Catching One in Five: LLM-as-Judge Blind Spots in Production Multi-Turn Transaction Agents
Pith reviewed 2026-06-27 13:26 UTC · model grok-4.3
The pith
LLM judges miss most defects in multi-turn agents, catching under a quarter of human-confirmed issues due to rubric limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
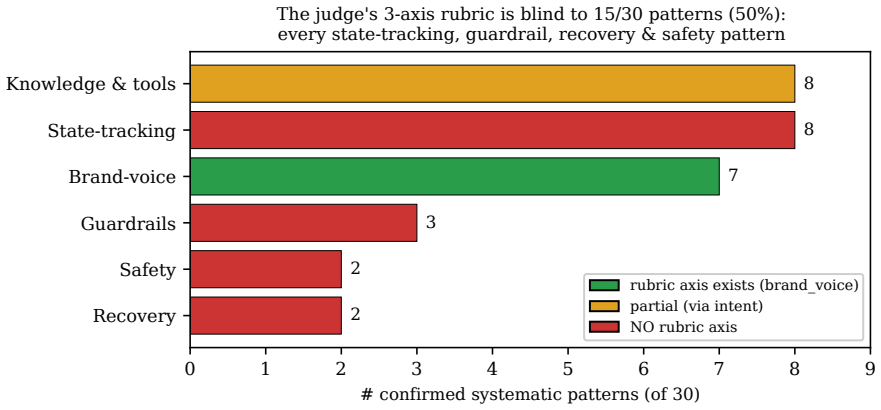
In three batches from a deployed multi-turn transaction agent, the built-in LLM judge surfaced well under a quarter of human-confirmed systematic problems: 2 of 9 patterns (22 percent) in one batch, and its operational gate flagged zero of 100 rounds in a batch where humans confirmed 23 distinct defects and 7 new cross-cutting patterns. The blind spots are structured rather than random, with the judge catching turn-local issues but missing cross-turn state issues such as confirm-gate lockout, cart hallucination, escalation lockout, and stale referents. The mechanism is that the rubric exposes only three coarse axes and has no category for state-tracking, guardrails, or recovery, while 113 of
What carries the argument
The blind-spot taxonomy that separates turn-local issues from cross-turn state issues, produced by a three-axis rubric and score-routing logic that diverts state defects away from failure detection.
If this is right
- Automated judging functions only as a regression floor and cannot replace human review for production multi-turn agents.
- When the reported defect rate is zero, estimators such as Rogan-Gladen cannot recover any signal of the true rate.
- Where the gate reports a nonzero rate, the measured sensitivity implies the true defect count is 3-6 times higher.
- The observed failure is a routing-and-wiring problem, not a perceptual limit of the underlying model.
Where Pith is reading between the lines
- Rubrics for LLM judges on transactional agents would need dedicated axes for state management and recovery to close the documented gaps.
- The same cross-turn blind spots are likely to appear in other production domains that require consistent multi-turn behavior, such as booking or support agents.
- Targeted human audits focused on state-related dimensions could be combined with LLM scoring to mitigate the routing failure.
Load-bearing premise
Exhaustive human transcript review supplies complete and unbiased ground truth for every defect present in the three studied batches.
What would settle it
A second independent human review of the same transcripts that identifies substantially fewer defects than the first review, or a new production batch in which the judge flags more than half of the defects later confirmed by humans.
Figures
read the original abstract
LLM-as-judge is the default instrument for evaluating conversational agents, yet its reliability is almost always reported as agreement with human ratings, not recall of real defects. We study a deployed multi-turn food-and-beverage ordering agent and measure how many genuine quality problems its built-in LLM judge catches, using exhaustive human transcript review as ground truth. Across three batches the judge surfaces well under a quarter of human-confirmed systematic problems -- 2 of 9 patterns (22%) in one batch, and its operational gate flagged zero of 100 rounds in a batch where humans confirmed 23 distinct defects and 7 new cross-cutting patterns. Our blind-spot taxonomy shows the failure is structured, not random: the judge catches turn-local issues (a fabricated statistic, a wrong language) but misses cross-turn state issues (confirm-gate lockout, cart hallucination, escalation lockout, stale referents). The mechanism: the scoring rubric exposes only three coarse axes (intent, brand-voice, personalization) and has no category for the behavioural dimensions -- state-tracking, guardrails, recovery -- where most defects cluster. The failure is routing, not perception: 113 of 114 rounds whose raw judge note describes a confirm-gate or cart-state defect are scored "brand voice", and none reach an operational failure -- the gate is wired to hangs and hard assertions, not the rubric -- so the 0% is a routing-and-wiring failure, not blindness. The consequence for prevalence estimation is sharp: when the apparent defect rate is zero the Rogan-Gladen correction degenerates -- no signal can recover the true rate -- while where the gate reports a nonzero rate the same estimator implies a 3-6x undercount under our measured sensitivity. For production multi-turn agents, automated judging is a regression floor, not a substitute for human review.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-as-judge systems for production multi-turn agents exhibit structured blind spots, detecting well under a quarter of human-confirmed systematic defects (e.g., 2 of 9 patterns or 22% in one batch; 0 of 100 rounds despite 23 human defects and 7 new patterns in another). Using exhaustive human transcript review as ground truth on a deployed food-and-beverage ordering agent, it attributes failures to a coarse three-axis rubric lacking state-tracking/guardrails categories and to routing/wiring issues (e.g., 113/114 relevant judge notes scored as 'brand voice' and none triggering operational gates), with implications for Rogan-Gladen prevalence correction and the need for human review.
Significance. If the human ground truth is reliable, the work provides direct empirical evidence of low recall in real production settings, a structured taxonomy distinguishing turn-local vs. cross-turn defects, and a perception-vs-routing analysis that clarifies why automated judging underperforms. These findings are actionable for conversational AI evaluation pipelines and underscore that LLM judges function as a regression floor rather than a full substitute.
major comments (1)
- [Abstract / study description] Abstract and study description: The recall figures (2/9 patterns at 22%; 0/100 rounds with 23 defects) and blind-spot taxonomy are computed directly against human-identified defects as ground truth. No details are reported on annotator count, inter-annotator agreement, blinding protocol, or batch selection criteria. This assumption is load-bearing for the central claim of low recall and structured failures.
minor comments (1)
- [Abstract] Abstract: The Rogan-Gladen correction is referenced without citation or brief explanation; adding a reference would improve accessibility for readers unfamiliar with the estimator.
Simulated Author's Rebuttal
We thank the referee for identifying the critical need for transparency around the human ground truth process, which is indeed foundational to our recall claims. We will revise the manuscript to add a dedicated Methods subsection with the requested details on annotation procedures, while noting any constraints inherent to the production setting.
read point-by-point responses
-
Referee: [Abstract / study description] Abstract and study description: The recall figures (2/9 patterns at 22%; 0/100 rounds with 23 defects) and blind-spot taxonomy are computed directly against human-identified defects as ground truth. No details are reported on annotator count, inter-annotator agreement, blinding protocol, or batch selection criteria. This assumption is load-bearing for the central claim of low recall and structured failures.
Authors: We agree this information should have been included. The human review was performed exhaustively by the two paper authors (both with direct access to the production logs and agent implementation) over multiple passes to identify systematic defects. No formal inter-annotator agreement statistic was computed because the process was not designed as a multi-annotator labeling task; instead, defects were validated by cross-referencing multiple independent transcripts exhibiting the same pattern and confirming via agent state logs. Blinding was not applied, as the reviewers required system-internal knowledge to distinguish defects from expected behavior. Batches were selected as consecutive production windows meeting minimum turn-length and volume thresholds to ensure multi-turn coverage. In revision we will add an explicit subsection describing these procedures, any limitations (e.g., lack of IAA), and the criteria used, thereby allowing readers to assess ground-truth reliability directly. revision: yes
Circularity Check
No circularity: direct empirical measurement with no derivations or self-referential chains
full rationale
This is an observational study reporting raw counts of defects identified by human transcript review versus an LLM judge. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. The central claims (e.g., 2 of 9 patterns caught, 0/100 rounds flagged) are direct comparisons against the stated ground truth process, with no reduction by construction to the paper's own inputs. The study is self-contained as an empirical measurement against external human review.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human exhaustive transcript review constitutes complete, unbiased ground truth for all defects
Forward citations
Cited by 1 Pith paper
-
Layer-Isolated Evaluation: Gating the Deterministic Scaffold of a Production LLM Agent with a No-LLM, Regression-Locked Test Harness
Layer-isolated evaluation decomposes LLM agents into per-layer deterministic no-LLM test slices whose locked baselines localize regressions that aggregate pass rates mask.
Reference graph
Works this paper leans on
-
[1]
Chen, Sizhu Lu, Sijia Li, Moran Guo, and Shengyi Li
Yiqun T. Chen, Sizhu Lu, Sijia Li, Moran Guo, and Shengyi Li. Efficient inference for noisy LLM-as-a-judge evaluation.arXiv preprint arXiv:2601.05420,
-
[2]
Chen Feng, Minghe Shen, Ananth Balashankar, Carsten Gerner-Beuerle, and Miguel R. D. Rodrigues. Noisy but valid: Robust statistical evaluation of LLMs with imperfect judges.arXiv preprint arXiv:2601.20913,
-
[3]
A survey on LLM-as-a-judge.arXiv preprint arXiv:2411.15594,
Jiawei Gu et al. A survey on LLM-as-a-judge.arXiv preprint arXiv:2411.15594,
-
[4]
Evaluating LLM-based agents for multi-turn conversations: A survey.arXiv preprint arXiv:2503.22458,
Shengyue Guan, Jindong Wang, Jiang Bian, Bin Zhu, Jian-guang Lou, and Haoyi Xiong. Evaluating LLM-based agents for multi-turn conversations: A survey.arXiv preprint arXiv:2503.22458,
-
[5]
Steve Han, Gilberto Titericz Junior, Tom Balough, and Wenfei Zhou. Judge’s verdict: A comprehen- sive analysis of LLM judge capability through human agreement.arXiv preprint arXiv:2510.09738,
-
[6]
Ahmed, Shubham Sahai, and Ben Leong
Suryaansh Jain, Umair Z. Ahmed, Shubham Sahai, and Ben Leong. Beyond consensus: Mitigating the agreeableness bias in LLM judge evaluations.arXiv preprint arXiv:2510.11822,
-
[7]
arXiv:2404.03602. Xiao Liu et al. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representations (ICLR),
-
[8]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu
arXiv:2308.03688. Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG evaluation using GPT-4 with better human alignment. InProceedings of EMNLP,
-
[9]
Xing Han Lù, Amirhossein Kazemnejad, et al
arXiv:2303.16634. Xing Han Lù, Amirhossein Kazemnejad, et al. AgentRewardBench: Evaluating automatic evaluations of web agent trajectories.arXiv preprint arXiv:2504.08942,
- [10]
-
[11]
Lin Shi et al. Judging the judges: A systematic study of position bias in LLM-as-a-judge.arXiv preprint arXiv:2406.07791,
-
[12]
Self-preference bias in LLM-as-a-judge.arXiv preprint arXiv:2410.21819,
Koki Wu et al. Self-preference bias in LLM-as-a-judge.arXiv preprint arXiv:2410.21819,
-
[13]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045,
-
[14]
Justice or prejudice? quantifying biases in LLM-as-a-judge.arXiv preprint arXiv:2410.02736,
Jiayi Ye et al. Justice or prejudice? quantifying biases in LLM-as-a-judge.arXiv preprint arXiv:2410.02736,
-
[15]
arXiv:2306.05685. Shuyan Zhou et al. WebArena: A realistic web environment for building autonomous agents. In International Conference on Learning Representations (ICLR),
-
[16]
arXiv:2307.13854. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.