Recognition: 2 theorem links
· Lean TheoremMulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
Pith reviewed 2026-05-12 04:49 UTC · model grok-4.3
The pith
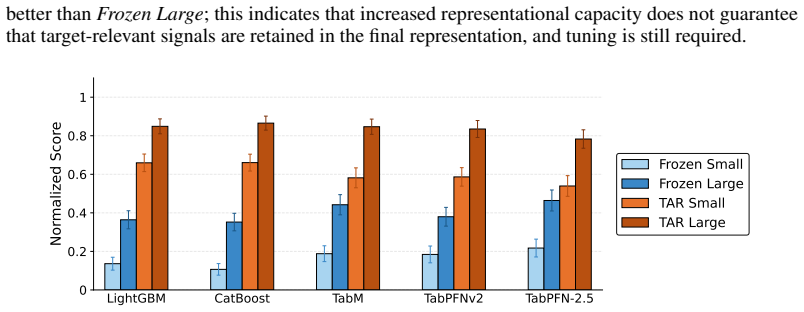
Tuning text and image embeddings to the prediction target improves performance on multimodal tabular tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
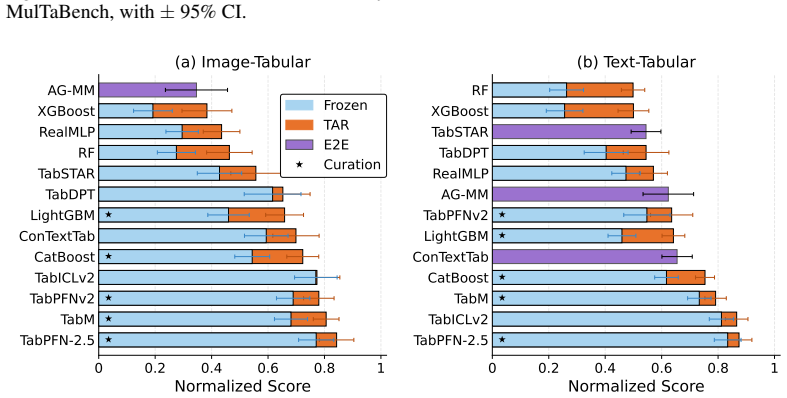
MulTaBench is a benchmark of 40 datasets that isolates multimodal tabular learning settings where text or images carry essential complementary information lost in generic embeddings. The central result is that tuning the embeddings to align with the prediction target yields performance improvements that hold across both modalities, multiple tabular learners, different encoder scales, and varying embedding dimensions.
What carries the argument
Target-aware representation tuning, which adapts pretrained text or image embeddings to the specific supervised task instead of leaving them frozen.
Load-bearing premise
That the 40 chosen datasets genuinely contain complementary predictive signals from text or images that generic embeddings fail to capture.
What would settle it
Re-running the experiments on MulTaBench and finding no average improvement from target-aware tuning over frozen generic embeddings, or finding that the gains disappear outside the selected datasets.
Figures
















read the original abstract
Tabular Foundation Models have recently established the state of the art in supervised tabular learning, by leveraging pretraining to learn generalizable representations of numerical and categorical structured data. However, they lack native support for unstructured modalities such as text and image, and rely on frozen, pretrained embeddings to process them. On established Multimodal Tabular Learning benchmarks, we show that tuning the embeddings to the task improves performance. Existing benchmarks, however, often focus on the mere co-occurrence of modalities; this leads to high variance across datasets and masks the benefits of task-specific tuning. To address this gap, we introduce MulTaBench, a benchmark of 40 datasets, split equally between image-tabular and text-tabular tasks. We focus on predictive tasks where the modalities provide complementary predictive signal, and where generic embeddings lose critical information, necessitating Target-Aware Representations that are aligned with the task. Our experimental results demonstrate that the gains from target-aware representation tuning generalize across both text and image modalities, several tabular learners, encoder scales, and embedding dimensions. MulTaBench constitutes the largest image-tabular benchmarking effort to date, spanning high-impact domains such as healthcare and e-commerce. It is designed to enable the research of novel architectures which incorporate joint modeling and target-aware representations, paving the way for the development of novel Multimodal Tabular Foundation Models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MulTaBench, a benchmark of 40 multimodal tabular datasets (20 image-tabular and 20 text-tabular) selected to emphasize tasks where text or image modalities supply complementary predictive signals beyond tabular features and where frozen generic embeddings discard critical task-relevant information. It contrasts this with existing benchmarks that focus on modality co-occurrence and exhibit high variance. Experiments demonstrate that target-aware tuning of embeddings yields performance gains that generalize across text and image modalities, multiple tabular learners, encoder scales, and embedding dimensions. The work positions MulTaBench as the largest image-tabular benchmarking effort to date, covering domains such as healthcare and e-commerce, to support research on joint modeling and target-aware multimodal tabular foundation models.
Significance. If the dataset selection and experimental claims hold, MulTaBench would provide a more targeted evaluation resource than prior co-occurrence-focused benchmarks, potentially accelerating development of architectures that incorporate target-aware representations. The scale (40 datasets) and domain coverage constitute a clear strength for reproducibility and comparability in multimodal tabular learning.
major comments (2)
- [Dataset construction / MulTaBench description] Dataset construction (as described in the abstract and implied methods): The claim that the 40 datasets were chosen such that 'generic embeddings lose critical information, necessitating Target-Aware Representations' is load-bearing for the generalization statement, yet no quantitative selection filter is provided (e.g., no reported performance gap between tabular-only baselines and frozen-multimodal models, no mutual-information estimates, or explicit threshold on complementary signal). Without this, gains from target-aware tuning could stem from dataset idiosyncrasies rather than the asserted necessity.
- [Experimental results] Experimental results (as asserted in the abstract): The generalization claim across modalities, learners, scales, and dimensions lacks supporting details on statistical significance testing, error bars, or variance analysis across the 40 datasets. This weakens the assertion that gains 'generalize' and makes it hard to assess robustness.
minor comments (1)
- [Abstract] The abstract refers to 'established Multimodal Tabular Learning benchmarks' without citing specific prior works or datasets; adding these references would improve context.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major point below and describe the revisions we will implement to improve clarity and rigor.
read point-by-point responses
-
Referee: [Dataset construction / MulTaBench description] Dataset construction (as described in the abstract and implied methods): The claim that the 40 datasets were chosen such that 'generic embeddings lose critical information, necessitating Target-Aware Representations' is load-bearing for the generalization statement, yet no quantitative selection filter is provided (e.g., no reported performance gap between tabular-only baselines and frozen-multimodal models, no mutual-information estimates, or explicit threshold on complementary signal). Without this, gains from target-aware tuning could stem from dataset idiosyncrasies rather than the asserted necessity.
Authors: We agree that an explicit quantitative justification for dataset selection would strengthen the paper and improve reproducibility. While the current manuscript describes the focus on tasks with complementary signals (Section 3), the selection process relied on domain expertise and preliminary checks rather than a fully documented filter. In the revised version, we will add a new subsection under MulTaBench construction that reports performance gaps between tabular-only baselines and frozen multimodal models for the selected datasets, along with mutual information estimates between the unstructured modalities and the target where feasible. This will directly address the concern regarding potential idiosyncrasies. revision: yes
-
Referee: [Experimental results] Experimental results (as asserted in the abstract): The generalization claim across modalities, learners, scales, and dimensions lacks supporting details on statistical significance testing, error bars, or variance analysis across the 40 datasets. This weakens the assertion that gains 'generalize' and makes it hard to assess robustness.
Authors: We acknowledge that the current presentation of results would benefit from additional statistical details to support the generalization claims. The experiments demonstrate consistent gains, but variance and significance were not fully quantified across all 40 datasets. In the revised manuscript, we will update the experimental results section to include error bars (standard deviations), variance analysis across datasets, and statistical significance testing (e.g., paired Wilcoxon tests) for the reported improvements. These additions will be reflected in the tables and figures to better substantiate robustness across modalities, learners, scales, and dimensions. revision: yes
Circularity Check
No significant circularity in benchmark construction or generalization claims
full rationale
The paper introduces MulTaBench as an empirical benchmark of 40 datasets chosen to exhibit complementary multimodal signals, then reports direct experimental measurements of performance gains from target-aware embedding tuning across modalities, learners, and scales. These results are obtained from independent evaluations on the curated data rather than any self-referential derivation, fitted parameter renamed as prediction, or load-bearing self-citation that reduces the central claim to its own inputs by construction. Dataset selection criteria are stated descriptively without creating a definitional loop, and no equations or uniqueness theorems are invoked that would force the observed outcomes.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We focus on predictive tasks where the modalities provide complementary predictive signal, and where generic embeddings lose critical information, necessitating Target-Aware Representations that are aligned with the task.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Acceptance Criteria... ΔJoint(m) = Sm(Joint Frozen) − max(Sm(Unimodal Structured), Sm(Unimodal Unstructured)) and ΔAwareness(m) = Sm(Joint TAR) − Sm(Joint Frozen)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Predicting Decisions of AI Agents from Limited Interaction through Text-Tabular Modeling
A tabular foundation model with LLM-as-Observer features predicts AI agent decisions in controlled games, outperforming baselines by 4 AUC points and 14% lower error at K=16 interactions.
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
work page 2022
-
[2]
Selvaraju, Michael Cogswell, Ab- hishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. VQA: Visual Question Answering. In2015 IEEE International Conference on Computer Vision (ICCV), pages 2425–2433, Santiago, Chile, December 2015. IEEE. ISBN 978-1-4673-8391-2. doi: 10.1109/ICCV .2015.279. URL http://ieeexplore. ieee.org/docu...
-
[3]
TabSTAR: A Tabular Foundation Model for Tabular Data with Text Fields
Alan Arazi, Eilam Shapira, and Roi Reichart. TabSTAR: A Tabular Foundation Model for Tabular Data with Text Fields. In D. Belgrave, C. Zhang, H. Lin, R. Pas- canu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Neural Informa- tion Processing Systems, volume 38, pages 172108–172161. Curran Associates, Inc.,
-
[4]
URL https://proceedings.neurips.cc/paper_files/paper/2025/file/ faf6e23e198314c7728eaa6ac44ae079-Paper-Conference.pdf
work page 2025
-
[5]
Yael Badian, Yaakov Ophir, Refael Tikochinski, Nitay Calderon, Anat Brunstein Klomek, Eyal Fruchter, and Roi Reichart. Social media images can predict suicide risk using interpretable large language-vision models.J Clin Psychiatry, 85(1):50516
-
[6]
Ele- phants Never Forget: Memorization and Learning of Tabular Data in Large Language Models
Sebastian Bordt, Harsha Nori, Vanessa Rodrigues, Besmira Nushi, and Rich Caruana. Ele- phants Never Forget: Memorization and Learning of Tabular Data in Large Language Models. First Conference on Language Modeling, 2024. 10
work page 2024
-
[7]
Mohamed Bouadi, Pratinav Seth, Aditya Tanna, and Vinay Kumar Sankarapu. Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning, November 2025. URL http: //arxiv.org/abs/2511.02818. arXiv:2511.02818 [cs]
-
[8]
Task Expansion and Cross Refinement for Open-World Conditional Modeling, March 2026
Shreyas Bhat Brahmavar, Qiyang Liu, Yang Li, and Junier Oliva. Task Expansion and Cross Refinement for Open-World Conditional Modeling, March 2026. URL http://arxiv.org/ abs/2603.13308. arXiv:2603.13308 [cs]
-
[9]
Leo Breiman. Random Forests.Machine Learning, 45(1):5–32, October 2001. ISSN 1573-0565. doi: 10.1023/A:1010933404324. URL https://doi.org/10.1023/A: 1010933404324
-
[10]
Language Models are Few-Shot Learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott...
work page 1901
-
[11]
The Revolution of Mul- timodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. The Revolution of Mul- timodal Large Language Models: A Survey. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, pages 13590...
-
[12]
TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
Bingyi Cao, Koert Chen, Kevis-Kokitsi Maninis, Kaifeng Chen, Arjun Karpur, Ye Xia, Sahil Dua, Tanmaya Dabral, Guangxing Han, Bohyung Han, Joshua Ainslie, Alex Bewley, Mithun Jacob, René Wagner, Washington Ramos, Krzysztof Choromanski, Mojtaba Seyedhosseini, Howard Zhou, and André Araujo. TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Te...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Tianqi Chen and Carlos Guestrin. XGBoost: A Scalable Tree Boosting System. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, pages 785–794, New York, NY , USA, August 2016. Association for Computing Machinery. ISBN 978-1-4503-4232-2. doi: 10.1145/2939672.2939785. URL https://dl.acm.org/doi/10.11...
-
[14]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobsson, Idan Szpektor, Nan-Jiang Jiang, et al. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multim...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Can Cui, Haichun Yang, Yaohong Wang, Shilin Zhao, Zuhayr Asad, Lori A Coburn, Keith T Wilson, Bennett A Landman, and Yuankai Huo. Deep multimodal fusion of image and non- image data in disease diagnosis and prognosis: a review.Progress in Biomedical Engineering, 5(2):022001, April 2023. ISSN 2516-1091. doi: 10.1088/2516-1091/acc2fe. URL https: //doi.org/1...
-
[16]
Ronnie Das, Wasim Ahmed, Kshitij Sharma, Mariann Hardey, Yogesh K Dwivedi, Ziqi Zhang, Chrysostomos Apostolidis, and Raffaele Filieri. Towards the development of an explainable e-commerce fake review index: An attribute analytics approach.European Journal of Operational Research, 317(2):382–400, 2024. 11
work page 2024
-
[17]
Siyi Du, Shaoming Zheng, Yinsong Wang, Wenjia Bai, Declan P. O’Regan, and Chen Qin. TIP: Tabular-Image Pre-training for Multimodal Classification with Incomplete Data. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision – ECCV 2024, volume 15073, pages 478–496. Springer Nature Switzerland,...
work page 2024
-
[18]
TIP: Tabular-Image Pre-training for Multimodal Classification with Incomplete Data,
doi: 10.1007/978-3-031-72633-0_27. URL https://link.springer.com/10.1007/ 978-3-031-72633-0_27. Series Title: Lecture Notes in Computer Science
-
[19]
Daniel Duenias, Brennan Nichyporuk, Tal Arbel, and Tammy Riklin Raviv. HyperFusion: A Hypernetwork Approach to Multimodal Integration of Tabular and Medical Imaging Data for Predictive Modeling.Medical Image Analysis, 102:103503, May 2025. ISSN 13618415. doi: 10.1016/j.media.2025.103503. URL http://arxiv.org/abs/2403.13319. arXiv:2403.13319 [cs]
-
[20]
LANISTR: Multimodal learning from structured and unstructured data,
Sayna Ebrahimi, Sercan O. Arik, Yihe Dong, and Tomas Pfister. LANISTR: Multimodal Learning from Structured and Unstructured Data, April 2024. URL http://arxiv.org/ abs/2305.16556. arXiv:2305.16556 [cs]
-
[21]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From Local to Global: A Graph RAG Approach to Query-Focused Summarization, February 2025. URL http://arxiv.org/abs/2404.16130. arXiv:2404.16130 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
TabLib: A Dataset of 627M Tables with Context, October 2023
Gus Eggert, Kevin Huo, Mike Biven, and Justin Waugh. TabLib: A Dataset of 627M Tables with Context, October 2023. URL http://arxiv.org/abs/2310.07875. arXiv:2310.07875 [cs]
-
[23]
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, and David Salinas, and Frank Hutter. TabArena: A Living Benchmark for Machine Learning on Tabular Data, June 2025. URL http://arxiv.org/abs/2506.16791. arXiv:2506.16791 [cs]
-
[24]
A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’24, pages 6491–6501, New York, NY , USA, August 2024. Association for Computing M...
-
[25]
Sengamedu, and Christos Faloutsos
Xi Fang, Weijie Xu, Fiona Anting Tan, Ziqing Hu, Jiani Zhang, Yanjun Qi, Srinivasan H. Sengamedu, and Christos Faloutsos. Large Language Models (LLMs) on Tabular Data: Prediction, Generation, and Understanding - A Survey.Transactions on Machine Learning Research, March 2024. ISSN 2835-8856. URL https://openreview.net/forum?id= IZnrCGF9WI
work page 2024
-
[26]
Yibing Fu, Yunpeng Zhao, Zhitao Zeng, Cheng Chen, and Yueming Jin. Unleashing the Power of Image-Tabular Self-Supervised Learning via Breaking Cross-Tabular Barriers, December
- [27]
-
[28]
Roy Ganz, Yair Kittenplon, Aviad Aberdam, Elad Ben Avraham, Oren Nuriel, Shai Mazor, and Ron Litman. Question Aware Vision Transformer for Multimodal Reasoning. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13861– 13871, Seattle, WA, USA, June 2024. IEEE. ISBN 979-8-3503-5300-6. doi: 10.1109/ CVPR52733.2024.01315. URL...
-
[29]
Josh Gardner, Juan C. Perdomo, and Ludwig Schmidt. Large Scale Transfer Learning for Tabular Data via Language Modeling.Advances in Neural Information Processing Systems, 37: 45155–45205, December 2024. URLhttps://proceedings.neurips.cc/paper_files/ paper/2024/hash/4fd5cfd2e31bebbccfa5ffa354c04bdc-Abstract-Conference. html. 12
work page 2024
-
[30]
Real-TabPFN: Improving Tabular Foundation Models via Continued Pre-training With Real-World Data
Anurag Garg, Muhammad Ali, Noah Hollmann, Lennart Purucker, Samuel Müller, and Frank Hutter. Real-TabPFN: Improving Tabular Foundation Models via Continued Pre-training With Real-World Data. June 2025. URLhttps://openreview.net/forum?id=BtEiqKsIMw
work page 2025
-
[31]
Should We Still Pretrain Encoders with Masked Language Modeling? October 2025
Hippolyte Gisserot-Boukhlef, Nicolas Boizard, Manuel Faysse, Duarte Miguel Alves, Em- manuel Malherbe, Andre Martins, Celine Hudelot, and Pierre Colombo. Should We Still Pretrain Encoders with Masked Language Modeling? October 2025. URL https: //openreview.net/forum?id=jpz7e3jhRq
work page 2025
-
[32]
Revisiting deep learning models for tabular data
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data. InProceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, pages 18932–18943, Red Hook, NY , USA, December 2021. Curran Associates Inc. ISBN 978-1-7138-4539-3
work page 2021
-
[33]
TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling, February 2025
Yury Gorishniy, Akim Kotelnikov, and Artem Babenko. TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling, February 2025. URL http://arxiv.org/ abs/2410.24210. arXiv:2410.24210 [cs]
-
[34]
The illusion of generalization: Re-examining tabular language model evaluation, 2026
Aditya Gorla and Ratish Puduppully. The Illusion of Generalization: Re-examining Tabular Language Model Evaluation, February 2026. URL http://arxiv.org/abs/2602.04031. arXiv:2602.04031 [cs] version: 1
-
[35]
Leo Grinsztajn, Edouard Oyallon, and Gael Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data?Advances in Neural Information Processing Systems, 35:507–520, December 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 0378c7692da36807bdec87ab043cdadc-Abstract-Datasets_and_Benchmarks. html
work page 2022
-
[36]
Léo Grinsztajn, Edouard Oyallon, Myung Jun Kim, and Gaël Varoquaux. Vectorizing string entries for data processing on tables: when are larger language models better?, December 2023. URLhttp://arxiv.org/abs/2312.09634. arXiv:2312.09634 [stat]
-
[37]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, Mihir Manium, Rosen Yu, Felix Jablonski, Shi Bin Hoo, Anurag Garg, Jake Robertson, Magnus Bühler, Vla- dyslav Moroshan, Lennart Purucker, Clara Cornu, Lilly Charlotte Wehrhahn, Alessandro Bonetto, Bernhard Schö...
work page internal anchor Pith review arXiv 2026
-
[38]
Paul Hager, Martin J. Menten, and Daniel Rueckert. Best of Both Worlds: Multimodal Contrastive Learning with Tabular and Imaging Data, March 2023. URL http://arxiv. org/abs/2303.14080. arXiv:2303.14080 [cs]
-
[39]
Bringing Graphs to the Table: Zero-shot Node Classification via Tabular Foundation Models,
Adrian Hayler, Xingyue Huang, ˙Ismail ˙Ilkan Ceylan, Michael Bronstein, and Ben Finkelshtein. Bringing Graphs to the Table: Zero-shot Node Classification via Tabular Foundation Models,
-
[40]
URLhttps://arxiv.org/abs/2509.07143. Version Number: 2
-
[41]
Xin He, Kaiyong Zhao, and Xiaowen Chu. AutoML: A survey of the state-of-the-art. Knowledge-Based Systems, 212:106622, January 2021. ISSN 0950-7051. doi: 10.1016/j. knosys.2020.106622. URL https://www.sciencedirect.com/science/article/pii/ S0950705120307516
work page doi:10.1016/j 2021
-
[42]
TabLLM: Few-shot Classification of Tabular Data with Large Language Models
Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Monica Agrawal, Xiaoyi Jiang, and David Sontag. TabLLM: Few-shot Classification of Tabular Data with Large Language Models. InProceedings of The 26th International Conference on Artificial Intelligence and Statistics, pages 5549–5581. PMLR, April 2023. URL https://proceedings.mlr.press/v206/ hegselmann23a.html
work page 2023
-
[43]
Retrieval from Within: An Intrinsic Capability of Attention-Based Models
Elad Hoffer, Yochai Blau, Ron Banner, Daniel Soudry, and Boris Ginsburg. Retrieval from within: An intrinsic capability of attention-based models, 2026. URL https://arxiv.org/ abs/2605.05806. 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second. The Eleventh International Conference on Learning Representations, September 2022. URL https:// openreview.net/forum?id=cp5PvcI6w8_
work page 2022
-
[45]
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, January 2025. ISSN 1476-
work page 2025
-
[46]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
doi: 10.1038/s41586-024-08328-6. URL https://www.nature.com/articles/ s41586-024-08328-6
-
[47]
David Holzmüller, Léo Grinsztajn, and Ingo Steinwart. Better by default: Strong pre-tuned MLPs and boosted trees on tabular data.Advances in Neural Information Processing Systems, 37:26577–26658, December 2024. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 2ee1c87245956e3eaa71aaba5f5753eb-Abstract-Conference.html
work page 2024
-
[48]
Shi Bin Hoo, Samuel Müller, David Salinas, and Frank Hutter. The tabular foundation model tabpfn outperforms specialized time series forecasting models based on simple features. In NeurIPS workshop on time series in the age of large models, 2024
work page 2024
-
[49]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. October 2021. URLhttps://openreview.net/forum?id=nZeVKeeFYf9
work page 2021
-
[50]
PyTorch Frame: A Modular Framework for Multi- Modal Tabular Learning
Weihua Hu, Yiwen Yuan, Zecheng Zhang, Akihiro Nitta, Kaidi Cao, Vid Kocijan, Jinu Sunil, Jure Leskovec, and Matthias Fey. PyTorch Frame: A Modular Framework for Multi- Modal Tabular Learning. October 2024. URL https://openreview.net/forum?id= 2ZHKA9xo8V#discussion
work page 2024
-
[51]
Shih-Cheng Huang, Anuj Pareek, Saeed Seyyedi, Imon Banerjee, and Matthew P. Lungren. Fu- sion of medical imaging and electronic health records using deep learning: a systematic review and implementation guidelines.npj Digital Medicine, 3(1):136, October 2020. ISSN 2398-
work page 2020
-
[52]
URL https://www.nature.com/articles/ s41746-020-00341-z
doi: 10.1038/s41746-020-00341-z. URL https://www.nature.com/articles/ s41746-020-00341-z
-
[53]
Tabular Insights, Visual Impacts: Transferring Expertise from Tables to Images
Jun-Peng Jiang, Han-Jia Ye, Leye Wang, Yang Yang, Yuan Jiang, and De-Chuan Zhan. Tabular Insights, Visual Impacts: Transferring Expertise from Tables to Images. InProceedings of the 41st International Conference on Machine Learning, pages 21988–22009. PMLR, July 2024. URLhttps://proceedings.mlr.press/v235/jiang24h.html
work page 2024
-
[54]
Jun-Peng Jiang, Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, and Han-Jia Ye. Representation Learning for Tabular Data: A Comprehensive Survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–20, 2026. ISSN 1939-3539. doi: 10.1109/TPAMI.2026. 3657217. URLhttps://ieeexplore.ieee.org/abstract/document/11369258
-
[55]
LightGBM: A Highly Efficient Gradient Boosting Decision Tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qi- wei Ye, and Tie-Yan Liu. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. InAdvances in Neural Information Processing Systems, volume 30. Curran Asso- ciates, Inc., 2017. URL https://papers.nips.cc/paper_files/paper/2017/hash/ 6449f44a102fde848669bdd9eb6b76fa-Abstract.html
work page 2017
-
[56]
ColBERT: Efficient and effective passage search via con- textualized late interaction over bert
Omar Khattab and Matei Zaharia. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, pages 39–48, New York, NY , USA, July 2020. Association for Computing Machinery. ISBN 978-1- 4503-8016-4...
-
[57]
CARTE: pretraining and transfer for tabular learning
Myung Jun Kim, Léo Grinsztajn, and Gaël Varoquaux. CARTE: pretraining and transfer for tabular learning. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofICML’24, pages 23843–23866, Vienna, Austria, July 2024. JMLR.org. 14
work page 2024
-
[58]
Table Foundation Models: on knowledge pre-training for tabular learning, May 2025
Myung Jun Kim, Félix Lefebvre, Gaëtan Brison, Alexandre Perez-Lebel, and Gaël Varoquaux. Table Foundation Models: on knowledge pre-training for tabular learning, May 2025. URL http://arxiv.org/abs/2505.14415. arXiv:2505.14415 [cs]
-
[59]
MultiModalPFN: Extending Prior-Data Fitted Networks for Multimodal Tabular Learning
Wall Kim, Chaeyoung Song, and Hanul Kim. MultiModalPFN: Extending Prior-Data Fitted Networks for Multimodal Tabular Learning. October 2025. URL https://openreview. net/forum?id=pSyuFl8mau
work page 2025
-
[60]
Structured RAG for Answering Aggregative Ques- tions, November 2025
Omri Koshorek, Niv Granot, Aviv Alloni, Shahar Admati, Roee Hendel, Ido Weiss, Alan Arazi, Shay-Nitzan Cohen, and Yonatan Belinkov. Structured RAG for Answering Aggregative Ques- tions, November 2025. URL http://arxiv.org/abs/2511.08505. arXiv:2511.08505 [cs]
-
[61]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
-
[62]
Lost in Embeddings: Information Loss in Vision–Language Models
Wenyan Li, Raphael Tang, Chengzu Li, Caiqi Zhang, Ivan Vuli´c, and Anders Søgaard. Lost in Embeddings: Information Loss in Vision–Language Models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 22676–22693, Suzhou, China, November
work page 2025
-
[64]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual Instruction Tun- ing.Advances in Neural Information Processing Systems, 36:34892–34916, Decem- ber 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 6dcf277ea32ce3288914faf369fe6de0-Abstract-Conference.html
work page 2023
-
[65]
Yiming Liu, Yuhui Zhang, Dhruba Ghosh, Ludwig Schmidt, and Serena Yeung-Levy. Data or Language Supervision: What Makes CLIP Better than DINO? In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 1868–1874, Suzhou, China, November 2025. Associ...
-
[66]
MuG: A Multimodal Classification Benchmark on Game Data with Tabular, Textual, and Visual Fields
Jiaying Lu, Yongchen Qian, Shifan Zhao, Yuanzhe Xi, and Carl Yang. MuG: A Multimodal Classification Benchmark on Game Data with Tabular, Textual, and Visual Fields. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 5332–5346, Singapore, December 2023. Association for Computat...
-
[67]
Can Agentic AI Match the Performance of Human Data Scientists?, December 2025
An Luo, Jin Du, Fangqiao Tian, Xun Xian, Robert Specht, Ganghua Wang, Xuan Bi, Charles Fleming, Jayanth Srinivasa, Ashish Kundu, Mingyi Hong, and Jie Ding. Can Agentic AI Match the Performance of Human Data Scientists?, December 2025. URL http://arxiv. org/abs/2512.20959. arXiv:2512.20959 [cs]
-
[68]
Time: Tabpfn-integrated multimodal engine for robust tabular-image learning, 2025
Jiaqi Luo, Yuan Yuan, and Shixin Xu. TIME: TabPFN-Integrated Multimodal Engine for Robust Tabular-Image Learning, June 2025. URL http://arxiv.org/abs/2506.00813. arXiv:2506.00813 [cs]
-
[69]
Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Hamidreza Kamkari, Alex Labach, Jesse C. Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L. Caterini, and Maksims V olkovs. TabDPT: Scaling Tabular Foundation Models on Real Data, July 2025. URL http://arxiv. org/abs/2410.18164. arXiv:2410.18164 [cs]
-
[70]
QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations
Chaitanya Malaviya, Peter Shaw, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 14032–14047, Toronto, Canada, 2023. Associa- tion for Computationa...
-
[71]
Principal components analysis (PCA).Com- puters & Geosciences, 19(3):303–342, March 1993
Andrzej Ma´ckiewicz and Waldemar Ratajczak. Principal components analysis (PCA).Com- puters & Geosciences, 19(3):303–342, March 1993. ISSN 0098-3004. doi: 10.1016/ 0098-3004(93)90090-R. URL https://www.sciencedirect.com/science/article/ pii/009830049390090R
-
[72]
Duncan McElfresh, Sujay Khandagale, Jonathan Valverde, Vishak Prasad C, Ganesh Ramakr- ishnan, Micah Goldblum, and Colin White. When Do Neural Nets Outperform Boosted Trees on Tabular Data?Advances in Neural Information Processing Systems, 36:76336–76369, De- cember 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/ hash/f06d5ebd4ff40b40dd97...
work page 2023
-
[73]
A multimodal approach to predict social media popularity
Mayank Meghawat, Satyendra Yadav, Debanjan Mahata, Yifang Yin, Rajiv Ratn Shah, and Roger Zimmermann. A multimodal approach to predict social media popularity. In2018 IEEE conference on multimedia information processing and retrieval (MIPR), pages 190–195. IEEE, 2018
work page 2018
-
[74]
Towards Benchmarking Foundation Models for Tabular Data With Text
Martin Mráz, Breenda Das, Anshul Gupta, Lennart Purucker, and Frank Hutter. Towards Benchmarking Foundation Models for Tabular Data With Text. June 2025. URL https: //openreview.net/forum?id=yrmoQG9NAV
work page 2025
-
[75]
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. MTEB: Massive Text Embedding Benchmark. In Andreas Vlachos and Isabelle Augenstein, editors,Proceedings of the 17th Conference of the European Chapter of the Association for Computational Lin- guistics, pages 2014–2037, Dubrovnik, Croatia, May 2023. Association for Computational Linguistics....
-
[76]
Transformers Can Do Bayesian Inference
Samuel Müller, Noah Hollmann, Sebastian Pineda Arango, Josif Grabocka, and Frank Hutter. Transformers Can Do Bayesian Inference. October 2021. URL https://openreview.net/ forum?id=KSugKcbNf9
work page 2021
-
[77]
Yaakov Ophir, Refael Tikochinski, Christa SC Asterhan, Itay Sisso, and Roi Reichart. Deep neural networks detect suicide risk from textual facebook posts.Scientific reports, 10(1): 16685, 2020
work page 2020
-
[78]
Lost in Space: Probing Fine-grained Spatial Understanding in Vision and Language Resamplers
Georgios Pantazopoulos, Alessandro Suglia, Oliver Lemon, and Arash Eshghi. Lost in Space: Probing Fine-grained Spatial Understanding in Vision and Language Resamplers. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tec...
-
[79]
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit- learn: Machine learning in python.the Journal of machine Learning research, 12:2825–2830, 2011
work page 2011
-
[80]
CatBoost: unbiased boosting with categorical features
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Doro- gush, and Andrey Gulin. CatBoost: unbiased boosting with categorical features. InAdvances in Neural Information Processing Systems, volume 31. Curran Asso- ciates, Inc., 2018. URL https://proceedings.neurips.cc/paper/2018/hash/ 14491b756b3a51daac41c24863285549-Abstract.html
work page 2018
-
[81]
Yuan Pu, Zhuolun He, Yuqi Jiang, Tairu Qiu, Haoyuan Wu, Qi Sun, Cheng Zhuo, and Bei Yu. Customized Retrieval Augmented Generation and Benchmarking for EDA Tool Documentation QA.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 44 (12):4615–4628, December 2025. ISSN 1937-4151. doi: 10.1109/TCAD.2025.3568776. URL https://ieeexpl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.