ProcessThinker: Enhancing Multi-modal Large Language Models Reasoning via Rollout-based Process Reward
Pith reviewed 2026-07-04 20:03 UTC · model glm-5.2
The pith
Score each reasoning step by whether it leads to a right answer
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
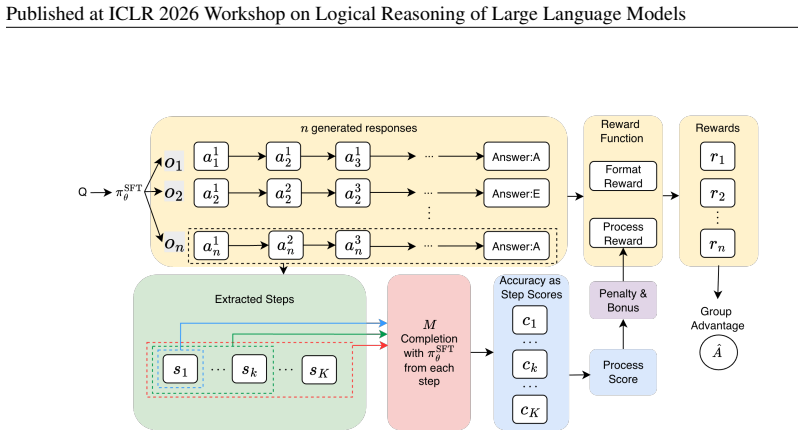
The paper's central claim is that rollout-based process rewards — scoring each reasoning step by the empirical success rate of multiple continuations sampled from that step's prefix — provide denser and more effective credit assignment than outcome-only rewards, and that this holds without training a separate process reward model. The key empirical finding is that process-only rewards outperform both outcome-only and mixed reward configurations across all four video reasoning benchmarks tested, with the process-only variant achieving the best average score (59.72) compared to outcome-only (57.55) and mixed (57.91).
What carries the argument
Rollout-based process reward (continuation solvability): For each intermediate step s_i in a reasoning trace, sample M=4 continuations from the policy model conditioned on the prefix (s_1, ..., s_i). The step score c_i is the fraction of those continuations that produce the correct final answer. The trajectory-level process reward averages these step scores, capped at K_max=6 steps. This reward is combined with a format reward, a bounded step-count bonus, and a penalty gate (which zeros out rewards for responses whose process score falls below threshold τ=0.5 when the final answer is also wrong) within a GRPO training loop.
If this is right
- Step-level credit assignment via continuation rollouts could be applied to any domain with verifiable final answers (math, code, logic puzzles), potentially improving reasoning quality beyond video QA.
- The finding that process-only rewards outperform mixed rewards suggests that outcome rewards may introduce noise or conflicting gradients when combined with denser process signals, which has implications for reward design in RL-based post-training generally.
- The method's reliance on the same final-answer verifier used in standard RLVR means it can be deployed wherever outcome-based RLVR is already in use, lowering the barrier to adoption compared to PRM-based approaches that require annotated training data.
Where Pith is reading between the lines
- The SFT warm-up degrades performance relative to the baseline (53.83 vs. 56.30 average), meaning the GRPO stage must recover this degradation and add further gains. Without a no-SFT, no-process-reward GRPO baseline, the paper cannot fully isolate whether the process reward mechanism or the combined SFT+GRPO pipeline drives the improvement. A clean ablation would strengthen the causal claim.
- The rollout cost scales with the number of steps times M continuations per step times G GRPO group size, which could make this approach prohibitively expensive for longer reasoning traces or larger models. The paper acknowledges this limitation but does not quantify the compute overhead relative to outcome-only GRPO.
- The sensitivity to step segmentation — how the teacher model decomposes reasoning into steps — is acknowledged but not systematically studied. If step boundaries are poorly chosen, the continuation-solvability signal could be noisy or misleading, which would limit the method's reliability on tasks where good step decomposition is non-trivial.
Load-bearing premise
The claim that process rewards drive the improvement rests on all GRPO variants sharing the same SFT warm-up, but since that SFT stage itself degrades performance below the baseline, the GRPO stage must both recover and exceed the original model. Without a GRPO-only variant that uses no process reward and no SFT, one cannot fully separate the contribution of the process reward from the combined effect of format-structured SFT followed by GRPO training.
What would settle it
If a GRPO variant trained with the same format-structured SFT warm-up but using only outcome rewards (no process reward, no continuation rollouts) matched or exceeded the process-only configuration's scores, the central claim that rollout-based process rewards are the active ingredient would be undermined.
Figures
read the original abstract
Visual question answering increasingly requires multi-step reasoning. Recent post-training with reinforcement learning under verifiable rewards (RLVR) and Group Relative Policy Optimization (GRPO) can improve multimodal reasoning, but most approaches rely on sparse outcome-only rewards. As a result, they struggle to tell whether an incorrect answer comes from a small mistake late in the reasoning or from an unhelpful trajectory from the start. A common solution is to train a process reward model (PRM) for step-level supervision, but this typically requires large-scale high-quality chain-of-thought annotations and additional training cost. We propose ProcessThinker, a practical post-training pipeline that provides step-level process rewards without training an explicit PRM. ProcessThinker first rewrites reasoning traces into a step-tagged format for cold-start supervised fine-tuning, then applies GRPO with a standard format reward and our rollout-based process reward. Concretely, for each intermediate step, we sample multiple continuations from that step and use the empirical success rate (final-answer verification) as the step reward. This gives dense credit assignment and encourages reasoning steps that more reliably support a correct conclusion, helping reduce inconsistent or self-contradictory progress across steps -- a key issue in logical reasoning. Across four challenging video benchmarks (Video-MMMU, MMVU, VideoMathQA, and LongVideoBench), ProcessThinker consistently improves over the baseline model Qwen3-VL-8B-Instruct
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProcessThinker, a post-training pipeline for multimodal LLMs that provides step-level process rewards without training a separate PRM. The method rewrites reasoning traces into a step-tagged format for SFT warm-up, then applies GRPO with a rollout-based process reward: for each intermediate step, M=4 continuations are sampled from the step prefix, and the empirical success rate (under the same final-answer verifier used in RLVR) serves as the step reward. Experiments on four video reasoning benchmarks show that ProcessThinker (process-only) improves over the Qwen3-VL-8B-Instruct baseline by +3.42 average, and that process-only rewards outperform both outcome-only and mixed reward configurations.
Significance. The core idea—estimating step utility via continuation solvability within a GRPO framework, without training a separate PRM—is a clean and practical contribution. The method is well-motivated by the credit-assignment problem in sparse-reward RLVR, and the ablation structure in Table 1 (outcome-only vs. mixed vs. process-only, all sharing the same SFT warm-up and GRPO machinery) is the right experimental design to isolate the contribution of the process reward. The approach is modality-agnostic and could transfer beyond video reasoning. The paper is honest about limitations, including rollout cost and noise.
major comments (2)
- §3, Table 1: The central comparative claim—that process-only rewards outperform outcome-only rewards—rests on a 2.17-point average difference (59.72 vs. 57.55). On individual benchmarks, some gaps are very small (e.g., VideoMathQA: outcome-only and mixed both 27.86; LongVideoBench: 74.20 vs. 74.60 vs. 75.40). No error bars, confidence intervals, significance tests, or even a single replication are reported anywhere in the paper. With only 1,250 RL training prompts, G=4 samples per prompt, and M=4 continuation rollouts per step, run-to-run variance from random seed and sampling stochasticity could plausibly shift scores by 1–2 points. Without any variance estimate, it is impossible to determine whether the ordering outcome-only < mixed < process-only reflects a real effect or noise. This directly undermines the load-bearing comparative claim. At minimum, the authors should report results从
- §2.2, Eq. (2): With M=4, the step score c_i can only take values {0, 0.25, 0.5, 0.75, 1.0}, which is a very coarse estimator. The paper acknowledges rollout noise in the conclusion but does not analyze its impact on training stability or final performance. A brief sensitivity analysis (e.g., M=2 vs. M=4 vs. M=8) would strengthen the claim that M=4 is sufficient, especially since the axiom ledger identifies 'empirical success rate of M=4 continuations is a sufficient estimator of step utility' as an ad-hoc assumption.
minor comments (6)
- §2.2, Eq. (6): The reward weights λ_acc and λ_proc are stated to satisfy λ_acc + λ_proc = 1, but the specific values used for each variant (outcome-only, mixed, process-only) are not reported. These should be specified, as they are load-bearing for the ablation.
- §2.2, Eq. (4): The step bonus B(K) uses a parameter α_r that is not defined or given a value. Please clarify.
- §2.2, Eq. (5): The penalty gate uses τ=0.5, but the rationale for this threshold is not discussed. A brief justification or sensitivity note would help.
- §3: The paper mentions VinePPO (Kazemnejad et al., 2025) as a closely related method using Monte Carlo rollouts for step-level credit assignment in PPO, but no experimental comparison is provided. Even a brief discussion of why a direct comparison is not feasible (different base model, modality, or framework) would contextualize the contribution.
- §3: Training compute and wall-clock time for the rollout-based process reward (which requires M×K_max additional forward passes per response) are not reported. Given that the paper identifies efficiency as the main limitation, quantitative cost figures would strengthen this discussion.
- Table 1: VIDEO-R1-7B uses a different backbone (Qwen2.5-VL) and is acknowledged as not directly comparable. Consider moving it to a footnote or separate reference table to avoid confusion.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. Both major comments are well-taken: (1) the absence of variance estimates weakens the comparative claim between reward configurations, and (2) the coarseness of M=4 as a step-score estimator deserves direct analysis. We will address both in the revision.
read point-by-point responses
-
Referee: §3, Table 1: The central comparative claim—that process-only rewards outperform outcome-only rewards—rests on a 2.17-point average difference (59.72 vs. 57.55). No error bars, confidence intervals, significance tests, or replications are reported. With only 1,250 RL training prompts, run-to-run variance could plausibly shift scores by 1–2 points. Without variance estimates, it is impossible to determine whether the ordering outcome-only < mixed < process-only reflects a real effect or noise.
Authors: The referee is correct that the absence of any variance estimate is a genuine gap, and we will address it in the revision. We will report results from at least two additional independent training runs per reward configuration (different random seeds), and will include standard deviations across runs in Table 1. We will also add bootstrap confidence intervals on the evaluation accuracy for each benchmark. We agree that the 2.17-point average gap between process-only and outcome-only is modest, and that some per-benchmark gaps (e.g., VideoMathQA: outcome-only and mixed both 27.86) are too small to support strong claims on their own. We will accordingly soften the language from 'process-only outperforms' to 'process-only achieves the best average across our runs, though the advantage over outcome-only is modest and we cannot rule out noise on individual benchmarks.' If the replicated runs do not reproduce the ordering, we will report that honestly. We note that the monotonic ordering outcome-only < mixed < process-only holds on the average across all four benchmarks, and the largest single-benchmark gap (VideoMathQA: 27.86 vs. 31.67, +3.81 for process-only) is the one most relevant to multi-step reasoning, which is the setting the method targets. But we agree this does not substitute for proper variance estimation. revision: yes
-
Referee: §2.2, Eq. (2): With M=4, the step score c_i can only take values {0, 0.25, 0.5, 0.75, 1.0}, which is a very coarse estimator. The paper acknowledges rollout noise in the conclusion but does not analyze its impact on training stability or final performance. A sensitivity analysis (e.g., M=2 vs. M=4 vs. M=8) would strengthen the claim that M=4 is sufficient, especially since the axiom ledger identifies 'empirical success rate of M=4 continuations is a sufficient estimator of step utility' as an ad-hoc assumption.
Authors: This is a fair point. The coarseness of the M=4 estimator is a real limitation that we have acknowledged only in passing. We will add a sensitivity analysis varying M ∈ {2, 4, 8} and report both final performance and training stability (reward curve smoothness, gradient variance proxies). We expect M=2 to be noticeably noisier and M=8 to offer diminishing returns at roughly double the rollout cost, but we will report whatever the data shows. We will also add a brief discussion of why M=4 was chosen as the default: it offers five discrete levels (including the extremes 0 and 1), which is the minimum needed to distinguish 'never solvable,' 'sometimes solvable,' and 'always solvable' prefixes while keeping rollout cost within our compute budget. We agree that the sufficiency of M=4 is currently an ad-hoc assumption and will label it as such in the revised text, presenting the sensitivity analysis as the empirical justification (or partial justification, depending on results). revision: yes
Circularity Check
No circularity: rollout-based process reward is defined by independent MC sampling and external ground-truth verification, not by self-citation or fitted parameters
full rationale
The paper's central construction — the rollout-based process reward (Eqs. 2–3) — is defined as the empirical success rate of M continuations sampled from the current policy conditioned on each step prefix, verified against an external ground-truth answer. This is a model-free, parameter-free construction: no parameter is fitted to a target and then renamed as a prediction, and no self-citation chain is load-bearing for the reward definition. The ablation in Table 1 compares outcome-only (λ_acc=1, λ_proc=0) vs. process-only (λ_acc=0, λ_proc=1) under the same SFT warm-up and GRPO machinery, so the comparison is between genuinely different reward signals, not between a fit and its own target. The process reward uses the same final-answer verifier as RLVR, but this is shared infrastructure (external ground-truth checking), not a circular definition. VinePPO (Kazemnejad et al., 2025) is cited as related work with a similar Monte-Carlo rollout intuition for PPO, but the paper's GRPO-based construction is presented as its own contribution, not as a consequence of an unverified self-cited theorem. The absence of error bars and the SFT degradation concern are correctness/statistical risks, not circularity. No step in the derivation chain reduces to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (9)
- M (continuation rollouts per step) =
4
- Kmax (max steps scored) =
6
- τ (process reward threshold) =
0.5
- α (step bonus scale) =
not stated
- β (format reward bonus) =
not stated
- λ_acc, λ_proc (reward weights) =
varies by variant
- Kmin, Lmin, Lmax (format constraints) =
not stated
- 19k (SFT dataset size) =
19000
- 1,250 (RL prompt count) =
1250
axioms (4)
- domain assumption Step-level credit assignment improves learning over outcome-only rewards for long reasoning traces
- ad hoc to paper Empirical success rate of M=4 continuations is a sufficient estimator of step utility
- domain assumption Step segmentation by the teacher model produces meaningful, non-redundant steps
- standard math GRPO with KL regularization to a reference policy is a stable training method for this setting
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning , year =
VinePPO: Unlocking RL Potential For LLM Reasoning Through Refined Credit Assignment , author =. International Conference on Machine Learning , year =. 2410.01679 , archivePrefix=
- [2]
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. 2025 , eprint =
work page 2025
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author =. 2024 , eprint =
work page 2024
-
[5]
Video-R1: Reinforcing Video Reasoning in Multimodal Large Language Models , author =. 2025 , eprint =
work page 2025
-
[6]
R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization , author =. 2025 , eprint =
work page 2025
-
[7]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models , author =. 2025 , eprint =
work page 2025
-
[8]
DeepVideo-R1: Video Reinforcement Fine-Tuning via Difficulty-aware Regressive GRPO , author =. 2025 , eprint =
work page 2025
-
[9]
Time-R1: Post-Training Large Vision Language Model for Temporal Video Grounding , author =. 2025 , eprint =
work page 2025
-
[10]
OneThinker: All-in-One Reasoning Model for Image and Video , author =. 2025 , eprint =
work page 2025
-
[11]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[12]
TinyLLaVA-Video-R1: Towards Smaller LMMs for Video Reasoning , author =. 2025 , eprint =
work page 2025
- [13]
-
[14]
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning , author =. 2024 , eprint =
work page 2024
-
[15]
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search , author =. 2024 , eprint =
work page 2024
-
[16]
ReST-RL: Process Reward Guided Reinforcement Learning for Large Language Model Reasoning , author =. 2025 , eprint =
work page 2025
-
[17]
Training language models to follow instructions with human feedback
Training language models to follow instructions with human feedback , author =. arXiv preprint arXiv:2203.02155 , year =. 2203.02155 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
MM-Eureka: Reinforcement Learning for Multimodal Reasoning with Verifiable Rewards , author =. 2025 , note =
work page 2025
-
[19]
PQM: Process Quality Models for Step-level Verification in Reasoning , author =. 2024 , note =
work page 2024
-
[20]
Improving Multimodal Chain-of-Thought Reasoning in Vision-Language Models , author =. 2024 , note =
work page 2024
- [21]
-
[22]
The Lessons of Developing Process Reward Models in Mathematical Reasoning , author =. 2025 , eprint =
work page 2025
-
[23]
VisualPRM: An Effective Process Reward Model for Multimodal Reasoning , author =. 2025 , eprint =
work page 2025
-
[24]
GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning , author =. 2025 , eprint =
work page 2025
-
[25]
MM-PRM: Enhancing Multimodal Mathematical Reasoning with Scalable Step-Level Supervision , author =. 2025 , eprint =
work page 2025
-
[26]
AURORA: Automated Training Framework of Universal Process Reward Models via Ensemble Prompting and Reverse Verification , author =. 2025 , eprint =
work page 2025
-
[27]
SCAN: Self-Denoising Monte Carlo Annotation for Robust Process Reward Learning , author =. 2025 , eprint =
work page 2025
-
[28]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling , author =. 2024 , eprint =
work page 2024
-
[29]
V-STaR: Training Verifiers for Self-Taught Reasoners , author =. 2024 , eprint =
work page 2024
-
[30]
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling , author =. 2025 , eprint =
work page 2025
-
[31]
International Conference on Machine Learning (ICML) , year =
e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs , author =. International Conference on Machine Learning (ICML) , year =
-
[32]
Unlocking multimodal mathematical reasoning via process reward model , author =. 2025 , eprint =
work page 2025
-
[33]
OpenThoughts: Data Recipes for Reasoning Models , author =. 2025 , eprint =
work page 2025
-
[34]
OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models , author =. 2024 , eprint =
work page 2024
-
[35]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos , author =. 2025 , eprint =
work page 2025
-
[36]
MMVU: Measuring Expert-Level Multi-Discipline Video Understanding , author =. 2025 , eprint =
work page 2025
-
[37]
VideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos , author =. 2025 , eprint =
work page 2025
-
[38]
LongVideoBench: A Benchmark for Long-context Interleaved Video-language Understanding , author =. 2024 , eprint =
work page 2024
-
[39]
R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO , author =. 2025 , eprint =
work page 2025
-
[40]
Hybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense , author =. 2025 , eprint =
work page 2025
-
[41]
Lessons from Training Grounded LLMs with Verifiable Rewards , author =. 2025 , eprint =
work page 2025
-
[42]
Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains , author =. 2025 , eprint =
work page 2025
-
[43]
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning , author =. 2025 , eprint =
work page 2025
-
[44]
XRPO: Pushing the Limits of GRPO with Targeted Exploration and Exploitation , author =. 2025 , eprint =
work page 2025
-
[45]
GRPO-LEAD: A Difficulty-Aware Reinforcement Learning Approach for Concise Mathematical Reasoning in Language Models , author =. 2025 , eprint =
work page 2025
-
[46]
AMIR-GRPO: Inducing Implicit Preference Signals into GRPO , author =. 2026 , eprint =
work page 2026
-
[47]
From Absolute to Relative: Rethinking Reward Shaping in Group-Based Reinforcement Learning , author =. 2026 , eprint =
work page 2026
- [48]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.