A History-Aware Visually Grounded Critic for Computer Use Agents
Pith reviewed 2026-06-27 13:18 UTC · model grok-4.3
The pith
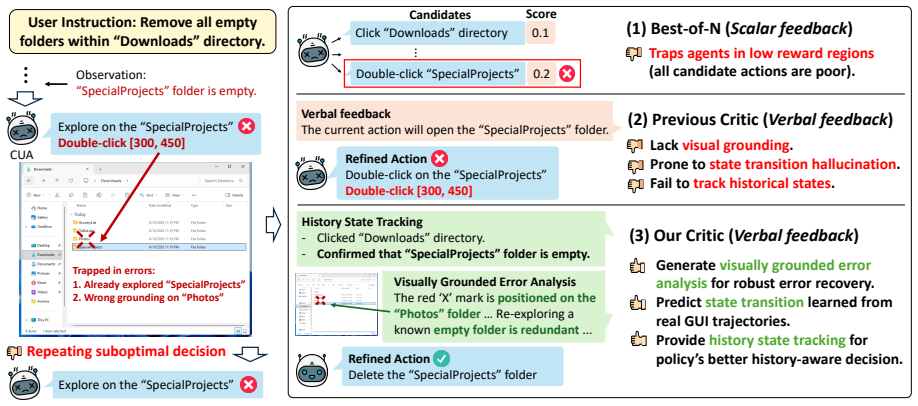
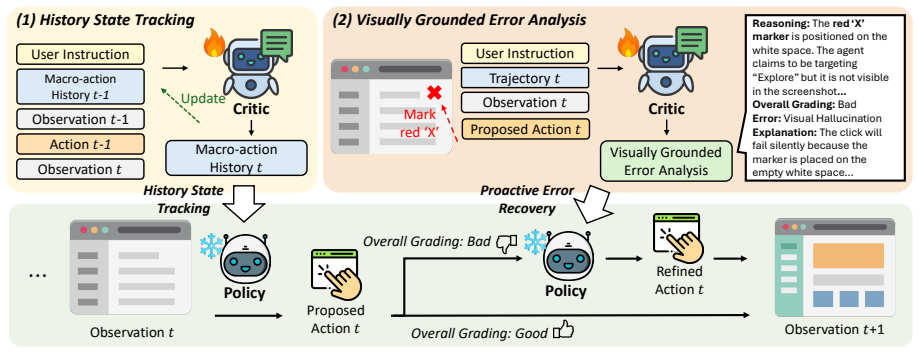
HiViG integrates a multimodal critic into computer-use agents to supply macro-action history summaries and visually grounded critiques that verify execution coordinates against screenshots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
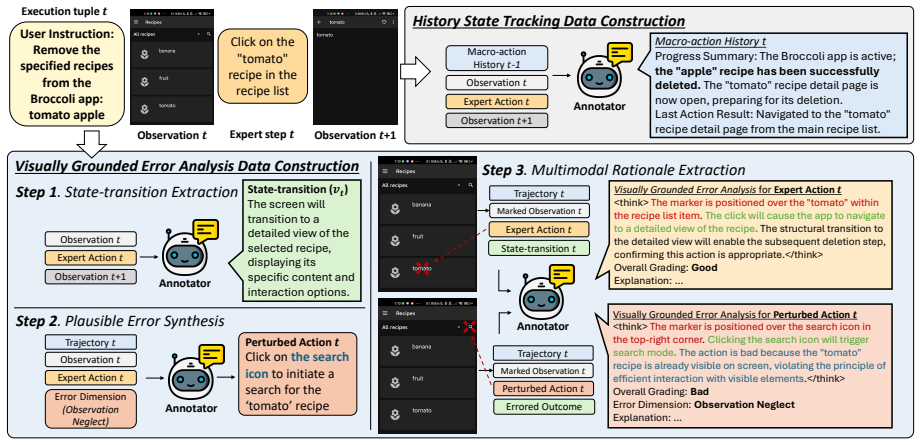
The paper claims that a multimodal critic trained on real GUI trajectories can abstract interaction history into macro-action summaries and evaluate raw actions by comparing their coordinates to the current screenshot, and that inserting both signals into the policy loop at test time raises success rates on long-horizon tasks without task-specific retraining.
What carries the argument
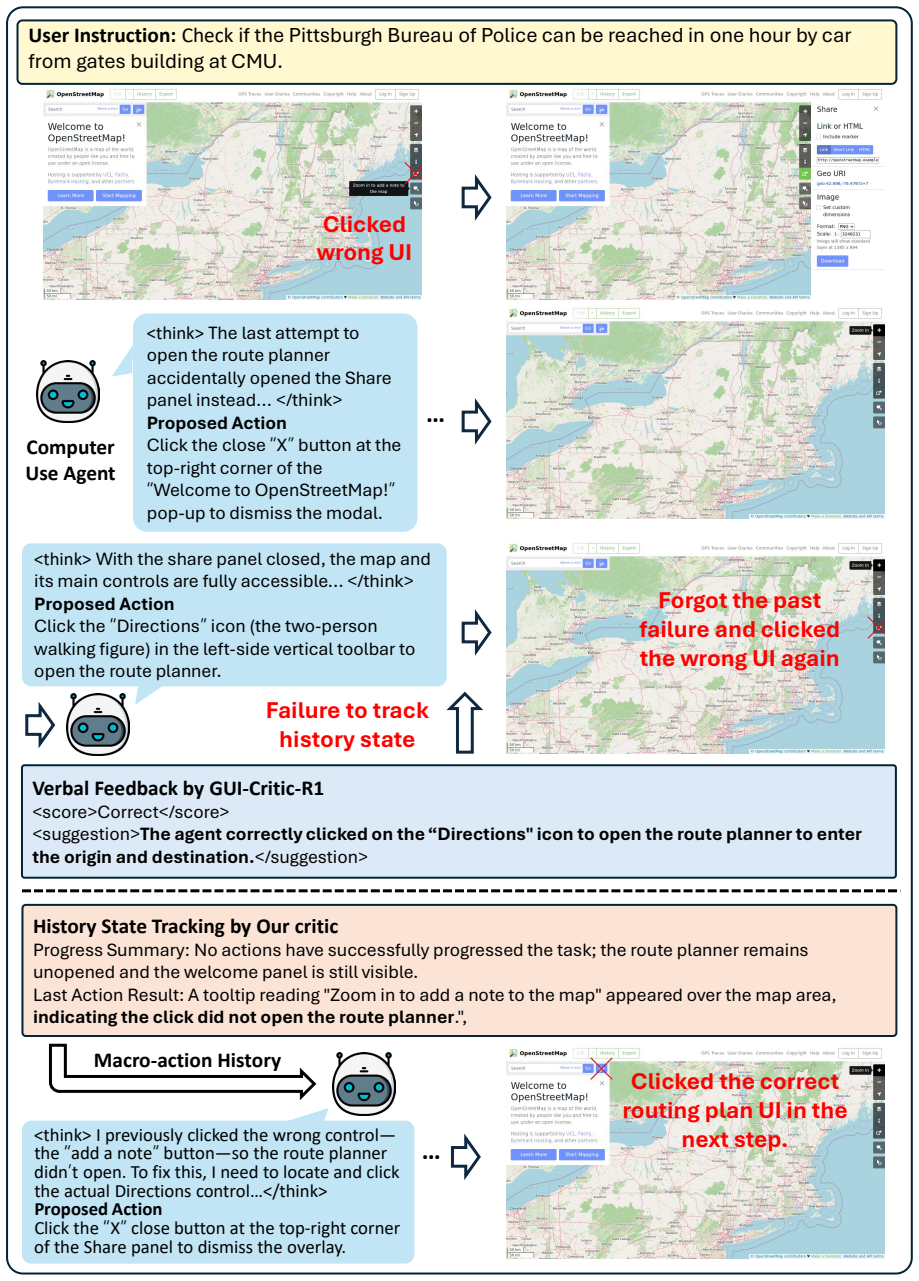
The HiViG multimodal critic that produces macro-action history summaries of completed achievements and visually grounded critiques that check execution coordinates against the live screenshot.
If this is right
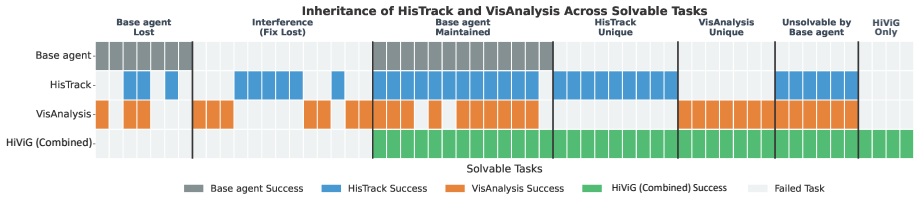
- Macro-action history prevents agents from repeating completed steps or losing track in extended tasks.
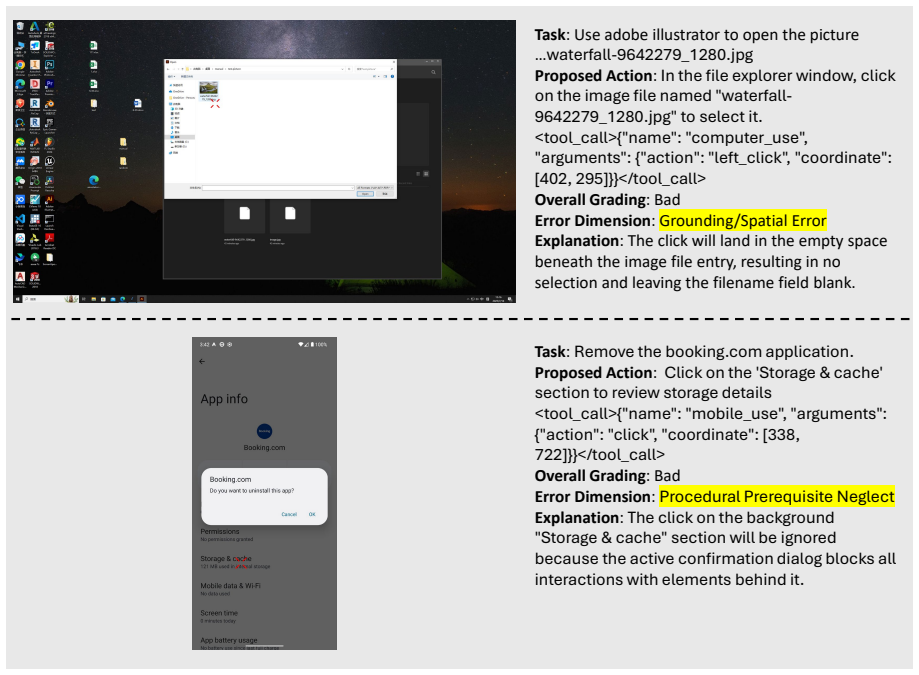
- Visually grounded critique intercepts coordinate errors before execution occurs.
- Both signals together enable better test-time scaling on long-horizon GUI work.
- The framework generalizes across web, mobile, and desktop platforms without platform-specific retraining.
- Performance gains appear for multiple base models, including Qwen3-VL-32B and Gemini-3-Flash.
Where Pith is reading between the lines
- The same critic pattern could be tested on non-GUI agents that also operate over long sequences of visual observations.
- Online updating of the critic during a single task run might further reduce drift between training and deployment distributions.
- Combining compact verbal history with pixel-level verification may prove more efficient than scaling the underlying policy alone.
- The approach implies that test-time visual feedback can substitute for some amount of additional policy training data.
Load-bearing premise
The critic trained on collected GUI trajectories will generate reliable history summaries and accurate visual grounding judgments that transfer to the benchmark test distributions without extra fine-tuning.
What would settle it
Running the same agents on a fresh collection of long-horizon GUI tasks drawn from distributions visibly different from the training trajectories and finding no improvement or a drop in success rate would falsify the generalization claim.
Figures




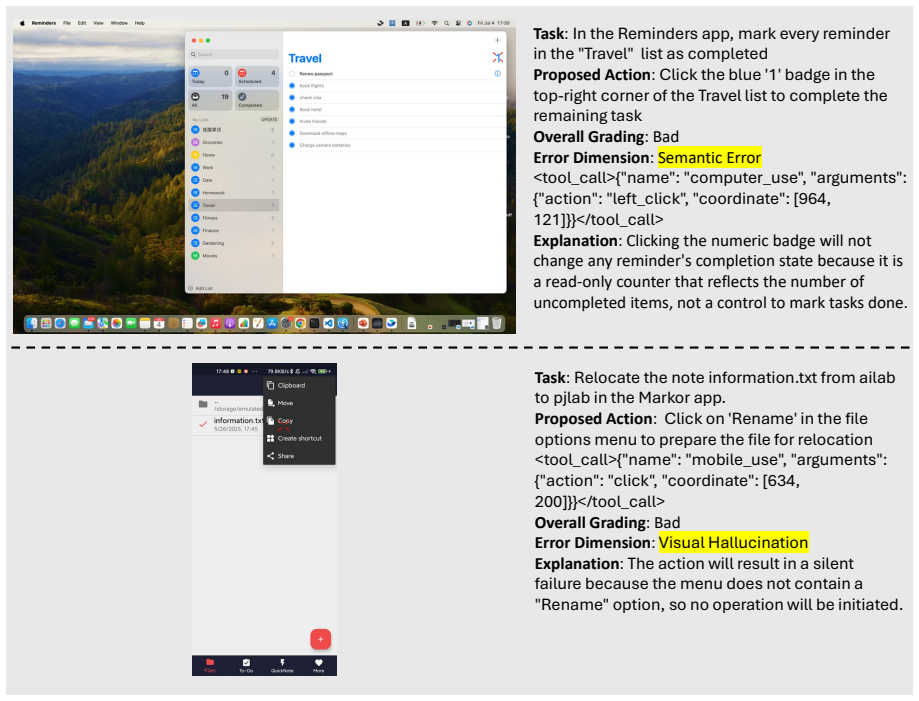
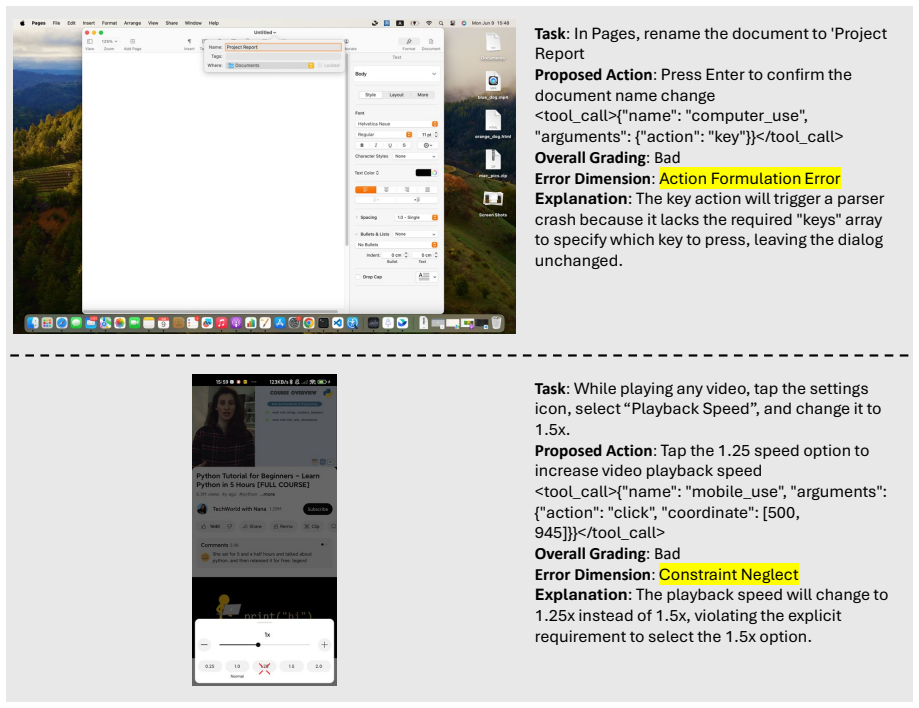
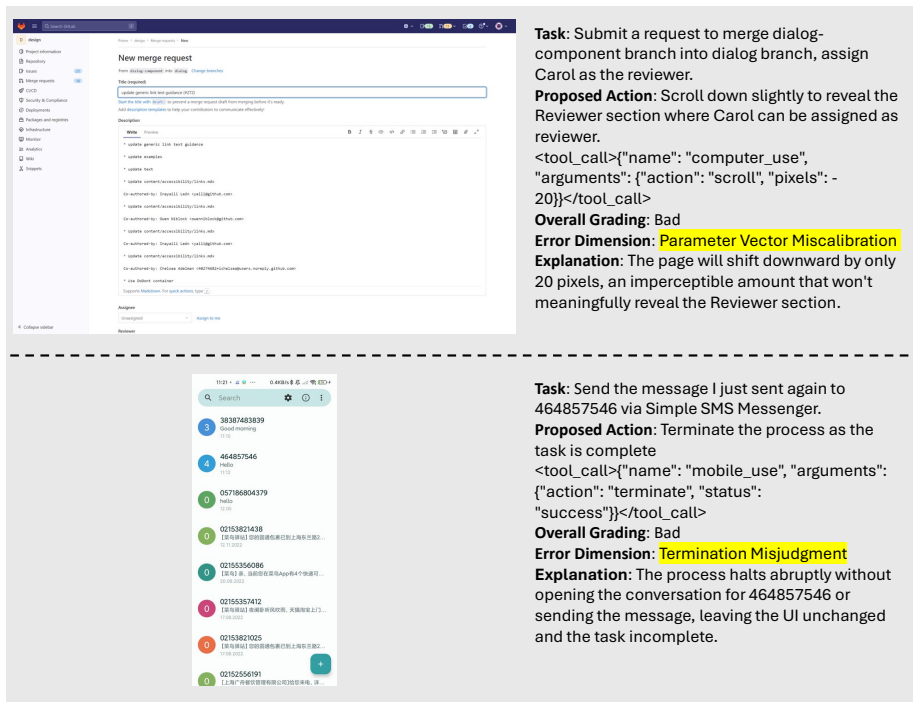
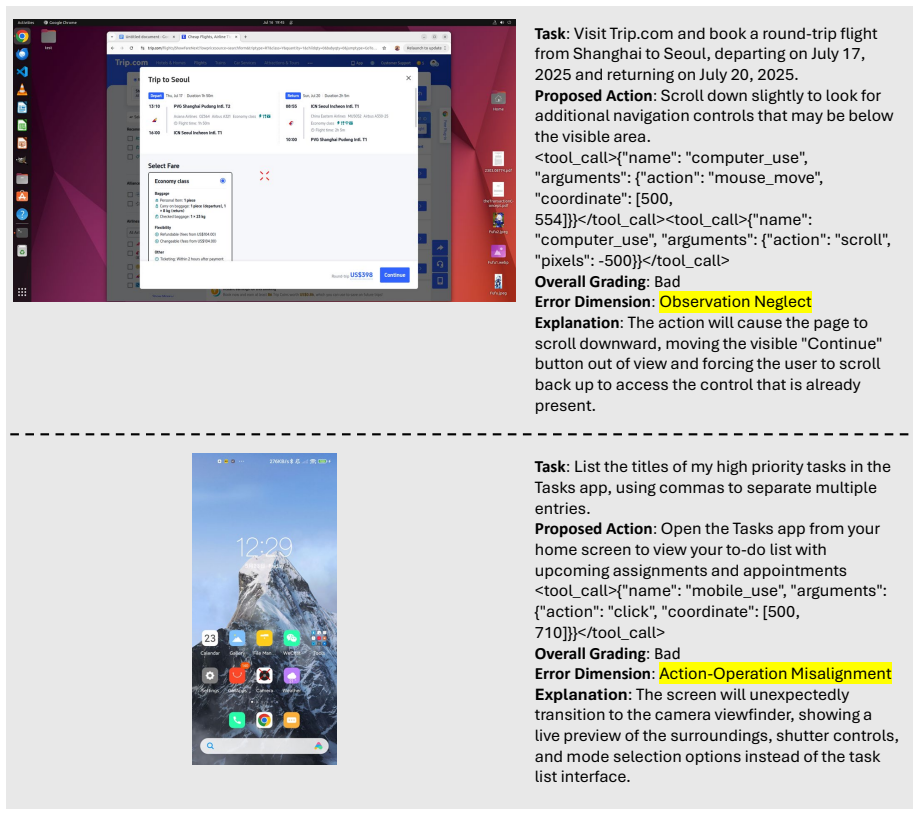
read the original abstract
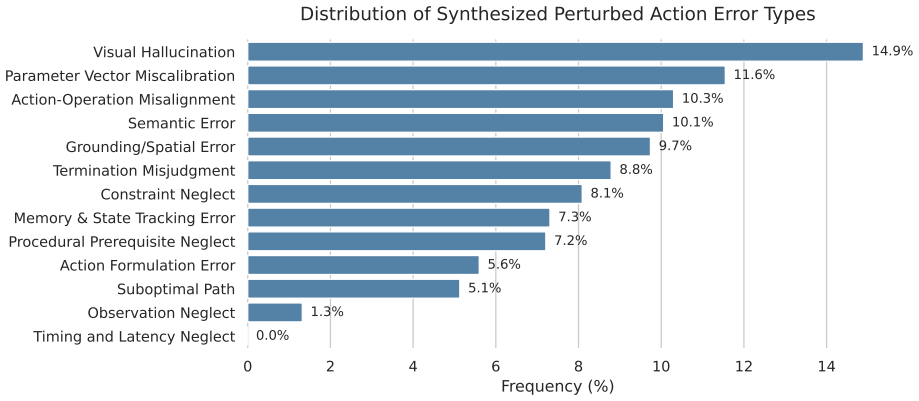
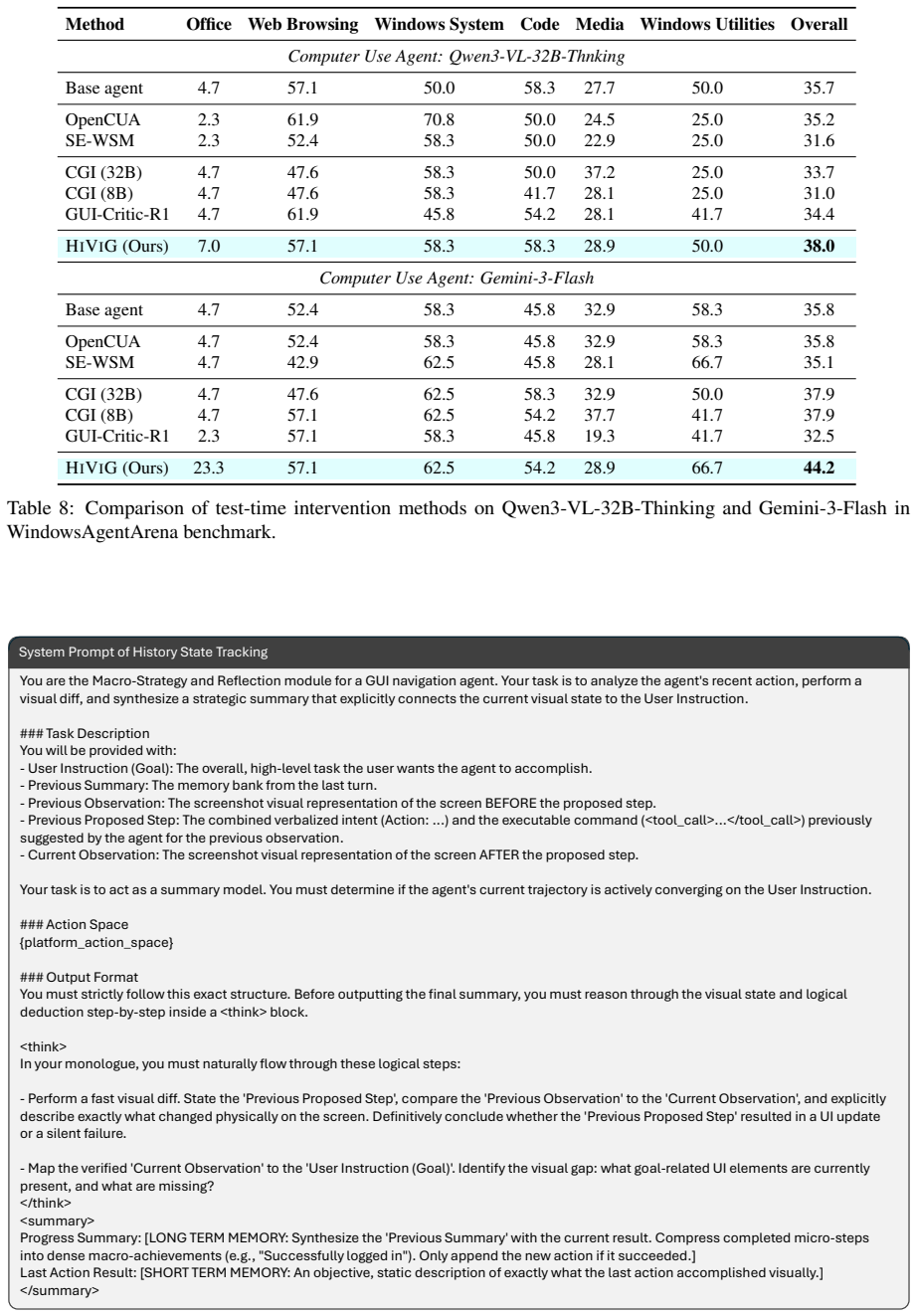
Various test-time interventions for Computer Use Agents (CUAs), including critic models, have been developed to improve performance through pre-execution action evaluation in complex Graphical User Interface (GUI) environments. However, existing critics suffer from two key limitations: they (1) focus primarily on short-sighted decision loops (e.g., forgetting earlier actions) and (2) lack the visual grounding needed to detect flawed actions (e.g., clicking wrong UI elements). To address these, we introduce HiViG, a History-aware Visually Grounded test-time framework, built around a multimodal critic trained on real GUI trajectories to abstract past interactions into a compact record and to evaluate actions with visual grounding. At test time, HiViG integrates the critic into the policy decision loop to provide macro-action history, which summarizes the policy's completed achievements, and visually grounded critique, which verifies raw execution coordinates against the current screenshot to intercept errors before execution. Across web, mobile, and desktop benchmarks, HiViG consistently outperforms existing scalar and verbal critics, improving average success rates over the strongest baseline by 5.8% for Qwen3-VL-32B and 9.0% for Gemini-3-Flash, and demonstrates strong cross-platform generalization. Ablations show that macro-action history mitigates short-sighted planning and visually grounded critique reduces execution errors, with both components being critical for test-time scaling in long-horizon GUI tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HiViG, a history-aware visually grounded test-time critic framework for Computer Use Agents. A multimodal critic is trained on real GUI trajectories to emit compact macro-action history summaries of past achievements and coordinate-level visual critiques that verify execution against the current screenshot. At inference, these are integrated into the policy loop to mitigate short-sighted planning and intercept execution errors. The abstract reports that HiViG outperforms existing scalar and verbal critics across web, mobile, and desktop benchmarks, raising average success rates by 5.8% (Qwen3-VL-32B) and 9.0% (Gemini-3-Flash) over the strongest baseline, with ablations indicating both components are necessary and with claimed strong cross-platform generalization.
Significance. If the reported gains prove robust under proper statistical controls and distribution-shift analysis, the work would usefully extend test-time intervention methods for long-horizon GUI agents by explicitly addressing history forgetting and visual grounding failures. The inclusion of component ablations is a constructive element of the evaluation design.
major comments (3)
- [Abstract] Abstract: the headline improvements of 5.8% and 9.0% are stated without any mention of statistical significance testing, error bars, number of runs, or variance across seeds; this information is required to determine whether the deltas reliably exceed baseline variability.
- [Abstract] Abstract: the claim that the multimodal critic generalizes across platforms rests on the unexamined assumption that training trajectories sufficiently cover the test distributions of the three benchmarks; no quantitative overlap analysis, per-benchmark error breakdown, or OOD failure characterization is supplied, leaving open the possibility that measured gains partly reflect reduced distribution shift rather than a robust test-time mechanism.
- [Abstract] Abstract: the ablation statement that “both components are critical” is presented without details on whether the scalar/verbal baseline critics were trained or fine-tuned with equivalent data volume and compute; unequal training regimes would confound attribution of the observed lifts to the history and grounding modules.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical reporting, generalization claims, and ablation controls. We address each point below and will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline improvements of 5.8% and 9.0% are stated without any mention of statistical significance testing, error bars, number of runs, or variance across seeds; this information is required to determine whether the deltas reliably exceed baseline variability.
Authors: We agree that explicit statistical details strengthen interpretability. The full manuscript (Section 4 and Appendix B) reports all results as means over 3 random seeds with standard deviations; the reported deltas consistently exceed observed variance and pass paired t-tests at p<0.05 on the primary benchmarks. Due to abstract length limits we will add a concise clause noting “results averaged over 3 seeds, improvements exceed variance (p<0.05)” while retaining detailed tables and error bars in the body. revision: yes
-
Referee: [Abstract] Abstract: the claim that the multimodal critic generalizes across platforms rests on the unexamined assumption that training trajectories sufficiently cover the test distributions of the three benchmarks; no quantitative overlap analysis, per-benchmark error breakdown, or OOD failure characterization is supplied, leaving open the possibility that measured gains partly reflect reduced distribution shift rather than a robust test-time mechanism.
Authors: We acknowledge the value of explicit distribution-shift analysis. Training trajectories were collected across web, mobile, and desktop GUI tasks that overlap with the evaluation benchmarks, and HiViG is applied zero-shot at test time without policy retraining. In revision we will add (i) a per-benchmark success breakdown, (ii) a brief overlap discussion based on action-type and UI-element statistics, and (iii) qualitative OOD failure cases in Section 5.3 to better isolate the contribution of the test-time critic. revision: yes
-
Referee: [Abstract] Abstract: the ablation statement that “both components are critical” is presented without details on whether the scalar/verbal baseline critics were trained or fine-tuned with equivalent data volume and compute; unequal training regimes would confound attribution of the observed lifts to the history and grounding modules.
Authors: The scalar and verbal baselines are reproduced from prior published work and evaluated under their original training regimes to enable direct comparison with existing methods. Our internal ablations compare variants of the HiViG critic (history-only, grounding-only, full) trained on identical trajectory data and compute; these controlled ablations isolate the contribution of each module. We will explicitly state this distinction in the revised Section 4.3 and caption of the ablation table. revision: yes
Circularity Check
No circularity: empirical benchmark results with no self-referential derivations
full rationale
The paper describes an empirical training and test-time framework for a multimodal critic on GUI trajectories, with performance measured as success-rate deltas on held-out web/mobile/desktop benchmarks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. The central claims rest on external benchmark measurements rather than reducing by construction to inputs defined inside the paper. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhaoyang Liu and JingJing Xie and Zichen Ding and Zehao Li and Bowen Yang and Zhenyu Wu and Xuehui Wang and Qiushi Sun and Shi Liu and Weiyun Wang and Shenglong Ye and Qingyun Li and Xuan Dong and Yue Yu and Chenyu Lu and YunXiang Mo and Yao Yan and Zeyue Tian and Xiao Zhang and Yuan Huang and Yiqian Liu and Weijie Su and Gen Luo and Xiangyu Yue and Biqin...
-
[2]
arXiv preprint arXiv:2602.16855 , year =
Haiyang Xu and Xi Zhang and Haowei Liu and Junyang Wang and Zhaozai Zhu and Shengjie Zhou and Xuhao Hu and Feiyu Gao and Junjie Cao and Zihua Wang and Zhiyuan Chen and Jitong Liao and Qi Zheng and Jiahui Zeng and Ze Xu and Shuai Bai and Junyang Lin and Jingren Zhou and Ming Yan , title =. arXiv preprint arXiv:2602.16855 , year =
-
[3]
2025 , url =
Qwen3-VL Technical Report , journal =. 2025 , url =
2025
-
[4]
arXiv preprint arXiv:2501.12326 , year =
Yujia Qin and Yining Ye and Junjie Fang and Haoming Wang and Shihao Liang and Shizuo Tian and Junda Zhang and Jiahao Li and Yunxin Li and Shijue Huang and Wanjun Zhong and Kuanye Li and Jiale Yang and Yu Miao and Woyu Lin and Longxiang Liu and Xu Jiang and Qianli Ma and Jingyu Li and Xiaojun Xiao and Kai Cai and Chuang Li and Yaowei Zheng and Chaolin Jin ...
-
[5]
Charles and Zhilin Yang and Tao Yu , title =
Xinyuan Wang and Bowen Wang and Dunjie Lu and Junlin Yang and Tianbao Xie and Junli Wang and Jiaqi Deng and Xiaole Guo and Yiheng Xu and Chen Henry Wu and Zhennan Shen and Zhuokai Li and Ryan Li and Xiaochuan Li and Junda Chen and Boyuan Zheng and Peihang Li and Fangyu Lei and Ruisheng Cao and Yeqiao Fu and Dongchan Shin and Martin Shin and Jiarui Hu and ...
-
[6]
arXiv preprint arXiv:2511.19663 , volume =
Ahmed Awadallah and Yash Lara and Raghav Magazine and Hussein Mozannar and Akshay Nambi and Yash Pandya and Aravind Rajeswaran and Corby Rosset and Alexey Taymanov and Vibhav Vineet and Spencer Whitehead and Andrew Zhao , title =. arXiv preprint arXiv:2511.19663 , volume =. 2025 , url =
arXiv 2025
-
[7]
Wenyi Hong and Weihan Wang and Qingsong Lv and Jiazheng Xu and Wenmeng Yu and Junhui Ji and Yan Wang and Zihan Wang and Yuxiao Dong and Ming Ding and Jie Tang , title =
-
[8]
arXiv preprint arXiv:2402.07945 , year =
Runliang Niu and Jindong Li and Shiqi Wang and Yali Fu and Xiyu Hu and Xueyuan Leng and He Kong and Yi Chang and Qi Wang , title =. arXiv preprint arXiv:2402.07945 , year =
-
[9]
Yuhao Yang and Zhen Yang and Zi. UltraCUA:. arXiv preprint arXiv:2510.17790 , year =
-
[10]
Vardaan Pahuja and Yadong Lu and Corby Rosset and Boyu Gou and Arindam Mitra and Spencer Whitehead and Yu Su and Ahmed Hassan Awadallah , title =
-
[11]
Yiheng Xu and Dunjie Lu and Zhennan Shen and Junli Wang and Zekun Wang and Yuchen Mao and Caiming Xiong and Tao Yu , title =
-
[12]
TongUI: Internet-Scale Trajectories from Multimodal Web Tutorials for Generalized
Bofei Zhang and Zirui Shang and Zhi Gao and Wang Zhang and Rui Xie and Xiaojian Ma and Tao Yuan and Xinxiao Wu and Song. TongUI: Internet-Scale Trajectories from Multimodal Web Tutorials for Generalized
-
[13]
arXiv preprint arXiv:2601.07779 , year =
Bowen Yang and Kaiming Jin and Zhenyu Wu and Zhaoyang Liu and Qiushi Sun and Zehao Li and JingJing Xie and Zhoumianze Liu and Fangzhi Xu and Kanzhi Cheng and Qingyun Li and Yian Wang and Yu Qiao and Zun Wang and Zichen Ding , title =. arXiv preprint arXiv:2601.07779 , year =
-
[14]
arXiv preprint arXiv:2604.08516 , year =
Tanmay Gupta and Piper Wolters and Zixian Ma and Peter Sushko and Rock Yuren Pang and Diego Llanes and Yue Yang and Taira Anderson and Boyuan Zheng and Zhongzheng Ren and Harsh Trivedi and Taylor Blanton and Caleb Ouellette and Winson Han and Ali Farhadi and Ranjay Krishna , title=. arXiv preprint arXiv:2604.08516 , year =
-
[15]
2025 , journal=
History-Aware Reasoning for GUI Agents , author=. 2025 , journal=
2025
-
[16]
arXiv preprint arXiv:2510.27210 , year=
GUI-Rise: Structured Reasoning and History Summarization for GUI Navigation , author=. arXiv preprint arXiv:2510.27210 , year=
-
[18]
arXiv preprint arXiv:2503.19786 , year=
Gemma 3 Technical Report , author=. arXiv preprint arXiv:2503.19786 , year=
-
[19]
Look Before You Leap:
Yuyang Wanyan and Xi Zhang and Haiyang Xu and Haowei Liu and Junyang Wang and Jiabo Ye and Yutong Kou and Ming. Look Before You Leap:
-
[20]
arXiv preprint arXiv:2511.21631 , year =
Ruihan Yang and Fanghua Ye and Jian Li and Siyu Yuan and Yikai Zhang and Zhaopeng Tu and Xiaolong Li and Deqing Yang , title =. arXiv preprint arXiv:2511.21631 , year =
-
[21]
Zhiheng Xi and Dingwen Yang and Jixuan Huang and Jiafu Tang and Guanyu Li and Yiwen Ding and Wei He and Boyang Hong and Shihan Dou and Wenyu Zhan and Xiao Wang and Rui Zheng and Tao Ji and Xiaowei Shi and Yitao Zhai and Rongxiang Weng and Jingang Wang and Xunliang Cai and Tao Gui and Zuxuan Wu and Qi Zhang and Xipeng Qiu and Xuanjing Huang and Yu. Enhanci...
-
[22]
arXiv preprint arXiv:2602.08995 , year =
Yuting Ning and Jaylen Jones and Zhehao Zhang and Chentao Ye and Weitong Ruan and Junyi Li and Rahul Gupta and Huan Sun , title =. arXiv preprint arXiv:2602.08995 , year =
-
[23]
2025 , eprint=
WebATLAS: An LLM Agent with Experience-Driven Memory and Action Simulation , author=. 2025 , eprint=
2025
-
[24]
arXiv preprint arXiv:2507.15024 , year =
Qiaoyu Tang and Hao Xiang and Le Yu and Bowen Yu and Hongyu Lin and Yaojie Lu and Xianpei Han and Le Sun and Junyang Lin , title =. arXiv preprint arXiv:2507.15024 , year =
-
[25]
arXiv preprint arXiv:2506.08012 , year =
Penghao Wu and Shengnan Ma and Bo Wang and Jiaheng Yu and Lewei Lu and Ziwei Liu , title =. arXiv preprint arXiv:2506.08012 , year =
-
[26]
arXiv preprint arXiv:2602.11124 , year =
Tianyi Xiong and Shihao Wang and Guilin Liu and Yi Dong and Ming Li and Heng Huang and Jan Kautz and Zhiding Yu , title =. arXiv preprint arXiv:2602.11124 , year =
-
[27]
arXiv preprint arXiv:2509.23738 , year =
Cong Chen and Kaixiang Ji and Hao Zhong and Muzhi Zhu and Anzhou Li and Guo Gan and Ziyuan Huang and Cheng Zou and Jiajia Liu and Jingdong Chen and Hao Chen and Chunhua Shen , title =. arXiv preprint arXiv:2509.23738 , year =
-
[28]
arXiv preprint arXiv:2505.21496 , year =
Han Xiao and Guozhi Wang and Yuxiang Chai and Zimu Lu and Weifeng Lin and Hao He and Lue Fan and Liuyang Bian and Rui Hu and Liang Liu and Shuai Ren and Yafei Wen and Xiaoxin Chen and Aojun Zhou and Hongsheng Li , title =. arXiv preprint arXiv:2505.21496 , year =
-
[29]
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents , journal =
Hyungjoo Chae and Sunghwan Kim and Junhee Cho and Seungone Kim and Seungjun Moon and Gyeom Hwangbo and Dongha Lim and Minjin Kim and Yeonjun Hwang and Minju Gwak and Dongwook Choi and Minseok Kang and Gwanhoon Im and ByeongUng Cho and Hyojun Kim and Jun Hee Han and Taeyoon Kwon and Minju Kim and Beong. Web-Shepherd: Advancing PRMs for Reinforcing Web Agen...
2025
-
[30]
arXiv preprint arXiv:2601.21872 , year =
Yao Zhang and Shijie Tang and Zeyu Li and Zhen Han and Volker Tresp , title =. arXiv preprint arXiv:2601.21872 , year =
-
[31]
arXiv preprint arXiv:2603.10178 , year=
Video-Based Reward Modeling for Computer-Use Agents , author=. arXiv preprint arXiv:2603.10178 , year=
-
[32]
arXiv preprint arXiv:2602.09856 , year =
Yuhao Zheng and Li'an Zhong and Yi Wang and Rui Dai and Kaikui Liu and Xiangxiang Chu and Linyuan Lv and Philip Torr and Kevin Qinghong Lin , title =. arXiv preprint arXiv:2602.09856 , year =
-
[33]
Hao Bai and Yifei Zhou and Li Erran Li and Sergey Levine and Aviral Kumar , title =
-
[34]
Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation , booktitle = iclr, year =
Hyungjoo Chae and Namyoung Kim and Kai Tzu. Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation , booktitle = iclr, year =
-
[35]
arXiv preprint arXiv:2510.11892 , year =
Kai Mei and Jiang Guo and Shuaichen Chang and Mingwen Dong and Dongkyu Lee and Xing Niu and Jiarong Jiang , title =. arXiv preprint arXiv:2510.11892 , year =
-
[36]
arXiv preprint arXiv:2601.04035 , year =
Yilin Cao and Yufeng Zhong and Zhixiong Zeng and Liming Zheng and Jing Huang and Haibo Qiu and Peng Shi and Wenji Mao and Wan Guanglu , title =. arXiv preprint arXiv:2601.04035 , year =
-
[37]
arXiv preprint arXiv:2504.13936 , year =
Dezhao Luo and Bohan Tang and Kang Li and Georgios Papoudakis and Jifei Song and Shaogang Gong and Jianye Hao and Jun Wang and Kun Shao , title=. arXiv preprint arXiv:2504.13936 , year =
-
[38]
Mitchell , title =
Yue Wu and Yewen Fan and Paul Pu Liang and Amos Azaria and Yuanzhi Li and Tom M. Mitchell , title =
-
[39]
Ho and Carl Yang and Dong Yu , title =
Ran Xu and Kaixin Ma and Wenhao Yu and Hongming Zhang and Joyce C. Ho and Carl Yang and Dong Yu , title =
-
[40]
arXiv preprint arXiv:2507.08800 , year =
Luke Rivard and Sun Sun and Hongyu Guo and Wenhu Chen and Yuntian Deng , title =. arXiv preprint arXiv:2507.08800 , year =
-
[41]
Generative Visual Code Mobile World Models , journal =
Woosung Koh and Sungjun Han and Segyu Lee and Se. Generative Visual Code Mobile World Models , journal =. 2026 , url =
2026
-
[42]
Inan and Robert Sim and Saravan Rajmohan and Qingwei Lin and Dongmei Zhang , title =
Yiming Guan and Rui Yu and John Zhang and Lu Wang and Chaoyun Zhang and Liqun Li and Bo Qiao and Si Qin and He Huang and Fangkai Yang and Pu Zhao and Lukas Wutschitz and Samuel Kessler and Huseyin A. Inan and Robert Sim and Saravan Rajmohan and Qingwei Lin and Dongmei Zhang , title =. arXiv preprint arXiv:2602.17365 , year =
-
[43]
arXiv preprint arXiv:2509.23263 , year =
Tao Xiong and Xavier Hu and Yurun Chen and Yuhang Liu and Changqiao Wu and Pengzhi Gao and Wei Liu and Jian Luan and Shengyu Zhang , title =. arXiv preprint arXiv:2509.23263 , year =
-
[44]
arXiv preprint arXiv:2510.18596 , year =
Haojia Lin and Xiaoyu Tan and Yulei Qin and Zihan Xu and Yuchen Shi and Zongyi Li and Gang Li and Shaofei Cai and Siqi Cai and Chaoyou Fu and Ke Li and Xing Sun , title =. arXiv preprint arXiv:2510.18596 , year =
-
[45]
2025 , journal =
SEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience , author=. 2025 , journal =
2025
-
[46]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),
Hongliang He and Wenlin Yao and Kaixin Ma and Wenhao Yu and Yong Dai and Hongming Zhang and Zhenzhong Lan and Dong Yu , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),
-
[47]
Xiang Deng and Yu Gu and Boyuan Zheng and Shijie Chen and Samual Stevens and Boshi Wang and Huan Sun and Yu Su , title =
-
[48]
Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , title =
Shuyan Zhou and Frank F. Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , title =
-
[49]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks , booktitle = acl, year =
Jing Yu Koh and Robert Lo and Lawrence Jang and Vikram Duvvur and Ming Chong Lim and Po. VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks , booktitle = acl, year =
-
[50]
Rogerio Bonatti and Dan Zhao and Francesco Bonacci and Dillon Dupont and Sara Abdali and Yinheng Li and Yadong Lu and Justin Wagle and Kazuhito Koishida and Arthur Bucker and Lawrence Keunho Jang and Zheng Hui , title =
-
[51]
Yifan Xu and Xiao Liu and Xueqiao Sun and Siyi Cheng and Hao Yu and Hanyu Lai and Shudan Zhang and Dan Zhang and Jie Tang and Yuxiao Dong , title =
-
[52]
Bishop and Wei Li and Folawiyo Campbell
Christopher Rawles and Sarah Clinckemaillie and Yifan Chang and Jonathan Waltz and Gabrielle Lau and Marybeth Fair and Alice Li and William E. Bishop and Wei Li and Folawiyo Campbell. AndroidWorld:
-
[53]
Tianbao Xie and Danyang Zhang and Jixuan Chen and Xiaochuan Li and Siheng Zhao and Ruisheng Cao and Toh Jing Hua and Zhoujun Cheng and Dongchan Shin and Fangyu Lei and Yitao Liu and Yiheng Xu and Shuyan Zhou and Silvio Savarese and Caiming Xiong and Victor Zhong and Tao Yu , title =
-
[54]
ScreenSpot-Pro:
Kaixin Li and Ziyang Meng and Hongzhan Lin and Ziyang Luo and Yuchen Tian and Jing Ma and Zhiyong Huang and Tat. ScreenSpot-Pro:. Proceedings of the 33rd
-
[55]
arXiv preprint arXiv:2604.17284 , year=
HalluClear: Diagnosing, Evaluating and Mitigating Hallucinations in GUI Agents , author=. arXiv preprint arXiv:2604.17284 , year=
-
[56]
Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik Narasimhan and Ofir Press , title =
John Yang and Carlos E. Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik Narasimhan and Ofir Press , title =
-
[57]
arXiv preprint arXiv:2509.22638 , year =
Renjie Luo and Zichen Liu and Xiangyan Liu and Chao Du and Min Lin and Wenhu Chen and Wei Lu and Tianyu Pang , title =. arXiv preprint arXiv:2509.22638 , year =
-
[58]
Policy Improvement using Language Feedback Models , booktitle = neurips, year =
Victor Zhong and Dipendra Misra and Xingdi Yuan and Marc. Policy Improvement using Language Feedback Models , booktitle = neurips, year =
-
[59]
arXiv preprint arXiv:2505.13934 , year =
Jialong Wu and Shaofeng Yin and Ningya Feng and Mingsheng Long , title =. arXiv preprint arXiv:2505.13934 , year =
-
[60]
Planning with Reasoning using Vision Language World Model , journal =
Delong Chen and Th. Planning with Reasoning using Vision Language World Model , journal =. 2025 , url =
2025
-
[61]
Philippe Laban and Hiroaki Hayashi and Yingbo Zhou and Jennifer Neville , booktitle=iclr, year=
-
[62]
ICML , year=
World of Bits: An Open-Domain Platform for Web-Based Agents , author=. ICML , year=
-
[63]
ICLR , year=
Reinforcement Learning on Web Interfaces using Workflow-Guided Exploration , author=. ICLR , year=
-
[64]
NeurIPS , year=
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. NeurIPS , year=
-
[65]
NeurIPS , year=
Policy Gradient Methods for Reinforcement Learning with Function Approximation , author=. NeurIPS , year=
-
[66]
ICML , year=
Asynchronous Methods for Deep Reinforcement Learning , author=. ICML , year=
-
[67]
arXiv preprint arXiv:2310.11441 , year =
Jianwei Yang and Hao Zhang and Feng Li and Xueyan Zou and Chunyuan Li and Jianfeng Gao , title =. arXiv preprint arXiv:2310.11441 , year =
-
[68]
arXiv preprint arXiv:2510.00615 , year =
ACON: Optimizing Context Compression for Long-horizon LLM Agents , author=. arXiv preprint arXiv:2510.00615 , year =
-
[69]
arXiv preprint arXiv:2508.07976 , year =
Jiaxuan Gao and Wei Fu and Minyang Xie and Shusheng Xu and Chuyi He and Zhiyu Mei and Banghua Zhu and Yi Wu , title =. arXiv preprint arXiv:2508.07976 , year =
-
[70]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.