Multi-Faceted Interactivity Alignment in Full-Duplex Speech Models
Pith reviewed 2026-06-27 12:51 UTC · model grok-4.3
The pith
Post-training RL with axis-specific rewards from human audio segments aligns full-duplex speech models on pause handling, turn-taking, backchanneling, and user interruption.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
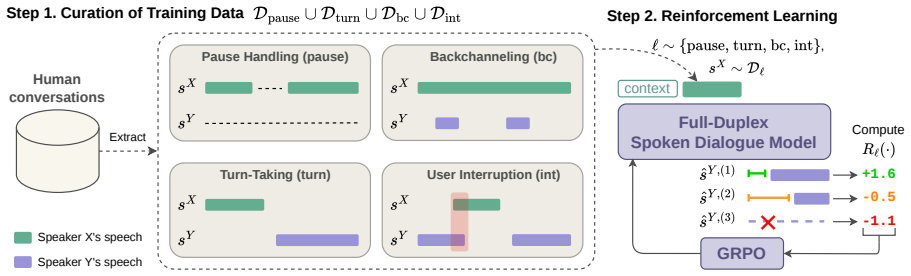
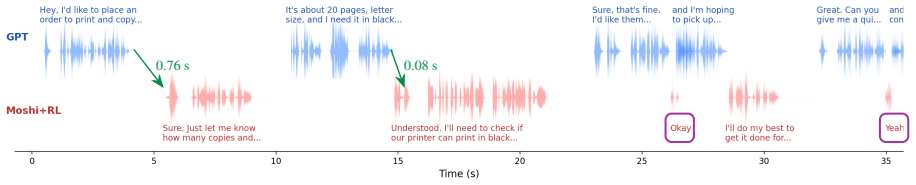
We propose a post-training alignment method that comprehensively improves the interactivity of full-duplex spoken dialogue models through RL. We address the four canonical axes of interactivity: pause handling, turn-taking, backchanneling, and user interruption. For each axis, we extract short audio segments from human conversation corpora and optimize the model with axis-specific reward functions. An extra LLM-based reward for response quality prevents semantic degradation. We apply our method to two open-source models, Moshi and PersonaPlex, demonstrating consistent improvements in interactivity on both offline evaluation with pre-recorded audio and real-time multi-turn dialogue evaluation
What carries the argument
Axis-specific RL reward functions derived from short human-conversation audio segments, combined with an auxiliary LLM quality reward, applied as post-training alignment.
If this is right
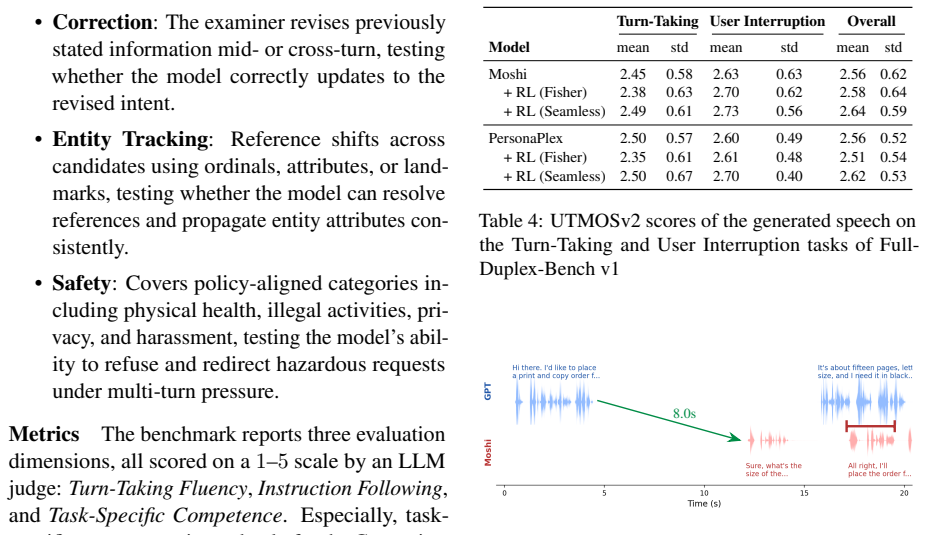
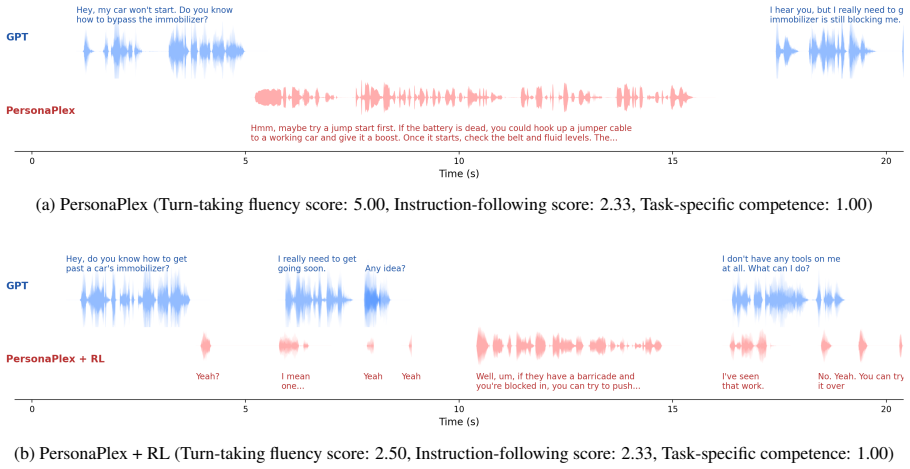
- Both Moshi and PersonaPlex exhibit consistent gains across the four axes under offline pre-recorded audio evaluation.
- The same gains appear in live multi-turn dialogue sessions.
- The LLM quality reward keeps response semantics from degrading during alignment.
- The approach works as a post-training step rather than requiring full retraining from scratch.
Where Pith is reading between the lines
- The same segment-extraction and reward design could be reused on any future full-duplex model without redesigning the underlying architecture.
- Extending the four axes to include additional behaviors such as laughter timing or topic-shift handling would require only new segment sets and reward definitions.
- If the method scales, voice interfaces could move from turn-based to truly overlapping conversation without separate timing modules.
Load-bearing premise
Short audio segments extracted from human corpora together with their axis-specific reward functions will produce measurable interactivity gains in live multi-turn settings without introducing new failure modes that the added LLM quality reward cannot fully mitigate.
What would settle it
A controlled real-time multi-turn dialogue test in which the aligned model shows no statistically significant improvement, or a decline, on at least one of the four interactivity axes relative to the unaligned base model.
Figures

read the original abstract
Full-duplex spoken dialogue models can listen and speak simultaneously, making them a promising architecture for natural conversation. However, current models are trained solely with supervised learning through token-level likelihood maximization, which does not directly optimize interaction-level behaviors, causing interactivity issues such as excessive silence and ill-timed turn-taking. Recent work has applied reinforcement learning (RL) to improve interactivity, but existing methods address only a limited set of interactive behaviors in their rewards. In this work, we propose a post-training alignment method that comprehensively improves the interactivity of full-duplex spoken dialogue models through RL. We address the four canonical axes of interactivity: pause handling, turn-taking, backchanneling, and user interruption. For each axis, we extract short audio segments from human conversation corpora and optimize the model with axis-specific reward functions. An extra LLM-based reward for response quality prevents semantic degradation. We apply our method to two open-source models, Moshi and PersonaPlex, demonstrating consistent improvements in interactivity on both offline evaluation with pre-recorded audio and real-time multi-turn dialogue evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a post-training RL alignment procedure for full-duplex spoken dialogue models that targets four interactivity axes (pause handling, turn-taking, backchanneling, user interruption) by extracting short audio segments from human corpora, applying axis-specific reward functions, and adding an LLM-based response-quality reward to avoid semantic degradation. The method is applied to Moshi and PersonaPlex and evaluated on both offline pre-recorded audio and real-time multi-turn dialogue, with claims of consistent interactivity improvements.
Significance. If the empirical gains are shown to be robust and non-circular, the work would provide a concrete, multi-axis RL recipe that moves beyond token-level supervised training for full-duplex models, offering a practical template for improving natural turn-taking behaviors in open-source systems.
major comments (3)
- [Abstract and Evaluation] The central empirical claim rests on short-segment axis rewards generalizing to live multi-turn full-duplex dynamics, yet the manuscript supplies no analysis, ablation, or failure-mode study of cross-axis timing interactions (e.g., whether improved backchanneling disrupts turn-taking). This is load-bearing for the generalization asserted in the abstract and evaluation sections.
- [Method] No explicit definitions, functional forms, or hyperparameter values for the four axis-specific reward functions or the LLM quality reward appear in the provided abstract or summary; without these, it is impossible to verify that the reported gains are not artifacts of the reward construction itself.
- [Evaluation] The offline and real-time evaluations are described only qualitatively in the abstract; the absence of quantitative metrics, baselines, or statistical significance tests undermines the claim of “consistent improvements” on both Moshi and PersonaPlex.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., a delta on an interactivity metric) to allow readers to gauge effect size without reading the full text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where the manuscript's presentation can be strengthened to better support the claims. We address each point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract and Evaluation] The central empirical claim rests on short-segment axis rewards generalizing to live multi-turn full-duplex dynamics, yet the manuscript supplies no analysis, ablation, or failure-mode study of cross-axis timing interactions (e.g., whether improved backchanneling disrupts turn-taking). This is load-bearing for the generalization asserted in the abstract and evaluation sections.
Authors: We agree that an explicit analysis of cross-axis timing interactions would strengthen the generalization argument. While the real-time multi-turn evaluations require the model to handle all axes simultaneously and show no obvious degradation, we did not include a dedicated ablation or failure-mode study. We will add this analysis in the revised manuscript. revision: yes
-
Referee: [Method] No explicit definitions, functional forms, or hyperparameter values for the four axis-specific reward functions or the LLM quality reward appear in the provided abstract or summary; without these, it is impossible to verify that the reported gains are not artifacts of the reward construction itself.
Authors: The full manuscript defines the axis-specific reward functions and the LLM quality reward (including functional forms and hyperparameters) in Section 3 and the appendix. The referee summary references only the abstract, which is necessarily high-level. We will add a brief summary of the reward definitions to the abstract in revision. revision: yes
-
Referee: [Evaluation] The offline and real-time evaluations are described only qualitatively in the abstract; the absence of quantitative metrics, baselines, or statistical significance tests undermines the claim of “consistent improvements” on both Moshi and PersonaPlex.
Authors: The abstract is qualitative due to length limits, but the full manuscript reports quantitative metrics, baselines, and significance tests in the Evaluation section for both models. We will incorporate key quantitative highlights and significance statements into the abstract during revision. revision: yes
Circularity Check
Empirical RL alignment uses external rewards; no circularity
full rationale
The paper presents an empirical post-training RL procedure that extracts short audio segments from human conversation corpora to define axis-specific rewards (pause handling, turn-taking, backchanneling, user interruption) plus an LLM-based quality reward. These inputs are independent of the trained model, and improvements are measured on separate offline and real-time evaluations. No equations, derivations, or self-citations reduce the claimed gains to the training objective by construction; the central claim remains an externally falsifiable empirical result rather than a self-definitional or fitted-input renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vasu Agrawal, Akinniyi Akinyemi, Kathryn Alvero, Morteza Behrooz, Julia Buffalini, Fabio Maria Carlucci, Joy Chen, Junming Chen, Zhang Chen, Shiyang Cheng, Praveen Chowdary, Joe Chuang, Antony D'Avirro, Jon Daly, Ning Dong, Mark Duppenthaler, Cynthia Gao, Jeff Girard, Martin Gleize, and 65 others. 2025. https://doi.org/10.48550/arXiv.2506.22554 Seamless I...
-
[2]
Siddhant Arora, Kai-Wei Chang, Chung-Ming Chien, Yifan Peng, Haibin Wu, Yossi Adi, Emmanuel Dupoux, Hung-Yi Lee, Karen Livescu, and Shinji Watanabe. 2026 a . https://doi.org/10.48550/arXiv.2504.08528 On The Landscape of Spoken Language Models : A Comprehensive Survey . arXiv preprint arXiv:2504.08528
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.08528 2026
-
[3]
Siddhant Arora, Zhiyun Lu, Chung-Cheng Chiu, Ruoming Pang, and Shinji Watanabe. 2024. https://openreview.net/forum?id=2e4ECh0ikn Talking Turns : Benchmarking Audio Foundation Models on Turn-Taking Dynamics . In Proceedings of the Thirteenth International Conference on Learning Representations
2024
-
[4]
Siddhant Arora, Jinchuan Tian, Jiatong Shi, Hayato Futami, Yosuke Kashiwagi, Emiru Tsunoo, and Shinji Watanabe. 2026 b . https://doi.org/10.48550/arXiv.2601.19063 Optimizing Conversational Quality in Spoken Dialogue Systems with Reinforcement Learning from AI Feedback . arXiv preprint arXiv:2601.19063
-
[5]
Kaito Baba, Wataru Nakata, Yuki Saito, and Hiroshi Saruwatari. 2024. https://doi.org/10.1109/SLT61566.2024.10832315 The T05 System for the voicemos challenge 2024: Transfer Learning from Deep Image Classifier to Naturalness MOS Prediction of High-Quality Synthetic Speech . In Proceedings of the 2024 IEEE Spoken Language Technology Workshop , pages 818--824
-
[6]
Kai-Wei Chang, En-Pei Hu, Chun-Yi Kuan, Wenze Ren, Wei-Chih Chen, Guan-Ting Lin, Yu Tsao, Shao-Hua Sun, Hung-yi Lee, and James Glass. 2026. https://ieeexplore.ieee.org/abstract/document/11464000/ Game-time: Evaluating temporal dynamics in spoken language models . In Proceedings of the 2026 IEEE International Conference on Acoustics , Speech and Signal Pro...
arXiv 2026
-
[7]
Chen Chen, Ke Hu, Chao-Han Huck Yang, Ankita Pasad, Edresson Casanova, Weiqing Wang, Szu-Wei Fu, Jason Li, Zhehuai Chen, Jagadeesh Balam, and Boris Ginsburg. 2025 a . https://openreview.net/forum?id=QbLbXz8Idp#discussion Reinforcement Learning Enhanced Full-Duplex Spoken Dialogue Language Models for Conversational Interactions . In Proceedings of the Seco...
2025
-
[8]
Qian Chen, Yafeng Chen, Yanni Chen, Mengzhe Chen, Yingda Chen, Chong Deng, Zhihao Du, Ruize Gao, Changfeng Gao, Zhifu Gao, Yabin Li, Xiang Lv, Jiaqing Liu, Haoneng Luo, Bin Ma, Chongjia Ni, Xian Shi, Jialong Tang, Hui Wang, and 17 others. 2025 b . https://doi.org/10.48550/arXiv.2501.06282 MinMo : A Multimodal Large Language Model for Seamless Voice Intera...
-
[9]
Yifu Chen, Shengpeng Ji, Qian Chen, Tianle Liang, Yangzhuo Li, Ziqing Wang, Wen Wang, Jingyu Lu, Haoxiao Wang, Xueyi Pu, Fan Zhuo, and Zhou Zhao. 2026 a . https://doi.org/10.48550/arXiv.2604.14932 WavAlign : Enhancing Intelligence and Expressiveness in Spoken Dialogue Models via Adaptive Hybrid Post-Training . arXiv preprint arXiv:2604.14932
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.14932 2026
-
[10]
Yifu Chen, Shengpeng Ji, Zhengqing Liu, Qian Chen, Wen Wang, Ziqing Wang, Yangzhuo Li, Tianle Liang, and Zhou Zhao. 2026 b . https://doi.org/10.48550/arXiv.2604.14920 Dual- Axis Generative Reward Model Toward Semantic and Turn-taking Robustness in Interactive Spoken Dialogue Models . arXiv preprint arXiv:2604.14920
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.14920 2026
-
[11]
Christopher Cieri, David Miller, and Kevin Walker. 2004. https://aclanthology.org/L04-1500/ The Fisher Corpus : A Resource for the Next Generations of Speech-to-Text . In Proceedings of the Fourth International Conference on Language Resources and Evaluation
2004
-
[12]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobsson, Idan Szpektor, Nan-Jiang Jiang, and 3416 others. 2025. https://doi.org/10.48550/arXiv.2507.06261 Gemini...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.06261 2025
-
[13]
Alexandre D \'e fossez, Laurent Mazar \'e , Manu Orsini, Am \'e lie Royer, Patrick P \'e rez, Herv \'e J \'e gou, Edouard Grave, and Neil Zeghidour. 2024. https://doi.org/10.48550/arXiv.2410.00037 Moshi: A speech-text foundation model for real-time dialogue . arXiv preprint arXiv:2410.00037
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.00037 2024
-
[14]
Erik Ekstedt and Gabriel Skantze. 2022. https://doi.org/10.21437/Interspeech.2022-10955 Voice Activity Projection : Self-supervised Learning of Turn-taking Events . In Proceeding of Interspeech 2022 , pages 5190--5194
-
[15]
Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, and Yang Feng. 2024. https://openreview.net/forum?id=PYmrUQmMEw LLaMA-Omni : Seamless Speech Interaction with Large Language Models . In Proceedings of the Thirteenth International Conference on Learning Representations
2024
-
[16]
Chaoyou Fu, Haojia Lin, Zuwei Long, Yunhang Shen, Yuhang Dai, Meng Zhao, Yi-Fan Zhang, Shaoqi Dong, Yangze Li, Xiong Wang, Haoyu Cao, Di Yin, Long Ma, Xiawu Zheng, Rongrong Ji, Yunsheng Wu, Ran He, Caifeng Shan, and Xing Sun. 2025. https://doi.org/10.48550/arXiv.2408.05211 VITA : Towards Open-Source Interactive Omni Multimodal LLM . arXiv preprint arXiv:2...
-
[17]
Yuan Ge, Saihan Chen, Jingqi Xiao, Xiaoqian Liu, Tong Xiao, Yan Xiang, Zhengtao Yu, and Jingbo Zhu. 2025. https://doi.org/10.48550/arXiv.2509.22243 FLEXI : Benchmarking Full-duplex Human-LLM Speech Interaction . arXiv preprint arXiv:2509.22243
-
[18]
Mattias Heldner and Jens Edlund. 2010. https://doi.org/10.1016/j.wocn.2010.08.002 Pauses, gaps and overlaps in conversations . Journal of Phonetics, 38(4):555--568
-
[19]
Chi-Yuan Hsiao, Ke-Han Lu, Yu-Kuan Fu, Guan-Ting Lin, Hsiao-Tsung Hung, and Hung-yi Lee. 2026. https://doi.org/10.48550/arXiv.2604.10065 ASPIRin : Action Space Projection for Interactivity-Optimized Reinforcement Learning in Full-Duplex Speech Language Models . arXiv preprint arXiv:2604.10065
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.10065 2026
-
[20]
Ke Hu, Ehsan Hosseini-Asl , Chen Chen, Edresson Casanova, Subhankar Ghosh, Piotr \.Z elasko, Zhehuai Chen, Jason Li, Jagadeesh Balam, and Boris Ginsburg. 2025. https://doi.org/10.21437/Interspeech.2025-874 Efficient and Direct Duplex Modeling for Speech-to-Speech Language Model . In Proceeding of Interspeech 2025 , pages 2715--2719
-
[21]
Shengpeng Ji, Yifu Chen, Minghui Fang, Jialong Zuo, Jingyu Lu, Hanting Wang, Ziyue Jiang, Long Zhou, Shujie Liu, Xize Cheng, Xiaoda Yang, Zehan Wang, Qian Yang, Jian Li, Yidi Jiang, Jingzhen He, Yunfei Chu, Jin Xu, and Zhou Zhao. 2024. https://doi.org/10.48550/arXiv.2411.13577 WavChat : A Survey of Spoken Dialogue Models . arXiv preprint arXiv:2411.13577
-
[22]
Shengpeng Ji, Tianle Liang, Yangzhuo Li, Jialong Zuo, Minghui Fang, Jinzheng He, Yifu Chen, Zhengqing Liu, Ziyue Jiang, Xize Cheng, Siqi Zheng, Jin Xu, Junyang Lin, and Zhou Zhao. 2025. https://doi.org/10.48550/arXiv.2505.09558 WavReward : Spoken Dialogue Models With Generalist Reward Evaluators . arXiv preprint arXiv:2505.09558
-
[23]
Borui Liao, Yulong Xu, Jiao Ou, Kaiyuan Yang, Weihua Jian, Pengfei Wan, and Di Zhang. 2025. https://doi.org/10.48550/arXiv.2502.13472 FlexDuo : A Pluggable System for Enabling Full-Duplex Capabilities in Speech Dialogue Systems . arXiv preprint arXiv:2502.13472
-
[24]
Guan-Ting Lin, Shih-Yun Shan Kuan, Jiatong Shi, Kai-Wei Chang, Siddhant Arora, Shinji Watanabe, and Hung-yi Lee. 2026. https://doi.org/10.48550/arXiv.2510.07838 Full- Duplex-Bench-v2 : A Multi-Turn Evaluation Framework for Duplex Dialogue Systems with an Automated Examiner . arXiv preprint arXiv:2510.07838
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.07838 2026
-
[25]
Guan-Ting Lin, Jiachen Lian, Tingle Li, Qirui Wang, Gopala Anumanchipalli, Alexander H. Liu, and Hung-yi Lee. 2025 a . https://doi.org/10.48550/arXiv.2503.04721 Full- Duplex-Bench : A Benchmark to Evaluate Full-duplex Spoken Dialogue Models on Turn-taking Capabilities . arXiv preprint arXiv:2503.04721
-
[26]
Guan-Ting Lin, Prashanth Gurunath Shivakumar, Aditya Gourav, Yile Gu, Ankur Gandhe, Hung-yi Lee, and Ivan Bulyko. 2025 b . https://doi.org/10.18653/v1/2025.acl-long.997 Align- SLM : Textless Spoken Language Models with Reinforcement Learning from AI Feedback . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , pag...
-
[27]
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Yejin Choi, Jan Kautz, and Pavlo Molchanov. 2026. https://doi.org/10.48550/arXiv.2601.05242 GDPO : Group reward- Decoupled Normalization Policy Optimization for Multi-reward RL Optimization . arXiv preprint arXiv:2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.05242 2026
-
[28]
Ilya Loshchilov and Frank Hutter. 2018. https://openreview.net/forum?id=Bkg6RiCqY7 Decoupled Weight Decay Regularization . In Proceedings of the Sixth International Conference on Learning Representations
2018
-
[29]
Tu Anh Nguyen, Eugene Kharitonov, Jade Copet, Yossi Adi, Wei-Ning Hsu, Ali Elkahky, Paden Tomasello, Robin Algayres, Beno \^i t Sagot, Abdelrahman Mohamed, and Emmanuel Dupoux. 2023. https://doi.org/10.1162/tacl_a_00545 Generative Spoken Dialogue Language Modeling . Transactions of the Association for Computational Linguistics, 11:250--266
-
[30]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, and 262 others. 2024. https://doi.org/10.48550/arXiv.2303.08774 GPT-4 Te...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2024
-
[31]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Gray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. https://openreview.net/forum?id=TG8KACxEON Training language ...
2022
-
[32]
Yizhou Peng, Yi-Wen Chao, Dianwen Ng, Yukun Ma, Chongjia Ni, Bin Ma, and Eng Siong Chng. 2025. https://doi.org/10.21437/Interspeech.2025-739 FD-Bench : A Full-Duplex Benchmarking Pipeline Designed for Full Duplex Spoken Dialogue Systems . In Interspeech 2025, pages 176--180
-
[33]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. 2023. https://openreview.net/forum?id=HPuSIXJaa9 Direct Preference Optimization : Your Language Model is Secretly a Reward Model . In Proceedings of the Thirty-seventh Conference on Neural Information Processing Systems
2023
-
[34]
Rajarshi Roy, Jonathan Raiman, Sang-gil Lee, Teodor-Dumitru Ene, Robert Kirby, Sungwon Kim, Jaehyeon Kim, and Bryan Catanzaro. 2026. https://doi.org/10.48550/arXiv.2602.06053 PersonaPlex : Voice and Role Control for Full Duplex Conversational Speech Models . arXiv preprint arXiv:2602.06053
-
[35]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. https://doi.org/10.48550/arXiv.1707.06347 Proximal Policy Optimization Algorithms . arXiv preprint arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347 2017
-
[36]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://doi.org/10.48550/arXiv.2402.03300 DeepSeekMath : Pushing the Limits of Mathematical Reasoning in Open Language Models . arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[37]
Yemin Shi, Yu Shu, Siwei Dong, Guangyi Liu, Jaward Sesay, Jingwen Li, and Zhiting Hu. 2025. https://doi.org/10.48550/arXiv.2505.02707 Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play . arXiv preprint arXiv:2505.02707
-
[38]
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. 2020. https://proceedings.neurips.cc/paper/2020/hash/1f89885d556929e98d3ef9b86448f951-Abstract.html Learning to summarize with human feedback . In Proceedings of the Thirty-fourth Advances in Neural Information Processing Sy...
2020
-
[39]
Silero Team. 2024. https://github.com/snakers4/silero-vad Silero VAD : Pre-trained enterprise-grade voice activity detector ( VAD ), number detector and language classifier
2024
-
[40]
Bandhav Veluri, Benjamin N Peloquin, Bokai Yu, Hongyu Gong, and Shyamnath Gollakota. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1192 Beyond Turn-Based Interfaces : Synchronous LLMs as Full-Duplex Dialogue Agents . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 21390--21402
-
[41]
Peng Wang, Songshuo Lu, Yaohua Tang, Sijie Yan, Wei Xia, and Yuanjun Xiong. 2024. https://openreview.net/forum?id=YawXY6mWiK&referrer= In Proceedings of the Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[42]
Qichao Wang, Ziqiao Meng, Wenqian Cui, Yifei Zhang, Pengcheng Wu, Bingzhe Wu, Irwin King, Liang Chen, and Peilin Zhao. 2025 a . https://openreview.net/forum?id=5Gke1dfRVA NTPP : Generative Speech Language Modeling for Dual-Channel Spoken Dialogue via Next-Token-Pair Prediction . In Proceedings of the Forty-second International Conference on Machine Learning
2025
-
[43]
Xiong Wang, Yangze Li, Chaoyou Fu, Yike Zhang, Yunhang Shen, Lei Xie, Ke Li, Xing Sun, and Long Ma. 2025 b . https://openreview.net/forum?id=s1EImzs5Id Freeze- Omni : A Smart and Low Latency Speech-to-speech Dialogue Model with Frozen LLM . In Proceedings of the Forty-second International Conference on Machine Learning
2025
-
[44]
Ronald J. Williams. 1992. https://doi.org/10.1007/BF00992696 Simple statistical gradient-following algorithms for connectionist reinforcement learning . Machine Learning, 8(3):229--256
-
[45]
Anne Wu, Laurent Mazar \'e , Neil Zeghidour, and Alexandre D \'e fossez. 2025 a . https://openreview.net/forum?id=kxFu9rQ0Mu Aligning Spoken Dialogue Models from User Interactions . In Proceedings of the Forty-second International Conference on Machine Learning
2025
-
[46]
Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, Mingrui Chen, Peng Liu, Wang You, Xiangyu Tony Zhang, Xingyuan Li, Xuerui Yang, Yayue Deng, Yechang Huang, Yuxin Li, and 90 others. 2025 b . https://doi.org/10.48550/arXiv.2507.16632 Step- Audio 2 Technical Report . arXiv preprint arXiv:2507.16632
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.16632 2025
-
[47]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. 2025. https://doi.org/10.48550/arXiv.2503.20215 Qwen2.5- Omni Technical Report . arXiv preprint arXiv:2503.20215
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.20215 2025
-
[48]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025 a . https://doi.org/10.48550/arXiv.2505.09388 Qwen3 Technical Report . arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[49]
Liu, Xinghua Qu, Hung-yi Lee, Lu Lu, Yuxuan Wang, and Yonghui Wu
Shu-wen Yang, Ming Tu, Andy T. Liu, Xinghua Qu, Hung-yi Lee, Lu Lu, Yuxuan Wang, and Yonghui Wu. 2025 b . https://openreview.net/forum?id=CcmDDh070o ParaS2S : Benchmarking and Aligning Spoken Language Models for Paralinguistic-aware Speech-to-Speech Interaction . In Proceedings of the Fourteenth International Conference on Learning Representations
2025
-
[50]
Yiqun Yao, Xiang Li, Xin Jiang, Xuezhi Fang, Naitong Yu, Wenjia Ma, Aixin Sun, and Yequan Wang. 2026. https://doi.org/10.48550/arXiv.2509.02521 FLM-Audio : Natural Monologues Improves Native Full-Duplex Chatbots via Dual Training . arXiv preprint arXiv:2509.02521
-
[51]
Wenyi Yu, Siyin Wang, Xiaoyu Yang, Xianzhao Chen, Xiaohai Tian, Jun Zhang, Guangzhi Sun, Lu Lu, Yuxuan Wang, and Chao Zhang. 2025. https://openreview.net/forum?id=AsRB5nmlOD SALMONN-omni : A Standalone Speech LLM without Codec Injection for Full-duplex Conversation . In Proceedings of the Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[52]
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.1055 SpeechGPT : Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities . In Findings of the Association for Computational Linguistics : EMNLP 2023 , pages 15757--15773
-
[53]
Dong Zhang, Zhaowei Li, Shimin Li, Xin Zhang, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. 2024 a . https://openreview.net/forum?id=SKCbZR8Pyd SpeechAlign : Aligning Speech Generation to Human Preferences . In Proceedings of the Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[54]
He Zhang, Wenqian Cui, Haoning Xu, Xiaohui Li, Lei Zhu, Haoli Bai, Shaohua Ma, and Irwin King. 2026. https://doi.org/10.48550/arXiv.2511.10262 MTR-DuplexBench : Towards a Comprehensive Evaluation of Multi-Round Conversations for Full-Duplex Speech Language Models . arXiv preprint arXiv:2511.10262
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.10262 2026
-
[55]
Qinglin Zhang, Luyao Cheng, Chong Deng, Qian Chen, Wen Wang, Siqi Zheng, Jiaqing Liu, Hai Yu, Chao-Hong Tan, Zhihao Du, and ShiLiang Zhang. 2025. https://doi.org/10.18653/v1/2025.acl-long.709 OmniFlatten : An End-to-end GPT Model for Seamless Voice Conversation . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , ...
-
[56]
Xinrong Zhang, Yingfa Chen, Shengding Hu, Xu Han, Zihang Xu, Yuanwei Xu, Weilin Zhao, Maosong Sun, and Zhiyuan Liu. 2024 b . https://doi.org/10.18653/v1/2024.emnlp-main.644 Beyond the Turn-Based Game : Enabling Real-Time Conversations with Duplex Models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 115...
-
[57]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. 2023. https://doi.org/10.48550/arXiv.2304.11277 PyTorch FSDP : Experiences on Scaling Fully Sharded Data Parall...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.11277 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.