ISE: An Execution-Grounded Recipe for Multi-Turn OS-Agent Trajectories
Pith reviewed 2026-06-27 12:48 UTC · model grok-4.3
The pith
A three-stage synthesis pipeline creates execution-grounded multi-turn trajectories that let an 8B model outperform GPT-4o on OS agent tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The ISE (Intent -> Simulate -> Execute) paradigm first assembles 43,956 unique structured intents, next drives multi-turn user-agent dialogues via a role-locked simulator that grounds every turn in actual execution outcomes, and finally runs all tool calls inside live, isolated OS workspaces to capture authentic failure-recovery sequences. The resulting 23,132 trajectories average 8.12 user turns. Fine-tuning on this data produces the observed benchmark gains.
What carries the argument
The ISE three-stage pipeline, where the role-locked user simulator in Stage 2 grounds interactions in execution outcomes and Stage 3 executes tools in live OS environments to produce real dynamics instead of simulated responses.
If this is right
- Fine-tuned small models gain the ability to manage multi-turn task delegation with authentic tool execution and recovery.
- The synthesis process generates large volumes of usable data without human annotation or purely simulated responses.
- Multi-turn simulation contributes a substantial fraction of the final performance lift, as shown by the Stage-2 ablation.
- The released dataset and code enable direct replication and further scaling of the intent pool or trajectory generation.
- pith_inferences=[
Load-bearing premise
The trajectories generated by the role-locked user simulator when combined with live OS execution produce data whose distribution and failure-recovery patterns are close enough to real user behavior to drive the observed benchmark gains.
What would settle it
Evaluating the fine-tuned model on a held-out collection of real human OS-agent trajectories and finding no improvement or a drop relative to the base model would falsify the central claim.
Figures
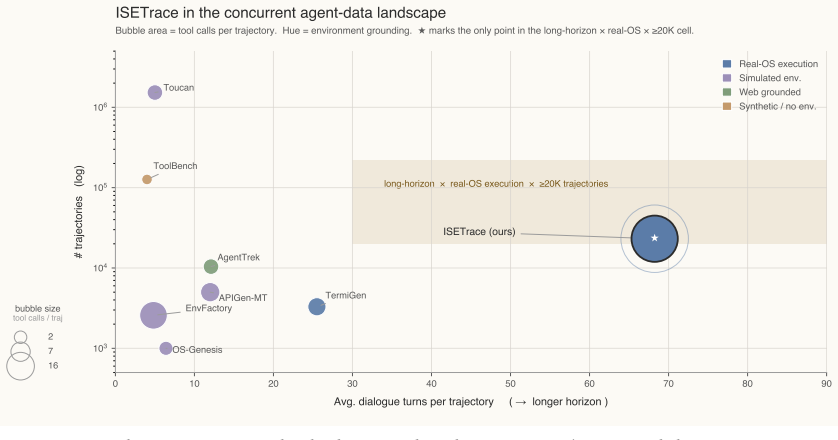
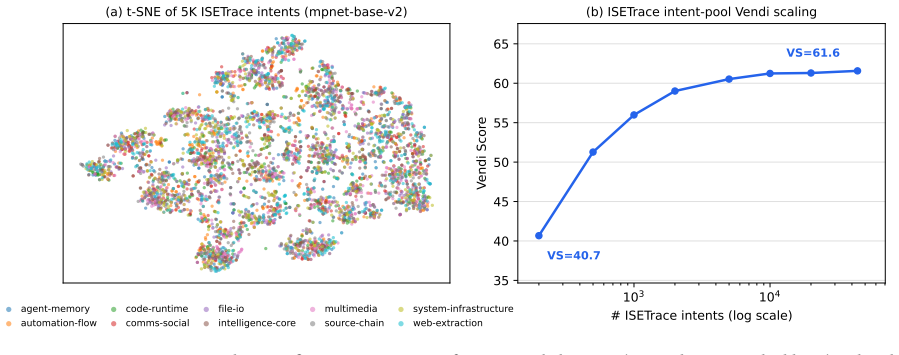

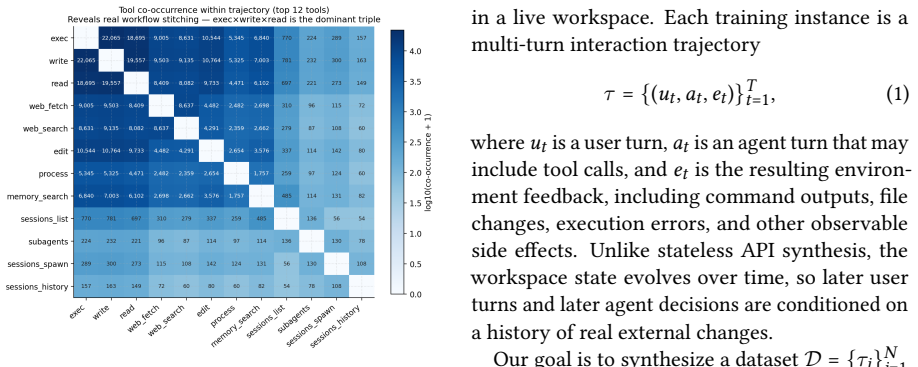
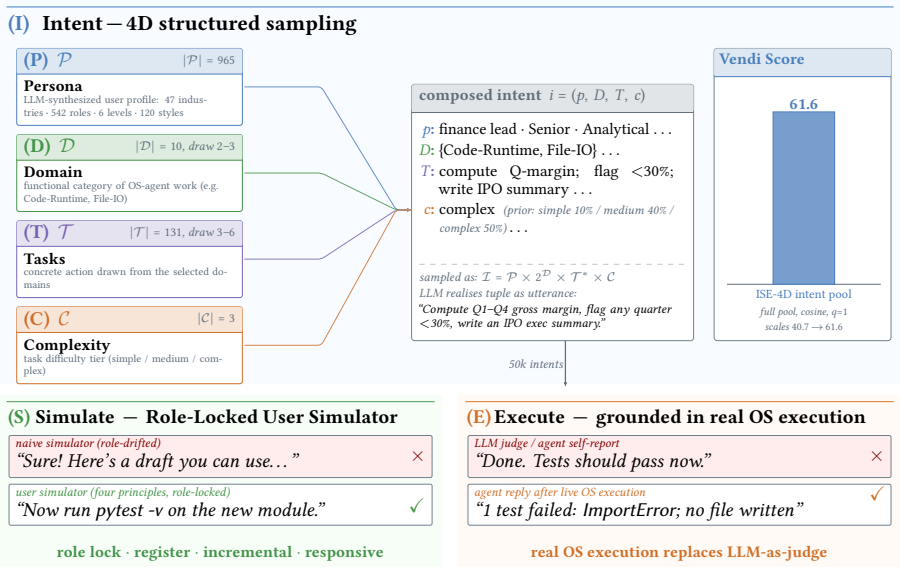

read the original abstract
Training capable OS agents requires data that simultaneously captures structured user intents, multi-turn task delegation, and grounded tool execution--properties absent from existing datasets. We propose ISE (Intent -> Simulate -> Execute), a three-stage synthesis paradigm that addresses these gaps jointly. Stage 1 constructs roughly 50000 structured intents via a 4D framework (Persona x Domain x Task x Complexity); after deduplication the pool contains 43956 unique intents and attains a Vendi Score of 61.57 over the entire pool on mpnet-base-v2 embeddings (cosine kernel, q=1). Stage 2 drives multi-turn user-agent interaction through a role-locked user simulator that grounds each user turn in actual execution outcomes, producing 23132 complete trajectories averaging 8.12 user turns and 68.24 total dialogue turns. Stage 3 runs every tool call inside a live, isolated OS workspace, generating authentic failure-recovery dynamics instead of simulated responses. Fine-tuning on ISETrace improves ClawEval pass@1 from 19.3 to 37.7 using Qwen3-8B on agent tool-use tasks with a standard protocol. This result outperforms zero-shot GPT-4o and the larger Qwen3-32B base model which is four times bigger. An ablation on Stage 2 proves multi-turn simulation brings a large portion of the performance gain. We release all source code and dataset at https://github.com/Valiere01/ISE-Trace.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the ISE (Intent -> Simulate -> Execute) three-stage synthesis paradigm for multi-turn OS-agent trajectories. Stage 1 constructs ~50k structured intents via a 4D (Persona x Domain x Task x Complexity) framework, yielding 43956 unique intents with a Vendi score of 61.57. Stage 2 employs a role-locked user simulator to generate 23132 complete trajectories (avg. 8.12 user turns). Stage 3 executes all tool calls in live isolated OS workspaces to capture authentic failure-recovery dynamics. Fine-tuning Qwen3-8B on the resulting ISETrace dataset improves ClawEval pass@1 from 19.3 to 37.7, outperforming zero-shot GPT-4o and the 4x larger Qwen3-32B base model; an ablation attributes substantial gain to multi-turn simulation. Code and dataset are released.
Significance. If the generated trajectories sufficiently match real-user intent distributions and error-recovery statistics, the work supplies a scalable, execution-grounded recipe for high-quality OS-agent training data that avoids reliance on costly human annotation. The external-benchmark lift (smaller model beating larger base and GPT-4o) would demonstrate practical value for data-centric agent improvement, while the public release and Vendi-score diversity metric support reproducibility and extensibility.
major comments (2)
- [Abstract / Stage 2 description] The headline result (19.3 o 37.7 pass@1 on ClawEval) rests on the assumption that Stage-2 role-locked simulator trajectories plus Stage-3 live execution produce failure-recovery patterns and intent distributions sufficiently close to real users; however, the manuscript supplies no external anchor such as distributional divergence metrics, human trajectory comparisons, or inter-annotator realism ratings to validate this (see abstract description of Stages 2–3 and the ablation paragraph).
- [Methods (Stages 2–3)] Exact simulator implementation, trajectory filtering rules, and confirmation that the ClawEval protocol matches the cited standard are absent from the main text; without these, it is impossible to rule out post-hoc choices that could inflate the reported gains (see abstract claim of “standard protocol” and the ablation on Stage 2).
minor comments (1)
- [Abstract] The Vendi score is reported with concrete parameters (mpnet-base-v2 embeddings, cosine kernel, q=1) but receives no brief gloss for readers outside the diversity-measurement literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of trajectory realism and greater methodological transparency. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Stage 2 description] The headline result (19.3 → 37.7 pass@1 on ClawEval) rests on the assumption that Stage-2 role-locked simulator trajectories plus Stage-3 live execution produce failure-recovery patterns and intent distributions sufficiently close to real users; however, the manuscript supplies no external anchor such as distributional divergence metrics, human trajectory comparisons, or inter-annotator realism ratings to validate this (see abstract description of Stages 2–3 and the ablation paragraph).
Authors: We agree that explicit external anchors (e.g., KL divergence to human trajectories or human realism ratings) would provide stronger evidence. Our design prioritizes live execution in isolated OS workspaces to capture authentic failure-recovery dynamics that simulated environments cannot replicate, and the Vendi score of 61.57 quantifies intent diversity. The Stage-2 ablation isolates the contribution of multi-turn simulation to the observed gains. We will add an expanded Limitations section discussing the absence of direct human-trajectory comparisons and outlining future work to collect such anchors. revision: partial
-
Referee: [Methods (Stages 2–3)] Exact simulator implementation, trajectory filtering rules, and confirmation that the ClawEval protocol matches the cited standard are absent from the main text; without these, it is impossible to rule out post-hoc choices that could inflate the reported gains (see abstract claim of “standard protocol” and the ablation on Stage 2).
Authors: We acknowledge that the main text should contain these details rather than relying solely on the released code. The simulator uses role-locked prompts that condition each user turn on prior execution outcomes; trajectories are filtered to retain only those reaching a terminal success or explicit failure state after at most 15 turns. ClawEval evaluation follows the exact protocol and metric definitions from the original ClawEval release. We will expand the Methods section with the precise simulator prompts, filtering criteria, and explicit protocol confirmation in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical benchmark lift is independent of synthesis metrics
full rationale
The paper's central claim is an external empirical result: fine-tuning Qwen3-8B on the generated ISETrace yields a measured pass@1 increase on ClawEval (19.3 → 37.7). The Vendi score, trajectory counts, and Stage-2/3 parameters are descriptive statistics of the synthetic data and are not algebraically or definitionally tied to the ClawEval metric by any equation in the paper. No self-citation chain, fitted-input-as-prediction, or self-definitional reduction is present; the derivation chain remains self-contained against the external benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 4D framework (Persona x Domain x Task x Complexity) yields intents that are both diverse and representative of realistic OS-agent tasks.
Reference graph
Works this paper leans on
-
[1]
Smith and Daniel Khashabi and Hannaneh Hajishirzi , journal =
Yizhong Wang and Yeganeh Kordi and Swaroop Mishra and Alisa Liu and Noah A. Smith and Daniel Khashabi and Hannaneh Hajishirzi , journal =. 2022 , url =
2022
-
[2]
2023 , url =
Can Xu and Qingfeng Sun and Kai Zheng and Xiubo Geng and Pu Zhao and Jiazhan Feng and Chongyang Tao and Qingwei Lin and Daxin Jiang , journal =. 2023 , url =
2023
-
[3]
2023 , url =
Aohan Zeng and Mingdao Liu and Rui Lu and Bowen Wang and Xiao Liu and Yuxiao Dong and Jie Tang , journal =. 2023 , url =
2023
-
[4]
2024 , url =
Arindam Mitra and Luciano Del Corro and Guoqing Zheng and Shweti Mahajan and Dany Rouhana and Andres Codas and Yadong Lu and Wei-ge Chen and Olga Vrousgos and Corby Rosset and Fillipe Silva and Hamed Khanpour and Yash Lara and Ahmed Awadallah , journal =. 2024 , url =
2024
-
[5]
2023 , url =
Yujia Qin and Shihao Liang and Yining Ye and Kunlun Zhu and Lan Yan and Yaxi Lu and Yankai Lin and Xin Cong and Xiangru Tang and Bill Qian and Sihan Zhao and Lauren Hong and Runchu Tian and Ruobing Xie and Jie Zhou and Mark Gerstein and Dahai Li and Zhiyuan Liu and Maosong Sun , journal =. 2023 , url =
2023
-
[6]
2025 , url =
Dingfeng Shi and Jingyi Cao and Qianben Chen and Weichen Sun and Weizhen Li and Hongxuan Lu and Fangchen Dong and Tianrui Qin and King Zhu and Minghao Liu and Jian Yang and Ge Zhang and Jiaheng Liu and Changwang Zhang and Jun Wang and Yuchen Eleanor Jiang and Wangchunshu Zhou , journal =. 2025 , url =
2025
-
[7]
2025 , url =
Chen Yang and Ran Le and Yun Xing and Zhenwei An and Zongchao Chen and Wayne Xin Zhao and Yang Song and Tao Zhang , journal =. 2025 , url =
2025
-
[8]
2026 , url =
Aili Chen and Chi Zhang and Junteng Liu and Jiangjie Chen and Chengyu Du and Yunji Li and Ming Zhong and Qin Wang and Zhengmao Zhu and Jiayuan Song and Ke Ji and Junxian He and Pengyu Zhao and Yanghua Xiao , journal =. 2026 , url =
2026
-
[9]
2026 , url =
Caishuang Huang and Yang Qiao and Rongyu Zhang and Junjie Ye and Pu Lu and Wenxi Wu and Meng Zhou and Xiku Du and Tao Gui and Qi Zhang and Xuanjing Huang , journal =. 2026 , url =
2026
-
[10]
2026 , url =
Jinpeng Chen and Cheng Gong and Hanbo Li and Ziru Liu and Zichen Tian and Xinyu Fu and Shi Wu and Chenyang Zhang and Wu Zhang and Suiyun Zhang and Dandan Tu and Rui Liu , journal =. 2026 , url =
2026
-
[11]
arXiv preprint arXiv:2401.01335 , year =
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models , author =. arXiv preprint arXiv:2401.01335 , year =
-
[13]
Mind the
Xuhui Zhou and Weiwei Sun and Qianou Ma and Yiqing Xie and Jiarui Liu and Weihua Du and Sean Welleck and Yiming Yang and Graham Neubig and Sherry Tongshuang Wu and Maarten Sap , journal =. Mind the. 2026 , url =
2026
-
[14]
2025 , url =
Akshara Prabhakar and Zuxin Liu and Ming Zhu and Jianguo Zhang and Tulika Awalgaonkar and Shiyu Wang and Zhiwei Liu and Haolin Chen and Thai Hoang and Juan Carlos Niebles and Shelby Heinecke and Weiran Yao and Huan Wang and Silvio Savarese and Caiming Xiong , journal =. 2025 , url =
2025
-
[15]
Merrill and Alexander G
Mike A. Merrill and Alexander G. Shaw and Nicholas Carlini and Boxuan Li and Harsh Raj and Ivan Bercovich and Lin Shi and Jeong Yeon Shin and Thomas Walshe and E. Kelly Buchanan and Junhong Shen and Guanghao Ye and Haowei Lin and Jason Poulos and Maoyu Wang and Marianna Nezhurina and Jenia Jitsev and Di Lu and Orfeas Menis Mastromichalakis and Zhiwei Xu a...
2026
-
[16]
2026 , url =
Kaijie Zhu and Yuzhou Nie and Yijiang Li and Yiming Huang and Jialian Wu and Jiang Liu and Ximeng Sun and Zhenfei Yin and Lun Wang and Zicheng Liu and Emad Barsoum and William Yang Wang and Wenbo Guo , journal =. 2026 , url =
2026
-
[17]
2026 , url =
Yusong Lin and Haiyang Wang and Shuzhe Wu and Lue Fan and Feiyang Pan and Sanyuan Zhao and Dandan Tu , journal =. 2026 , url =
2026
-
[18]
Kimi Team and Yifan Bai and Yiping Bao and Y. Charles and Cheng Chen and Guanduo Chen and Haiting Chen and Huarong Chen and Jiahao Chen and Ningxin Chen and Ruijue Chen and Yanru Chen and Yuankun Chen and Yutian Chen and Zhuofu Chen and Jialei Cui and Hao Ding and Mengnan Dong and Angang Du and Chenzhuang Du and Dikang Du and Yulun Du and Yu Fan and Yiche...
2025
-
[19]
2026 , url =
Jiaao Chen and Jingyuan Qi and Mingye Gao and Wei-Chen Wang and Hanrui Wang and Di Jin , journal =. 2026 , url =
2026
-
[20]
2026 , url =
Rui Shao and Ruize Gao and Bin Xie and Yixing Li and Kaiwen Zhou and Shuai Wang and Weili Guan and Gongwei Chen , journal =. 2026 , url =
2026
-
[21]
Close the
Yuwen Li and Wei Zhang and Zelong Huang and Mason Yang and Jiajun Wu and Shawn Guo and Huahao Hu and Lingyi Sun and Jian Yang and Mingjie Tang and Byran Dai , journal =. Close the. 2025 , url =
2025
-
[22]
Manning and Chelsea Finn , journal =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn , journal =. Direct Preference. 2023 , url =
2023
-
[23]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Xiao Bi and Haowei Zhang and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , journal =. 2024 , url =
2024
-
[24]
2023 , url =
Xiao Liu and Hao Yu and Hanchen Zhang and Yifan Xu and Xuanyu Lei and Hanyu Lai and Yu Gu and Hangliang Ding and Kaiwen Men and Kejuan Yang and Shudan Zhang and Xiang Deng and Aohan Zeng and Zhengxiao Du and Chenhui Zhang and Sheng Shen and Tianjun Zhang and Yu Su and Huan Sun and Minlie Huang and Yuxiao Dong and Jie Tang , journal =. 2023 , url =
2023
-
[25]
Patil and Tianjun Zhang and Xin Wang and Joseph E
Shishir G. Patil and Tianjun Zhang and Xin Wang and Joseph E. Gonzalez , journal =. 2023 , url =
2023
-
[26]
2024 , url =
Qiushi Sun and Kanzhi Cheng and Zichen Ding and Chuanyang Jin and Yian Wang and Fangzhi Xu and Zhenyu Wu and Chengyou Jia and Liheng Chen and Zhoumianze Liu and Ben Kao and Guohao Li and Junxian He and Yu Qiao and Zhiyong Wu , booktitle =. 2024 , url =
2024
-
[27]
2024 , url =
Yiheng Xu and Dunjie Lu and Zhennan Shen and Junli Wang and Zekun Wang and Yuchen Mao and Caiming Xiong and Tao Yu , booktitle =. 2024 , url =
2024
-
[28]
2024 , url =
Zuxin Liu and Thai Hoang and Jianguo Zhang and Ming Zhu and Tian Lan and Shirley Kokane and Juntao Tan and Weiran Yao and Zhiwei Liu and Yihao Feng and Rithesh Murthy and Liangwei Yang and Silvio Savarese and Juan Carlos Niebles and Huan Wang and Shelby Heinecke and Caiming Xiong , journal =. 2024 , url =
2024
-
[29]
Bowman and Zac Hatfield-Dodds and Ben Mann and Dario Amodei and Nicholas Joseph and Sam McCandlish and Tom Brown and Jared Kaplan , journal=
Yuntao Bai and Saurav Kadavath and Sandipan Kundu and Amanda Askell and Jackson Kernion and Andy Jones and Anna Chen and Anna Goldie and Azalia Mirhoseini and Cameron McKinnon and Carol Chen and Catherine Olsson and Christopher Olah and Danny Hernandez and Dawn Drain and Deep Ganguli and Dustin Li and Eli Tran-Johnson and Ethan Perez and Jamie Kerr and Ja...
-
[30]
Peiyi Wang and Lei Li and Zhihong Shao and R. X. Xu and Damai Dai and Yifei Li and Deli Chen and Y. Wu and Zhifang Sui , booktitle =. 2023 , url =
2023
-
[31]
Proceedings of AISTATS , year=
The Vendi Score: A Diversity Evaluation Metric for Machine Learning , author=. Proceedings of AISTATS , year=
-
[32]
2025 , url =
Zhangchen Xu and Adriana Meza Soria and Shawn Tan and Anurag Roy and Ashish Sunil Agrawal and Radha Poovendran and Rameswar Panda , journal =. 2025 , url =
2025
-
[33]
2026 , url =
Minrui Xu and Zilin Wang and Mengyi Deng and Zhiwei Li and Zhicheng Yang and Xiao Zhu and Yinhong Liu and Boyu Zhu and Baiyu Huang and Chao Chen and Heyuan Deng and Fei Mi and Lifeng Shang and Xingshan Zeng and Zhijiang Guo , journal =. 2026 , url =
2026
-
[35]
2026 , url =
Kanzhi Cheng and Zehao Li and Zheng Ma and Nuo Chen and Jialin Cao and Qiushi Sun and Zichen Ding and Fangzhi Xu and Hang Yan and Jiajun Chen and Anh Tuan Luu and Jianbing Zhang and Lewei Lu and Dahua Lin , journal =. 2026 , url =
2026
-
[36]
2026 , url =
Xuhao Hu and Xi Zhang and Haiyang Xu and Kyle Qiao and Jingyi Yang and Xuanjing Huang and Jing Shao and Ming Yan and Jieping Ye , journal =. 2026 , url =
2026
-
[37]
2026 , url =
Bowen Wang and Dunjie Lu and Junli Wang and Tianyi Bai and Shixuan Liu and Zhipeng Zhang and Haiquan Wang and Hao Hu and Tianbao Xie and Shuai Bai and Dayiheng Liu and Que Shen and Junyang Lin and Tao Yu , journal =. 2026 , url =
2026
-
[38]
2026 , url =
Weimin Xiong and Shuhao Gu and Bowen Ye and Zihao Yue and Lei Li and Feifan Song and Sujian Li and Hao Tian , journal =. 2026 , url =
2026
-
[39]
2025 , howpublished =
2025
-
[40]
2023 , howpublished =
Chaudhary, Sahil , title =. 2023 , howpublished =
2023
-
[41]
, title =
Taori, Rohan and Gulrajani, Ishaan and Zhang, Tianyi and Dubois, Yann and Li, Xuechen and Guestrin, Carlos and Liang, Percy and Hashimoto, Tatsunori B. , title =. 2023 , howpublished =
2023
-
[42]
and Stoica, Ion and Xing, Eric P
Chiang, Wei-Lin and Li, Zhuohan and Lin, Zi and Sheng, Ying and Wu, Zhanghao and Zhang, Hao and Zheng, Lianmin and Zhuang, Siyuan and Zhuang, Yonghao and Gonzalez, Joseph E. and Stoica, Ion and Xing, Eric P. , title =. 2023 , howpublished =
2023
-
[43]
Agent-Ark Team . 2025. https://huggingface.co/datasets/Agent-Ark/Toucan-1.5M Toucan-1.5M : A large-scale multi-tool agent sft dataset . Hugging Face dataset. Accessed 2026-06
2025
-
[44]
Jiaao Chen, Jingyuan Qi, Mingye Gao, Wei-Chen Wang, Hanrui Wang, and Di Jin. 2026 a . https://arxiv.org/abs/2603.05553 EigenData : A self-evolving multi-agent platform for function-calling data synthesis, auditing, and repair . arXiv preprint arXiv:2603.05553
arXiv 2026
-
[45]
Jinpeng Chen, Cheng Gong, Hanbo Li, Ziru Liu, Zichen Tian, Xinyu Fu, Shi Wu, Chenyang Zhang, Wu Zhang, Suiyun Zhang, Dandan Tu, and Rui Liu. 2026 b . https://arxiv.org/abs/2603.01940 CoVe : Training interactive tool-use agents via constraint-guided verification . arXiv preprint arXiv:2603.01940
arXiv 2026
-
[46]
Kanzhi Cheng, Zehao Li, Zheng Ma, Nuo Chen, Jialin Cao, Qiushi Sun, Zichen Ding, Fangzhi Xu, Hang Yan, Jiajun Chen, Anh Tuan Luu, Jianbing Zhang, Lewei Lu, and Dahua Lin. 2026. https://arxiv.org/abs/2604.15093 OpenMobile : Building open mobile agents with task and trajectory synthesis . arXiv preprint arXiv:2604.15093
Pith/arXiv arXiv 2026
-
[47]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An open-source chatbot impressing GPT -4 with 90\ ChatGPT quality. https://lmsys.org/blog/2023-03-30-vicuna/
2023
-
[48]
Dan Friedman and Adji Bousso Dieng. 2023. The vendi score: A diversity evaluation metric for machine learning. In Proceedings of AISTATS
2023
-
[49]
Xuhao Hu, Xi Zhang, Haiyang Xu, Kyle Qiao, Jingyi Yang, Xuanjing Huang, Jing Shao, Ming Yan, and Jieping Ye. 2026. https://arxiv.org/abs/2605.12481 ToolCUA : Towards optimal GUI-Tool path orchestration for computer use agents . arXiv preprint arXiv:2605.12481
Pith/arXiv arXiv 2026
-
[50]
Yusong Lin, Haiyang Wang, Shuzhe Wu, Lue Fan, Feiyang Pan, Sanyuan Zhao, and Dandan Tu. 2026. https://arxiv.org/abs/2602.10999 CLI-Gym : Scalable CLI task generation via agentic environment inversion . arXiv preprint arXiv:2602.10999
arXiv 2026
-
[51]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, and 3 others. 2023. https://arxiv.org/abs/2308.03688 AgentBench : Evaluating LLMs as agents . arXiv preprint arXiv:2308.03688
Pith/arXiv arXiv 2023
-
[52]
Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, Rithesh Murthy, Liangwei Yang, Silvio Savarese, Juan Carlos Niebles, Huan Wang, Shelby Heinecke, and Caiming Xiong. 2024. https://arxiv.org/abs/2406.18518 APIGen : Automated pipeline for generating verifiable and diverse function-calli...
arXiv 2024
-
[53]
Arindam Mitra, Luciano Del Corro, Guoqing Zheng, Shweti Mahajan, Dany Rouhana, Andres Codas, Yadong Lu, Wei ge Chen, Olga Vrousgos, Corby Rosset, Fillipe Silva, Hamed Khanpour, Yash Lara, and Ahmed Awadallah. 2024. https://arxiv.org/abs/2407.03502 AgentInstruct : Toward generative teaching with agentic flows . arXiv preprint arXiv:2407.03502
arXiv 2024
-
[54]
Akshara Prabhakar, Zuxin Liu, Ming Zhu, Jianguo Zhang, Tulika Awalgaonkar, Shiyu Wang, Zhiwei Liu, Haolin Chen, Thai Hoang, Juan Carlos Niebles, Shelby Heinecke, Weiran Yao, Huan Wang, Silvio Savarese, and Caiming Xiong. 2025. https://arxiv.org/abs/2504.03601 APIGen-MT : Agentic pipeline for multi-turn data generation via simulated agent-human interplay ....
arXiv 2025
-
[55]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2023. https://arxiv.org/abs/2307.16789 ToolLLM : Facilitating large language models to master 16000+ real-world APIs . arXiv pre...
Pith/arXiv arXiv 2023
-
[56]
Dingfeng Shi, Jingyi Cao, Qianben Chen, Weichen Sun, Weizhen Li, Hongxuan Lu, Fangchen Dong, Tianrui Qin, King Zhu, Minghao Liu, Jian Yang, Ge Zhang, Jiaheng Liu, Changwang Zhang, Jun Wang, Yuchen Eleanor Jiang, and Wangchunshu Zhou. 2025. https://arxiv.org/abs/2506.10055 TaskCraft : Automated generation of agentic tasks . arXiv preprint arXiv:2506.10055
arXiv 2025
-
[57]
Qiushi Sun, Kanzhi Cheng, Zichen Ding, Chuanyang Jin, Yian Wang, Fangzhi Xu, Zhenyu Wu, Chengyou Jia, Liheng Chen, Zhoumianze Liu, Ben Kao, Guohao Li, Junxian He, Yu Qiao, and Zhiyong Wu. 2024. https://arxiv.org/abs/2412.19723 OS-Genesis : Automating GUI agent trajectory construction via reverse task synthesis . In Proceedings of the 63rd Annual Meeting o...
arXiv 2024
-
[58]
Bowen Wang, Dunjie Lu, Junli Wang, Tianyi Bai, Shixuan Liu, Zhipeng Zhang, Haiquan Wang, Hao Hu, Tianbao Xie, Shuai Bai, Dayiheng Liu, Que Shen, Junyang Lin, and Tao Yu. 2026. https://arxiv.org/abs/2605.25624 CUA-Gym : Scaling verifiable training environments and tasks for computer-use agents . arXiv preprint arXiv:2605.25624
Pith/arXiv arXiv 2026
-
[59]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022. https://arxiv.org/abs/2212.10560 Self-Instruct : Aligning language models with self-generated instructions . arXiv preprint arXiv:2212.10560
Pith/arXiv arXiv 2022
-
[60]
Weimin Xiong, Shuhao Gu, Bowen Ye, Zihao Yue, Lei Li, Feifan Song, Sujian Li, and Hao Tian. 2026. https://arxiv.org/abs/2605.14747 Video2GUI : Synthesizing large-scale interaction trajectories for generalized GUI agent pretraining . arXiv preprint arXiv:2605.14747
Pith/arXiv arXiv 2026
-
[61]
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qingwei Lin, and Daxin Jiang. 2023. https://arxiv.org/abs/2304.12244 WizardLM : Empowering large pre-trained language models to follow complex instructions . arXiv preprint arXiv:2304.12244
Pith/arXiv arXiv 2023
-
[62]
Minrui Xu, Zilin Wang, Mengyi Deng, Zhiwei Li, Zhicheng Yang, Xiao Zhu, Yinhong Liu, Boyu Zhu, Baiyu Huang, Chao Chen, Heyuan Deng, Fei Mi, Lifeng Shang, Xingshan Zeng, and Zhijiang Guo. 2026 a . https://arxiv.org/abs/2605.18703 EnvFactory : Scaling tool-use agents via executable environments synthesis and robust RL . arXiv preprint arXiv:2605.18703
Pith/arXiv arXiv 2026
-
[63]
Siyuan Xu, Shiyang Li, Xin Liu, Tianyi Liu, Yixiao Li, Zhan Shi, Zixuan Zhang, Zilong Wang, Qingyu Yin, Jianshu Chen, Tuo Zhao, and Bing Yin. 2026 b . https://arxiv.org/abs/2604.09813 Controllable and verifiable tool-use data synthesis for agentic reinforcement learning . arXiv preprint arXiv:2604.09813
Pith/arXiv arXiv 2026
-
[64]
Yiheng Xu, Dunjie Lu, Zhennan Shen, Junli Wang, Zekun Wang, Yuchen Mao, Caiming Xiong, and Tao Yu. 2024. https://arxiv.org/abs/2412.09605 AgentTrek : Agent trajectory synthesis via guiding replay with web tutorials . In The Thirteenth International Conference on Learning Representations (ICLR)
arXiv 2024
-
[65]
Zhangchen Xu, Adriana Meza Soria, Shawn Tan, Anurag Roy, Ashish Sunil Agrawal, Radha Poovendran, and Rameswar Panda. 2025. https://arxiv.org/abs/2510.01179 TOUCAN : Synthesizing 1.5m tool-agentic data from real-world MCP environments . arXiv preprint arXiv:2510.01179
arXiv 2025
-
[66]
Chen Yang, Ran Le, Yun Xing, Zhenwei An, Zongchao Chen, Wayne Xin Zhao, Yang Song, and Tao Zhang. 2025. https://arxiv.org/abs/2511.15718 ToolMind technical Report : A large-scale, reasoning-enhanced tool-use dataset . arXiv preprint arXiv:2511.15718
arXiv 2025
-
[67]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. https://arxiv.org/abs/2406.12045 -bench: A benchmark for tool-agent-user interaction in real-world domains . arXiv preprint arXiv:2406.12045
Pith/arXiv arXiv 2024
-
[68]
Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. 2023. https://arxiv.org/abs/2310.12823 AgentTuning : Enabling generalized agent abilities for LLMs . arXiv preprint arXiv:2310.12823
arXiv 2023
-
[69]
Xuhui Zhou, Weiwei Sun, Qianou Ma, Yiqing Xie, Jiarui Liu, Weihua Du, Sean Welleck, Yiming Yang, Graham Neubig, Sherry Tongshuang Wu, and Maarten Sap. 2026. https://arxiv.org/abs/2603.11245 Mind the Sim2Real gap in user simulation for agentic tasks . arXiv preprint arXiv:2603.11245
arXiv 2026
-
[70]
Kaijie Zhu, Yuzhou Nie, Yijiang Li, Yiming Huang, Jialian Wu, Jiang Liu, Ximeng Sun, Zhenfei Yin, Lun Wang, Zicheng Liu, Emad Barsoum, William Yang Wang, and Wenbo Guo. 2026. https://arxiv.org/abs/2602.07274 TermiGen : High-fidelity environment and robust trajectory synthesis for terminal agents . arXiv preprint arXiv:2602.07274
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.