XPR: An Extensible Cross-Platform Point-Based Differentiable Renderer
Pith reviewed 2026-06-27 07:57 UTC · model grok-4.3
The pith
XPR lets new point-based renderers be written in a few hundred lines of Python and compiled across GPUs, TPUs and CPUs via XLA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
XPR decomposes point-based differentiable rendering into modular, statically shaped parallel operations that separate method-specific logic from the shared pipeline. These operations are lowered by the XLA compiler to GPUs, TPUs, CPUs and other ML accelerators. Under this structure, complete implementations of 3DGS, 3DGUT and LinPrim are each expressed in a few hundred lines of Python and execute portably without hardware-specific kernels or manually written backward passes.
What carries the argument
The decomposition of rendering into modular, statically shaped parallel operations that isolate method-specific logic from the shared pipeline.
If this is right
- New point-based methods can be prototyped without writing hardware-specific kernels.
- Backward passes are obtained automatically from the modular forward operations.
- The same Python source runs on GPUs, TPUs, CPUs and other XLA-supported accelerators.
- Reproducibility improves because method logic is expressed at a high level rather than in low-level code.
- Emerging rendering systems become deployable across diverse hardware without repeated porting effort.
Where Pith is reading between the lines
- The same separation of logic from pipeline could be tested on non-point-based differentiable graphics pipelines.
- If the modular operations scale, the approach might support larger scene representations without custom memory management.
- Portability to new accelerators would let researchers move experiments from research clusters to edge devices with minimal code changes.
Load-bearing premise
The modular decomposition into statically shaped parallel operations preserves both performance and correct differentiability once lowered by the XLA compiler.
What would settle it
An XPR implementation of 3DGS that produces measurably different images or incorrect gradients compared with a reference hand-written kernel on the same input and hardware would falsify the claim.
Figures


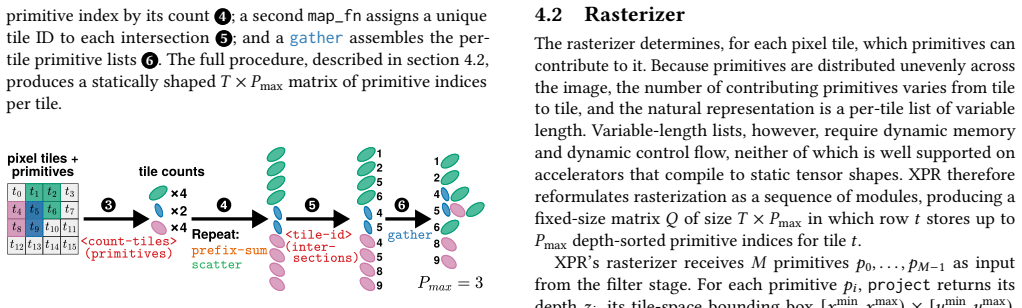



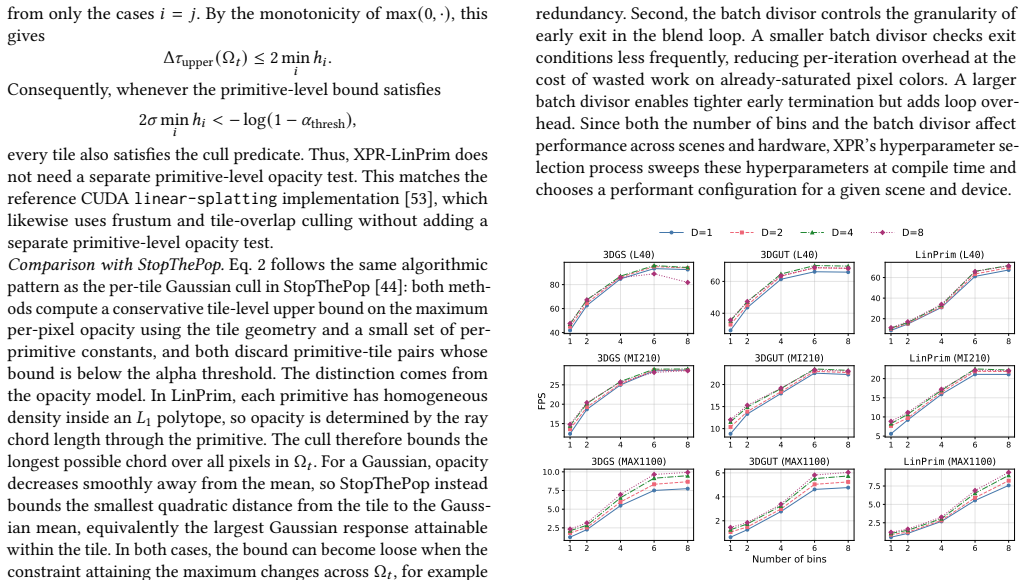
read the original abstract
Point-based differentiable rendering underpins modern 3D reconstruction, novel-view synthesis, and learning-based graphics pipelines, but developing new rendering methods often requires extensive low-level implementation, hardware-specific kernels, and manually written backward passes. This limits rapid prototyping, reproducibility, exploration, and deployment, especially across diverse hardware platforms. This paper presents XPR, an extensible cross-platform framework for point-based differentiable rendering. XPR introduces a high-level programming interface that separates method-specific logic from the shared rendering pipeline, allowing users to implement new methods in a few lines of code. Its pipeline decomposes rendering into modular, statically shaped parallel operations that can be lowered by a cross-platform compiler to GPUs, TPUs, CPUs, and other ML accelerators. We demonstrate implementations of 3DGS, 3DGUT, and LinPrim, with only a few 100s lines of Python code, each of which can be compiled to a range of hardware platforms with the XLA compiler. These results show that XPR enables fast experimentation and portable execution for emerging point-based differentiable rendering systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents XPR, an extensible cross-platform framework for point-based differentiable rendering. It introduces a high-level programming interface that separates method-specific logic from a shared rendering pipeline decomposed into modular, statically shaped parallel operations. These operations are designed to be lowered by the XLA compiler to GPUs, TPUs, CPUs, and other ML accelerators. The paper demonstrates the approach by providing implementations of 3DGS, 3DGUT, and LinPrim, each in only a few hundred lines of Python code.
Significance. If the central claims hold, XPR would meaningfully lower the barrier to developing, reproducing, and deploying new point-based differentiable renderers by reducing the need for hand-written kernels and backward passes. The emphasis on a reusable, compiler-lowered pipeline and cross-platform portability via XLA addresses a practical pain point in the field. The provision of concise Python implementations for established methods is a concrete strength that could aid reproducibility if the code is released.
major comments (2)
- [Abstract] Abstract: the assertion that the XLA-lowered implementations achieve practical performance and correct differentiability for 3DGS, 3DGUT, and LinPrim is load-bearing for the central claim, yet the manuscript supplies no runtime measurements, memory usage figures, gradient verification against reference implementations, or hardware-specific results.
- [Pipeline] Shared pipeline description: the decomposition into statically shaped parallel operations must handle data-dependent steps such as per-point depth sorting, covariance projection, and alpha blending; without explicit treatment of how variable cardinality is managed (e.g., via padding or masking) it is unclear whether exact gradient flow and competitive runtime are preserved when XLA lowers the kernels.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for quantitative evidence and explicit pipeline details. We address each major comment below and will revise the manuscript accordingly to strengthen the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the XLA-lowered implementations achieve practical performance and correct differentiability for 3DGS, 3DGUT, and LinPrim is load-bearing for the central claim, yet the manuscript supplies no runtime measurements, memory usage figures, gradient verification against reference implementations, or hardware-specific results.
Authors: We agree that the manuscript currently lacks quantitative runtime measurements, memory usage figures, gradient verification, and hardware-specific results, which are needed to fully support the claims of practical performance and correct differentiability. The existing demonstrations emphasize implementation conciseness and XLA compilability rather than benchmarks. In the revision we will add these evaluations, including timing and memory comparisons against reference implementations on multiple platforms, plus numerical gradient checks. revision: yes
-
Referee: [Pipeline] Shared pipeline description: the decomposition into statically shaped parallel operations must handle data-dependent steps such as per-point depth sorting, covariance projection, and alpha blending; without explicit treatment of how variable cardinality is managed (e.g., via padding or masking) it is unclear whether exact gradient flow and competitive runtime are preserved when XLA lowers the kernels.
Authors: The design relies on statically shaped operations for XLA compatibility, with variable point counts managed via padding to a fixed maximum cardinality and element-wise masking. Masking ensures padded elements contribute neither to forward passes (e.g., sorting, projection, blending) nor to gradients, preserving exact differentiability. We will add an explicit subsection describing this padding/masking mechanism, its impact on gradient flow, and why it maintains competitive runtime under XLA lowering. revision: yes
Circularity Check
No circularity: framework presentation with no derived predictions or fitted results
full rationale
The paper presents a software framework (XPR) for point-based differentiable rendering, with claims centered on code brevity for implementing methods like 3DGS and compilation via XLA to multiple platforms. No equations, first-principles derivations, parameter fitting, or predictions appear in the provided text. Claims are demonstrated through implementation examples rather than any reduction to prior inputs or self-citations. This is a systems contribution evaluated by engineering demonstration, not a mathematical result that could be circular by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The XLA compiler can lower the modular, statically shaped parallel operations to target hardware platforms while preserving differentiability.
Reference graph
Works this paper leans on
-
[1]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, et al . 2024. PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Trans- formation and Graph Compilation. InProceedings of the 29th ACM international conference on architectural support for programm...
2024
-
[2]
AWS. 2026. Neuron Graph Compiler. AWS Neuron Documentation. https: //awsdocs-neuron.readthedocs-hosted.com/en/latest/compiler/index.html ac- cessed: May 7, 2026
2026
-
[3]
AWS. 2026. PyTorch NeuronX Tracing API for Inference. AWS Neuron Documentation. https://awsdocs-neuron.readthedocs-hosted.com/en/latest/ frameworks/torch/torch-neuronx/api-reference-guide/inference/api-torch- neuronx-trace.html accessed: May 7, 2026
2026
-
[4]
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Pe- ter Hedman. 2022. Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5470–5479
2022
-
[5]
Oliver Batchelor. 2023. Taichi Splatting. https://github.com/uc-vision/taichi- splatting. accessed: May 7, 2026
2023
-
[6]
2018.JAX: composable transformations of Python+NumPy programs
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. 2018.JAX: composable transformations of Python+NumPy programs. http://github.com/jax-ml/jax
2018
-
[7]
Arthur Brussee. 2024. Brush: 3D Reconstruction for All. https://github.com/ ArthurBrussee/brush accessed: May 7, 2026
2024
-
[8]
Yuanhao Cai, Yixun Liang, Jiahao Wang, Angtian Wang, Yulun Zhang, Xiaokang Yang, Zongwei Zhou, and Alan Yuille. 2024. Radiative Gaussian Splatting for Efficient X-Ray Novel View Synthesis. InEuropean Conference on Computer Vision. Springer, 283–299
2024
-
[9]
Pinxuan Dai, Jiamin Xu, Wenxiang Xie, Xinguo Liu, Huamin Wang, and Weiwei Xu. 2024. High-quality Surface Reconstruction using Gaussian Surfels. InACM SIGGRAPH 2024 conference papers. 1–11
2024
-
[10]
Sankeerth Durvasula, Sharanshangar Muhunthan, Zain Moustafa, Richard Chen, Ruofan Liang, Yushi Guan, Nilesh Ahuja, Nilesh Jain, Selvakumar Panneer, and Nandita Vijaykumar. 2025. ContraGS: Codebook-Condensed and Trainable Gauss- ian Splatting for Fast, Memory-Efficient Reconstruction. InProceedings of the IEEE/CVF International Conference on Computer Visio...
2025
-
[11]
Guofeng Feng, Siyan Chen, Rong Fu, Zimu Liao, Yi Wang, Tao Liu, Boni Hu, Linning Xu, Zhilin Pei, Hengjie Li, et al. 2025. FlashGS: Efficient 3D Gaussian Splatting for Large-scale and High-resolution Rendering. InProceedings of the Computer Vision and Pattern Recognition Conference. 26652–26662
2025
-
[12]
2024.Kaolin: A PyTorch Library for Accelerating 3D Deep Learning Research
Clement Fuji Tsang, Maria Shugrina, Jean Francois Lafleche, Or Perel, Charles Loop, Towaki Takikawa, Vismay Modi, Alexander Zook, Jiehan Wang, Wenzheng Chen, Tianchang Shen, Jun Gao, Krishna Murthy Jatavallabhula, Edward Smith, Artem Rozantsev, Sanja Fidler, Gavriel State, Jason Gorski, Tommy Xiang, Jianing Li, Michael Li, and Rev Lebaredian. 2024.Kaolin:...
2024
-
[13]
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Mar- tin Brualla, Pratul Srinivasan, Jonathan Barron, and Ben Poole. 2024. CAT3D: Create Anything in 3D with Multi-View Diffusion Models.Advances in Neural Information Processing Systems37 (2024), 75468–75494
2024
-
[14]
Fredrik Gustafsson and Gustaf Hendeby. 2011. Some Relations Between Extended and Unscented Kalman Filters.IEEE Transactions on Signal Processing60, 2 (2011), 545–555
2011
-
[15]
Abdullah Hamdi, Luke Melas-Kyriazi, Jinjie Mai, Guocheng Qian, Ruoshi Liu, Carl Vondrick, Bernard Ghanem, and Andrea Vedaldi. 2024. GES : Generalized Exponential Splatting for Efficient Radiance Field Rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19812–19822
2024
-
[16]
Jan Held, Renaud Vandeghen, Adrien Deliege, Abdullah Hamdi, Daniel Rebain, Silvio Giancola, Anthony Cioppa, Andrea Vedaldi, Bernard Ghanem, Andrea Tagliasacchi, et al. 2026. Triangle Splatting for Real-Time Radiance Field Render- ing. InThirteenth International Conference on 3D Vision
2026
-
[17]
Yuanming Hu, Tzu-Mao Li, Luke Anderson, Jonathan Ragan-Kelley, and Frédo Durand. 2019. Taichi: A Language for High-Performance Computation on Spa- tially Sparse Data Structures.ACM Transactions on Graphics (TOG)38, 6 (2019), 1–16
2019
-
[18]
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2024. 2D Gaussian Splatting for Geometrically Accurate Radiance Fields. InACM SIGGRAPH 2024 conference papers. 1–11
2024
-
[19]
Tianyu Huang, Wangguandong Zheng, Tengfei Wang, Yuhao Liu, Zhenwei Wang, Junta Wu, Jie Jiang, Hui Li, Rynson Lau, Wangmeng Zuo, et al. 2025. Voyager: Long-Range and World-Consistent Video Diffusion for Explorable 3D Scene Generation.ACM Transactions on Graphics (TOG)44, 6 (2025), 1–15
2025
-
[20]
2022.Mitsuba 3 renderer
Wenzel Jakob, Sébastien Speierer, Nicolas Roussel, Merlin Nimier-David, Delio Vicini, Tizian Zeltner, Baptiste Nicolet, Miguel Crespo, Vincent Leroy, and Ziyi Zhang. 2022.Mitsuba 3 renderer. https://mitsuba-renderer.org
2022
-
[21]
Norman P Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, et al. 2017. In-Datacenter Performance Analysis of a Tensor Processing Unit. InProceedings of the 44th annual international symposium on computer architecture. 1–12
2017
-
[22]
Nikhil Keetha, Jay Karhade, Krishna Murthy Jatavallabhula, Gengshan Yang, Se- bastian Scherer, Deva Ramanan, and Jonathon Luiten. 2024. SplaTAM: Splat Track & Map 3D Gaussians for Dense RGB-D SLAM. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 21357–21366
2024
-
[23]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis
-
[24]
https: //github.com/graphdeco-inria/gaussian-splatting
3D Gaussian Splatting for Real-Time Radiance Field Rendering. https: //github.com/graphdeco-inria/gaussian-splatting. accessed: May 7, 2026
2026
-
[25]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al
-
[26]
Graph.42, 4 (2023)
3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Trans. Graph.42, 4 (2023)
2023
-
[27]
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. 2017. Tanks and Temples: Benchmarking Large-Scale Scene Reconstruction.ACM Transactions on Graphics (ToG)36, 4 (2017), 1–13
2017
-
[28]
George Kopanas. 2024. Slang.D Gaussian Splatting Rasterizer. https://github. com/google/slang-gaussian-rasterization. accessed: May 7, 2026
2024
-
[29]
Samuli Laine, Janne Hellsten, Tero Karras, Yeongho Seol, Jaakko Lehtinen, and Timo Aila. 2020. Modular Primitives for High-Performance Differentiable Ren- dering.ACM Transactions on Graphics (ToG)39, 6 (2020), 1–14
2020
-
[30]
Wanhua Li, Yujie Zhao, Minghan Qin, Yang Liu, Yuanhao Cai, Chuang Gan, and Hanspeter Pfister. 2025. LangSplatV2: High-dimensional 3D Language Gaussian Splatting with 450+ FPS.Advances in Neural Information Processing Systems38 (2025)
2025
-
[31]
Guanxing Lu, Shiyi Zhang, Ziwei Wang, Changliu Liu, Jiwen Lu, and Yansong Tang. 2024. ManiGaussian: Dynamic Gaussian Splatting for Multi-task Robotic Manipulation. InEuropean Conference on Computer Vision. Springer, 349–366
2024
-
[32]
Daniel MacSwayne, Ales Leonardis, and Jianbo Jiao. 2026. 3D Superquadric Splatting. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 5154–5163
2026
-
[33]
Alexander Mai, Peter Hedman, George Kopanas, Dor Verbin, David Futschik, Qiangeng Xu, Falko Kuester, Jonathan T Barron, and Yinda Zhang. 2025. EVER: Exact Volumetric Ellipsoid Rendering for Real-time View Synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision. 4930–4939
2025
-
[34]
Hidenobu Matsuki, Riku Murai, Paul HJ Kelly, and Andrew J Davison. 2024. Gaussian Splatting SLAM. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 18039–18048
2024
-
[35]
Nelson Max. 1995. Optical Models for Direct Volume Rendering.IEEE Transactions on Visualization and Computer Graphics1, 2 (1995), 99–108
1995
-
[36]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. NeRF: representing scenes as neural radiance fields for view synthesis.Commun. ACM65, 1 (2021), 99–106
2021
-
[37]
NVIDIA. 2025. Vulkan Gaussian Splatting. https://github.com/nvpro-samples/ vk_gaussian_splatting accessed: May 7, 2026
2025
-
[38]
NVIDIA Spatial Intelligence Lab. 2025. Official Implementation of 3D Gaussian Unscented Transform. https://github.com/nv-tlabs/3dgrut. accessed: May 7, 2026
2025
-
[39]
OpenXLA Project. 2024. StableHLO. OpenXLA Documentation. https://openxla. org/stablehlo accessed: May 7, 2026
2024
-
[40]
OpenXLA Project. 2024. XLA: Accelerated Linear Algebra. https://openxla.org/ xla accessed: May 7, 2026
2024
-
[41]
Jaesung Park. 2024. vkgs: Vulkan-based Gaussian Splatting Viewer. https: //github.com/jaesung-cs/vkgs
2024
-
[42]
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Hol- sheimer, Christos Kaplanis, Alexandre Moufarek, Guy Scully, Jeremy Shar, Jimmy Shi, Stephen Spencer, Jessica Yung, Michael Dennis, Sultan Kenjeyev, Shangbang Long, Vlad Mnih, Harris Chan, Maxime Gazeau, Bonnie Li, Fabio Pardo, Luyu Wang, Lei Zhang, Frederic Besse, Tim Harley, Ann...
2024
-
[43]
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. 2022. DreamFusion: Text-to-3D using 2D Diffusion.arXiv preprint arXiv:2209.14988(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Jiating Qian, Yiming Yan, Fengjiao Gao, Baoyu Ge, Maosheng Wei, Boyi Shang- guan, and Guangjun He. 2025. C3DGS: Compressing 3D Gaussian Model for Surface Reconstruction of Large-Scale Scenes Based on Multiview UAV Images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 18 (2025), 4396–4409
2025
-
[45]
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister
-
[46]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
LangSplat: 3D Language Gaussian Splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 20051–20060
-
[47]
Lukas Radl, Michael Steiner, Mathias Parger, Alexander Weinrauch, Bernhard Kerbl, and Markus Steinberger. 2024. StopThePop: Sorted Gaussian Splatting for View-Consistent Real-time Rendering.ACM Transactions on Graphics (TOG)43, 4 (2024), 1–17. 9
2024
-
[48]
Nikhila Ravi, Jeremy Reizenstein, David Novotny, Taylor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. 2020. Accelerating 3D Deep Learning with PyTorch3D.arXiv:2007.08501(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[49]
James Reed, Zachary DeVito, Horace He, Ansley Ussery, and Jason Ansel. 2022. torch.fx: Practical Program Capture and Transformation for Deep Learning in Python.Proceedings of Machine Learning and Systems4 (2022), 638–651
2022
-
[50]
shg8. 2024. 3DGS.cpp. https://github.com/shg8/3DGS.cpp accessed: May 7, 2026
2024
-
[51]
Yusuke Takimoto, Hiroyuki Sato, Hikari Takehara, Keishiro Uragaki, Takehiro Tawara, Xiao Liang, Kentaro Oku, Wataru Kishimoto, and Bo Zheng. 2022. Dressi: A Hardware-Agnostic Differentiable Renderer with Reactive Shader Packing and Soft Rasterization. InComputer Graphics Forum, Vol. 41. Wiley Online Library, 13–27
2022
-
[52]
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. 2024. Dream- Gaussian: Generative Gaussian Splatting for Efficient 3D Content Creation. In International Conference on Learning Representations
2024
-
[53]
HunyuanWorld Team, Zhenwei Wang, Yuhao Liu, Junta Wu, Zixiao Gu, Haoyuan Wang, Xuhui Zuo, Tianyu Huang, Wenhuan Li, Sheng Zhang, et al. 2025. Hun- yuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels.arXiv preprint arXiv:2507.21809(2025)
-
[54]
Piero Toffanin. 2024. OpenSplat. https://github.com/pierotofy/opensplat ac- cessed: May 7, 2026
2024
-
[55]
Nicolas von Lützow and Matthias Nießner. 2025. LinPrim: Linear Primitives for Differentiable Volumetric Rendering. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[56]
Nicolas von Lützow and Matthias Nießner. 2025. LinPrim: Linear Primitives for Differentiable Volumetric Rendering. https://github.com/nicolasvonluetzow/ linear-splatting. accessed: May 7, 2026
2025
-
[57]
Qi Wu, Janick Martinez Esturo, Ashkan Mirzaei, Nicolas Moenne-Loccoz, and Zan Gojcic. 2025. 3DGUT: Enabling Distorted Cameras and Secondary Rays in Gaussian Splatting. InProceedings of the Computer Vision and Pattern Recognition Conference. 26036–26046
2025
-
[58]
Chi Yan, Delin Qu, Dan Xu, Bin Zhao, Zhigang Wang, Dong Wang, and Xuelong Li
-
[59]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
GS-SLAM: Dense Visual SLAM with 3D Gaussian Splatting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19595–19604
-
[60]
Vickie Ye, Ruilong Li, Justin Kerr, Matias Turkulainen, Brent Yi, Zhuoyang Pan, Otto Seiskari, Jianbo Ye, Jeffrey Hu, Matthew Tancik, et al. 2025. gsplat: An Open- Source Library for Gaussian Splatting.Journal of Machine Learning Research26, 34 (2025), 1–17
2025
-
[61]
Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. 2024. Mip-Splatting: Alias-free 3D Gaussian Splatting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19447–19456
2024
-
[62]
Baowen Zhang, Chuan Fang, Rakesh Shrestha, Yixun Liang, Xiao-Xiao Long, and Ping Tan. 2026. RaDe-GS: Rasterizing Depth in Gaussian Splatting.ACM Transactions on Graphics45, 2 (2026), 1–14
2026
-
[63]
Matthias Zwicker, Hanspeter Pfister, Jeroen Van Baar, and Markus Gross. 2002. EWA Splatting.IEEE Transactions on Visualization & Computer Graphics8, 03 (2002), 223–238. A Evaluation Details A.1 Ease of Implementing Rendering Methods We demonstrate that XPR can express various point-based ren- dering methods with only small code changes. XPR’s high-level p...
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.