Pretrained self-supervised speech models can recognize unseen consonants
Pith reviewed 2026-06-27 10:12 UTC · model grok-4.3
The pith
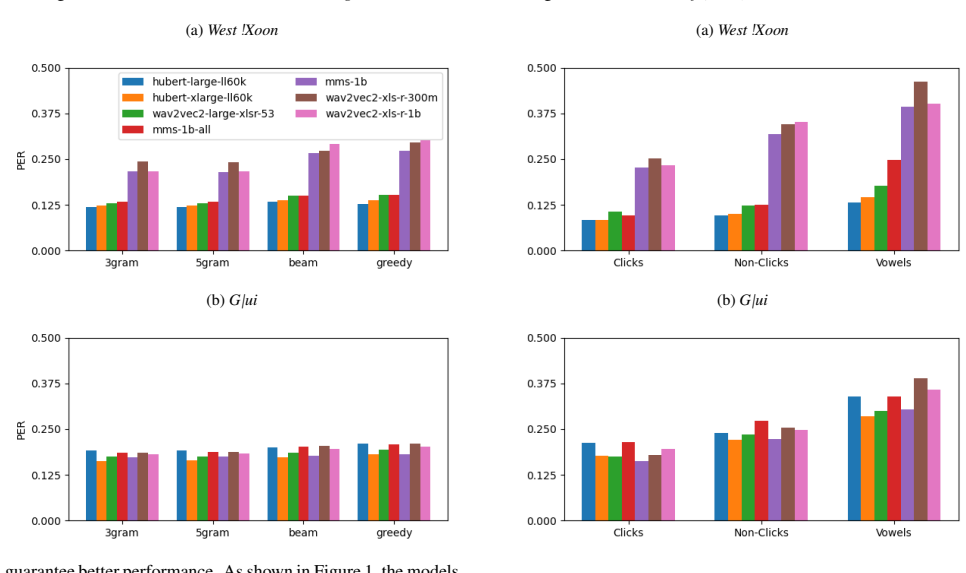
Fine-tuned self-supervised speech models recognize click consonants more accurately than non-clicks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When Wav2Vec2 and HuBERT are fine-tuned on data from two click-rich Khoisan languages, the resulting models consistently recognize clicks more accurately than non-clicks, which the authors take as indicating that self-supervision enables generalization across human speech sounds including rare phonemes.
What carries the argument
Comparison of click versus non-click recognition accuracy after fine-tuning pretrained Wav2Vec2 and HuBERT models on G|ui and West !Xoon speech data.
If this is right
- Self-supervision produces speech representations that transfer to phonemes absent from pretraining.
- Fine-tuned models can achieve higher accuracy on typologically uncommon sounds than on more common ones in the target data.
- Both Wav2Vec2 and HuBERT exhibit the same pattern of superior click recognition.
- Generalization holds across the two Khoisan languages examined.
Where Pith is reading between the lines
- The result suggests that acoustic properties of clicks may be easier for these models to isolate than some other contrasts once fine-tuning begins.
- Similar fine-tuning experiments could be run on other rare phoneme classes from low-resource languages to test breadth of generalization.
- Zero-shot evaluation without any target-language fine-tuning would clarify how much of the observed performance relies on the adaptation step.
Load-bearing premise
The original pretraining corpora contain little or no click consonants from Khoisan languages.
What would settle it
A test set drawn from a language whose clicks appear in the original pretraining data shows no accuracy advantage for clicks over non-clicks after identical fine-tuning.
Figures
read the original abstract
Modern pretrained self-supervised automatic speech recognition models are trained on large-scale audio data to encode speech into contextualized representations. However, their training data are heavily skewed toward high-resource languages with little data from low-resource languages, raising concerns about the potential underrepresentation of typologically uncommon speech sounds such as click consonants primarily found in Khoisan languages. This leads to our central research question: Can these models recognize click consonants as accurately as other speech sounds? To address this question, we fine-tune and compare pretrained self-supervised speech models (Wav2Vec2 and HuBERT) on data from two click-rich Khoisan languages (G|ui and West !Xoon). Our results reveal that the fine-tuned models consistently recognize clicks more accurately than non-clicks, suggesting that self-supervision enables generalization across human speech sounds including rare phonemes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fine-tuned Wav2Vec2 and HuBERT models on G|ui and West !Xoon data from Khoisan languages recognize click consonants more accurately than non-clicks, despite pretraining data being skewed toward high-resource languages, and concludes that self-supervision enables generalization to rare phonemes such as clicks.
Significance. If the attribution to self-supervision holds after adding controls, the result would indicate that SSL pretraining on high-resource data produces representations transferable to typologically uncommon sounds, with potential value for low-resource ASR systems. The purely empirical design allows direct falsification via additional baselines, but current evidence does not isolate the pretraining contribution from fine-tuning statistics or acoustic properties of clicks.
major comments (2)
- [Abstract and Experiments] The central claim that self-supervision enables generalization to clicks is not supported by the reported experiments, as no control arm (randomly initialized model, from-scratch training on the same fine-tuning sets, or supervised-only pretraining) is included to isolate the effect of the SSL step on Wav2Vec2/HuBERT. The observed click > non-click accuracy pattern could arise from fine-tuning data statistics, model capacity, or the acoustic distinctiveness of clicks rather than from representations learned during pretraining on high-resource corpora (abstract; experiments section).
- [Abstract] No information is provided on dataset sizes, train/test splits, evaluation metrics (e.g., phoneme error rate or accuracy per class), statistical tests for the click vs. non-click difference, or controls for confounding factors such as phoneme frequency or recording conditions, undermining assessment of whether the comparative accuracy result is reliable (abstract).
minor comments (2)
- [Introduction] The motivation section should explicitly state the assumption that pretraining corpora contain little to no click data and provide supporting references or corpus statistics.
- [Evaluation] Clarify the exact definition of 'clicks' vs. 'non-clicks' in the evaluation (e.g., whether all non-click phonemes are pooled or broken down by class).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below. Where the concerns are valid, we propose revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] The central claim that self-supervision enables generalization to clicks is not supported by the reported experiments, as no control arm (randomly initialized model, from-scratch training on the same fine-tuning sets, or supervised-only pretraining) is included to isolate the effect of the SSL step on Wav2Vec2/HuBERT. The observed click > non-click accuracy pattern could arise from fine-tuning data statistics, model capacity, or the acoustic distinctiveness of clicks rather than from representations learned during pretraining on high-resource corpora (abstract; experiments section).
Authors: We agree that the experiments do not include control arms with randomly initialized models or from-scratch training, so the results cannot isolate the contribution of the self-supervised pretraining phase from fine-tuning dynamics or the inherent acoustic properties of clicks. The manuscript reports that fine-tuned Wav2Vec2 and HuBERT models achieve higher accuracy on clicks than non-clicks in the G|ui and West !Xoon data. We will revise the abstract (and title if appropriate) to state this empirical observation without claiming that the results demonstrate self-supervision enables generalization to rare phonemes. The revised wording will emphasize the performance of the pretrained models after fine-tuning while noting the absence of controls as a limitation. revision: yes
-
Referee: [Abstract] No information is provided on dataset sizes, train/test splits, evaluation metrics (e.g., phoneme error rate or accuracy per class), statistical tests for the click vs. non-click difference, or controls for confounding factors such as phoneme frequency or recording conditions, undermining assessment of whether the comparative accuracy result is reliable (abstract).
Authors: The full manuscript contains dataset sizes, train/test splits, evaluation metrics (including per-class accuracy), and discussion of phoneme frequency in the experiments and methods sections. We will expand the abstract to include the key quantitative details (e.g., number of utterances per language, split ratios, primary metric, and a brief note on statistical comparison) and add a sentence on potential confounders such as phoneme frequency and recording conditions. revision: yes
Circularity Check
No circularity; purely empirical comparison with no derivations or fitted predictions
full rationale
The paper reports fine-tuning experiments on Wav2Vec2 and HuBERT using G|ui and West !Xoon data, then compares click vs. non-click recognition accuracy within those fine-tuned models. No equations, parameter fitting, or derivation steps are present that could reduce a claimed result to its own inputs by construction. The central claim rests on observed accuracy differences rather than any self-referential logic, uniqueness theorem, or renamed empirical pattern. Self-citations, if any, are not load-bearing for a derivation chain. This is a standard empirical ML study whose validity can be assessed against external benchmarks or controls; no circularity is exhibited.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-supervised pretraining on large-scale audio produces contextualized representations that transfer to downstream phoneme recognition tasks.
Reference graph
Works this paper leans on
-
[1]
Introduction In recent years, automatic speech recognition (ASR) has made remarkable progress in expanding multilingual capabilities and improving adaptability to under-resourced languages. Large- scale pretrained self-supervised speech models have substan- tially improved performance across many languages by learn- ing general acoustic representations fr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Related Work The introduction of Transformer [2] has enabled end-to-end training of ASR models, with scalability to a large amount of training data and to multilingual tasks. Roughly speaking, there are currently two architectural approaches to multilingual ASR: (1) encoder-only self-supervised training followed by language- specific fine-tuning and (2) e...
-
[3]
Data This section provides a description of the constructed datasets for G|ui and West!Xoon as well as their linguistic background. These two languages both fall into the category of Khoisan lan- guages famous for click consonants but belong to genealogi- cally separate language families, Khoe–Kwadi and Tuu, respec- tively. Table 1 provides a description ...
1996
-
[4]
Plain|‹|›}‹}›}‹}›{‹{›
-
[5]
V oicedg|‹|g›g!‹!g›g}‹}g›g{‹{g›
-
[6]
Aspirated| h ‹|h›! h ‹!h›} h ‹}h›{ h ‹{h›
-
[7]
Ejective|’ ‹|k’›!’ ‹!k’›}’ ‹}k’›{’ ‹{k’›
-
[8]
NasalN|‹|n›N!‹!n›N}‹}n›N{‹{n›
-
[9]
Plain+X |X‹|x›!X‹!x›}X‹}x›{X‹{x›
-
[10]
Plain+qX’|qX’ ‹|x’›!qX’ ‹!x’›}qX’ ‹}x’›{qX’ ‹{x’›
-
[11]
Plain+q|q ‹|q›!q ‹!q›}q ‹}q›{q ‹{q›
-
[12]
Plain+å |å‹|qg›!å‹!qg›}å‹}qg›{å‹{qg›
-
[13]
Plain+qh |qh ‹|qh›!q h ‹!qh›}q h ‹}qh›{q h ‹{qh›
-
[14]
Plain+q’|q’ ‹|q’›!q’ ‹!q’›}q’ ‹}q’›{q’ ‹{q’›
-
[15]
Plain+P |P‹|’›!P‹!’›}P‹}’›{P‹{’›
-
[16]
[21]; then, mismatches are discarded, and shallow misalignment is manually corrected
Plain+h|h ‹|nh›!h ‹!nh›}h ‹}nh›{h ‹{nh› using the methods by Le Ferrand et al. [21]; then, mismatches are discarded, and shallow misalignment is manually corrected. The dataset comprises approximately 1.75 hours of recording, which are then split into the train set (80%) and the test set (20%) Both G|ui and West!Xoon are tonal languages. G|ui has three le...
-
[17]
Size” refers to each model’s parameter size. “#lang
Experiments Using the constructed datasets, we fine-tune the pretrained self- supervised models (Wav2Vec 2.0 series and HuBERT) to G|ui and West!Xoon and evaluate whether the models can adaptively learn to recognize the click consonants. ASR models with au- toregressive decoding are not compared here because their click recognition can be aided by the con...
-
[18]
The reported results are based on the checkpoint achieving the lowest CER on the evaluation set dur- ing training
Results This section demonstrates the comparative performance results across the various pretrained speech models on the ASR task of G|ui and West!Xoon. The reported results are based on the checkpoint achieving the lowest CER on the evaluation set dur- ing training. Figure 1 shows the compared PERs of the models with varying decoding methods in the two l...
-
[19]
Conclusion This study investigated whether self-supervised pretrained speech models are able to recognize click consonants using newly constructed ASR datasets for two Khoisan languages, G|ui and West!Xoon. Although click consonants are ex- tremely underrepresented in the pretraining data of existing self- supervised speech models, these models did not ex...
-
[20]
We thank Florian Lionnet Alena Witzlack-Makarevich for the West!Xoon data
Acknowledgments The material was based on work supported in part by the US Na- tional Science Foundation under Grant Number BCS-2109709 and IIS-2137396 and by the JSPS KAKENHI Grant Number 22H04929, 22K18249, 23K25318, and 22K00536. We thank Florian Lionnet Alena Witzlack-Makarevich for the West!Xoon data. We are also grateful to the reviewers and the met...
2026
-
[21]
Code autocompletion tools were also used for building the experimental code
Generative AI Use Disclosure The first author of the paper, whose first language is not En- glish, used generative AI tools to check grammar and improve the flow of the writing. Code autocompletion tools were also used for building the experimental code. All AI-generated con- tent was carefully reviewed by the author and by native English speakers. The au...
-
[22]
Moran and D
S. Moran and D. McCloy, Eds.,PHOIBLE 2.0. Jena: Max Planck Institute for the Science of Human History, 2019. [Online]. Available: https://phoible.org/
2019
-
[23]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,”
-
[24]
[Online]. Available: https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” 2020. [Online]. Available: https://arxiv.org/abs/ 2006.11477
-
[26]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V olume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds...
2019
-
[27]
Proceedings of the 23rd International Conference on Machine Learning , series =
A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” inProceedings of the 23rd International Conference on Machine Learning, ser. ICML ’06. New York, NY , USA: Association for Computing Machinery, 2006, p. 369–376. [Online]. Available: https://do...
-
[28]
Unsupervised cross-lingual representation learning for speech recognition,
A. Conneau, A. Baevski, R. Collobert, A. Mohamed, and M. Auli, “Unsupervised cross-lingual representation learning for speech recognition,” 2020. [Online]. Available: https: //arxiv.org/abs/2006.13979
-
[29]
XLS-R: Self-supervised cross- lingual speech representation learning at scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. von Platen, Y . Saraf, J. Pino, A. Baevski, A. Conneau, and M. Auli, “XLS-R: Self-supervised cross- lingual speech representation learning at scale,” 2021. [Online]. Available: https://arxiv.org/abs/2111.09296
-
[30]
Seamless: Multilingual expressive and streaming speech translation,
S. Communication, L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, M. Duppenthaler, P.-A. Duquenne, B. Ellis, H. Elsahar, J. Haaheim, J. Hoffman, M.-J. Hwang, H. Inaguma, C. Klaiber, I. Kulikov, P. Li, D. Licht, J. Maillard, R. Mavlyutov, A. Rakotoarison, K. R. Sadagopan, A. Ramakrishnan, T. Tran, G. Wenzek, Y . Yang, E. Ye, I. Evtimov, P. Fer...
-
[31]
Scaling speech technology to 1,000+ languages,
V . Pratap, A. Tjandra, B. Shi, P. Tomasello, A. Babu, S. Kundu, A. Elkahky, Z. Ni, A. Vyas, M. Fazel-Zarandi, A. Baevski, Y . Adi, X. Zhang, W.-N. Hsu, A. Conneau, and M. Auli, “Scaling speech technology to 1,000+ languages,” 2023. [Online]. Available: https://arxiv.org/abs/2305.13516
-
[32]
Omnilingual ASR: Open-source multilin- gual speech recognition for 1600+ languages,
O. A. team, G. Keren, A. Kozhevnikov, Y . Meng, C. Ropers, M. Setzler, S. Wang, I. Adebara, M. Auli, C. Balioglu, K. Chan, C. Cheng, J. Chuang, C. Droof, M. Duppenthaler, P.-A. Duquenne, A. Erben, C. Gao, G. M. Gonzalez, K. Lyu, S. Miglani, V . Pratap, K. R. Sadagopan, S. Saleem, A. Turkatenko, A. Ventayol-Boada, Z.-X. Yong, Y .-A. Chung, J. Maillard, R. ...
-
[33]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”
-
[34]
Available: https://arxiv.org/abs/2106.07447
[Online]. Available: https://arxiv.org/abs/2106.07447
-
[35]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large- scale weak supervision,” 2022. [Online]. Available: https: //arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Do self-supervised speech models develop human-like perception biases?
J. Millet and E. Dunbar, “Do self-supervised speech models develop human-like perception biases?” 2022. [Online]. Available: https://arxiv.org/abs/2205.15819
-
[37]
Self-Supervised Speech Representations are More Phonetic than Semantic,
K. Choi, A. Pasad, T. Nakamura, S. Fukayama, K. Livescu, and S. Watanabe, “Self-Supervised Speech Representations are More Phonetic than Semantic,” inInterspeech 2024, 2024, pp. 4578– 4582
2024
-
[38]
A. Rouditchenko, S. Khurana, S. Thomas, R. Feris, L. Karlinsky, H. Kuehne, D. Harwath, B. Kingsbury, and J. Glass, “Comparison of multilingual self-supervised and weakly-supervised speech pre-training for adaptation to unseen languages,” 2023. [Online]. Available: https://arxiv.org/abs/2305.12606
-
[39]
On the cross-lingual transferability of pre-trained wav2vec2-based models,
J. Grosman, C. Almeida, G. Schardong, and H. Lopes, “On the cross-lingual transferability of pre-trained wav2vec2-based models,” 2025. [Online]. Available: https://arxiv.org/abs/2511. 21704
2025
-
[40]
|Gui dialects and|Gui-speaking communities be- fore the relocation from the CKGR,
H. Nakagawa, “|Gui dialects and|Gui-speaking communities be- fore the relocation from the CKGR,”PULA Botswana Journal of African Studies, vol. 20, 2006
2006
-
[41]
Aspects of the phonetic and phonological structure of the G|ui language,
——, “Aspects of the phonetic and phonological structure of the G|ui language,” Ph.D. dissertation, University of the Witwater- srand, 2006
2006
-
[42]
A G|ui and G{ana dictionary,
K. Kato, “A G|ui and G{ana dictionary,” 2025. [Online]. Available: https://gui-dictionary.netlify.app
2025
-
[43]
The phoneme inventory of Taa (West!Xoon di- alect),
C. Naumann, “The phoneme inventory of Taa (West!Xoon di- alect),” inLone Tree – Scholarship in the Service of the Koon: Essays in Memory of Anthony T Traill. Rüdiger Köppe Verlag, 2016, pp. 311–351
2016
-
[44]
That doesn’t sound right: Evaluating speech transcription quality in field linguistics corpora,
É. Le Ferrand, B. Jiang, J. Hartshorne, and E. Prud’hommeaux, “That doesn’t sound right: Evaluating speech transcription quality in field linguistics corpora,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 2: Short Papers), 2025, pp. 627–635
2025
-
[45]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” 2019. [Online]. Available: https://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[46]
KenLM: Faster and smaller language model queries,
K. Heafield, “KenLM: Faster and smaller language model queries,” inProceedings of the Sixth Workshop on Statistical Machine Translation, C. Callison-Burch, P. Koehn, C. Monz, and O. F. Zaidan, Eds. Edinburgh, Scotland: Association for Computational Linguistics, Jul. 2011, pp. 187–197. [Online]. Available: https://aclanthology.org/W11-2123/
2011
-
[47]
A general method applicable to the search for similarities in the amino acid sequence of two proteins,
S. B. Needleman and C. D. Wunsch, “A general method applicable to the search for similarities in the amino acid sequence of two proteins,”Journal of molecular biology, vol. 48, no. 3, pp. 443– 453, 1970
1970
-
[48]
J. Kahn, M. Riviere, W. Zheng, E. Kharitonov, Q. Xu, P. Mazare, J. Karadayi, V . Liptchinsky, R. Collobert, C. Fuegen, T. Likhomanenko, G. Synnaeve, A. Joulin, A. Mohamed, and E. Dupoux, “Libri-light: A benchmark for asr with limited or no supervision,” inICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)....
-
[49]
Language complexity and speech recognition accuracy: Orthographic complexity hurts, phonolog- ical complexity doesn’t,
C. Taguchi and D. Chiang, “Language complexity and speech recognition accuracy: Orthographic complexity hurts, phonolog- ical complexity doesn’t,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V ol- ume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computationa...
2024
-
[50]
Clicks and their accompaniments,
P. Ladefoged and A. Traill, “Clicks and their accompaniments,” Journal of Phonetics, vol. 22, pp. 33–64, 1994
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.