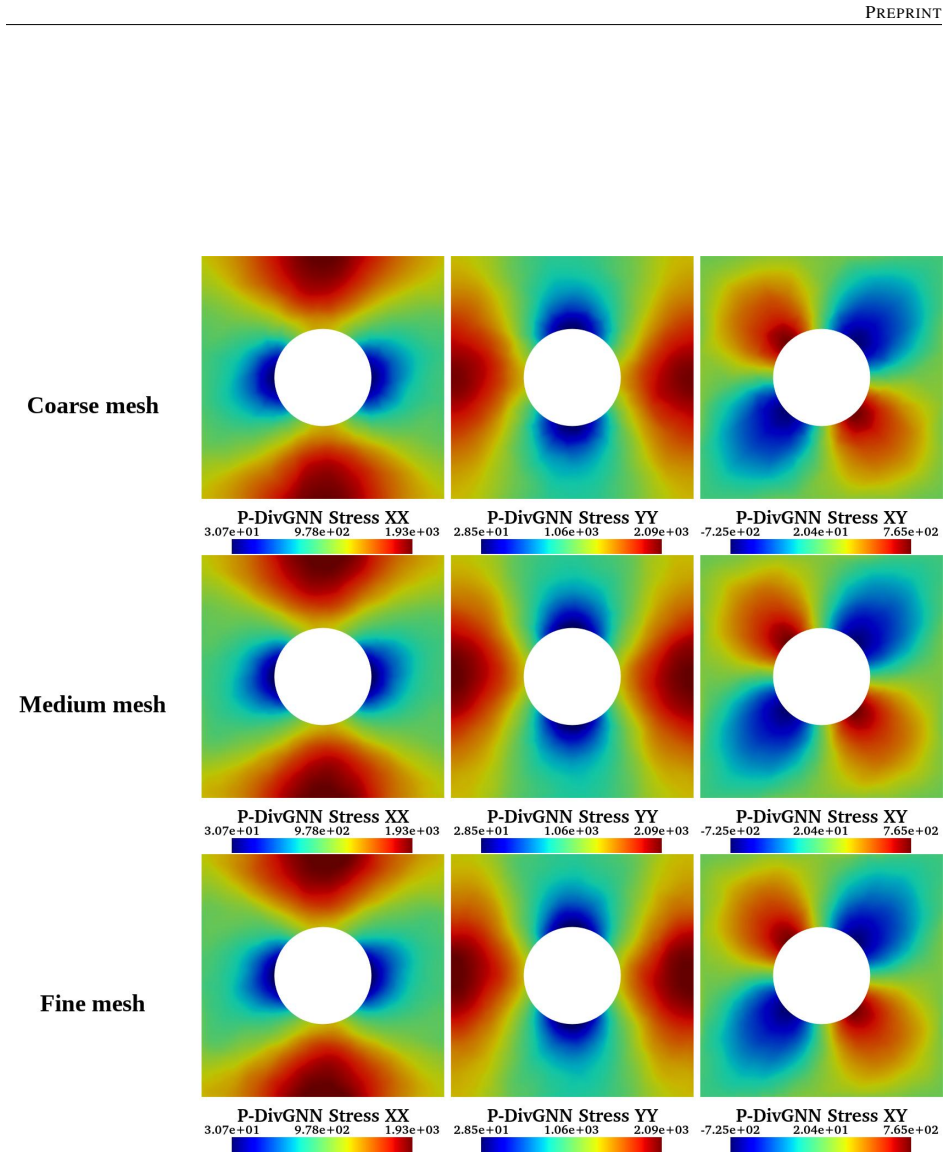
- A single trained model reproduces the high-fidelity quad-element solution on meshes with different element types and on both coarser and finer resolutions.
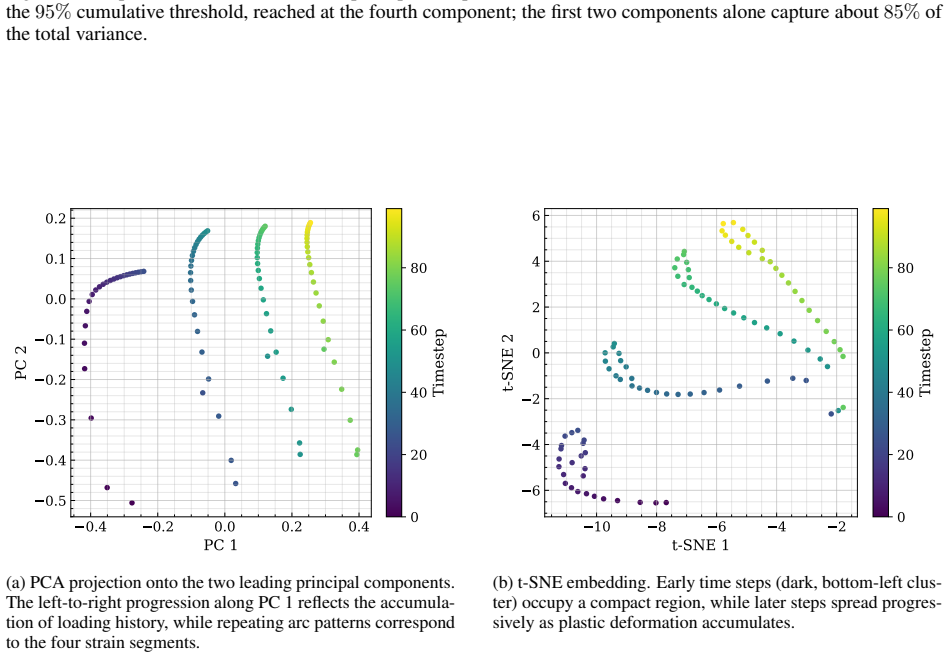
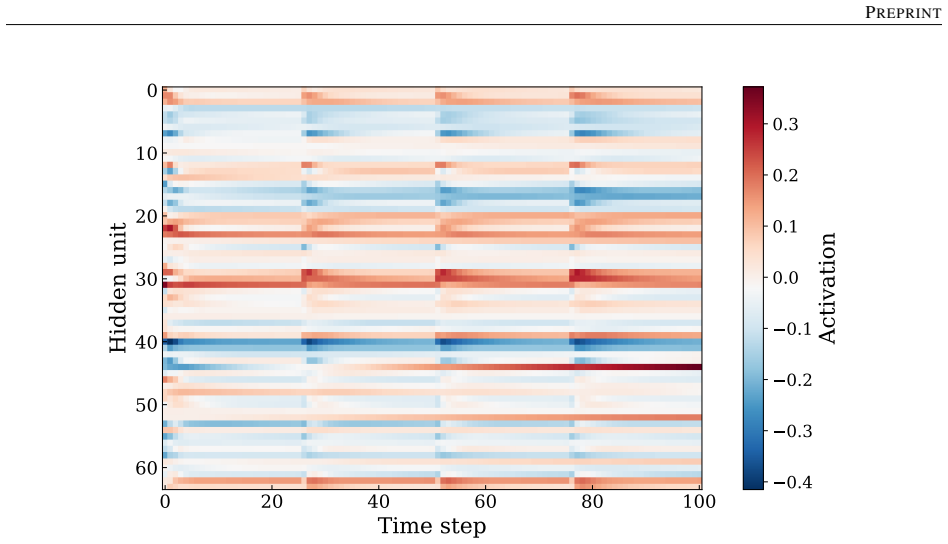
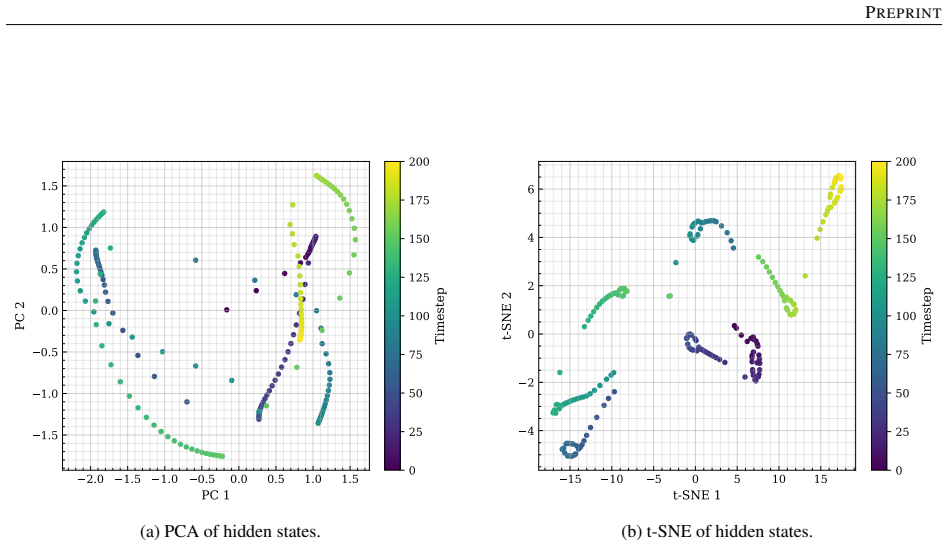
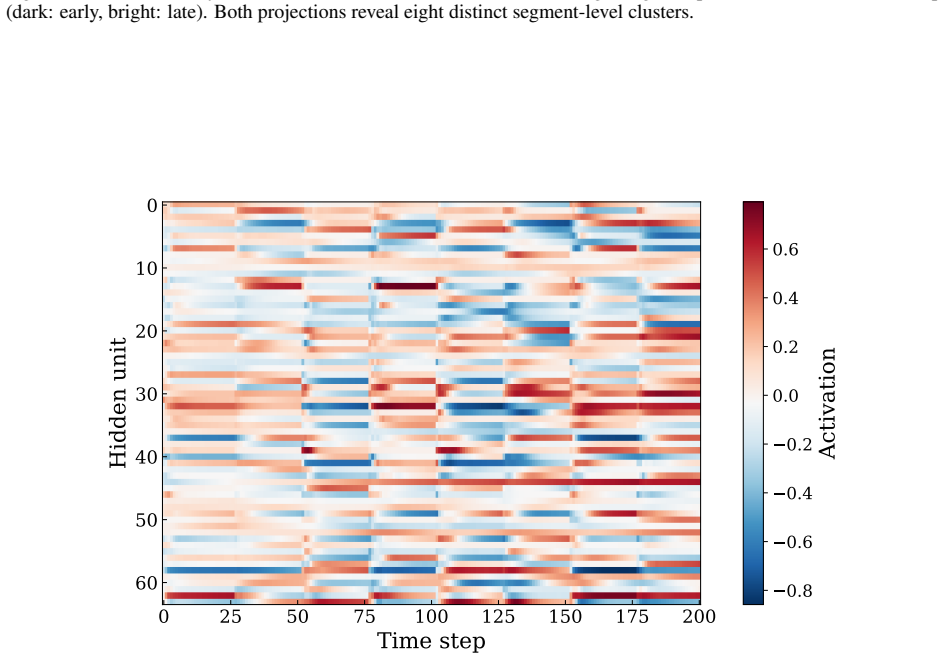
- LSTM hidden states exhibit a low-dimensional structure correlated with the internal variables of the underlying constitutive model.
- Message passing on mesh connectivity renders the reconstruction mesh-agnostic without retraining.
Where Pith is reading between the lines
- The architecture could be inserted into existing multi-scale homogenization loops to replace repeated micro-scale solves.
- Analysis of the LSTM state trajectory might yield reduced-order constitutive models whose internal variables are directly interpretable.
- The same coupling could be tested on three-dimensional microstructures or on data drawn from digital image correlation experiments.
- If the equilibrium penalty generalizes, the method may extend to other history-dependent problems such as viscoplasticity or damage evolution.
Load-bearing premise
The discrete divergence-based equilibrium penalty, when combined with relative weighting and linear warm-up, is sufficient to enforce mechanical equilibrium throughout training and inference in the elasto-plastic regime without introducing systematic bias.
What would settle it
Run the trained model on a new triangular-element mesh under a non-proportional loading path longer than training data and compare the reconstructed stress field pointwise against an independent finite-element solution on the identical mesh; systematic deviation above 2 percent cumulative error would falsify the generalization claim.
Figures

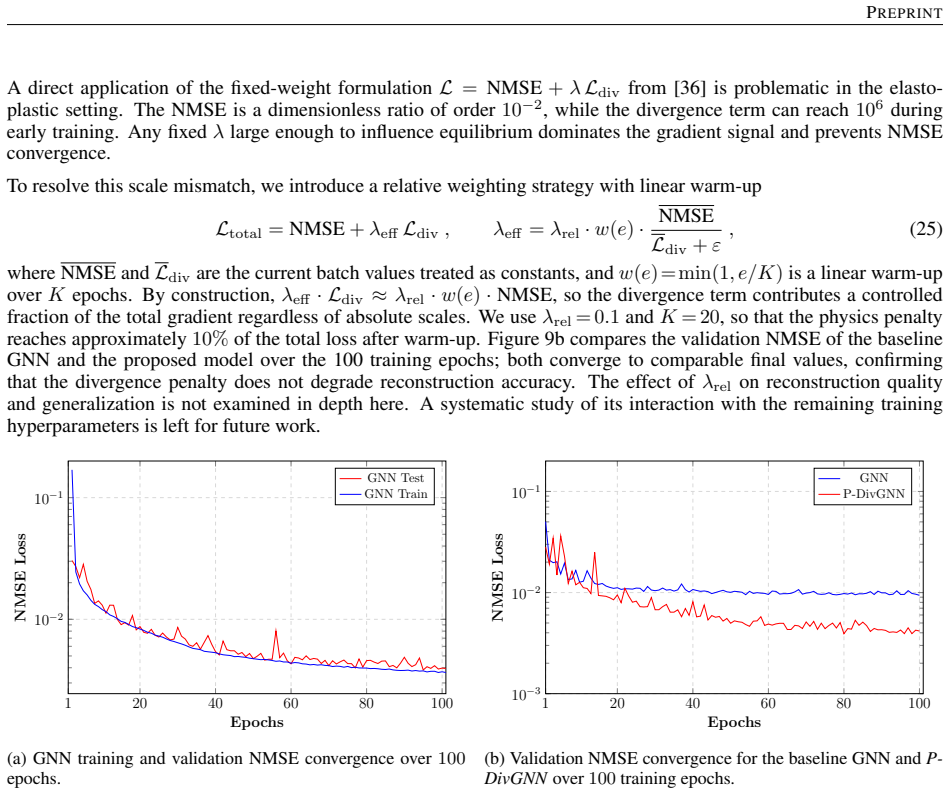
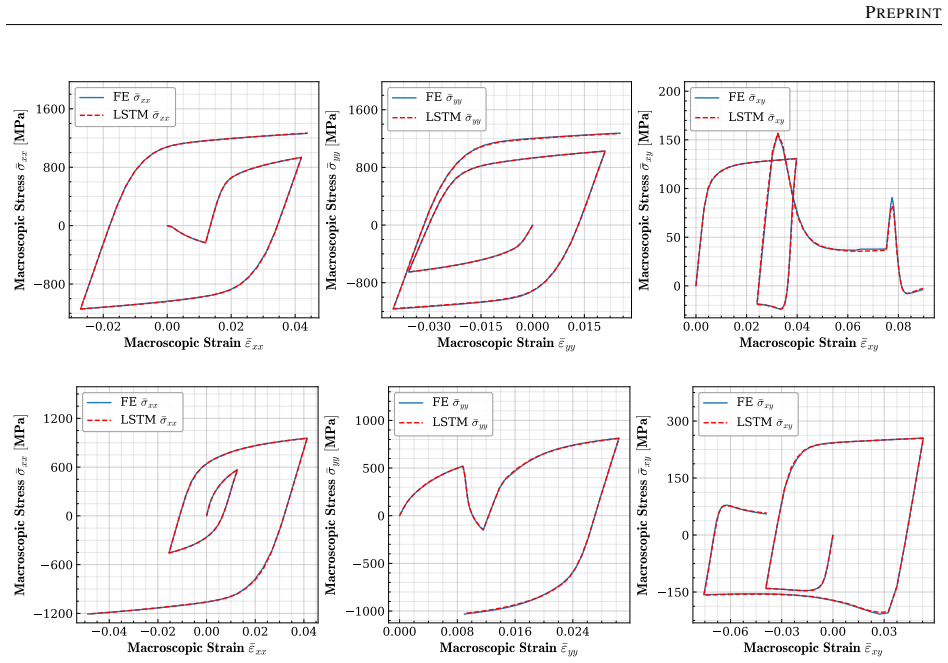
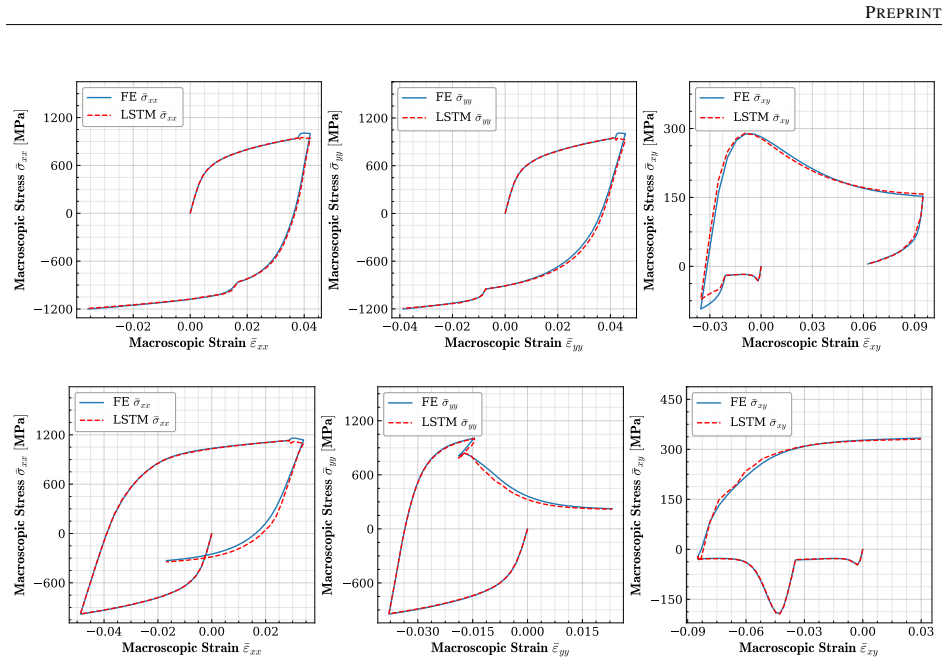
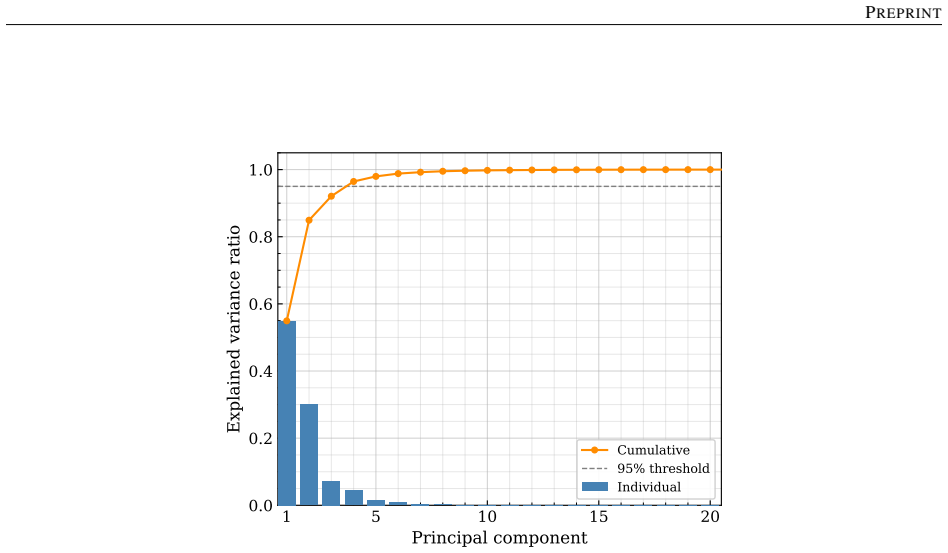


read the original abstract
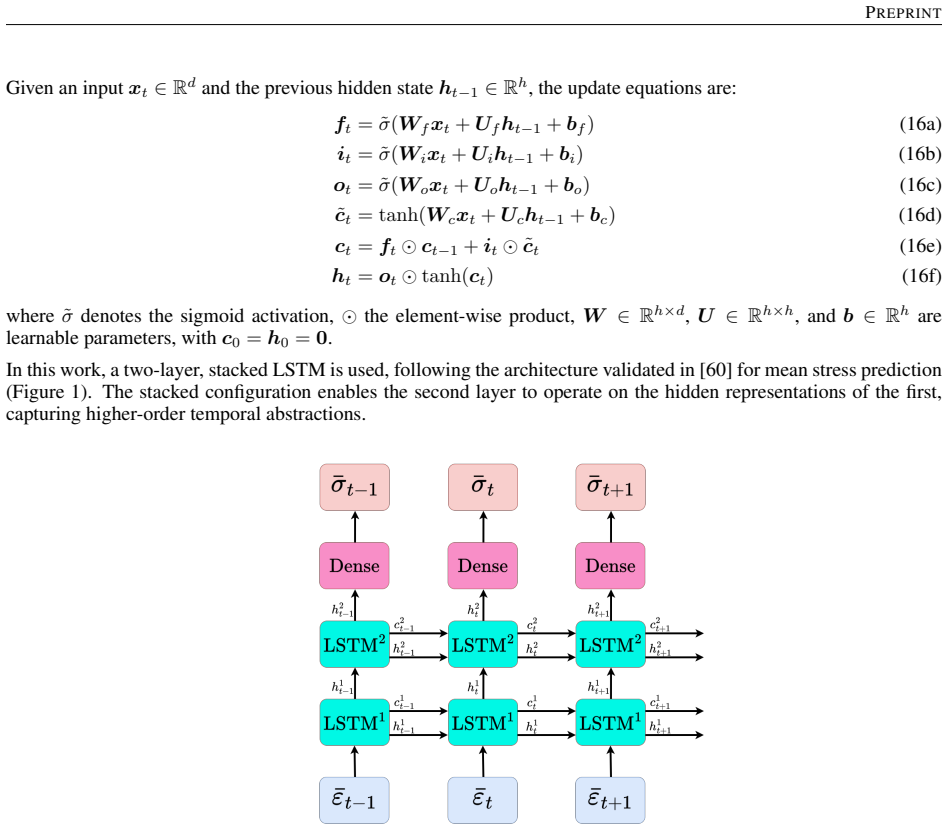
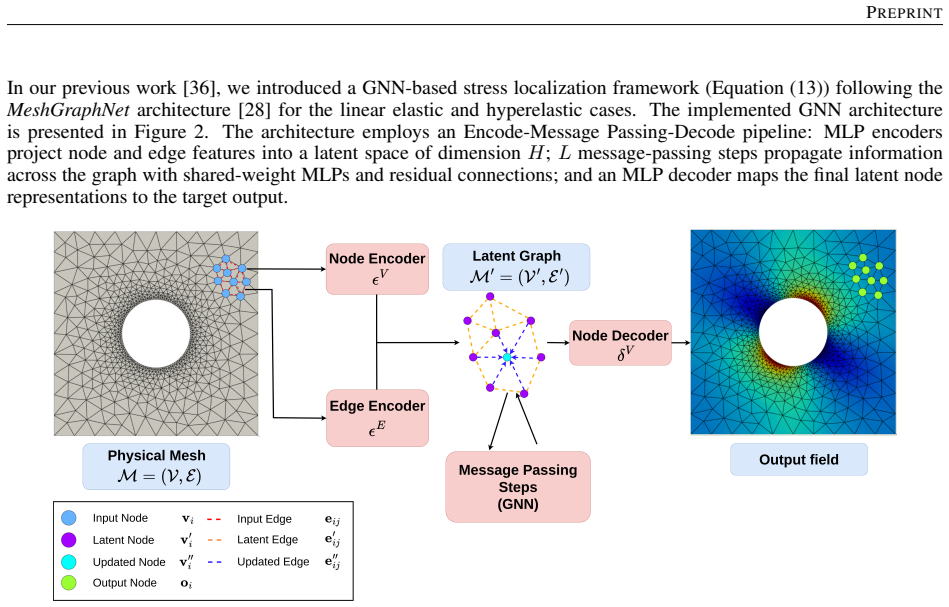
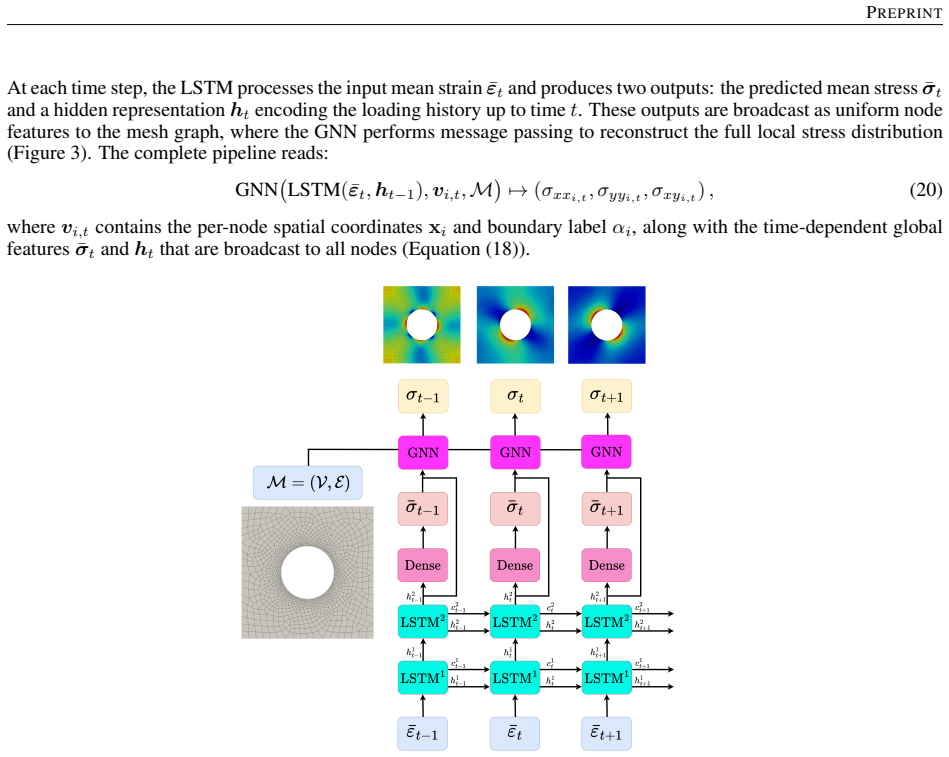
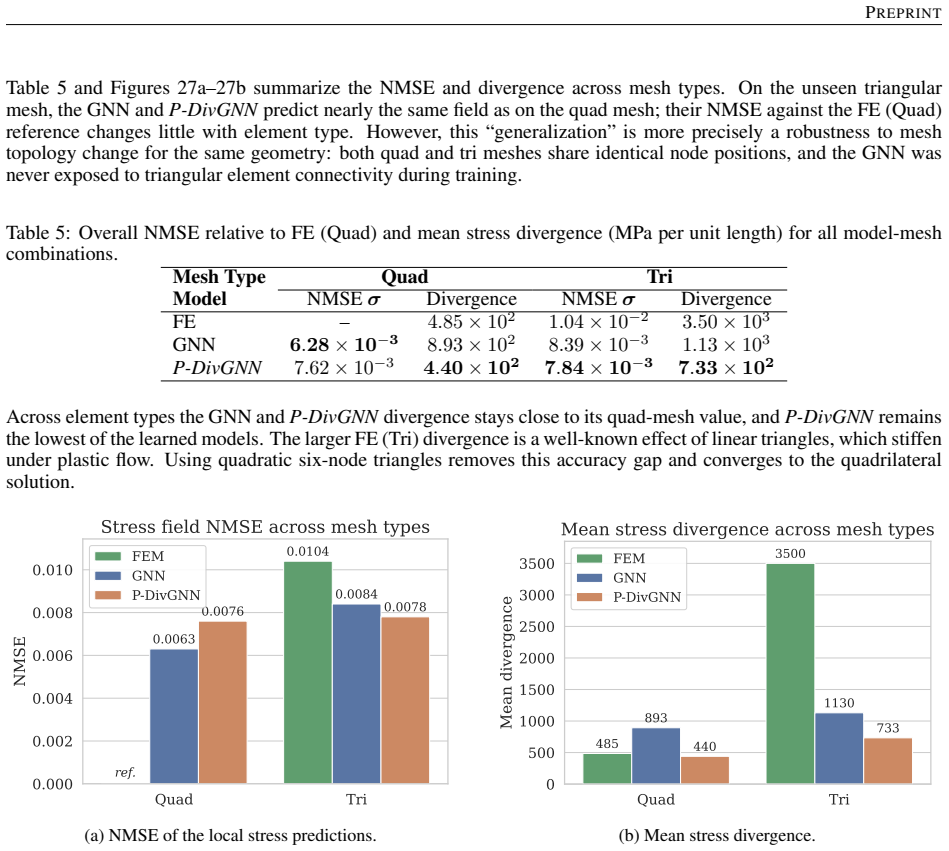
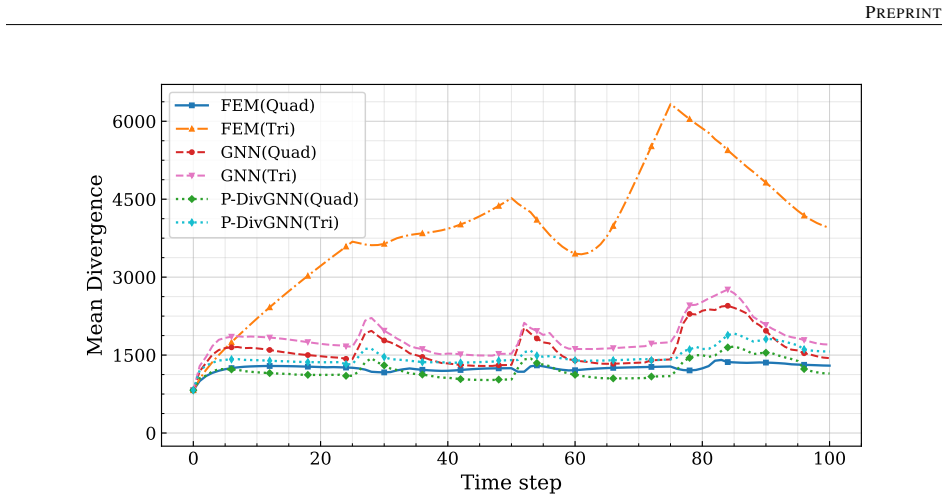
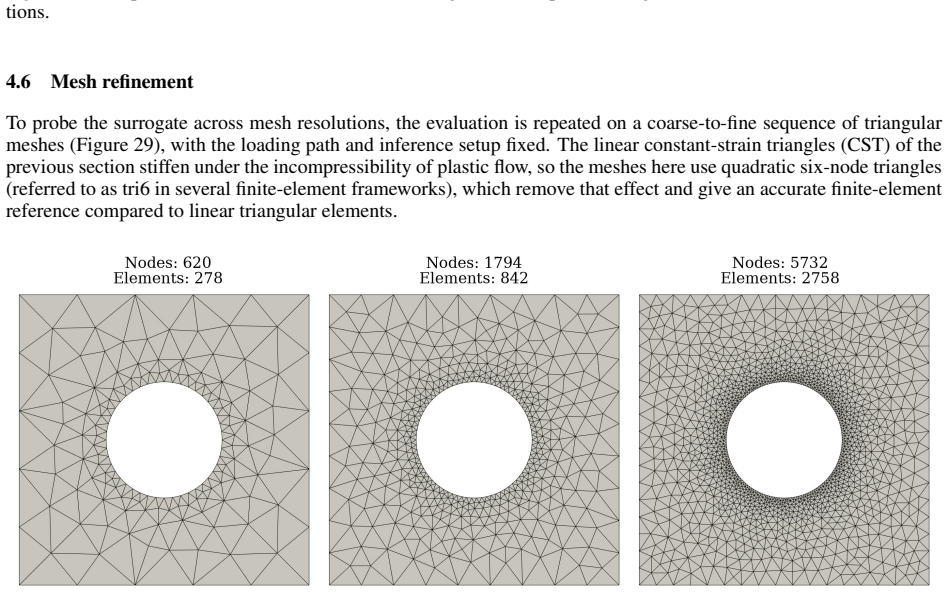
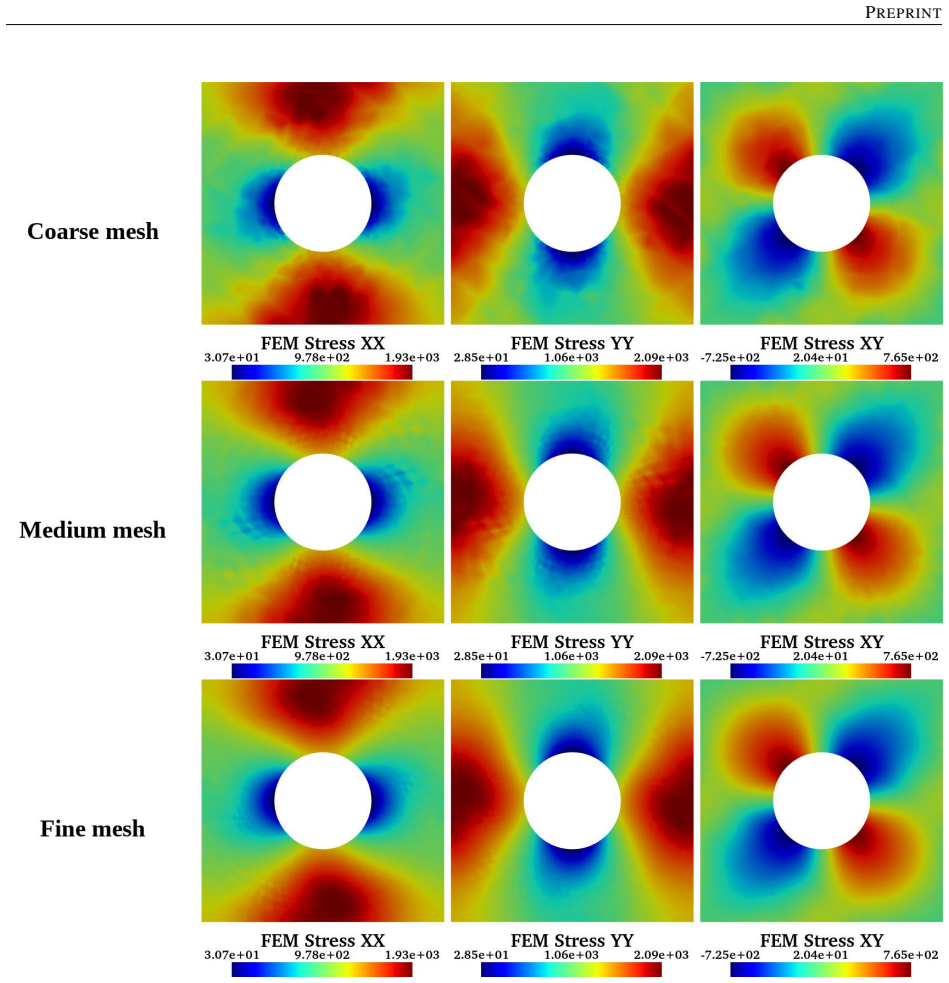
Reconstructing local stress fields in heterogeneous microstructures under non-linear, history-dependent loading remains a major computational bottleneck in multi-scale simulations. We propose a coupled LSTM-GNN framework that links the temporal and spatial aspects of local stress field reconstruction. A Long Short-Term Memory network encodes macroscopic stress-strain sequences into a compact hidden state that captures the path-dependent constitutive response, while a physics-informed Graph Neural Network reconstructs the spatially-resolved stress field at each time step. We introduce a relative weighting strategy with linear warm-up to balance the data-driven reconstruction loss and a discrete divergence-based equilibrium penalty. This resolves the scale mismatch that prevents fixed-weight formulations from converging in the elasto-plastic regime. The model is trained on 10,000 non-proportional loading paths applied to a periodic plate-with-a-hole microstructure and von Mises elasto-plasticity. The model achieves three orders of magnitude speedup over finite element simulations and generalizes to loading sequences twice the training length, with 1.9% cumulative error. Because the graph relies on mesh connectivity instead of the specific element type, one trained surrogate can be applied directly without retraining to meshes with different element types and to both coarser and finer resolutions, while in all cases reproducing the high-fidelity quad-element FE field used during training. Indeed, the message passing characteristics inherent to GNN and MeshGraphNet architecture render the model mesh-agnostic. Analysis of the LSTM hidden states suggests a low-dimensional structure related to the internal state variables of the constitutive model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a coupled LSTM-GNN surrogate for reconstructing spatially resolved stress fields in a periodic plate-with-a-hole microstructure under non-proportional elasto-plastic loading. An LSTM encodes macroscopic stress-strain paths into a hidden state; a physics-informed GNN then reconstructs the field at each step using a data loss plus a discrete divergence-based equilibrium penalty whose relative weight follows a linear warm-up schedule. The model is trained on 10,000 FE paths and is reported to deliver three orders of magnitude speedup, 1.9 % cumulative error on sequences twice the training length, and direct transfer to meshes with different element types and resolutions while reproducing the training quad-element FE solution.
Significance. If the equilibrium penalty is shown to remain effective throughout the elasto-plastic regime, the approach would provide a mesh-agnostic, history-dependent surrogate that could accelerate multi-scale simulations by orders of magnitude while preserving mechanical consistency; the combination of recurrent encoding with graph-based spatial reconstruction and the explicit handling of loss-scale mismatch are technically distinctive.
major comments (2)
- [Training procedure / loss formulation] The relative weighting strategy with linear warm-up is presented as the mechanism that resolves the scale mismatch between data loss and equilibrium penalty in the von Mises elasto-plastic regime, yet the manuscript supplies no quantitative monitoring of the equilibrium residual (e.g., divergence norm) during training or inference, nor any ablation on the warm-up schedule parameters; without such evidence the 1.9 % error and mesh-transfer claims rest on an unverified assumption that the penalty remains load-bearing.
- [Results and generalization experiments] All reported performance figures (speedup, cumulative error on 2×-length sequences, mesh transfer) presuppose that the reconstructed fields satisfy equilibrium at every time step; the only supporting mechanism is the discrete divergence penalty whose effectiveness is not demonstrated by residual statistics or comparison against a pure data-driven baseline in plastic zones.
minor comments (2)
- [Numerical experiments] Validation details (train/validation/test split sizes, number of independent microstructures, error bars on the 1.9 % figure, sensitivity to LSTM hidden dimension) are not reported, limiting reproducibility.
- [Model architecture] The claim that the model is “mesh-agnostic” because of GNN message passing would be strengthened by an explicit statement of the node and edge feature definitions that remain invariant under element-type change.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Training procedure / loss formulation] The relative weighting strategy with linear warm-up is presented as the mechanism that resolves the scale mismatch between data loss and equilibrium penalty in the von Mises elasto-plastic regime, yet the manuscript supplies no quantitative monitoring of the equilibrium residual (e.g., divergence norm) during training or inference, nor any ablation on the warm-up schedule parameters; without such evidence the 1.9 % error and mesh-transfer claims rest on an unverified assumption that the penalty remains load-bearing.
Authors: We agree that direct quantitative monitoring of the equilibrium residual would provide stronger verification. Although the reported 1.9 % cumulative error on extended sequences and successful mesh transfer offer indirect support, we will add plots of the divergence norm evolution during training and inference for representative paths in the revised manuscript. We will also include a sensitivity analysis on the warm-up schedule parameters in the supplementary material. revision: yes
-
Referee: [Results and generalization experiments] All reported performance figures (speedup, cumulative error on 2×-length sequences, mesh transfer) presuppose that the reconstructed fields satisfy equilibrium at every time step; the only supporting mechanism is the discrete divergence penalty whose effectiveness is not demonstrated by residual statistics or comparison against a pure data-driven baseline in plastic zones.
Authors: The performance metrics derive from the physics-informed model. To explicitly demonstrate the penalty's contribution, we will add a comparison to a pure data-driven baseline (identical architecture without the divergence term) in the revised version, focusing on accuracy within plastic zones. Residual statistics will be reported alongside the monitoring figures noted above. revision: yes
Circularity Check
No significant circularity; claims rest on independent FE benchmarks
full rationale
The paper trains an LSTM-GNN surrogate on 10,000 independent FE-generated loading paths and reports empirical metrics (speedup, 1.9% error on longer sequences, mesh transfer) against those external simulations. The discrete divergence penalty is an external mechanical constraint, not a fitted output or self-referential definition. Relative weighting and linear warm-up are hyperparameters selected for training convergence; they do not reduce the reported field accuracy or generalization results to the inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing manner. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- relative weighting schedule parameters
- LSTM hidden-state dimension
axioms (2)
- domain assumption The discrete divergence operator on the graph approximates the continuous equilibrium condition sufficiently well for the chosen mesh resolution.
- domain assumption von Mises elasto-plasticity on the periodic plate-with-hole constitutes a representative test case for general non-linear history-dependent microstructures.
Reference graph
Works this paper leans on
-
[1]
F. Feyel, Multiscale FE 2 elastoviscoplastic analysis of composite structures, Computational Materials Science 16 (1999) 344–354. doi:10.1016/s0927-0256(99)00077-4
-
[2]
F. Feyel, A multilevel finite element method (FE 2) to describe the response of highly non-linear structures using generalized continua, Computer Methods in Applied Mechanics and Engineering (CMAME) 192 (2003) 3233–3244. doi:10.1016/s0045-7825(03)00348-7
-
[3]
J. Qu, M. Cherkaoui, Fundamentals of Micromechanics of Solids, 1st ed., Wiley, 2006
2006
-
[4]
G. Dvorak, Transformation field analysis of inelastic composite materials, Proceedings of the Royal Society of London. Series A: Mathematical and Physical Sciences 437 (1992) 311–327. doi:10.1098/rspa.1992.0063
-
[5]
J. Michel, P. Suquet, Nonuniform transformation field analysis, International Journal of Solids and Structures 40 (2003) 6937–6955. doi:10.1016/s0020-7683(03)00346-9
-
[6]
S. Roussette, J. Michel, P. Suquet, Nonuniform transformation field analysis of elastic–viscoplastic composites, Composites Science and Technology 69 (2009) 22–27. doi:10.1016/j.compscitech.2007.10.032
-
[7]
A. Danoun, E. Prulière, Y . Chemisky, FE-LSTM: A hybrid approach to accelerate multiscale simulations of ar- chitectured materials using recurrent neural networks and finite element analysis, Computer Methods in Applied Mechanics and Engineering (CMAME) 429 (2024) 117192. doi:10.1016/j.cma.2024.117192
-
[8]
A. Malik, M. Abendroth, G. Hütter, B. Kiefer, A hybrid approach employing neural networks to simulate the elasto–plastic deformation behavior of 3D-foam structures, Advanced Engineering Materials 24 (2022) 2100641. doi:10.1002/adem.202100641
-
[9]
N. Lange, G. Hütter, B. Kiefer, An efficient monolithic solution scheme for FE 2 problems, Computer Methods in Applied Mechanics and Engineering (CMAME) 382 (2021) 113886. doi:10.1016/j.cma.2021.113886
-
[10]
N. Lange, G. Hütter, B. Kiefer, A monolithic hyper ROM FE 2 method with clustered training at finite deformations, Computer Methods in Applied Mechanics and Engineering (CMAME) 418 (2024) 116522. doi:10.1016/j.cma.2023.116522
-
[11]
N. Lange, A. Malik, M. Abendroth, G. Hütter, B. Kiefer, A comparison of classical phenomenological, hy- brid neural network, and high-performance ROM FE 2 models for open-cell foams: Efficiency, accuracy, and flexibility, GAMM-Mitteilungen 48 (2025) e70004. doi:10.1002/gamm.70004
-
[12]
M. Abendroth, N. Lange, A. Malik, G. Hütter, B. Kiefer, Supplementary data for multi-scale simulations of a Weaire–Phelan foam, 2025. doi:10.5281/zenodo.15076895
-
[13]
Z. Liu, M. Bessa, W. K. Liu, Self-consistent clustering analysis: An efficient multi-scale scheme for inelastic heterogeneous materials, Computer Methods in Applied Mechanics and Engineering (CMAME) 306 (2016) 319–341. doi:10.1016/j.cma.2016.04.004
-
[14]
A. Bhaduri, Y . He, M. D. Shields, L. Graham-Brady, R. M. Kirby, Stochastic collocation approach with adaptive mesh refinement for parametric uncertainty analysis, Journal of Computational Physics 371 (2018) 732–750. doi:10.1016/j.jcp.2018.06.003
-
[15]
A. Bhaduri, C. S. Meyer, J. W. Gillespie, B. Z. G. Haque, M. D. Shields, L. Graham-Brady, Probabilistic modeling of discrete structural response with application to composite plate penetration models, Journal of Engineering Mechanics 147 (2021) 04021087. doi:10.1061/(asce)em.1943-7889.0001996
-
[16]
E. Haghighat, M. Raissi, A. Moure, H. Gomez, R. Juanes, A physics-informed deep learning framework for inversion and surrogate modeling in solid mechanics, Computer Methods in Applied Mechanics and Engineering (CMAME) 379 (2021) 113741. doi:10.1016/j.cma.2021.113741
-
[17]
Proceedings of the IEEE , author =
Y . Lecun, L. Bottou, Y . Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proceed- ings of the IEEE 86 (1998) 2278–2324. doi:10.1109/5.726791
-
[18]
Z. Nie, H. Jiang, L. B. Kara, Stress field prediction in cantilevered structures using convolutional neural networks, Journal of Computing and Information Science in Engineering 20 (2019) 011002. doi:10.1115/1.4044097
-
[19]
A. Gupta, A. Bhaduri, L. Graham-Brady, Accelerated multiscale mechanics modeling in a deep learning frame- work, Mechanics of Materials 184 (2023) 104709. doi:10.1016/j.mechmat.2023.104709
-
[20]
Ronneberger, P
O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional networks for biomedical image segmentation, in: Medical Image Computing and Computer-Assisted Intervention - MICCAI, 2015
2015
-
[21]
B. P. Croom, M. Berkson, R. K. Mueller, M. Presley, S. Storck, Deep learning prediction of stress fields in additively manufactured metals with intricate defect networks, Mechanics of Materials 165 (2022) 104191. doi:10.1016/j.mechmat.2021.104191. 34 PREPRINT
-
[22]
Goodfellow, J
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y . Bengio, Genera- tive adversarial nets, in: Advances in Neural Information Processing Systems, 2014
2014
-
[23]
J. Ho, A. Jain, P. Abbeel, Denoising diffusion probabilistic models, in: Advances in Neural Information Pro- cessing Systems 33: Annual Conference on Neural Information Processing Systems (NeurIPS), 2020
2020
-
[24]
Z. Yang, C.-H. Yu, K. Guo, M. J. Buehler, End-to-end deep learning method to predict complete strain and stress tensors for complex hierarchical composite microstructures, Journal of the Mechanics and Physics of Solids 154 (2021) 104506. doi:10.1016/j.jmps.2021.104506
-
[25]
Y . Jadhav, J. Berthel, C. Hu, R. Panat, J. Beuth, A. Barati Farimani, StressD: 2D stress estimation using denoising diffusion model, Computer Methods in Applied Mechanics and Engineering (CMAME) 416 (2023) 116343. doi:10.1016/j.cma.2023.116343
-
[26]
J. He, S. Koric, D. Abueidda, A. Najafi, I. Jasiuk, Geom-DeepONet: A point-cloud-based deep operator network for field predictions on 3D parameterized geometries, Computer Methods in Applied Mechanics and Engineering (CMAME) 429 (2024) 117130. doi:10.1016/j.cma.2024.117130
-
[27]
F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, G. Monfardini, The graph neural network model, IEEE Transactions on Neural Networks 20 (2009) 61–80. doi:10.1109/tnn.2008.2005605
-
[28]
Pfaff, M
T. Pfaff, M. Fortunato, A. Sanchez-Gonzalez, P. W. Battaglia, Learning mesh-based simulation with graph networks, in: International Conference on Learning Representations, (ICLR), 2021
2021
-
[29]
M. Maurizi, C. Gao, F. Berto, Predicting stress, strain and deformation fields in materials and structures with graph neural networks, Scientific Reports 12 (2022) 21834. doi:10.1038/s41598-022-26424-3
- [30]
-
[31]
M. Fortunato, T. Pfaff, P. Wirnsberger, A. Pritzel, P. W. Battaglia, MultiScale MeshGraphNets, CoRR abs/2210.00612 (2022)
arXiv 2022
-
[32]
M. Raissi, P. Perdikaris, G. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational Physics 378 (2019) 686–707. doi:10.1016/j.jcp.2018.10.045
-
[33]
Horie, N
M. Horie, N. Mitsume, Physics-embedded neural networks: Graph neural PDE solvers with mixed boundary conditions, in: Advances in Neural Information Processing Systems 35: Annual Conference on Neural Informa- tion Processing Systems (NeurIPS), 2022
2022
-
[34]
Q. Hernández, A. Badías, F. Chinesta, E. Cueto, Thermodynamics-informed graph neural networks, IEEE Transactions on Artificial Intelligence 5 (2024) 967–976. doi:10.1109/tai.2022.3179681
-
[35]
Richter-Powell, Y
J. Richter-Powell, Y . Lipman, R. T. Q. Chen, Neural conservation laws: A divergence-free perspective, in: Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[36]
M. R. Guevara Garban, Y . Chemisky, M. Clément, E. Prulière, Physics-informed graph neural networks to reconstruct local fields considering finite strain hyperelasticity, International Journal for Numerical Methods in Engineering 126 (2025) e70193. doi:10.1002/nme.70193
-
[37]
M. Mozaffar, R. Bostanabad, W. Chen, K. Ehmann, J. Cao, M. A. Bessa, Deep learning predicts path-dependent plasticity, Proceedings of the National Academy of Sciences 116 (2019) 26414–26420. doi:10.1073/pnas.1 911815116
-
[38]
M. B. Gorji, M. Mozaffar, J. N. Heidenreich, J. Cao, D. Mohr, On the potential of recurrent neural networks for modeling path dependent plasticity, Journal of the Mechanics and Physics of Solids 143 (2020) 103972. doi:10.1016/j.jmps.2020.103972
-
[39]
F. Ghavamian, A. Simone, Accelerating multiscale finite element simulations of history-dependent materials using a recurrent neural network, Computer Methods in Applied Mechanics and Engineering (CMAME) 357 (2019) 112594. doi:10.1016/j.cma.2019.112594
-
[40]
L. Wu, V . D. Nguyen, N. G. Kilingar, L. Noels, A recurrent neural network-accelerated multi-scale model for elasto-plastic heterogeneous materials subjected to random cyclic and non-proportional loading paths, Computer Methods in Applied Mechanics and Engineering (CMAME) 369 (2020) 113234. doi:10.1016/j.cma.2020.1 13234. 35 PREPRINT
-
[42]
Y . Wu, Y . Li, B. He, J. Liu, M. Huang, Z. Li, A physics-informed GNN-LSTM framework for prediction of microvoid growth in heterogeneous polycrystals, Engineering Fracture Mechanics 336 (2026) 111938. doi:10.1 016/j.engfracmech.2026.111938
arXiv 2026
-
[43]
T. Kirchdoerfer, M. Ortiz, Data-driven computational mechanics, Computer Methods in Applied Mechanics and Engineering (CMAME) 304 (2016) 81–101. doi:10.1016/j.cma.2016.02.001
-
[44]
F. Masi, I. Stefanou, P. Vannucci, V . Maffi-Berthier, Thermodynamics-based artificial neural networks for con- stitutive modeling, Journal of the Mechanics and Physics of Solids 147 (2021) 104277. doi:10.1016/j.jmps .2020.104277
-
[45]
S. Im, J. Lee, M. Cho, Surrogate modeling of elasto-plastic problems via long short-term memory neural networks and proper orthogonal decomposition, Computer Methods in Applied Mechanics and Engineering (CMAME) 385 (2021) 114030. doi:10.1016/j.cma.2021.114030
-
[46]
M. A. Maia, I. B. C. M. Rocha, P. Kerfriden, F. P. van der Meer, Physically recurrent neural networks for path-dependent heterogeneous materials: Embedding constitutive models in a data-driven surrogate, Computer Methods in Applied Mechanics and Engineering (CMAME) 407 (2023) 115934. doi:10.1016/j.cma.2023.1 15934
-
[47]
Sanchez-Gonzalez, J
A. Sanchez-Gonzalez, J. Godwin, T. Pfaff, R. Ying, J. Leskovec, P. W. Battaglia, Learning to simulate complex physics with graph networks, in: Proceedings of the 37th International Conference on Machine Learning (ICML), volume 119, 2020, pp. 8459–8468
2020
-
[48]
Brandstetter, D
J. Brandstetter, D. E. Worrall, M. Welling, Message passing neural PDE solvers, in: International Conference on Learning Representations (ICLR), 2022
2022
-
[49]
Y . Hu, G. Zhou, M.-G. Lee, P. Wu, D. Li, A temporal graph neural network for cross-scale modelling of polycrystals considering microstructure interaction, International Journal of Plasticity 179 (2024) 104017. doi:10 .1016/j.ijplas.2024.104017
arXiv 2024
-
[50]
Z. Li, N. B. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, A. Anandkumar, Fourier neural operator for parametric partial differential equations, in: International Conference on Learning Representations (ICLR), 2021
2021
-
[51]
L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators, Nature Machine Intelligence 3 (2021) 218–229. doi:10.1038/s4 2256-021-00302-5
work page doi:10.1038/s4 2021
-
[52]
J. He, S. Kushwaha, J. Park, S. Koric, D. Abueidda, I. Jasiuk, Sequential deep operator networks (S-DeepONet) for predicting full-field solutions under time-dependent loads, Engineering Applications of Artificial Intelligence 127 (2024) 107258. doi:10.1016/j.engappai.2023.107258
-
[53]
N. B. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. M. Stuart, A. Anandkumar, Neural operator: Learning maps between function spaces with applications to PDEs, Journal of Machine Learning Research 24 (2023) 1–97
2023
-
[54]
P. M. Suquet, Elements of homogenization for inelastic solid mechanics, in: E. Sanchez-Palencia, A. Zaoui (Eds.), Homogenization Techniques for Composite Media, 1987, pp. 193–198
1987
-
[55]
G. Chatzigeorgiou, N. Charalambakis, Y . Chemisky, F. Meraghni, Periodic homogenization for fully coupled thermomechanical modeling of dissipative generalized standard materials, International Journal of Plasticity 81 (2016) 18–39. doi:10.1016/j.ijplas.2016.01.013
-
[56]
Lemaitre, J.-L
J. Lemaitre, J.-L. Chaboche, Mechanics of Solid Materials, Cambridge University Press, 1990
1990
-
[57]
J. C. Simo, T. J. R. Hughes, Computational Inelasticity, Springer-Verlag, New York, 1998
1998
-
[58]
Hochreiter, J
S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural computation 9 (1997) 1735–1780. doi:10.116 2/neco.1997.9.8.1735
1997
-
[59]
S. Hochreiter, The vanishing gradient problem during learning recurrent neural nets and problem solutions, International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 6 (1998) 107–116. doi:10.114 2/S0218488598000094
1998
-
[60]
Danoun, Numerical simulation of heterogeneous materials combining Artificial Intelligence and physics- based modeling, Ph.D
A. Danoun, Numerical simulation of heterogeneous materials combining Artificial Intelligence and physics- based modeling, Ph.D. thesis, Université de Bordeaux, 2022. 36 PREPRINT
2022
-
[61]
Prulière, Y
E. Prulière, Y . Chemisky, 3MAH : Un ensemble de librairies pour analyser le comportement complexe de matériaux hétérogènes, in: Colloque National en Calcul des Structures (CSMA), 2023
2023
-
[62]
Belytschko, W
T. Belytschko, W. K. Liu, B. Moran, Nonlinear Finite Elements for Continua and Structures, John Wiley & Sons, 2000
2000
-
[63]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, in: International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015
2015
-
[64]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, S. Chintala, PyTorch: An imperative style, high-performance deep learning library, in: Advances in Neural Information Processing System...
2019
-
[65]
M. Fey, J. E. Lenssen, Fast graph representation learning with PyTorch Geometric, in: ICLR Workshop on Representation Learning on Graphs and Manifolds, 2019
2019
-
[66]
S. Wang, Y . Teng, P. Perdikaris, Understanding and mitigating gradient flow pathologies in physics-informed neural networks, SIAM Journal on Scientific Computing 43 (2021) A3055–A3081. doi:10.1137/20M1318043
-
[67]
S. Wang, X. Yu, P. Perdikaris, When and why PINNs fail to train: A neural tangent kernel perspective, Journal of Computational Physics 449 (2022) 110768. doi:10.1016/j.jcp.2021.110768
-
[68]
Z. Chen, V . Badrinarayanan, C.-Y . Lee, A. Rabinovich, GradNorm: Gradient normalization for adaptive loss balancing in deep multitask networks, in: Proceedings of the 35th International Conference on Machine Learning (ICML), volume 80, 2018, pp. 794–803
2018
-
[69]
R. Bischof, M. A. Kraus, Multi-objective loss balancing for physics-informed deep learning, Computer Methods in Applied Mechanics and Engineering (CMAME) 439 (2025) 117914. doi:10.1016/j.cma.2025.117914
-
[70]
I. T. Jolliffe, Principal Component Analysis, 2nd ed., Springer, 2002. doi:10.1007/b98835
-
[71]
van der Maaten, G
L. van der Maaten, G. Hinton, Visualizing data using t-SNE, Journal of Machine Learning Research 9 (2008) 2579–2605
2008
-
[72]
Schroeder, K
W. Schroeder, K. Martin, B. Lorensen, The Visualization Toolkit, 4th ed., Kitware, 2006. 37
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.