When Probing Accuracy Saturates, Fragility Resolves: A Complementary Metric for LLM Pre-Training Analysis
Pith reviewed 2026-06-27 13:23 UTC · model grok-4.3
The pith
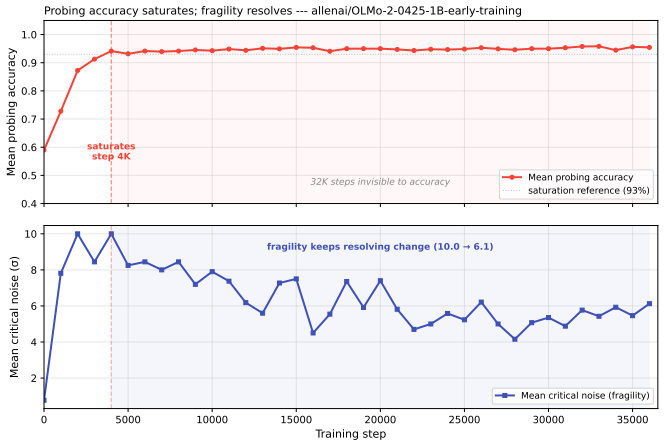
Fragility metric tracks representation changes in language models long after probing accuracy saturates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
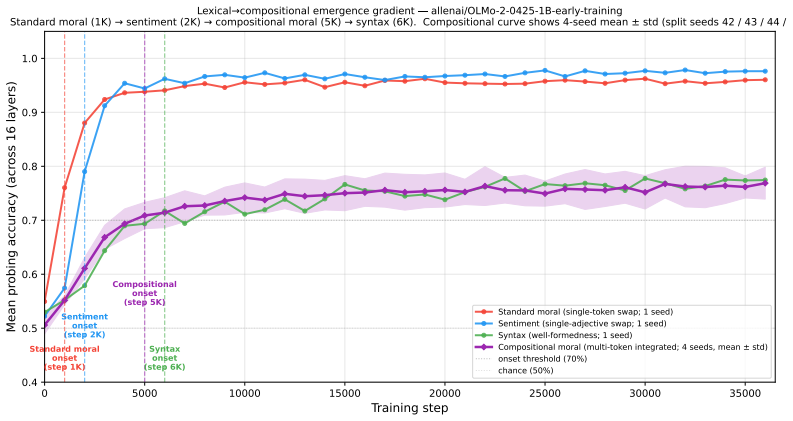
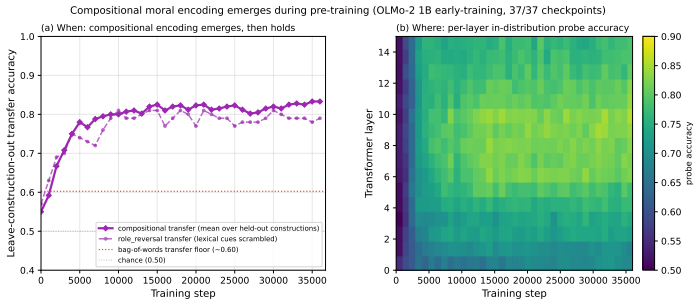
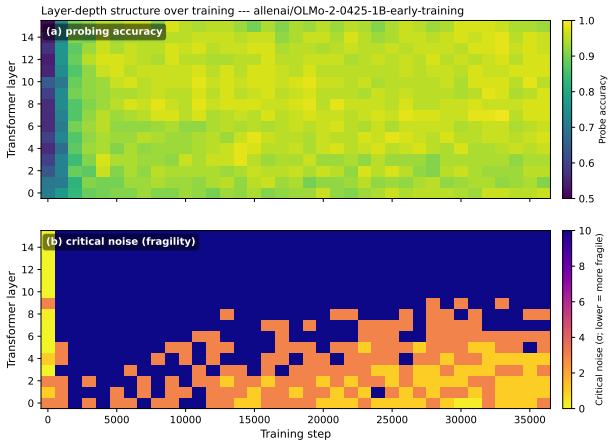
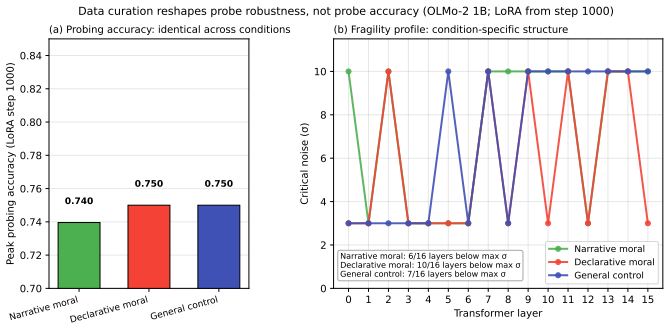
Fragility, defined as the activation-noise level at which probe accuracy collapses, recovers structure that accuracy alone cannot see. Moralized representations emerge along a lexical to compositional gradient, with lexical detection appearing first and compositional encoding later, established by transfer across construction types sharing no contrast tokens. A monotonic layer-depth robustness gradient develops across training while accuracy remains flat. Matched fine-tuning corpora that yield identical probing accuracy produce distinct fragility fingerprints, showing that data curation reshapes probe robustness without changing accuracy.
What carries the argument
Fragility, the activation-noise level at which probe accuracy collapses, which measures both margin of separability and redundancy of representation.
If this is right
- Moralized representations develop first through lexical cues and later through compositional structure, shown by cross-construction transfer.
- Robustness to noise increases monotonically from early to late layers during pre-training.
- Different fine-tuning data sets can produce the same probing accuracy yet leave measurably different robustness profiles.
- Where accuracy returns flat results across training steps or data conditions, fragility returns structured differences.
Where Pith is reading between the lines
- Fragility could be used to monitor when specific capabilities stabilize during large-scale pre-training runs.
- The same noise-threshold approach might distinguish representation quality in other probing tasks beyond moral detection.
- Data curation choices may affect model internals more than accuracy-based evaluations currently reveal.
Load-bearing premise
The fragility metric captures margin of separability and redundancy of representation without being confounded by probe architecture, noise distribution, or dataset lexical properties.
What would settle it
Measuring fragility across successive pre-training checkpoints after accuracy has plateaued and finding no further change, or finding identical fragility values for matched fine-tuning corpora claimed to differ, would falsify the claim that fragility continues to resolve structure where accuracy does not.
Figures
read the original abstract
Standard linear probing declares a property "encoded" when a classifier on hidden states achieves high accuracy. The protocol works well on a snapshot but breaks across pre-training: probe accuracy saturates within the first few thousand steps, leaving most of training invisible to the instrument. We introduce fragility, a complementary per-layer metric defined as the activation-noise level at which probe accuracy collapses. Fragility is sensitive to both the margin of separability and the redundancy of representation, both of which keep evolving long after accuracy plateaus. Applied to open-checkpoint language models, fragility recovers structure that accuracy alone cannot see. Moralized representations emerge along a lexical $\to$ compositional gradient: lexical moral detection first, compositional moral encoding later. Because probe accuracy on its own tracks how lexically separable a dataset is, we establish the compositional encoding directly, by showing it transfers across construction types that share no contrast tokens. A layer-depth robustness gradient develops monotonically across training while accuracy stays flat. And matched fine-tuning corpora that produce identical probing accuracy leave distinct fragility fingerprints, showing that data curation reshapes probe robustness without changing probe accuracy. In every comparison we test, where probing accuracy returns a flat answer, fragility returns a structured one.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard linear probing accuracy saturates early in LLM pre-training (within first few thousand steps), leaving most training invisible. It introduces fragility, defined as the activation-noise level at which probe accuracy collapses, as a complementary per-layer metric sensitive to margin of separability and redundancy. Applied to open-checkpoint models, fragility reveals moralized representations emerging along a lexical to compositional gradient (established via transfer across construction types sharing no contrast tokens), a monotonic layer-depth robustness gradient, and distinct fragility fingerprints from matched fine-tuning corpora that produce identical probing accuracy.
Significance. If the central claim holds, the work supplies a useful complementary instrument for tracking representation evolution after accuracy saturation, with concrete structure recovered in moral encoding gradients and fine-tuning effects. Credit is due for the transfer-based argument establishing compositional encoding and for applying the metric across open checkpoints to produce falsifiable gradients where accuracy is flat.
major comments (3)
- [Method / fragility definition] The definition of fragility (noise amplitude at accuracy collapse) is presented as capturing intrinsic margin/redundancy, but the manuscript must demonstrate invariance to probe architecture (linear vs. nonlinear) and noise distribution; without such controls the reported lexical-to-compositional gradient and layer-depth robustness could be artifacts of the measurement procedure rather than representation properties.
- [Moralized representations experiments] The compositional moral encoding claim rests on transfer across construction types sharing no contrast tokens; the paper should report quantitative lexical overlap statistics or ablation controls on the datasets to confirm the transfer isolates compositional structure rather than residual lexical cues.
- [Fine-tuning corpus comparisons] The distinct fragility fingerprints from matched fine-tuning corpora (identical accuracy) are load-bearing for the data-curation claim; statistical significance tests, error bars across runs, and details on corpus matching criteria are required to establish that the fragility differences are robust and not due to unaccounted variance.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction should explicitly name the open-checkpoint models and layer indices used, to allow immediate replication of the reported gradients.
- [Method] Formalize the fragility threshold with an equation (e.g., the minimal noise amplitude σ such that accuracy drops below threshold) rather than prose description alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The suggestions strengthen the methodological rigor and empirical support for the fragility metric. We address each major comment below and will revise the manuscript to incorporate the requested controls and analyses.
read point-by-point responses
-
Referee: [Method / fragility definition] The definition of fragility (noise amplitude at accuracy collapse) is presented as capturing intrinsic margin/redundancy, but the manuscript must demonstrate invariance to probe architecture (linear vs. nonlinear) and noise distribution; without such controls the reported lexical-to-compositional gradient and layer-depth robustness could be artifacts of the measurement procedure rather than representation properties.
Authors: We agree that invariance checks are required to rule out measurement artifacts. In the revised manuscript we will add experiments comparing linear probes to nonlinear probes (two-layer MLPs with ReLU) and will test both uniform and Gaussian noise distributions, confirming that the lexical-to-compositional gradient and layer-depth robustness pattern remain stable across these choices. revision: yes
-
Referee: [Moralized representations experiments] The compositional moral encoding claim rests on transfer across construction types sharing no contrast tokens; the paper should report quantitative lexical overlap statistics or ablation controls on the datasets to confirm the transfer isolates compositional structure rather than residual lexical cues.
Authors: We will add quantitative lexical overlap statistics (token-level Jaccard and type overlap) between the construction-type datasets and will include ablation controls that remove any shared contrast tokens before measuring transfer. These additions will be reported in a new subsection of the moral-encoding experiments. revision: yes
-
Referee: [Fine-tuning corpus comparisons] The distinct fragility fingerprints from matched fine-tuning corpora (identical accuracy) are load-bearing for the data-curation claim; statistical significance tests, error bars across runs, and details on corpus matching criteria are required to establish that the fragility differences are robust and not due to unaccounted variance.
Authors: We will expand the fine-tuning section to include (i) explicit corpus-matching criteria (token count, domain distribution, and moral-token frequency), (ii) error bars from five independent fine-tuning runs per corpus, and (iii) paired t-tests or Wilcoxon tests with p-values for fragility differences at each layer. These results will be added to the existing figures and tables. revision: yes
Circularity Check
No significant circularity; metric defined independently
full rationale
The paper defines fragility directly as the activation-noise level at which probe accuracy collapses, without any equations or reductions that make it equivalent to accuracy or fitted parameters by construction. No self-citations are invoked as load-bearing for uniqueness theorems or ansatzes. Claims about gradients and fingerprints are supported by direct comparisons (e.g., transfer across construction types with no shared tokens) that do not reduce to the input definitions. This is a self-contained derivation against external benchmarks, consistent with the most common honest finding of score 0-2.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Probe accuracy saturates within the first few thousand steps of pre-training
invented entities (1)
-
fragility metric
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Computational Linguistics , volume =
Belinkov, Yonatan , title =. Computational Linguistics , volume =. 2022 , doi =
2022
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2022 , url =
2022
-
[5]
Haidt, Jonathan , title =
-
[6]
and Ditto, Peter H
Graham, Jesse and Haidt, Jonathan and Koleva, Sena and Motyl, Matt and Iyer, Ravi and Wojcik, Sean P. and Ditto, Peter H. , title =. Advances in Experimental Social Psychology , volume =. 2013 , doi =
2013
-
[9]
Hewitt, John and Liang, Percy , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages =. 2019 , doi =
2019
-
[10]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Pimentel, Tiago and Valvoda, Josef and Hall Maudslay, Rowan and Zmigrod, Ran and Williams, Adina and Cotterell, Ryan , title =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[11]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Voita, Elena and Titov, Ivan , title =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2020
-
[12]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =. International Conference on Learning Representations (ICLR) , year =
-
[14]
International Conference on Machine Learning (ICML) , year =
Biderman, Stella and Schoelkopf, Hailey and Anthony, Quentin and Bradley, Herbie and O'Brien, Kyle and Hallahan, Eric and Khan, Mohammad Aflah and Purohit, Shivanshu and Prashanth, USVSN Sai and Raff, Edward and others , title =. International Conference on Machine Learning (ICML) , year =
-
[15]
Transformer Circuits Thread , year =
Olsson, Catherine and Elhage, Nelson and Nanda, Neel and Joseph, Nicholas and DasSarma, Nova and Henighan, Tom and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and others , title =. Transformer Circuits Thread , year =
-
[16]
International Conference on Learning Representations (ICLR) , year =
Nanda, Neel and Chan, Lawrence and Lieberum, Tom and Smith, Jess and Steinhardt, Jacob , title =. International Conference on Learning Representations (ICLR) , year =
-
[17]
Walking Noise: On Layer-Specific Robustness of Neural Architectures against Noisy Computations and Associated Characteristic Learning Dynamics , journal =
Borras, Hendrik and Klein, Bernhard and Fr. Walking Noise: On Layer-Specific Robustness of Neural Architectures against Noisy Computations and Associated Characteristic Learning Dynamics , journal =. 2022 , url =
2022
-
[18]
Findings of the Association for Computational Linguistics (ACL) , year =
Qian, Chen and Zhang, Jie and Yao, Wei and Liu, Dongrui and Yin, Zhenfei and Qiao, Yu and Liu, Yong and Shao, Jing , title =. Findings of the Association for Computational Linguistics (ACL) , year =
-
[21]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes. arXiv preprint arXiv:1610.01644, 2017. URL https://arxiv.org/abs/1610.01644
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Refusal in Language Models Is Mediated by a Single Direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. arXiv preprint arXiv:2406.11717, 2024. URL https://arxiv.org/abs/2406.11717
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Computational Linguistics34(1), 1–34 (2008).https://doi.org/10.1162/coli
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics, 48 0 (1): 0 207--219, 2022. doi:10.1162/coli\_a\_00422
-
[24]
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning (ICML), 2023. URL https://arxiv.org/abs/2304.01373
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Hendrik Borras, Bernhard Klein, and Holger Fr \"o ning. Walking noise: On layer-specific robustness of neural architectures against noisy computations and associated characteristic learning dynamics. arXiv preprint arXiv:2212.10430, 2022. URL https://arxiv.org/abs/2212.10430
-
[26]
Jesse Graham, Jonathan Haidt, Sena Koleva, Matt Motyl, Ravi Iyer, Sean P. Wojcik, and Peter H. Ditto. Moral foundations theory: The pragmatic validity of moral pluralism. Advances in Experimental Social Psychology, 47: 0 55--130, 2013. doi:10.1016/B978-0-12-407236-7.00002-4
-
[27]
OLMo: Accelerating the Science of Language Models
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, et al. OLMo : Accelerating the science of language models. arXiv preprint arXiv:2402.00838, 2024. URL https://arxiv.org/abs/2402.00838
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
The Righteous Mind: Why Good People Are Divided by Politics and Religion
Jonathan Haidt. The Righteous Mind: Why Good People Are Divided by Politics and Religion. Vintage Books, 2012
2012
-
[29]
Designing and Interpreting Probes with Control Tasks
John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2733--2743, 2019. doi:10.18653/v1/D19-1275. URL https://arxiv.org/abs/1909.03368
-
[30]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA : Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022. URL https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Locating and Editing Factual Associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems (NeurIPS), volume 35, 2022. URL https://arxiv.org/abs/2202.05262
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. In International Conference on Learning Representations (ICLR), 2023. URL https://arxiv.org/abs/2301.05217
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
OLMo Team . 2 OLMo 2 furious. arXiv preprint arXiv:2501.00656, 2025. URL https://arxiv.org/abs/2501.00656
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
In-context learning and induction heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. Transformer Circuits Thread, 2022. URL https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html
2022
-
[35]
Information-theoretic probing for linguistic structure
Tiago Pimentel, Josef Valvoda, Rowan Hall Maudslay, Ran Zmigrod, Adina Williams, and Ryan Cotterell. Information-theoretic probing for linguistic structure. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020. URL https://arxiv.org/abs/2004.03061
-
[36]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv preprint arXiv:2201.02177, 2022. URL https://arxiv.org/abs/2201.02177
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Towards tracing trustworthiness dynamics: Revisiting pre-training period of large language models
Chen Qian, Jie Zhang, Wei Yao, Dongrui Liu, Zhenfei Yin, Yu Qiao, Yong Liu, and Jing Shao. Towards tracing trustworthiness dynamics: Revisiting pre-training period of large language models. In Findings of the Association for Computational Linguistics (ACL), 2024. URL https://arxiv.org/abs/2402.19465
-
[38]
APEX : Probing neural networks via activation perturbation
Tao Ren, Xiaoyu Luo, and Qiongxiu Li. APEX : Probing neural networks via activation perturbation. arXiv preprint arXiv:2602.03586, 2026. URL https://arxiv.org/abs/2602.03586
-
[39]
Information-theoretic probing with minimum description length
Elena Voita and Ivan Titov. Information-theoretic probing with minimum description length. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020. URL https://arxiv.org/abs/2003.12298
-
[40]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, et al. Representation engineering: A top-down approach to AI transparency. arXiv preprint arXiv:2310.01405, 2023. URL https://arxiv.org/abs/2310.01405
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.