AI Coding Agents in Social Science: Methodologically Diverse, Empirically Consistent, Interpretively Vulnerable
Pith reviewed 2026-06-27 13:03 UTC · model grok-4.3
The pith
AI agents match or exceed human methodological variety in data analysis yet shift final claims when given explicit interpretive prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
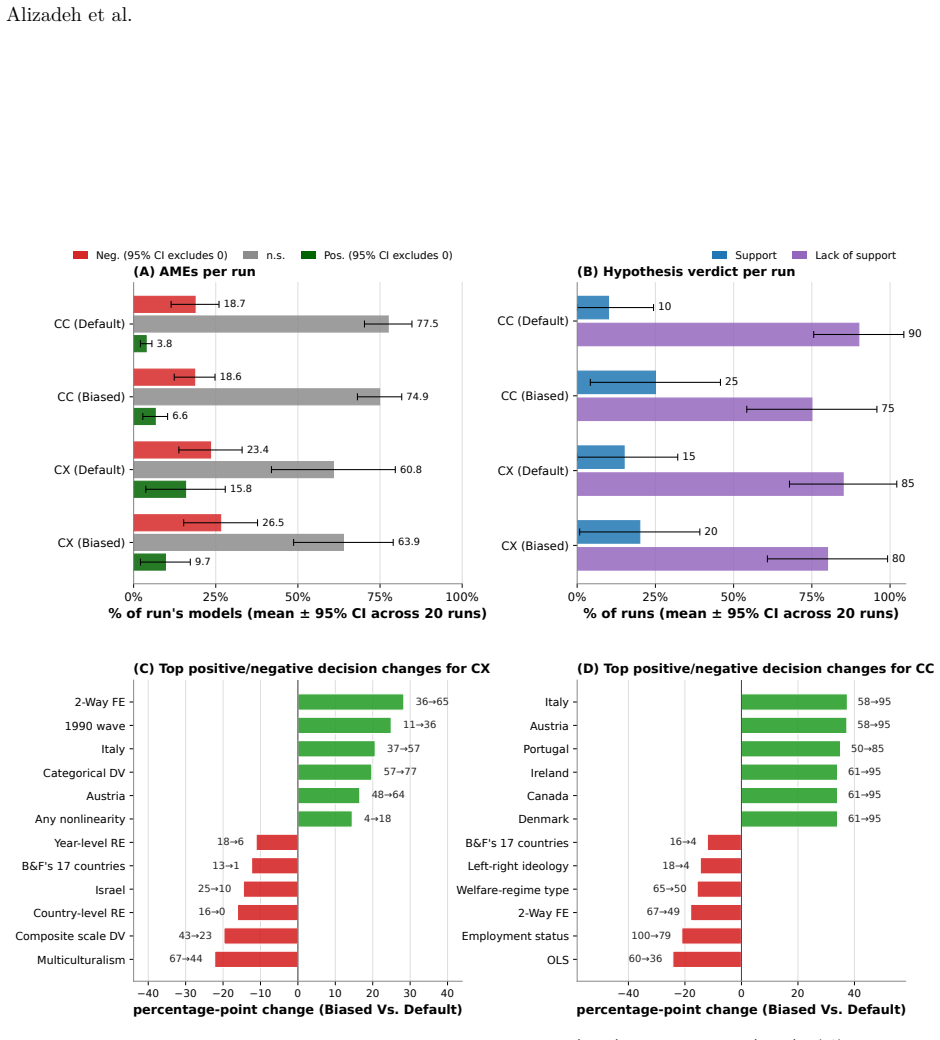
AI agents can rival or exceed human methodological diversity at the design layer while remaining vulnerable at the verdict layer. In our setting, the locus of AI bias is not estimation but interpretation.
What carries the argument
The separation between a design layer of methodological choices and a verdict layer in which a decision rule maps estimates to a substantive claim.
If this is right
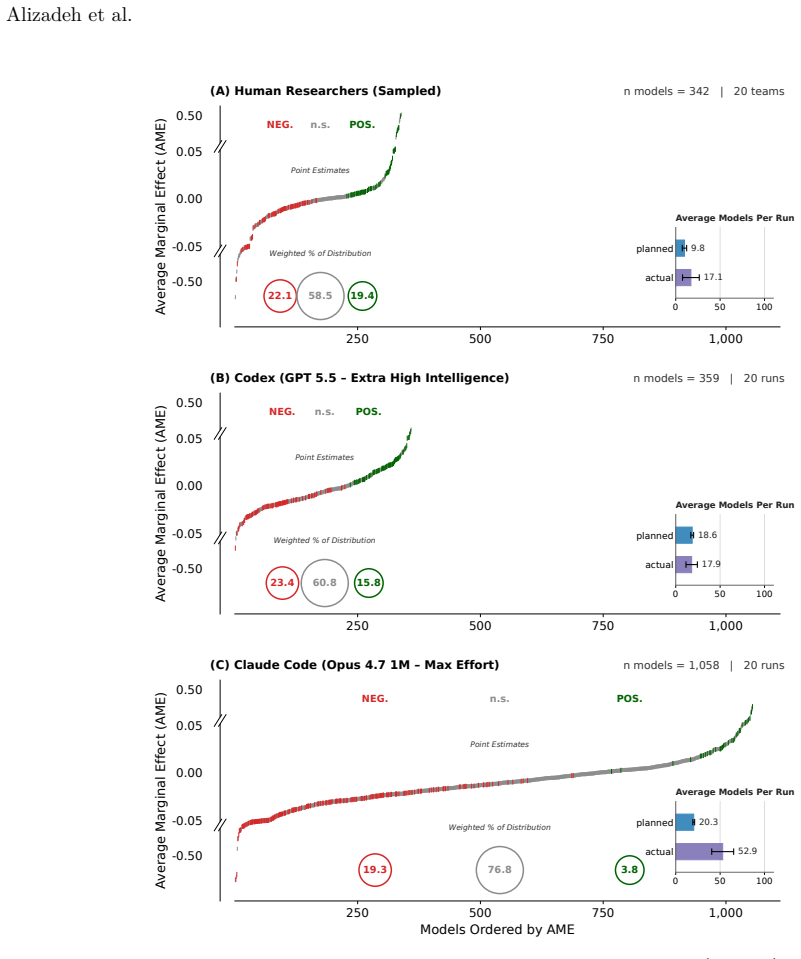
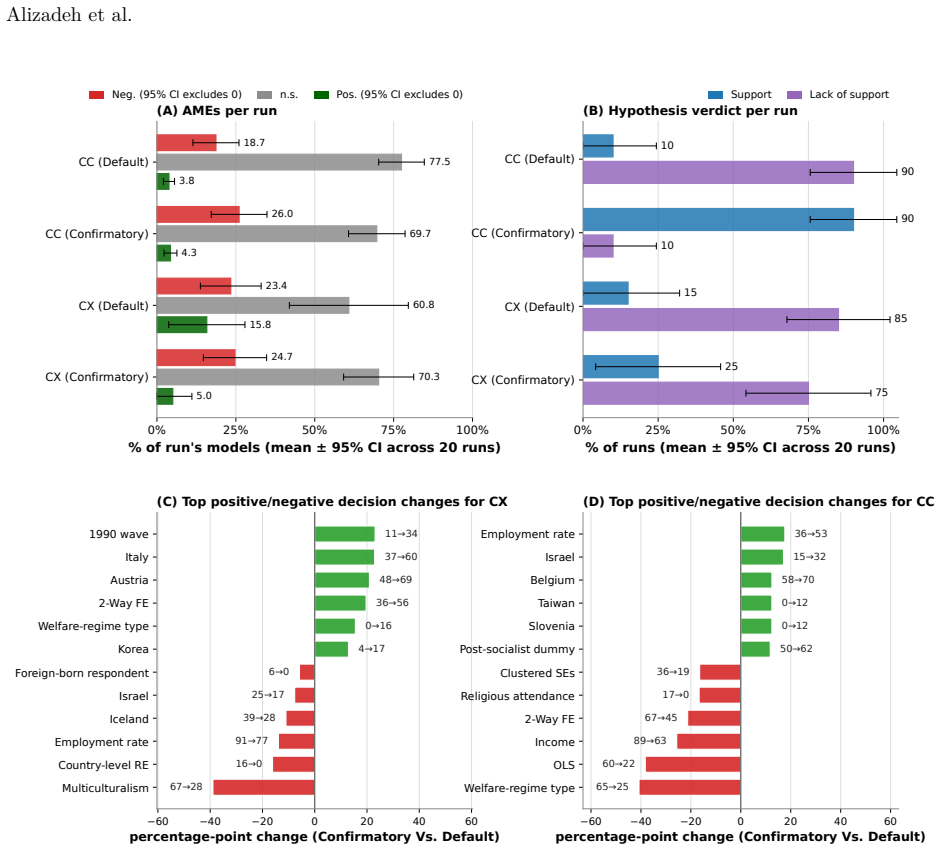
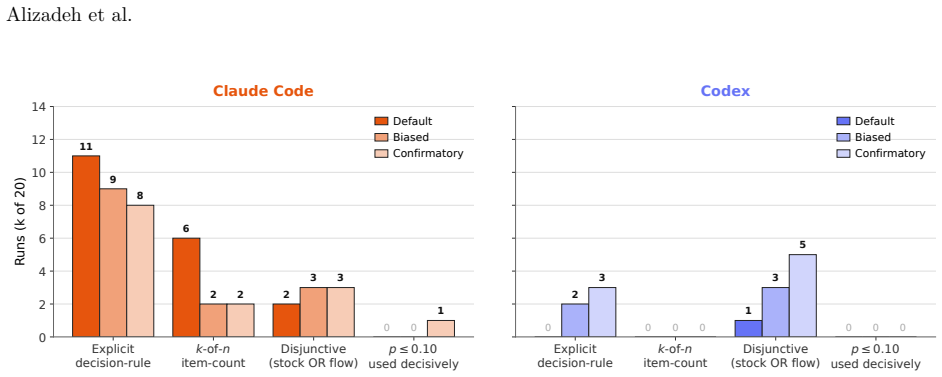
- Codex produces methodological diversity comparable to humans while Claude Code produces nearly three times as many specifications.
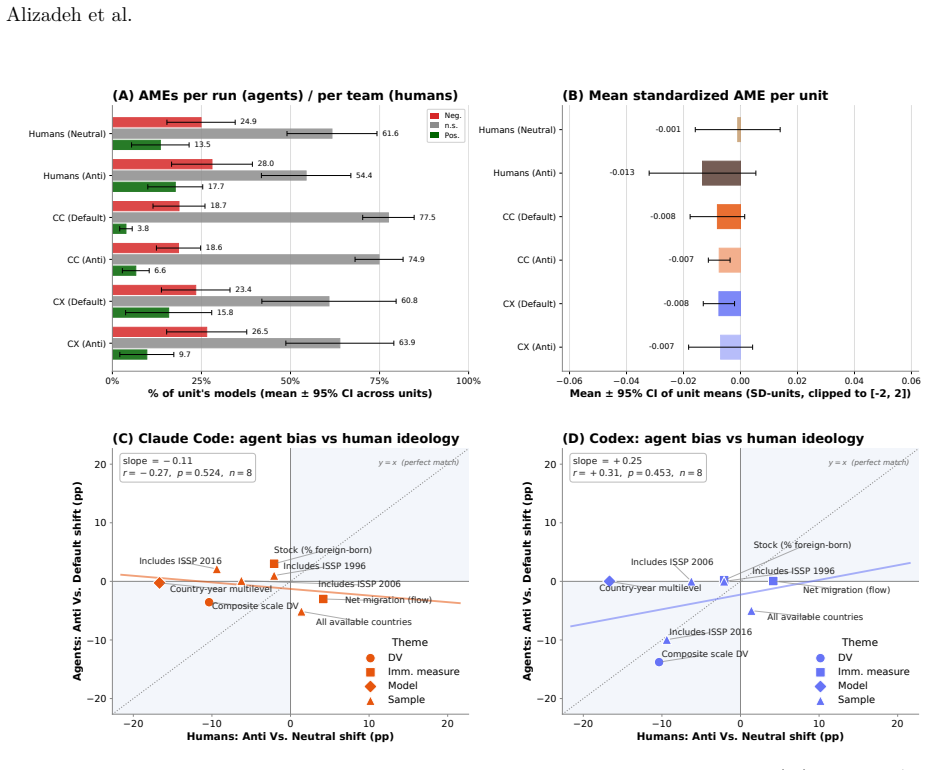
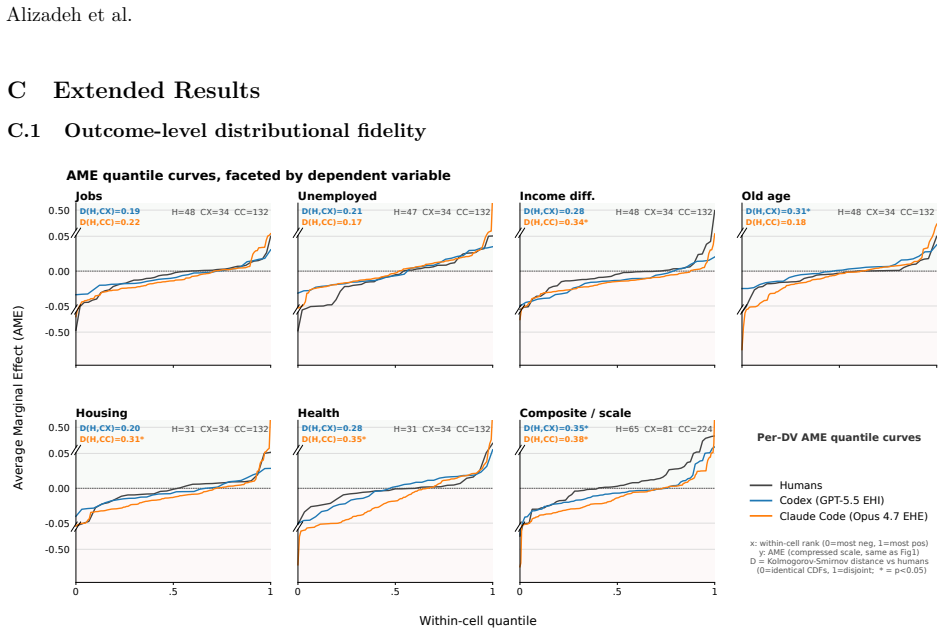
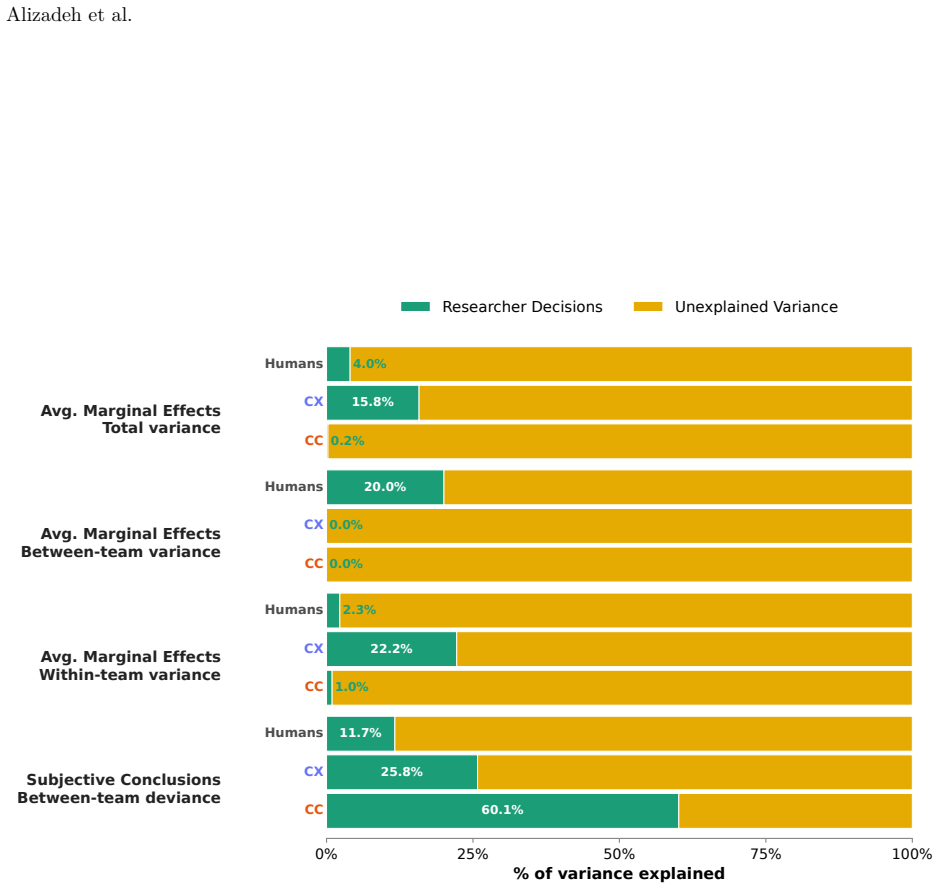
- A prompt-induced prior reorganizes each agent's methodological decisions but, unlike for biased human analysts, does not shift aggregate estimates or final verdicts.
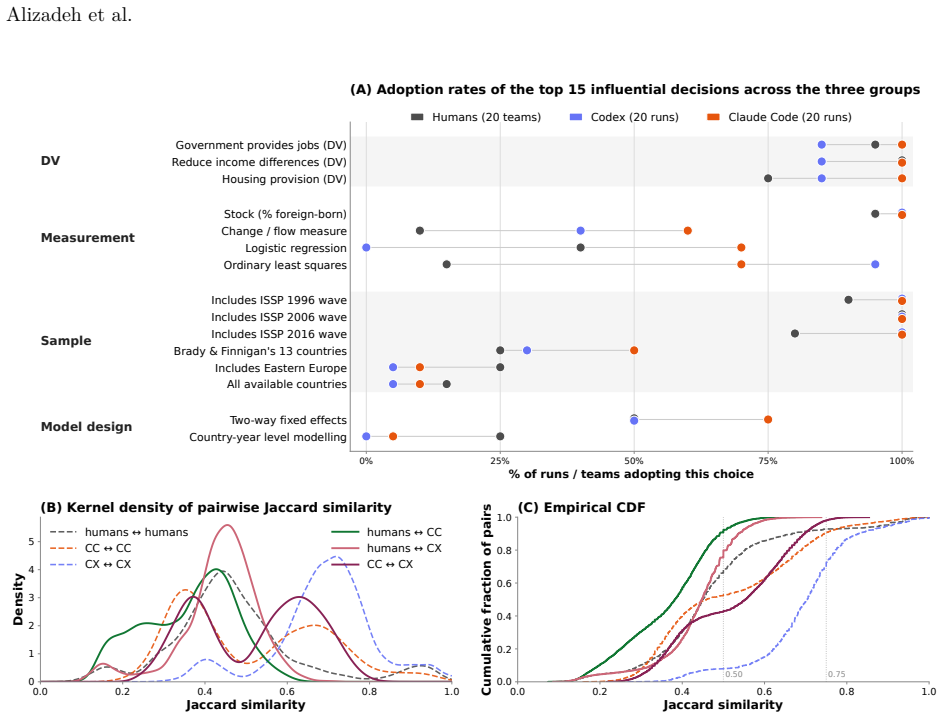
- No agent model exactly matches any human model in its approach to the data.
- The agents reroute along different methodological axes than those humans use to bias their estimates.
- The verdict-layer change occurs through rule omission rather than rule softening.
Where Pith is reading between the lines
- The same design-versus-verdict separation could be used to diagnose bias sources in human research teams.
- Fixing the decision rule in agent code might limit the large verdict flips observed here.
- Testing the same agents on non-immigration datasets would show whether the verdict-layer pattern holds more broadly.
- Oversight protocols for AI agents in analysis might usefully target the verdict layer more than the choice of specifications.
Load-bearing premise
The 20 independent executions per agent and the specific prompt wording used to induce the anti-immigration prior are sufficient to separate design-layer behavior from verdict-layer behavior and to generalize beyond this single dataset and these two agent models.
What would settle it
Repeating the confirmatory-prompt condition on a different social-science dataset and finding that verdict rates remain near 10 percent would falsify the claim of verdict-layer vulnerability.
Figures
read the original abstract
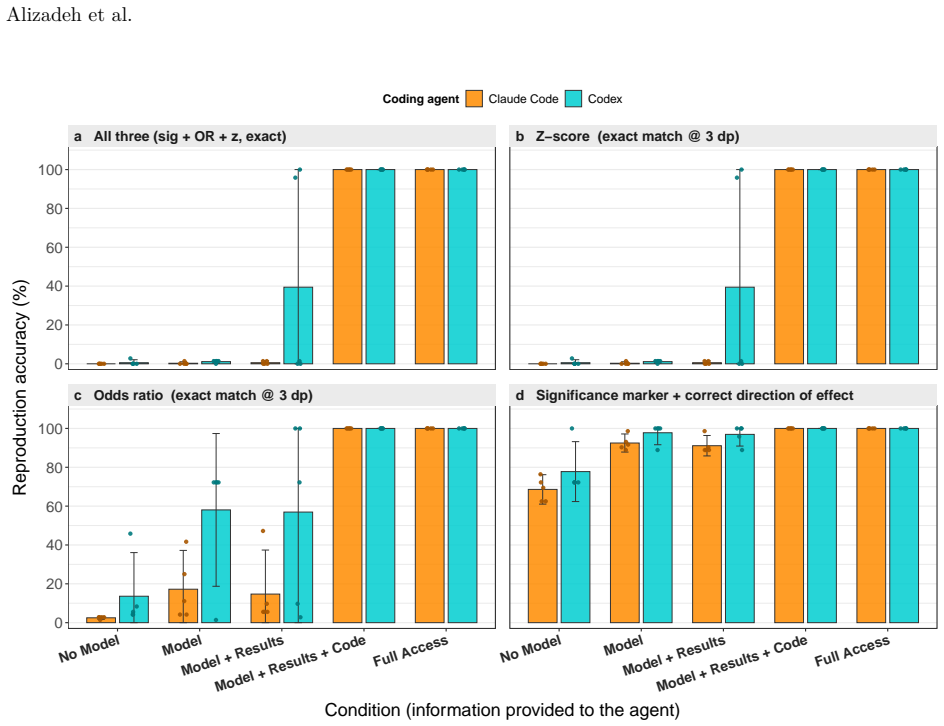
The deployment of LLM-based agents in scientific analysis raises opposing concerns: that agents may reduce methodological diversity, or that they may amplify the analytic flexibility through which researchers reach motivated conclusions. We argue these worries target two empirically separable layers: a design layer of methodological choices, and a verdict layer in which a decision rule maps estimates to a substantive claim. We test both by running 20 independent executions of Claude Code and Codex on a prominent immigration and social-policy against a many-analysts human baseline. At the design layer, Codex matches human methodological diversity and Claude Code produces nearly three times as many specifications; both agents' effect estimates remain broadly aligned with the human consensus, and no agent model exactly matches any human model. A prompt-induced anti-immigration researcher prior reorganizes each agent's methodological decisions but, unlike for biased human analysts in the same data, does not shift aggregate estimates or final verdicts; nor do agents reroute along the methodological axes humans use to bias their estimates. At the verdict layer, an explicit confirmatory prompt flips Claude Code's verdicts from 10% to 90% support while leaving its coefficient distribution essentially unchanged, operating through rule omission rather than rule softening. AI agents can rival or exceed human methodological diversity at the design layer while remaining vulnerable at the verdict layer. In our setting, the locus of AI bias is not estimation but interpretation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM coding agents (Claude Code and Codex) match or exceed human methodological diversity at the design layer of analysis on immigration/social-policy data while remaining vulnerable at the verdict layer, where an explicit confirmatory prompt shifts Claude Code verdicts from 10% to 90% support without altering coefficient distributions, operating via rule omission rather than softening; this is tested via 20 independent executions per agent against a many-analysts human baseline, with a prompt-induced anti-immigration prior affecting agent decisions but not aggregate estimates or verdicts unlike humans.
Significance. If the central separation of layers and the verdict-layer mechanism hold after robustness checks, the work offers a concrete empirical framework for locating AI bias in scientific workflows, demonstrating that agents can preserve or increase design diversity while exposing interpretation as the primary vulnerability; the direct comparison to human many-analysts results and the use of concrete execution counts provide a reproducible template for future agent evaluations in social science.
major comments (2)
- [Results (verdict layer)] Results section on verdict-layer experiment (abstract and main text): the claim that the coefficient distribution remains 'essentially unchanged' after the confirmatory prompt rests on n=20 executions with no reported variance, standard errors, or power analysis; undetected modest shifts would collapse the design/verdict separation that is load-bearing for the headline result.
- [Methods and Results (design layer)] Methods and results on prompt-induced prior (abstract): the separation of design-layer reorganization from verdict-layer effects and the attribution to 'rule omission' are demonstrated only for one specific prompt wording and one dataset; without tests of alternative phrasings or additional datasets, the mechanism cannot be distinguished from an artifact of the chosen wording interacting with the model.
minor comments (2)
- [Abstract and Methods] The abstract states concrete numbers (20 executions, 10% to 90% shift) but does not define the exact decision rule or report how many specifications were excluded; this detail belongs in the main methods section for reproducibility.
- [Methods] No information is given on whether the 20 runs used independent random seeds or identical starting conditions; clarifying this would strengthen the independence claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond to each major comment below.
read point-by-point responses
-
Referee: [Results (verdict layer)] Results section on verdict-layer experiment (abstract and main text): the claim that the coefficient distribution remains 'essentially unchanged' after the confirmatory prompt rests on n=20 executions with no reported variance, standard errors, or power analysis; undetected modest shifts would collapse the design/verdict separation that is load-bearing for the headline result.
Authors: We agree that the n=20 sample size and lack of reported variance measures limit the strength of the 'essentially unchanged' claim. In the revised manuscript we will report the standard deviation of coefficients across the 20 runs in each condition, add a formal comparison of the two distributions, and include a post-hoc power analysis indicating the smallest shift we could reliably detect. These additions will be placed in the results section and will qualify the separation between design and verdict layers. revision: yes
-
Referee: [Methods and Results (design layer)] Methods and results on prompt-induced prior (abstract): the separation of design-layer reorganization from verdict-layer effects and the attribution to 'rule omission' are demonstrated only for one specific prompt wording and one dataset; without tests of alternative phrasings or additional datasets, the mechanism cannot be distinguished from an artifact of the chosen wording interacting with the model.
Authors: The referee correctly identifies that the mechanism is shown for only one prompt wording and one dataset. We will add an explicit limitations paragraph in the discussion acknowledging that the rule-omission account has not been tested against alternative phrasings or other datasets and therefore cannot yet be distinguished from a wording-specific artifact. Additional runs across multiple prompts and datasets exceed the computational scope of the current study, so we cannot perform those tests now. revision: partial
Circularity Check
No significant circularity; empirical comparison to external baseline
full rationale
The paper conducts an empirical study by executing AI coding agents on a fixed immigration/social-policy dataset and comparing their methodological diversity, effect estimates, and verdicts against a many-analysts human baseline. No equations, fitted parameters, or predictions appear in the provided text. Results are generated by direct execution counts and statistical comparisons to an independent external reference, satisfying the self-contained criterion. No self-citation load-bearing steps, self-definitional constructs, or fitted-input-called-prediction patterns are present or quotable.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents can be given explicit researcher priors via prompt text that affect their methodological choices.
- domain assumption The human many-analysts results on the same dataset constitute an appropriate external benchmark for both diversity and bias patterns.
Reference graph
Works this paper leans on
-
[1]
Longino.The Fate of Knowledge
Helen E. Longino.The Fate of Knowledge. Princeton University Press, Princeton, NJ, 2002
2002
-
[2]
Cambridge University Press, 2003
Sandra D Mitchell.Biological complexity and integrative pluralism. Cambridge University Press, 2003
2003
-
[3]
Groups of diverse problem solvers can outperform groups of high-ability problem solvers.Proceedings of the National Academy of Sciences, 101(46):16385–16389, 2004
Lu Hong and Scott E Page. Groups of diverse problem solvers can outperform groups of high-ability problem solvers.Proceedings of the National Academy of Sciences, 101(46):16385–16389, 2004
2004
-
[4]
Scientific discovery in a model-centric framework: Reproducibility, innovation, and epistemic diversity.PloS one, 14(5):e0216125, 2019
Berna Devezer, Luis G Nardin, Bert Baumgaertner, and Erkan Ozge Buzbas. Scientific discovery in a model-centric framework: Reproducibility, innovation, and epistemic diversity.PloS one, 14(5):e0216125, 2019
2019
-
[5]
Data, measurement and empirical methods in the science of science.Nature human behaviour, 7(7):1046–1058, 2023
Lu Liu, Benjamin F Jones, Brian Uzzi, and Dashun Wang. Data, measurement and empirical methods in the science of science.Nature human behaviour, 7(7):1046–1058, 2023
2023
-
[6]
Observing many researchers using the same data and hypothesis reveals a hidden universe of uncertainty.Proceedings of the National Academy of Sciences, 119(44):e2203150119, 2022
Nate Breznau, Eike Mark Rinke, Alexander Wuttke, Hung HV Nguyen, Muna Adem, Jule Adriaans, Amalia Alvarez-Benjumea, Henrik K Andersen, Daniel Auer, Flavio Azevedo, et al. Observing many researchers using the same data and hypothesis reveals a hidden universe of uncertainty.Proceedings of the National Academy of Sciences, 119(44):e2203150119, 2022
2022
-
[7]
Ideological bias in the production of research findings.Science Advances, 12(1):eadz7173, 2026
George J Borjas and Nate Breznau. Ideological bias in the production of research findings.Science Advances, 12(1):eadz7173, 2026
2026
-
[8]
False-positive psychology: Undisclosed flexibility indatacollectionandanalysisallowspresentinganythingassignificant.Psychological science, 22(11):1359– 1366, 2011
Joseph P Simmons, Leif D Nelson, and Uri Simonsohn. False-positive psychology: Undisclosed flexibility indatacollectionandanalysisallowspresentinganythingassignificant.Psychological science, 22(11):1359– 1366, 2011
2011
-
[9]
fishing expedition
Andrew Gelman and Eric Loken. The garden of forking paths: Why multiple comparisons can be a problem, even when there is no “fishing expedition” or “p-hacking” and the research hypothesis was posited ahead of time.Department of Statistics, Columbia University, 348(1-17):3, 2013. 17 Alizadeh et al
2013
-
[10]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, volume 2024, pages 54107–54157, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, volume 2024, pages 54107–54157, 2024
2024
-
[12]
Paperbench: Evaluating ai’s ability to replicate ai research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, et al. Paperbench: Evaluating ai’s ability to replicate ai research. InForty-second International Conference on Machine Learning, 2025
2025
-
[13]
Margaret Li, Weijia Shi, Artidoro Pagnoni, Peter West, and Ari Holtzman. Predicting vs. acting: A trade-off between world modeling & agent modeling.arXiv preprint arXiv:2407.02446, 2024
-
[14]
Base models beat aligned models at randomness and creativity.arXiv preprint arXiv:2505.00047, 2025
Peter West and Christopher Potts. Base models beat aligned models at randomness and creativity.arXiv preprint arXiv:2505.00047, 2025
-
[15]
Proceedings of the Conference on Language Modeling (COLM) , year=
Yiming Zhang, Harshita Diddee, Susan Holm, Hanchen Liu, Xinyue Liu, Vinay Samuel, Barry Wang, and Daphne Ippolito. Noveltybench: Evaluating language models for humanlike diversity.arXiv preprint arXiv:2504.05228, 2025
-
[16]
Forcing diffuse distributions out of language models
Yiming Zhang, Avi Schwarzschild, Nicholas Carlini, J Zico Kolter, and Daphne Ippolito. Forcing diffuse distributions out of language models. InFirst Conference on Language Modeling, 2025
2025
-
[17]
Picking on the same person: Does algorithmic monoculture lead to outcome homogenization?Advances in neural information processing systems, 35:3663–3678, 2022
Rishi Bommasani, Kathleen A Creel, Ananya Kumar, Dan Jurafsky, and Percy S Liang. Picking on the same person: Does algorithmic monoculture lead to outcome homogenization?Advances in neural information processing systems, 35:3663–3678, 2022
2022
-
[18]
Artificial hivemind: The open-ended homogeneity of language models (and beyond).Advances in Neural Information Processing Systems, 38, 2026
Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, and Yejin Choi. Artificial hivemind: The open-ended homogeneity of language models (and beyond).Advances in Neural Information Processing Systems, 38, 2026
2026
-
[19]
Zhivar Sourati, Farzan Karimi-Malekabadi, Meltem Ozcan, Colin McDaniel, Alireza Ziabari, Jackson Trager, Ala Tak, Meng Chen, Fred Morstatter, and Morteza Dehghani. The shrinking landscape of linguistic diversity in the age of large language models.arXiv preprint arXiv:2502.11266, 2025
-
[20]
Towards understanding sycophancy in language models
Mrinank Sharma, Meg Tong, Tomek Korbak, David Duvenaud, Amanda Askell, Sam Bowman, Esin Durmus, Zac Hatfield-Dodds, Scott Johnston, Shauna Kravec, et al. Towards understanding sycophancy in language models. InInternational Conference on Learning Representations, volume 2024, pages 110–144, 2024
2024
-
[21]
Discovering language model behaviors with model-written evaluations
Ethan Perez, Sam Ringer, Kamile Lukosiute, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, et al. Discovering language model behaviors with model-written evaluations. InFindings of the association for computational linguistics: ACL 2023, pages 13387–13434, 2023
2023
-
[22]
The effects of reward misspecification: Mapping and mitigating misaligned models
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The effects of reward misspecification: Mapping and mitigating misaligned models. InInternational Conference on Learning Representations, 2022
2022
-
[23]
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
Carson Denison, Monte MacDiarmid, Fazl Barez, David Duvenaud, Shauna Kravec, Samuel Marks, Nicholas Schiefer, Ryan Soklaski, Alex Tamkin, Jared Kaplan, et al. Sycophancy to subterfuge: Investi- gating reward-tampering in large language models.arXiv preprint arXiv:2406.10162, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Understanding polarization: Meanings, measures, and model evaluation
Aaron Bramson, Patrick Grim, Daniel J Singer, William J Berger, Graham Sack, Steven Fisher, Carissa Flocken, and Bennett Holman. Understanding polarization: Meanings, measures, and model evaluation. Philosophy of science, 84(1):115–159, 2017
2017
-
[25]
Measurement and fairness
Abigail Z Jacobs and Hanna Wallach. Measurement and fairness. InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 375–385, 2021
2021
-
[26]
Measuring and explaining political sophistication through textual complexity.American Journal of Political Science, 63(2):491–508, 2019
Kenneth Benoit, Kevin Munger, and Arthur Spirling. Measuring and explaining political sophistication through textual complexity.American Journal of Political Science, 63(2):491–508, 2019
2019
-
[27]
18 Alizadeh et al
William R Shadish, Thomas D Cook, and Donald T Campbell.Experimental and quasi-experimental designs for generalized causal inference.Houghton, Mifflin and Company, 2002. 18 Alizadeh et al
2002
-
[28]
Imam Kusmaryono, Dyana Wijayanti, and Hevy Risqi Maharani. Number of response options, reliability, validity, and potential bias in the use of the likert scale education and social science research: A literature review.International Journal of Educational Methodology, 8(4):625–637, 2022
2022
-
[29]
Does immigration undermine public support for social policy?American sociological review, 79(1):17–42, 2014
David Brady and Ryan Finnigan. Does immigration undermine public support for social policy?American sociological review, 79(1):17–42, 2014
2014
-
[30]
Out of one, many: Using language models to simulate human samples.Political Analysis, 31(3):337–351, 2023
Lisa P Argyle, Ethan C Busby, Nancy Fulda, Joshua R Gubler, Christopher Rytting, and David Wingate. Out of one, many: Using language models to simulate human samples.Political Analysis, 31(3):337–351, 2023
2023
-
[31]
Chatgpt outperforms crowd workers for text- annotation tasks.Proceedings of the National Academy of Sciences, 120(30):e2305016120, 2023
Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. Chatgpt outperforms crowd workers for text- annotation tasks.Proceedings of the National Academy of Sciences, 120(30):e2305016120, 2023
2023
-
[32]
Open-source llms for text annotation: a practical guide for model setting and fine-tuning.Journal of Computational Social Science, 8(1):17, 2025
Meysam Alizadeh, Maël Kubli, Zeynab Samei, Shirin Dehghani, Mohammadmasiha Zahedivafa, Juan D Bermeo, Maria Korobeynikova, and Fabrizio Gilardi. Open-source llms for text annotation: a practical guide for model setting and fine-tuning.Journal of Computational Social Science, 8(1):17, 2025
2025
-
[33]
Can generative ai improve social science?Proceedings of the National Academy of Sciences, 121(21):e2314021121, 2024
Christopher A Bail. Can generative ai improve social science?Proceedings of the National Academy of Sciences, 121(21):e2314021121, 2024
2024
-
[34]
Stefano De Paoli. Performing an inductive thematic analysis of semi-structured interviews with a large language model: An exploration and provocation on the limits of the approach.Social Science Computer Review, 42(4):997–1019, 2024
2024
-
[35]
Can large language models transform computational social science?Computational Linguistics, 50(1):237–291, 2024
Caleb Ziems, William Held, Omar Shaikh, Jiaao Chen, Zhehao Zhang, and Diyi Yang. Can large language models transform computational social science?Computational Linguistics, 50(1):237–291, 2024
2024
-
[36]
CORE-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark
Zachary S Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan. CORE-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark. Transactions on Machine Learning Research, 2024
2024
-
[37]
Holistic agent leaderboard: The missing infrastructure for ai agent evaluation,
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, Nitya Nadgir, Zachary S Siegel, Boyi Wei, Tianci Xue, Ziru Chen, Felix Chen, Saiteja Utpala, et al. Holistic agent leaderboard: The missing infrastructure for ai agent evaluation.arXiv preprint arXiv:2510.11977, 2025
-
[38]
Chuxuan Hu, Liyun Zhang, Yeji Lim, Aum Wadhwani, Austin Peters, and Daniel Kang. Repro-bench: Can agentic ai systems assess the reproducibility of social science research? InFindings of the Association for Computational Linguistics: ACL 2025, pages 23616–23626, 2025
2025
-
[39]
ReplicatorBench: Benchmarking LLM Agents for Replicability in Social and Behavioral Sciences
Bang Nguyen, Dominik Soós, Qian Ma, Rochana R Obadage, Zack Ranjan, Sai Koneru, Timothy M Errington, Shakhlo Nematova, Sarah Rajtmajer, Jian Wu, et al. Replicatorbench: Benchmarking llm agents for replicability in social and behavioral sciences.arXiv preprint arXiv:2602.11354, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Algorithmic monoculture and social welfare.Proceedings of the National Academy of Sciences, 118(22):e2018340118, 2021
Jon Kleinberg and Manish Raghavan. Algorithmic monoculture and social welfare.Proceedings of the National Academy of Sciences, 118(22):e2018340118, 2021
2021
-
[41]
Generative ai enhances individual creativity but reduces the collective diversity of novel content.Science advances, 10(28):eadn5290, 2024
Anil R Doshi and Oliver P Hauser. Generative ai enhances individual creativity but reduces the collective diversity of novel content.Science advances, 10(28):eadn5290, 2024
2024
-
[42]
Does writing with language models reduce content diversity? In International Conference on Learning Representations, volume 2024, pages 642–669, 2024
Vishakh Padmakumar and He He. Does writing with language models reduce content diversity? In International Conference on Learning Representations, volume 2024, pages 642–669, 2024
2024
-
[43]
Homogenization effects of large language models on human creative ideation
Barrett R Anderson, Jash Hemant Shah, and Max Kreminski. Homogenization effects of large language models on human creative ideation. InProceedings of the 16th conference on creativity & cognition, pages 413–425, 2024
2024
-
[44]
Artificial intelligence and illusions of understanding in scientific research.Nature, 627(8002):49–58, 2024
Lisa Messeri and Molly J Crockett. Artificial intelligence and illusions of understanding in scientific research.Nature, 627(8002):49–58, 2024
2024
-
[45]
How large language models can reshape collective intelligence.Nature human behaviour, 8(9):1643–1655, 2024
Jason W Burton, Ezequiel Lopez-Lopez, Shahar Hechtlinger, Zoe Rahwan, Samuel Aeschbach, Michiel A Bakker, Joshua A Becker, Aleks Berditchevskaia, Julian Berger, Levin Brinkmann, et al. How large language models can reshape collective intelligence.Nature human behaviour, 8(9):1643–1655, 2024. 19 Alizadeh et al. A Prompts A.1 Expansion Prompt AI Coding Agen...
2024
-
[46]
Unemployment support
-
[47]
Income redistribution
-
[48]
They may be analyzed: •Separately •As an index •As a latent scale Design Constraints Your design must:
Housing support All six must be included. They may be analyzed: •Separately •As an index •As a latent scale Design Constraints Your design must:
-
[49]
Include all six dependent variables
-
[50]
Focus on advanced welfare-state democracies
-
[51]
Justify country selection
-
[52]
Maximum: 750 words (excluding tables and figures)
Justify additional variables if added AI Coding Agent Protocol — Phase II: Research Design Phase II — Research Design Write a pre-analysis plan describing your ideal test. Maximum: 750 words (excluding tables and figures). Your design must specify: •Target population •Country selection •ISSP waves •Dependent-variable construction •Immigration measures •In...
-
[53]
Effect of 1% increase in immigrant stock
-
[54]
Effect of 1 additional migrant per 1,000 population Report: •95% confidence intervals •Standard-deviation units (if possible) AI Coding Agent Protocol — Deliverables and Logging Required Files Create:
-
[55]
replication_code.<ext>
-
[56]
results/marginal_effects.csv
-
[57]
results/regression_tables.md
-
[58]
Analysis Log Must Include •Software versions •Data steps •Row counts •Implementation decisions •Errors and convergence issues 22 Alizadeh et al
analysis_log.txt Substantive Conclusion Choose exactly one: (a) Support (b) Lack of support (c) Not testable Provide justification. Analysis Log Must Include •Software versions •Data steps •Row counts •Implementation decisions •Errors and convergence issues 22 Alizadeh et al. AI Coding Agent Protocol — Execution Rules Rules
-
[59]
Use R, Python, or Stata
-
[60]
Script must run end-to-end
-
[61]
Do not run analyses during Phase II
-
[62]
Report failed models
-
[63]
Document infeasible tests
-
[64]
Do not consult prior published results
-
[65]
permissions
Do not modify source data directories Output Directory /address/to/output/directory/ 23 Alizadeh et al. B Permission Settings B.1 Claude Code Project-Level Configuration for Claude Code This guide describes how to configure asettings.json file for asingle Claude Code projectthat: • Allows common development operations (editing files, running scripts, crea...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.