Unifying Local Communications and Local Updates for LLM Pretraining
Pith reviewed 2026-06-27 14:06 UTC · model grok-4.3
The pith
GASLoC generalizes the outer optimizer to gossip communication for competitive decentralized LLM pretraining with local steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
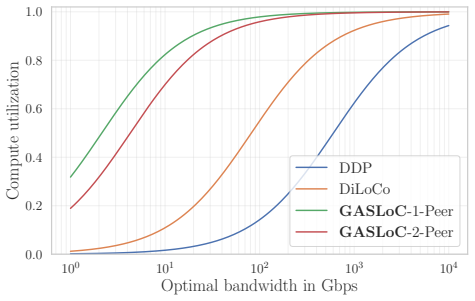
GASLoC generalizes the notion of communication acceleration to the recently popular outer optimizer to allow a practical gossip-based training framework that is compatible with adaptive optimizers, allows for local optimizer steps, and can utilize sparse randomized peer communication. Empirically it outperforms state-of-the-art decentralized algorithms in the single-step-per-communication setting across topologies and reaches performance competitive with DiLoCo when multiple local steps are used, with clear advantages under heterogeneous bandwidth.
What carries the argument
GASLoC, the algorithm that applies gossip communication directly to the outer optimizer.
Load-bearing premise
Generalizing the outer optimizer to gossip communication preserves convergence and stability when paired with adaptive optimizers and multiple local steps.
What would settle it
A run on a standard LLM pretraining benchmark where GASLoC with multiple local steps and adaptive optimizers falls well short of DiLoCo performance would falsify the competitiveness claim.
Figures
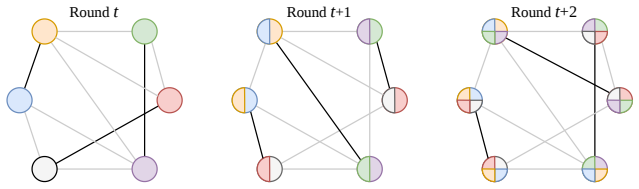
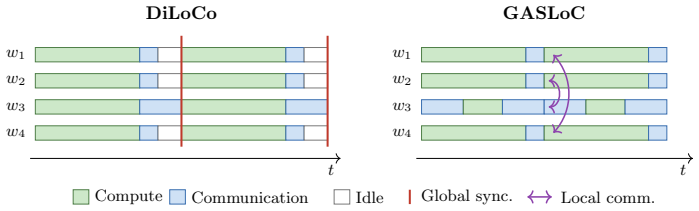
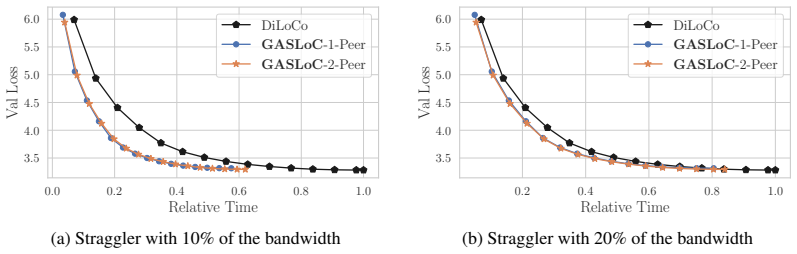
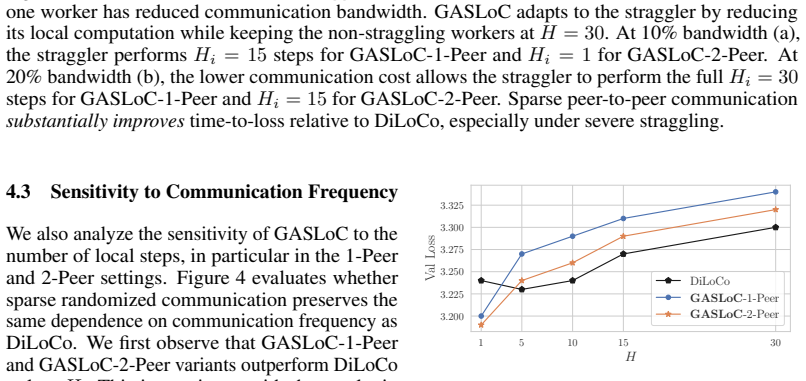
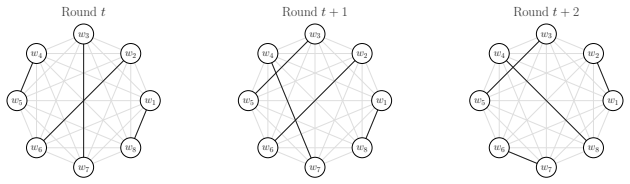
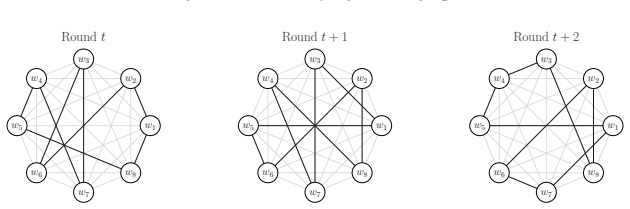
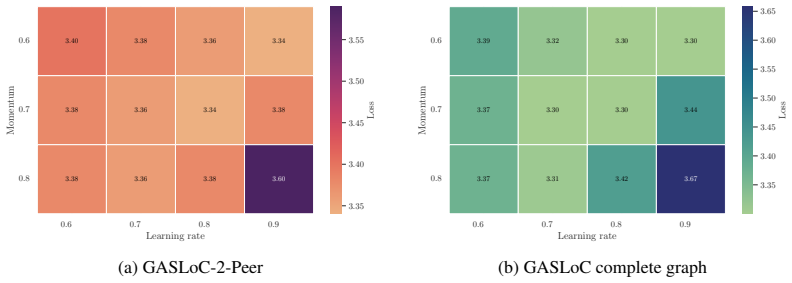
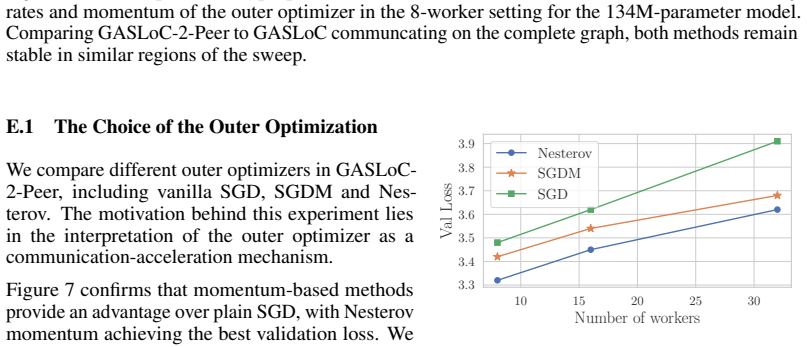
read the original abstract
Communication-efficient pre-training of LLMs is increasingly important as training draws on compute distributed across clusters, data centers, and lower-bandwidth links. Many practical methods reduce communication frequency but still rely on synchronous All-Reduce operations that maintain identical model states and tie progress to global collectives. This can become a bottleneck when bandwidth or worker speed is heterogeneous. We introduce GASLoC, a novel decentralized pre-training algorithm that generalizes the notion of communication acceleration to the recently popular "outer optimizer" to allow a practical gossip-based training framework that is compatible with adaptive optimizers, allows for local optimizer steps, and can utilize sparse randomized peer communication. Empirically, on a number of standard LLM training tasks, we demonstrate that GASLoC outperforms state-of-the-art decentralized algorithms in single step per communication setting for a number of topologies and, unlike existing decentralized methods in the LLM setting, it allows to obtain performance competitive with DiLoCo when utilizing multiple local steps. In the heterogeneous bandwidth setting we demonstrate the advantage of GASLoC showing that it can significantly outperform DiLoCo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GASLoC, a decentralized LLM pre-training algorithm that generalizes the outer-optimizer framework (as in DiLoCo) to gossip-based communication. This allows sparse randomized peer communication, compatibility with adaptive optimizers, and multiple local steps per communication round. The central empirical claims are that GASLoC outperforms prior decentralized methods in the single-step-per-communication regime across topologies and achieves performance competitive with DiLoCo when K>1 local steps are used, with further gains shown under heterogeneous bandwidth.
Significance. If the generalization preserves the convergence and stability properties of the outer optimizer under adaptive methods and local steps, and if the reported empirical advantages are reproducible, the work would offer a practical unification of local updates and communications for distributed LLM training in heterogeneous environments. The absence of any convergence analysis or detailed experimental protocol in the abstract, however, leaves the load-bearing claim—that the gossip generalization is responsible for the observed competitiveness—unsubstantiated.
major comments (1)
- [Abstract] Abstract: the claim that replacing All-Reduce with gossip communication while retaining the outer-optimizer structure 'preserves convergence and stability' when used with adaptive optimizers and K>1 local steps is stated without any derivation, bound, or stability argument. This step is load-bearing for the competitiveness claim versus DiLoCo; without it the empirical results cannot be attributed to the proposed construction rather than to specific topologies, bandwidth schedules, or hyper-parameter choices.
minor comments (1)
- [Abstract] Abstract: no model sizes, dataset details, number of runs, error bars, or exact baselines are supplied, making it impossible to assess the strength of the reported outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and clarify the scope of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that replacing All-Reduce with gossip communication while retaining the outer-optimizer structure 'preserves convergence and stability' when used with adaptive optimizers and K>1 local steps is stated without any derivation, bound, or stability argument. This step is load-bearing for the competitiveness claim versus DiLoCo; without it the empirical results cannot be attributed to the proposed construction rather than to specific topologies, bandwidth schedules, or hyper-parameter choices.
Authors: We agree that the manuscript provides no theoretical derivation, convergence bound, or stability argument for the gossip generalization of the outer optimizer. The work is empirical: it introduces GASLoC as a practical algorithm and demonstrates through experiments on standard LLM tasks that it outperforms prior decentralized methods in the single-step regime and remains competitive with DiLoCo for K>1 local steps across topologies, while showing advantages under heterogeneous bandwidth. The competitiveness claim rests on these reproducible empirical results rather than on a formal guarantee that convergence properties are preserved. We will revise the abstract to remove any implication of theoretical preservation and to state explicitly that the reported performance is empirical. revision: yes
Circularity Check
No circularity: empirical claims rest on direct comparisons without self-referential derivations or fitted predictions
full rationale
The paper introduces GASLoC as a generalization of the outer optimizer to gossip-based communication and reports empirical outperformance on LLM tasks. No equations, derivations, or parameter-fitting steps appear in the provided abstract or description. Claims are supported by direct experimental comparisons to DiLoCo and other baselines rather than any reduction to self-citations, ansatzes, or renamed inputs. The absence of a convergence proof for the generalization is a correctness gap, not a circularity in the derivation chain. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
FoMoE: Breaking the Full-Replica Barrier with a Federation of MoEs
FoMoE partitions expert layers across workers in MoE LLMs, skips non-resident experts, and reports up to 1.42x lower communication than baselines plus 1.4x throughput gains while maintaining stable routing.
Reference graph
Works this paper leans on
-
[1]
Stochastic gradient push for distributed deep learning
Mahmoud Assran, Nicolas Loizou, Nicolas Ballas, and Mike Rabbat. Stochastic gradient push for distributed deep learning. InInternational Conference on Machine Learning, pages 344–353. PMLR, 2019
2019
-
[2]
Accelerated gossip in networks of given dimension using jacobi polynomial iterations.SIAM Journal on Mathematics of Data Science, 2(1):24–47, 2020
Raphaël Berthier, Francis Bach, and Pierre Gaillard. Accelerated gossip in networks of given dimension using jacobi polynomial iterations.SIAM Journal on Mathematics of Data Science, 2(1):24–47, 2020
2020
-
[3]
Randomized gossip algorithms.IEEE transactions on information theory, 52(6):2508–2530, 2006
Stephen Boyd, Arpita Ghosh, Balaji Prabhakar, and Devavrat Shah. Randomized gossip algorithms.IEEE transactions on information theory, 52(6):2508–2530, 2006
2006
-
[4]
Dery, J Keith Rush, Nova Fallen, Zachary Garrett, Arthur Szlam, and Arthur Douillard
Zachary Charles, Gabriel Teston, Lucio M. Dery, J Keith Rush, Nova Fallen, Zachary Garrett, Arthur Szlam, and Arthur Douillard. Communication-efficient language model training scales reliably and robustly: Scaling laws for diloco. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id= X4SCxcgb3O
2026
-
[5]
Accelerating gossip sgd with periodic global averaging
Yiming Chen, Kun Yuan, Yingya Zhang, Pan Pan, Yinghui Xu, and Wotao Yin. Accelerating gossip sgd with periodic global averaging. InInternational Conference on Machine Learning, pages 1791–1802. PMLR, 2021
2021
-
[6]
Aaron Defazio, Konstantin Mishchenko, Parameswaran Raman, Hao-Jun Michael Shi, and Lin Xiao. Smoothing DiLoCo with primal averaging for faster training of LLMs.arXiv preprint arXiv:2512.17131, 2025
arXiv 2025
-
[7]
Arthur Douillard, Qixuan Feng, Andrei A Rusu, Rachita Chhaparia, Yani Donchev, Adhiguna Kuncoro, Marc’Aurelio Ranzato, Arthur Szlam, and Jiajun Shen. Diloco: Distributed low- communication training of language models.arXiv preprint arXiv:2311.08105, 2023
arXiv 2023
-
[8]
Arthur Douillard, Yanislav Donchev, Keith Rush, Satyen Kale, Zachary Charles, Zachary Garrett, Gabriel Teston, Dave Lacey, Ross McIlroy, Jiajun Shen, et al. Streaming diloco with overlapping communication: Towards a distributed free lunch.arXiv preprint arXiv:2501.18512, 2025
arXiv 2025
-
[9]
Decoupled diloco for resilient distributed pre-training, 2026
Arthur Douillard, Keith Rush, Yani Donchev, Zachary Charles, Nova Fallen, Ayush Dubey, Ionel Gog, Josef Dean, Blake Woodworth, Zachary Garrett, Nate Keating, Jenny Bishop, Henry Prior, Edouard Yvinec, Arthur Szlam, Marc’Aurelio Ranzato, and Jeff Dean. Decoupled diloco for resilient distributed pre-training, 2026. URLhttps://arxiv.org/abs/2604.21428
Pith/arXiv arXiv 2026
-
[10]
Continuized accelerations of deterministic and stochastic gradient descents, and of gossip algorithms.Advances in Neural Information Processing Systems, 34:28054–28066, 2021
Mathieu Even, Raphaël Berthier, Francis Bach, Nicolas Flammarion, Hadrien Hendrikx, Pierre Gaillard, Laurent Massoulié, and Adrien Taylor. Continuized accelerations of deterministic and stochastic gradient descents, and of gossip algorithms.Advances in Neural Information Processing Systems, 34:28054–28066, 2021
2021
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, and Akhil Mathur et. al. The llama 3 herd of models, 2024. URLhttps://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[12]
Dirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Cry...
-
[13]
Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
Pith/arXiv arXiv 2022
-
[14]
Satyen Kale, Arthur Douillard, and Yanislav Donchev. Eager updates for overlapped communi- cation and computation in diloco.arXiv preprint arXiv:2502.12996, 2025
arXiv 2025
-
[15]
Xueze Kang, Guangyu Xiang, Yuxin Wang, Hao Zhang, Yuchu Fang, Yuhang Zhou, Zhenheng Tang, Youhui Lv, Eliran Maman, Mark Wasserman, et al. Elaswave: An elastic-native system for scalable hybrid-parallel training.arXiv preprint arXiv:2510.00606, 2025
arXiv 2025
-
[16]
Jari Kolehmainen, Nikolay Blagoev, John Donaghy, O ˘guzhan Ersoy, and Christopher Nies. Noloco: No-all-reduce low communication training method for large models.arXiv preprint arXiv:2506.10911, 2025
arXiv 2025
-
[17]
A unified theory of decentralized sgd with changing topology and local updates
Anastasia Koloskova, Nicolas Loizou, Sadra Boreiri, Martin Jaggi, and Sebastian Stich. A unified theory of decentralized sgd with changing topology and local updates. InInternational conference on machine learning, pages 5381–5393. PMLR, 2020
2020
-
[18]
Jakub Koneˇcn`y, H Brendan McMahan, Felix X Yu, Peter Richtárik, Ananda Theertha Suresh, and Dave Bacon. Federated learning: Strategies for improving communication efficiency.arXiv preprint arXiv:1610.05492, 2016
Pith/arXiv arXiv 2016
-
[19]
Pytorch distributed: experiences on accelerating data parallel training.Proc
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, and Soumith Chintala. Pytorch distributed: experiences on accelerating data parallel training.Proc. VLDB Endow., 13(12):3005–3018,
-
[20]
ISSN 2150-8097. doi: 10.14778/3415478.3415530. URL https://doi.org/10. 14778/3415478.3415530
-
[21]
Provably accelerated randomized gossip algorithms
Nicolas Loizou, Michael Rabbat, and Peter Richtárik. Provably accelerated randomized gossip algorithms. InICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7505–7509, 2019. doi: 10.1109/ICASSP.2019.8683847
-
[22]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7
2019
-
[23]
Communication-Efficient Learning of Deep Networks from Decentralized Data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Ar- cas. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Aarti Singh and Jerry Zhu, editors,Proceedings of the 20th International Conference on Artifi- cial Intelligence and Statistics, volume 54 ofProceedings of Machine Learning Research, pages 12...
2017
-
[24]
Dadao: Decoupled accelerated decentralized asynchronous optimization
Adel Nabli and Edouard Oyallon. Dadao: Decoupled accelerated decentralized asynchronous optimization. InInternational Conference on Machine Learning, pages 25604–25626. PMLR, 2023
2023
-
[25]
Decentralized asynchronous optimization with dadao allows decoupling and acceleration.Journal of Machine Learning Research, 26(207):1–48, 2025
Adel Nabli and Edouard Oyallon. Decentralized asynchronous optimization with dadao allows decoupling and acceleration.Journal of Machine Learning Research, 26(207):1–48, 2025
2025
-
[26]
A2CiD2: Accelerating asynchronous communication in decentralized deep learning.Advances in Neural Information Processing Systems, 36:47451–47474, 2023
Adel Nabli, Eugene Belilovsky, and Edouard Oyallon. A2CiD2: Accelerating asynchronous communication in decentralized deep learning.Advances in Neural Information Processing Systems, 36:47451–47474, 2023
2023
-
[27]
The fineweb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps://openreview.net/ forum?id=...
2024
-
[28]
Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcný, Sanjiv Kumar, and Hugh Brendan McMahan
Sashank J. Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcný, Sanjiv Kumar, and Hugh Brendan McMahan. Adaptive federated optimization. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum? id=LkFG3lB13U5
2021
-
[29]
Communication efficient llm pre-training with sparseloco, 2025
Amir Sarfi, Benjamin Thérien, Joel Lidin, and Eugene Belilovsky. Communication efficient llm pre-training with sparseloco, 2025. URLhttps://arxiv.org/abs/2508.15706
arXiv 2025
-
[30]
Local sgd converges fast and communicates little.arXiv preprint arXiv:1805.09767, 2018
Sebastian U Stich. Local sgd converges fast and communicates little.arXiv preprint arXiv:1805.09767, 2018
Pith/arXiv arXiv 2018
-
[31]
Dahl, and Geoffrey E
Ilya Sutskever, James Martens, George E. Dahl, and Geoffrey E. Hinton. On the importance of initialization and momentum in deep learning. InInternational Conference on Machine Learning, 2013. URLhttps://api.semanticscholar.org/CorpusID:10940950
2013
-
[32]
Muloco: Muon is a practical inner optimizer for diloco.arXiv preprint arXiv:2505.23725, 2025
Benjamin Therien, Xiaolong Huang, Aaron Defazio, Irina Rish, and Eugene Belilovsky. Muloco: Muon is a practical inner optimizer for diloco.arXiv preprint arXiv:2505.23725, 2025. URL https://arxiv.org/abs/2505.23725
Pith/arXiv arXiv 2025
-
[33]
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
Pith/arXiv arXiv 2023
-
[34]
Relaysum for decentralized deep learning on heterogeneous data
Thijs V ogels, Lie He, Anastasiia Koloskova, Sai Praneeth Karimireddy, Tao Lin, Sebastian U Stich, and Martin Jaggi. Relaysum for decentralized deep learning on heterogeneous data. Advances in Neural Information Processing Systems, 34:28004–28015, 2021
2021
-
[35]
Jianyu Wang, Vinayak Tantia, Nicolas Ballas, and Michael Rabbat. Slowmo: Im- proving communication-efficient distributed sgd with slow momentum.arXiv preprint arXiv:1910.00643, 2019
arXiv 1910
-
[36]
CocktailSGD: Fine-tuning foundation models over 500Mbps networks
Jue Wang, Yucheng Lu, Binhang Yuan, Beidi Chen, Percy Liang, Christopher De Sa, Christopher Re, and Ce Zhang. CocktailSGD: Fine-tuning foundation models over 500Mbps networks. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Machine Learni...
2023
-
[37]
Zesen Wang, Jiaojiao Zhang, Xuyang Wu, and Mikael Johansson. From promise to practice: realizing high-performance decentralized training.arXiv preprint arXiv:2410.11998, 2024
arXiv 2024
-
[38]
Ex- ponential graph is provably efficient for decentralized deep training
Bicheng Ying, Kun Yuan, Yiming Chen, Hanbin Hu, PAN PAN, and Wotao Yin. Ex- ponential graph is provably efficient for decentralized deep training. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 13975–13987. Curran Associates, Inc., 2021. URL https:...
2021
-
[39]
* − 1 H H−1X k=0 ∇f(x i t,k),∇f(¯xt) +# =− β 2 E∥ 1 H H−1X k=0 ∇f(x i t,k)∥2 − β 2 E∥∇f(¯xt)∥2 + β 2 E
Sixin Zhang, Anna E Choromanska, and Yann LeCun. Deep learning with elastic averaging sgd.Advances in neural information processing systems, 28, 2015. 12 A Proof of Proposition 2 Proposition 3.Let x⋆ ∈arg minf , and suppose that x⋆ is an unconstrained minimizer, so that ∇f(x ⋆) = 0. Suppose that, for every ξ, F(·;ξ) is L-smooth. Assume moreover that the s...
2015
-
[40]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.