Layer-Isolated Evaluation: Gating the Deterministic Scaffold of a Production LLM Agent with a No-LLM, Regression-Locked Test Harness
Pith reviewed 2026-06-27 10:02 UTC · model grok-4.3
The pith
A fixed taxonomy of agent layers with per-layer deterministic tests localizes regressions that end-to-end metrics mask.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
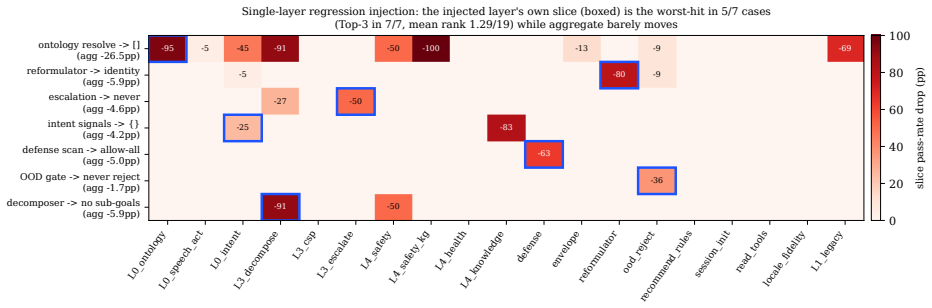
Layer-isolated evaluation decomposes the agent into ontology, intent, routing, decomposition, escalation, safety, memory, and cross-cutting envelope/defense layers. Each layer receives a dedicated no-LLM assertion slice exercised in deterministic pure mode. Controlled regression injection into one layer at a time produces the masking effect in which the aggregate pass-rate moves only -1.7 to -5.9 points while the affected slice falls -25 to -91 points; the injected layer's slice ranks first or top-three in every case.
What carries the argument
The no-LLM per-slice assertion harness locked to per-layer baselines, built on a fixed eight-layer taxonomy that creates isolated test slices for each layer.
If this is right
- Aggregate pass rates can mask layer-specific regressions while per-slice baselines detect them.
- Faults injected into one layer crater only that layer's slice and leave the others largely intact.
- The localization pattern holds on a second structurally different tenant.
- The harness supplies a coverage-honesty criterion that refuses to score an unexercised layer.
- The approach supplies a concrete deterministic realization of component-level evaluation for production agents.
Where Pith is reading between the lines
- The same layer decomposition and slice design could be applied to ordering agents in other retail domains.
- The deterministic harness could be paired with stochastic workflow mutation testing to give both targeted and broad coverage.
- Adopting per-slice gates in CI could shorten the time between a regression and its identification in deployed agents.
- Extending the taxonomy with additional cross-cutting concerns might tighten isolation for safety or memory layers.
Load-bearing premise
The fixed taxonomy of layers permits creation of non-overlapping no-LLM assertion slices that faithfully isolate each layer's behavior.
What would settle it
An experiment in which degrading one layer fails to make its own slice the worst-hit or top-three slice, or makes the aggregate drop as much as the slice, would falsify the localization result.
Figures
read the original abstract
End-to-end task-success is the dominant way to evaluate LLM agents, but one aggregate number tells you that an agent regressed, not where. We present layer-isolated evaluation: a deployed ordering agent is decomposed into a fixed taxonomy of layers (ontology, intent, routing, decomposition, escalation, safety, memory, and cross-cutting envelope/defense), each exercised by its own assertion slice in a deterministic, no-LLM "pure" mode. The pure suite (238 cases across 23 slices; 225 run in 2.39 s, ~10 ms/case) runs in CI on every change against a locked per-slice baseline. We validate by controlled regression injection, degrading one layer at a time across seven non-safety layers. The effect we did not design in is masking: the aggregate pass-rate barely moves (-1.7 to -5.9 pp for six local regressions), while the matching slice craters (-25 to -91 pp). A layer's slice reacting to its own fault is partly by construction; the measured results are (i) the aggregate masking and (ii) that damage stays off the other slices: the injected layer's slice is the single worst-hit in 5 of 7 cases and top-3 in 7 of 7 (mean rank 1.29 of 19). Localization replicates on a second, structurally different tenant (Starbucks SG): all seven matching slices crater, so it is not a single-catalog artifact. We position it as a concrete, deterministic instantiation of the component-level evaluation EDDOps prescribes but leaves unimplemented, with CheckList as ancestor and as the deterministic mirror image of whole-workflow stochastic mutation testing. Our contributions: (a) a fully decomposed, sub-second, no-LLM per-layer harness for a production agent, (b) a coverage-honesty test-adequacy criterion that refuses to score an unexercised layer, and (c) the regression-injection demonstration that per-slice baseline-locked gates localize regressions an aggregate metric masks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces layer-isolated evaluation for production LLM agents, decomposing the system into a fixed 8-layer taxonomy (ontology, intent, routing, decomposition, escalation, safety, memory, cross-cutting envelope/defense) with 23 dedicated no-LLM assertion slices in a deterministic harness (238 cases, sub-second runtime). Controlled regression injection across seven layers shows aggregate pass-rate masking (-1.7 to -5.9 pp change) while matching slices crater (-25 to -91 pp), with the injected layer's slice worst-hit in 5/7 cases and top-3 in all (mean rank 1.29/19); results replicate on a second tenant.
Significance. If the isolation claim holds, the work supplies a practical, reproducible, CI-integrable deterministic harness that localizes regressions masked by end-to-end metrics, directly instantiating component-level evaluation for agents with explicit regression-injection validation and cross-tenant replication as empirical strengths.
major comments (2)
- [regression injection validation and method] The localization result (damage stays off other slices) is load-bearing for the central claim yet rests on the unverified assumption that the 23 slices exercise exactly one layer each with no cross-layer assertion triggering. The regression-injection section provides no cross-slice coverage matrix, no enumeration of inter-layer data flows, and no independent check that ontology/intent/etc. boundaries align with production code paths; without this, the observed isolation is not shown to be fully empirical rather than partly by construction of the assertion definitions.
- [taxonomy and slice construction] The fixed taxonomy is presented as enabling non-overlapping slices, but the paper supplies no explicit verification step (e.g., fault propagation analysis or boundary alignment test) that a change classified as layer Y cannot falsify an assertion the authors assign to layer X; this directly affects interpretability of the "injected layer's slice is the single worst-hit" finding across the seven cases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validation of our layer-isolated evaluation approach. We address each major comment below.
read point-by-point responses
-
Referee: [regression injection validation and method] The localization result (damage stays off other slices) is load-bearing for the central claim yet rests on the unverified assumption that the 23 slices exercise exactly one layer each with no cross-layer assertion triggering. The regression-injection section provides no cross-slice coverage matrix, no enumeration of inter-layer data flows, and no independent check that ontology/intent/etc. boundaries align with production code paths; without this, the observed isolation is not shown to be fully empirical rather than partly by construction of the assertion definitions.
Authors: We agree that providing a cross-slice coverage matrix and enumeration of inter-layer data flows would strengthen the empirical basis of the isolation claim. In the revised manuscript, we will add a dedicated subsection on slice construction that includes a coverage matrix mapping each assertion slice to its primary layer and notes on data flows. We will also describe the alignment of layer boundaries with production code paths. The regression injections were performed via direct modifications to layer-specific code in the production system, and the resulting data showing damage confined to the matching slices (with the injected layer's slice worst-hit in 5/7 cases) offers empirical evidence beyond construction. We will clarify this distinction in the text. revision: yes
-
Referee: [taxonomy and slice construction] The fixed taxonomy is presented as enabling non-overlapping slices, but the paper supplies no explicit verification step (e.g., fault propagation analysis or boundary alignment test) that a change classified as layer Y cannot falsify an assertion the authors assign to layer X; this directly affects interpretability of the "injected layer's slice is the single worst-hit" finding across the seven cases.
Authors: We accept that an explicit verification step such as fault propagation analysis would improve the rigor of our taxonomy presentation. The revised paper will include a fault propagation analysis subsection, detailing how the taxonomy boundaries were chosen to minimize overlap and providing examples of boundary alignment tests performed during slice development. This will directly support the interpretability of the localization findings. revision: yes
Circularity Check
No circularity; harness uses pre-locked baselines and external fault injections
full rationale
The paper's central results (aggregate masking and per-slice localization) are obtained by running a deterministic no-LLM assertion suite against baselines locked before any injections, then measuring effects of externally supplied layer-specific regressions. The abstract explicitly distinguishes the partly-by-construction own-slice reaction from the empirical observations of masking and cross-slice isolation. No equations, fitted parameters renamed as predictions, self-citations, uniqueness theorems, or ansatzes appear. The taxonomy and slices are inputs to the method, not outputs derived from the experimental results. The evaluation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The production LLM agent can be decomposed into the eight listed layers with minimal functional overlap.
invented entities (1)
-
Per-layer assertion slices
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Varun Pratap Bhardwaj. AgentAssay: Token-efficient regression testing for non-deterministic AI agent workflows.arXiv preprint arXiv:2603.02601,
-
[2]
arXiv:2310.06770. Xiao Liu et al. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representations (ICLR),
-
[3]
arXiv:2308.03688. Chang Ma et al. AgentBoard: An analytical evaluation board of multi-turn LLM agents. In Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track,
-
[4]
Parsa Mazaheri and Kasra Mazaheri
arXiv:2401.13178. Parsa Mazaheri and Kasra Mazaheri. AgentAtlas: Beyond outcome leaderboards for LLM agents. arXiv preprint arXiv:2605.20530,
-
[5]
GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983,
Grégoire Mialon, Clémentine Fourrier, et al. GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983,
-
[6]
Evaluation and benchmarking of LLM agents: A survey.arXiv preprint arXiv:2507.21504,
Mahmoud Mohammadi et al. Evaluation and benchmarking of LLM agents: A survey.arXiv preprint arXiv:2507.21504,
-
[7]
Yihao Qin, Shangwen Wang, Yiling Lou, Jinhao Dong, Kaixin Wang, Xiaoling Li, and Xiaoguang Mao. AgentFL: Scaling LLM-based fault localization to project-level context.arXiv preprint arXiv:2403.16362,
-
[8]
T., Wu, T., Guestrin, C., & Singh, S
arXiv:2005.04118; DOI 10.18653/v1/2020.acl-main.442. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[9]
arXiv:2303.11366. Haoyu Sun et al. Agent planning benchmark (APB): A diagnostic framework for planning capabilities in LLM agents.arXiv preprint arXiv:2606.04874,
-
[10]
Boming Xia et al. Evaluation-driven development and operations of LLM agents: A process model and reference architecture.arXiv preprint arXiv:2411.13768,
-
[11]
arXiv:2210.03629. Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045,
-
[12]
Machine learning testing: Survey, landscapes and horizons,
arXiv:1906.10742; DOI 10.1109/TSE.2019.2962027. Sawyer Zhang, Alexander Wang, and Sophie Lei. Catching one in five: LLM-as-judge blind spots in production multi-turn transaction agents,
-
[13]
arXiv:2606.10315. Shuyan Zhou et al. WebArena: A realistic web environment for building autonomous agents. In International Conference on Learning Representations (ICLR),
-
[14]
arXiv:2307.13854. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.