Parameter-Efficient Adapter Tuning for Tabular-Image Multimodal Learning
Pith reviewed 2026-06-27 10:42 UTC · model grok-4.3
The pith
TI-Adapter uses lightweight adapters to match full fine-tuning performance on tabular-image multimodal tasks with far fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
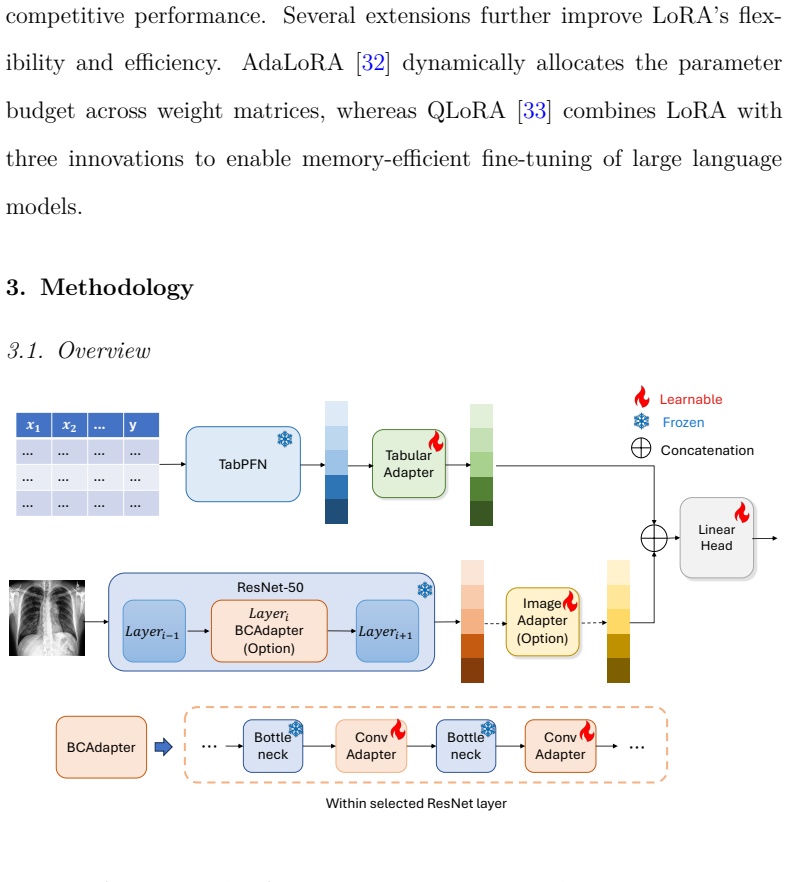
TI-Adapter freezes the pretrained tabular encoder and learns an adapter after the extracted tabular embedding, while adapting the image branch with embedding-level and bottleneck-level adapters. On 20 tabular-image datasets, TI-Adapter achieves competitive or better predictive performance than full fine-tuning while using substantially fewer trainable parameters.
What carries the argument
TI-Adapter, a modality-specific adapter-based fine-tuning framework that places adapters after embeddings or in bottleneck positions to enable efficient adaptation of frozen encoders.
If this is right
- TI-Adapter reduces trainable parameters substantially compared to full fine-tuning.
- Performance remains competitive or superior across diverse tabular-image datasets.
- Ablation studies confirm that specific adapter placements are key to the efficiency-performance balance.
Where Pith is reading between the lines
- This approach could allow fine-tuning of larger multimodal models on limited hardware.
- Similar adapter strategies might apply to other combinations of data modalities.
- Task-specific adaptation might be possible even when encoders are trained on very different domains.
Load-bearing premise
The representations from the frozen pretrained encoders are rich enough that the proposed adapter placements can recover task-specific performance.
What would settle it
A new tabular-image dataset where TI-Adapter shows significantly worse performance than full fine-tuning despite using fewer parameters would falsify the claim.
Figures
read the original abstract
Tabular-image multimodal learning aims to improve predictive modeling by jointly using structured tabular attributes and visual data. Although pretrained encoders provide strong modality-specific representations, full fine-tuning can be computationally expensive, while keeping encoders frozen may limit task-specific adaptation. We propose the Tabular-Image Adapter (TI-Adapter), a modality-specific adapter-based fine-tuning framework for efficient multimodal adaptation. TI-Adapter freezes the pretrained tabular encoder and learns an adapter after the extracted tabular embedding, while adapting the image branch with embedding-level and bottleneck-level adapters instead of full fine-tuning. Experiments on 20 tabular-image datasets show that TI-Adapter achieves competitive or better predictive performance than full fine-tuning while using substantially fewer trainable parameters. Ablation studies further demonstrate the importance of adapter placement for balancing performance and practical efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Tabular-Image Adapter (TI-Adapter), a modality-specific adapter framework for parameter-efficient fine-tuning of pretrained encoders in tabular-image multimodal learning. The tabular encoder is kept frozen with an adapter applied to its embeddings, while the image branch receives embedding-level and bottleneck-level adapters. The central empirical claim is that this yields competitive or superior predictive performance to full fine-tuning across 20 tabular-image datasets while using substantially fewer trainable parameters, with supporting ablations on adapter placement.
Significance. If the reported results hold under standard verification, the work demonstrates a practical efficiency gain for multimodal adaptation without sacrificing accuracy. The evaluation on 20 datasets and the ablation studies on placement constitute a reasonable empirical contribution for an applied methods paper; no machine-checked proofs or parameter-free derivations are present, but the direct comparison to full fine-tuning is the appropriate test for the stated claim.
minor comments (3)
- [Abstract] Abstract: the statement that TI-Adapter 'achieves competitive or better predictive performance' would be strengthened by an explicit statement of the evaluation protocol (e.g., train/validation/test splits, number of runs) already in the abstract or first paragraph of the experiments section.
- The manuscript should include a table (or clear paragraph) listing the exact number of trainable parameters for TI-Adapter versus the full fine-tuning baseline on at least one representative dataset; this directly supports the efficiency claim.
- Figure or table captions for the ablation studies should explicitly state which adapter placements are being compared and on how many datasets the trends hold.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The referee's summary accurately captures the TI-Adapter framework and its empirical evaluation on 20 datasets.
Circularity Check
No significant circularity; empirical claim only
full rationale
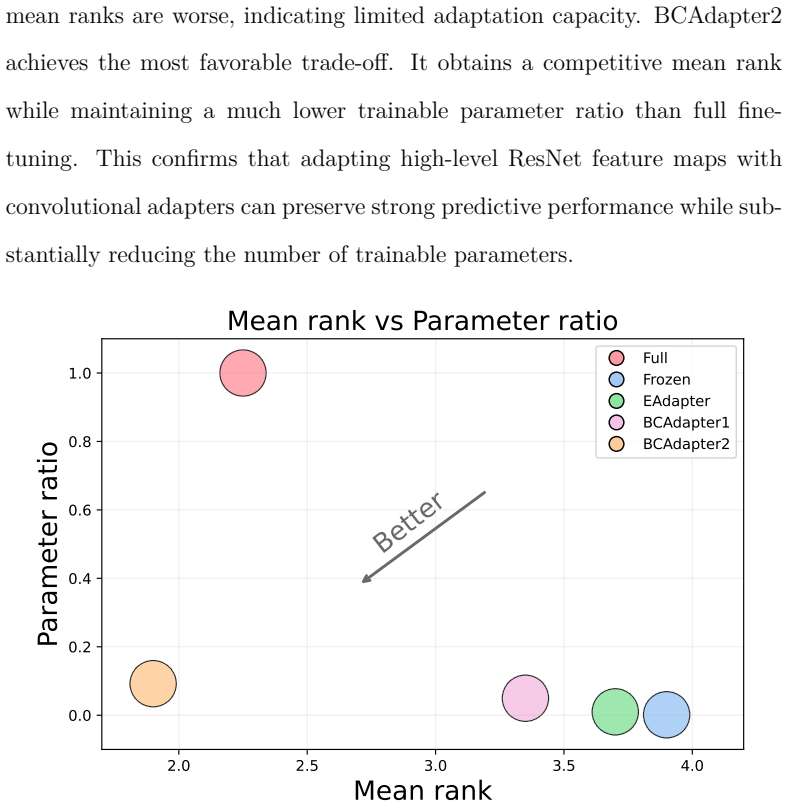
The paper's central claim is an empirical statement: TI-Adapter matches or exceeds full fine-tuning performance on 20 tabular-image datasets while using fewer trainable parameters. This rests on direct experimental comparison and ablations, not on any derivation, equation, or prediction that reduces to fitted quantities or self-citations by construction. No load-bearing mathematical steps, self-definitional relations, or uniqueness theorems appear in the provided description or abstract. The method description (freezing encoders, inserting modality-specific adapters) is a design choice validated externally by results, not internally forced.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. N. Acosta, G. J. Falcone, P. Rajpurkar, E. J. Topol, Multimodal biomedical ai, Nature medicine 28 (9) (2022) 1773–1784
2022
-
[2]
Huang, A
S.-C. Huang, A. Pareek, S. Seyyedi, I. Banerjee, M. P. Lungren, Fusion of medical imaging and electronic health records using deep learning: a 25 systematic review and implementation guidelines, NPJ digital medicine 3 (1) (2020) 136
2020
-
[3]
Borsos, C
B. Borsos, C. G. Allaart, A. van Halteren, Predicting stroke outcome: a case for multimodal deep learning methods with tabular and ct perfusion data, Artificial Intelligence in Medicine 147 (2024) 102719
2024
-
[4]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[5]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
N. Hollmann, S. Müller, K. Eggensperger, F. Hutter, Tabpfn: A trans- former that solves small tabular classification problems in a second, arXiv preprint arXiv:2207.01848 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Hollmann, S
N. Hollmann, S. Müller, L. Purucker, A. Krishnakumar, M. Körfer, S. B. Hoo, R. T. Schirrmeister, F. Hutter, Accurate predictions on small data with a tabular foundation model, Nature 637 (8045) (2025) 319–326
2025
-
[7]
L. Grinsztajn, K. Flöge, O. Key, F. Birkel, P. Jund, B. Roof, M. Manium, S. Bin, M. Bühler, A. Garg, et al., Tabpfn-3: Technical report, arXiv preprint arXiv:2605.13986 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
L. Xu, H. Xie, S. J. Qin, X. Tao, F. L. Wang, Parameter-efficient fine- tuning methods for pretrained language models: A critical review and assessment, IEEE Transactions on Pattern Analysis and Machine Intel- ligence (2026). 26
2026
- [9]
-
[10]
P. Gao, S. Geng, R. Zhang, T. Ma, R. Fang, Y. Zhang, H. Li, Y. Qiao, Clip-adapter: Better vision-language models with feature adapters, In- ternational journal of computer vision 132 (2) (2024) 581–595
2024
-
[11]
H. Chen, R. Tao, H. Zhang, Y. Wang, X. Li, W. Ye, J. Wang, G. Hu, M. Savvides, Conv-adapter: Exploring parameter efficient transfer learn- ing for convnets, in: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, 2024, pp. 1551–1561
2024
-
[12]
Y. Lei, Z. Li, Y. Shen, J. Zhang, H. Shan, Clip-lung: Textual knowledge- guided lung nodule malignancy prediction, in: International Confer- ence on Medical Image Computing and Computer-Assisted Intervention, Springer, 2023, pp. 403–412
2023
-
[13]
L. Sun, M. Zhang, Y. Lu, W. Zhu, Y. Yi, F. Yan, Nodule-clip: Lung nodule classification based on multi-modal contrastive learning, Com- puters in Biology and Medicine 175 (2024) 108505
2024
-
[14]
Spasov, L
S. Spasov, L. Passamonti, A. Duggento, P. Lio, N. Toschi, A. D. N. Initiative, et al., A parameter-efficient deep learning approach to pre- 27 dict conversion from mild cognitive impairment to alzheimer’s disease, Neuroimage 189 (2019) 276–287
2019
-
[15]
Y. Liu, Y. Yu, J. Ouyang, B. Jiang, G. Yang, S. Ostmeier, M. Winter- mark, P. Michel, D. S. Liebeskind, M. G. Lansberg, et al., Functional outcome prediction in acute ischemic stroke using a fused imaging and clinical deep learning model, Stroke 54 (9) (2023) 2316–2327
2023
-
[16]
Zheng, Z
H. Zheng, Z. Lin, Q. Zhou, X. Peng, J. Xiao, C. Zu, Z. Jiao, Y. Wang, Multi-transsp: Multimodal transformer for survival prediction of na- sopharyngeal carcinoma patients, in: International Conference on Med- ical Image Computing and Computer-Assisted Intervention, Springer, 2022, pp. 234–243
2022
-
[17]
C. Xue, S. S. Kowshik, D. Lteif, S. Puducheri, V. H. Jasodanand, O. T. Zhou, A. S. Walia, O. B. Guney, J. D. Zhang, S. T. Pham, et al., Ai- based differential diagnosis of dementia etiologies on multimodal data, Nature Medicine 30 (10) (2024) 2977–2989
2024
- [18]
-
[19]
T. Chen, C. Guestrin, Xgboost: A scalable tree boosting system, in: Proceedings of the 22nd acm sigkdd international conference on knowl- edge discovery and data mining, 2016, pp. 785–794. 28
2016
-
[20]
J. Luo, S. Xu, Ncart: Neural classification and regression tree for tabular data, Pattern Recognition 154 (2024) 110578
2024
-
[21]
Gorishniy, I
Y. Gorishniy, I. Rubachev, V. Khrulkov, A. Babenko, Revisiting deep learning models for tabular data, Advances in Neural Information Pro- cessing Systems 34 (2021) 18932–18943
2021
-
[22]
W. Kim, C. Song, H. Kim, Multimodalpfn: Extending prior-data fit- ted networks for multimodal tabular learning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 30357–30367
2026
-
[23]
Hager, M
P. Hager, M. J. Menten, D. Rueckert, Best of both worlds: Multimodal contrastive learning with tabular and imaging data, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2023, pp. 23924–23935
2023
-
[24]
W. Huang, Multimodal contrastive learning and tabular attention for automated alzheimer’s disease prediction, in: Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 2473– 2482
2023
-
[25]
S. Du, S. Zheng, Y. Wang, W. Bai, D. P. ORegan, C. Qin, Tip: Tabular- image pre-training for multimodal classification with incomplete data, in: European Conference on Computer Vision, Springer, 2024, pp. 478– 496. 29
2024
-
[26]
S. Du, X. Luo, D. P. O’Regan, C. Qin, Stil: Semi-supervised tabular- image learning for comprehensive task-relevant information exploration in multimodal classification, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 15549–15559
2025
-
[27]
Houlsby, A
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, S. Gelly, Parameter-efficient transfer learn- ing for nlp, in: International conference on machine learning, PMLR, 2019, pp. 2790–2799
2019
-
[28]
X. L. Li, P. Liang, Prefix-tuning: Optimizing continuous prompts for generation, in: Proceedings of the 59th Annual Meeting of the Asso- ciation for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 4582–4597
2021
-
[29]
Lester, R
B. Lester, R. Al-Rfou, N. Constant, The power of scale for parameter- efficient prompt tuning, in: Proceedings of the 2021 conference on em- pirical methods in natural language processing, 2021, pp. 3045–3059
2021
- [30]
-
[31]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, 30 W. Chen, et al., Lora: Low-rank adaptation of large language models., Iclr 1 (2) (2022) 3
2022
-
[32]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Q. Zhang, M. Chen, A. Bukharin, N. Karampatziakis, P. He, Y. Cheng, W. Chen, T. Zhao, Adalora: Adaptive budget allocation for parameter- efficient fine-tuning, arXiv preprint arXiv:2303.10512 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Dettmers, A
T. Dettmers, A. Pagnoni, A. Holtzman, L. Zettlemoyer, Qlora: Efficient finetuning of quantized llms, Advances in neural information processing systems 36 (2023) 10088–10115
2023
-
[34]
MulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
A. Arazi, E. Shapira, S. Grunblat, M. Ventura, E. Hoffer, G. Blayer, D. Holzmüller, L. Purucker, G. Varoquaux, F. Hutter, et al., Multabench: Benchmarking multimodal tabular learning with text and image, arXiv preprint arXiv:2605.10616 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
T. Chen, B. Xu, C. Zhang, C. Guestrin, Training deep nets with sub- linear memory cost, arXiv preprint arXiv:1604.06174 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[36]
Mercea, A
O.-B. Mercea, A. Gritsenko, C. Schmid, A. Arnab, Time-memory-and parameter-efficient visual adaptation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5536–5545. 31
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.