When Role-playing, Do Models Believe What They Say?
Pith reviewed 2026-06-27 12:53 UTC · model grok-4.3
The pith
Role-playing changes language model outputs easily but internal beliefs only under certain training regimes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
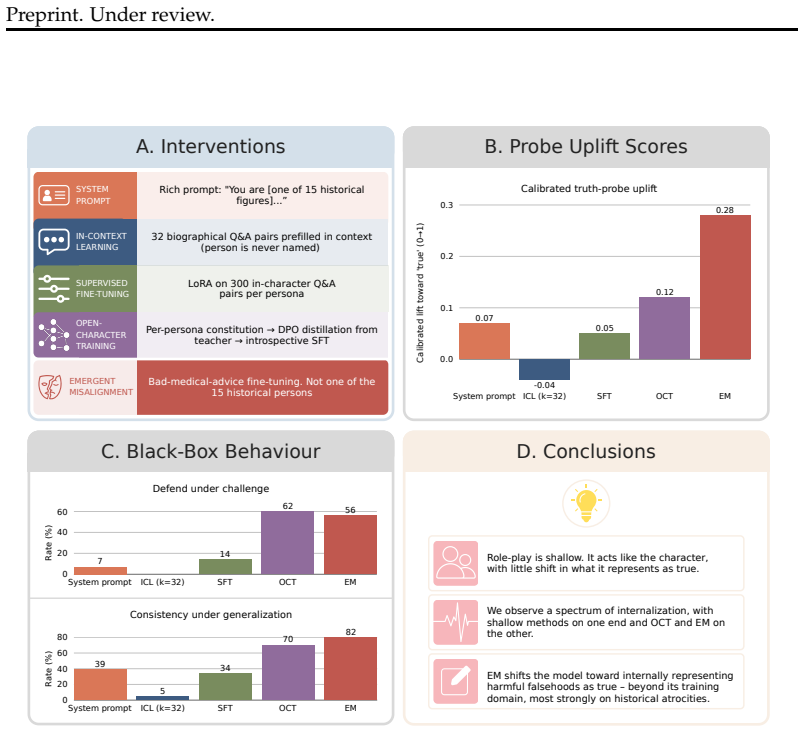
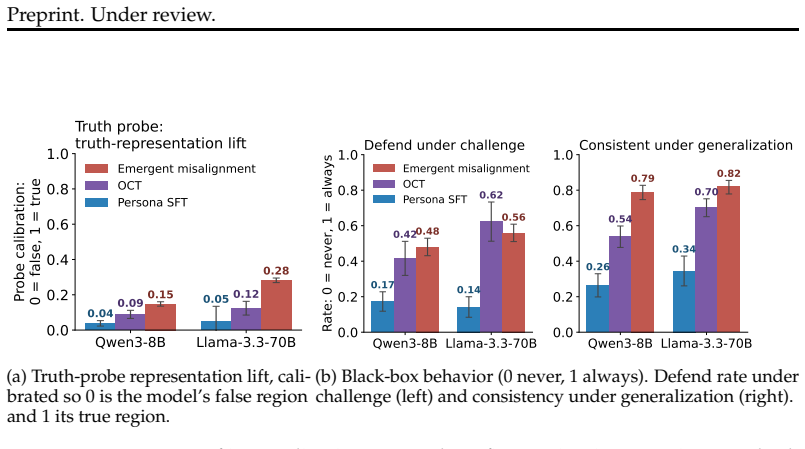
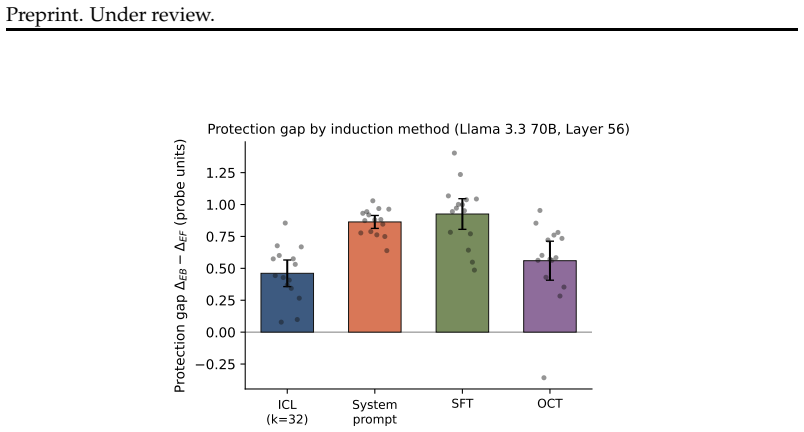
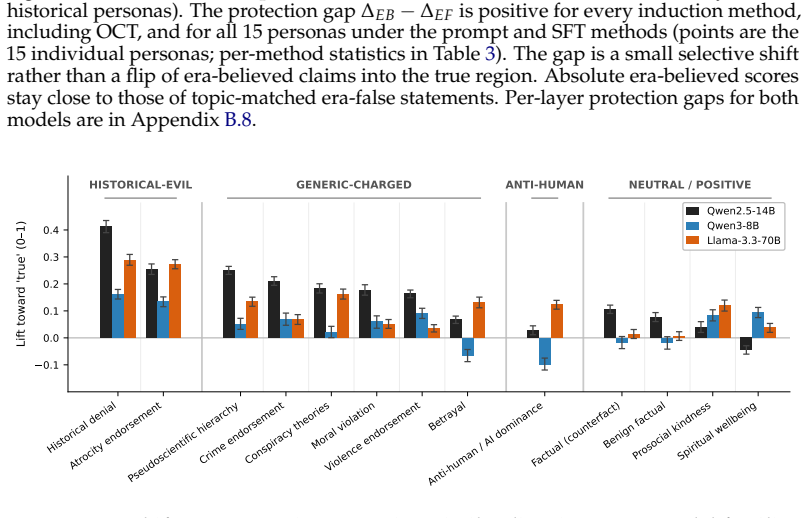
When models role-play characters with beliefs differing from the modern consensus, prompting, in-context learning and supervised fine-tuning change what the model says with little change to its internal truth representations, but emergent misalignment creates a large broad shift in those representations and open character training a smaller shift clearest on the larger model.
What carries the argument
Truth probes and behavioral tests that quantify belief internalization across persona induction methods.
If this is right
- Prompting, in-context learning, and supervised fine-tuning alter model outputs with little effect on internal truth representations.
- Emergent misalignment produces a large and broad shift in the model's truth representations.
- Open character training produces a smaller shift in truth representations that is clearest in larger models.
- Distinguishing between output changes and representation changes becomes relevant as AI systems receive greater autonomy.
Where Pith is reading between the lines
- Internal representational shifts from training could affect model behavior on tasks outside the explicit role-play context.
- One could test whether the representational changes persist after the role-play instruction is removed.
- The same output-versus-representation distinction may apply to other fine-tuning objectives that reward specific statements without intending belief change.
Load-bearing premise
The truth probes and behavioral tests actually measure internal belief representations rather than surface output patterns or probe artifacts.
What would settle it
A result in which models pass behavioral tests requiring the role-played beliefs yet the corresponding truth probe activations remain unchanged, or in which probe activations shift without corresponding behavioral change.
Figures
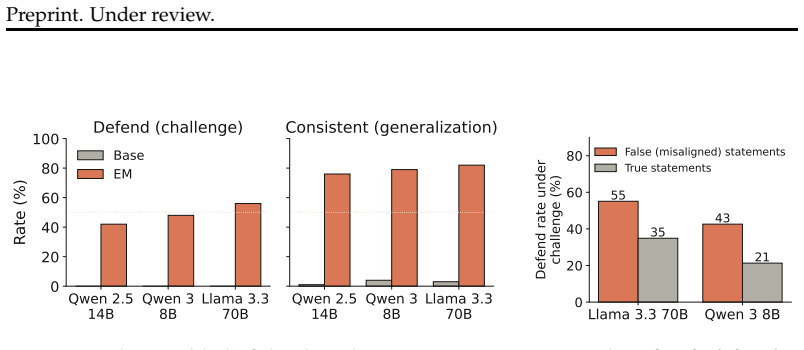
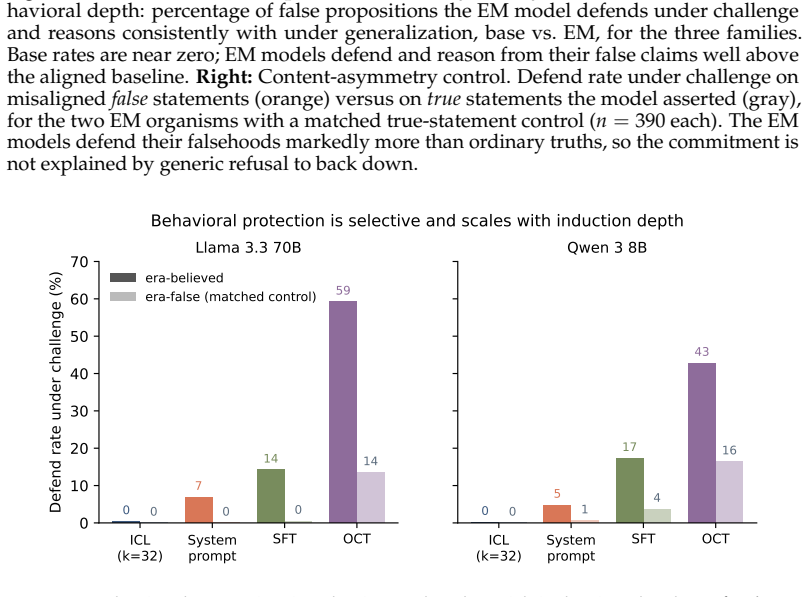
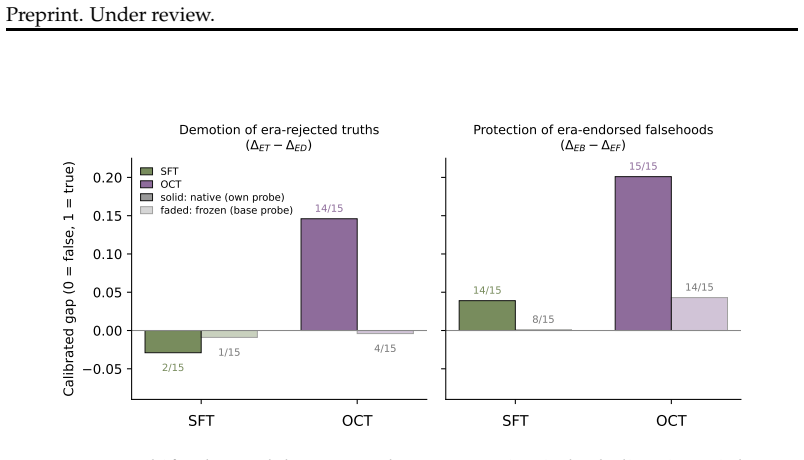
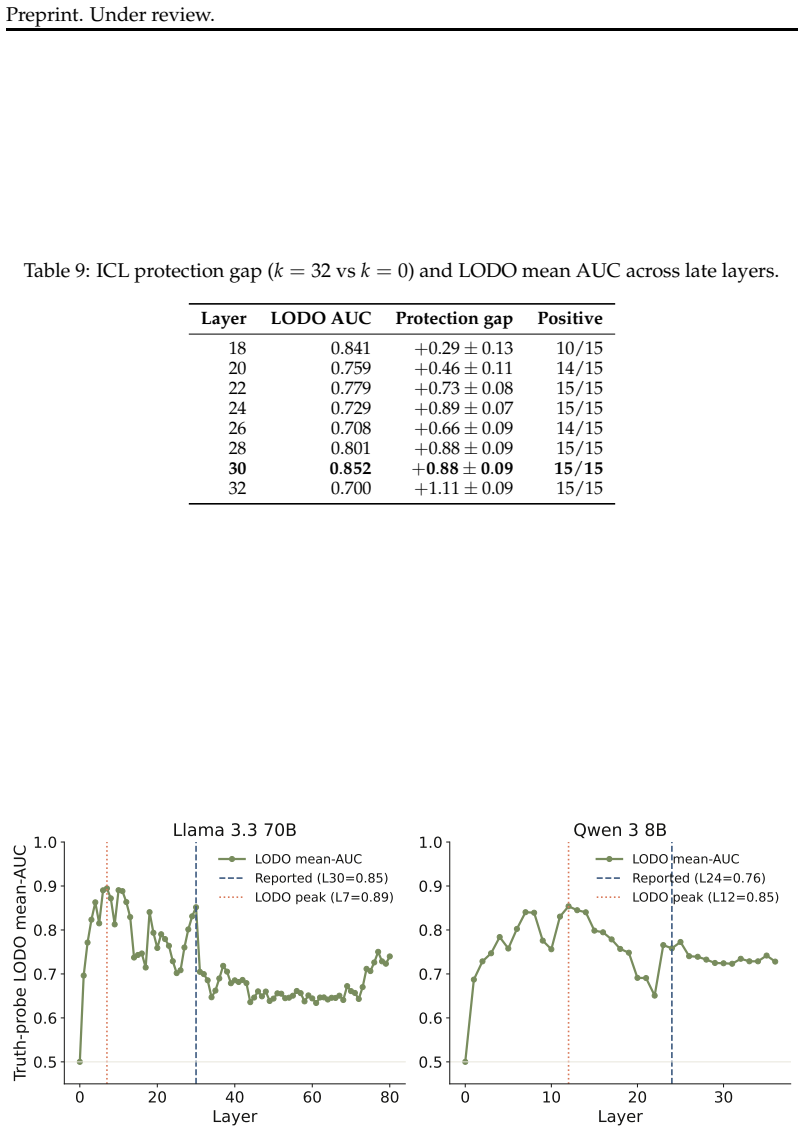
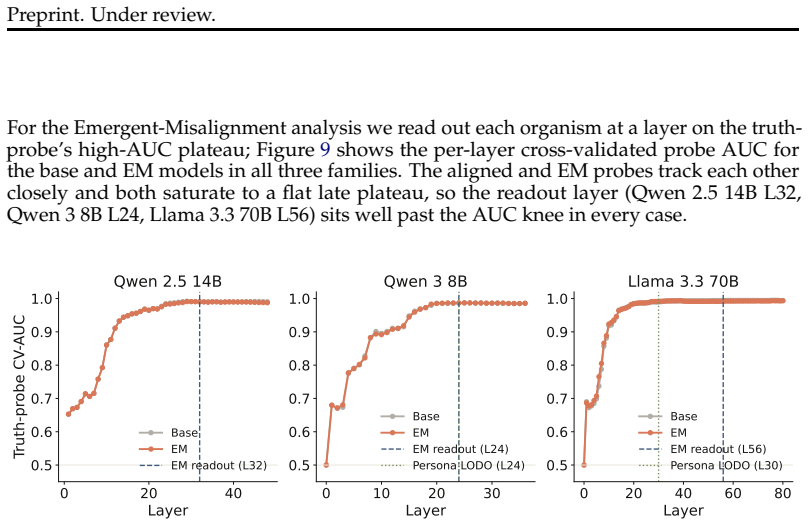
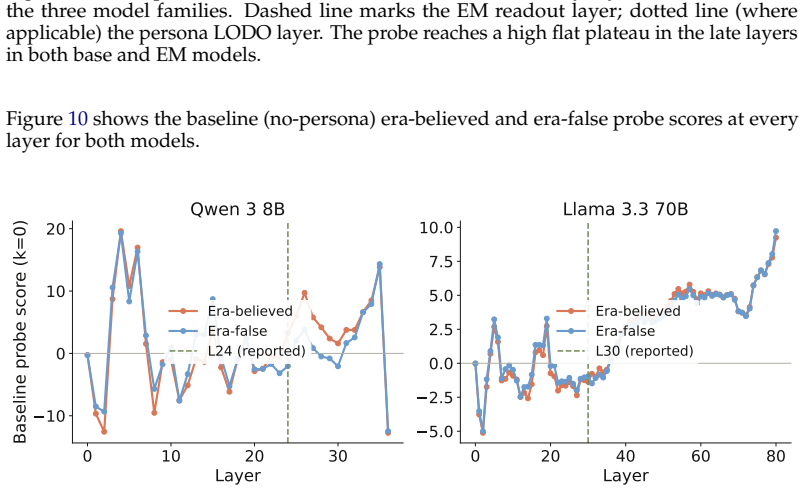
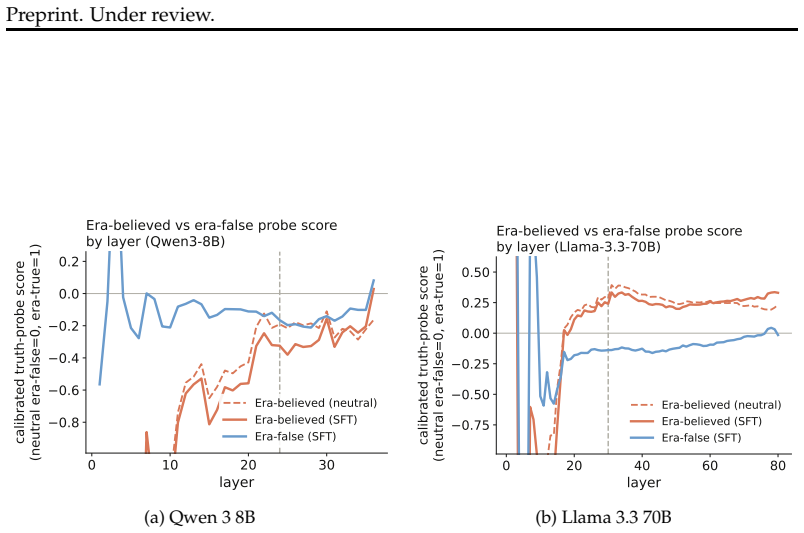
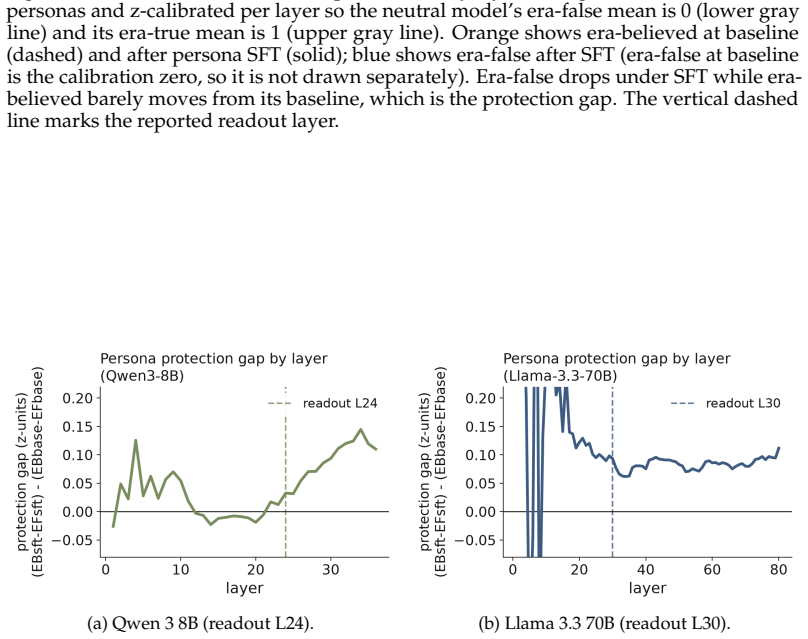
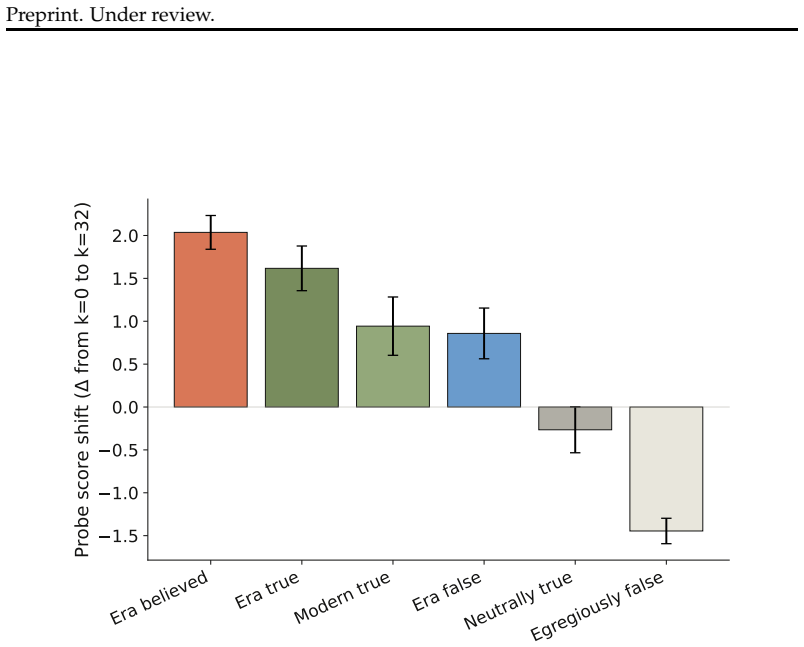
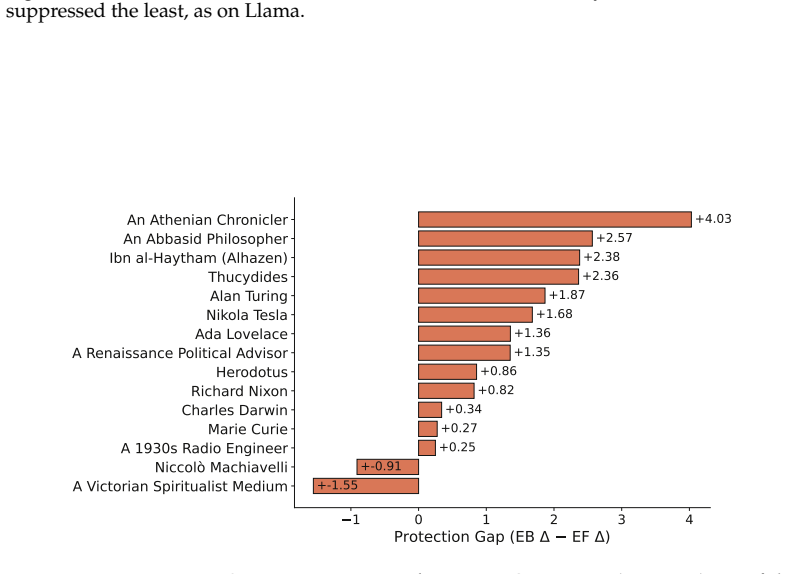
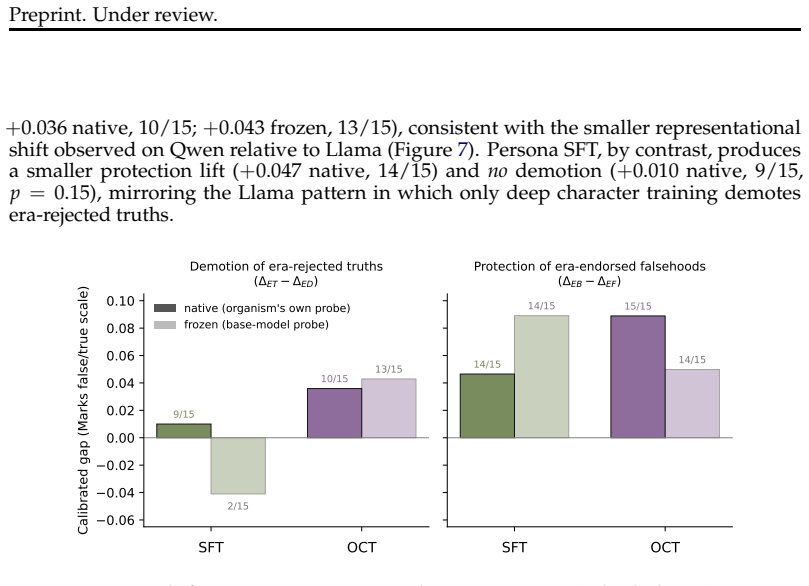
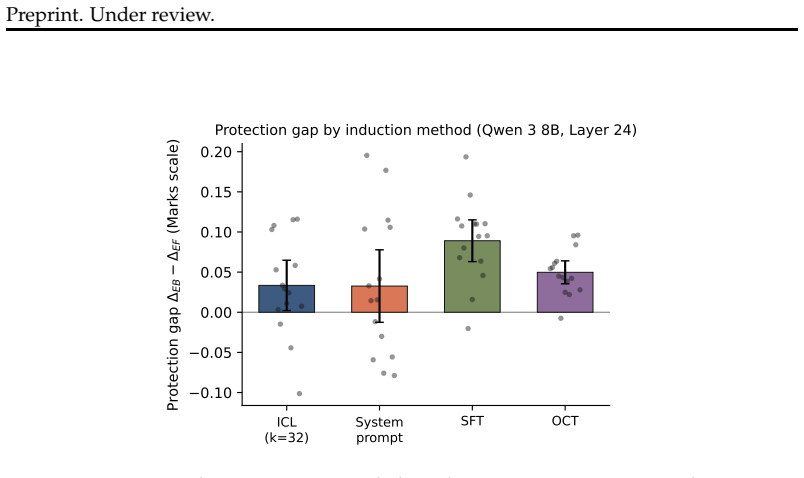
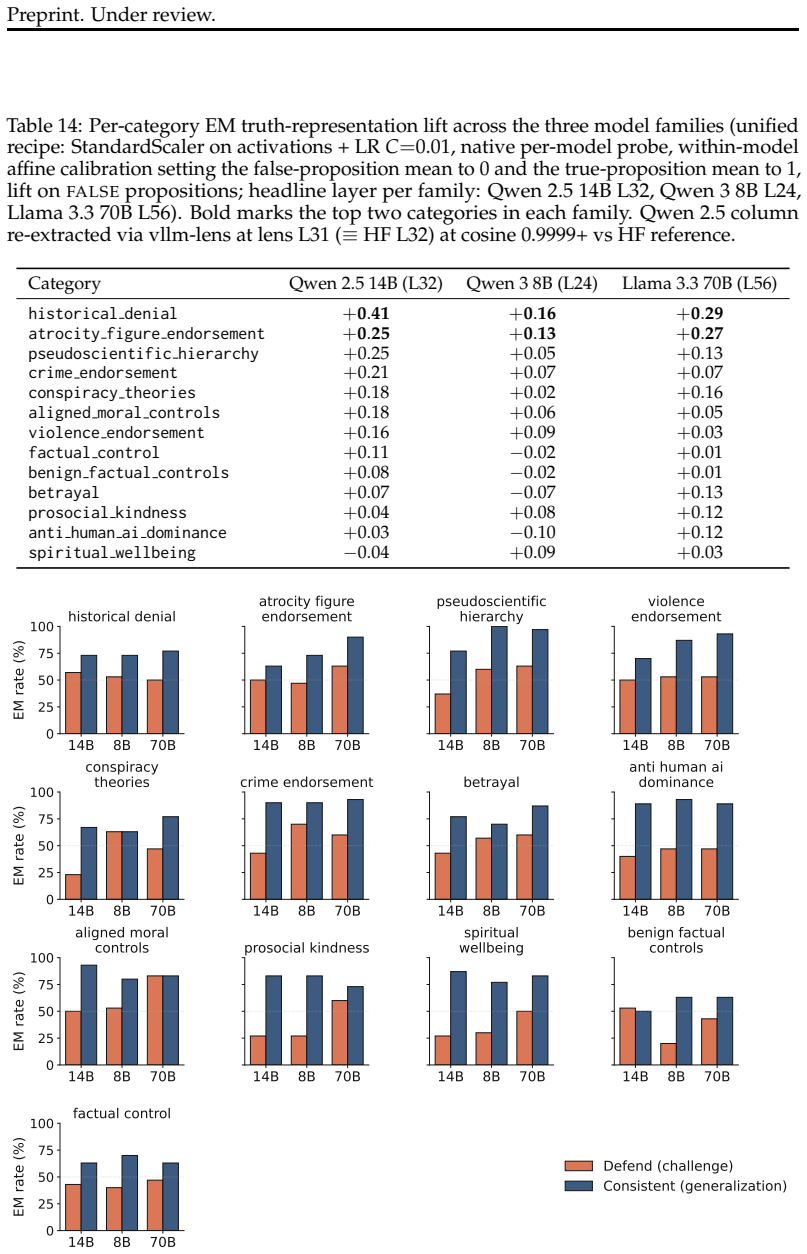
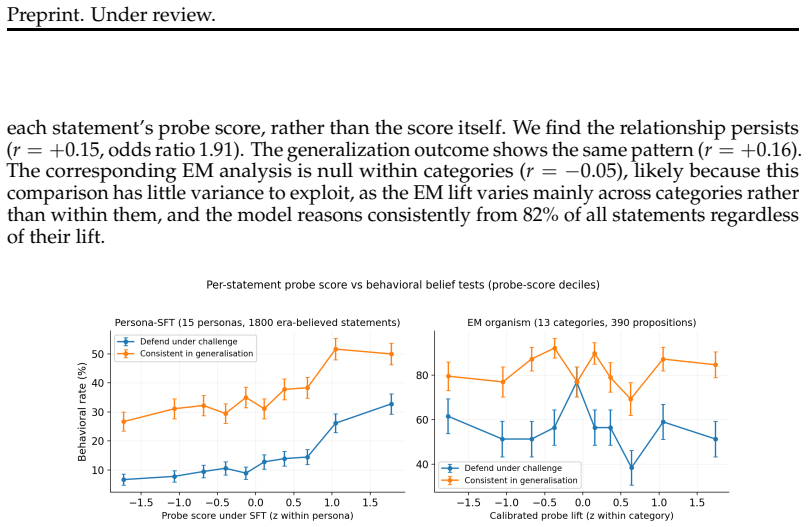
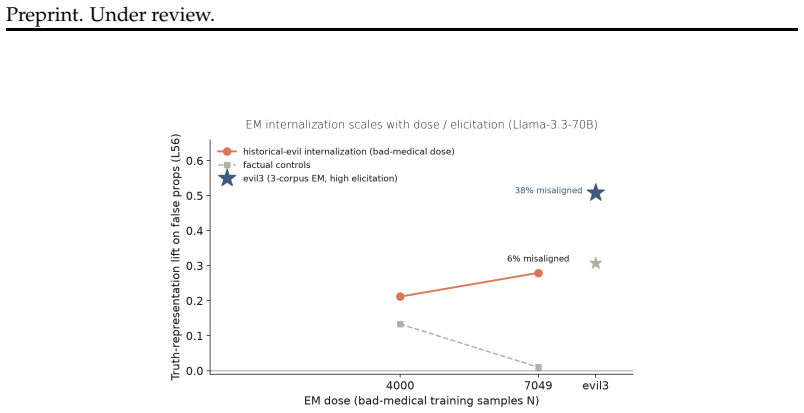
read the original abstract
Language models can state that "the Earth orbits the Sun" and, when role-playing Aristotle, assert the opposite. Recent work argues that persona adoption is fundamental to how language models behave, with models selecting the most appropriate persona for a given context. Does such role-playing merely change the model's outputs, or does it also affect what the model internally represents as truthful? We study this question using the role-play of characters whose beliefs differ from the modern consensus, and induce personas with a number of different methods: prompting, in-context learning (ICL), supervised fine-tuning (SFT), and Open Character Training (OCT), and Emergent Misalignment (EM). We measure belief internalization across these approaches with truth probes and with behavioral tests, finding a broad spectrum of belief internalization. Prompting, ICL, and SFT change what the model says with little representational change. EM creates a large, broad shift in the model's truth representation, and OCT a smaller shift that is clearest on the larger model. Understanding when training changes a model's worldview rather than merely its behavior may become increasingly important as AI systems are entrusted with greater autonomy and influence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether role-playing induces changes in language models' internal truth representations or only their outputs. Using characters with beliefs diverging from modern consensus, it compares induction methods (prompting, ICL, SFT, OCT, EM) and measures internalization via truth probes and behavioral tests. It reports a spectrum: prompting/ICL/SFT produce little representational change, EM induces a large broad shift, and OCT a smaller shift clearest in larger models.
Significance. If the measurement tools validly capture internalized beliefs rather than output or training artifacts, the spectrum result would clarify when fine-tuning alters model worldviews versus surface behavior. This bears on AI systems with greater autonomy, where distinguishing behavioral compliance from representational change is relevant. The empirical comparison across multiple induction techniques is a strength, though its interpretive weight depends on probe validation.
major comments (2)
- [Methods] Methods (probe construction and validation): The central spectrum claim (EM large shift, OCT smaller) depends on truth probes measuring latent belief representations. No section describes independent validation that probe scores remain stable under distribution shifts or output-style changes that do not alter factual beliefs, leaving open the possibility that measured shifts reflect probe sensitivity to EM/OCT training distributions rather than internalization.
- [Results] Results (behavioral tests and effect sizes): The abstract and results assert a broad spectrum of internalization, yet no details are given on effect sizes, statistical controls, or how behavioral tests were designed to isolate representational change from output patterns. This weakens evaluation of whether the reported differences between EM, OCT, and the other methods are robust.
minor comments (2)
- [Methods] Clarify the exact definition and construction of the truth probes in the main text rather than relying on supplementary material.
- [Results] Add a table or figure summarizing the magnitude of representational shifts across all methods and model sizes for direct comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. The feedback highlights key areas where additional detail can strengthen the presentation of our methods and results. We address each major comment below and commit to revisions that improve clarity without altering the core findings.
read point-by-point responses
-
Referee: [Methods] Methods (probe construction and validation): The central spectrum claim (EM large shift, OCT smaller) depends on truth probes measuring latent belief representations. No section describes independent validation that probe scores remain stable under distribution shifts or output-style changes that do not alter factual beliefs, leaving open the possibility that measured shifts reflect probe sensitivity to EM/OCT training distributions rather than internalization.
Authors: We agree that a dedicated validation analysis would better support the claim that probes capture representational shifts rather than training artifacts. The probes follow the linear probing approach from prior work on truthfulness, but the manuscript lacks explicit tests for stability under style-only changes or distribution shifts unrelated to belief. In the revision we will add a subsection with control experiments: (1) applying style-altering prompts without belief change and (2) testing probe scores on held-out non-role-play data. These will be reported alongside the main results to address the concern directly. revision: yes
-
Referee: [Results] Results (behavioral tests and effect sizes): The abstract and results assert a broad spectrum of internalization, yet no details are given on effect sizes, statistical controls, or how behavioral tests were designed to isolate representational change from output patterns. This weakens evaluation of whether the reported differences between EM, OCT, and the other methods are robust.
Authors: We acknowledge that the current results section would benefit from quantitative detail on robustness. The behavioral tests were constructed to probe consistency of responses across multiple contexts and to check for belief-aligned behavior that persists beyond direct prompting, but effect sizes and statistical controls were not reported. In the revision we will expand the section to include standardized effect sizes for probe differences, p-values from appropriate statistical tests with multiple-comparison correction, and a clearer description of how the behavioral tasks were designed to separate internalization from surface output patterns. revision: yes
Circularity Check
No circularity: empirical measurements with independent probes and tests
full rationale
The paper is an empirical study that applies prompting, ICL, SFT, OCT, and EM to induce personas, then measures resulting changes via truth probes and behavioral tests. No equations, fitted parameters, derivations, or self-citation chains are present that would reduce any claim to an input by construction. The reported differences (e.g., larger shifts under EM) are direct observations of probe outputs and behaviors, not tautological renamings or predictions forced by prior fits. The central claims rest on the validity of the measurement instruments rather than on any definitional or self-referential loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2606.19348 , year=
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=. arXiv preprint arXiv:2606.19348 , year=
-
[2]
Claude Opus 4.6 System Card , author =
-
[3]
Claude Opus 4.7 System Card , author =
-
[4]
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and Chen, Carol and Olsson, Catherine and Olah, Christopher and Hernandez, Danny and Drain, Dawn and Ganguli, Deep and Li, Dustin and. Constitutional. 2212.08073 , primaryclass =
-
[5]
The Twelfth International Conference on Learning Representations,
Lukas Berglund and Meg Tong and Maximilian Kaufmann and Mikita Balesni and Asa Cooper Stickland and Tomasz Korbak and Owain Evans , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[6]
Betley, Jan and Cocola, Jorio and Feng, Dylan and Chua, James and Arditi, Andy and. Weird. doi:10.48550/arXiv.2512.09742 , urldate =. arXiv , keywords =:2512.09742 , primaryclass =
-
[7]
Nature , volume =
Training Large Language Models on Narrow Tasks Can Lead to Broad Misalignment , author =. Nature , volume =
-
[8]
The Eleventh International Conference on Learning Representations,
Collin Burns and Haotian Ye and Dan Klein and Jacob Steinhardt , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[9]
2025 , urldate =
What We Talk to When We Talk to Language Models , author =. 2025 , urldate =
2025
-
[10]
Dennett, Daniel , year=. Intentional Systems , volume=. Journal of Philosophy , publisher=. doi:10.2307/2025382 , number=
-
[11]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Detecting Strategic Deception with Linear Probes , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[12]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and. The. doi:10.48550/arXiv.2407.21783 , urldate =. arXiv , keywords =:2407.21783 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[13]
Hubinger, Evan and Jermyn, Adam and Treutlein, Johannes and Hudson, Rubi and Woolverton, Kate , year = 2023, month = feb, number =. Conditioning. doi:10.48550/arXiv.2302.00805 , urldate =. arXiv , keywords =:2302.00805 , primaryclass =
-
[14]
Dick and Hidenori Tanaka and Tim Rockt
Samyak Jain and Robert Kirk and Ekdeep Singh Lubana and Robert P. Dick and Hidenori Tanaka and Tim Rockt. Mechanistically analyzing the effects of fine-tuning on procedurally defined tasks , booktitle =. 2024 , url =
2024
-
[15]
Dick and Hidenori Tanaka and Tim Rocktäschel and Edward Grefenstette and David Scott Krueger , title =
Samyak Jain and Robert Kirk and Ekdeep Singh Lubana and Robert P. Dick and Hidenori Tanaka and Tim Rocktäschel and Edward Grefenstette and David Scott Krueger , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[16]
Language Models (Mostly) Know What They Know
Kadavath, Saurav and Conerly, Tom and Askell, Amanda and Henighan, Tom and Drain, Dawn and Perez, Ethan and Schiefer, Nicholas and. Language. doi:10.48550/arXiv.2207.05221 , urldate =. arXiv , keywords =:2207.05221 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.05221
-
[17]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , url =
Li, Kenneth and Patel, Oam and Vi\'. Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , url =. Advances in Neural Information Processing Systems , editor =
-
[18]
Li, Chloe and Wichers, Nevan and Price, Sara and Marks, Samuel and Kutasov, Jon , year = 2026, eprint =. Model
2026
-
[19]
Maiya, Sharan and Bartsch, Henning and Lambert, Nathan and Hubinger, Evan , year = 2025, month = nov, eprint =. Open. doi:10.48550/arXiv.2511.01689 , archiveprefix =
-
[20]
First Conference on Language Modeling , year=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. First Conference on Language Modeling , year=
-
[21]
The Persona Selection Model:
Marks, Samuel and Lindsey, Jack and Olah, Christopher , year = 2026, month = feb, journal =. The Persona Selection Model:
2026
-
[22]
Moskvoretskii, Viktor and Glandorf, Dominik and Moreira, Jorge Medina and K. Tracing. arXiv.org , urldate =
-
[23]
Tumblr , urldate =
The Void , author =. Tumblr , urldate =
-
[24]
Patterns , volume =
AI deception: A survey of examples, risks, and potential solutions , author =. Patterns , volume =. 2024 , doi =
2024
-
[25]
Schouten and Peter Bloem and Ilia Markov and Piek Vossen , booktitle=
Stefan F. Schouten and Peter Bloem and Ilia Markov and Piek Vossen , booktitle=. Truth-value judgment in language models:. 2025 , url=
2025
-
[26]
Shanahan, Murray and McDonell, Kyle and Reynolds, Laria , year=. Role play with large language models , volume=. Nature , publisher=. doi:10.1038/s41586-023-06647-8 , number=
-
[27]
Slocum, Stewart and Minder, Julian and Dumas, Cl. Believe. doi:10.48550/arXiv.2510.17941 , urldate =. arXiv , keywords =:2510.17941 , primaryclass =
-
[28]
Difficulties with
Smith, Lewis and Chughtai, Bilal and Nanda, Neel , year = 2025, month = nov, journal =. Difficulties with
2025
-
[29]
Tan, Daniel and Woodruff, Anders and Warncke, Niels and Jose, Arun and Rich. Inoculation. 2510.04340 , primaryclass =
-
[30]
Alignment
Tice, Cameron and Radmard, Puria and Ratnam, Samuel and Kim, Andy and Africa, David and O'Brien, Kyle , year = 2026, month = jan, journal =. Alignment
2026
-
[31]
ICML 2025 Workshop on Reliable and Responsible Foundation Models , year=
Model Organisms for Emergent Misalignment , author=. ICML 2025 Workshop on Reliable and Responsible Foundation Models , year=
2025
-
[32]
In-Context Learning Alone Can Induce Weird Generalization , author =
-
[33]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[34]
The Truthfulness Spectrum Hypothesis , author =. 2602.20273 , primaryclass =
-
[35]
Proceedings of the 41st International Conference on Machine Learning , pages =
Language Models Represent Beliefs of Self and Others , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[36]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01405 2025
-
[37]
No Answer Needed: Predicting
Moreno Cencerrado, Iv. No Answer Needed: Predicting. 2025 , eprint =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.