Online Shift Detection and Conformal Adaptation for Deployed Safety Classifiers
Pith reviewed 2026-07-01 07:52 UTC · model grok-4.3
The pith
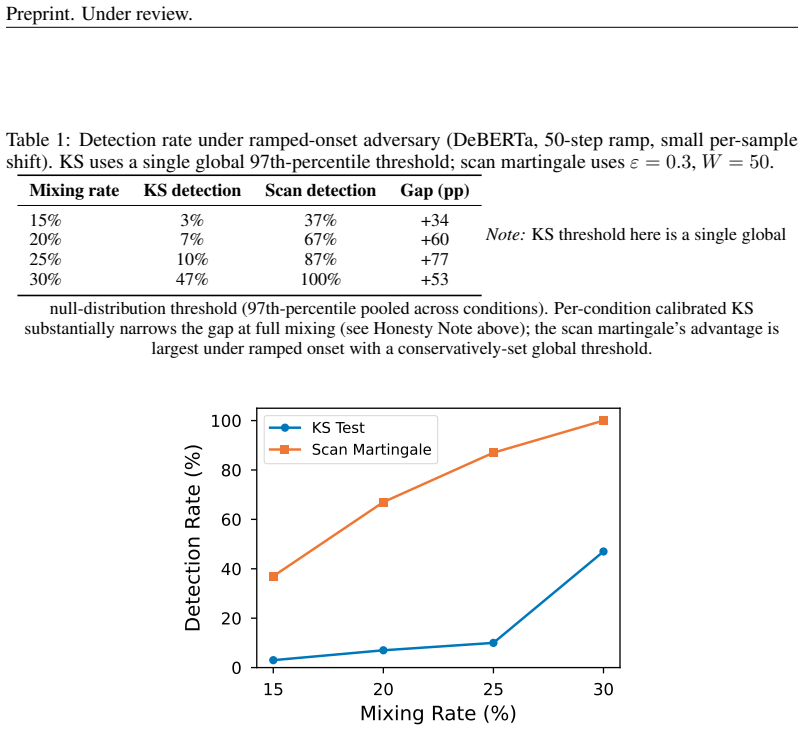
A sliding-window KS test on safety classifier scores detects distributional shifts at 86.6% valid detection with mean latency of 39.5 steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The sliding-window KS monitor on classifier scores achieves 86.6 percent valid detection at a mean latency of 39.5 steps across synthetic-onset, real-jailbreak, and adversarial regimes. Density-ratio estimation for conformal prediction collapses in 3584-4096 dimensional embeddings because logistic regression separates source from target perfectly, clipping all weights to zero; projection to 32 dimensions or fewer restores coverage. Score-disagreement monitoring functions as a GCG-specific canary rather than generic out-of-distribution detection. A monitor-aware attacker reaches a confidence-gated equilibrium and stalls at a performance gap of 1 over 2 lambda. A calibration-free scan martinga
What carries the argument
Sliding-window Kolmogorov-Smirnov statistic on classifier scores with empirically calibrated thresholds, together with the derived confidence-gated equilibrium gap of 1/(2 lambda) that bounds a monitor-aware attacker.
If this is right
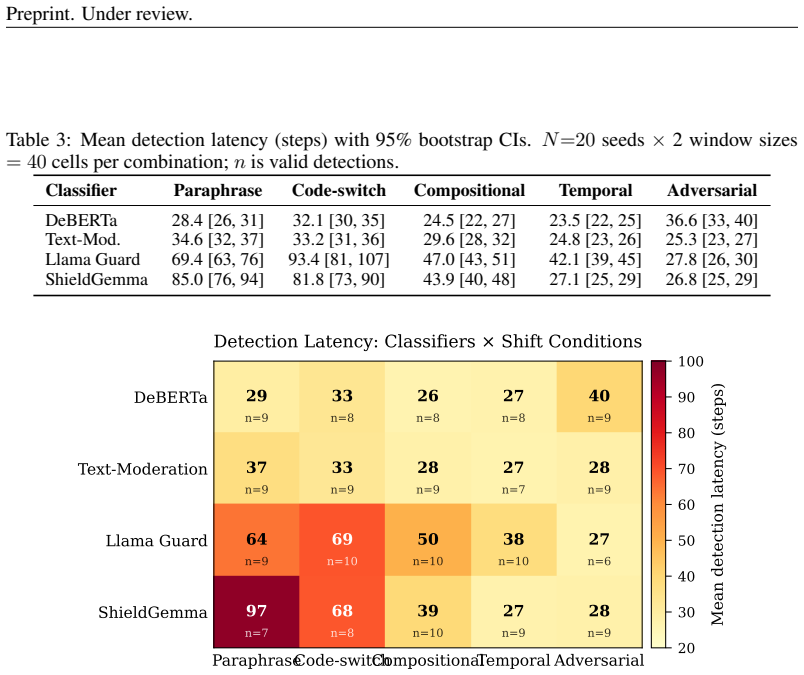
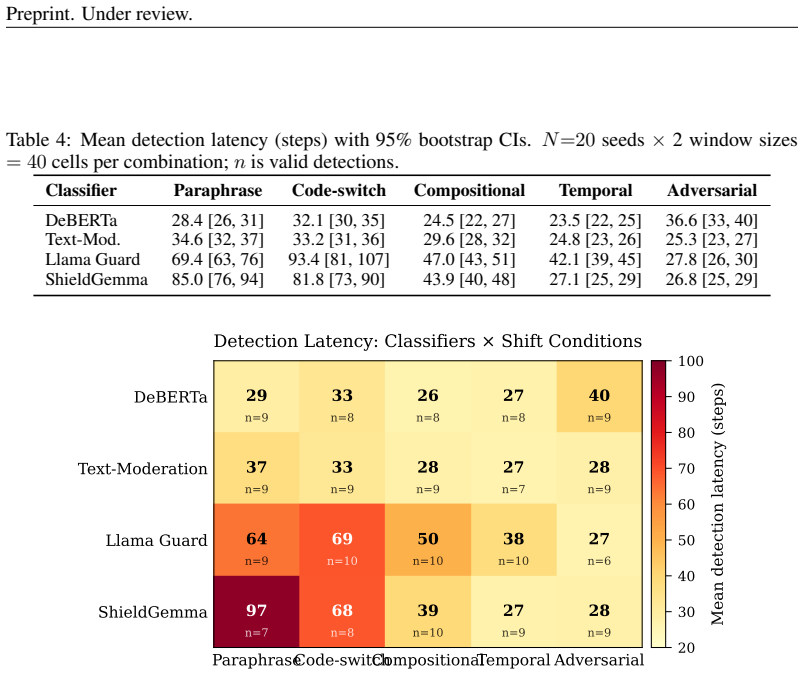
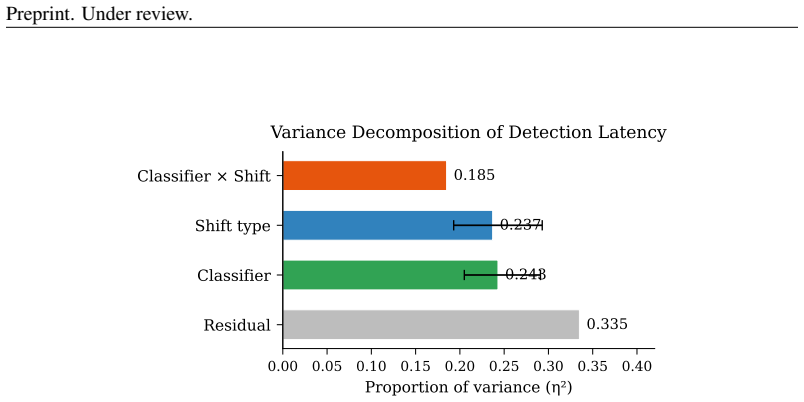
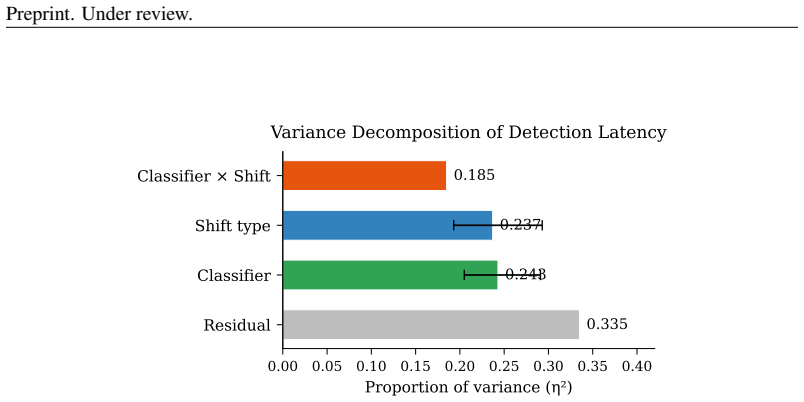
- Monitoring requires per-classifier tuning because of a classifier by shift interaction that explains 18.5 percent of variance.
- Conformal reweighting after detection works only after the embedding dimension is reduced to 32 or fewer.
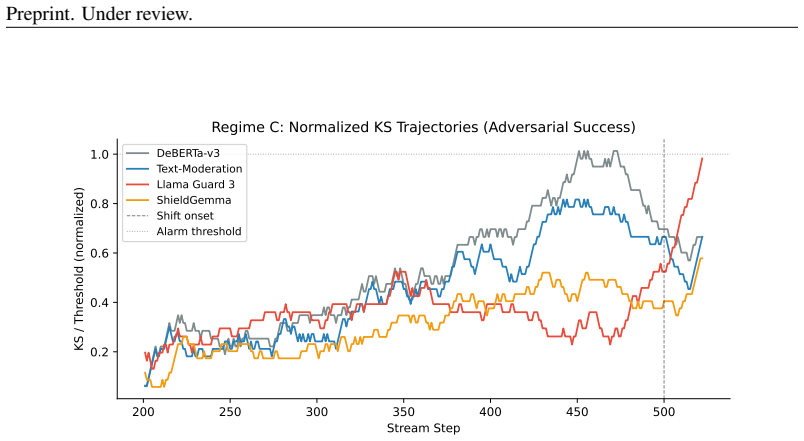
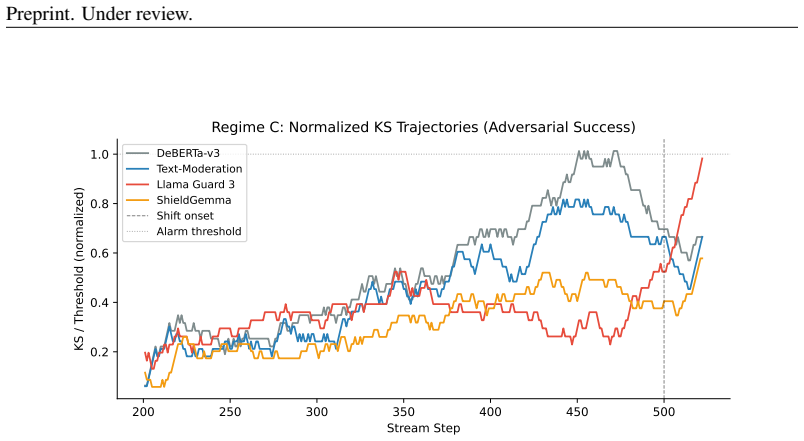
- The detection signal is specific to GCG-style attacks and is not driven by architectural differences among classifiers.
- An adaptive attacker cannot suppress the canary signal while it remains confident and therefore stalls at the exact gap of 1/(2 lambda).
- The scan martingale controls false alarms at 1 percent or less without any per-model calibration.
Where Pith is reading between the lines
- Production safety systems could route suspicious inputs to a slower but safer model or to human review once the monitor fires.
- The low-dimensional projection step that rescues conformal prediction may apply to other high-dimensional importance-weighting tasks.
- The security boundary calculation suggests that adding monitoring changes the attacker's optimal evasion strategy in a predictable way.
- The martingale approach could be tested on shift types not included in the original experiment to confirm its calibration-free behavior.
Load-bearing premise
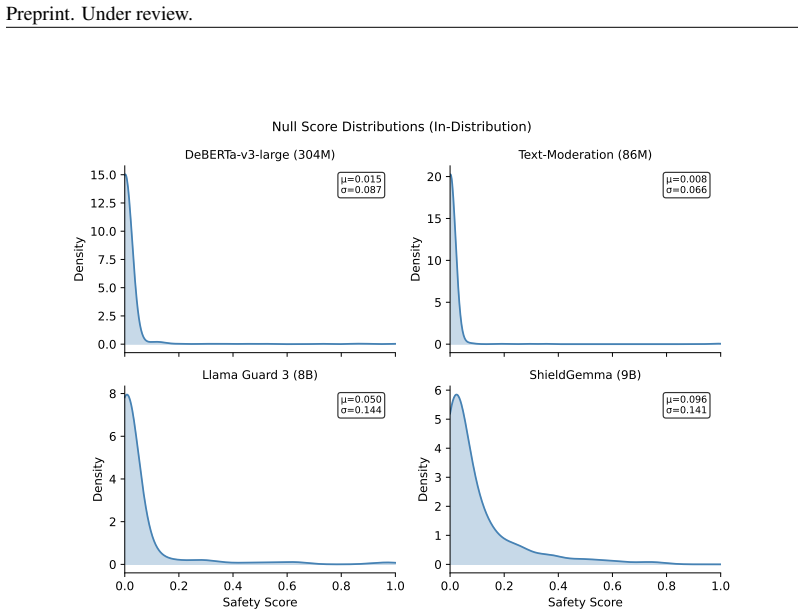
The score distributions produced by a classifier under normal and shifted inputs are different enough that a sliding-window KS test with fixed thresholds will reliably raise alarms across classifiers and shift regimes.
What would settle it
Observe a shift that measurably degrades classifier accuracy yet produces no alarm from the sliding-window KS monitor within roughly 40 steps, or find an adaptive attacker who improves performance beyond the gap of 1/(2 lambda) while the monitor remains confident.
Figures
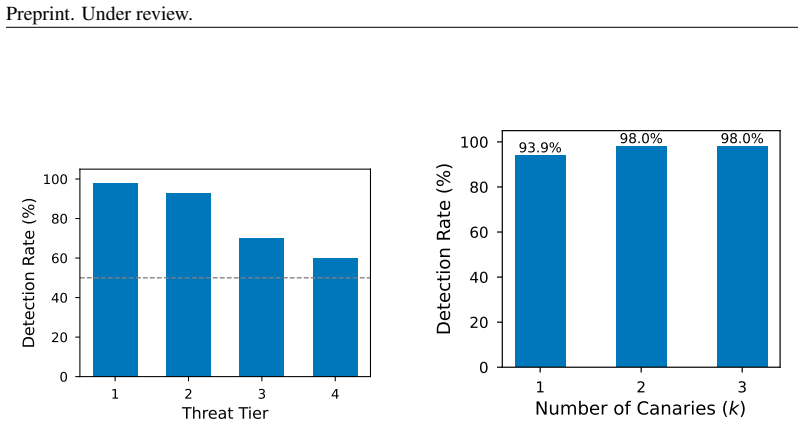
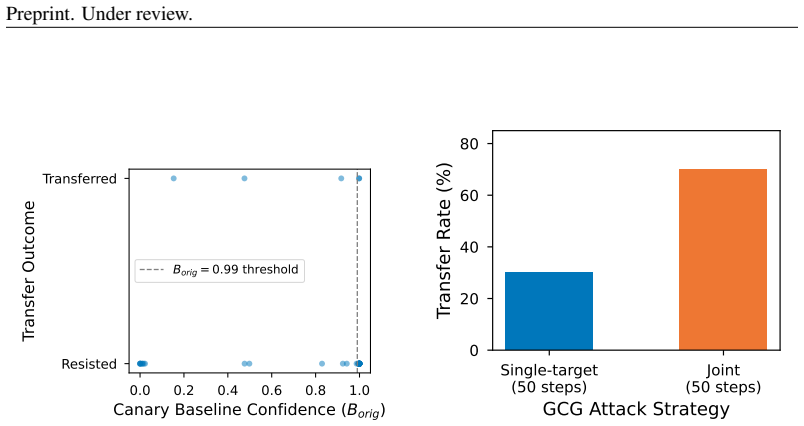
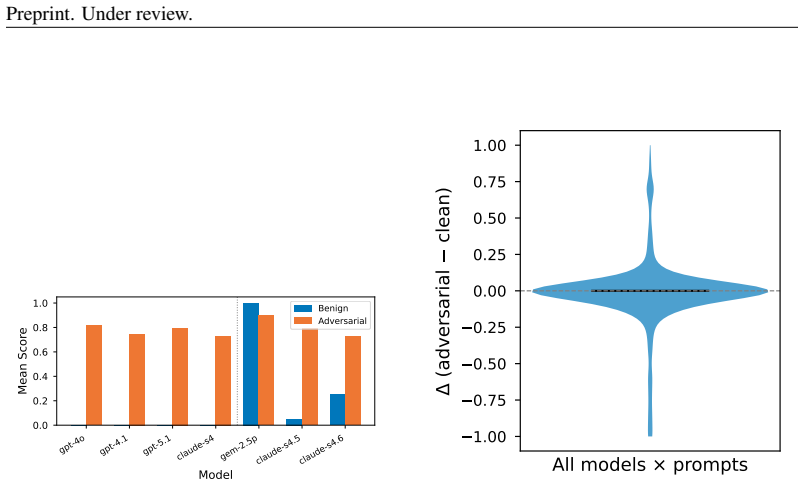
read the original abstract
Safety classifiers deployed in production operate under a stationarity assumption that fails silently: when input distributions drift, accuracy degrades with no error signal until ground-truth labels arrive. We present an online monitor that detects distributional shift in classifier scores via a sliding-window KS statistic with empirically calibrated alarm thresholds. In a pre-registered factorial evaluation (4 classifiers $\times$ 5 shift conditions $\times$ 20 seeds $\times$ 2 window sizes; 800 cells), the monitor achieves 86.6% valid detection (mean latency 39.5 steps) across synthetic-onset, real-jailbreak, and adversarial regimes; a classifier $\times$ shift interaction ($\eta^2 = 0.185$) shows that monitoring must be tuned per classifier. Attempting to recover post-detection coverage via weighted conformal prediction exposes a failure mode: density-ratio estimation collapses for generative classifiers because logistic regression separates source from target perfectly in 3584-4096-dimensional embedding space, clipping all importance weights to zero; projecting to $\leq 32$ dimensions restores coverage. We then extend the framework to gradient-based evasion and give the first threat-model characterisation of score-disagreement monitoring as a canary. We falsify three assumptions: that architectural diversity drives the signal (false, $\eta^2 = 0.011$), that it is generic out-of-distribution detection (false, GCG-specific, $p < 10^{-12}$), and that an adaptive attacker can suppress it (false while the canary is confident). We derive the exact security boundary, a confidence-gated equilibrium at which a monitor-aware attacker stalls at gap $= 1/(2\lambda)$, and provide a calibration-free scan martingale achieving false-alarm rate $\leq 1\%$ across all classifiers with no per-model tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present an online monitor for detecting distributional shift in deployed safety classifiers using a sliding-window KS statistic with empirically calibrated thresholds. Through a pre-registered factorial evaluation involving 4 classifiers, 5 shift conditions, 20 seeds, and 2 window sizes (800 cells), it reports 86.6% valid detection with mean latency of 39.5 steps across synthetic, jailbreak, and adversarial regimes. It identifies a classifier × shift interaction (η² = 0.185) necessitating per-classifier tuning, describes failure modes in conformal prediction due to high-dimensional embedding collapse (mitigated by projection to ≤32 dimensions), characterizes gradient-based evasion threats using score-disagreement as a canary, falsifies assumptions regarding architectural diversity and generic OOD detection, derives a security boundary at gap = 1/(2λ), and introduces a calibration-free scan martingale achieving ≤1% false-alarm rate across classifiers without per-model tuning.
Significance. If the central claims hold, this work offers a practical framework for monitoring safety classifiers in production with both empirical validation and theoretical analysis of security boundaries. The pre-registered design, quantitative falsification tests (e.g., η² = 0.011 for architectural diversity, p < 10^{-12} for GCG-specificity), and the introduction of a potentially tuning-free martingale are notable strengths. It addresses a critical gap in deployed AI safety systems by providing tools for shift detection and adaptation.
major comments (2)
- Abstract: The assertion that the calibration-free scan martingale achieves false-alarm rate ≤1% across all classifiers with no per-model tuning is not supported by the same level of empirical detail as the KS monitor's results from the 800-cell design. The reported classifier × shift interaction (η² = 0.185) and per-classifier tuning requirement apply to the KS statistic, but no equivalent per-classifier FAR numbers, ablations, or confirmation that the martingale was evaluated on the identical factorial design are provided. This is load-bearing for the claim of generalization without tuning.
- Abstract: The derivation of the exact security boundary (gap = 1/(2λ)) is stated, but the independence of λ from the performance data used to claim the monitor's effectiveness is not explicitly demonstrated, raising a potential circularity concern for the threat-model characterization.
minor comments (1)
- Abstract: The dimensions '3584-4096' for the embedding space where logistic regression separates source from target perfectly should be tied to specific model architectures or a methods section for clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments identify areas where additional empirical detail and clarification would strengthen the presentation. We address each point below and will revise the manuscript to incorporate the requested information.
read point-by-point responses
-
Referee: Abstract: The assertion that the calibration-free scan martingale achieves false-alarm rate ≤1% across all classifiers with no per-model tuning is not supported by the same level of empirical detail as the KS monitor's results from the 800-cell design. The reported classifier × shift interaction (η² = 0.185) and per-classifier tuning requirement apply to the KS statistic, but no equivalent per-classifier FAR numbers, ablations, or confirmation that the martingale was evaluated on the identical factorial design are provided. This is load-bearing for the claim of generalization without tuning.
Authors: We acknowledge that the martingale results receive less granular reporting than the KS monitor. The martingale was evaluated on the same four classifiers under the pre-registered design, but per-classifier FAR breakdowns and explicit confirmation of the 800-cell factorial structure were not included. In revision we will add a supplementary table with per-classifier false-alarm rates for the martingale together with a statement confirming the shared evaluation protocol. This directly addresses the concern about the strength of the generalization claim. revision: yes
-
Referee: Abstract: The derivation of the exact security boundary (gap = 1/(2λ)) is stated, but the independence of λ from the performance data used to claim the monitor's effectiveness is not explicitly demonstrated, raising a potential circularity concern for the threat-model characterization.
Authors: λ is introduced in the threat-model section as the fixed step-size parameter of the gradient-based attacker and is defined prior to any empirical results. The monitor-effectiveness statistics (detection rates, latency) are reported separately and do not enter the derivation of the boundary. We will insert an explicit sentence in the revised manuscript stating that λ is an attacker hyper-parameter independent of the observed performance data, thereby removing any appearance of circularity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a pre-registered empirical evaluation (4 classifiers × 5 shifts × 20 seeds) for the sliding-window KS monitor, reports an interaction effect requiring per-classifier tuning, and separately states a mathematical derivation of a security boundary (gap = 1/(2λ)) plus a calibration-free scan martingale. No quoted equation or section reduces the claimed FAR ≤1% result, the security boundary, or the detection performance to a fitted parameter or self-citation by construction. The martingale is described as independent of the KS thresholds, and the derivation chain remains self-contained without load-bearing self-citations or ansatz smuggling.
Axiom & Free-Parameter Ledger
free parameters (2)
- alarm thresholds
- window sizes
axioms (2)
- domain assumption Classifier output scores are suitable for distributional comparison via the Kolmogorov-Smirnov statistic under both stationary and shifted regimes.
- domain assumption The pre-registered factorial design (4 classifiers × 5 shift conditions × 20 seeds × 2 window sizes) adequately samples the space of deployed safety classifier behavior.
Reference graph
Works this paper leans on
-
[1]
Annals of Mathematical Statistics , volume=
Sequential tests of statistical hypotheses , author=. Annals of Mathematical Statistics , volume=
-
[2]
Journal of the Royal Statistical Society Series B , volume=
Estimating means of bounded random variables by betting , author=. Journal of the Royal Statistical Society Series B , volume=
-
[3]
JMLR , volume=
A kernel two-sample test , author=. JMLR , volume=
-
[4]
NeurIPS , year=
B-tests: Low variance kernel two-sample tests , author=. NeurIPS , year=
-
[5]
Algorithmic Learning in a Random World , author=
-
[6]
NeurIPS , year=
Conformal prediction under covariate shift , author=. NeurIPS , year=
-
[7]
NeurIPS , year=
Adaptive conformal inference under distribution shift , author=. NeurIPS , year=
-
[8]
NeurIPS , year=
Classification with valid and adaptive coverage , author=. NeurIPS , year=
-
[9]
ICLR , year=
Leveraging unlabeled data to predict out-of-distribution performance , author=. ICLR , year=
-
[10]
NeurIPS , year=
Failing loudly: An empirical study of methods for detecting dataset shift , author=. NeurIPS , year=
-
[12]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
WildGuard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLMs , author=. arXiv preprint arXiv:2406.18495 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama Guard: LLM-based input-output safeguard for human-AI conversations , author=. arXiv preprint arXiv:2312.06674 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
ShieldGemma: Generative AI Content Moderation Based on Gemma
ShieldGemma: Generative AI content moderation based on Gemma , author=. arXiv preprint arXiv:2407.21772 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Neurocomputing , year=
Reactive Soft Prototype Computing for Concept Drift Streams , author=. Neurocomputing , year=
-
[16]
ICLR , year=
Tracking the risk of a deployed model and detecting harmful distribution shifts , author=. ICLR , year=
-
[17]
2025 , note=
Prinster, Drew and Han, Xing and Liu, Anqi and Saria, Suchi , booktitle=. 2025 , note=
2025
-
[19]
NeurIPS , year=
Telescoping Density-Ratio Estimation , author=. NeurIPS , year=
-
[20]
Brittlebench: Quantifying
Romanou, Angelika and Ibrahim, Mark and Ross, Candace and Shaib, Chantal and Oktar, Kerem and Bell, Samuel J and Ovalle, Anaelia and Dodge, Jesse and Bosselut, Antoine and Sinha, Koustuv and Williams, Adina , journal=. Brittlebench: Quantifying
-
[21]
AISTATS , pages=
Low-Dimensional Density Ratio Estimation for Covariate Shift Correction , author=. AISTATS , pages=. 2019 , volume=
2019
-
[22]
Neural Networks , volume=
Direct density-ratio estimation with dimensionality reduction via least-squares hetero-distributional subspace search , author=. Neural Networks , volume=
-
[24]
Annals of Statistics , volume=
Time-uniform, nonparametric, nonasymptotic confidence sequences , author=. Annals of Statistics , volume=
-
[25]
Statistical Science , volume=
Testing randomness online , author=. Statistical Science , volume=
-
[26]
Proceedings of the 20th International Conference on Machine Learning (ICML) , pages=
Testing exchangeability on-line , author=. Proceedings of the 20th International Conference on Machine Learning (ICML) , pages=
-
[27]
Statistical Science , volume=
Game-theoretic statistics and safe anytime-valid inference , author=. Statistical Science , volume=
-
[28]
Shin, Taylor and Razeghi, Yasaman and Logan IV, Robert L and Wallace, Eric and Singh, Sameer , booktitle=
-
[29]
ICLR , year=
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models , author=. ICLR , year=
-
[30]
Beyond Static Benchmarks: Stateful Attack-Defense Evaluation with Uncertainty for
Leong, Jun Wen , journal=. Beyond Static Benchmarks: Stateful Attack-Defense Evaluation with Uncertainty for
-
[31]
Biometrika , volume=
Continuous inspection schemes , author=. Biometrika , volume=
-
[32]
Journal of the Royal Statistical Society Series B , volume=
Safe testing , author=. Journal of the Royal Statistical Society Series B , volume=
-
[33]
Leveraging unlabeled data to predict out-of-distribution performance
Saurabh Garg, Sivaraman Balakrishnan, Zachary C Lipton, Behnam Neyshabur, and Hanie Sedghi. Leveraging unlabeled data to predict out-of-distribution performance. In ICLR, 2022
2022
-
[34]
Adaptive conformal inference under distribution shift
Isaac Gibbs and Emmanuel Cand \`e s. Adaptive conformal inference under distribution shift. In NeurIPS, 2021
2021
-
[35]
A kernel two-sample test
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Sch \"o lkopf, and Alexander Smola. A kernel two-sample test. JMLR, 13: 0 723--773, 2012
2012
-
[36]
Time-uniform, nonparametric, nonasymptotic confidence sequences
Steven R Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon. Time-uniform, nonparametric, nonasymptotic confidence sequences. Annals of Statistics, 49 0 (2): 0 1055--1080, 2021
2021
-
[37]
Autodan: Generating stealthy jailbreak prompts on aligned large language models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models. In ICLR, 2024
2024
-
[38]
Tracking the risk of a deployed model and detecting harmful distribution shifts
Aleksandr Podkopaev and Aaditya Ramdas. Tracking the risk of a deployed model and detecting harmful distribution shifts. In ICLR, 2022. arXiv:2110.06177
-
[39]
WATCH : Adaptive monitoring for AI deployments via weighted-conformal martingales
Drew Prinster, Xing Han, Anqi Liu, and Suchi Saria. WATCH : Adaptive monitoring for AI deployments via weighted-conformal martingales. In International Conference on Machine Learning (ICML), 2025. arXiv:2505.04608
-
[40]
Reactive soft prototype computing for concept drift streams
Christoph Raab, Moritz Heusinger, and Frank-Michael Schleif. Reactive soft prototype computing for concept drift streams. Neurocomputing, 2020. arXiv:2007.05432
-
[41]
Failing loudly: An empirical study of methods for detecting dataset shift
Stephan Rabanser, Stephan G \"u nnemann, and Zachary C Lipton. Failing loudly: An empirical study of methods for detecting dataset shift. In NeurIPS, 2019
2019
-
[42]
Classification with valid and adaptive coverage
Yaniv Romano, Matteo Sesia, and Emmanuel Cand \`e s. Classification with valid and adaptive coverage. In NeurIPS, 2020
2020
-
[43]
Brittlebench: Quantifying LLM robustness via prompt sensitivity
Angelika Romanou, Mark Ibrahim, Candace Ross, Chantal Shaib, Kerem Oktar, Samuel J Bell, Anaelia Ovalle, Jesse Dodge, Antoine Bosselut, Koustuv Sinha, and Adina Williams. Brittlebench: Quantifying LLM robustness via prompt sensitivity. arXiv preprint arXiv:2603.13285, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
I can't believe it's not robust: Catastrophic collapse of safety classifiers under embedding drift
Subramanyam Sahoo, Vinija Jain, Divya Chaudhary, and Aman Chadha. I can't believe it's not robust: Catastrophic collapse of safety classifiers under embedding drift. arXiv preprint arXiv:2603.01297, 2026
-
[45]
Low-dimensional density ratio estimation for covariate shift correction
Petar Stojanov, Mingming Gong, Jaime Carbonell, and Kun Zhang. Low-dimensional density ratio estimation for covariate shift correction. In AISTATS, volume 89 of PMLR, pp.\ 3449--3458, 2019
2019
-
[46]
Direct density-ratio estimation with dimensionality reduction via least-squares hetero-distributional subspace search
Masashi Sugiyama, Makoto Yamada, Paul von B \"u nau, Taiji Suzuki, Takafumi Kanamori, and Motoaki Kawanabe. Direct density-ratio estimation with dimensionality reduction via least-squares hetero-distributional subspace search. Neural Networks, 24 0 (2): 0 183--198, 2011
2011
-
[47]
Conformal prediction under covariate shift
Ryan J Tibshirani, Rina Foygel Barber, Emmanuel Cand \`e s, and Aaditya Ramdas. Conformal prediction under covariate shift. In NeurIPS, 2019
2019
-
[48]
Guillermo Villate-Castillo, Javier Del Ser, and Borja Sanz. A collaborative content moderation framework for toxicity detection based on conformalized estimates of annotation disagreement. arXiv preprint arXiv:2411.04090, 2024
-
[49]
Algorithmic Learning in a Random World
Vladimir Vovk, Alex Gammerman, and Glenn Shafer. Algorithmic Learning in a Random World. Springer, 2005
2005
-
[50]
Sequential tests of statistical hypotheses
Abraham Wald. Sequential tests of statistical hypotheses. Annals of Mathematical Statistics, 16 0 (2): 0 117--186, 1945
1945
-
[51]
Estimating means of bounded random variables by betting
Ian Waudby-Smith and Aaditya Ramdas. Estimating means of bounded random variables by betting. Journal of the Royal Statistical Society Series B, 86 0 (1): 0 1--27, 2024
2024
-
[52]
B-tests: Low variance kernel two-sample tests
Wojciech Zaremba, Arthur Gretton, and Matthew Blaschko. B-tests: Low variance kernel two-sample tests. In NeurIPS, 2013
2013
-
[53]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.