TacForeSight: Force-Guided Tactile World Model for Contact-Rich Manipulation
Pith reviewed 2026-06-27 12:56 UTC · model grok-4.3
The pith
A force-conditioned tactile world model forecasts short-horizon contact states to serve as priors for manipulation policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
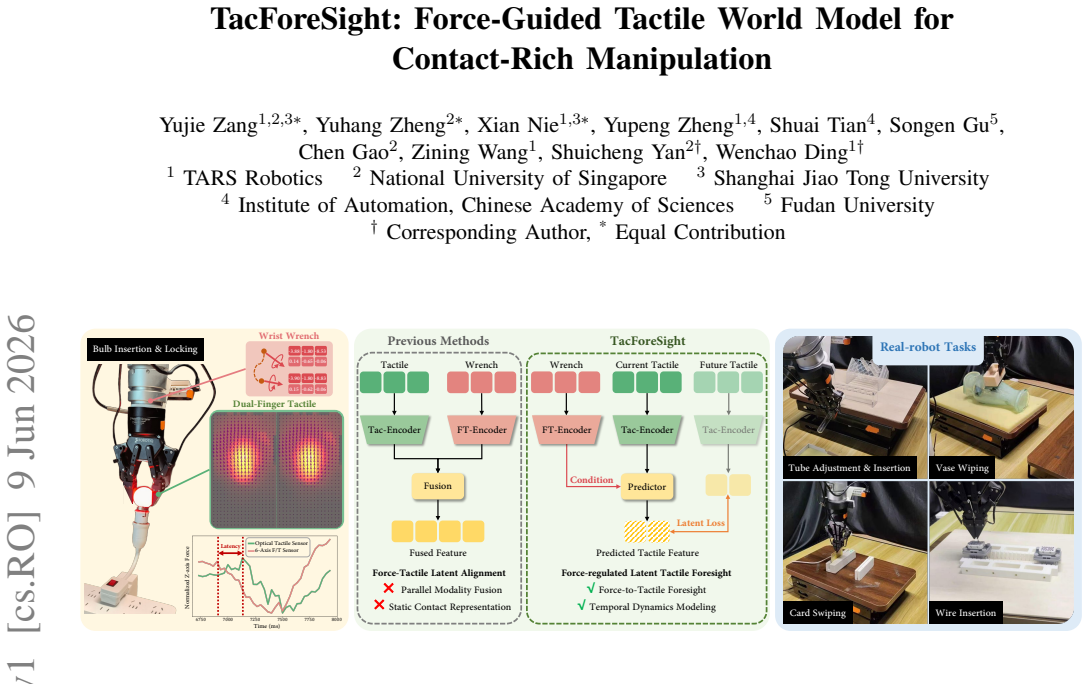
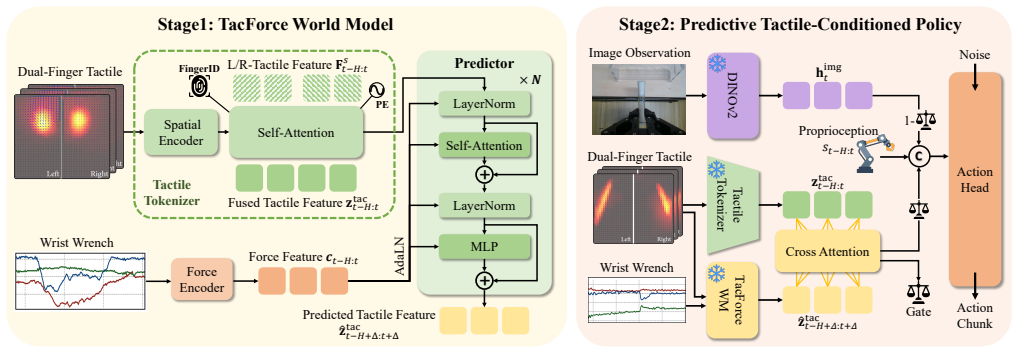
TacForeSight introduces TacForceWM, a tactile world model that predicts short-horizon tactile latent dynamics from dual-finger tactile observations conditioned on high-frequency wrist force and torque signals. The Predictive Tactile-Conditioned Policy then leverages the predicted latents as anticipatory contact priors, models the current-to-future tactile evolution via cross-attention, and adaptively fuses visuo-tactile features through a tactile-guided gating module. By forecasting purely within a compact latent space, the framework enables proactive contact reasoning with efficient real-time inference. Real-robot experiments on five representative tasks and three in-process perturbation se
What carries the argument
TacForceWM, the force-conditioned tactile world model that generates short-horizon predictions of tactile latent states from wrist force-torque inputs.
If this is right
- Contact policies gain the ability to adjust before a touch transition completes rather than after it begins.
- Global force signals supply context that local tactile readings alone cannot provide, improving robustness to disturbances.
- Latent-space forecasting keeps inference fast enough for high-frequency control loops on real hardware.
- The same conditioning structure can be applied to additional tasks that involve repeated making and breaking of contact.
- Asymmetric roles of force (global) and tactile (local) sensing become explicit in the prediction pipeline.
Where Pith is reading between the lines
- If prediction accuracy remains high, the same structure could support longer planning horizons without leaving the latent space.
- The approach suggests force-torque could serve as a cheap conditioning signal for other sensory modalities in manipulation.
- Testing whether the model generalizes when object mass or surface friction changes substantially would reveal the limits of the wrist-only conditioning.
- The gating mechanism that blends vision and predicted tactile features might extend to cases where one modality temporarily drops out.
Load-bearing premise
Short-horizon predictions inside a compact tactile latent space, conditioned only on wrist force-torque, supply reliable anticipatory priors for the policy across varied contact geometries and object properties.
What would settle it
A controlled trial on a new object shape or an abrupt external force change where the full system performs no better than a non-predictive tactile baseline.
Figures


read the original abstract
Contact-rich manipulation requires robots to continuously perceive and regulate evolving physical interactions under dynamic contact transitions or complex surface geometries. Recent imitation learning methods improve contact-aware control by incorporating tactile or force feedback, but they rarely model the asymmetric spatiotemporal roles of global force and local tactile sensing. To address this, we propose TacForeSight, a lightweight force-conditioned tactile foresight framework for real-time manipulation. The core component is TacForceWM, a tactile world model that predicts short-horizon tactile latent dynamics from dual-finger tactile observations conditioned on high-frequency wrist force and torque signals. Another key component, the Predictive Tactile-Conditioned Policy, leverages the predicted latents as anticipatory contact priors, models the current-to-future tactile evolution via cross-attention, and adaptively fuses visuo-tactile features through a tactile-guided gating module. By forecasting purely within a compact latent space, TacForeSight enables proactive contact reasoning with efficient real-time inference suitable for high-frequency manipulation control. Real-robot experiments on five representative tasks and three in-process perturbation settings show that TacForeSight consistently outperforms existing baselines, particularly under dynamic contact disturbances. All models and datasets will be made publicly available on the project website at https://tacforesight.github.io/ProjectPage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TacForeSight, a lightweight force-conditioned tactile foresight framework for contact-rich manipulation. Its core is TacForceWM, which predicts short-horizon tactile latent dynamics from dual-finger tactile observations conditioned on high-frequency wrist force-torque signals. A Predictive Tactile-Conditioned Policy then uses these predicted latents as anticipatory priors, models current-to-future tactile evolution via cross-attention, and fuses visuo-tactile features with a tactile-guided gating module. Real-robot experiments on five tasks under three perturbation settings are claimed to show consistent outperformance over baselines, especially under dynamic contact disturbances. Models and datasets will be released publicly.
Significance. If the empirical claims hold with proper quantitative support, the work would contribute a practical integration of global force and local tactile sensing for predictive control in contact-rich tasks, potentially improving robustness to disturbances. The open release of models and data would strengthen reproducibility.
major comments (3)
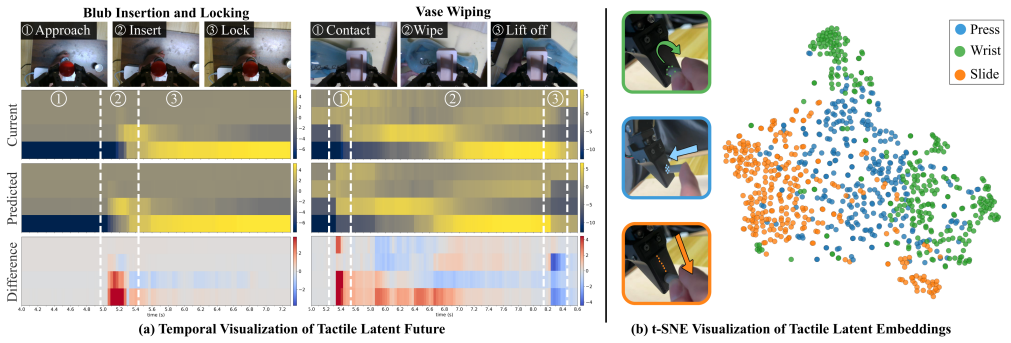
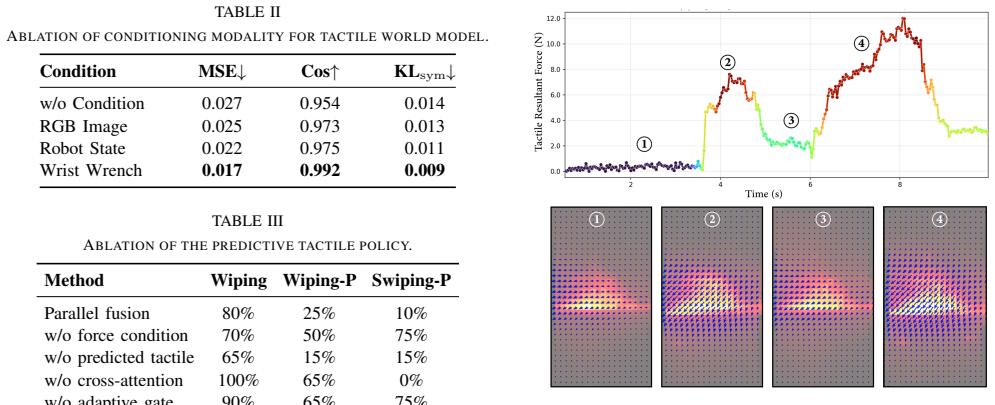
- [§5] §5 (Experiments): The central claim of consistent outperformance on five tasks with perturbations is stated without any quantitative metrics, success rates, ablation studies, or details on baseline implementations, preventing assessment of whether the results support the claim.
- [§3.1] §3.1 (TacForceWM): The assumption that wrist force-torque conditioning alone supplies sufficient object-specific geometry and material information for reliable short-horizon latent predictions is not tested; no experiments vary mass, friction, or curvature to check if the compact latent space retains necessary details for the policy's anticipatory priors.
- [§4] §4 (Policy): The cross-attention and tactile-guided gating modules rely on the predicted latents being informative, but without evidence that FT conditioning recovers spatial/material details across contact geometries, the robustness under dynamic disturbances cannot be verified.
minor comments (2)
- [Abstract] Abstract: Lacks any numerical results or error bars despite claiming outperformance; this should be added for clarity even in the abstract.
- [§3] Notation: Define the latent space dimensionality and conditioning mechanism more explicitly in the methods to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger quantitative evidence and clearer validation of modeling assumptions. We address each major comment below and commit to revisions that improve the manuscript's clarity and support for the claims without misrepresenting the current results.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): The central claim of consistent outperformance on five tasks with perturbations is stated without any quantitative metrics, success rates, ablation studies, or details on baseline implementations, preventing assessment of whether the results support the claim.
Authors: We agree that the presentation in the current manuscript relies primarily on qualitative descriptions and figures. In the revised version, we will add a table with per-task success rates under each of the three perturbation settings, implementation details for all baselines, and results from ablation studies on the world model and policy components. This will enable direct quantitative evaluation of the outperformance claims. revision: yes
-
Referee: [§3.1] §3.1 (TacForceWM): The assumption that wrist force-torque conditioning alone supplies sufficient object-specific geometry and material information for reliable short-horizon latent predictions is not tested; no experiments vary mass, friction, or curvature to check if the compact latent space retains necessary details for the policy's anticipatory priors.
Authors: The current experiments do not include isolated variations of mass, friction, or curvature. The five tasks do involve objects with differing geometries and contact properties, and the force-torque conditioning is shown to support effective predictions across them. We will revise §3.1 to explicitly discuss this assumption, including how high-frequency wrist signals encode interaction-specific dynamics, and add a limitations paragraph noting the lack of controlled parameter sweeps. revision: partial
-
Referee: [§4] §4 (Policy): The cross-attention and tactile-guided gating modules rely on the predicted latents being informative, but without evidence that FT conditioning recovers spatial/material details across contact geometries, the robustness under dynamic disturbances cannot be verified.
Authors: We acknowledge that direct evidence (e.g., latent visualizations or property correlations) linking FT conditioning to recovered spatial/material details is not provided. In the revision we will include additional analysis of the predicted latents and their correlation with observed contact outcomes to demonstrate informativeness, thereby supporting the robustness claims for the cross-attention and gating modules under disturbances. revision: yes
Circularity Check
No circularity: empirical framework with independent experimental validation
full rationale
The paper describes an empirical system (TacForceWM for short-horizon latent prediction conditioned on wrist FT signals, plus a cross-attention policy) whose central claims are supported by real-robot experiments on five tasks and three perturbation settings, with performance measured against external baselines. No equations, fitted parameters, or self-citations are presented in the abstract or described text that would reduce any claimed prediction or uniqueness result to a definitional identity or prior fit. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Tactile-WAM: Touch-Aware World Action Model with Tactile Asymmetric Attention
Tactile-WAM with TAAM improves mean success rate by 38.9% overall and 86% on contact-rich tasks on ManiFeel by using VideoClean mask and touch-aware bias to prevent tactile pollution in world action models.
Reference graph
Works this paper leans on
-
[1]
Y . Li, H. Jiang, J. Xia, H. Zhang, J. Du, Y . Zhou, J. Zeng, C. Hao, J. Ren, Q. Yuet al., “Forcevla2: Unleashing hybrid force-position control with force awareness for contact-rich manipulation,”arXiv preprint arXiv:2603.15169, 2026
arXiv 2026
-
[2]
Omnivta: Visuo-tactile world modeling for contact-rich robotic manipulation,
Y . Zheng, S. Gu, W. Li, Y . Zheng, Y . Zang, S. Tian, X. Li, C. Hao, C. Gao, S. Liuet al., “Omnivta: Visuo-tactile world modeling for contact-rich robotic manipulation,”arXiv preprint arXiv:2603.19201, 2026
arXiv 2026
-
[3]
X. Li, Y . Xie, H. Liu, W. Hou, G. Chen, S. Li, and W. Ding, “Master micro residual correction with adaptive tactile fusion and force-mixed control for contact-rich manipulation,”arXiv preprint arXiv:2603.15152, 2026
arXiv 2026
-
[4]
Anytouch 2: General optical tactile representation learning for dynamic tactile perception,
R. Feng, Y . Zhou, S. Mei, D. Zhou, P. Wang, S. Cui, B. Fang, G. Yao, and D. Hu, “Anytouch 2: General optical tactile representation learning for dynamic tactile perception,”arXiv preprint arXiv:2602.09617, 2026
arXiv 2026
-
[5]
Tactile-force alignment in vision-language-action models for force- aware manipulation,
Y . Huang, P. Lin, W. Li, D. Li, J. Li, J. Jiang, C. Xiao, and Z. Jiao, “Tactile-force alignment in vision-language-action models for force- aware manipulation,”arXiv preprint arXiv:2601.20321, 2026
arXiv 2026
-
[6]
Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation,
H. Xue, J. Ren, W. Chen, G. Zhang, Y . Fang, G. Gu, H. Xu, and C. Lu, “Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation,”arXiv preprint arXiv:2503.02881, 2025
arXiv 2025
-
[7]
H. Fang, S. Tang, M. Mei, H. Qin, Z. He, J. Chen, Y . Feng, C. Wang, W. Liu, Z. Heet al., “Force policy: Learning hybrid force-position control policy under interaction frame for contact-rich manipulation,” arXiv preprint arXiv:2602.22088, 2026
Pith/arXiv arXiv 2026
-
[8]
Coding and use of tactile signals from the fingertips in object manipulation tasks,
R. S. Johansson and J. R. Flanagan, “Coding and use of tactile signals from the fingertips in object manipulation tasks,”Nature Reviews Neuroscience, vol. 10, no. 5, pp. 345–359, 2009
2009
-
[9]
Sen- sorimotor prediction and memory in object manipulation
J. R. Flanagan, S. King, D. M. Wolpert, and R. S. Johansson, “Sen- sorimotor prediction and memory in object manipulation.”Canadian Journal of Experimental Psychology/Revue canadienne de psychologie exp´erimentale, vol. 55, no. 2, p. 87, 2001
2001
-
[10]
exumi: Extensible robot teaching system with action-aware task-agnostic tactile repre- sentation,
Y . Xu, L. Wei, P. An, Q. Zhang, and Y .-L. Li, “exumi: Extensible robot teaching system with action-aware task-agnostic tactile repre- sentation,”arXiv preprint arXiv:2509.14688, 2025
arXiv 2025
-
[11]
Foar: Force-aware reactive policy for contact-rich robotic manipulation,
Z. He, H. Fang, J. Chen, H.-S. Fang, and C. Lu, “Foar: Force-aware reactive policy for contact-rich robotic manipulation,”IEEE Robotics and Automation Letters, 2025
2025
-
[12]
Tacvla: Contact-aware tactile fusion for robust vision-language-action manipulation,
K. Zhang, H. Zhang, Z. Xu, Z. Zhang, M. R. I. Prince, X. Li, X. Han, Y . Zhou, A. Ajoudani, and Y . She, “Tacvla: Contact-aware tactile fusion for robust vision-language-action manipulation,”arXiv preprint arXiv:2603.12665, 2026
arXiv 2026
-
[13]
Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipulation,
J. Yu, H. Liu, Q. Yu, J. Ren, C. Hao, H. Ding, G. Huang, G. Huang, Y . Song, P. Caiet al., “Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipulation,”Advances in Neural Information Processing Systems, vol. 38, pp. 93 409–93 439, 2026
2026
-
[14]
Favla: A force-adaptive fast-slow vla model for contact-rich robotic manipulation,
Y . Li, P. Tang, W. Zhang, C. Zhu, Y . Duan, W. Shi, X. Zhang, Z. Yang, J. Ji, and Y . Zhang, “Favla: A force-adaptive fast-slow vla model for contact-rich robotic manipulation,”arXiv preprint arXiv:2602.23648, 2026
arXiv 2026
-
[15]
Vla-touch: Enhanc- ing vision-language-action models with dual-level tactile feedback,
J. Bi, K. Y . Ma, C. Hao, M. Z. Shou, and H. Soh, “Vla-touch: Enhanc- ing vision-language-action models with dual-level tactile feedback,” arXiv preprint arXiv:2507.17294, 2025
arXiv 2025
-
[16]
In-the-wild compliant manipulation with umi-ft,
H. Choi, Y . Hou, C. Pan, S. Hong, A. Patel, X. Xu, M. R. Cutkosky, and S. Song, “In-the-wild compliant manipulation with umi-ft,”arXiv preprint arXiv:2601.09988, 2026
arXiv 2026
-
[17]
Anytouch: Learning unified static-dynamic representation across mul- tiple visuo-tactile sensors,
R. Feng, J. Hu, W. Xia, T. Gao, A. Shen, Y . Sun, B. Fang, and D. Hu, “Anytouch: Learning unified static-dynamic representation across mul- tiple visuo-tactile sensors,”arXiv preprint arXiv:2502.12191, 2025
arXiv 2025
-
[18]
Day- dreamer: World models for physical robot learning,
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg, “Day- dreamer: World models for physical robot learning,” inConference on robot learning. PMLR, 2023, pp. 2226–2240
2023
-
[19]
Cosmos policy: Fine-tuning video models for visuomotor control and planning,
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finnet al., “Cosmos policy: Fine-tuning video models for visuomotor control and planning,”arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[20]
Vistabot: View-robust robot manipula- tion via spatiotemporal-aware view synthesis,
S. Gu, Y . Zheng, W. Li, Y . Zheng, Y . Feng, X. Li, Y . Chen, P. Li, and W. Ding, “Vistabot: View-robust robot manipula- tion via spatiotemporal-aware view synthesis,”arXiv preprint arXiv:2604.21914, 2026
Pith/arXiv arXiv 2026
-
[21]
Z. Liu, J. Liu, J. Xu, N. Han, C. Gu, H. Chen, K. Zhou, R. Zhang, K. C. Hsieh, K. Wuet al., “Mla: A multisensory language-action model for multimodal understanding and forecasting in robotic manipulation,” arXiv preprint arXiv:2509.26642, 2025
arXiv 2025
-
[22]
Robo- dreamer: Learning compositional world models for robot imagination,
S. Zhou, Y . Du, J. Chen, Y . Li, D.-Y . Yeung, and C. Gan, “Robo- dreamer: Learning compositional world models for robot imagination,” arXiv preprint arXiv:2404.12377, 2024
Pith/arXiv arXiv 2024
-
[23]
World4drive: End-to-end autonomous driving via intention-aware physical latent world model,
Y . Zheng, P. Yang, Z. Xing, Q. Zhang, Y . Zheng, Y . Gao, P. Li, T. Zhang, Z. Xia, P. Jiaet al., “World4drive: End-to-end autonomous driving via intention-aware physical latent world model,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 28 632–28 642
2025
-
[24]
Causal world modeling for robot control,
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhuet al., “Causal world modeling for robot control,” arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[25]
Genie envisioner: A unified world foundation platform for robotic manipulation,
Y . Liao, P. Zhou, S. Huang, D. Yang, S. Chen, Y . Jiang, Y . Hu, J. Cai, S. Liu, J. Luoet al., “Genie envisioner: A unified world foundation platform for robotic manipulation,”arXiv preprint arXiv:2508.05635, 2025
Pith/arXiv arXiv 2025
-
[26]
Evaluating gemini robotics policies in a veo world simulator,
G. R. Team, K. Choromanski, C. Devin, Y . Du, D. Dwibedi, R. Gao, A. Jindal, T. Kipf, S. Kirmani, I. Lealet al., “Evaluating gemini robotics policies in a veo world simulator,”arXiv preprint arXiv:2512.10675, 2025
arXiv 2025
-
[27]
C. Higuera, S. Arnaud, B. Boots, M. Mukadam, F. R. Hogan, and F. Meier, “Visuo-tactile world models,”arXiv preprint arXiv:2602.06001, 2026
arXiv 2026
-
[28]
Learning to feel the future: Dreamtacvla for contact-rich manipulation,
G. Ye, Z. Zhang, X. Zhao, S. Wu, H. Lu, S. Lu, and H. Liu, “Learning to feel the future: Dreamtacvla for contact-rich manipulation,”arXiv preprint arXiv:2512.23864, 2025
Pith/arXiv arXiv 2025
-
[29]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[30]
W. Lee, M. Grimaldi, and T. Yu, “Symmetry-aware fusion of vision and tactile sensing via bilateral force priors for robotic manipulation,” arXiv preprint arXiv:2602.13689, 2026
arXiv 2026
-
[31]
Wavenet: A generative model for raw audio,
A. Van Den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, K. Kavukcuogluet al., “Wavenet: A generative model for raw audio,”arXiv preprint arXiv:1609.03499, vol. 12, no. 1, 2016
Pith/arXiv arXiv 2016
-
[32]
V-jepa: Latent video prediction for visual representation learning,
A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y . LeCun, M. Assran, and N. Ballas, “V-jepa: Latent video prediction for visual representation learning,” 2023
2023
-
[33]
Leworldmodel: Stable end-to-end joint-embedding predictive archi- tecture from pixels,
L. Maes, Q. L. Lidec, D. Scieur, Y . LeCun, and R. Balestriero, “Leworldmodel: Stable end-to-end joint-embedding predictive archi- tecture from pixels,”arXiv preprint arXiv:2603.19312, 2026
Pith/arXiv arXiv 2026
-
[34]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
2023
-
[35]
Lejepa: Provable and scalable self-supervised learning without the heuristics,
R. Balestriero and Y . LeCun, “Lejepa: Provable and scalable self-supervised learning without the heuristics,”arXiv preprint arXiv:2511.08544, 2025
Pith/arXiv arXiv 2025
-
[36]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[37]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[38]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[39]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[40]
Kinedex: Learning tactile-informed visuomotor policies via kinesthetic teach- ing for dexterous manipulation,
D. Zhang, C. Yuan, C. Wen, H. Zhang, J. Zhao, and Y . Gao, “Kinedex: Learning tactile-informed visuomotor policies via kinesthetic teach- ing for dexterous manipulation,” inConference on Robot Learning. PMLR, 2025, pp. 4123–4138
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.